 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Boosting One-Point Derivative-Free Online Optimization via Residual Feedback
Oct 14, 2020
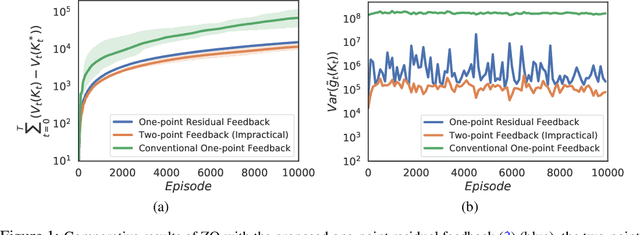
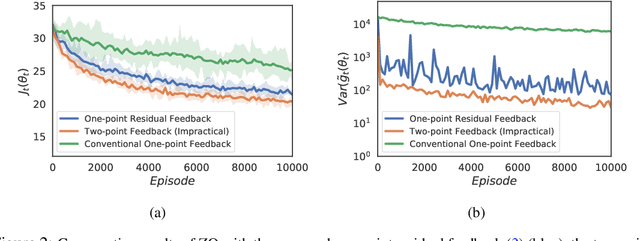
Zeroth-order optimization (ZO) typically relies on two-point feedback to estimate the unknown gradient of the objective function. Nevertheless, two-point feedback can not be used for online optimization of time-varying objective functions, where only a single query of the function value is possible at each time step. In this work, we propose a new one-point feedback method for online optimization that estimates the objective function gradient using the residual between two feedback points at consecutive time instants. Moreover, we develop regret bounds for ZO with residual feedback for both convex and nonconvex online optimization problems. Specifically, for both deterministic and stochastic problems and for both Lipschitz and smooth objective functions, we show that using residual feedback can produce gradient estimates with much smaller variance compared to conventional one-point feedback methods. As a result, our regret bounds are much tighter compared to existing regret bounds for ZO with conventional one-point feedback, which suggests that ZO with residual feedback can better track the optimizer of online optimization problems. Additionally, our regret bounds rely on weaker assumptions than those used in conventional one-point feedback methods. Numerical experiments show that ZO with residual feedback significantly outperforms existing one-point feedback methods also in practice.
Contrastive Self-supervised Neural Architecture Search
Feb 21, 2021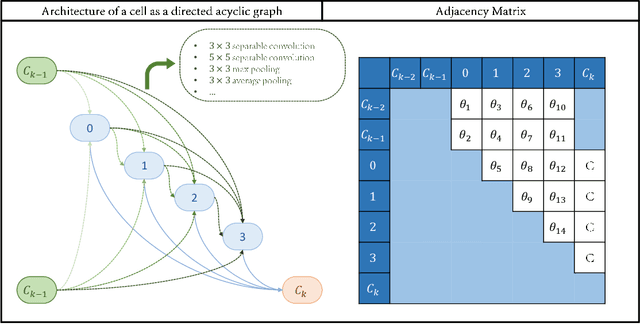
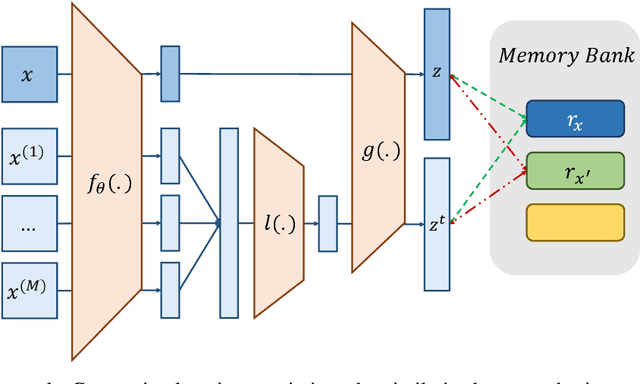
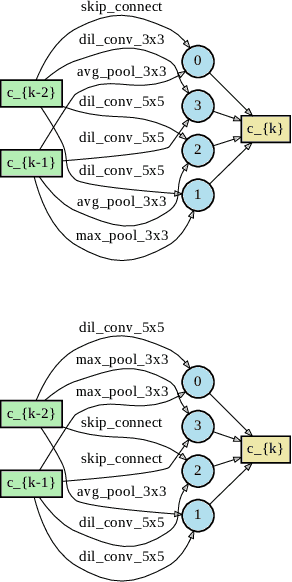
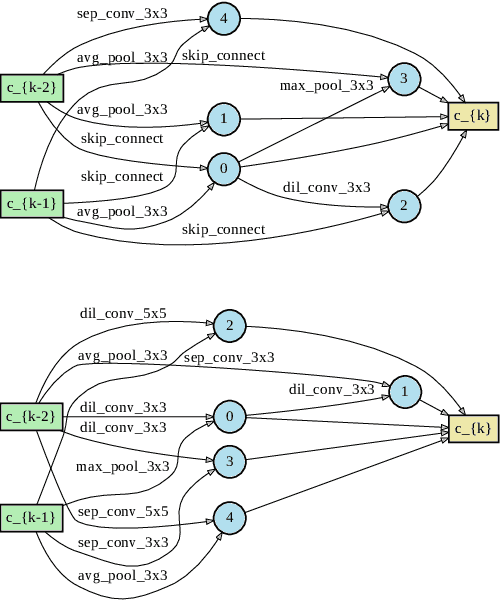
