 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Automating Program Structure Classification
Jan 15, 2021
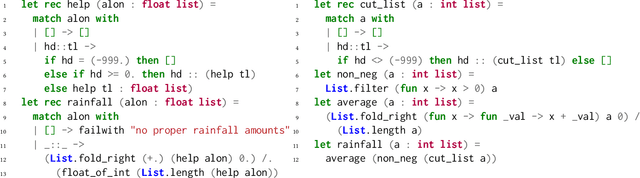

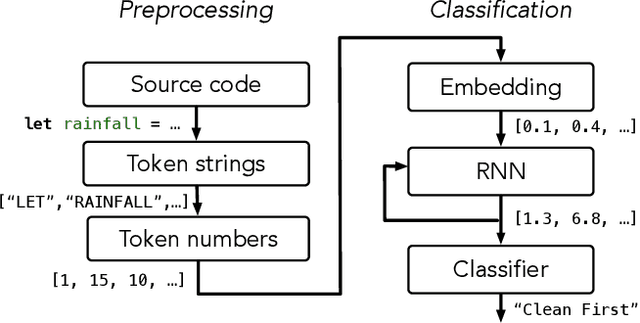
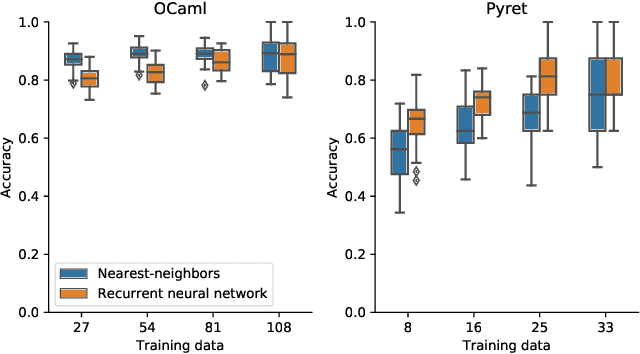
When students write programs, their program structure provides insight into their learning process. However, analyzing program structure by hand is time-consuming, and teachers need better tools for computer-assisted exploration of student solutions. As a first step towards an education-oriented program analysis toolkit, we show how supervised machine learning methods can automatically classify student programs into a predetermined set of high-level structures. We evaluate two models on classifying student solutions to the Rainfall problem: a nearest-neighbors classifier using syntax tree edit distance and a recurrent neural network. We demonstrate that these models can achieve 91% classification accuracy when trained on 108 programs. We further explore the generality, trade-offs, and failure cases of each model.
MetaSCI: Scalable and Adaptive Reconstruction for Video Compressive Sensing
Mar 02, 2021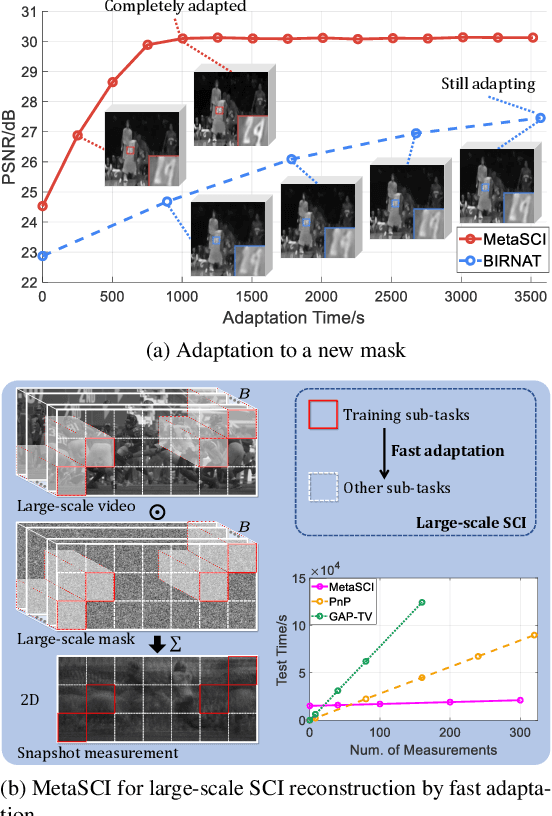

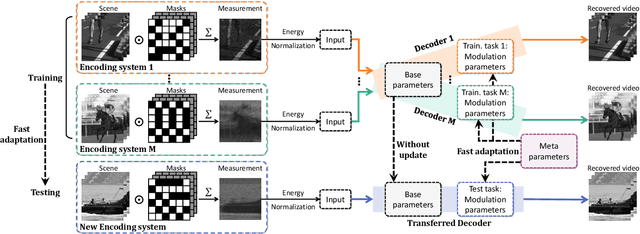
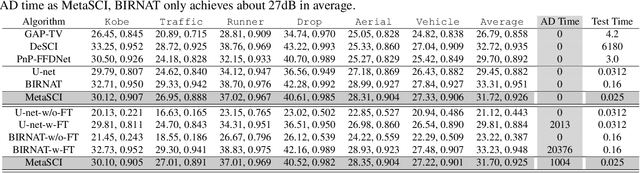
To capture high-speed videos using a two-dimensional detector, video snapshot compressive imaging (SCI) is a promising system, where the video frames are coded by different masks and then compressed to a snapshot measurement. Following this, efficient algorithms are desired to reconstruct the high-speed frames, where the state-of-the-art results are achieved by deep learning networks. However, these networks are usually trained for specific small-scale masks and often have high demands of training time and GPU memory, which