 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Copula Transport for Clustering Multivariate Time Series
Jan 11, 2016
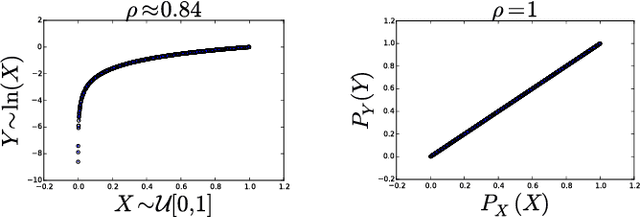
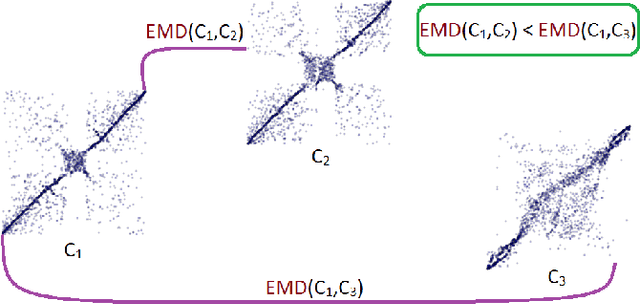
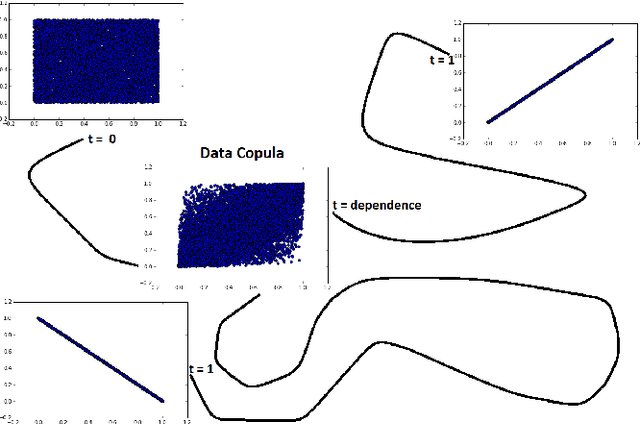
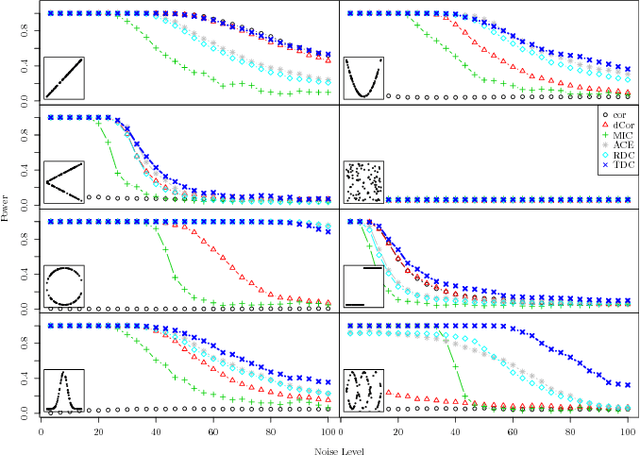
This paper presents a new methodology for clustering multivariate time series leveraging optimal transport between copulas. Copulas are used to encode both (i) intra-dependence of a multivariate time series, and (ii) inter-dependence between two time series. Then, optimal copula transport allows us to define two distances between multivariate time series: (i) one for measuring intra-dependence dissimilarity, (ii) another one for measuring inter-dependence dissimilarity based on a new multivariate dependence coefficient which is robust to noise, deterministic, and which can target specified dependencies.