This paper proposes a novel cell-based neural architecture search algorithm (NAS), which completely alleviates the expensive costs of data labeling inherited from supervised learning. Our algorithm capitalizes on the effectiveness of self-supervised learning for image representations, which is an increasingly crucial topic of computer vision. First, using only a small amount of unlabeled train data under contrastive self-supervised learning allow us to search on a more extensive search space, discovering better neural architectures without surging the computational resources. Second, we entirely relieve the cost for labeled data (by contrastive loss) in the search stage without compromising architectures' final performance in the evaluation phase. Finally, we tackle the inherent discrete search space of the NAS problem by sequential model-based optimization via the tree-parzen estimator (SMBO-TPE), enabling us to reduce the computational expense response surface significantly. An extensive number of experiments empirically show that our search algorithm can achieve state-of-the-art results with better efficiency in data labeling cost, searching time, and accuracy in final validation.
A Multi-View Approach To Audio-Visual Speaker Verification
Feb 11, 2021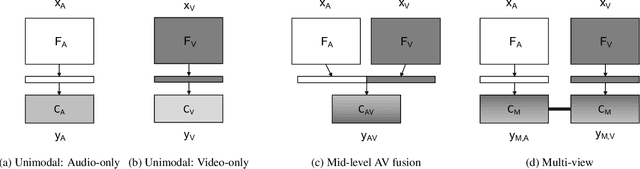
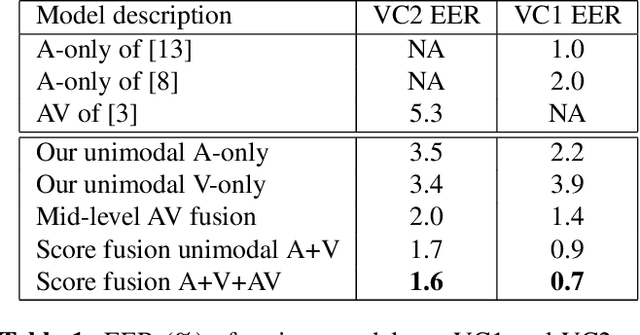

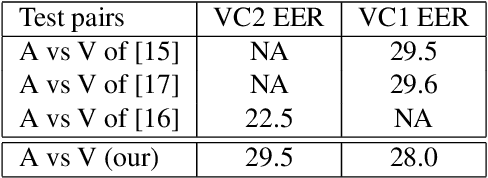
Although speaker verification has conventionally been an audio-only task, some practical applications provide both audio and visual streams of input. In these cases, the visual stream provides complementary information and can often be leveraged in conjunction with the acoustics of speech to improve verification performance. In this study, we explore audio-visual approaches to speaker verification, starting with standard fusion techniques to learn joint audio-visual (AV) embeddings, and then propose a novel approach to handle cross-modal verification at test time. Specifically, we investigate unimodal and concatenation based AV fusion and report the lowest AV equal error rate (EER) of 0.7% on the VoxCeleb1 dataset using our best system. As these methods lack the ability to do cross-modal verification, we introduce a multi-view model which uses a shared classifier to map audio and video into the same space. This new approach achieves 28% EER on VoxCeleb1 in the challenging testing condition of cross-modal verification.
