 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Implicit Integration for Articulated Bodies with Contact via the Nonconvex Maximal Dissipation Principle
Oct 28, 2020
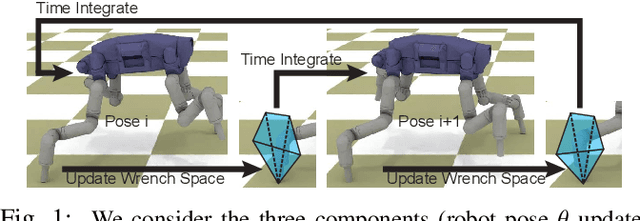



We present non-convex maximal dissipation principle (NMDP), a time integration scheme for articulated bodies with simultaneous contacts. Our scheme resolves contact forces via the maximal dissipation principle (MDP). Prior MDP solvers compute contact forces via convex programming by assuming linearized dynamics integrated using the forward multistep scheme. Instead, we consider the coupled system of nonlinear Newton-Euler dynamics and MDP, which is time-integrated using the backward integration scheme. We show that the coupled system of equations can be solved efficiently using the projected gradient method with guaranteed convergence. We evaluate our method by predicting several locomotion trajectories for a quadruped robot. The results show that our NMDP scheme has several desirable properties including: (1) generalization to novel contact models; (2) superior stability under large timestep sizes; (3) consistent trajectory generation under varying timestep sizes.
Persistent Rule-based Interactive Reinforcement Learning
Feb 04, 2021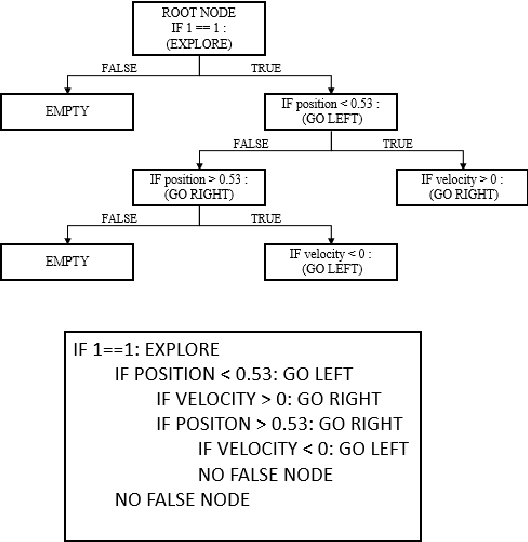
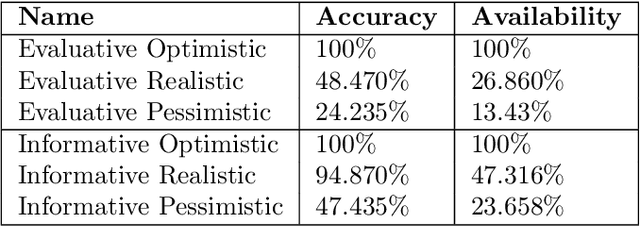
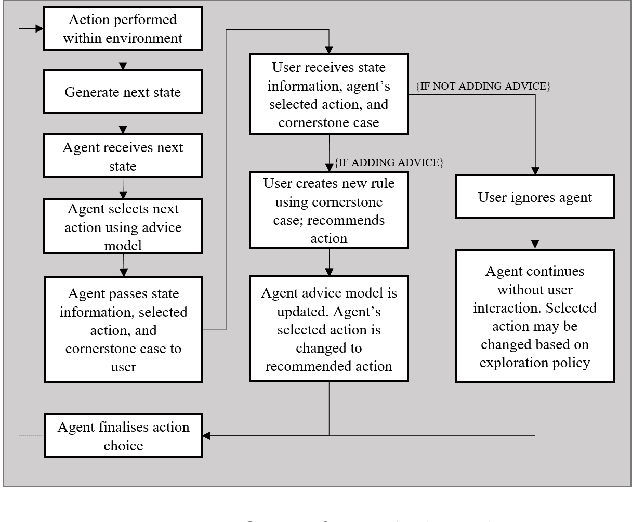
Interactive reinforcement learning has allowed speeding up the learning process in autonomous agents by including a human trainer providing extra information to the agent in real-time. Current interactive reinforcement learning research has been limited to interactions that offer relevant advice to the current state only. Additionally, the information provided by each interaction is not retained and instead discarded by the agent after a single-use. In this work, we propose a persistent rule-based interactive reinforcement learning approach, i.e., a method for retaining and reusing provided knowledge, allowing trainers to give general advice relevant to more than just the current state. Our experimental results show persistent advice substantially improves the performance of the agent while reducing the number of interactions required for the trainer. Moreover, rule-based advice shows similar performance impact as state-based advice, but with a substantially reduced interaction count.
