 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bayesian Algorithms for Decentralized Stochastic Bandits
Oct 28, 2020
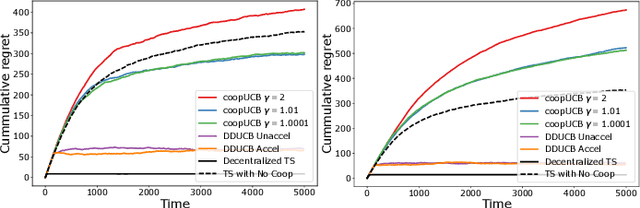
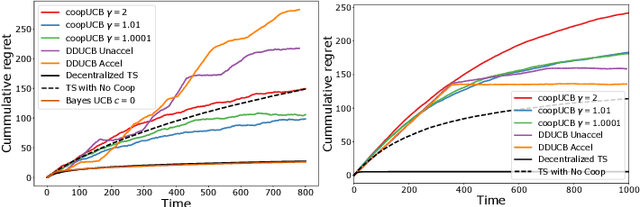
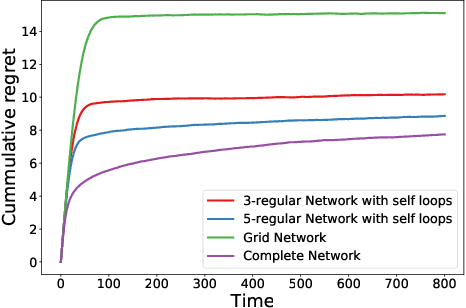
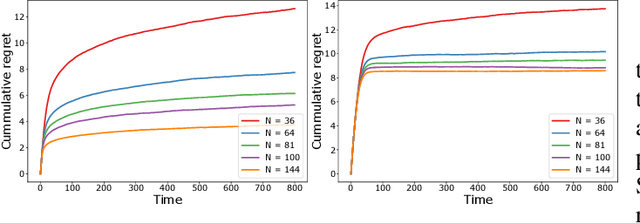
We study a decentralized cooperative multi-agent multi-armed bandit problem with $K$ arms and $N$ agents connected over a network. In our model, each arm's reward distribution is same for all agents, and rewards are drawn independently across agents and over time steps. In each round, agents choose an arm to play and subsequently send a message to their neighbors. The goal is to minimize cumulative regret averaged over the entire network. We propose a decentralized Bayesian multi-armed bandit framework that extends single-agent Bayesian bandit algorithms to the decentralized setting. Specifically, we study an information assimilation algorithm that can be combined with existing Bayesian algorithms, and using this, we propose a decentralized Thompson Sampling algorithm and decentralized Bayes-UCB algorithm. We analyze the decentralized Thompson Sampling algorithm under Bernoulli rewards and establish a problem-dependent upper bound on the cumulative regret. We show that regret incurred scales logarithmically over the time horizon with constants that match those of an optimal centralized agent with access to all observations across the network. Our analysis also characterizes the cumulative regret in terms of the network structure. Through extensive numerical studies, we show that our extensions of Thompson Sampling and Bayes-UCB incur lesser cumulative regret than the state-of-art algorithms inspired by the Upper Confidence Bound algorithm. We implement our proposed decentralized Thompson Sampling under gossip protocol, and over time-varying networks, where each communication link has a fixed probability of failure.
