 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Improving J-divergence of brain connectivity states by graph Laplacian denoising
Dec 22, 2020
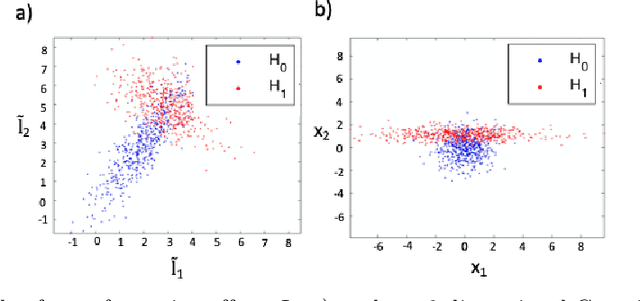
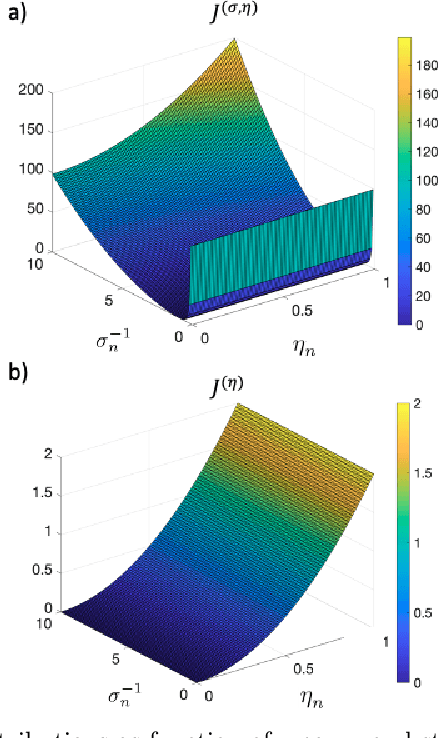
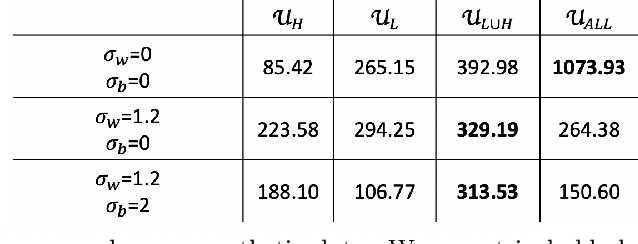
Functional connectivity (FC) can be represented as a network, and is frequently used to better understand the neural underpinnings of complex tasks such as motor imagery (MI) detection in brain-computer interfaces (BCIs). However, errors in the estimation of connectivity can affect the detection performances. In this work, we address the problem of denoising common connectivity estimates to improve the detectability of different connectivity states. Specifically, we propose a denoising algorithm that acts on the network graph Laplacian, which leverages recent graph signal processing results. Further, we derive a novel formulation of the Jensen divergence for the denoised Laplacian under different states. Numerical simulations on synthetic data show that the denoising method improves the Jensen divergence of connectivity patterns corresponding to different task conditions. Furthermore, we apply the Laplacian denoising technique to brain networks estimated from real EEG data recorded during MI-BCI experiments. Using our novel formulation of the J-divergence, we are able to quantify the distance between the FC networks in the motor imagery and resting states, as well as to understand the contribution of each Laplacian variable to the total J-divergence between two states. Experimental results on real MI-BCI EEG data demonstrate that the Laplacian denoising improves the separation of motor imagery and resting mental states, and shortens the time interval required for connectivity estimation. We conclude that the approach shows promise for the robust detection of connectivity states while being appealing for implementation in real-time BCI applications.