are hence {\bf \em not flexible} to $i$) a new mask with the same size and $ii$) a larger-scale mask. We address these challenges by developing a Meta Modulated Convolutional Network for SCI reconstruction, dubbed MetaSCI. MetaSCI is composed of a shared backbone for different masks, and light-weight meta-modulation parameters to evolve to different modulation parameters for each mask, thus having the properties of {\bf \em fast adaptation} to new masks (or systems) and ready to {\bf \em scale to large data}. Extensive simulation and real data results demonstrate the superior performance of our proposed approach. Our code is available at {\small\url{https://github.com/xyvirtualgroup/MetaSCI-CVPR2021}}.
InstantEmbedding: Efficient Local Node Representations
Oct 14, 2020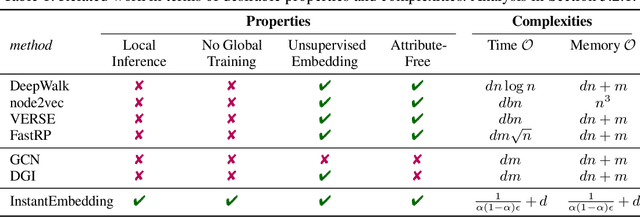
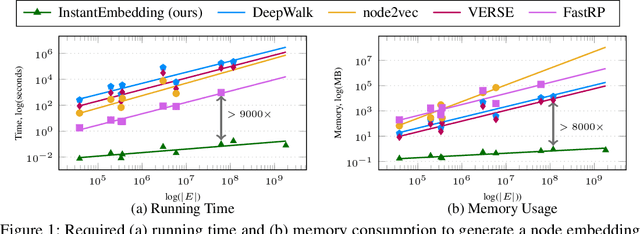
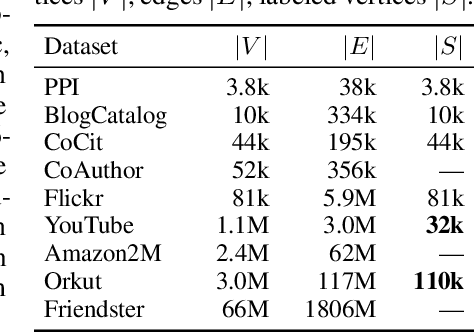
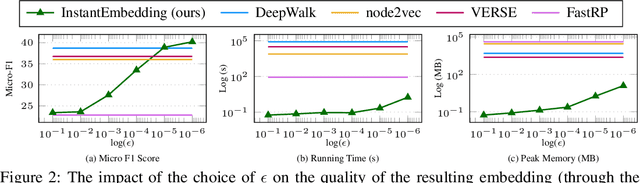
In this paper, we introduce InstantEmbedding, an efficient method for generating single-node representations using local PageRank computations. We theoretically prove that our approach produces globally consistent representations in sublinear time. We demonstrate this empirically by conducting extensive experiments on real-world datasets with over a billion edges. Our experiments confirm that InstantEmbedding requires drastically less computation time (over 9,000 times faster) and less memory (by over 8,000 times) to produce a single node's embedding than traditional methods including DeepWalk, node2vec, VERSE, and FastRP. We also show that our method produces high quality representations, demonstrating results that meet or exceed the state of the art for unsupervised representation learning on tasks like node classification and link prediction.
