 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multitarget Tracking with Transformers
Apr 01, 2021
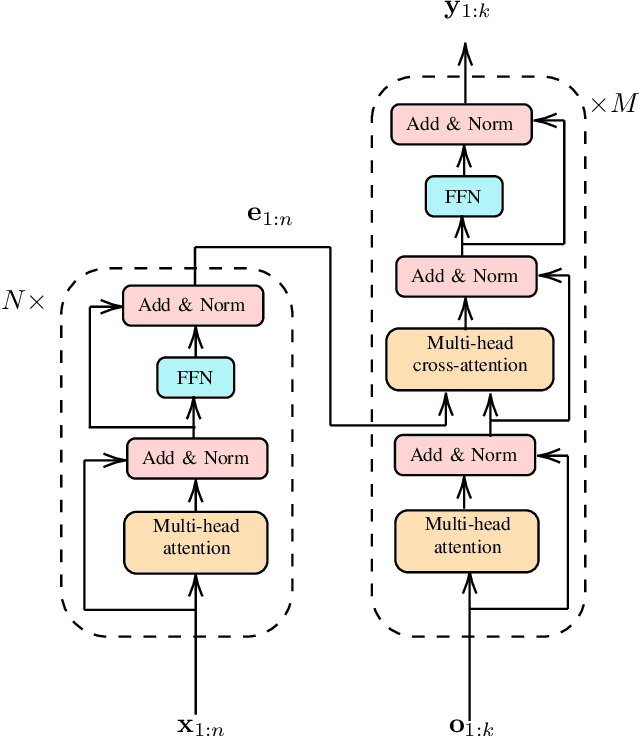
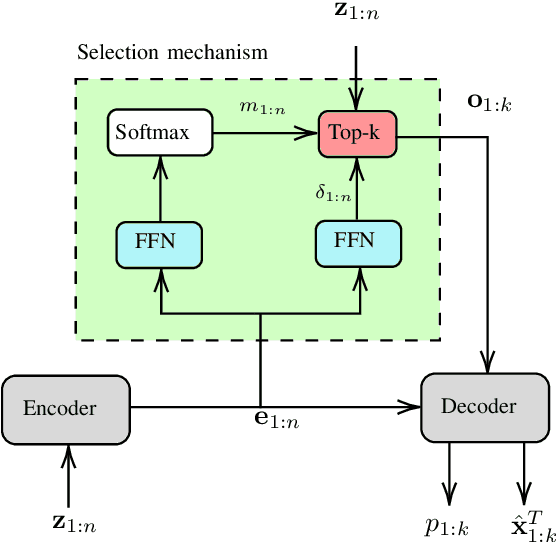
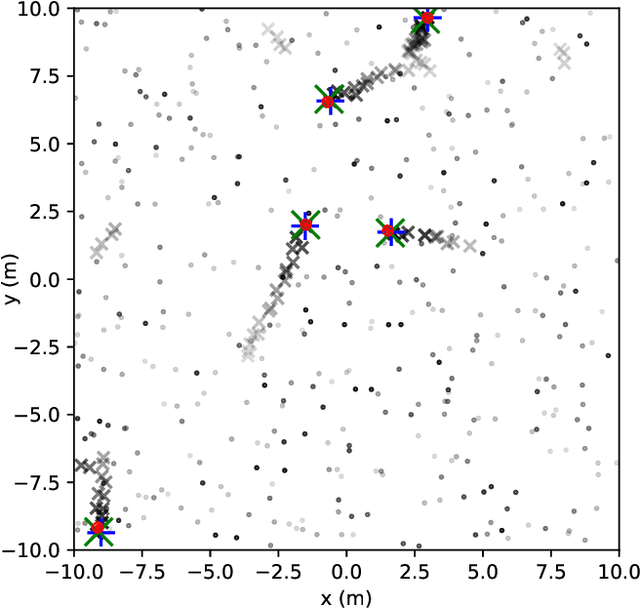
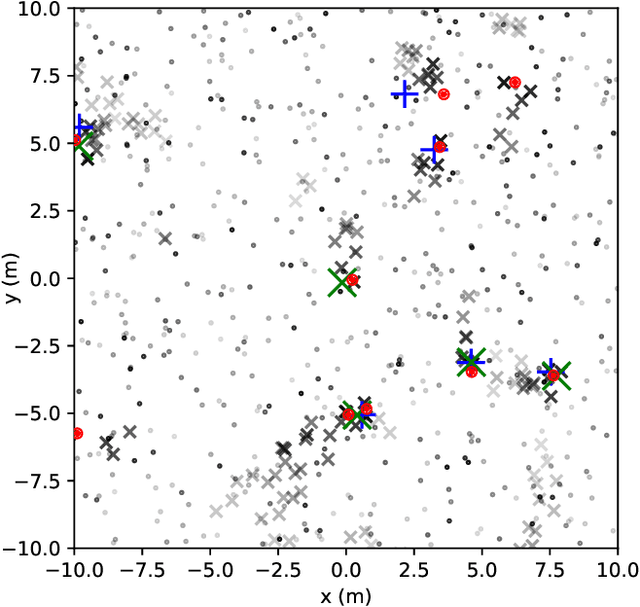
Multitarget Tracking (MTT) is the problem of tracking the states of an unknown number of objects using noisy measurements, with important applications to autonomous driving, surveillance, robotics, and others. In the model-based Bayesian setting, there are conjugate priors that enable us to express the multi-object posterior in closed form, which could theoretically provide Bayes-optimal estimates. However, the posterior involves a super-exponential growth of the number of hypotheses over time, forcing state-of-the-art methods to resort to approximations for remaining tractable, which can impact their performance in complex scenarios. Model-free methods based on deep-learning provide an attractive alternative, as they can in principle learn the optimal filter from data, but to the best of our knowledge were never compared to current state-of-the-art Bayesian filters, specially not in contexts where accurate models are available. In this paper, we propose a high-performing deep-learning method for MTT based on the Transformer architecture and compare it to two state-of-the-art Bayesian filters, in a setting where we assume the correct model is provided. Although this gives an edge to the model-based filters, it also allows us to generate