 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Timely Tracking of Infection Status of Individuals in a Population
Dec 24, 2020
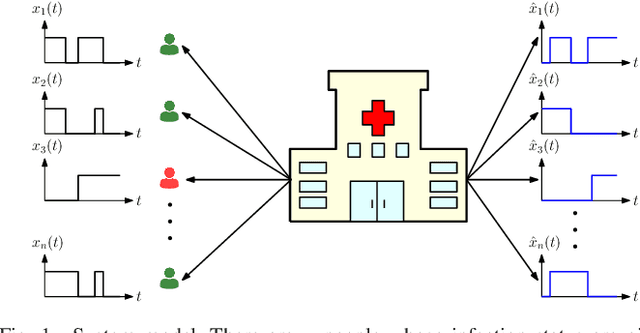
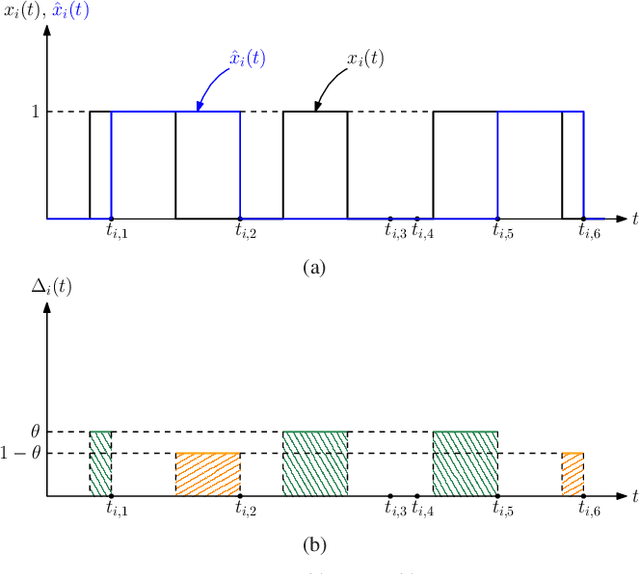
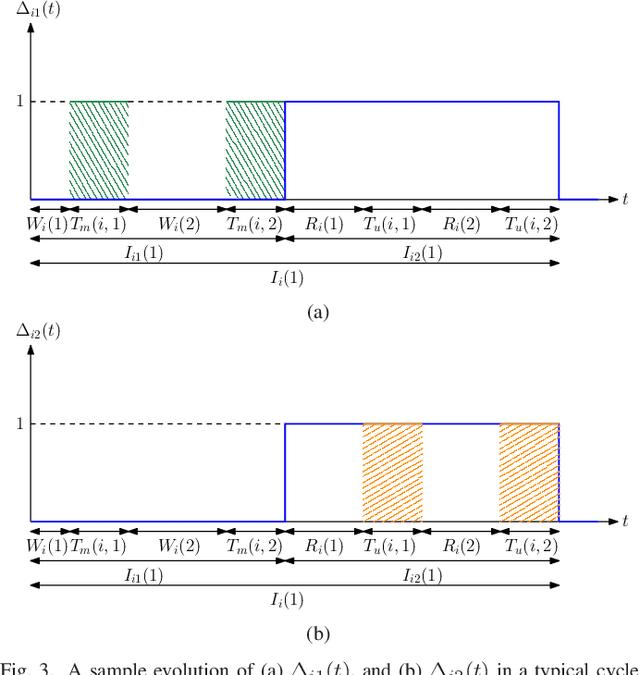
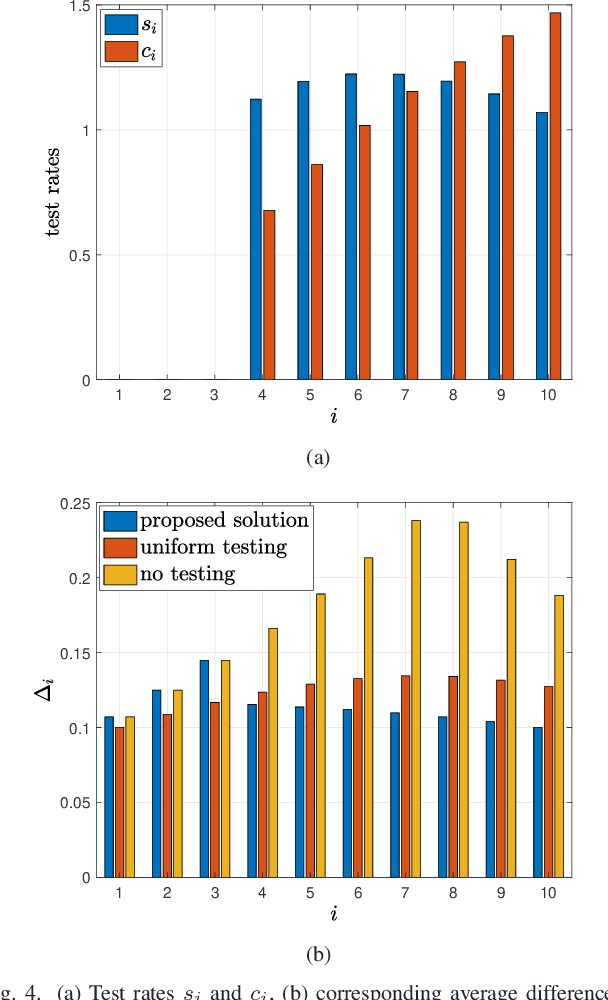
We consider real-time timely tracking of infection status (e.g., covid-19) of individuals in a population. In this work, a health care provider wants to detect infected people as well as people who recovered from the disease as quickly as possible. In order to measure the timeliness of the tracking process, we use the long-term average difference between the actual infection status of the people and their real-time estimate by the health care provider based on the most recent test results. We first find an analytical expression for this average difference for given test rates, and given infection and recovery rates of people. Next, we propose an alternating minimization based algorithm to minimize this average difference. We observe that if the total test rate is limited, instead of testing all members of the population equally, only a portion of the population is tested based on their infection and recovery rates. We also observe that increasing the total test rate helps track the infection status better. In addition, an increased population size increases diversity of people with different infection and recovery rates, which may be exploited to spend testing capacity more efficiently, thereby improving the system performance. Finally, depending on the health care provider's preferences, test rate allocation can be altered to detect either the infected people or the recovered people more quickly.
