 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A framework to compare music generative models using automatic evaluation metrics extended to rhythm
Jan 19, 2021
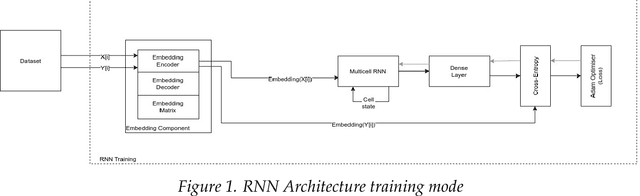
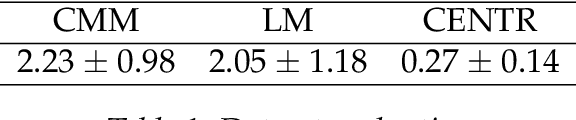
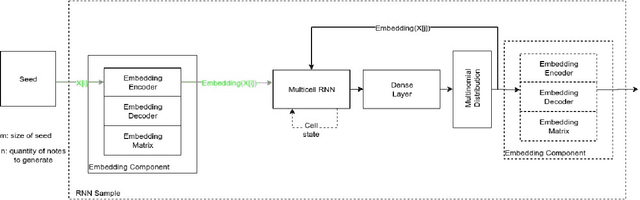

To train a machine learning model is necessary to take numerous decisions about many options for each process involved, in the field of sequence generation and more specifically of music composition, the nature of the problem helps to narrow the options but at the same time, some other options appear for specific challenges. This paper takes the framework proposed in a previous research that did not consider rhythm to make a series of design decisions, then, rhythm support is added to evaluate the performance of two RNN memory cells in the creation of monophonic music. The model considers the handling of music transposition and the framework evaluates the quality of the generated pieces using automatic quantitative metrics based on geometry which have rhythm support added as well.
ALVIO: Adaptive Line and Point Feature-based Visual Inertial Odometry for Robust Localization in Indoor Environments
Dec 30, 2020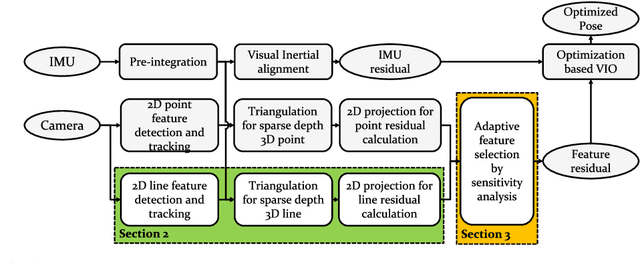
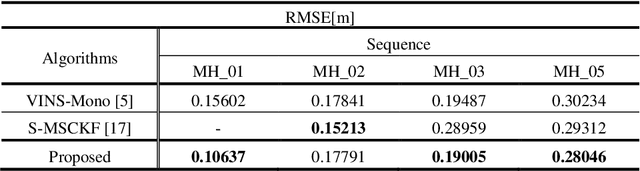
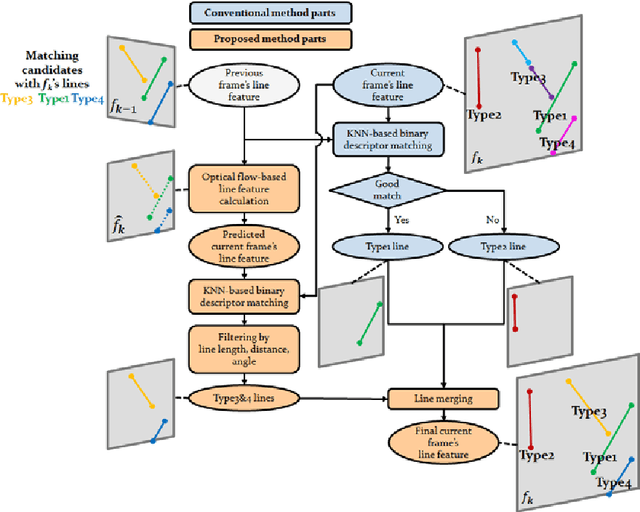
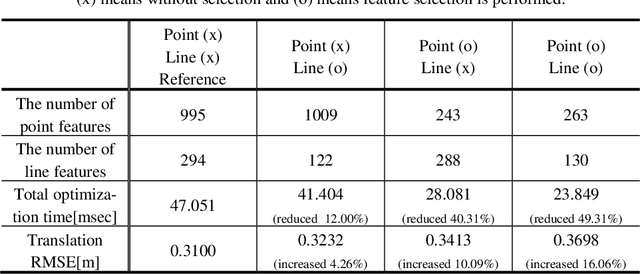
The amount of texture can be rich or deficient depending on the objects and the structures of the building. The conventional mono visual-initial navigation system (VINS)-based localization techniques perform well in environments where stable features are guaranteed. However, their performance is not assured in a changing indoor environment. As a solution to this, we propose Adaptive Line and point feature-based Visual Inertial Odometry (ALVIO) in this paper. ALVIO actively exploits the geometrical information of lines that exist in abundance in an indoor space. By using a strong line tracker and adaptive selection of feature-based tightly coupled optimization, it is possible to perform robust localization in a variable texture environment. The structural characteristics of ALVIO are as follows: First, the proposed optical flow-based line tracker