 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Contrastive Self-supervised Neural Architecture Search
Feb 21, 2021
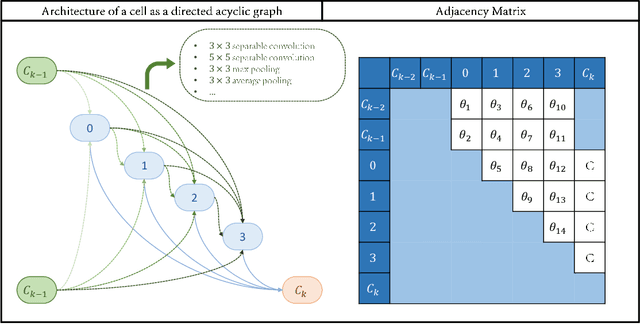
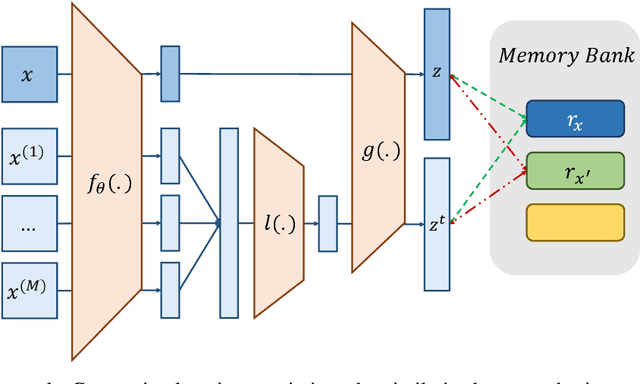
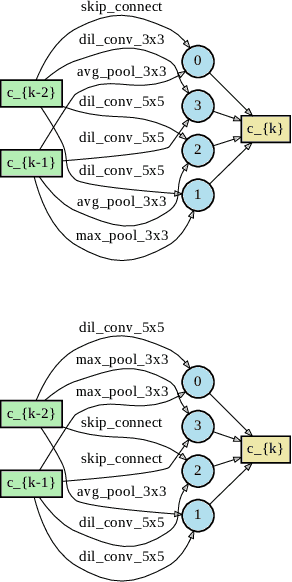
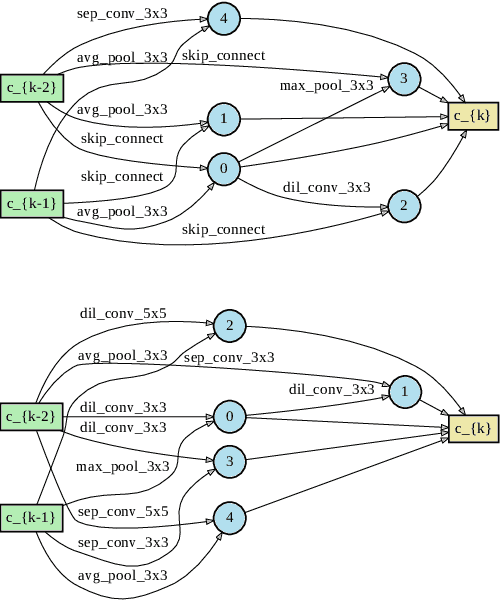
This paper proposes a novel cell-based neural architecture search algorithm (NAS), which completely alleviates the expensive costs of data labeling inherited from supervised learning. Our algorithm capitalizes on the effectiveness of self-supervised learning for image representations, which is an increasingly crucial topic of computer vision. First, using only a small amount of unlabeled train data under contrastive self-supervised learning allow us to search on a more extensive search space, discovering better neural architectures without surging the computational resources. Second, we entirely relieve the cost for labeled data (by contrastive loss) in the search stage without compromising architectures' final performance in the evaluation phase. Finally, we tackle the inherent discrete search space of the NAS problem by sequential model-based optimization via the tree-parzen estimator (SMBO-TPE), enabling us to reduce the computational expense response surface significantly. An extensive number of experiments empirically show that our search algorithm can achieve state-of-the-art results with better efficiency in data labeling cost, searching time, and accuracy in final validation.