Machine Learning-based Automatic Graphene Detection with Color Correction for Optical Microscope Images
Mar 24, 2021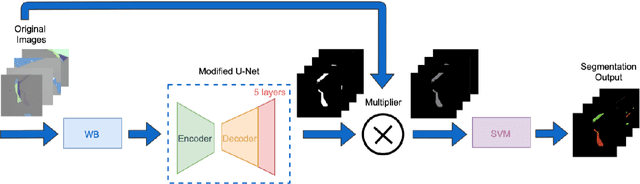
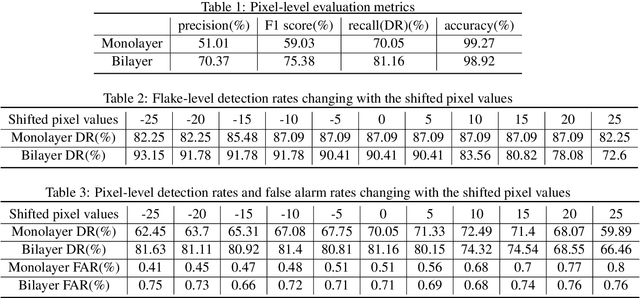


Graphene serves critical application and research purposes in various fields. However, fabricating high-quality and large quantities of graphene is time-consuming and it requires heavy human resource labor costs. In this paper, we propose a Machine Learning-based Automatic Graphene Detection Method with Color Correction (MLA-GDCC), a reliable and autonomous graphene detection from microscopic images. The MLA-GDCC includes a white balance (WB) to correct the color imbalance on the images, a modified U-Net and a support vector machine (SVM) to segment the graphene flakes. Considering the color shifts of the images caused by different cameras, we apply WB correction to correct the imbalance of the color pixels. A modified U-Net model, a convolutional neural network (CNN) architecture for fast and precise image segmentation, is introduced to segment the graphene flakes from the background. In order to improve the pixel-level accuracy, we implement a SVM after the modified U-Net model to separate the monolayer and bilayer graphene flakes. The MLA-GDCC achieves flake-level detection rates of 87.09% for monolayer and 90.41% for bilayer graphene, and the pixel-level accuracy of 99.27% for monolayer and 98.92% for bilayer graphene. MLA-GDCC not only achieves high detection rates of the graphene flakes but also speeds up the latency for the graphene detection process from hours to seconds.