3DIoUMatch: Leveraging IoU Prediction for Semi-Supervised 3D Object Detection
Dec 08, 2020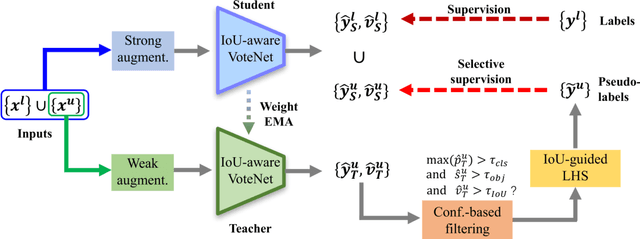
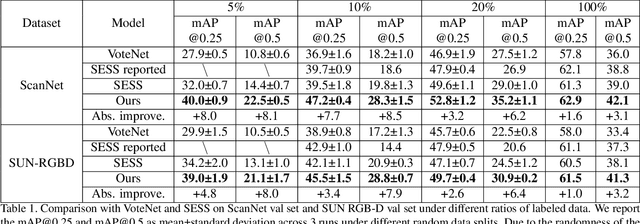
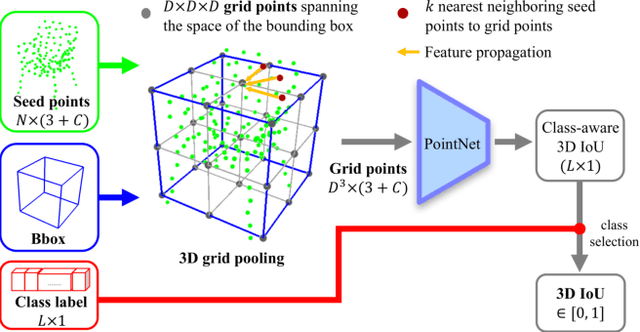
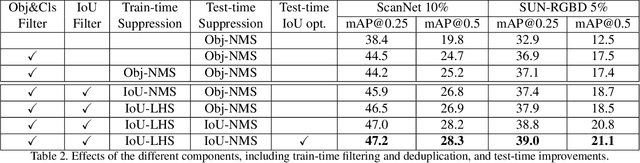
3D object detection is an important yet demanding task that heavily relies on difficult to obtain 3D annotations. To reduce the required amount of supervision, we propose 3DIoUMatch, a novel method for semi-supervised 3D object detection. We adopt VoteNet, a popular point cloud-based object detector, as our backbone and leverage a teacher-student mutual learning framework to propagate information from the labeled to the unlabeled train set in the form of pseudo-labels. However, due to the high task complexity, we observe that the pseudo-labels suffer from significant noise and are thus not directly usable. To that end, we introduce a confidence-based filtering mechanism. The key to our approach is a novel differentiable 3D IoU estimation module. This module is used for filtering poorly localized proposals as well as for IoU-guided bounding box deduplication. At inference time, this module is further utilized to improve localization through test-time optimization. Our method consistently improves state-of-the-art methods on both ScanNet and SUN-RGBD benchmarks by significant margins. For example, when training using only 10\% labeled data on ScanNet, 3DIoUMatch achieves 7.7 absolute improvement on mAP@0.25 and 8.5 absolute improvement on mAP@0.5 upon the prior art.