Massive Access in Media Modulation Based Massive Machine-Type Communications
Apr 08, 2021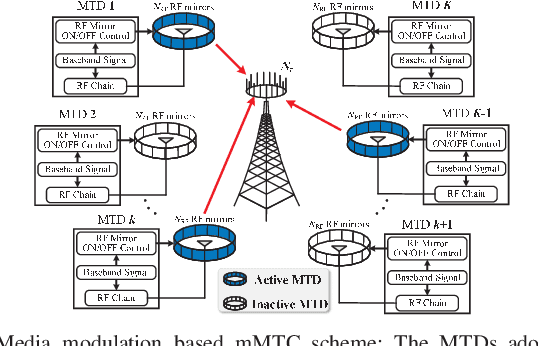
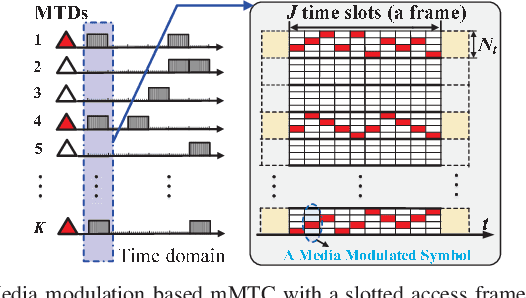
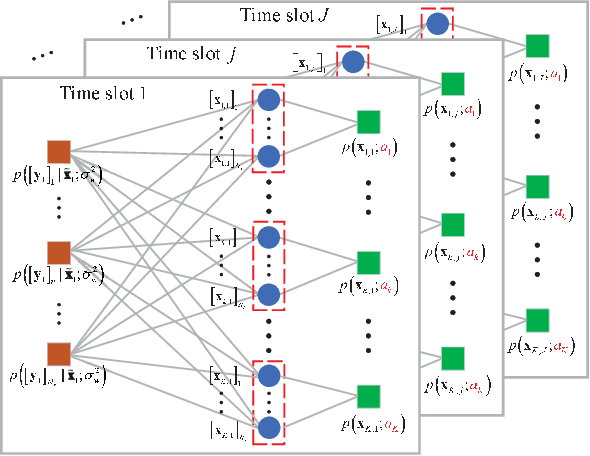
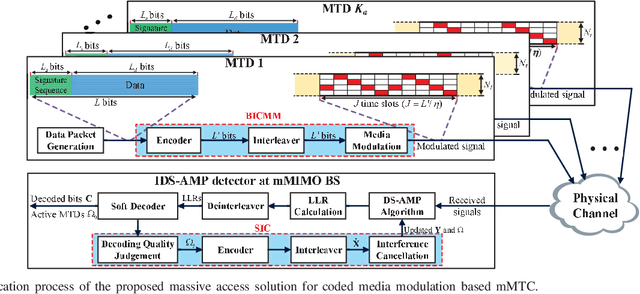
The massive machine-type communications (mMTC) paradigm based on media modulation in conjunction with massive MIMO base stations (BSs) is emerging as a viable solution to support the massive connectivity for the future Internet-of-Things, in which the inherent massive access at the BSs poses significant challenges for device activity and data detection (DADD). This paper considers the DADD problem for both uncoded and coded media modulation based mMTC with a slotted access frame structure, where the device activity remains unchanged within one frame. Specifically, due to the slotted access frame structure and the adopted media modulated symbols, the access signals exhibit a doubly structured sparsity in both the time domain and the modulation domain. Inspired by this, a doubly structured approximate message passing (DS-AMP) algorithm is proposed for reliable DADD in the uncoded case. Also, we derive the state evolution of the DS-AMP algorithm to theoretically characterize its performance. As for the coded case, we develop a bit-interleaved coded media modulation scheme and propose an iterative DS-AMP (IDS-AMP) algorithm based on successive inference cancellation (SIC), where the signal components associated with the detected active devices are successively subtracted to improve the data decoding performance. In addition, the channel estimation problem for media modulation based mMTC is discussed and an efficient data-aided channel state information (CSI) update strategy is developed to reduce the training overhead in block fading channels. Finally, simulation results and computational complexity analysis verify the superiority of the proposed algorithms in both uncoded and coded cases. Also, our results verify the validity of the proposed data-aided CSI update strategy.