Improved Brain Age Estimation with Slice-based Set Networks
Feb 09, 2021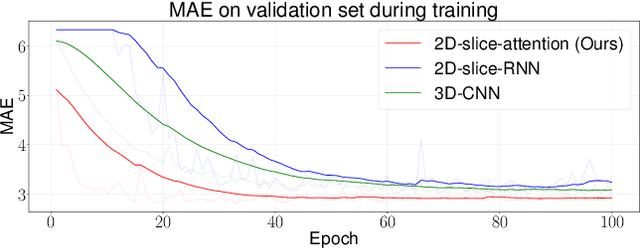

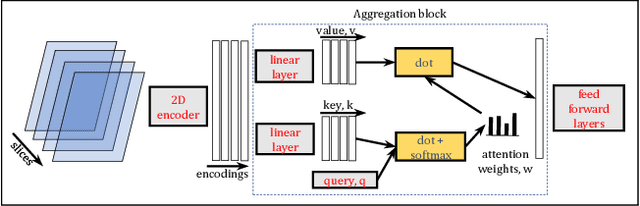
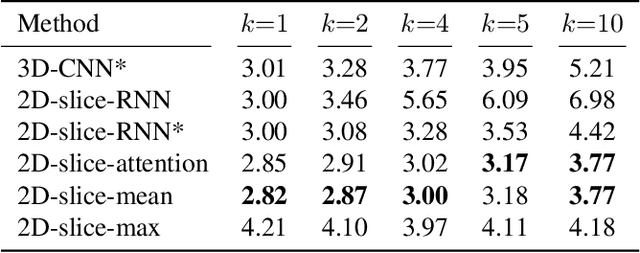
Deep Learning for neuroimaging data is a promising but challenging direction. The high dimensionality of 3D MRI scans makes this endeavor compute and data-intensive. Most conventional 3D neuroimaging methods use 3D-CNN-based architectures with a large number of parameters and require more time and data to train. Recently, 2D-slice-based models have received increasing attention as they have fewer parameters and may require fewer samples to achieve comparable performance. In this paper, we propose a new architecture for BrainAGE prediction. The proposed architecture works by encoding each 2D slice in an MRI with a deep 2D-CNN model. Next, it combines the information from these 2D-slice encodings using set networks or permutation invariant layers. Experiments on the BrainAGE prediction problem, using the UK Biobank dataset, showed that the model with the permutation invariant layers trains faster and provides better predictions compared to other state-of-the-art approaches.
Shape Control of Elastic Objects Based on Implicit Sensorimotor Models and Data-Driven Geometric Features
Jan 06, 2021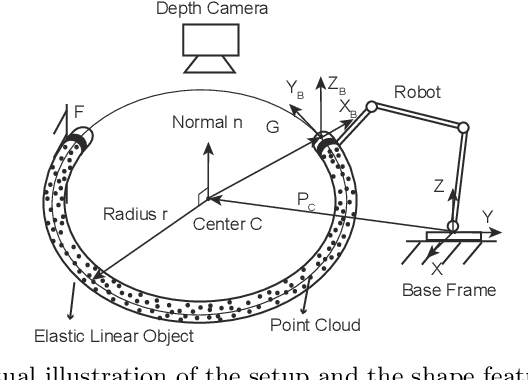
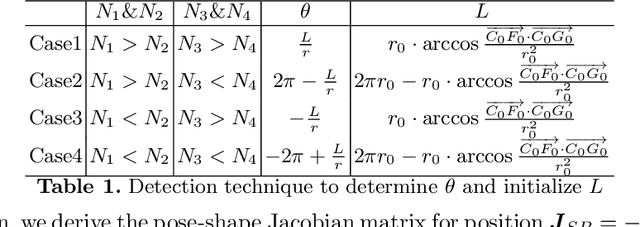
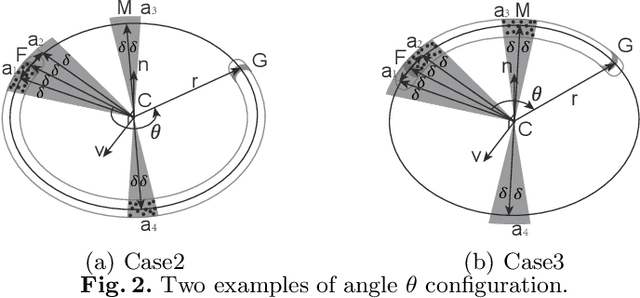
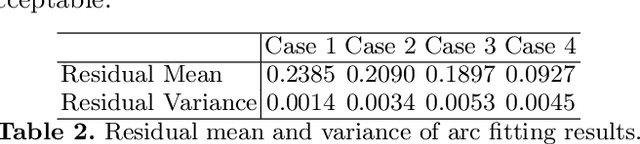
This paper proposes a general approach to design automatic controls to manipulate elastic objects into desired shapes. The object's geometric model is defined as the shape feature based on the specific task to globally describe the deformation. Raw visual feedback data is processed using classic regression methods to identify parameters of data-driven geometric models in real-time. Our proposed method is able to analytically compute a pose-shape Jacobian matrix based on implicit functions. This model is then used to derive a shape servoing controller. To validate the proposed method, we report a detailed experimental study with robotic manipulators deforming an elastic rod.