Active Anomaly Detection for time-domain discoveries
Sep 29, 2019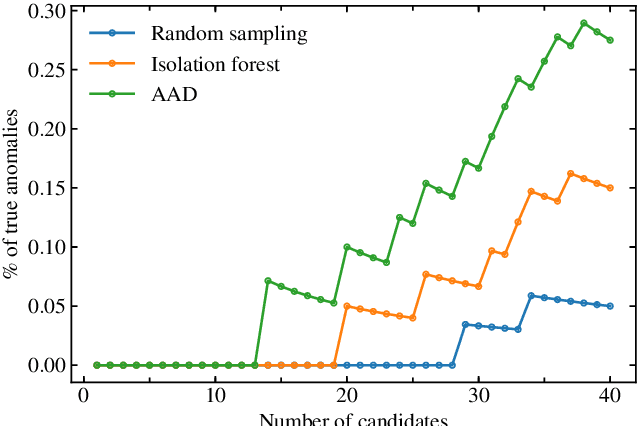
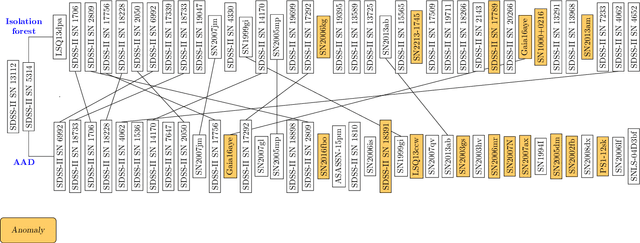
We present the first application of adaptive machine learning to the identification of anomalies in a data set of non-periodic astronomical light curves. The method follows an active learning strategy where highly informative objects are selected to be labelled. This new information is subsequently used to improve the machine learning model, allowing its accuracy to evolve with the addition of every new classification. For the case of anomaly detection, the algorithm aims to maximize the number of real anomalies presented to the expert by slightly modifying the decision boundary of a traditional isolation forest in each iteration. As a proof of concept, we apply the Active Anomaly Discovery (AAD) algorithm to light curves from the Open Supernova Catalog and compare its results to those of a static Isolation Forest (IF). For both methods, we visually inspected objects within 2% highest anomaly scores. We show that AAD was able to identify 80% more true anomalies than IF. This result is the first evidence that AAD algorithms can play a central role in the search for new physics in the era of large scale sky surveys.
Using Spatio-temporal Deep Learning for Forecasting Demand and Supply-demand Gap in Ride-hailing System with Anonymized Spatial Adjacency Information
Dec 16, 2020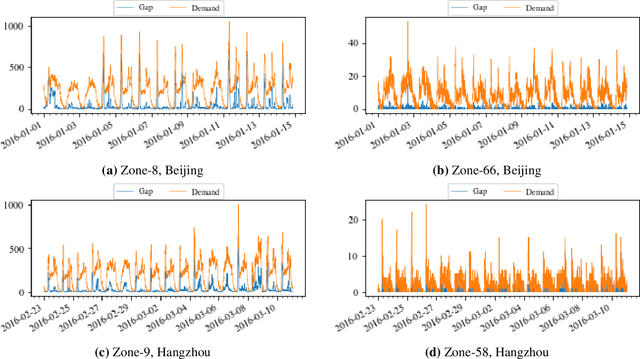

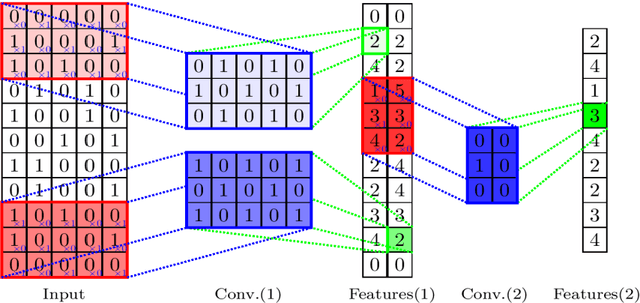
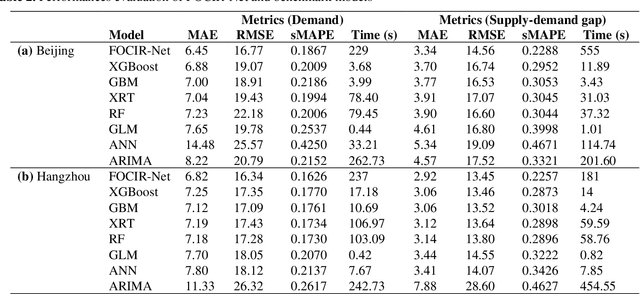
To reduce passenger waiting time and driver search friction, ride-hailing companies need to accurately forecast spatio-temporal demand and supply-demand gap. However, due to spatio-temporal dependencies pertaining to demand and supply-demand gap in a ride-hailing system, making accurate forecasts for both demand and supply-demand gap is a difficult task. Furthermore, due to confidentiality and privacy issues, ride-hailing data are sometimes released to the researchers by removing spatial adjacency information of the zones, which hinders the detection of spatio-temporal dependencies. To that end, a novel spatio-temporal deep learning architecture is proposed in this paper for forecasting demand and supply-demand gap in a ride-hailing system with anonymized spatial adjacency information, which integrates feature importance layer with a spatio-temporal deep learning architecture containing one-dimensional convolutional neural network (CNN) and zone-distributed independently recurrent neural network (IndRNN). The developed architecture is tested with real-world datasets of Didi Chuxing, which shows that our models based on the proposed architecture can outperform conventional time-series models (e.g., ARIMA) and machine learning models (e.g., gradient boosting machine, distributed random forest, generalized linear model, artificial neural network). Additionally, the feature importance layer provides an interpretation of the model by revealing the contribution of the input features utilized in prediction.