A Termination Criterion for Probabilistic PointClouds Registration
Oct 10, 2020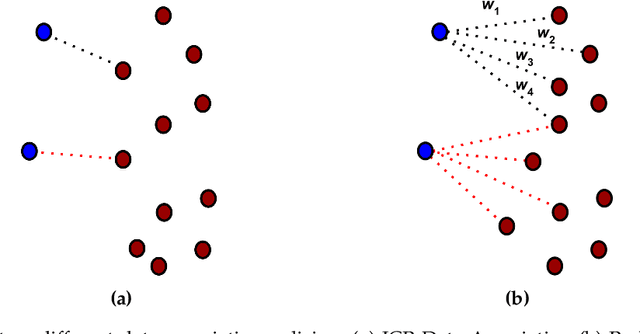
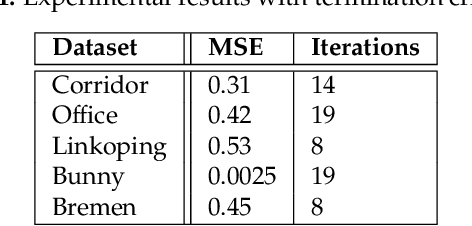
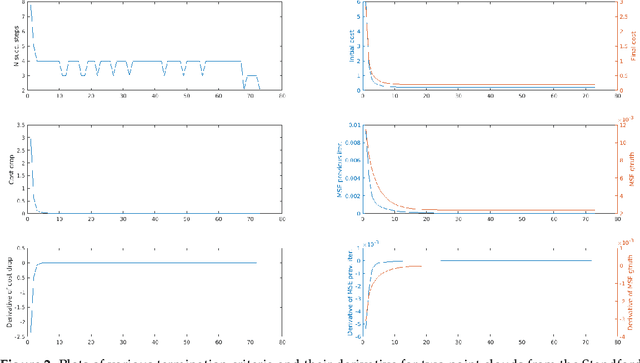
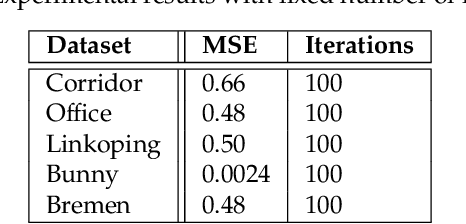
Probabilistic Point Clouds Registration (PPCR) is an algorithm that, in its multi-iteration version, outperformed state of the art algorithms for local point clouds registration. However, its performances have been tested using a fixed high number of iterations. To be of practical usefulness, we think that the algorithm should decide by itself when to stop, to avoid an excessive number of iterations and, therefore, wasting computational time. With this work, we compare different termination criterion on several datasets and prove that the chosen one produce very good results that are comparable to those obtained using a very high number of iterations while saving computational time.
On Riemannian Stochastic Approximation Schemes with Fixed Step-Size
Feb 15, 2021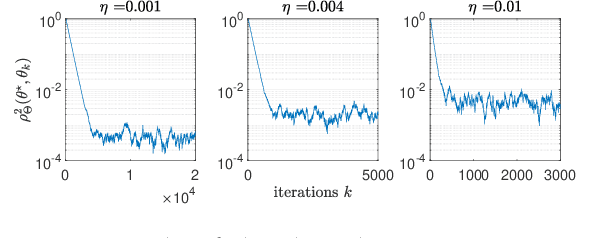
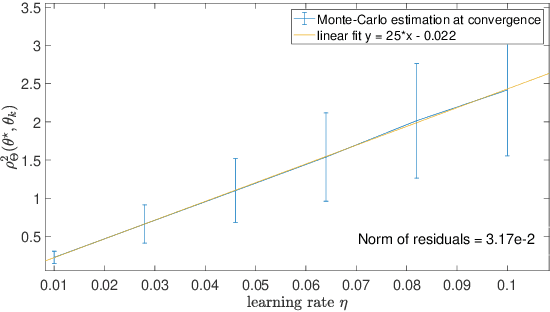
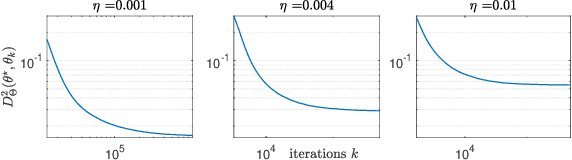
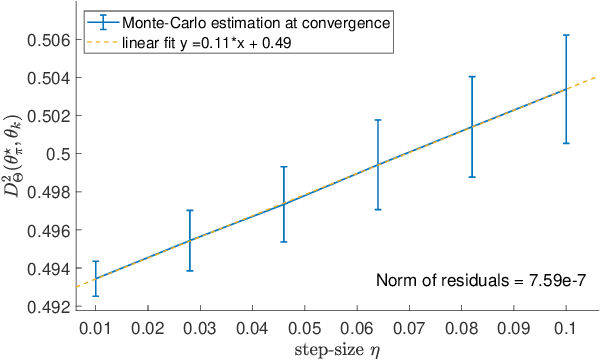
This paper studies fixed step-size stochastic approximation (SA) schemes, including stochastic gradient schemes, in a Riemannian framework. It is motivated by several applications, where geodesics can be computed explicitly, and their use accelerates crude Euclidean methods. A fixed step-size scheme defines a family of time-homogeneous Markov chains, parametrized by the step-size. Here, using this formulation, non-asymptotic performance bounds are derived, under Lyapunov conditions. Then, for any step-size, the corresponding Markov chain is proved to admit a unique stationary distribution, and to be geometrically ergodic. This result gives rise to a family of stationary distributions indexed by the step-size, which is further shown to converge to a Dirac measure, concentrated at the solution of the problem at hand, as the step-size goes to 0. Finally, the asymptotic rate of this convergence is established, through an asymptotic expansion of the bias, and a central limit theorem.