GVINS: Tightly Coupled GNSS-Visual-Inertial for Smooth and Consistent State Estimation
Mar 14, 2021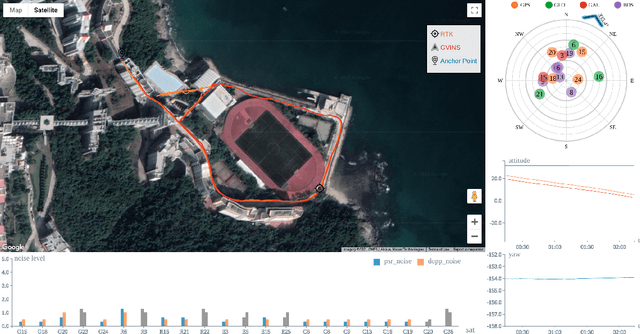
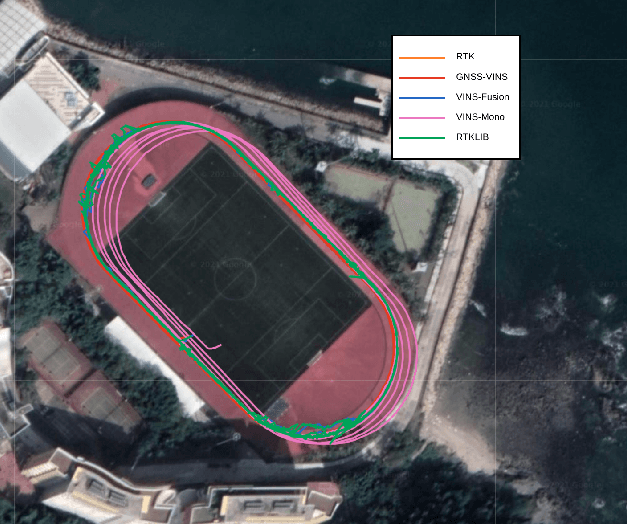
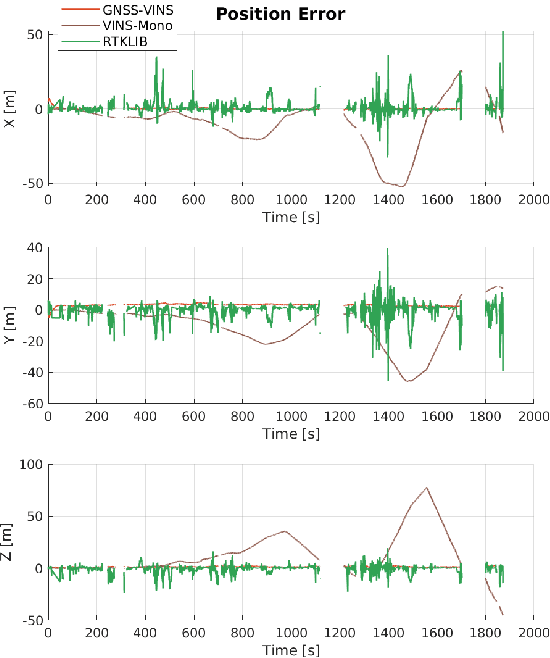
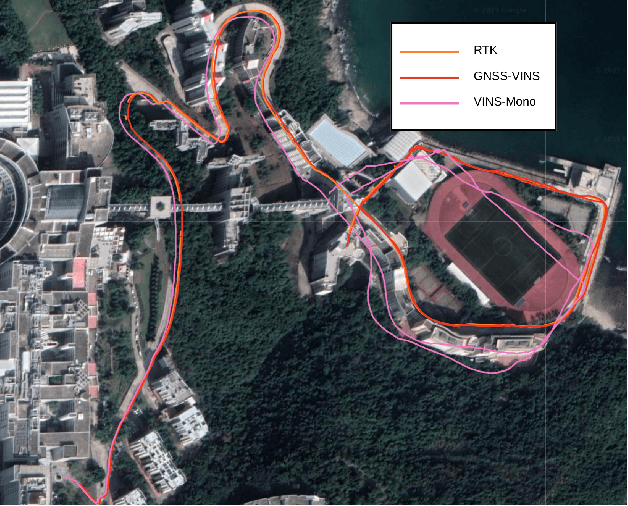
Visual-Inertial odometry is known to suffer from drifting especially over long-term runs. In this paper, we present GVINS, a non-linear optimization based system that tightly fuses GNSS raw measurements with visual and inertial information for real-time and drift-free state estimation. The proposed system combines merits from VIO and GNSS system, thus is able to achieve both local smoothness and global consistency. To associate global measurements with local states, a coarse-to-fine initialization procedure is proposed to efficiently online calibrate the transformation and initialize GNSS states from only a short window of measurements. The GNSS pseudorange and Doppler shift measurements are modelled and optimized under a factor graph framework along with visual and inertial constraints. For complex and GNSS-unfriendly area, the degenerate cases are discussed and carefully handled to ensure robustness. The engineering challenges involved in the system are also included to facilitate relevant GNSS fusion researches. Thanks to the tightly-coupled multi-sensor approach and system design, our estimator is able to recover the position and orientation in the global Earth frame, even with less than 