Survival of the strictest: Stable and unstable equilibria under regularized learning with partial information
Feb 04, 2021
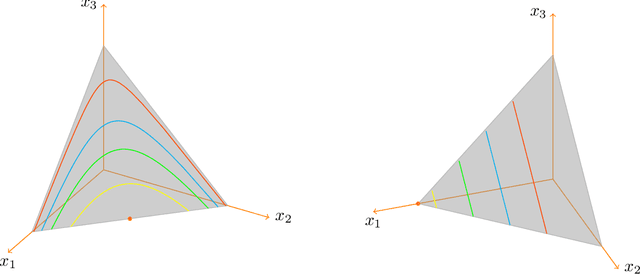
In this paper, we examine the Nash equilibrium convergence properties of no-regret learning in general N-player games. For concreteness, we focus on the archetypal follow the regularized leader (FTRL) family of algorithms, and we consider the full spectrum of uncertainty that the players may encounter - from noisy, oracle-based feedback, to bandit, payoff-based information. In this general context, we establish a comprehensive equivalence between the stability of a Nash equilibrium and its support: a Nash equilibrium is stable and attracting with arbitrarily high probability if and only if it is strict (i.e., each equilibrium strategy has a unique best response). This equivalence extends existing continuous-time versions of the folk theorem of evolutionary game theory to a bona fide algorithmic learning setting, and it provides a clear refinement criterion for the prediction of the day-to-day behavior of no-regret learning in games
IRON: Invariant-based Highly Robust Point Cloud Registration
Mar 07, 2021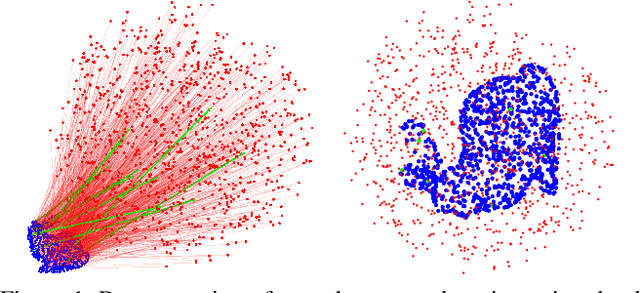
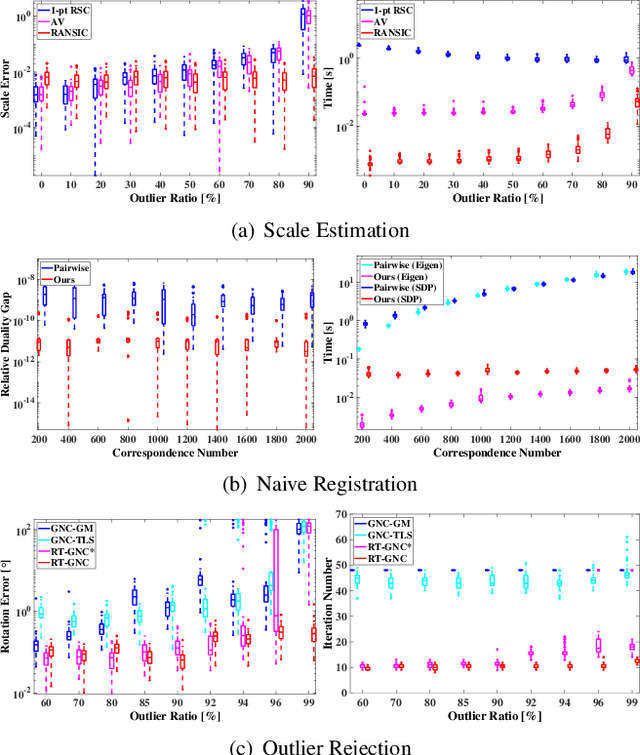
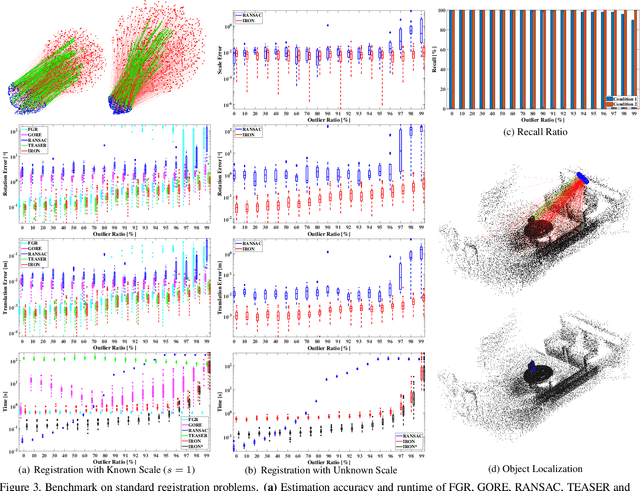
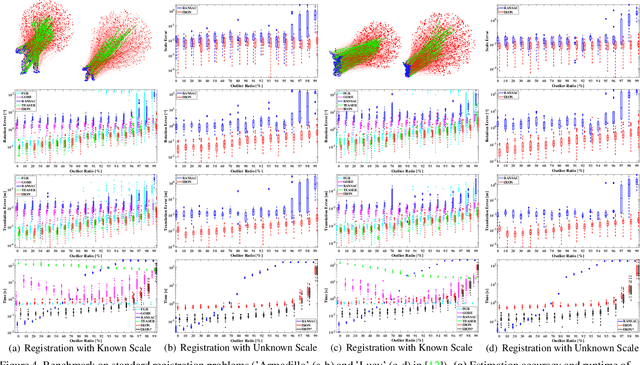
In this paper, we present IRON (Invariant-based global Robust estimation and OptimizatioN), a non-minimal and highly robust solution for point cloud registration with a great number of outliers among the correspondences. To realize this, we decouple the registration problem into the estimation of scale, rotation and translation, respectively. Our first contribution is to propose RANSIC (RANdom Samples with Invariant Compatibility), which employs the invariant compatibility to seek inliers among random