performs robust line feature tracking and management. By using epipolar geometry and trigonometry, accurate 3D lines are recovered. These 3D lines are used to calculate the line re-projection error. Finally, with the sensitivity-analysis-based adaptive feature selection in the optimization process, we can estimate the pose robustly in various indoor environments. We validate the performance of our system on public datasets and compare it against other state-of the-art algorithms (S-MSKCF, VINS-Mono). In the proposed algorithm based on point and line feature selection, translation RMSE increased by 16.06% compared to VINS-Mono, while total optimization time decreased by up to 49.31%. Through this, we proved that it is a useful algorithm as a real-time pose estimation algorithm.
Fundamental Limits on the Maximum Deviations in Control Systems: How Short Can Distribution Tails be Made by Feedback?
Jan 06, 2021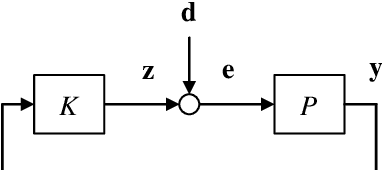
In this paper, we adopt an information-theoretic approach to investigate the fundamental lower bounds on the maximum deviations in feedback control systems, where the plant is linear time-invariant while the controller can generically be any causal functions as long as it stabilizes the plant. It is seen in general that the lower bounds are characterized by the unstable poles (or nonminimum-phase zeros) of the plant as well as the level of randomness (as quantified by the conditional entropy) contained in the disturbance. Such bounds provide fundamental limits on how short the distribution tails in control systems can be made by feedback.
Knowledge driven Description Synthesis for Floor Plan Interpretation
Mar 15, 2021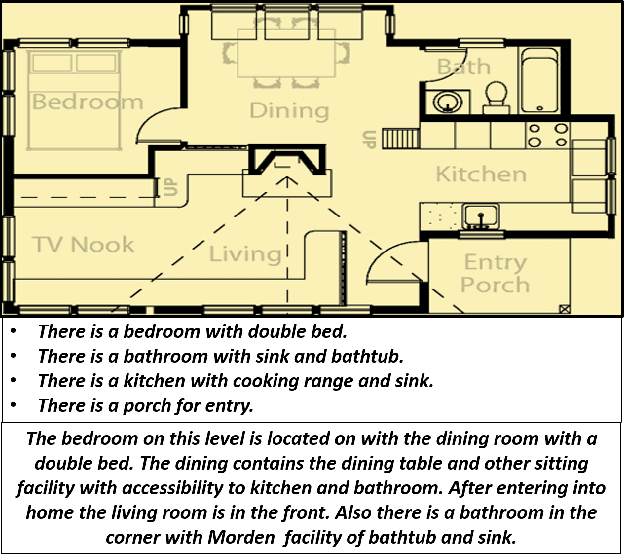
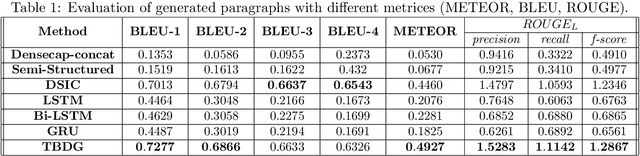
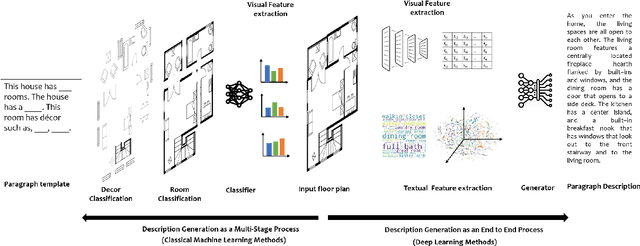
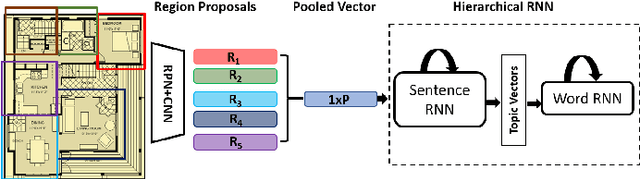
Image captioning is a widely known problem in the area of AI. Caption generation from floor plan images has applications in indoor path planning, real estate, and providing architectural solutions. Several methods have been explored in literature for generating captions or semi-structured descriptions from floor plan images. Since only the caption is insufficient to capture fine-grained