CycleGAN-VC3: Examining and Improving CycleGAN-VCs for Mel-spectrogram Conversion
Oct 22, 2020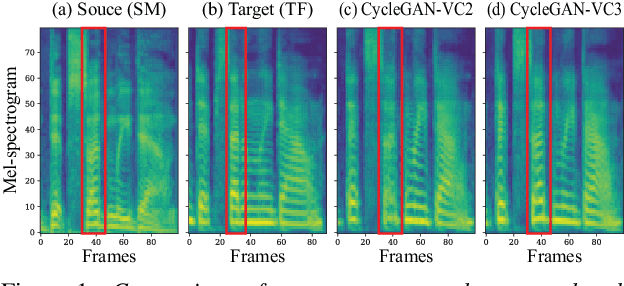
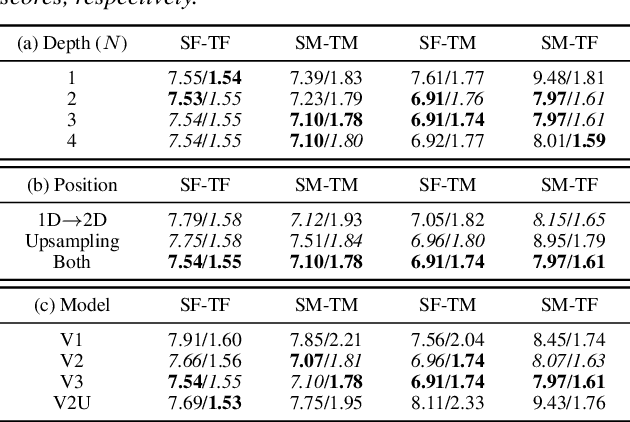
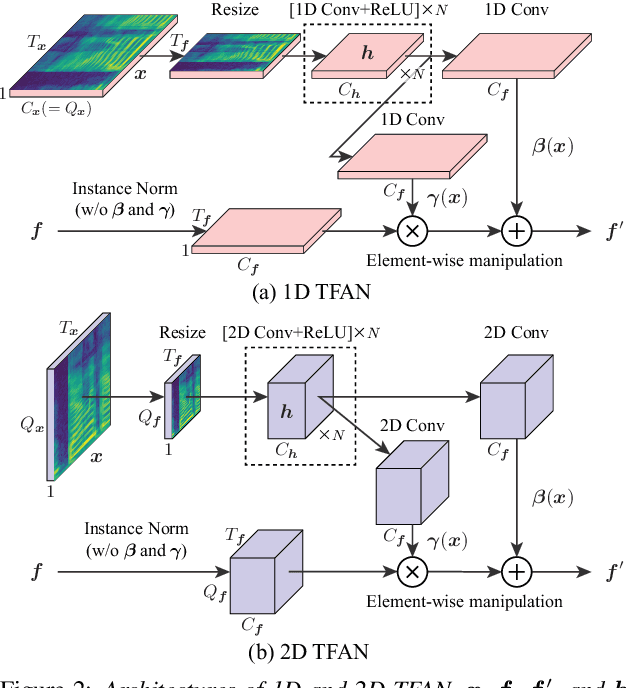
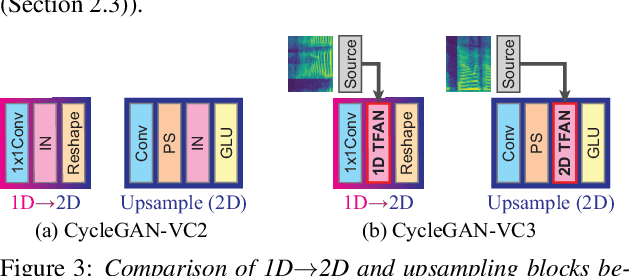
Non-parallel voice conversion (VC) is a technique for learning mappings between source and target speeches without using a parallel corpus. Recently, cycle-consistent adversarial network (CycleGAN)-VC and CycleGAN-VC2 have shown promising results regarding this problem and have been widely used as benchmark methods. However, owing to the ambiguity of the effectiveness of CycleGAN-VC/VC2 for mel-spectrogram conversion, they are typically used for mel-cepstrum conversion even when comparative methods employ mel-spectrogram as a conversion target. To address this, we examined the applicability of CycleGAN-VC/VC2 to mel-spectrogram conversion. Through initial experiments, we discovered that their direct applications compromised the time-frequency structure that should be preserved during conversion. To remedy this, we propose CycleGAN-VC3, an improvement of CycleGAN-VC2 that incorporates time-frequency adaptive normalization (TFAN). Using TFAN, we can adjust the scale and bias of the converted features while reflecting the time-frequency structure of the source mel-spectrogram. We evaluated CycleGAN-VC3 on inter-gender and intra-gender non-parallel VC. A subjective evaluation of naturalness and similarity showed that for every VC pair, CycleGAN-VC3 outperforms or is competitive with the two types of CycleGAN-VC2, one of which was applied to mel-cepstrum and the other to mel-spectrogram. Audio samples are available at http://www.kecl.ntt.co.jp/people/kaneko.takuhiro/projects/cyclegan-vc3/index.html.