samples and robustly estimates the scale between two sets of point clouds in the meantime. Once the scale is estimated, our second contribution is to relax the non-convex global registration problem into a convex Semi-Definite Program (SDP) in a certifiable way using Sum-of-Squares (SOS) Relaxation and show that the relaxation is tight. For robust estimation, we further propose RT-GNC (Rough Trimming and Graduated Non-Convexity), a global outlier rejection heuristic having better robustness and time-efficiency than traditional GNC, as our third contribution. With these contributions, we can render our registration algorithm, IRON. Through experiments over real datasets, we show that IRON is efficient, highly accurate and robust against as many as 99% outliers whether the scale is known or unknown, outperforming the existing state-of-the-art algorithms.
Contemplating real-world object classification
Mar 27, 2021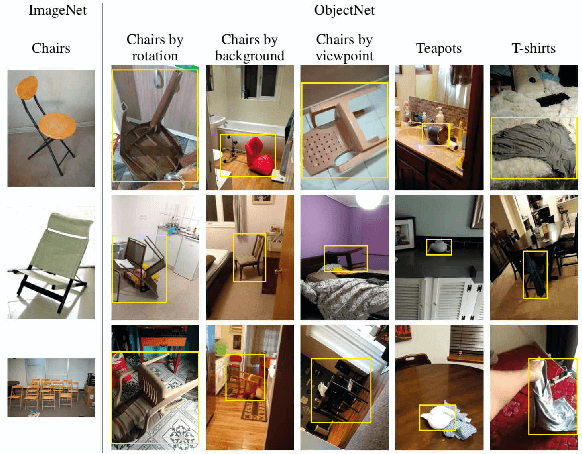

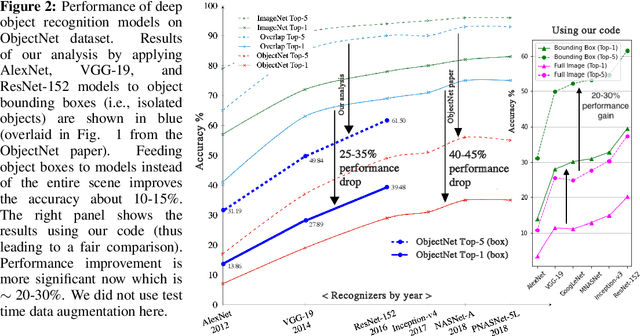
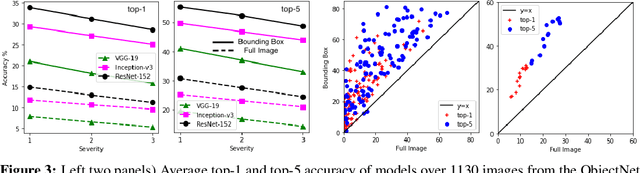
Deep object recognition models have been very successful over benchmark datasets such as ImageNet. How accurate and robust are they to distribution shifts arising from natural and synthetic variations in datasets? Prior research on this problem has primarily focused on ImageNet variations (e.g., ImageNetV2, ImageNet-A). To avoid potential inherited biases in these studies, we take a different approach. Specifically, we reanalyze the ObjectNet dataset recently proposed by Barbu et al. containing objects in daily life situations. They showed a dramatic performance drop of the state of the art object recognition models on this dataset. Due to the importance and implications of their results regarding the generalization ability of deep models, we take a second look at their analysis. We find that applying