details, researchers also proposed descriptive paragraphs from images. However, these descriptions have a rigid structure and lack flexibility, making it difficult to use them in real-time scenarios. This paper offers two models, Description Synthesis from Image Cue (DSIC) and Transformer Based Description Generation (TBDG), for the floor plan image to text generation to fill the gaps in existing methods. These two models take advantage of modern deep neural networks for visual feature extraction and text generation. The difference between both models is in the way they take input from the floor plan image. The DSIC model takes only visual features automatically extracted by a deep neural network, while the TBDG model learns textual captions extracted from input floor plan images with paragraphs. The specific keywords generated in TBDG and understanding them with paragraphs make it more robust in a general floor plan image. Experiments were carried out on a large-scale publicly available dataset and compared with state-of-the-art techniques to show the proposed model's superiority.
Finding the Stochastic Shortest Path with Low Regret: The Adversarial Cost and Unknown Transition Case
Feb 10, 2021
We make significant progress toward the stochastic shortest path problem with adversarial costs and unknown transition. Specifically, we develop algorithms that achieve $\widetilde{O}(\sqrt{S^2ADT_\star K})$ regret for the full-information setting and $\widetilde{O}(\sqrt{S^3A^2DT_\star K})$ regret for the bandit feedback setting, where $D$ is the diameter, $T_\star$ is the expected hitting time of the optimal policy, $S$ is the number of states, $A$ is the number of actions, and $K$ is the number of episodes. Our work strictly improves (Rosenberg and Mansour, 2020) in the full information setting, extends (Chen et al., 2020) from known transition to unknown transition, and is also the first to consider the most challenging combination: bandit feedback with adversarial costs and unknown transition. To remedy the gap between our upper bounds and the current best lower bounds constructed via a stochastically oblivious adversary, we also propose algorithms with near-optimal regret for this special case.