unzipFPGA: Enhancing FPGA-based CNN Engines with On-the-Fly Weights Generation
Mar 09, 2021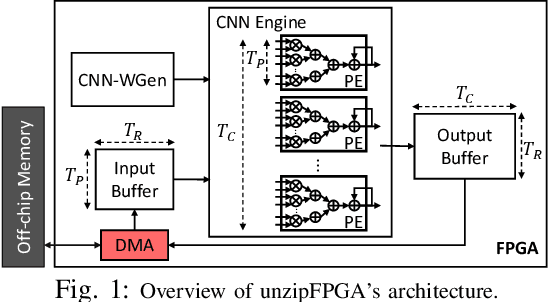
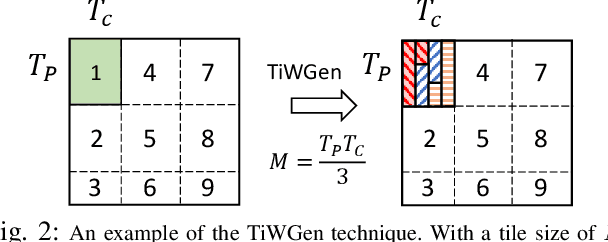
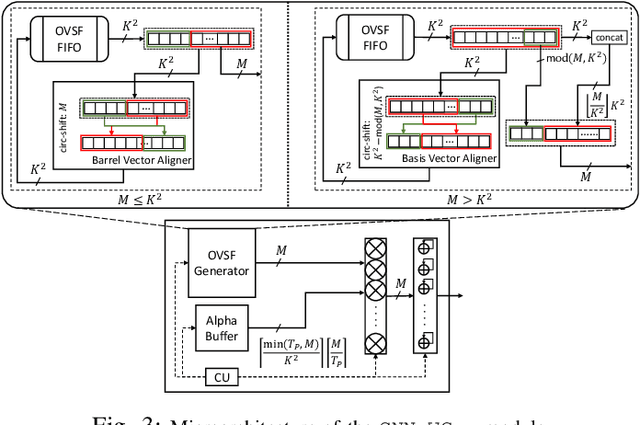
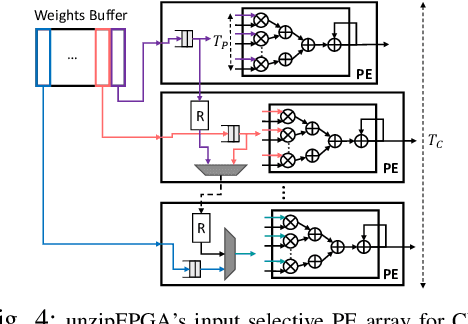
Single computation engines have become a popular design choice for FPGA-based convolutional neural networks (CNNs) enabling the deployment of diverse models without fabric reconfiguration. This flexibility, however, often comes with significantly reduced performance on memory-bound layers and resource underutilisation due to suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. To minimise the negative impact of limited bandwidth on memory-bound layers, we present a novel hardware component that enables the on-chip on-the-fly generation of weights. We further introduce an input selective processing element (PE) design that balances the load between PEs on suboptimally mapped layers. Finally, we present unzipFPGA, a framework to train on-the-fly models and traverse the design space to select the highest performing CNN engine configuration. Quantitative evaluation shows that unzipFPGA yields an average speedup of 2.14x and 71% over optimised status-quo and pruned CNN engines under constrained bandwidth and up to 3.69x higher performance density over the state-of-the-art FPGA-based CNN accelerators.
