 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Segment Boundary Detection via Class Entropy Measurements in Connectionist Phoneme Recognition
Jan 12, 2024
This article investigates the possibility to use the class entropy of the output of a connectionist phoneme recogniser to predict time boundaries between phonetic classes. The rationale is that the value of the entropy should increase in proximity of a transition between two segments that are well modelled (known) by the recognition network since it is a measure of uncertainty. The advantage of this measure is its simplicity as the posterior probabilities of each class are available in connectionist phoneme recognition. The entropy and a number of measures based on differentiation of the entropy are used in isolation and in combination. The decision methods for predicting the boundaries range from simple thresholds to neural network based procedure. The different methods are compared with respect to their precision, measured in terms of the ratio between the number C of predicted boundaries within 10 or 20 msec of the reference and the total number of predicted boundaries, and recall, measured as the ratio between C and the total number of reference boundaries.
Edge-Enabled Anomaly Detection and Information Completion for Social Network Knowledge Graphs
Jan 13, 2024In the rapidly advancing information era, various human behaviors are being precisely recorded in the form of data, including identity information, criminal records, and communication data. Law enforcement agencies can effectively maintain social security and precisely combat criminal activities by analyzing the aforementioned data. In comparison to traditional data analysis methods, deep learning models, relying on the robust computational power in cloud centers, exhibit higher accuracy in extracting data features and inferring data. However, within the architecture of cloud centers, the transmission of data from end devices introduces significant latency, hindering real-time inference of data. Furthermore, low-latency edge computing architectures face limitations in direct deployment due to relatively weak computing and storage capacities of nodes. To address these challenges, a lightweight distributed knowledge graph completion architecture is proposed. Firstly, we introduce a lightweight distributed knowledge graph completion architecture that utilizes knowledge graph embedding for data analysis. Subsequently, to filter out substandard data, a personnel data quality assessment method named PDQA is proposed. Lastly, we present a model pruning algorithm that significantly reduces the model size while maximizing performance, enabling lightweight deployment. In experiments, we compare the effects of 11 advanced models on completing the knowledge graph of public security personnel information. The results indicate that the RotatE model outperforms other models significantly in knowledge graph completion, with the pruned model size reduced by 70\%, and hits@10 reaching 86.97\%.}
BP(λ): Online Learning via Synthetic Gradients
Jan 13, 2024Training recurrent neural networks typically relies on backpropagation through time (BPTT). BPTT depends on forward and backward passes to be completed, rendering the network locked to these computations before loss gradients are available. Recently, Jaderberg et al. proposed synthetic gradients to alleviate the need for full BPTT. In their implementation synthetic gradients are learned through a mixture of backpropagated gradients and bootstrapped synthetic gradients, analogous to the temporal difference (TD) algorithm in Reinforcement Learning (RL). However, as in TD learning, heavy use of bootstrapping can result in bias which leads to poor synthetic gradient estimates. Inspired by the accumulate $\mathrm{TD}(\lambda)$ in RL, we propose a fully online method for learning synthetic gradients which avoids the use of BPTT altogether: accumulate $BP(\lambda)$. As in accumulate $\mathrm{TD}(\lambda)$, we show analytically that accumulate $\mathrm{BP}(\lambda)$ can control the level of bias by using a mixture of temporal difference errors and recursively defined eligibility traces. We next demonstrate empirically that our model outperforms the original implementation for learning synthetic gradients in a variety of tasks, and is particularly suited for capturing longer timescales. Finally, building on recent work we reflect on accumulate $\mathrm{BP}(\lambda)$ as a principle for learning in biological circuits. In summary, inspired by RL principles we introduce an algorithm capable of bias-free online learning via synthetic gradients.
Parameter-Efficient Detoxification with Contrastive Decoding
Jan 13, 2024The field of natural language generation has witnessed significant advancements in recent years, including the development of controllable text generation techniques. However, controlling the attributes of the generated text remains a challenge, especially when aiming to avoid undesirable behavior such as toxicity. In this work, we introduce Detoxification Generator (DETOXIGEN), an inference-time algorithm that steers the generation away from unwanted styles. DETOXIGEN is an ensemble of a pre-trained language model (generator) and a detoxifier. The detoxifier is trained intentionally on the toxic data representative of the undesirable attribute, encouraging it to generate text in that style exclusively. During the actual generation, we use the trained detoxifier to produce undesirable tokens for the generator to contrast against at each decoding step. This approach directly informs the generator to avoid generating tokens that the detoxifier considers highly likely. We evaluate DETOXIGEN on the commonly used REALTOXICITYPROMPTS benchmark (Gehman et al., 2020) with various language models as generators. We find that it significantly outperforms previous approaches in detoxification metrics while not compromising on the generation quality. Moreover, the detoxifier is obtained by soft prompt-tuning using the same backbone language model as the generator. Hence, DETOXIGEN requires only a tiny amount of extra weights from the virtual tokens of the detoxifier to be loaded into GPU memory while decoding, making it a promising lightweight, practical, and parameter-efficient detoxification strategy.