A Review and Refinement of Surprise Adequacy
Mar 10, 2021
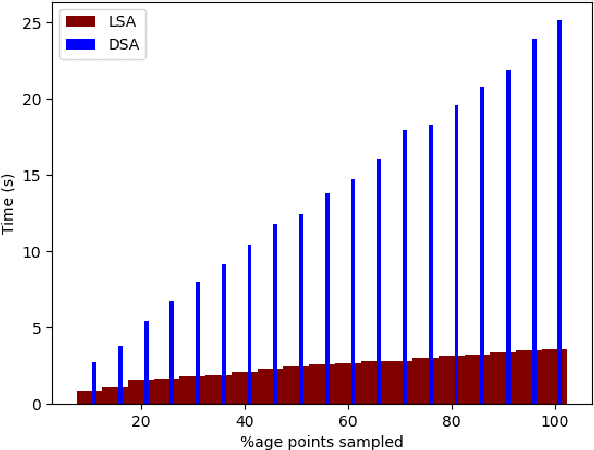
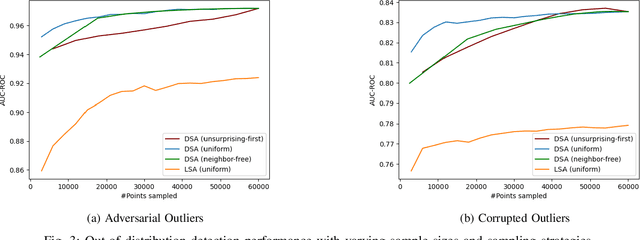
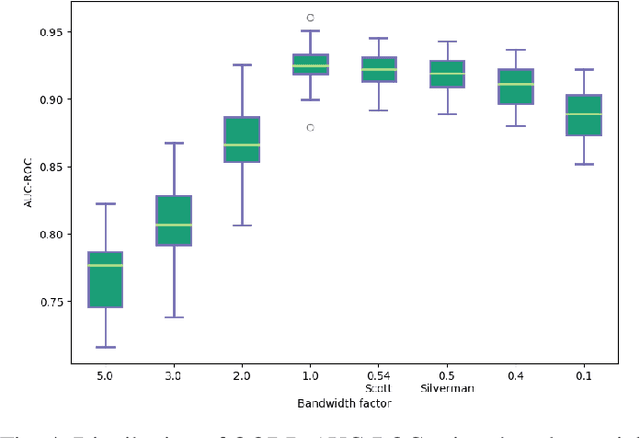
Surprise Adequacy (SA) is one of the emerging and most promising adequacy criteria for Deep Learning (DL) testing. As an adequacy criterion, it has been used to assess the strength of DL test suites. In addition, it has also been used to find inputs to a Deep Neural Network (DNN) which were not sufficiently represented in the training data, or to select samples for DNN retraining. However, computation of the SA metric for a test suite can be prohibitively expensive, as it involves a quadratic number of distance calculations. Hence, we developed and released a performance-optimized, but functionally equivalent, implementation of SA, reducing the evaluation time by up to 97\%. We also propose refined variants of the SA omputation algorithm, aiming to further increase the evaluation speed. We then performed an empirical study on MNIST, focused on the out-of-distribution detection capabilities of SA, which allowed us to reproduce parts of the results presented when SA was first released. The experiments show that our refined variants are substantially faster than plain SA, while producing comparable outcomes. Our experimental results exposed also an overlooked issue of SA: it can be highly sensitive to the non-determinism associated with the DNN training procedure.