A Subjective Model of Human Decision Making Based on Quantum Decision Theory
Jan 14, 2021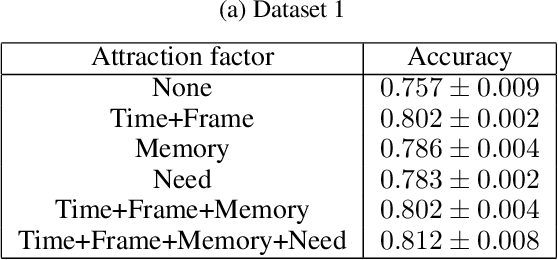
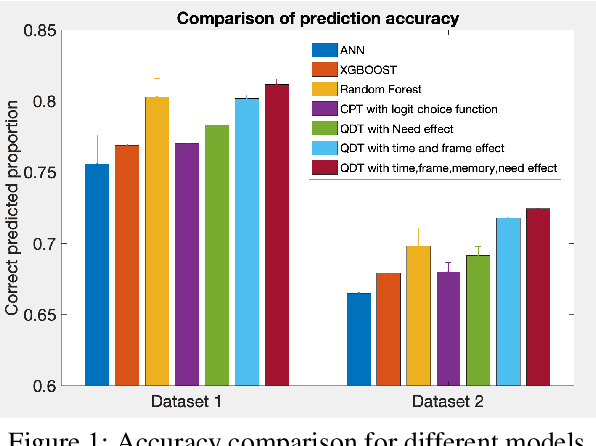
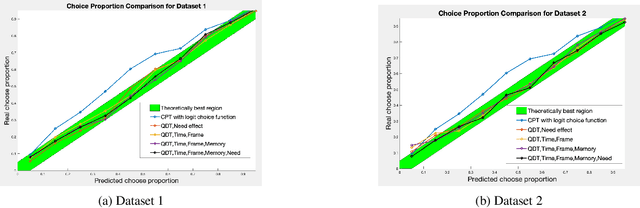
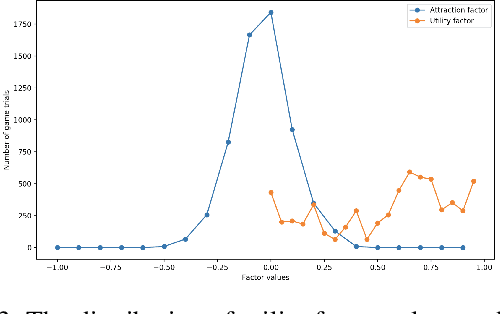
Computer modeling of human decision making is of large importance for, e.g., sustainable transport, urban development, and online recommendation systems. In this paper we present a model for predicting the behavior of an individual during a binary game under different amounts of risk, gain, and time pressure. The model is based on Quantum Decision Theory (QDT), which has been shown to enable modeling of the irrational and subjective aspects of the decision making, not accounted for by the classical Cumulative Prospect Theory (CPT). Experiments on two different datasets show that our QDT-based approach outperforms both a CPT-based approach and data driven approaches such as feed-forward neural networks and random forests.
CheckSoft : A Scalable Event-Driven Software Architecture for Keeping Track of People and Things in People-Centric Spaces
Feb 21, 2021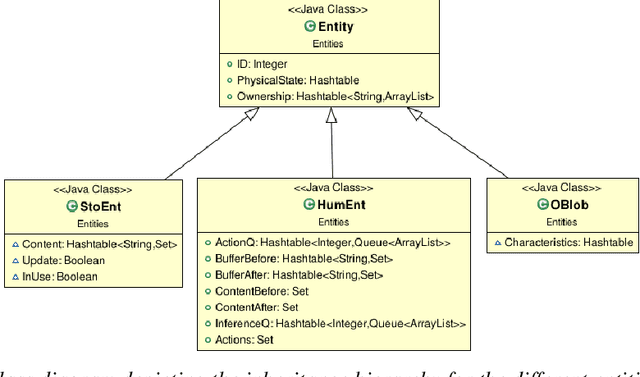
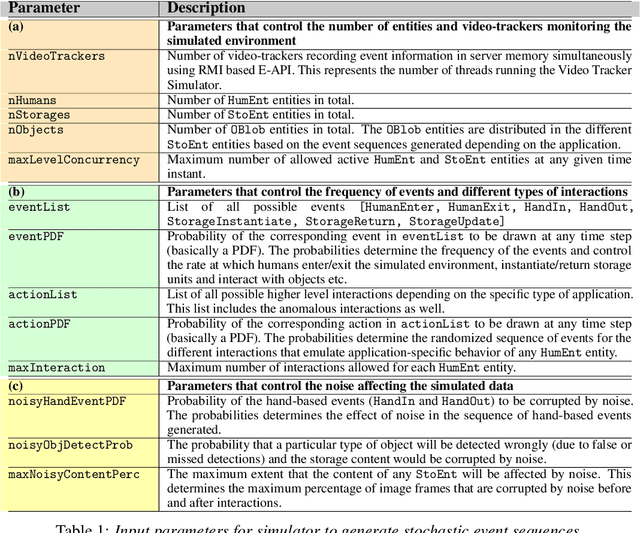
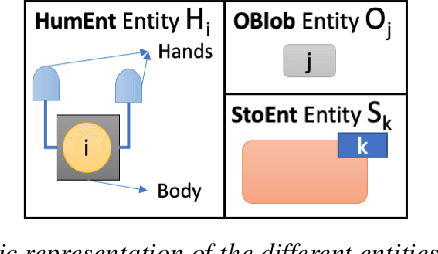
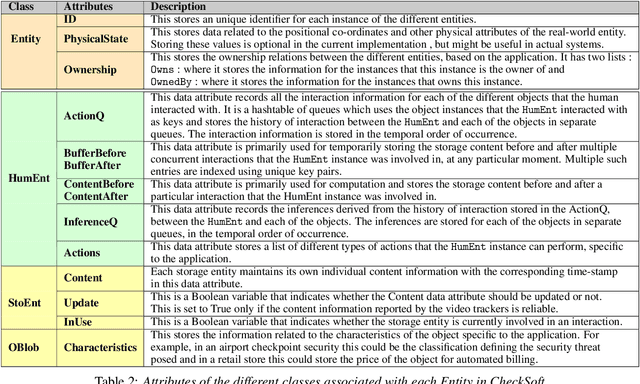
We present CheckSoft, a scalable event-driven software architecture for keeping track of people-object interactions in people-centric applications such as airport checkpoint security areas, automated retail stores, smart libraries, and so on. The architecture works off the video data generated in real time by a network of surveillance cameras. Although there are many different aspects to automating these applications, the most difficult part of the overall problem is keeping track of the interactions between the people and the objects. CheckSoft uses finite-state-machine (FSM) based logic for keeping track of such interactions which allows the system to quickly reject any false detections of the interactions by the video