4 satellites being tracked. We extensively evaluate the proposed system on simulation and real-world experiments, and the result demonstrates that our system substantially eliminates the drift of VIO and preserves the accuracy in spite of noisy GNSS measurements.
Training Federated GANs with Theoretical Guarantees: A Universal Aggregation Approach
Feb 09, 2021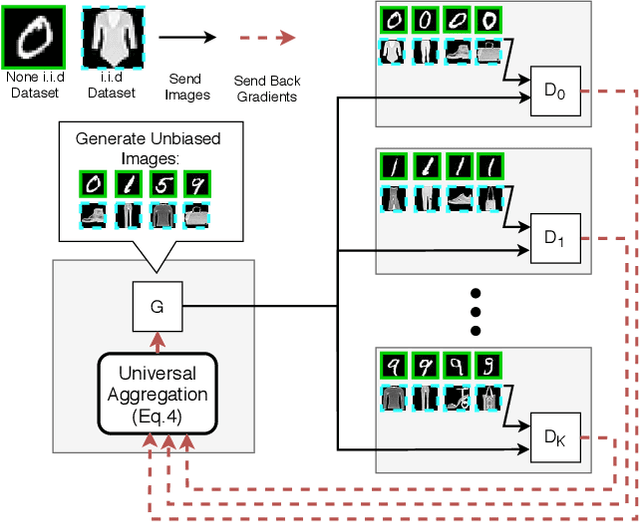
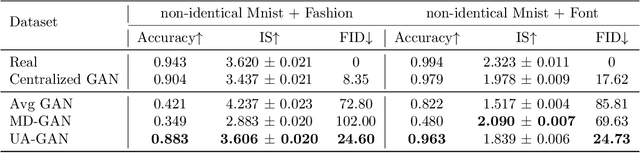
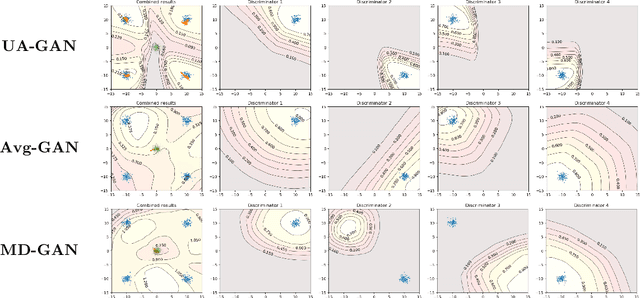
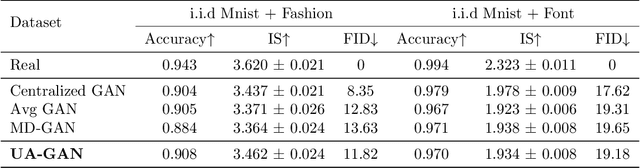
Recently, Generative Adversarial Networks (GANs) have demonstrated their potential in federated learning, i.e., learning a centralized model from data privately hosted by multiple sites. A federatedGAN jointly trains a centralized generator and multiple private discriminators hosted at different sites. A major theoretical challenge for the federated GAN is the heterogeneity of the local data distributions. Traditional approaches cannot guarantee to learn the target distribution, which isa mixture of the highly different local distributions. This paper tackles this theoretical challenge, and for the first time, provides a provably correct framework for federated GAN. We propose a new approach called Universal Aggregation, which simulates a centralized discriminator via carefully aggregating the mixture of all private discriminators. We prove that a generator trained with this simulated centralized discriminator can learn the desired target distribution. Through synthetic and real datasets, we show that our method can learn the mixture of largely different distributions where existing federated GAN methods fail.