unlimited training data. We show that the proposed model outperforms state-of-the-art Bayesian filters in complex scenarios, while macthing their performance in simpler cases, which validates the applicability of deep-learning also in the model-based regime. The code for all our implementations is made available at (github link to be provided).
Universal Approximation Theorems of Fully Connected Binarized Neural Networks
Feb 04, 2021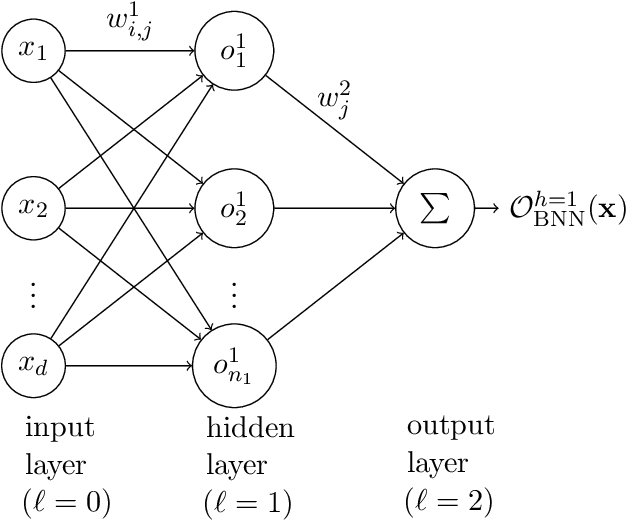

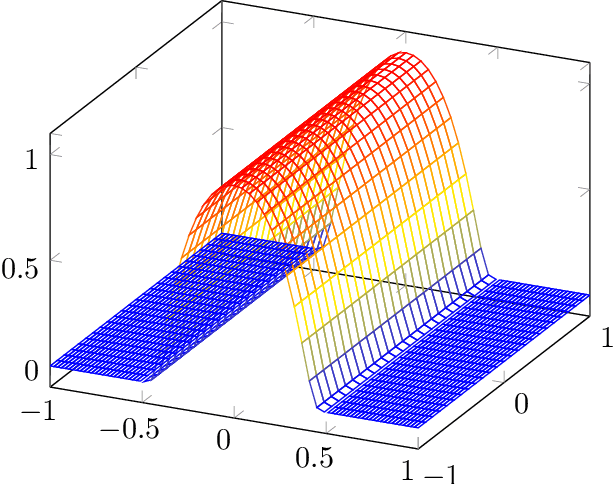
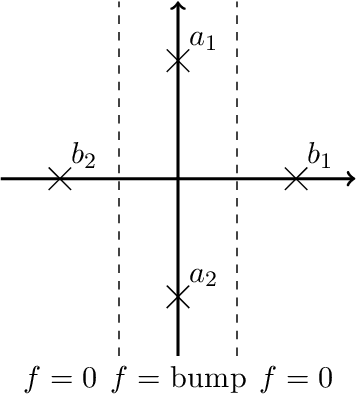
Neural networks (NNs) are known for their high predictive accuracy in complex learning problems. Beside practical advantages, NNs also indicate favourable theoretical properties such as universal approximation (UA) theorems. Binarized Neural Networks (BNNs) significantly reduce time and memory demands by restricting the weight and activation domains to two values. Despite the practical advantages, theoretical guarantees based on UA theorems of BNNs are rather sparse in the literature. We close this gap by providing UA theorems for fully connected BNNs under the following scenarios: (1) for binarized inputs, UA can be constructively achieved under one hidden layer; (2) for inputs with real numbers, UA can not be achieved under one hidden layer but can be constructively achieved under two hidden layers for Lipschitz-continuous functions. Our results indicate that fully connected BNNs can approximate functions universally, under certain conditions.