Let's be friends! A rapport-building 3D embodied conversational agent for the Human Support Robot
Mar 08, 2021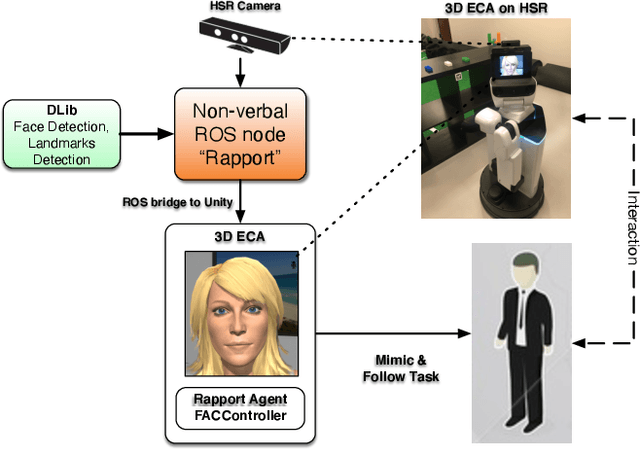
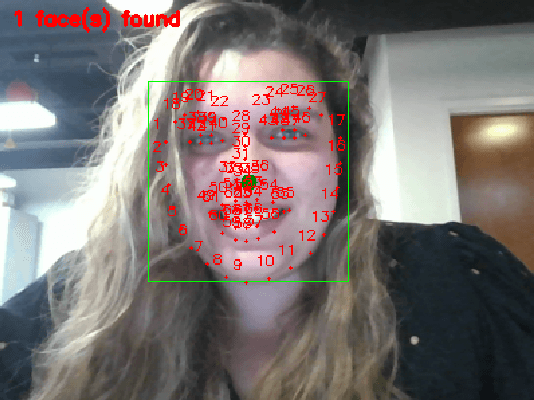


Partial subtle mirroring of nonverbal behaviors during conversations (also known as mimicking or parallel empathy), is essential for rapport building, which in turn is essential for optimal human-human communication outcomes. Mirroring has been studied in interactions between robots and humans, and in interactions between Embodied Conversational Agents (ECAs) and humans. However, very few studies examine interactions between humans and ECAs that are integrated with robots, and none of them examine the effect of mirroring nonverbal behaviors in such interactions. Our research question is whether integrating an ECA able to mirror its interlocutor's facial expressions and head movements (continuously or intermittently) with a human-service robot will improve the user's experience with the support robot that is able to perform useful mobile manipulative tasks (e.g. at home). Our contribution is the complex integration of an expressive ECA, able to track its interlocutor's face, and to mirror his/her facial expressions and head movements in real time, integrated with a human support robot such that the robot and the agent are fully aware of each others', and of the users', nonverbals cues. We also describe a pilot study we conducted towards answering our research question, which shows promising results for our forthcoming larger user study.
Unsupervised Monocular Depth Learning with Integrated Intrinsics and Spatio-Temporal Constraints
Nov 02, 2020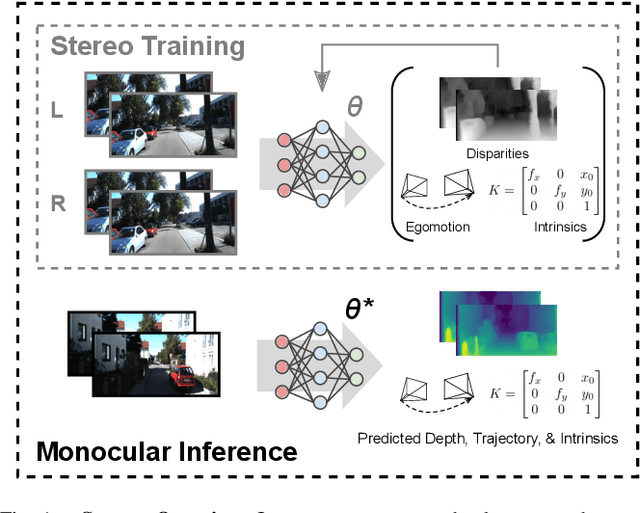
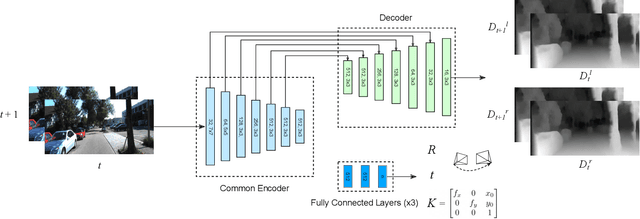
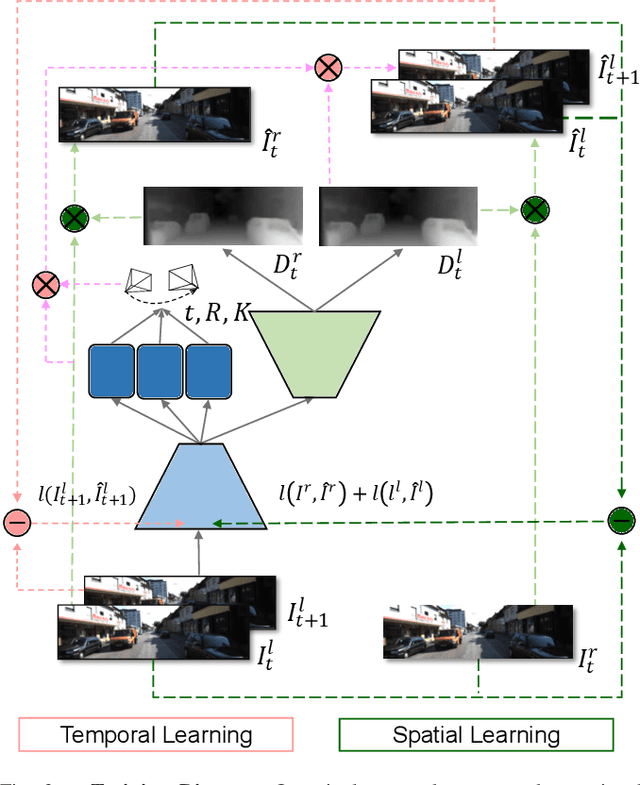

Monocular depth inference has gained tremendous attention from researchers in recent years and remains as a promising replacement for expensive time-of-flight sensors, but issues with scale acquisition and implementation overhead still plague these systems. To this end, this work presents an unsupervised learning framework that is able to predict at-scale depth maps and egomotion, in addition to