NVIDIA SimNet^{TM}: an AI-accelerated multi-physics simulation framework
Dec 14, 2020

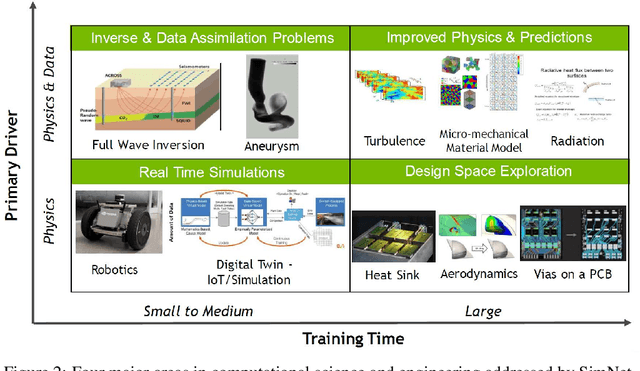

We present SimNet, an AI-driven multi-physics simulation framework, to accelerate simulations across a wide range of disciplines in science and engineering. Compared to traditional numerical solvers, SimNet addresses a wide range of use cases - coupled forward simulations without any training data, inverse and data assimilation problems. SimNet offers fast turnaround time by enabling parameterized system representation that solves for multiple configurations simultaneously, as opposed to the traditional solvers that solve for one configuration at a time. SimNet is integrated with parameterized constructive solid geometry as well as STL modules to generate point clouds. Furthermore, it is customizable with APIs that enable user extensions to geometry, physics and network architecture. It has advanced network architectures that are optimized for high-performance GPU computing, and offers scalable performance for multi-GPU and multi-Node implementation with accelerated linear algebra as well as FP32, FP64 and TF32 computations. In this paper we review the neural network solver methodology, the SimNet architecture, and the various features that are needed for effective solution of the PDEs. We present real-world use cases that range from challenging forward multi-physics simulations with turbulence and complex 3D geometries, to industrial design optimization and inverse problems that are not addressed efficiently by the traditional solvers. Extensive comparisons of SimNet results with open source and commercial solvers show good correlation.
Player Modeling via Multi-Armed Bandits
Feb 10, 2021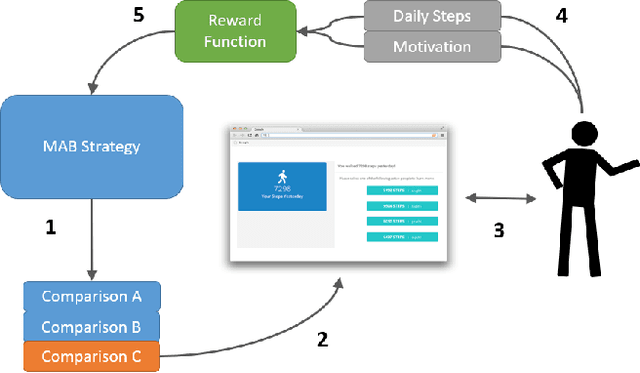
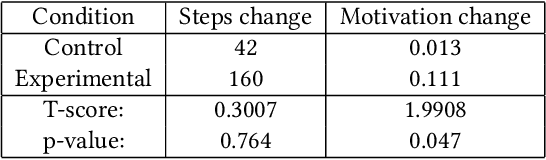
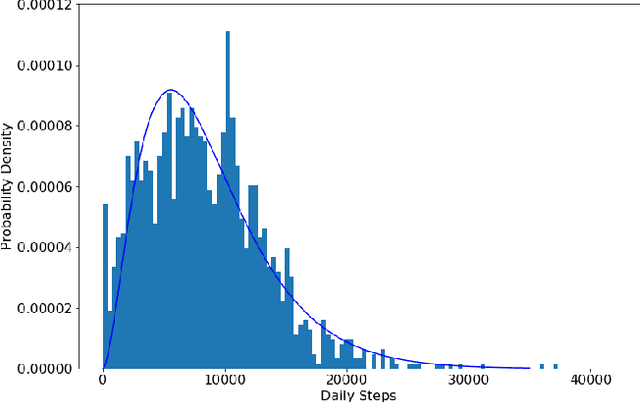
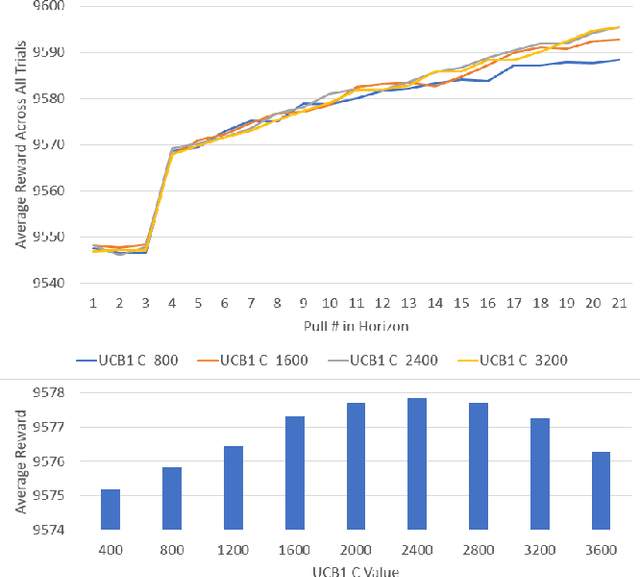
This paper focuses on building personalized player models solely from player behavior in the context of adaptive games. We present two main contributions: The first is a novel approach to player modeling based on multi-armed bandits (MABs). This approach addresses, at the same time and in a principled way, both the problem of collecting data to model the characteristics of interest for the current player and the problem of adapting the interactive experience based on this model. Second, we present an approach to evaluating and fine-tuning these algorithms prior to generating data in a user study. This is an important problem, because conducting user studies is an expensive and labor-intensive process; therefore, an ability to evaluate the algorithms beforehand can save a significant amount of resources. We evaluate our approach in the context of modeling players' social comparison orientation (SCO) and present empirical results from both simulations and real players.