Efficient Retrieval Augmented Generation from Unstructured Knowledge for Task-Oriented Dialog
Feb 09, 2021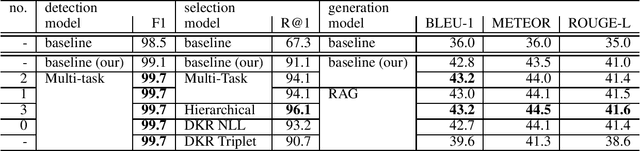
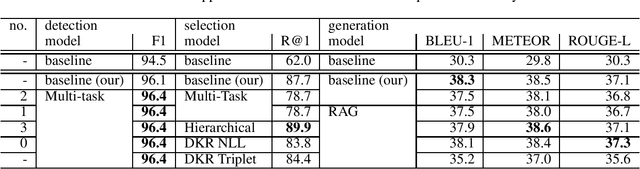

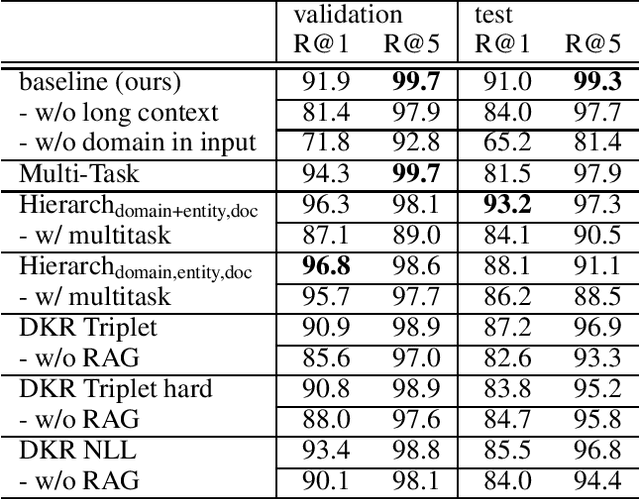
This paper summarizes our work on the first track of the ninth Dialog System Technology Challenge (DSTC 9), "Beyond Domain APIs: Task-oriented Conversational Modeling with Unstructured Knowledge Access". The goal of the task is to generate responses to user turns in a task-oriented dialog that require knowledge from unstructured documents. The task is divided into three subtasks: detection, selection and generation. In order to be compute efficient, we formulate the selection problem in terms of hierarchical classification steps. We achieve our best results with this model. Alternatively, we employ siamese sequence embedding models, referred to as Dense Knowledge Retrieval, to retrieve relevant documents. This method further reduces the computation time by a factor of more than 100x at the cost of degradation in R@1 of 5-6% compared to the first model. Then for either approach, we use Retrieval Augmented Generation to generate responses based on multiple selected snippets and we show how the method can be used to fine-tune trained embeddings.