FastIF: Scalable Influence Functions for Efficient Model Interpretation and Debugging
Dec 31, 2020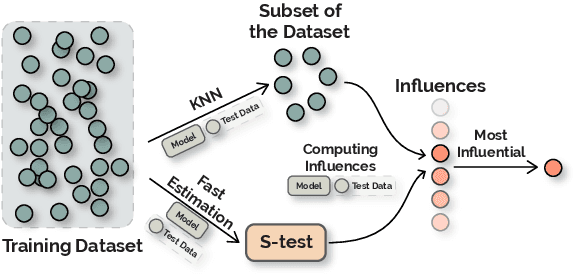

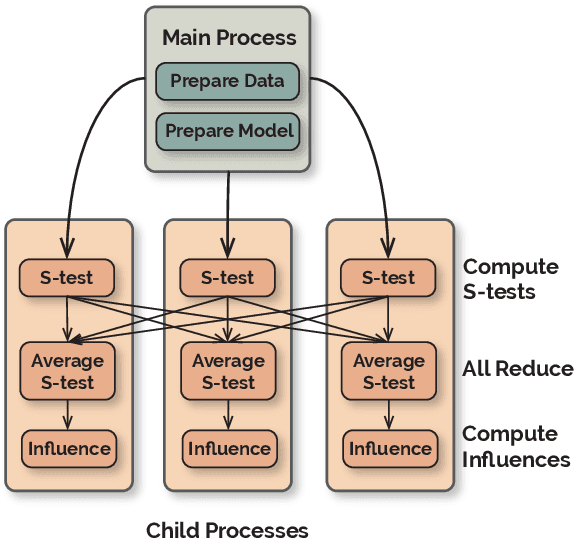
Influence functions approximate the 'influences' of training data-points for test predictions and have a wide variety of applications. Despite the popularity, their computational cost does not scale well with model and training data size. We present FastIF, a set of simple modifications to influence functions that significantly improves their run-time. We use k-Nearest Neighbors (kNN) to narrow the search space down to a subset of good candidate data points, identify the configurations that best balance the speed-quality trade-off in estimating the inverse Hessian-vector product, and introduce a fast parallel variant. Our proposed method achieves about 80x speedup while being highly correlated with the original influence values. With the availability of the fast influence functions, we demonstrate their usefulness in four applications. First, we examine whether influential data-points can 'explain' test time behavior using the framework of simulatability. Second, we visualize the influence interactions between training and test data-points. Third, we show that we can correct model errors by additional fine-tuning on certain influential data-points, improving the accuracy of a trained MNLI model by 2.6% on the HANS challenge set using a small number of gradient updates. Finally, we experiment with a data-augmentation setup where we use influence functions to search for new data-points unseen during training to improve model performance. Overall, our fast influence functions can be efficiently applied to large models and datasets, and our experiments demonstrate the potential of influence functions in model interpretation and correcting model errors. Code is available at https://github.com/salesforce/fast-influence-functions
Factorized Neural Processes for Neural Processes: $K$-Shot Prediction of Neural Responses
Oct 22, 2020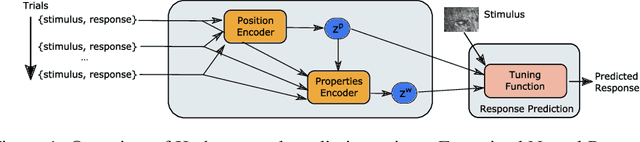

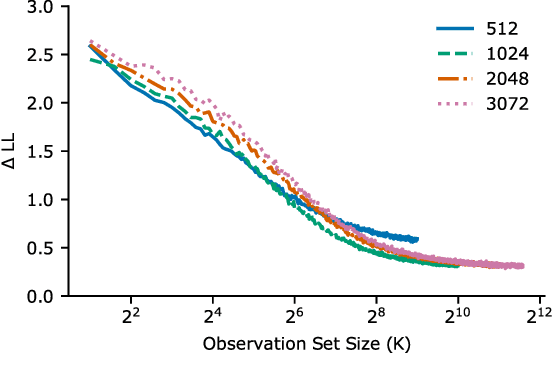
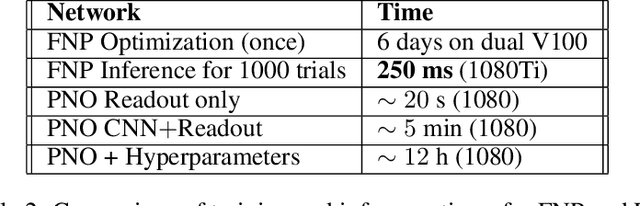