cameras. CheckSoft is easily scalable since the architecture is based on multi-processing in which a separate process is assigned to each human and to each "storage container" for the objects. A storage container may be a shelf on which the objects are displayed or a bin in which the objects are stored, depending on the specific application in which CheckSoft is deployed.
Variational quantum policies for reinforcement learning
Mar 09, 2021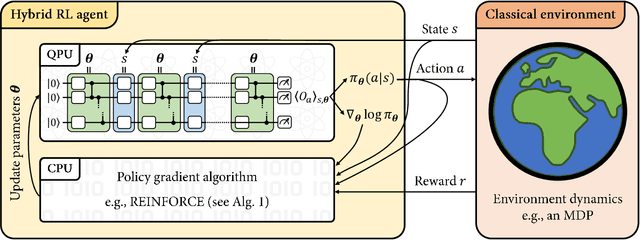

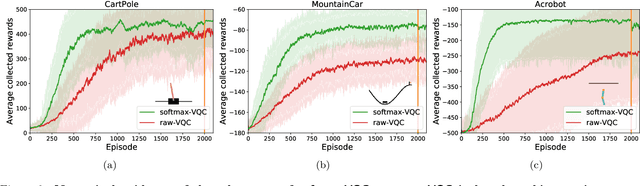
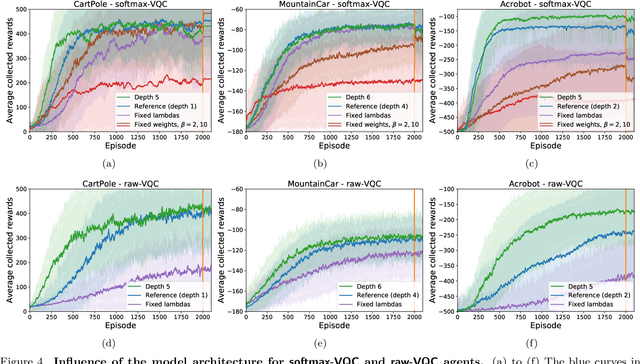
Variational quantum circuits have recently gained popularity as quantum machine learning models. While considerable effort has been invested to train them in supervised and unsupervised learning settings, relatively little attention has been given to their potential use in reinforcement learning. In this work, we leverage the understanding of quantum policy gradient algorithms in a number of ways. First, we investigate how to construct and train reinforcement learning policies based on variational quantum circuits. We propose several designs for quantum policies, provide their learning algorithms, and test their performance on classical benchmarking environments. Second, we show the existence of task environments with a provable separation in performance between quantum learning agents and any polynomial-time classical learner, conditioned on the widely-believed classical hardness of the discrete logarithm problem. We also consider more natural settings, in which we show an empirical quantum advantage of our quantum policies over standard neural-network policies. Our results constitute a first step towards establishing a practical near-term quantum advantage in a reinforcement learning setting. Additionally, we believe that some of our design choices for variational quantum policies may also be beneficial to other models based on variational quantum circuits, such as quantum classifiers and quantum regression models.