Polarized Skylight Navigation System (PSNS)/ GNSS/SINS Integrated Navigation
Oct 20, 2020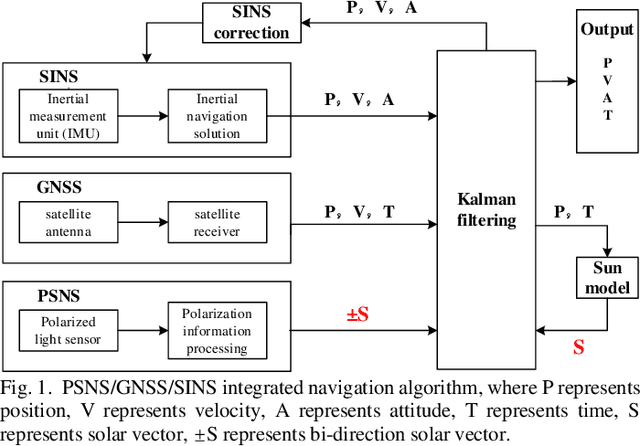

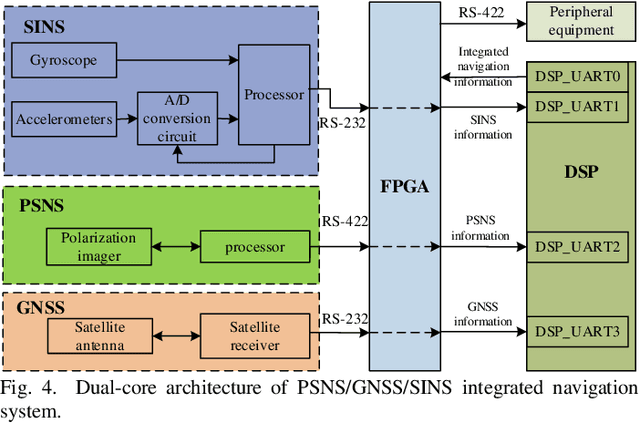
Bioinspired polarized skylight navigation system (PSNS) is a new navigation method, which imitates insects using polarized skylight for navigation. However, the latest research shows that the current PSNS is difficult to obtain the three-dimensional (3D) attitude in real time only relying on polarized skylight. This causes not only that three-dimensional (3D) cannot be estimated only by PSNS in real time, but also when polarized light is integrated with other navigation methods, 3D attitude cannot be directly used for integrated navigation. Therefore, an integrated navigation algorithm based on bi-direction solar vector is proposed, and a DSP+FPGA (digital signal processor + field programmable gate array) dual-core architecture PSNS/GNSS/SINS (global navigation satellite system/strapdown inertial navigation system) integrated navigation system was constructed.
Combining Learning from Demonstration with Learning by Exploration to Facilitate Contact-Rich Tasks
Mar 10, 2021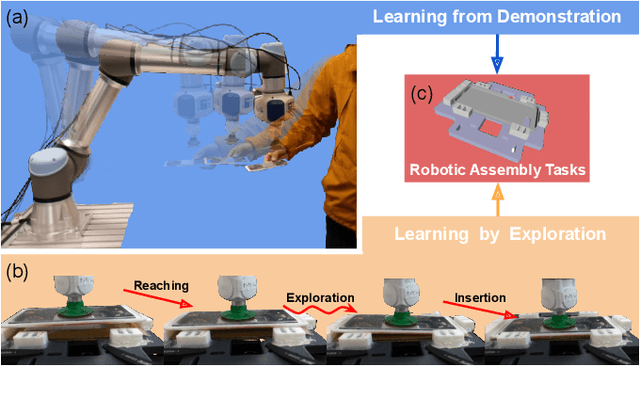

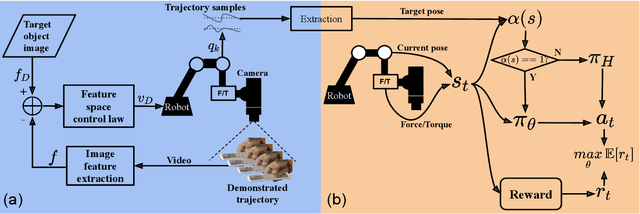
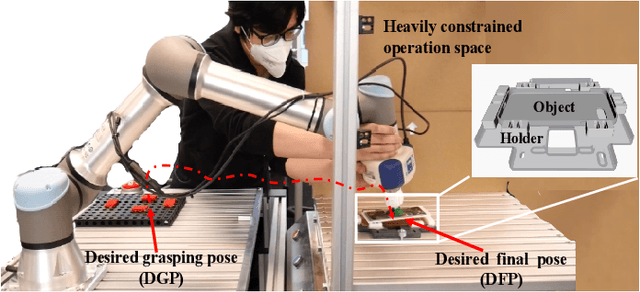
Collaborative robots are expected to be able to work alongside humans and in some cases directly replace existing human workers, thus effectively responding to rapid assembly line changes. Current methods for programming contact-rich tasks, especially in heavily constrained space, tend to be fairly inefficient. Therefore, faster and more intuitive approaches to robot teaching are urgently required. This work focuses on combining visual servoing based learning from demonstration (LfD) and force-based learning by exploration (LbE), to enable fast and intuitive programming of contact-rich tasks with minimal user effort required. Two learning approaches were developed and integrated into a framework, and one relying on human to robot motion mapping (the visual servoing approach) and one on force-based reinforcement learning. The developed framework implements the non-contact demonstration teaching method based on visual servoing approach and optimizes the demonstrated robot target positions according to the detected contact state. The framework has been compared with two most commonly used baseline techniques, pendant-based teaching and hand-guiding teaching. The efficiency and reliability of the framework have been validated through comparison experiments involving the teaching and execution of contact-rich tasks. The framework proposed in this paper has performed the best in terms of teaching time, execution success rate, risk of damage, and ease of use.