Effective Image Differencing with ConvNets for Real-time Transient Hunting
Oct 04, 2017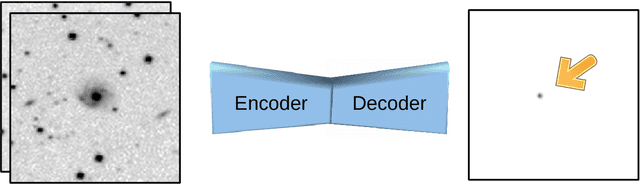

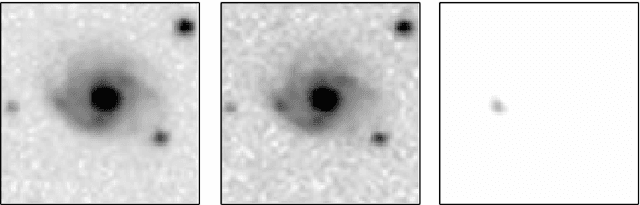
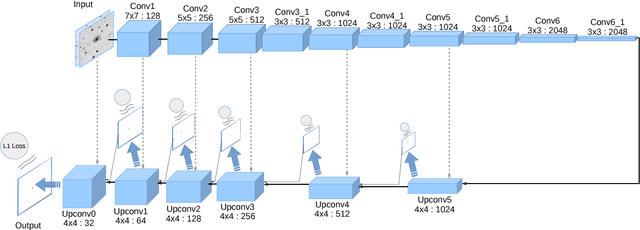
Large sky surveys are increasingly relying on image subtraction pipelines for real-time (and archival) transient detection. In this process one has to contend with varying PSF, small brightness variations in many sources, as well as artifacts resulting from saturated stars, and, in general, matching errors. Very often the differencing is done with a reference image that is deeper than individual images and the attendant difference in noise characteristics can also lead to artifacts. We present here a deep-learning approach to transient detection that encapsulates all the steps of a traditional image subtraction pipeline -- image registration, background subtraction, noise removal, psf matching, and subtraction -- into a single real-time convolutional network. Once trained the method works lighteningly fast, and given that it does multiple steps at one go, the advantages for multi-CCD, fast surveys like ZTF and LSST are obvious.