Helping Reduce Environmental Impact of Aviation with Machine Learning
Dec 17, 2020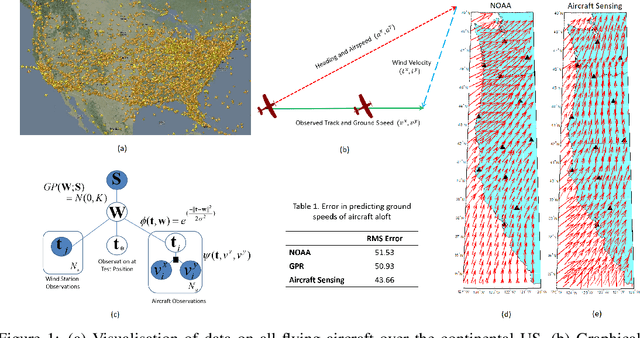
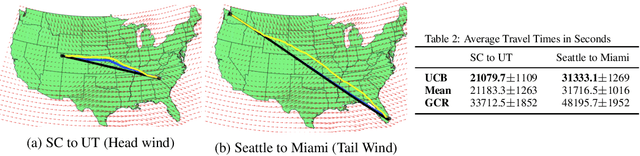
Commercial aviation is one of the biggest contributors towards climate change. We propose to reduce environmental impact of aviation by considering solutions that would reduce the flight time. Specifically, we first consider improving winds aloft forecast so that flight planners could use better information to find routes that are efficient. Secondly, we propose an aircraft routing method that seeks to find the fastest route to the destination by considering uncertainty in the wind forecasts and then optimally trading-off between exploration and exploitation.
Exploiting multi-temporal information for improved speckle reduction of Sentinel-1 SAR images by deep learning
Feb 01, 2021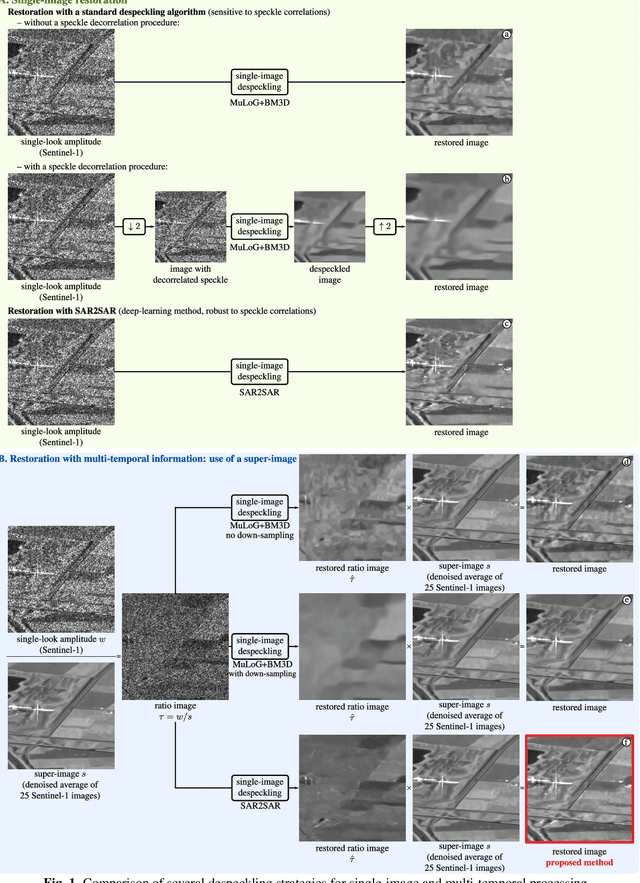
Deep learning approaches show unprecedented results for speckle reduction in SAR amplitude images. The wide availability of multi-temporal stacks of SAR images can improve even further the quality of denoising. In this paper, we propose a flexible yet efficient way to integrate temporal information into a deep neural network for speckle suppression. Archives provide access to long time-series of SAR images, from which multi-temporal averages can be computed with virtually no remaining speckle fluctuations. The proposed method combines this multi-temporal average and the image at a given date in the form of a ratio image and uses a state-of-the-art neural network to remove the speckle in this ratio image. This simple strategy is shown to offer a noticeable improvement compared to filtering the original image without knowledge of the multi-temporal average.