BayesBeat: A Bayesian Deep Learning Approach for Atrial Fibrillation Detection from Noisy Photoplethysmography Data
Nov 02, 2020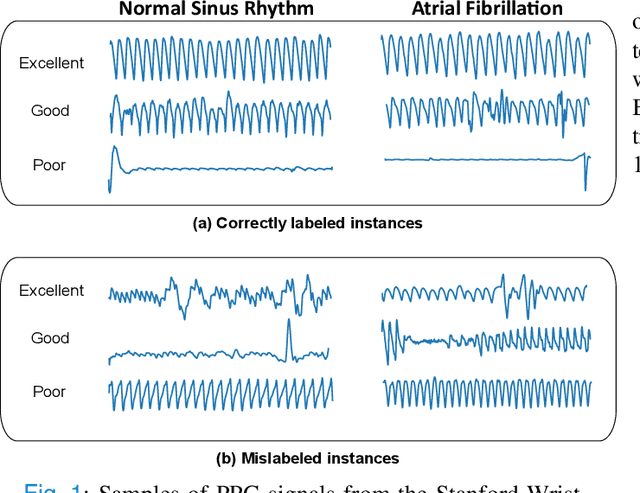
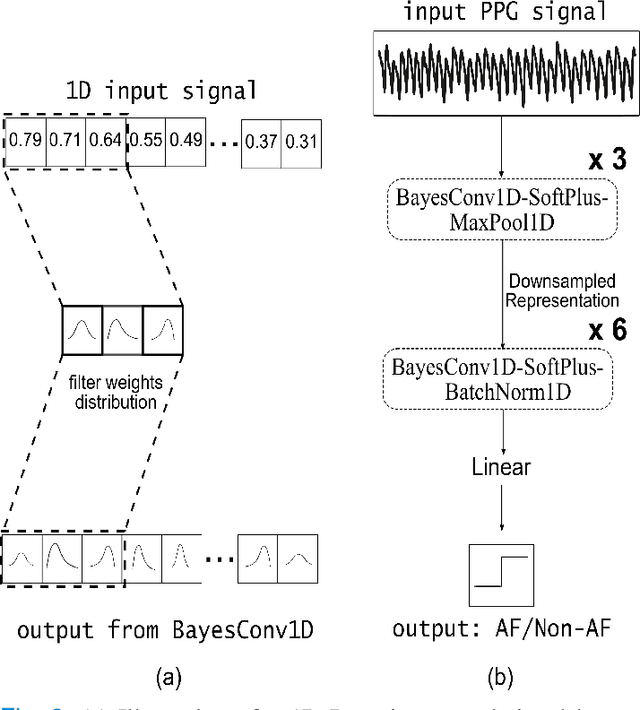

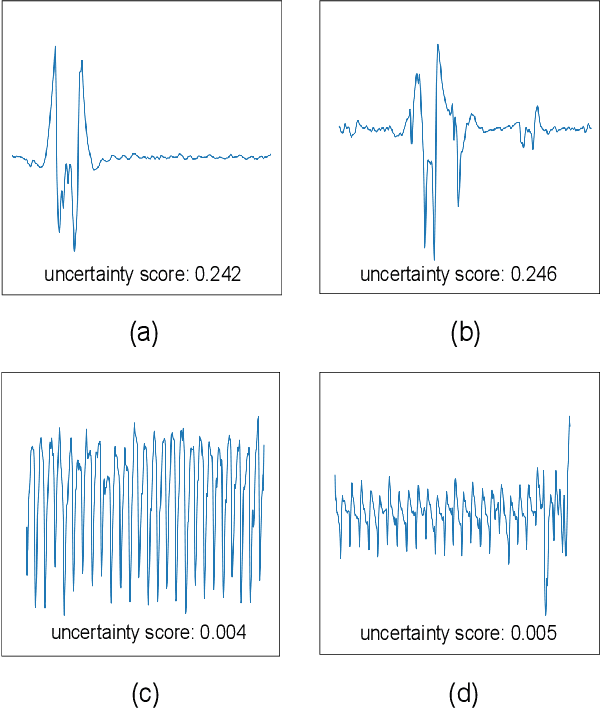
The increasing popularity of smartwatches as affordable and longitudinal monitoring devices enables us to capture photoplethysmography (PPG) sensor data for detecting Atrial Fibrillation (AF) in real-time. A significant challenge in AF detection from PPG signals comes from the inherent noise in the smartwatch PPG signals. In this paper, we propose a novel deep learning based approach, BayesBeat that leverages the power of Bayesian deep learning to accurately infer AF risks from noisy PPG signals, and at the same time provide the uncertainty estimate of the prediction. Bayesbeat is efficient, robust, flexible, and highly scalable which makes it particularly suitable for deployment in commercially available wearable devices. Extensive experiments on a recently published large dataset reveal that our proposed method BayesBeat substantially outperforms the existing state-of-the-art methods.
Autonomous Navigation of an Ultrasound Probe Towards Standard Scan Planes with Deep Reinforcement Learning