camera intrinsics, from a sequence of monocular images via a single network. Our method incorporates both spatial and temporal geometric constraints to resolve depth and pose scale factors, which are enforced within the supervisory reconstruction loss functions at training time. Only unlabeled stereo sequences are required for training the weights of our single-network architecture, which reduces overall implementation overhead as compared to previous methods. Our results demonstrate strong performance when compared to the current state-of-the-art on multiple sequences of the KITTI driving dataset.
Adaptive Autonomy in Human-on-the-Loop Vision-Based Robotics Systems
Mar 28, 2021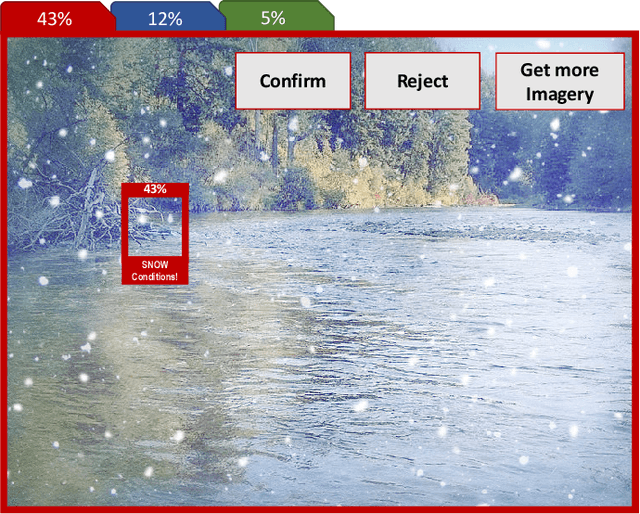
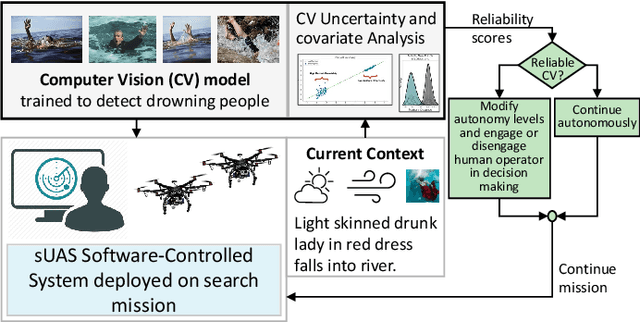
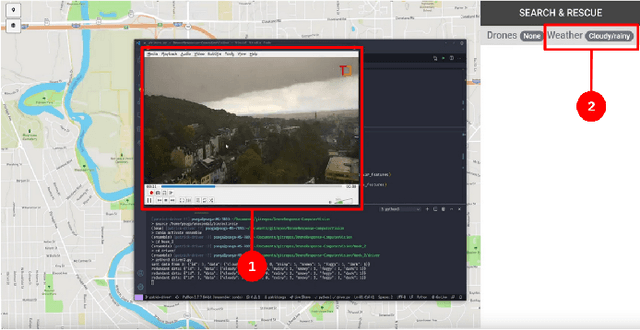

Computer vision approaches are widely used by autonomous robotic systems to sense the world around them and to guide their decision making as they perform diverse tasks such as collision avoidance, search and rescue, and object manipulation. High accuracy is critical, particularly for Human-on-the-loop (HoTL) systems where decisions are made autonomously by the system, and humans play only a supervisory role. Failures of the vision model can lead to erroneous decisions with potentially life or death consequences. In this paper, we propose a solution based upon adaptive autonomy levels, whereby the system detects loss of reliability of these models and responds by temporarily lowering its own autonomy levels and increasing engagement of the human in the decision-making process. Our solution is applicable for vision-based tasks in which humans have time to react and provide guidance. When implemented, our approach would estimate the reliability of the vision task by considering uncertainty in its model, and by performing covariate analysis to determine when the current operating environment is ill-matched to the model's training data. We provide examples from DroneResponse, in which small Unmanned Aerial Systems are deployed for Emergency Response missions, and show how the vision model's reliability would be used in addition to confidence scores to drive and specify the behavior and adaptation of the system's autonomy. This workshop paper outlines our proposed approach and describes open challenges at the intersection of Computer Vision and Software Engineering for the safe and reliable deployment of vision models in the decision making of autonomous systems.