In recent years, artificial neural networks have achieved state-of-the-art performance for predicting the responses of neurons in the visual cortex to natural stimuli. However, they require a time consuming parameter optimization process for accurately modeling the tuning function of newly observed neurons, which prohibits many applications including real-time, closed-loop experiments. We overcome this limitation by formulating the problem as $K$-shot prediction to directly infer a neuron's tuning function from a small set of stimulus-response pairs using a Neural Process. This required us to developed a Factorized Neural Process, which embeds the observed set into a latent space partitioned into the receptive field location and the tuning function properties. We show on simulated responses that the predictions and reconstructed receptive fields from the Factorized Neural Process approach ground truth with increasing number of trials. Critically, the latent representation that summarizes the tuning function of a neuron is inferred in a quick, single forward pass through the network. Finally, we validate this approach on real neural data from visual cortex and find that the predictive accuracy is comparable to -- and for small $K$ even greater than -- optimization based approaches, while being substantially faster. We believe this novel deep learning systems identification framework will facilitate better real-time integration of artificial neural network modeling into neuroscience experiments.
unzipFPGA: Enhancing FPGA-based CNN Engines with On-the-Fly Weights Generation
Mar 09, 2021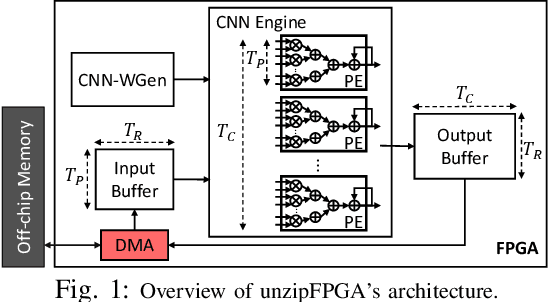
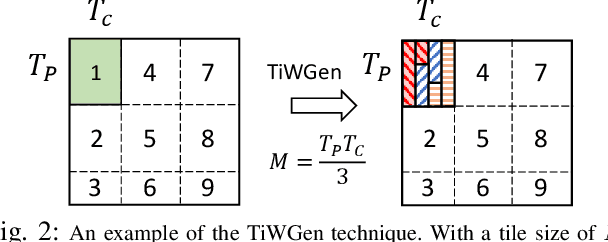
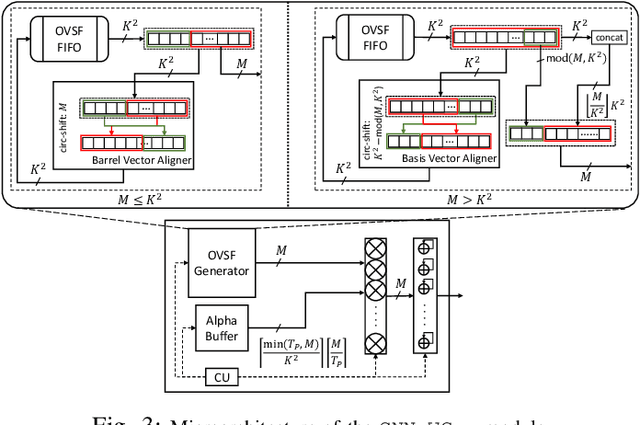
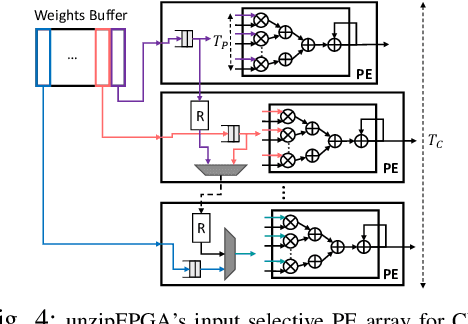
Single computation engines have become a popular design choice for FPGA-based convolutional neural networks (CNNs) enabling the deployment of diverse models without fabric reconfiguration. This flexibility, however, often comes with significantly reduced performance on memory-bound layers and resource underutilisation due to suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. To minimise the negative impact of limited bandwidth on memory-bound layers, we present a novel hardware component that enables the on-chip on-the-fly generation of weights. We further introduce an input selective processing element (PE) design that balances the load between PEs on suboptimally mapped layers. Finally, we present unzipFPGA, a framework to train on-the-fly models and traverse the design space to select the highest performing CNN engine configuration. Quantitative evaluation shows that unzipFPGA yields an average speedup of 2.14x and 71% over optimised status-quo and pruned CNN engines under constrained bandwidth and up to 3.69x higher performance density over the state-of-the-art FPGA-based CNN accelerators.