deep models to the isolated objects, rather than the entire scene as is done in the original paper, results in around 20-30% performance improvement. Relative to the numbers reported in Barbu et al., around 10-15% of the performance loss is recovered, without any test time data augmentation. Despite this gain, however, we conclude that deep models still suffer drastically on the ObjectNet dataset. We also investigate the robustness of models against synthetic image perturbations such as geometric transformations (e.g., scale, rotation, translation), natural image distortions (e.g., impulse noise, blur) as well as adversarial attacks (e.g., FGSM and PGD-5). Our results indicate that limiting the object area as much as possible (i.e., from the entire image to the bounding box to the segmentation mask) leads to consistent improvement in accuracy and robustness.
Expert decision support system for aeroacoustic classification
Feb 27, 2021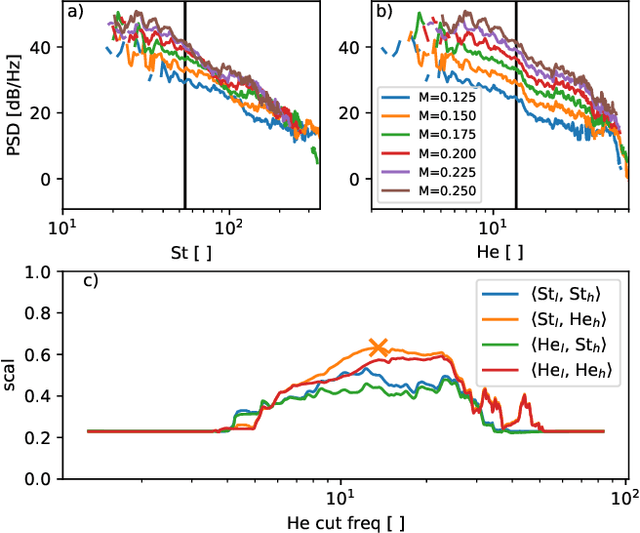
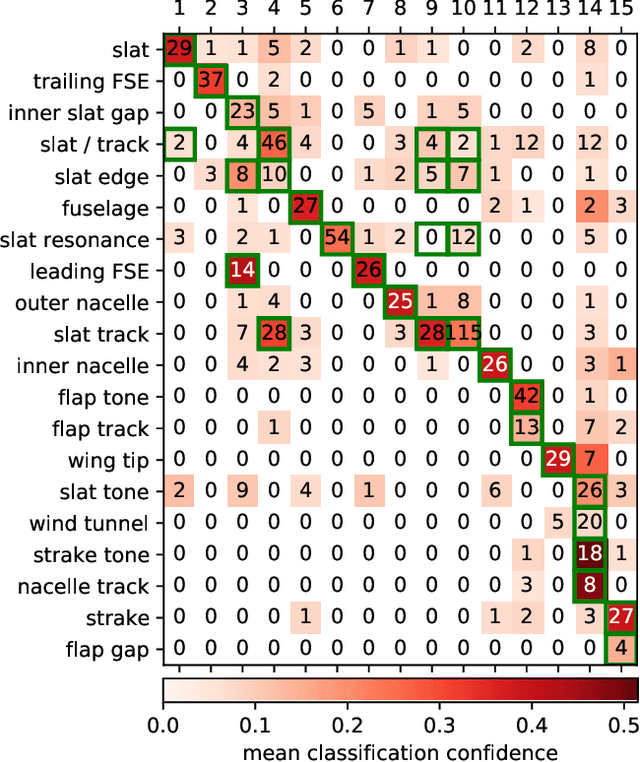
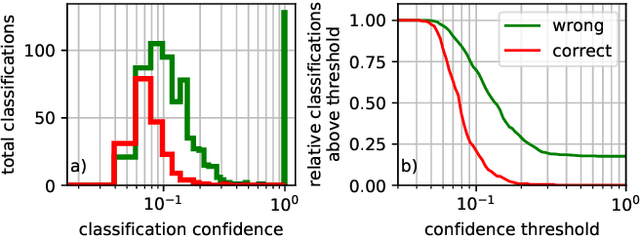
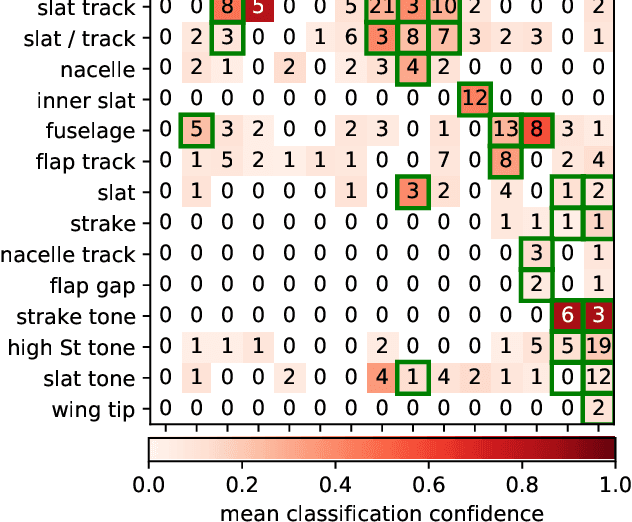
This paper presents an expert decision support system for time-invariant aeroacoustic source classification. The system comprises two steps: first, the calculation of acoustic properties based on spectral and spatial information; and second, the clustering of the sources based on these properties. Example data of two scaled airframe half-model wind tunnel measurements is evaluated based on deconvolved beamforming maps. A variety of aeroacoustic features are proposed that capture the characteristics and properties of the spectra. These features represent aeroacoustic properties that can be interpreted by both the machine and experts. The features are independent of absolute flow parameters such as the observed Mach numbers. This enables