Bayesian Algorithms for Decentralized Stochastic Bandits
Oct 28, 2020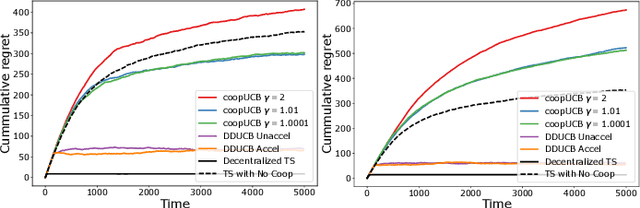
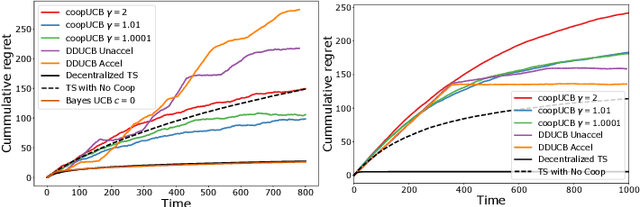
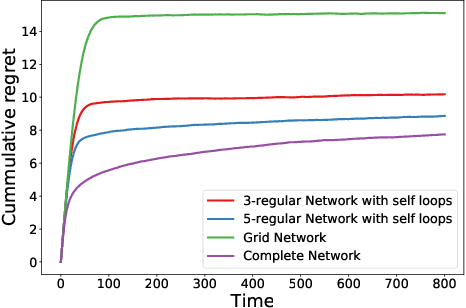
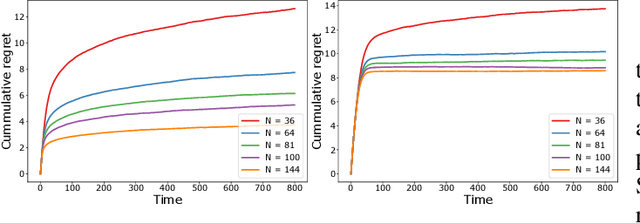
We study a decentralized cooperative multi-agent multi-armed bandit problem with $K$ arms and $N$ agents connected over a network. In our model, each arm's reward distribution is same for all agents, and rewards are drawn independently across agents and over time steps. In each round, agents choose an arm to play and subsequently send a message to their neighbors. The goal is to minimize cumulative regret averaged over the entire network. We propose a decentralized Bayesian multi-armed bandit framework that extends single-agent Bayesian bandit algorithms to the decentralized setting. Specifically, we study an information assimilation algorithm that can be combined with existing Bayesian algorithms, and using this, we propose a decentralized Thompson Sampling algorithm and decentralized Bayes-UCB algorithm. We analyze the decentralized Thompson Sampling algorithm under Bernoulli rewards and establish a problem-dependent upper bound on the cumulative regret. We show that regret incurred scales logarithmically over the time horizon with constants that match those of an optimal centralized agent with access to all observations across the network. Our analysis also characterizes the cumulative regret in terms of the network structure. Through extensive numerical studies, we show that our extensions of Thompson Sampling and Bayes-UCB incur lesser cumulative regret than the state-of-art algorithms inspired by the Upper Confidence Bound algorithm. We implement our proposed decentralized Thompson Sampling under gossip protocol, and over time-varying networks, where each communication link has a fixed probability of failure.