Sublinear classical and quantum algorithms for general matrix games
Dec 11, 2020
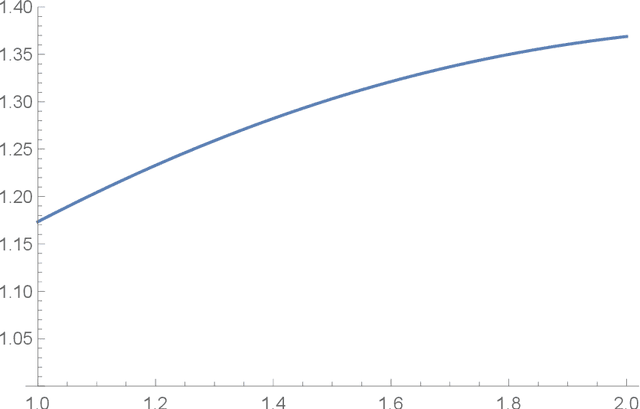
We investigate sublinear classical and quantum algorithms for matrix games, a fundamental problem in optimization and machine learning, with provable guarantees. Given a matrix $A\in\mathbb{R}^{n\times d}$, sublinear algorithms for the matrix game $\min_{x\in\mathcal{X}}\max_{y\in\mathcal{Y}} y^{\top} Ax$ were previously known only for two special cases: (1) $\mathcal{Y}$ being the $\ell_{1}$-norm unit ball, and (2) $\mathcal{X}$ being either the $\ell_{1}$- or the $\ell_{2}$-norm unit ball. We give a sublinear classical algorithm that can interpolate smoothly between these two cases: for any fixed $q\in (1,2]$, we solve the matrix game where $\mathcal{X}$ is a $\ell_{q}$-norm unit ball within additive error $\epsilon$ in time $\tilde{O}((n+d)/{\epsilon^{2}})$. We also provide a corresponding sublinear quantum algorithm that solves the same task in time $\tilde{O}((\sqrt{n}+\sqrt{d})\textrm{poly}(1/\epsilon))$ with a quadratic improvement in both $n$ and $d$. Both our classical and quantum algorithms are optimal in the dimension parameters $n$ and $d$ up to poly-logarithmic factors. Finally, we propose sublinear classical and quantum algorithms for the approximate Carath\'eodory problem and the $\ell_{q}$-margin support vector machines as applications.