the proposed method to analyze data which is measured at different flow configurations. The aeroacoustic sources are clustered based on these features to determine similar or atypical behavior. For the given example data, the method results in source type clusters that correspond to human expert classification of the source types. Combined with a classification confidence and the mean feature values for each cluster, these clusters help aeroacoustic experts in classifying the identified sources and support them in analyzing their typical behavior and identifying spurious sources in-situ during measurement campaigns.
Baseline Pruning-Based Approach to Trojan Detection in Neural Networks
Feb 09, 2021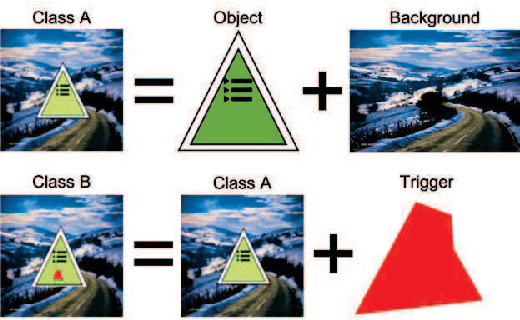
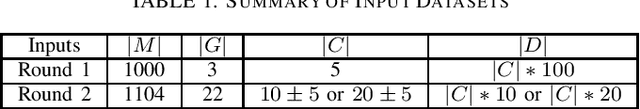
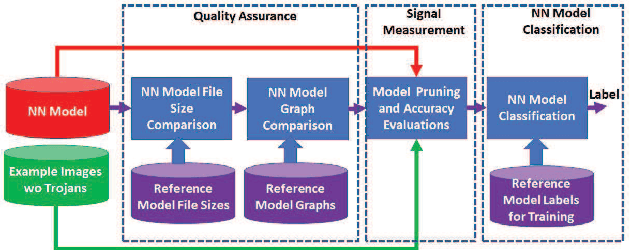

This paper addresses the problem of detecting trojans in neural networks (NNs) by analyzing systematically pruned NN models. Our pruning-based approach consists of three main steps. First, detect any deviations from the reference look-up tables of model file sizes and model graphs. Next, measure the accuracy of a set of systematically pruned NN models following multiple pruning schemas. Finally, classify a NN model as clean or poisoned by applying a mapping between accuracy measurements and NN model labels. This work outlines a theoretical and experimental framework for finding the optimal mapping over a large search space of pruning parameters. Based on our experiments using Round 1 and Round 2 TrojAI Challenge datasets, the approach achieves average classification accuracy of 69.73 % and 82.41% respectively with an average processing time of less than 60 s per model. For both datasets random guessing would produce 50% classification accuracy. Reference model graphs and source code are available from GitHub.