A Holistic Motion Planning and Control Solution to Challenge a Professional Racecar Driver
Feb 28, 2021
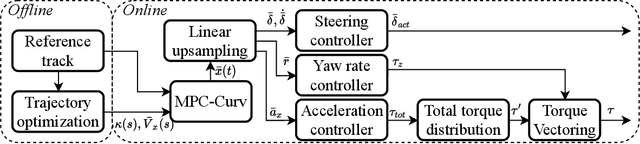
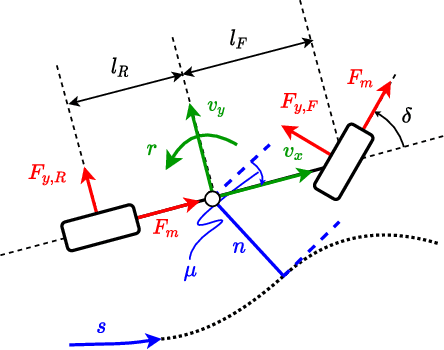
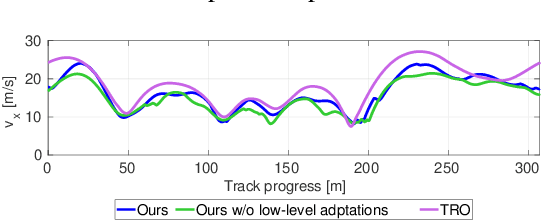
We present a holistically designed three layer control architecture capable of outperforming a professional driver racing the same car. Our approach focuses on the co-design of the motion planning and control layers, extracting the full potential of the connected system. First, a high-level planner computes an optimal trajectory around the track, then in real-time the mid-level nonlinear model predictive controller follows this path using the high-level information as guidance. Finally a high frequency, low-level controller tracks the states predicted by the mid-level controller. Tracking the predicted behavior has two advantages: it reduces the mismatch between the model used in the upper layers and the real car, and allows for a torque vectoring command to be optimized by the higher level motion planners. The tailored design of the low-level controller proved to be crucial for bridging the gap between planning and control, unlocking unseen performance in autonomous racing. The proposed approach was verified on a full size racecar, resulting in a considerable improvement over the state-of-the-art results achieved on the same vehicle. Finally, we also show that the proposed co-design approach outperforms a professional racecar driver.
Uncertainty Quantification and Propagation for Airline Disruption Management
Feb 09, 2021
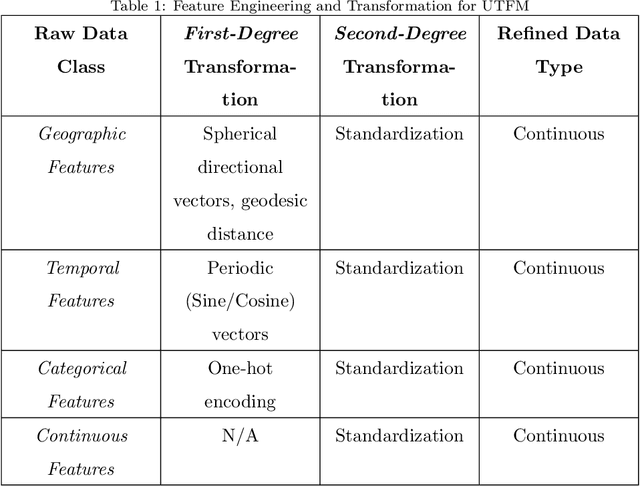
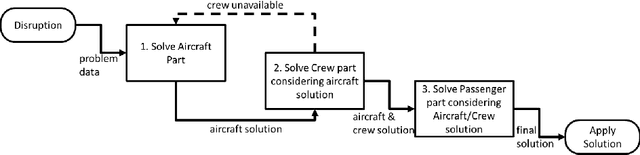
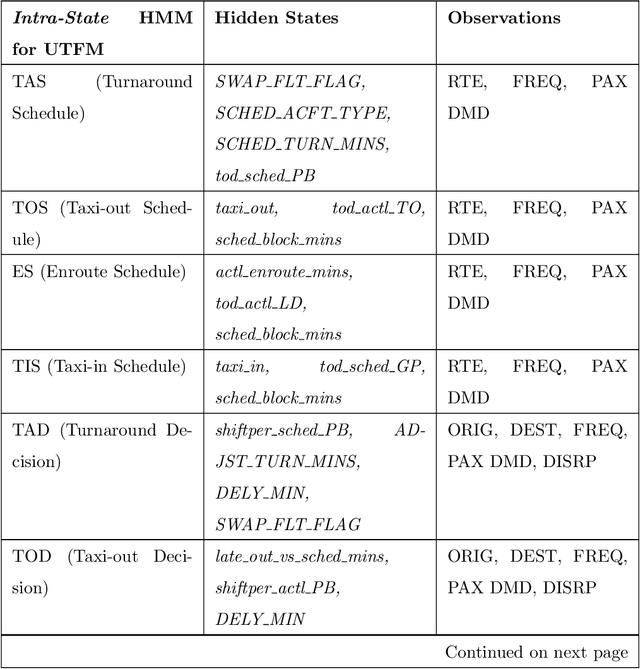
Disruption management during the airline scheduling process can be compartmentalized into proactive and reactive processes depending upon the time of schedule execution. The state of the art for decision-making in airline disruption management involves a heuristic human-centric approach that does not categorically study uncertainty in proactive and reactive processes for managing airline schedule disruptions. Hence, this paper introduces an uncertainty transfer function model (UTFM) framework