Mar 01, 2021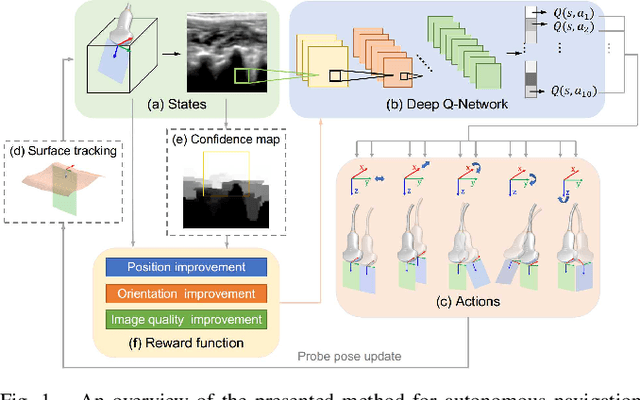

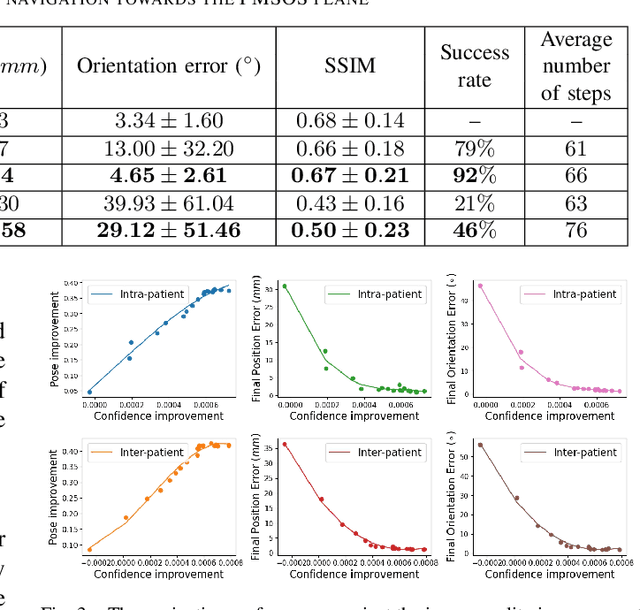

Autonomous ultrasound (US) acquisition is an important yet challenging task, as it involves interpretation of the highly complex and variable images and their spatial relationships. In this work, we propose a deep reinforcement learning framework to autonomously control the 6-D pose of a virtual US probe based on real-time image feedback to navigate towards the standard scan planes under the restrictions in real-world US scans. Furthermore, we propose a confidence-based approach to encode the optimization of image quality in the learning process. We validate our method in a simulation environment built with real-world data collected in the US imaging of the spine. Experimental results demonstrate that our method can perform reproducible US probe navigation towards the standard scan plane with an accuracy of $4.91mm/4.65^\circ$ in the intra-patient setting, and accomplish the task in the intra- and inter-patient settings with a success rate of $92\%$ and $46\%$, respectively. The results also show that the introduction of image quality optimization in our method can effectively improve the navigation performance.