Machine Learning for Initial Value Problems of Parameter-Dependent Dynamical Systems
Jan 12, 2021

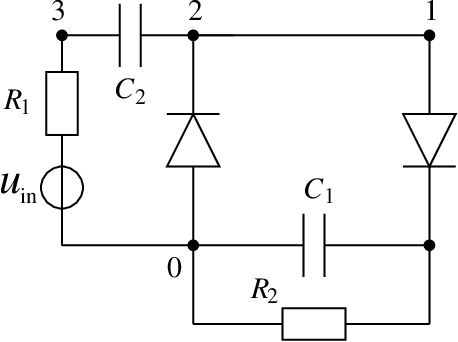
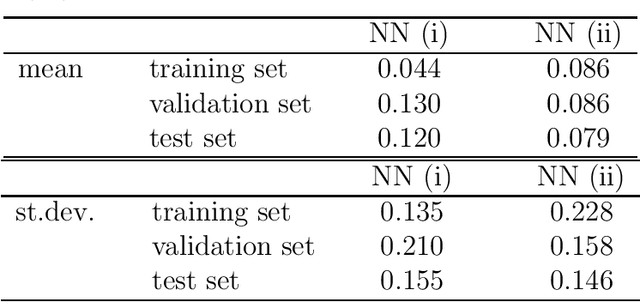
We consider initial value problems of nonlinear dynamical systems, which include physical parameters. A quantity of interest depending on the solution is observed. A discretisation yields the trajectories of the quantity of interest in many time points. We examine the mapping from the set of parameters to the discrete values of the trajectories. An evaluation of this mapping requires to solve an initial value problem. Alternatively, we determine an approximation, where the evaluation requires low computation work, using a concept of machine learning. We employ feedforward neural networks, which are fitted to data from samples of the trajectories. Results of numerical computations are presented for a test example modelling an electric circuit.
Iterative Greedy Matching for 3D Human Pose Tracking from Multiple Views
Jan 24, 2021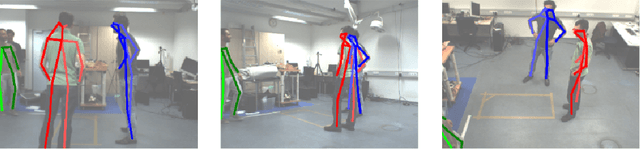
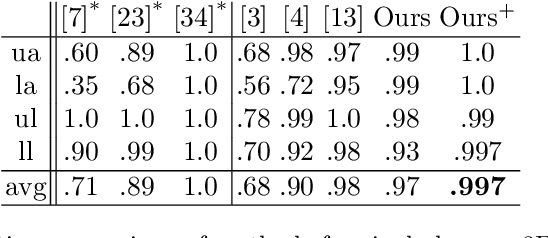

In this work we propose an approach for estimating 3D human poses of multiple people from a set of calibrated cameras. Estimating 3D human poses from multiple views has several compelling properties: human poses are estimated within a global coordinate space and multiple cameras provide an extended field of view which helps in resolving ambiguities, occlusions and motion blur. Our approach builds upon a real-time 2D multi-person pose estimation system and greedily solves the association problem between multiple views. We utilize bipartite matching to track multiple people over multiple frames. This proofs to be especially efficient as problems associated with greedy matching such as occlusion can be easily resolved in 3D. Our approach achieves state-of-the-art results on popular benchmarks and may serve as a baseline for future work.
* German Conference on Pattern Recognition 2019