Analysis of Nonstationary Time Series Using Locally Coupled Gaussian Processes
Oct 31, 2016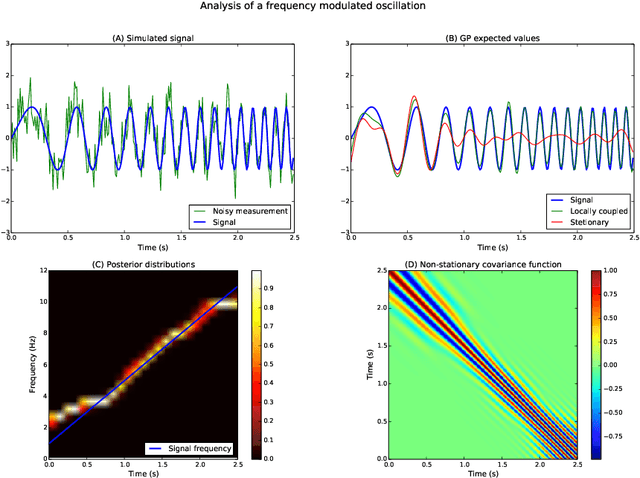
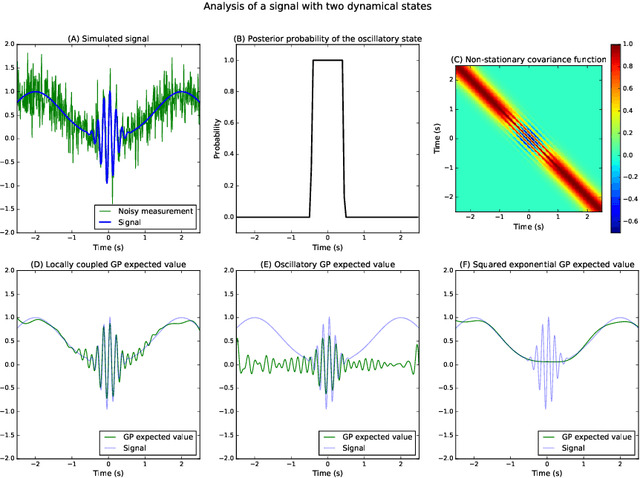
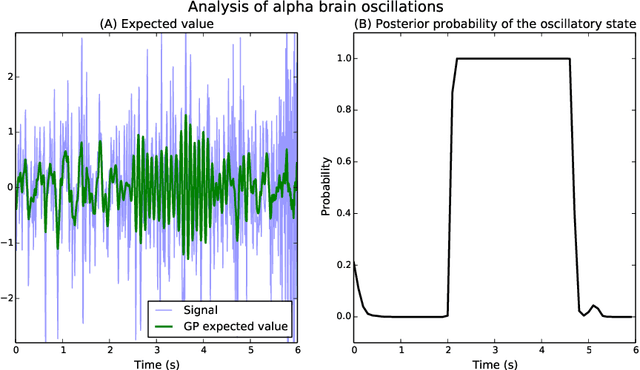
The analysis of nonstationary time series is of great importance in many scientific fields such as physics and neuroscience. In recent years, Gaussian process regression has attracted substantial attention as a robust and powerful method for analyzing time series. In this paper, we introduce a new framework for analyzing nonstationary time series using locally stationary Gaussian process analysis with parameters that are coupled through a hidden Markov model. The main advantage of this framework is that arbitrary complex nonstationary covariance functions can be obtained by combining simpler stationary building blocks whose hidden parameters can be estimated in closed-form. We demonstrate the flexibility of the method by analyzing two examples of synthetic nonstationary signals: oscillations with time varying frequency and time series with two dynamical states. Finally, we report an example application on real magnetoencephalographic measurements of brain activity.
Searching by Generating: Flexible and Efficient One-Shot NAS with Architecture Generator
Mar 12, 2021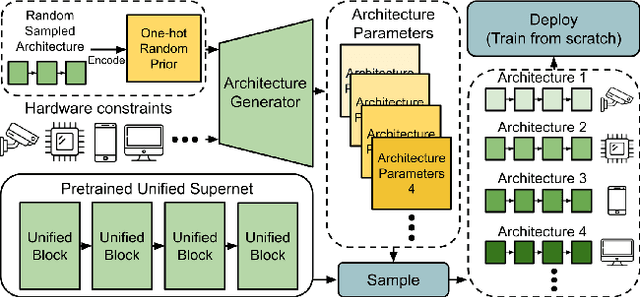

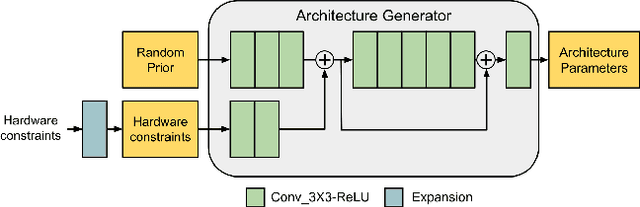
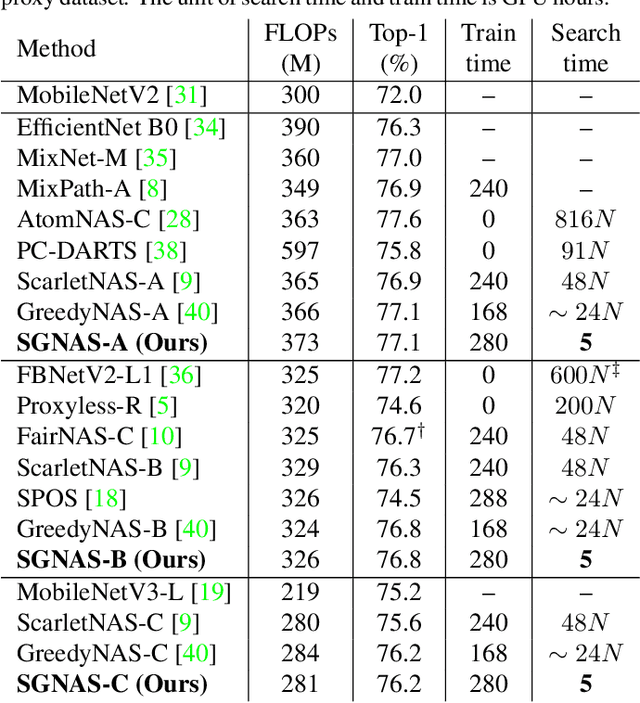
In one-shot NAS, sub-networks need to be searched from the supernet to meet different hardware constraints. However, the search cost is high and $N$ times of searches are needed for $N$ different constraints. In this work, we propose a novel search strategy called architecture generator to search sub-networks by generating them, so that the search process can be much more efficient and flexible. With the trained architecture generator, given