Online Planning in Uncertain and Dynamic Environment in the Presence of Multiple Mobile Vehicles
Sep 08, 2020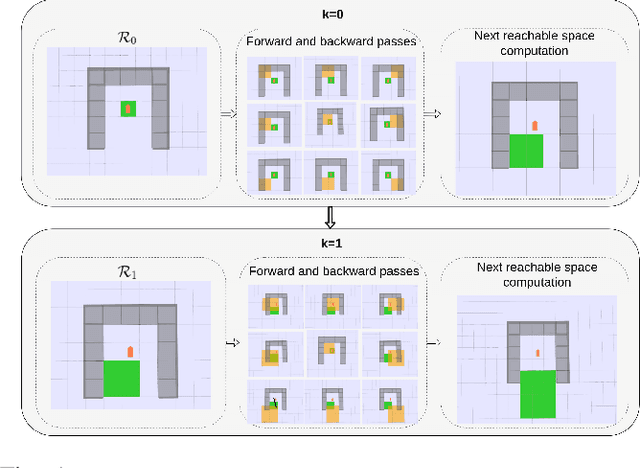
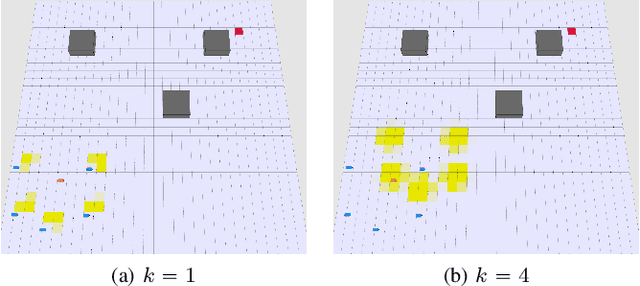
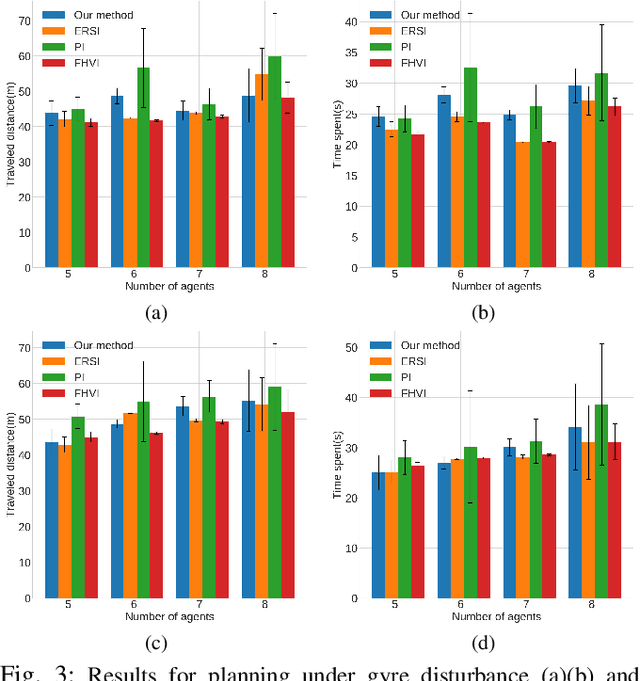
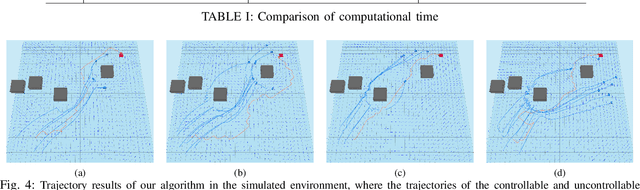
We investigate the autonomous navigation of a mobile robot in the presence of other moving vehicles under time-varying uncertain environmental disturbances. We first predict the future state distributions of other vehicles to account for their uncertain behaviors affected by the time-varying disturbances. We then construct a dynamic-obstacle-aware reachable space that contains states with high probabilities to be reached by the robot, within which the optimal policy is searched. Since, in general, the dynamics of both the vehicle and the environmental disturbances are nonlinear, we utilize a nonlinear Gaussian filter -- the unscented transform -- to approximate the future state distributions. Finally, the forward reachable space computation and backward policy search are iterated until convergence. Extensive simulation evaluations have revealed significant advantages of this proposed method in terms of computation time, decision accuracy, and planning reliability.