Three-Dimensional Virtual Histology in Unprocessed Resected Tissues with Photoacoustic Remote Sensing (PARS) Microscopy and Optical Coherence Tomography
Mar 01, 2021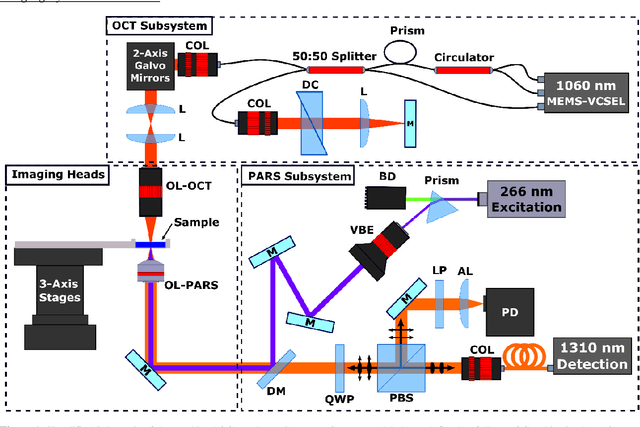


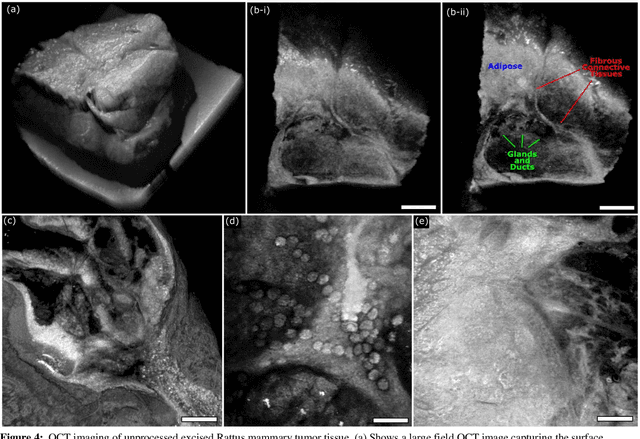
Histological visualizations are critical in the diagnosis and treatment of cancers and other malignancies. Unfortunately, the current method for capturing these visualizations requires resource intensive tissue preparation which can delay diagnostics for weeks. To streamline this process, clinicians are limited to assessing small macroscopically representative subsets of tissues. Here, we present a conjoined photoacoustic remote sensing (PARS) microscope and swept source optical coherence tomography (SS-OCT) system aiming to circumvent these diagnostic limitations. The proposed multimodal microscope provides label-free three-dimensional depth resolved virtual histology visualizations, capturing nuclear and extranuclear tissue morphology directly on thick unprocessed specimens. The capabilities of the proposed method are demonstrated directly in unprocessed formalin fixed resected tissues. Here, we present the first images of nuclear contrast in resected human tissues, and the first 3-dimensional visualization of subsurface nuclear morphology in resected Rattus tissues, captured with a non-contact photoacoustic system. Moreover, we present the first co-registered OCT and PARS images enabling direct histological assessment of unprocessed tissues. This work represents a vital step towards the development of a real-time histological imaging modality to circumvent the limitations of current histopathology techniques.