target hardware constraints as the input, $N$ good architectures can be generated for $N$ constraints by just one forward pass without re-searching and supernet retraining. Moreover, we propose a novel single-path supernet, called unified supernet, to further improve search efficiency and reduce GPU memory consumption of the architecture generator. With the architecture generator and the unified supernet, we propose a flexible and efficient one-shot NAS framework, called Searching by Generating NAS (SGNAS). With the pre-trained supernt, the search time of SGNAS for $N$ different hardware constraints is only 5 GPU hours, which is $4N$ times faster than previous SOTA single-path methods. After training from scratch, the top1-accuracy of SGNAS on ImageNet is 77.1%, which is comparable with the SOTAs. The code is available at: https://github.com/eric8607242/SGNAS.
Real-time data-driven detection of the rock type alteration during a directional drilling
Mar 27, 2019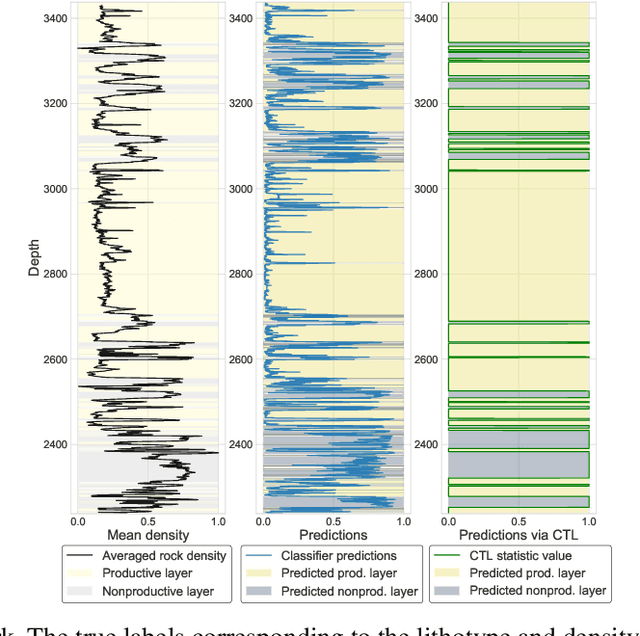
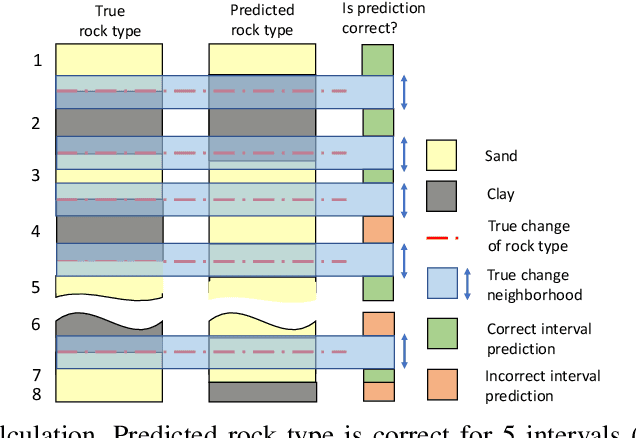
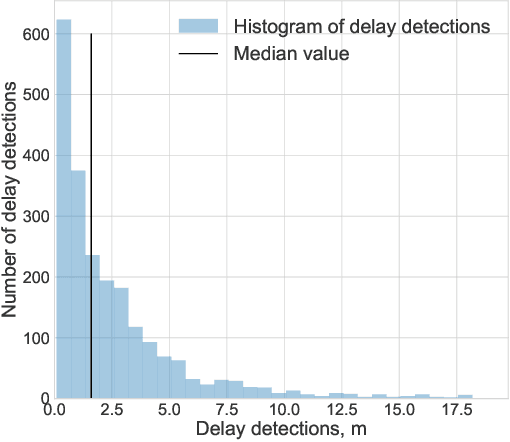
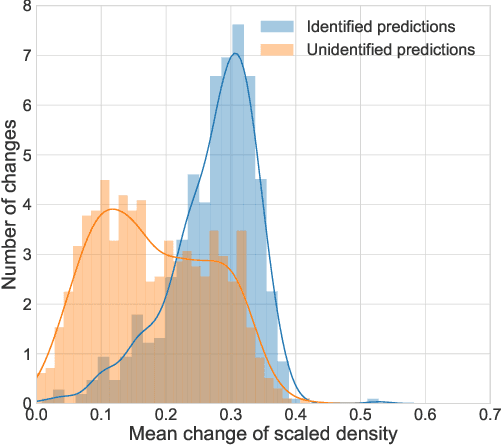
During the directional drilling, a bit may sometimes go to a nonproductive rock layer due to the gap about 20 m between the bit and high-fidelity rock type sensors. The only way to detect the lithotype changes in time is the usage of Measurements While Drilling (MWD) data. However, there are no mathematical modeling approaches that reconstruct the rock type based on MWD data with high accuracy. In this article, we present a data-driven procedure that utilizes MWD data for quick detection of changes in rock type. We propose the approach that combines traditional machine learning based on the solution of the rock type classification problem with change detection procedures rarely used before in Oil & Gas industry. The data come from a newly developed oilfield in the North of Western Siberia. The results suggest that we can detect a significant part of changes in rock type reducing the change detection delay from 20 to 2.6 m and the number of false positive alarms from 71 to 7 per well.