CheckSoft : A Scalable Event-Driven Software Architecture for Keeping Track of People and Things in People-Centric Spaces
Feb 21, 2021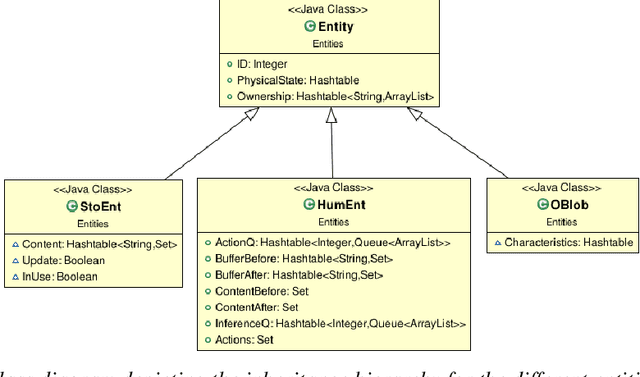
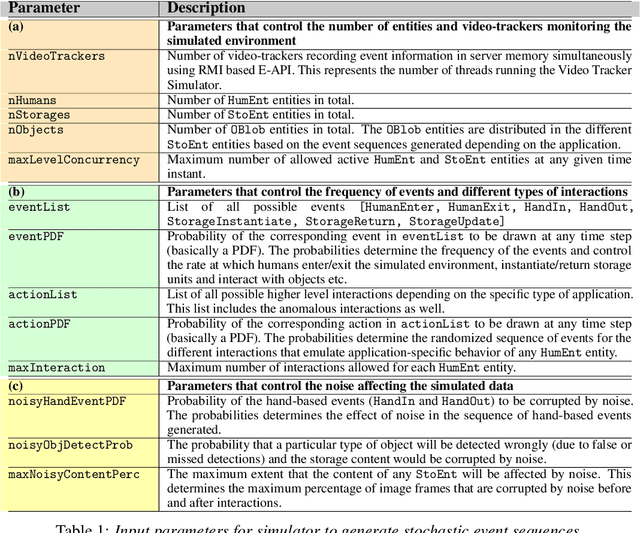
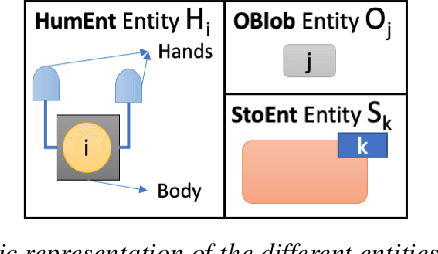
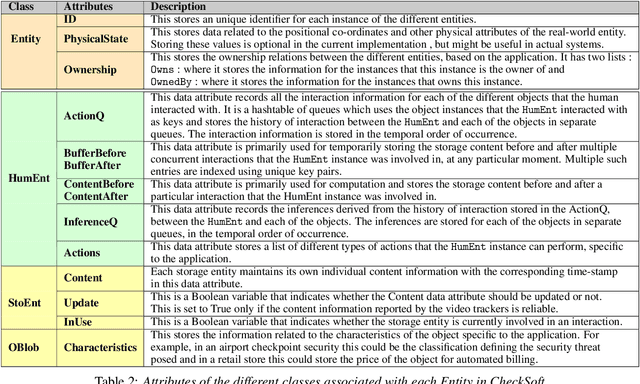
We present CheckSoft, a scalable event-driven software architecture for keeping track of people-object interactions in people-centric applications such as airport checkpoint security areas, automated retail stores, smart libraries, and so on. The architecture works off the video data generated in real time by a network of surveillance cameras. Although there are many different aspects to automating these applications, the most difficult part of the overall problem is keeping track of the interactions between the people and the objects. CheckSoft uses finite-state-machine (FSM) based logic for keeping track of such interactions which allows the system to quickly reject any false detections of the interactions by the video cameras. CheckSoft is easily scalable since the architecture is based on multi-processing in which a separate process is assigned to each human and to each "storage container" for the objects. A storage container may be a shelf on which the objects are displayed or a bin in which the objects are stored, depending on the specific application in which CheckSoft is deployed.
Variational quantum policies for reinforcement learning
Mar 09, 2021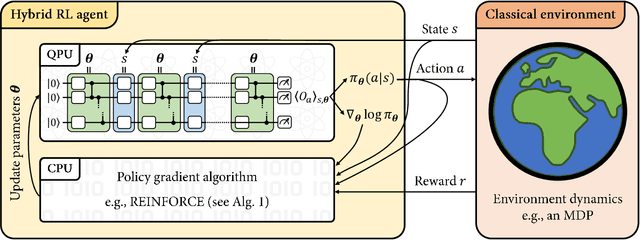