If you've got it, flaunt it: Making the most of fine-grained sentiment annotations
Jan 30, 2021
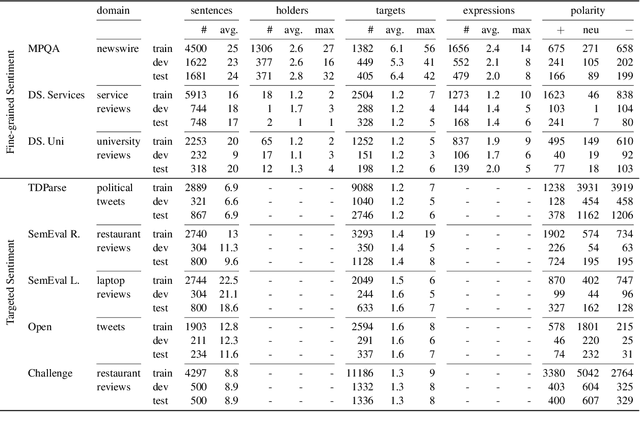
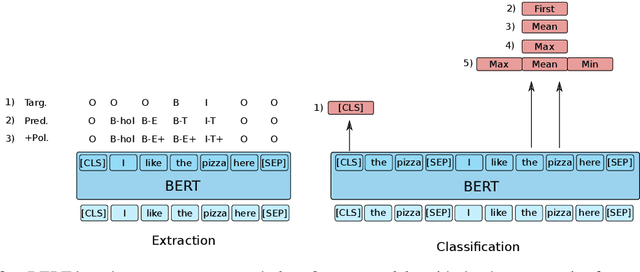

Fine-grained sentiment analysis attempts to extract sentiment holders, targets and polar expressions and resolve the relationship between them, but progress has been hampered by the difficulty of annotation. Targeted sentiment analysis, on the other hand, is a more narrow task, focusing on extracting sentiment targets and classifying their polarity.In this paper, we explore whether incorporating holder and expression information can improve target extraction and classification and perform experiments on eight English datasets. We conclude that jointly predicting target and polarity BIO labels improves target extraction, and that augmenting the input text with gold expressions generally improves targeted polarity classification. This highlights the potential importance of annotating expressions for fine-grained sentiment datasets. At the same time, our results show that performance of current models for predicting polar expressions is poor, hampering the benefit of this information in practice.
Intermittent Demand Forecasting with Renewal Processes
Oct 04, 2020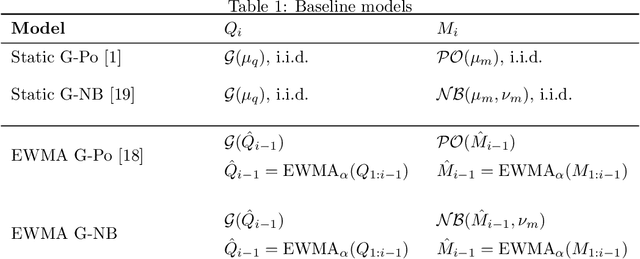
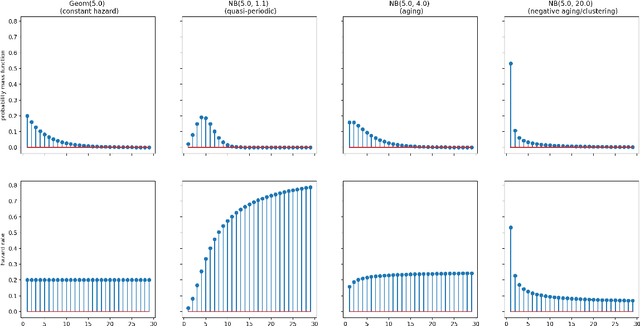

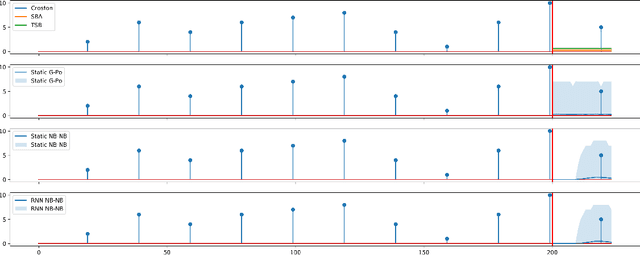
Intermittency is a common and challenging problem in demand forecasting. We introduce a new, unified framework for building intermittent demand forecasting models, which incorporates and allows to generalize existing methods in several directions. Our framework is based on extensions of well-established model-based methods to discrete-time renewal processes, which can parsimoniously account for patterns such as aging, clustering and quasi-periodicity in demand arrivals. The connection to discrete-time renewal processes allows not only for a principled extension of Croston-type models, but also for an natural inclusion of neural network based models---by replacing exponential smoothing with a recurrent neural network. We also demonstrate that modeling continuous-time demand arrivals, i.e., with a temporal point process, is possible via a trivial extension of our framework. This leads to more flexible modeling in scenarios where data of individual purchase orders are directly available with granular timestamps. Complementing this theoretical advancement, we demonstrate the efficacy of our framework for forecasting practice via an extensive empirical study on standard intermittent demand data sets, in which we report predictive accuracy in a variety of scenarios that compares favorably to the state of the art.