Domain Adaptation on Semantic Segmentation for Aerial Images
Dec 11, 2020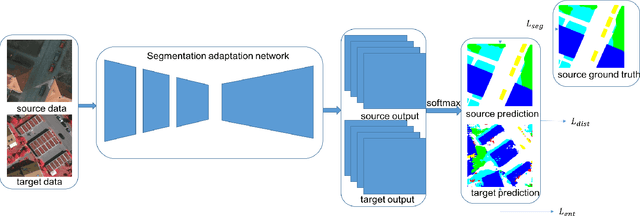
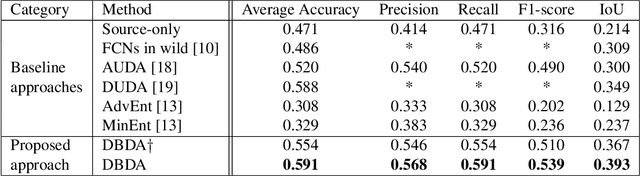

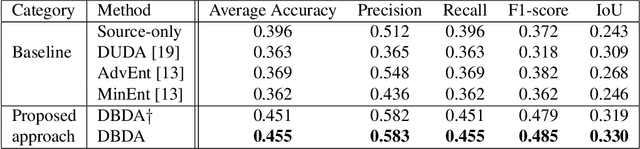
Semantic segmentation has achieved significant advances in recent years. While deep neural networks perform semantic segmentation well, their success rely on pixel level supervision which is expensive and time-consuming. Further, training using data from one domain may not generalize well to data from a new domain due to a domain gap between data distributions in the different domains. This domain gap is particularly evident in aerial images where visual appearance depends on the type of environment imaged, season, weather, and time of day when the environment is imaged. Subsequently, this distribution gap leads to severe accuracy loss when using a pretrained segmentation model to analyze new data with different characteristics. In this paper, we propose a novel unsupervised domain adaptation framework to address domain shift in the context of aerial semantic image segmentation. To this end, we solve the problem of domain shift by learn the soft label distribution difference between the source and target domains. Further, we also apply entropy minimization on the target domain to produce high-confident prediction rather than using high-confident prediction by pseudo-labeling. We demonstrate the effectiveness of our domain adaptation framework using the challenge image segmentation dataset of ISPRS, and show improvement over state-of-the-art methods in terms of various metrics.