Improved Regret Bound and Experience Replay in Regularized Policy Iteration
Feb 25, 2021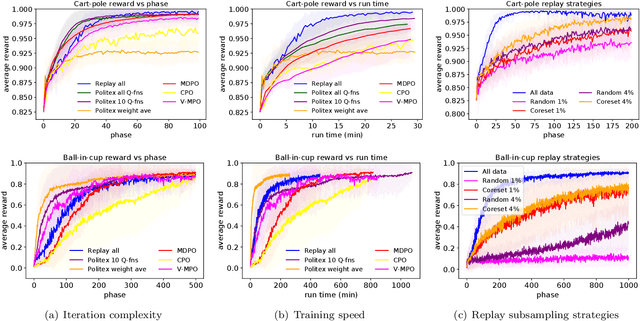
In this work, we study algorithms for learning in infinite-horizon undiscounted Markov decision processes (MDPs) with function approximation. We first show that the regret analysis of the Politex algorithm (a version of regularized policy iteration) can be sharpened from $O(T^{3/4})$ to $O(\sqrt{T})$ under nearly identical assumptions, and instantiate the bound with linear function approximation. Our result provides the first high-probability $O(\sqrt{T})$ regret bound for a computationally efficient algorithm in this setting. The exact implementation of Politex with neural network function approximation is inefficient in terms of memory and computation. Since our analysis suggests that we need to approximate the average of the action-value functions of past policies well, we propose a simple efficient implementation where we train a single Q-function on a replay buffer with past data. We show that this often leads to superior performance over other implementation choices, especially in terms of wall-clock time. Our work also provides a novel theoretical justification for using experience replay within policy iteration algorithms.
Regret Analysis of Distributed Gaussian Process Estimation and Coverage
Feb 05, 2021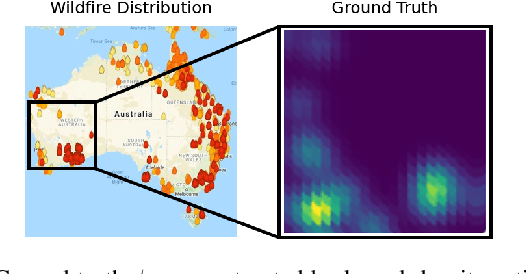
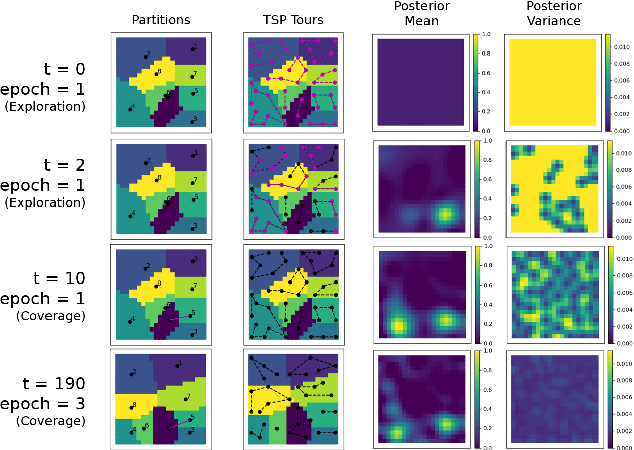
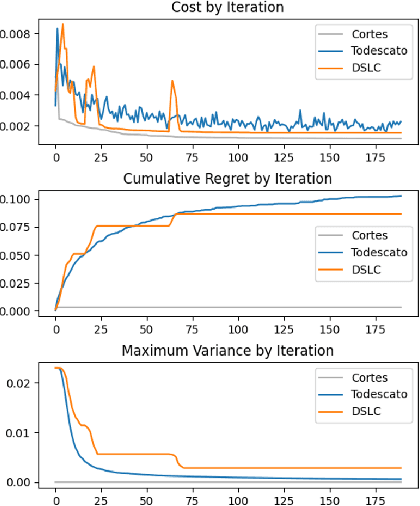
We study the problem of distributed multi-robot coverage over an unknown, nonuniform sensory field. Modeling the sensory field as a realization of a Gaussian Process and using Bayesian techniques, we devise a policy which aims to balance the tradeoff between learning the sensory function and covering the environment. We propose an adaptive coverage algorithm called Deterministic Sequencing of Learning and Coverage (DSLC) that schedules learning and coverage epochs such