Acoustic Structure Inverse Design and Optimization Using Deep Learning
Feb 18, 2021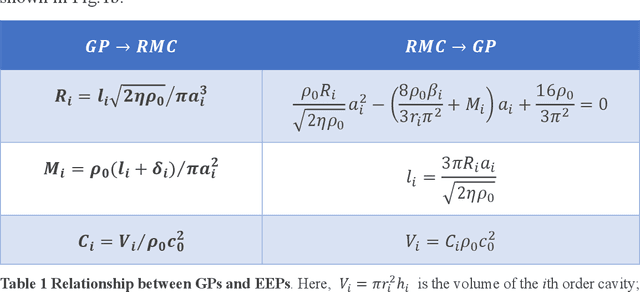
From ancient to modern times, acoustic structures have been used to control the propagation of acoustic waves. However, the design of the acoustic structures has remained widely a time-consuming and computational resource-consuming iterative process. In recent years, Deep Learning has attracted unprecedented attention for its ability to tackle hard problems with huge datasets, which has achieved state-of-the-art results in various tasks. In this work, an acoustic structure design method is proposed based on deep learning. Taking the design of multi-order Helmholtz resonator for instance, we experimentally demonstrate the effectiveness of the proposed method. Our method is not only able to give a very accurate prediction of the geometry of the acoustic structures with multiple strong-coupling parameters, but also capable of improving the performance of evolutionary approaches in optimization for a desired property. Compared with the conventional numerical methods, our method is more efficient, universal and automatic, which has a wide range of potential applications, such as speech enhancement, sound absorption and insulation.
NLP-CIC @ DIACR-Ita: POS and Neighbor Based Distributional Models for Lexical Semantic Change in Diachronic Italian Corpora
Nov 07, 2020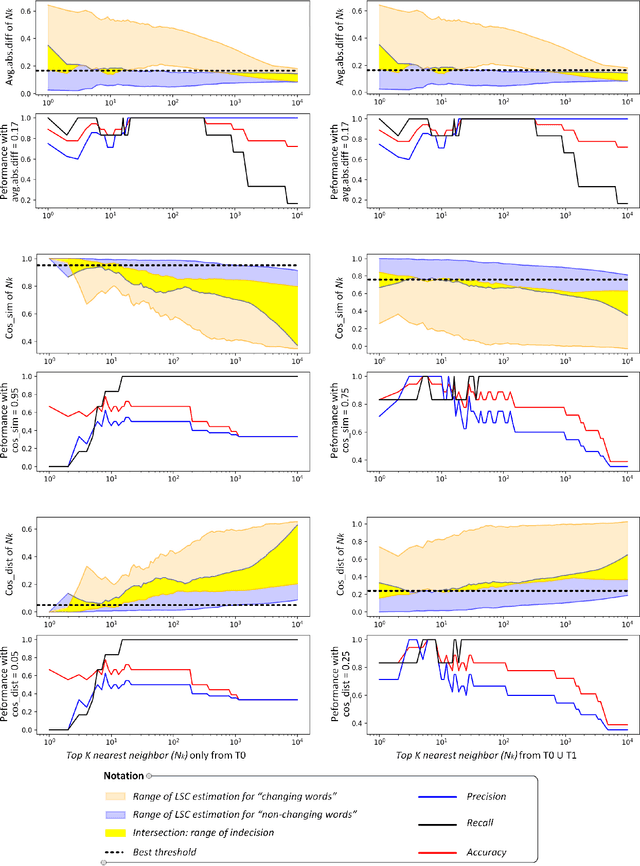


We present our systems and findings on unsupervised lexical semantic change for the Italian language in the DIACR-Ita shared-task at EVALITA 2020. The task is to determine whether a target word has evolved its meaning with time, only relying on raw-text from two time-specific datasets. We propose two models representing the target words across the periods to predict the changing words using threshold and voting schemes. Our first model solely relies on part-of-speech usage and an ensemble of distance measures. The second model uses word embedding representation to extract the neighbor's relative distances across spaces and propose "the average of absolute differences" to estimate lexical semantic change. Our models achieved competent results, ranking third in the DIACR-Ita competition. Furthermore, we experiment with the k_neighbor parameter of our second model to compare the impact of using "the average of absolute differences" versus the cosine distance used in Hamilton et al. (2016).