Expressway visibility estimation based on image entropy and piecewise stationary time series analysis
Apr 08, 2018



Vision-based methods for visibility estimation can play a critical role in reducing traffic accidents caused by fog and haze. To overcome the disadvantages of current visibility estimation methods, we present a novel data-driven approach based on Gaussian image entropy and piecewise stationary time series analysis (SPEV). This is the first time that Gaussian image entropy is used for estimating atmospheric visibility. To lessen the impact of landscape and sunshine illuminance on visibility estimation, we used region of interest (ROI) analysis and took into account relative ratios of image entropy, to improve estimation accuracy. We assume fog and haze cause blurred images and that fog and haze can be considered as a piecewise stationary signal. We used piecewise stationary time series analysis to construct the piecewise causal relationship between image entropy and visibility. To obtain a real-world visibility measure during fog and haze, a subjective assessment was established through a study with 36 subjects who performed visibility observations. Finally, a total of two million videos were used for training the SPEV model and validate its effectiveness. The videos were collected from the constantly foggy and hazy Tongqi expressway in Jiangsu, China. The contrast model of visibility estimation was used for algorithm performance comparison, and the validation results of the SPEV model were encouraging as 99.14% of the relative errors were less than 10%.
The Role of Edge Robotics As-a-Service in Monitoring COVID-19 Infection
Dec 09, 2020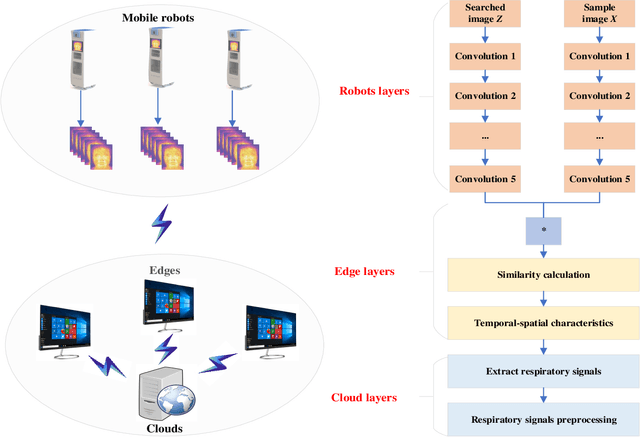
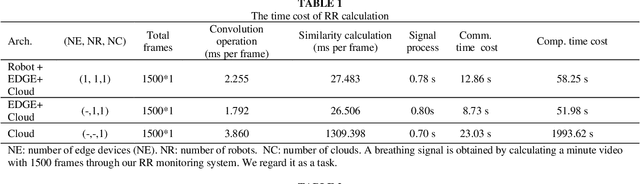
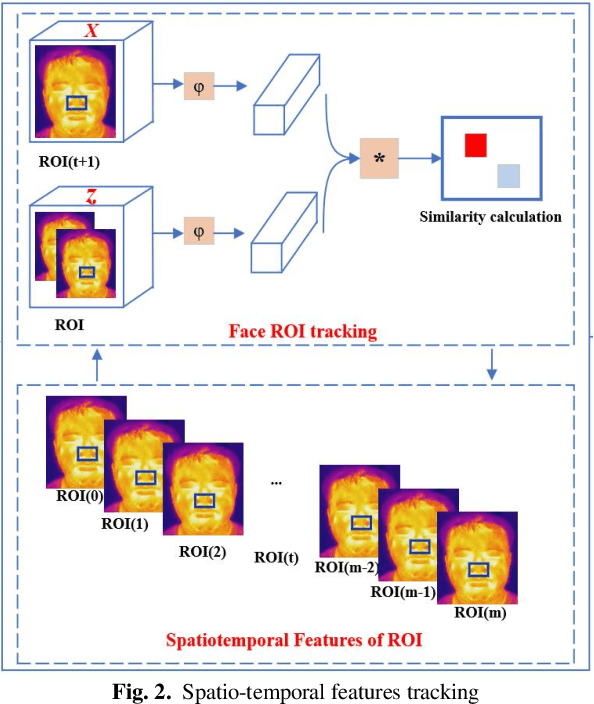
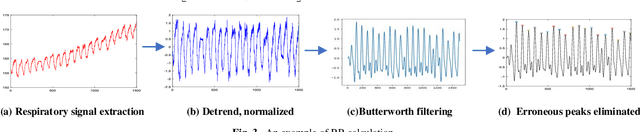