that its emphasis gradually shifts from exploration to exploitation while never fully ceasing to learn. Using a novel definition of coverage regret which characterizes overall coverage performance of a multi-robot team over a time horizon $T$, we analyze DSLC to provide an upper bound on expected cumulative coverage regret. Finally, we illustrate the empirical performance of the algorithm through simulations of the coverage task over an unknown distribution of wildfires.
Abstraction and Symbolic Execution of Deep Neural Networks with Bayesian Approximation of Hidden Features
Mar 05, 2021
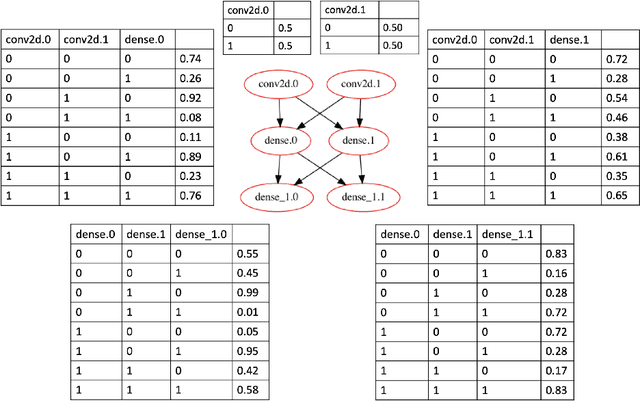
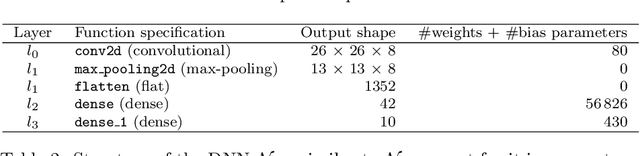
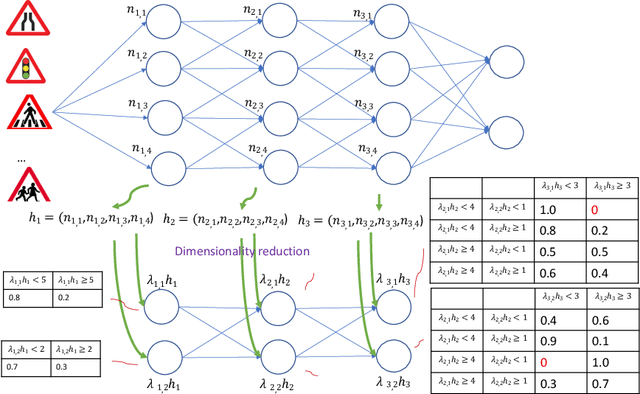
Intensive research has been conducted on the verification and validation of deep neural networks (DNNs), aiming to understand if, and how, DNNs can be applied to safety critical applications. However, existing verification and validation techniques are limited by their scalability, over both the size of the DNN and the size of the dataset. In this paper, we propose a novel abstraction method which abstracts a DNN and a dataset into a Bayesian network (BN). We make use of dimensionality reduction techniques to identify hidden features that have been learned by hidden layers of the DNN, and associate each hidden feature with a node of the BN. On this BN, we can conduct probabilistic inference to understand the behaviours of the DNN processing data. More importantly, we can derive a runtime monitoring approach to detect in operational time rare inputs and covariate shift of the input data. We can also adapt existing structural coverage-guided testing techniques (i.e., based on low-level elements of the DNN such as neurons), in order to generate test cases that better exercise hidden features. We implement and evaluate the BN abstraction technique using our DeepConcolic tool available at https://github.com/TrustAI/DeepConcolic.