that characterizes uncertainty for proactive airline disruption management before schedule execution, reactive airline disruption management during schedule execution, and proactive airline disruption management after schedule execution to enable the construction of quantitative tools that can allow an intelligent agent to rationalize complex interactions and procedures for robust airline disruption management. Specifically, we use historical scheduling and operations data from a major U.S. airline to facilitate the development and assessment of the UTFM, defined by hidden Markov models (a special class of probabilistic graphical models) that can efficiently perform pattern learning and inference on portions of large data sets.
Quantum-Inspired Classical Algorithm for Principal Component Regression
Oct 16, 2020
This paper presents a sublinear classical algorithm for principal component regression. The algorithm uses quantum-inspired linear algebra, an idea developed by Tang. Using this technique, her algorithm for recommendation systems achieved runtime only polynomially slower than its quantum counterpart. Her work was quickly adapted to solve many other problems in sublinear time complexity. In this work, we developed an algorithm for principal component regression that runs in time polylogarithmic to the number of data points, an exponential speed up over the state-of-the-art algorithm, under the mild assumption that the input is given in some data structure that supports a norm-based sampling procedure. This exponential speed up allows for potential applications in much larger data sets.
Optical Flow Dataset Synthesis from Unpaired Images
Apr 02, 2021
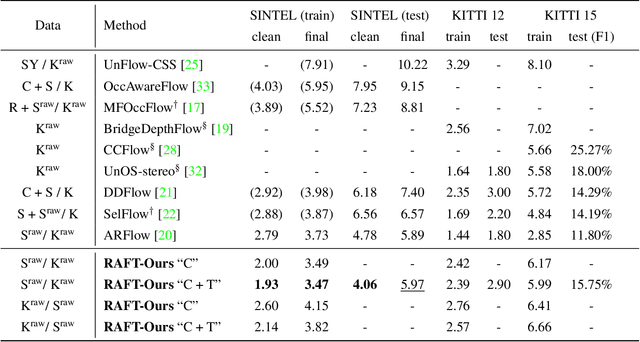

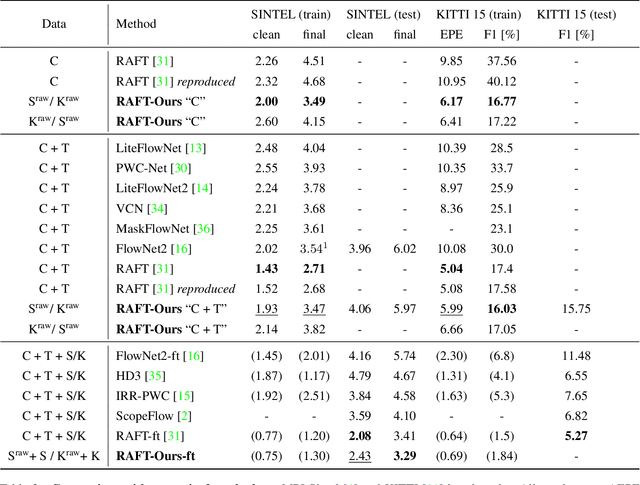
The estimation of optical flow is an ambiguous task due to the lack of correspondence at occlusions, shadows, reflections, lack of texture and changes in illumination over time. Thus, unsupervised methods face major challenges as they need to tune complex cost functions with several terms designed to handle each of these sources of ambiguity. In contrast, supervised methods avoid these challenges altogether by relying