An Online Multilingual Hate speech Recognition System
Nov 23, 2020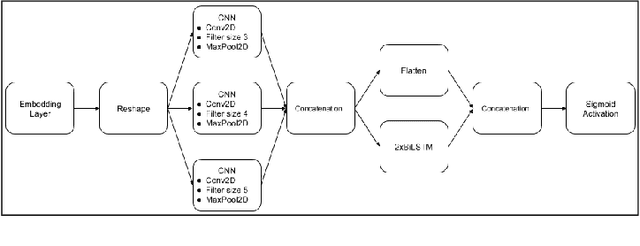
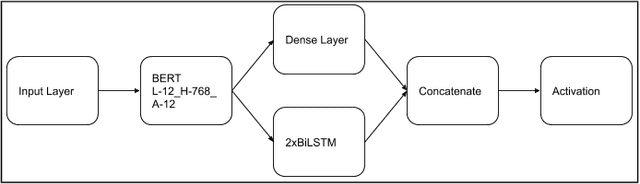

The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
Error-driven Pruning of Language Models for Virtual Assistants
Feb 14, 2021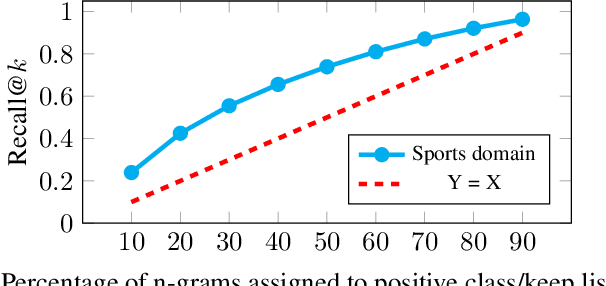
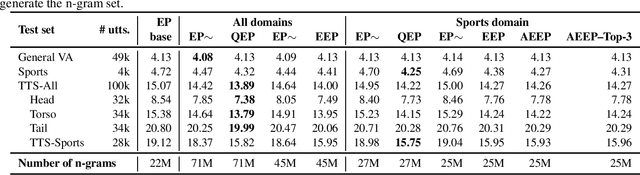
Language models (LMs) for virtual assistants (VAs) are typically trained on large amounts of data, resulting in prohibitively large models which require excessive memory and/or cannot be used to serve user requests in real-time. Entropy pruning results in smaller models but with significant degradation of effectiveness in the tail of the user request distribution. We customize entropy pruning by allowing for a keep list of infrequent n-grams that require a more relaxed pruning threshold, and propose three methods to construct the keep list. Each method has its own advantages and disadvantages with respect to LM size, ASR accuracy and cost of constructing the keep list. Our best LM gives 8% average Word Error Rate (WER) reduction on a targeted test set, but is 3 times larger than the baseline. We also propose discriminative methods to reduce the size of the LM while retaining the majority of the WER gains achieved by the largest LM.
Learning Whole-Slide Segmentation from Inexact and Incomplete Labels using Tissue Graphs
Mar 04, 2021Segmenting histology images into diagnostically relevant regions is imperative to support timely and reliable decisions by pathologists. To this end, computer-aided techniques have been proposed to delineate relevant regions in scanned histology slides. However, the techniques necessitate task-specific large datasets of annotated pixels, which is tedious, time-consuming, expensive, and infeasible to acquire for many histology tasks. Thus, weakly-supervised semantic segmentation techniques are proposed to utilize weak supervision that is cheaper and quicker to acquire. In this paper, we propose SegGini, a weakly supervised segmentation method using graphs, that can utilize weak multiplex annotations, i.e. inexact and incomplete annotations, to segment arbitrary and large images, scaling from tissue microarray (TMA) to whole slide image (WSI). Formally, SegGini constructs a tissue-graph representation for an input histology image, where the graph nodes depict tissue regions. Then, it performs weakly-supervised segmentation via node classification by using inexact image-level labels, incomplete scribbles, or both. We evaluated SegGini on two public prostate cancer datasets containing TMAs and WSIs. Our method achieved state-of-the-art segmentation performance on both datasets for various annotation settings while being comparable to a pathologist baseline.