Active Privacy-utility Trade-off Against a Hypothesis Testing Adversary
Feb 18, 2021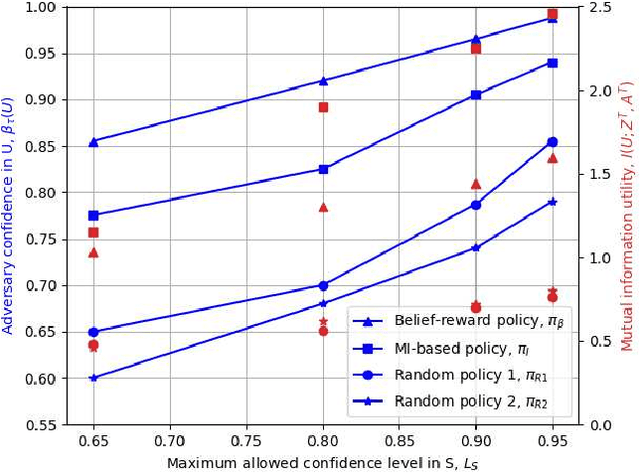
We consider a user releasing her data containing some personal information in return of a service. We model user's personal information as two correlated random variables, one of them, called the secret variable, is to be kept private, while the other, called the useful variable, is to be disclosed for utility. We consider active sequential data release, where at each time step the user chooses from among a finite set of release mechanisms, each revealing some information about the user's personal information, i.e., the true hypotheses, albeit with different statistics. The user manages data release in an online fashion such that maximum amount of information is revealed about the latent useful variable, while the confidence for the sensitive variable is kept below a predefined level. For the utility, we consider both the probability of correct detection of the useful variable and the mutual information (MI) between the useful variable and released data. We formulate both problems as a Markov decision process (MDP), and numerically solve them by advantage actor-critic (A2C) deep reinforcement learning (RL).
$γ$-Models: Generative Temporal Difference Learning for Infinite-Horizon Prediction
Oct 27, 2020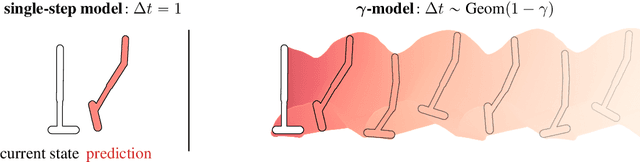

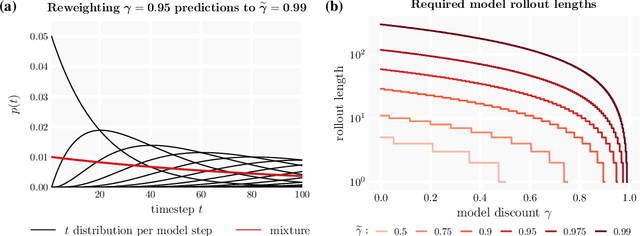

We introduce the $\gamma$-model, a predictive model of environment dynamics with an infinite probabilistic horizon. Replacing standard single-step models with $\gamma$-models leads to generalizations of the procedures that form the foundation of model-based control, including the model rollout and model-based value estimation. The $\gamma$-model, trained with a generative reinterpretation of temporal difference learning, is a natural continuous analogue of the successor representation and a hybrid between model-free and model-based mechanisms. Like a value function, it contains information about the long-term future; like a standard predictive model, it is independent of task reward. We instantiate the $\gamma$-model as both a generative adversarial network and normalizing flow, discuss how its training reflects an inescapable tradeoff between training-time and testing-time compounding errors, and empirically investigate its utility for prediction and control.