Time Series Clustering via Community Detection in Networks
Aug 19, 2015
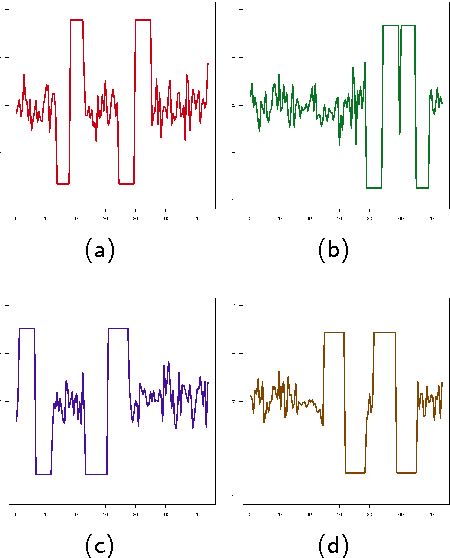
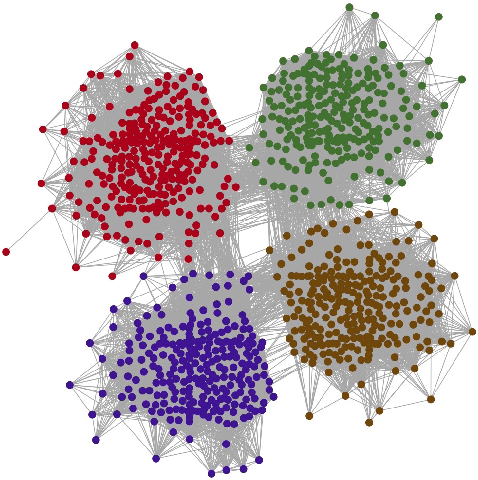
In this paper, we propose a technique for time series clustering using community detection in complex networks. Firstly, we present a method to transform a set of time series into a network using different distance functions, where each time series is represented by a vertex and the most similar ones are connected. Then, we apply community detection algorithms to identify groups of strongly connected vertices (called a community) and, consequently, identify time series clusters. Still in this paper, we make a comprehensive analysis on the influence of various combinations of time series distance functions, network generation methods and community detection techniques on clustering results. Experimental study shows that the proposed network-based approach achieves better results than various classic or up-to-date clustering techniques under consideration. Statistical tests confirm that the proposed method outperforms some classic clustering algorithms, such as $k$-medoids, diana, median-linkage and centroid-linkage in various data sets. Interestingly, the proposed method can effectively detect shape patterns presented in time series due to the topological structure of the underlying network constructed in the clustering process. At the same time, other techniques fail to identify such patterns. Moreover, the proposed method is robust enough to group time series presenting similar pattern but with time shifts and/or amplitude variations. In summary, the main point of the proposed method is the transformation of time series from time-space domain to topological domain. Therefore, we hope that our approach contributes not only for time series clustering, but also for general time series analysis tasks.