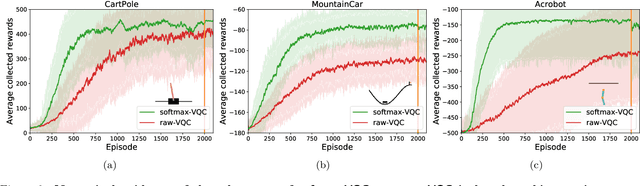
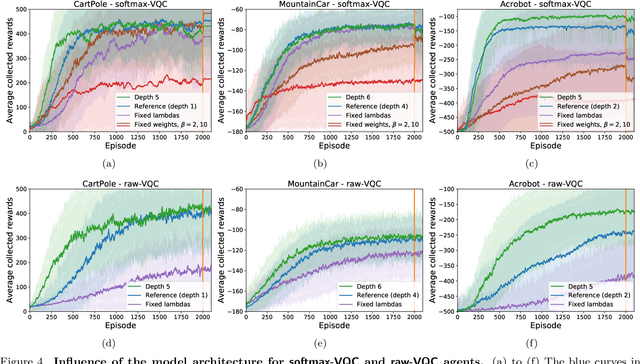
Variational quantum circuits have recently gained popularity as quantum machine learning models. While considerable effort has been invested to train them in supervised and unsupervised learning settings, relatively little attention has been given to their potential use in reinforcement learning. In this work, we leverage the understanding of quantum policy gradient algorithms in a number of ways. First, we investigate how to construct and train reinforcement learning policies based on variational quantum circuits. We propose several designs for quantum policies, provide their learning algorithms, and test their performance on classical benchmarking environments. Second, we show the existence of task environments with a provable separation in performance between quantum learning agents and any polynomial-time classical learner, conditioned on the widely-believed classical hardness of the discrete logarithm problem. We also consider more natural settings, in which we show an empirical quantum advantage of our quantum policies over standard neural-network policies. Our results constitute a first step towards establishing a practical near-term quantum advantage in a reinforcement learning setting. Additionally, we believe that some of our design choices for variational quantum policies may also be beneficial to other models based on variational quantum circuits, such as quantum classifiers and quantum regression models.