CLeaRForecast: Contrastive Learning of High-Purity Representations for Time Series Forecasting
Dec 10, 2023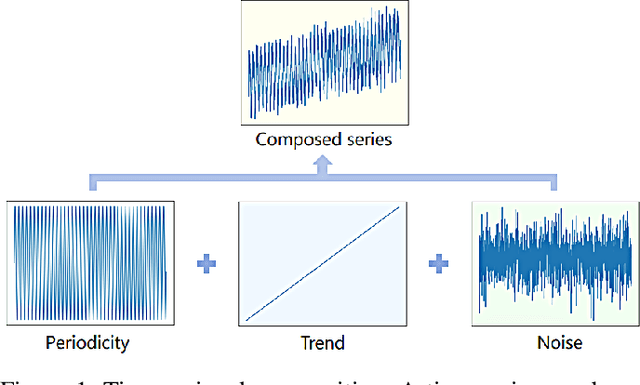
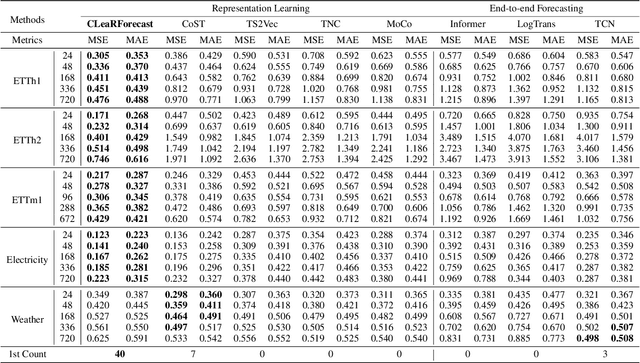
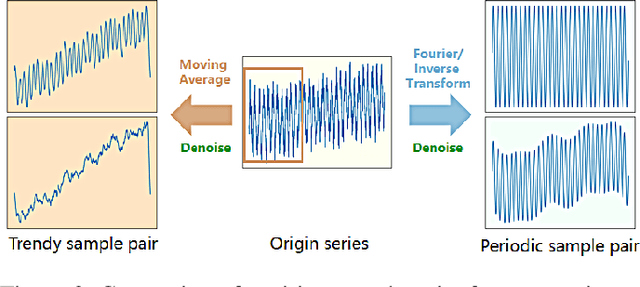
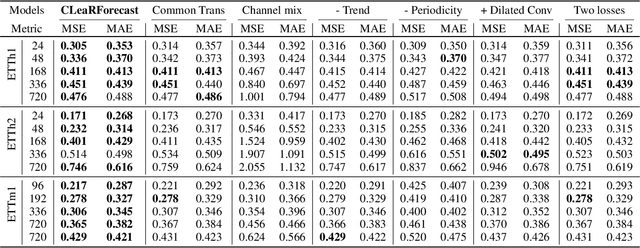
Time series forecasting (TSF) holds significant importance in modern society, spanning numerous domains. Previous representation learning-based TSF algorithms typically embrace a contrastive learning paradigm featuring segregated trend-periodicity representations. Yet, these methodologies disregard the inherent high-impact noise embedded within time series data, resulting in representation inaccuracies and seriously demoting the forecasting performance. To address this issue, we propose CLeaRForecast, a novel contrastive learning framework to learn high-purity time series representations with proposed sample, feature, and architecture purifying methods. More specifically, to avoid more noise adding caused by the transformations of original samples (series), transformations are respectively applied for trendy and periodic parts to provide better positive samples with obviously less noise. Moreover, we introduce a channel independent training manner to mitigate noise originating from unrelated variables in the multivariate series. By employing a streamlined deep-learning backbone and a comprehensive global contrastive loss function, we prevent noise introduction due to redundant or uneven learning of periodicity and trend. Experimental results show the superior performance of CLeaRForecast in various downstream TSF tasks.