Annealed Flow Transport Monte Carlo
Feb 15, 2021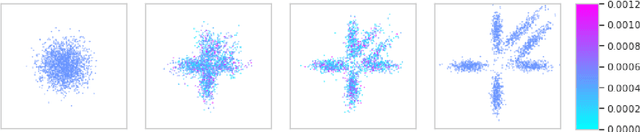
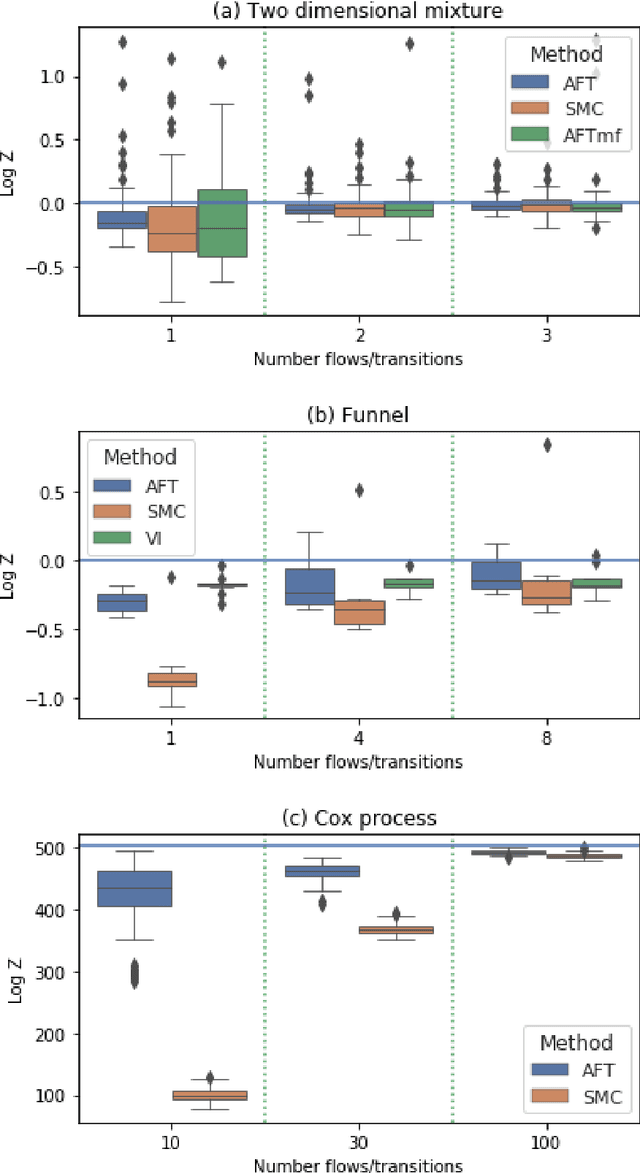
Annealed Importance Sampling (AIS) and its Sequential Monte Carlo (SMC) extensions are state-of-the-art methods for estimating normalizing constants of probability distributions. We propose here a novel Monte Carlo algorithm, Annealed Flow Transport (AFT), that builds upon AIS and SMC and combines them with normalizing flows (NF) for improved performance. This method transports a set of particles using not only importance sampling (IS), Markov chain Monte Carlo (MCMC) and resampling steps - as in SMC, but also relies on NF which are learned sequentially to push particles towards the successive annealed targets. We provide limit theorems for the resulting Monte Carlo estimates of the normalizing constant and expectations with respect to the target distribution. Additionally, we show that a continuous-time scaling limit of the population version of AFT is given by a Feynman--Kac measure which simplifies to the law of a controlled diffusion for expressive NF. We demonstrate experimentally the benefits and limitations of our methodology on a variety of applications.
Expressway visibility estimation based on image entropy and piecewise stationary time series analysis
Apr 08, 2018



Vision-based methods for visibility estimation can play a critical role in reducing traffic accidents caused by fog and haze. To overcome the disadvantages of current visibility estimation methods, we present a novel data-driven approach based on Gaussian image entropy and piecewise stationary time series analysis (SPEV). This is the first time that Gaussian image entropy is used for estimating atmospheric visibility. To lessen the impact of landscape and sunshine illuminance on visibility estimation, we used region of interest (ROI) analysis and took into account relative ratios of image entropy, to improve estimation accuracy. We assume fog and haze cause blurred images and that fog and haze can be considered as a piecewise stationary signal. We used piecewise stationary time series analysis to construct the piecewise causal relationship between image entropy and visibility. To obtain a real-world visibility measure during fog and haze, a subjective assessment was established through a study with 36 subjects who performed visibility observations. Finally, a total of two million videos were used for training the SPEV model and validate its effectiveness. The videos were collected from the constantly foggy and hazy Tongqi expressway in Jiangsu, China. The contrast model of visibility estimation was used for algorithm performance comparison, and the validation results of the SPEV model were encouraging as 99.14% of the relative errors were less than 10%.