on explicit ground truth optical flow obtained directly from synthetic or real data. In the case of synthetic data, the ground truth provides an exact and explicit description of what optical flow to assign to a given scene. However, the domain gap between synthetic data and real data often limits the ability of a trained network to generalize. In the case of real data, the ground truth is obtained through multiple sensors and additional data processing, which might introduce persistent errors and contaminate it. As a solution to these issues, we introduce a novel method to build a training set of pseudo-real images that can be used to train optical flow in a supervised manner. Our dataset uses two unpaired frames from real data and creates pairs of frames by simulating random warps, occlusions with super-pixels, shadows and illumination changes, and associates them to their corresponding exact optical flow. We thus obtain the benefit of directly training on real data while having access to an exact ground truth. Training with our datasets on the Sintel and KITTI benchmarks is straightforward and yields models on par or with state of the art performance compared to much more sophisticated training approaches.
Shape Control of Elastic Objects Based on Implicit Sensorimotor Models and Data-Driven Geometric Features
Jan 06, 2021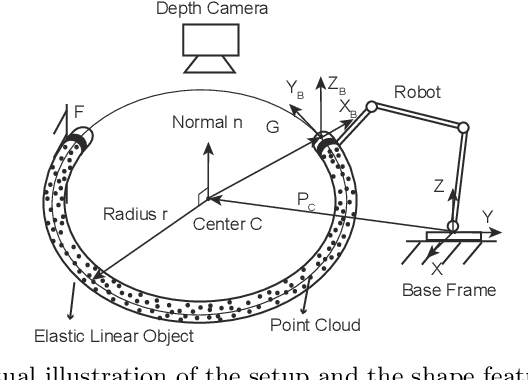
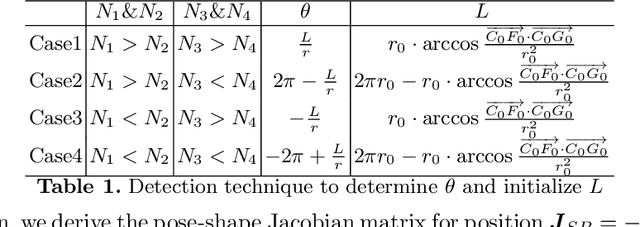
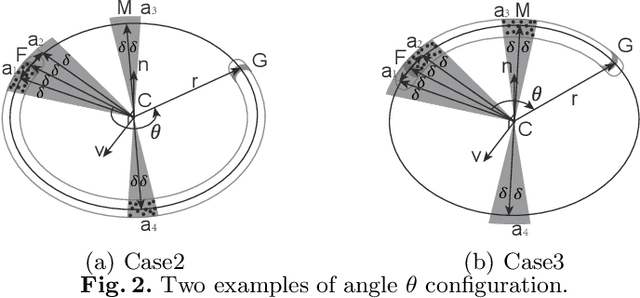
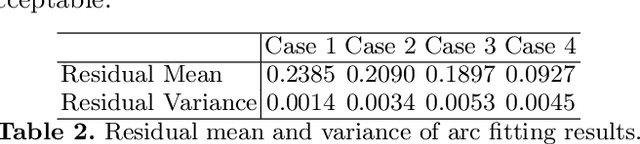
This paper proposes a general approach to design automatic controls to manipulate elastic objects into desired shapes. The object's geometric model is defined as the shape feature based on the specific task to globally describe the deformation. Raw visual feedback data is processed using classic regression methods to identify parameters of data-driven geometric models in real-time. Our proposed method is able to analytically compute a pose-shape Jacobian matrix based on implicit functions. This model is then used to derive a shape servoing controller. To validate the proposed method, we report a detailed experimental study with robotic manipulators deforming an elastic rod.