CautionSuicide: A Deep Learning Based Approach for Detecting Suicidal Ideation in Real Time Chatbot Conversation
Jan 02, 2024Suicide is recognized as one of the most serious concerns in the modern society. Suicide causes tragedy that affects countries, communities, and families. There are many factors that lead to suicidal ideations. Early detection of suicidal ideations can help to prevent suicide occurrence by providing the victim with the required professional support, especially when the victim does not recognize the danger of having suicidal ideations. As technology usage has increased, people share and express their ideations digitally via social media, chatbots, and other digital platforms. In this paper, we proposed a novel, simple deep learning-based model to detect suicidal ideations in digital content, mainly focusing on chatbots as the primary data source. In addition, we provide a framework that employs the proposed suicide detection integration with a chatbot-based support system.
Combating Adversarial Attacks with Multi-Agent Debate
Jan 11, 2024While state-of-the-art language models have achieved impressive results, they remain susceptible to inference-time adversarial attacks, such as adversarial prompts generated by red teams arXiv:2209.07858. One approach proposed to improve the general quality of language model generations is multi-agent debate, where language models self-evaluate through discussion and feedback arXiv:2305.14325. We implement multi-agent debate between current state-of-the-art language models and evaluate models' susceptibility to red team attacks in both single- and multi-agent settings. We find that multi-agent debate can reduce model toxicity when jailbroken or less capable models are forced to debate with non-jailbroken or more capable models. We also find marginal improvements through the general usage of multi-agent interactions. We further perform adversarial prompt content classification via embedding clustering, and analyze the susceptibility of different models to different types of attack topics.
MultiSlot ReRanker: A Generic Model-based Re-Ranking Framework in Recommendation Systems
Jan 11, 2024In this paper, we propose a generic model-based re-ranking framework, MultiSlot ReRanker, which simultaneously optimizes relevance, diversity, and freshness. Specifically, our Sequential Greedy Algorithm (SGA) is efficient enough (linear time complexity) for large-scale production recommendation engines. It achieved a lift of $+6\%$ to $ +10\%$ offline Area Under the receiver operating characteristic Curve (AUC) which is mainly due to explicitly modeling mutual influences among items of a list, and leveraging the second pass ranking scores of multiple objectives. In addition, we have generalized the offline replay theory to multi-slot re-ranking scenarios, with trade-offs among multiple objectives. The offline replay results can be further improved by Pareto Optimality. Moreover, we've built a multi-slot re-ranking simulator based on OpenAI Gym integrated with the Ray framework. It can be easily configured for different assumptions to quickly benchmark both reinforcement learning and supervised learning algorithms.
Graph Q-Learning for Combinatorial Optimization
Jan 11, 2024Graph-structured data is ubiquitous throughout natural and social sciences, and Graph Neural Networks (GNNs) have recently been shown to be effective at solving prediction and inference problems on graph data. In this paper, we propose and demonstrate that GNNs can be applied to solve Combinatorial Optimization (CO) problems. CO concerns optimizing a function over a discrete solution space that is often intractably large. To learn to solve CO problems, we formulate the optimization process as a sequential decision making problem, where the return is related to how close the candidate solution is to optimality. We use a GNN to learn a policy to iteratively build increasingly promising candidate solutions. We present preliminary evidence that GNNs trained through Q-Learning can solve CO problems with performance approaching state-of-the-art heuristic-based solvers, using only a fraction of the parameters and training time.
Change points detection in crime-related time series: an on-line fuzzy approach based on a shape space representation
Dec 18, 2023The extension of traditional data mining methods to time series has been effectively applied to a wide range of domains such as finance, econometrics, biology, security, and medicine. Many existing mining methods deal with the task of change points detection, but very few provide a flexible approach. Querying specific change points with linguistic variables is particularly useful in crime analysis, where intuitive, understandable, and appropriate detection of changes can significantly improve the allocation of resources for timely and concise operations. In this paper, we propose an on-line method for detecting and querying change points in crime-related time series with the use of a meaningful representation and a fuzzy inference system. Change points detection is based on a shape space representation, and linguistic terms describing geometric properties of the change points are used to express queries, offering the advantage of intuitiveness and flexibility. An empirical evaluation is first conducted on a crime data set to confirm the validity of the proposed method and then on a financial data set to test its general applicability. A comparison to a similar change-point detection algorithm and a sensitivity analysis are also conducted. Results show that the method is able to accurately detect change points at very low computational costs. More broadly, the detection of specific change points within time series of virtually any domain is made more intuitive and more understandable, even for experts not related to data mining.