Deep learning technology has been widely used in edge computing. However, pandemics like covid-19 require deep learning capabilities at mobile devices (detect respiratory rate using mobile robotics or conduct CT scan using a mobile scanner), which are severely constrained by the limited storage and computation resources at the device level. To solve this problem, we propose a three-tier architecture, including robot layers, edge layers, and cloud layers. We adopt this architecture to design a non-contact respiratory monitoring system to break down respiratory rate calculation tasks. Experimental results of respiratory rate monitoring show that the proposed approach in this paper significantly outperforms other approaches. It is supported by computation time costs with 2.26 ms per frame, 27.48 ms per frame, 0.78 seconds for convolution operation, similarity calculation, processing one-minute length respiratory signals, respectively. And the computation time costs of our three-tier architecture are less than that of edge+cloud architecture and cloud architecture. Moreover, we use our three-tire architecture for CT image diagnosis task decomposition. The evaluation of a CT image dataset of COVID-19 proves that our three-tire architecture is useful for resolving tasks on deep learning networks by edge equipment. There are broad application scenarios in smart hospitals in the future.
The Invertible U-Net for Optical-Flow-free Video Interframe Generation
Mar 17, 2021
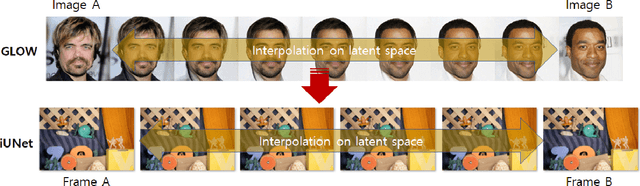
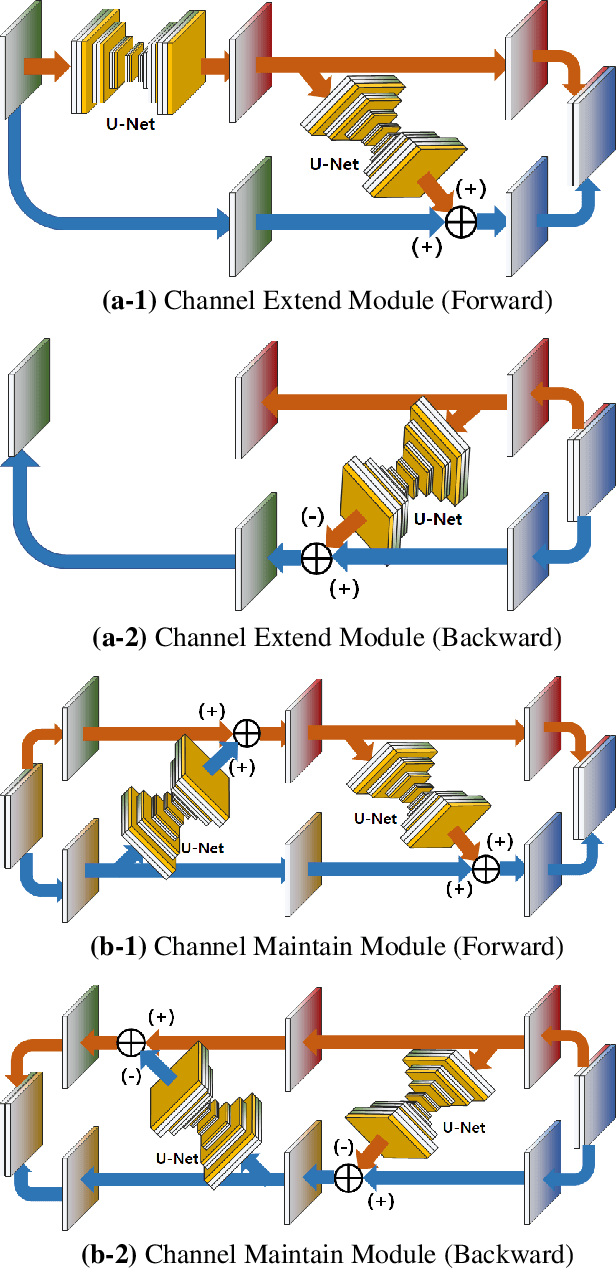
Video frame interpolation is the task of creating an interface between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow. To enable this, we have tried to use a deep neural network with an invertible structure and developed an invertible U-Net which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we confirmed the feasibility of the proposed algorithm and would like to suggest invertible U-Net as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the worlds first attempt to use invertible networks instead of optical flows for video interpolation.