Deep learning and high harmonic generation
Dec 18, 2020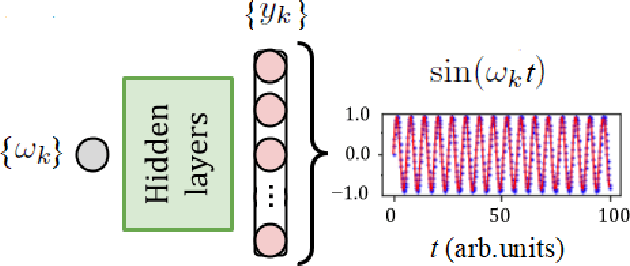
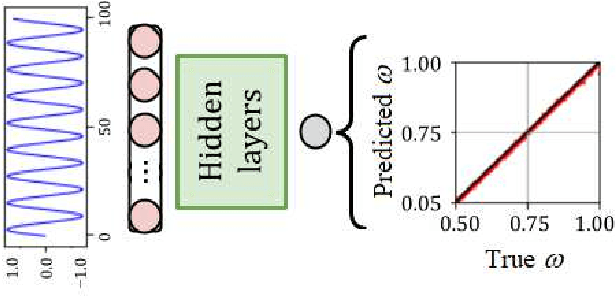
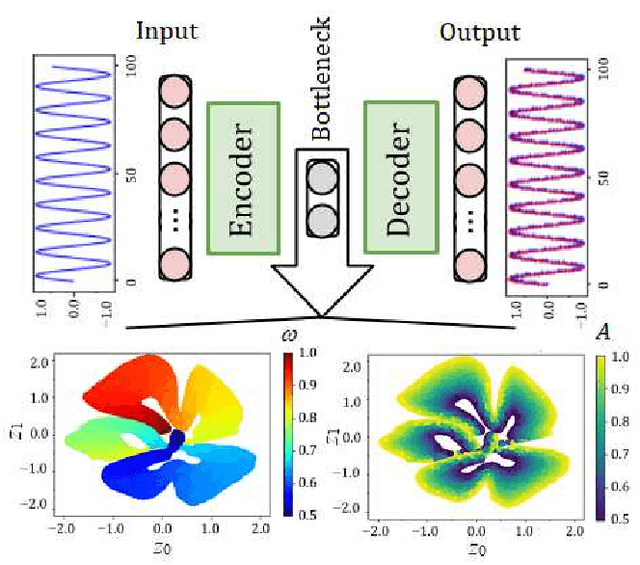
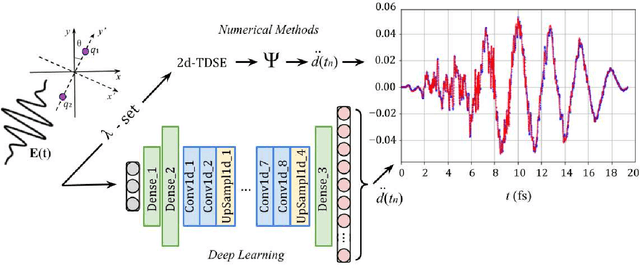
For the high harmonic generation problem, we trained deep convolutional neural networks to predict time-dependent dipole moments and spectra based on sets of randomly generated parameters (laser pulse intensity, internuclear distance, and molecules orientation). We also taught neural networks to solve the inverse problem - to determine parameters based on spectra or dipole moment data. The latter datasets can also be used to classify molecules by type: di- or triatomic, symmetric or asymmetric, wherein we can even rely on fairly simple fully connected neural networks.