Constrained Contextual Bandit Learning for Adaptive Radar Waveform Selection
Mar 09, 2021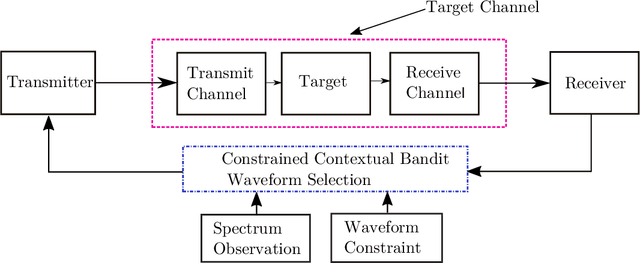
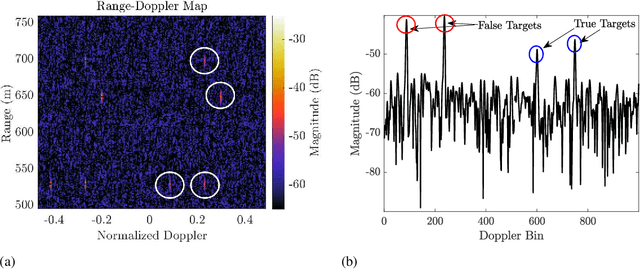
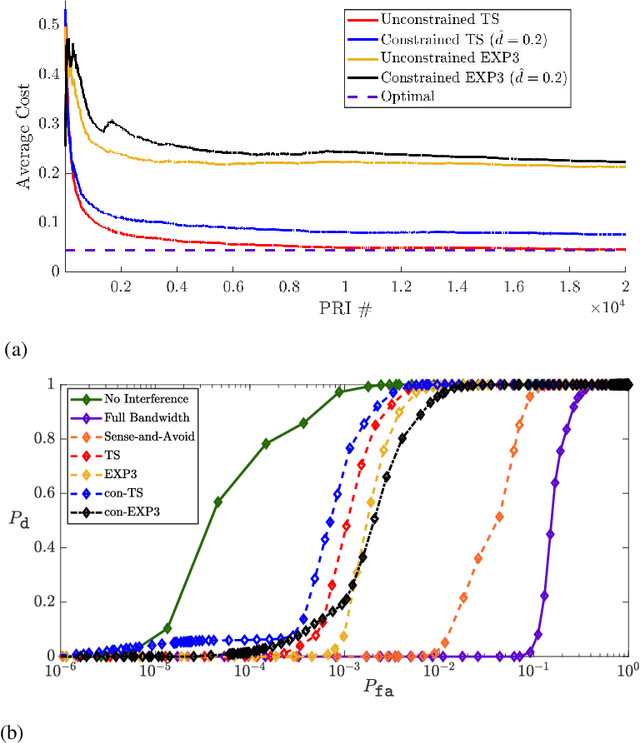
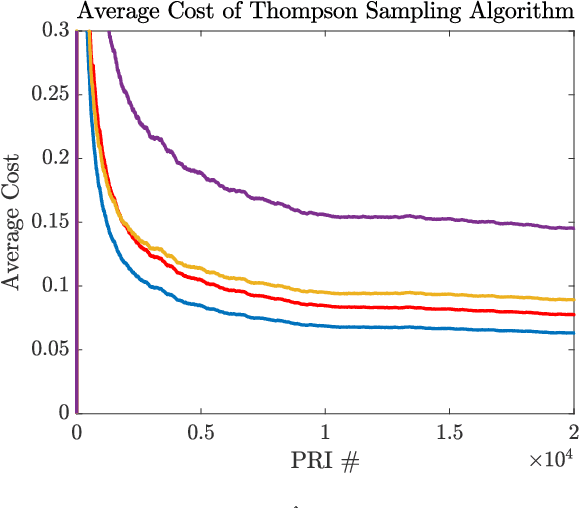
A sequential decision process in which an adaptive radar system repeatedly interacts with a finite-state target channel is studied. The radar is capable of passively sensing the spectrum at regular intervals, which provides side information for the waveform selection process. The radar transmitter uses the sequence of spectrum observations as well as feedback from a collocated receiver to select waveforms which accurately estimate target parameters. It is shown that the waveform selection problem can be effectively addressed using a linear contextual bandit formulation in a manner that is both computationally feasible and sample efficient. Stochastic and adversarial linear contextual bandit models are introduced, allowing the radar to achieve effective performance in broad classes of physical environments. Simulations in a radar-communication coexistence scenario, as well as in an adversarial radar-jammer scenario, demonstrate that the proposed formulation provides a substantial improvement in target detection performance when Thompson Sampling and EXP3 algorithms are used to drive the waveform selection process. Further, it is shown that the harmful impacts of pulse-agile behavior on coherently processed radar data can be mitigated by adopting a time-varying constraint on the radar's waveform catalog.