RackLay: Multi-Layer Layout Estimation for Warehouse Racks
Mar 17, 2021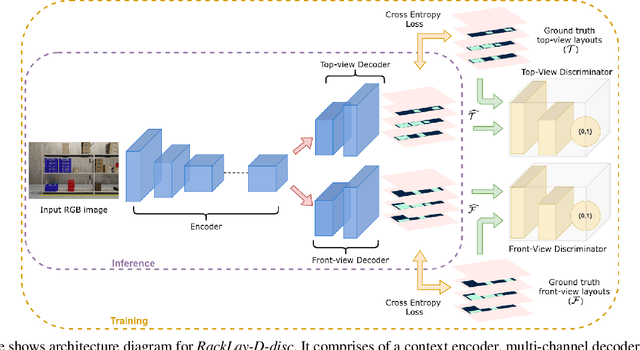

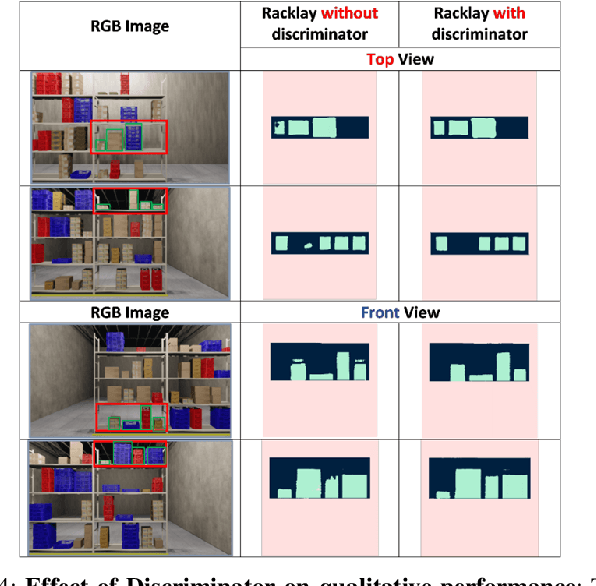

Given a monocular colour image of a warehouse rack, we aim to predict the bird's-eye view layout for each shelf in the rack, which we term as multi-layer layout prediction. To this end, we present RackLay, a deep neural network for real-time shelf layout estimation from a single image. Unlike previous layout estimation methods, which provide a single layout for the dominant ground plane alone, RackLay estimates the top-view and front-view layout for each shelf in the considered rack populated with objects. RackLay's architecture and its variants are versatile and estimate accurate layouts for diverse scenes characterized by varying number of visible shelves in an image, large range in shelf occupancy factor and varied background clutter. Given the extreme paucity of datasets in this space and the difficulty involved in acquiring real data from warehouses, we additionally release a flexible synthetic dataset generation pipeline WareSynth which allows users to control the generation process and tailor the dataset according to contingent application. The ablations across architectural variants and comparison with strong prior baselines vindicate the efficacy of RackLay as an apt architecture for the novel problem of multi-layered layout estimation. We also show that fusing the top-view and front-view enables 3D reasoning applications such as metric free space estimation for the considered rack.