Identification of LTV Dynamical Models with Smooth or Discontinuous Time Evolution by means of Convex Optimization
Feb 27, 2018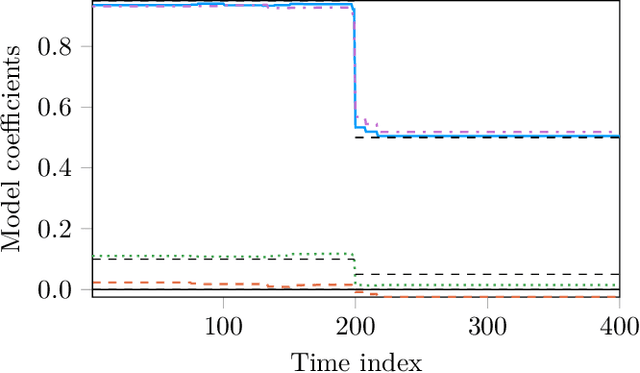
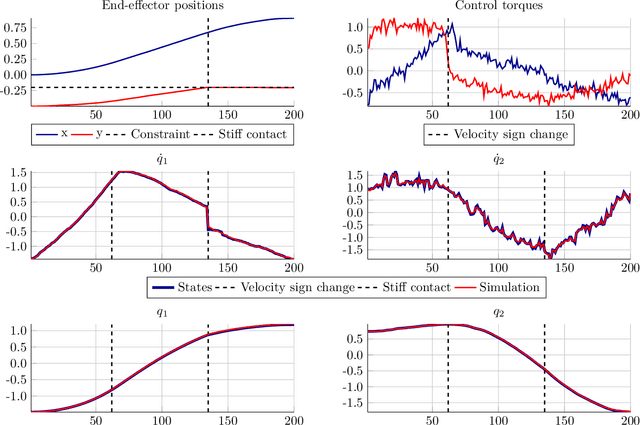
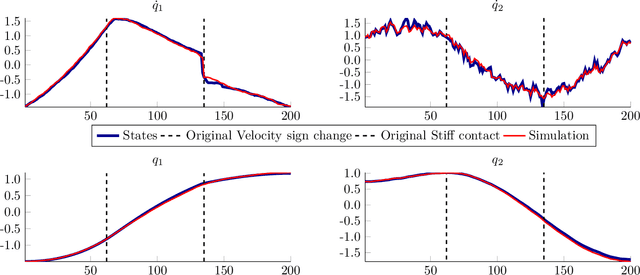
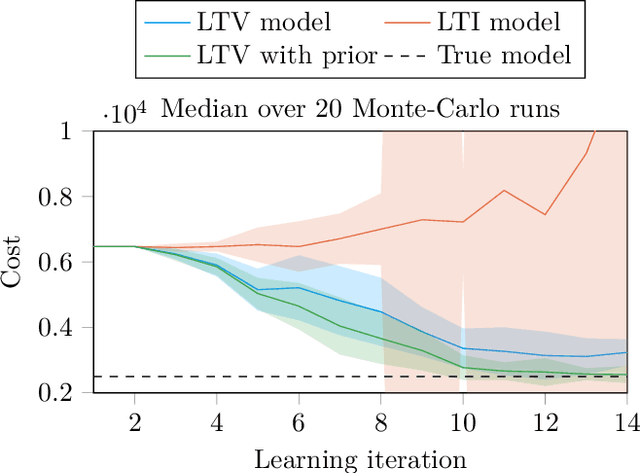
We establish a connection between trend filtering and system identification which results in a family of new identification methods for linear, time-varying (LTV) dynamical models based on convex optimization. We demonstrate how the design of the cost function promotes a model with either a continuous change in dynamics over time, or causes discontinuous changes in model coefficients occurring at a finite (sparse) set of time instances. We further discuss the introduction of priors on the model parameters for situations where excitation is insufficient for identification. The identification problems are cast as convex optimization problems and are applicable to, e.g., ARX models and state-space models with time-varying parameters. We illustrate usage of the methods in simulations of jump-linear systems, a nonlinear robot arm with non-smooth friction and stiff contacts as well as in model-based, trajectory centric reinforcement learning on a smooth nonlinear system.