A Robust Extrinsic Calibration Framework for Vehicles with Unscaled Sensors
Mar 17, 2021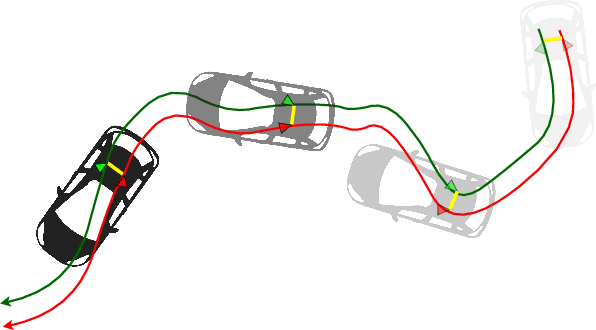
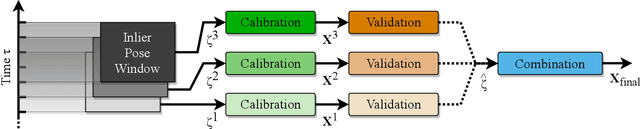
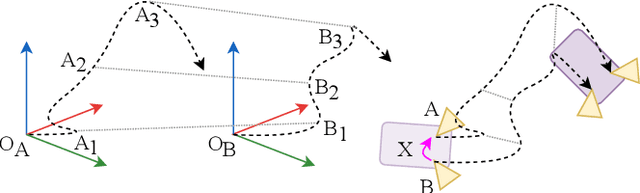
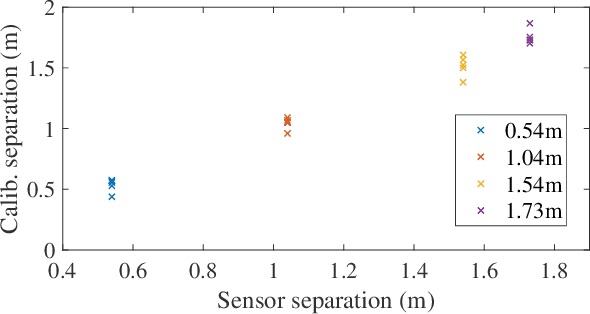
Accurate extrinsic sensor calibration is essential for both autonomous vehicles and robots. Traditionally this is an involved process requiring calibration targets, known fiducial markers and is generally performed in a lab. Moreover, even a small change in the sensor layout requires recalibration. With the anticipated arrival of consumer autonomous vehicles, there is demand for a system which can do this automatically, after deployment and without specialist human expertise. To solve these limitations, we propose a flexible framework which can estimate extrinsic parameters without an explicit calibration stage, even for sensors with unknown scale. Our first contribution builds upon standard hand-eye calibration by jointly recovering scale. Our second contribution is that our system is made robust to imperfect and degenerate sensor data, by collecting independent sets of poses and automatically selecting those which are most ideal. We show that our approach's robustness is essential for the target scenario. Unlike previous approaches, ours runs in real time and constantly estimates the extrinsic transform. For both an ideal experimental setup and a real use case, comparison against these approaches shows that we outperform the state-of-the-art. Furthermore, we demonstrate that the recovered scale may be applied to the full trajectory, circumventing the need for scale estimation via sensor fusion.
A Bayesian approach for $T_2^*$ Mapping and Quantitative Susceptibility Mapping
Mar 09, 2021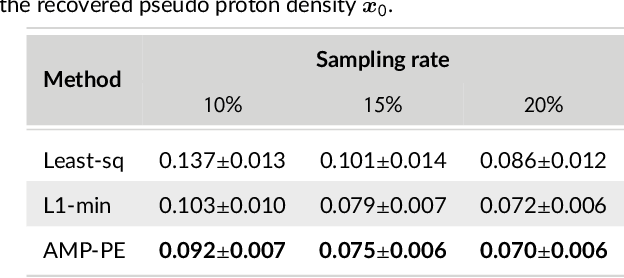
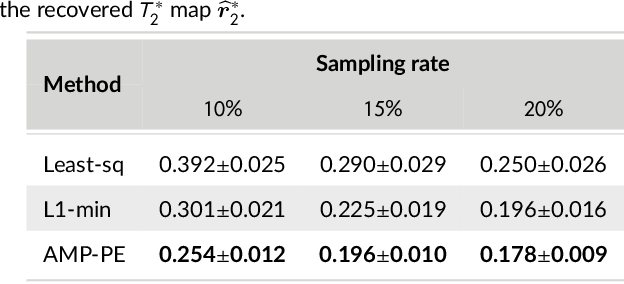
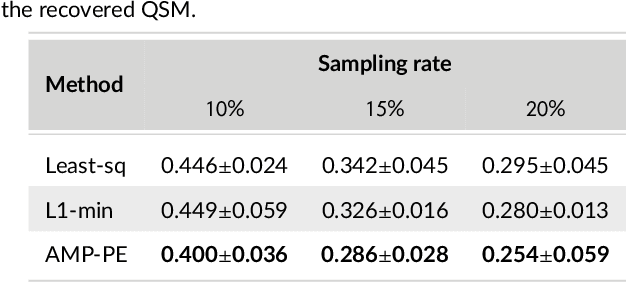
Magnetic resonance $T_2^*$ mapping and quantitative susceptibility mapping (QSM) provide direct and precise mappings of tissue contrasts. They are widely used to study iron deposition, hemorrhage and calcification in various clinical applications. In practice, the measurements can be undersampled in the $k$-space to reduce the scan time needed for high-resolution 3D maps, and sparse prior on the wavelet coefficients of images can be used to fill in the missing information via compressive sensing. To avoid the extensive parameter tuning process of conventional regularization methods, we adopt a Bayesian approach to perform $T_2^*$ mapping and QSM using approximate message passing (AMP): the sparse prior is enforced through probability distributions, and the distribution parameters can be automatically and adaptively estimated. In this paper we propose a new nonlinear AMP framework that incorporates the mono-exponential decay model, and use it to recover the proton density, the $T_2^*$ map and complex multi-echo images. The QSM can be computed from the multi-echo images subsequently. Experimental results show that the proposed approach successfully recovers $T_2^*$ map and QSM across various sampling rates, and performs much better than the state-of-the-art $l_1$-norm regularization approach.
Noise-Contrastive Estimation for Multivariate Point Processes
Nov 02, 2020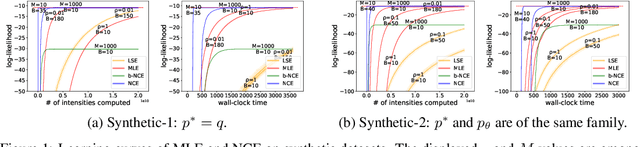
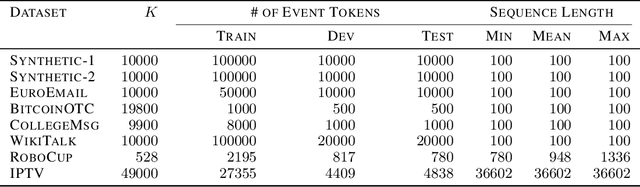
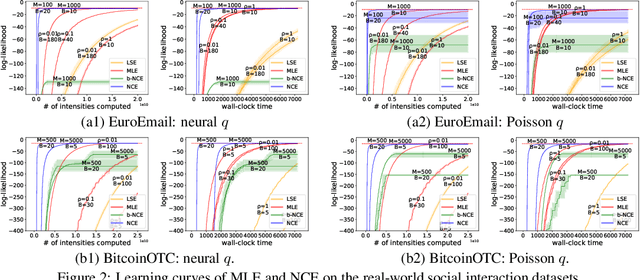
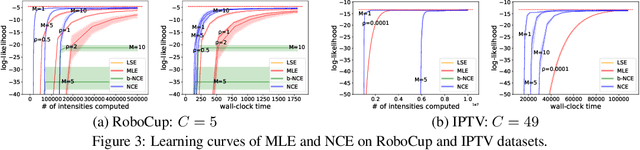
The log-likelihood of a generative model often involves both positive and negative terms. For a temporal multivariate point process, the negative term sums over all the possible event types at each time and also integrates over all the possible times. As a result, maximum likelihood estimation is expensive. We show how to instead apply a version of noise-contrastive estimation---a general parameter estimation method with a less expensive stochastic objective. Our specific instantiation of this general idea works out in an interestingly non-trivial way and has provable guarantees for its optimality, consistency and efficiency. On several synthetic and real-world datasets, our method shows benefits: for the model to achieve the same level of log-likelihood on held-out data, our method needs considerably fewer function evaluations and less wall-clock time.