 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Interpretable Visualization and Higher-Order Dimension Reduction for ECoG Data
Dec 12, 2020
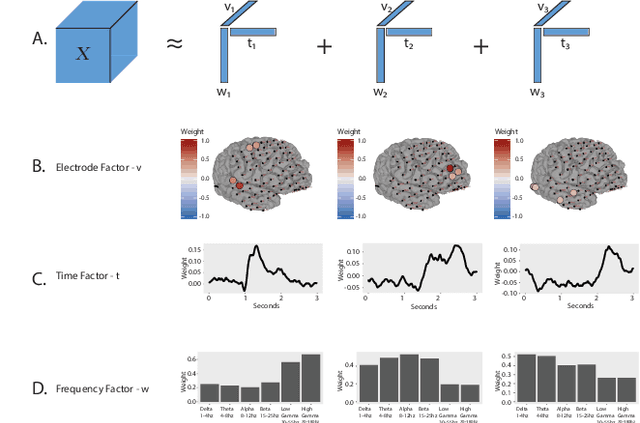
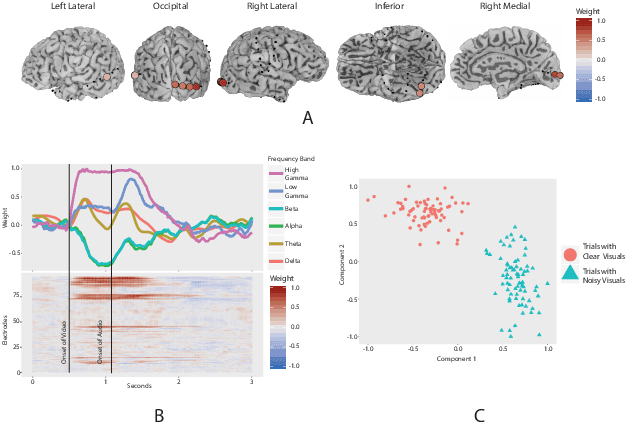
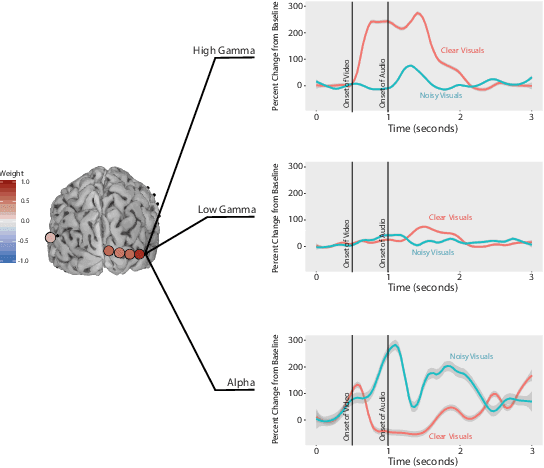
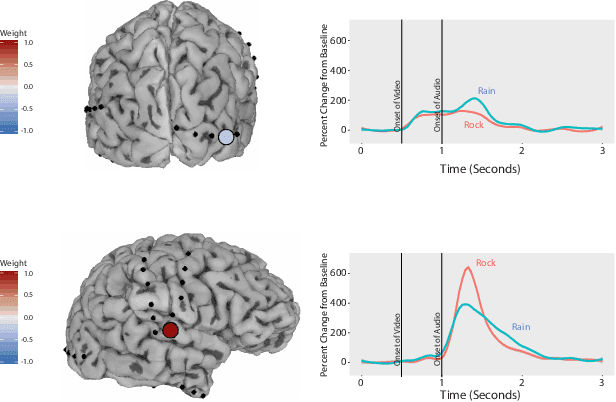
ElectroCOrticoGraphy (ECoG) technology measures electrical activity in the human brain via electrodes placed directly on the cortical surface during neurosurgery. Through its capability to record activity at a fast temporal resolution, ECoG experiments have allowed scientists to better understand how the human brain processes speech. By its nature, ECoG data is difficult for neuroscientists to directly interpret for two major reasons. Firstly, ECoG data tends to be large in size, as each individual experiment yields data up to several gigabytes. Secondly, ECoG data has a complex, higher-order nature. After signal processing, this type of data may be organized as a 4-way tensor with dimensions representing trials, electrodes, frequency, and time. In this paper, we develop an interpretable dimension reduction approach called Regularized Higher Order Principal Components Analysis, as well as an extension to Regularized Higher Order Partial Least Squares, that allows neuroscientists to explore and visualize ECoG data. Our approach employs a sparse and functional Candecomp-Parafac (CP) decomposition that incorporates sparsity to select relevant electrodes and frequency bands, as well as smoothness over time and frequency, yielding directly interpretable factors. We demonstrate the performance and interpretability of our method with an ECoG case study on audio and visual processing of human speech.
Path Signatures on Lie Groups
Jul 15, 2020
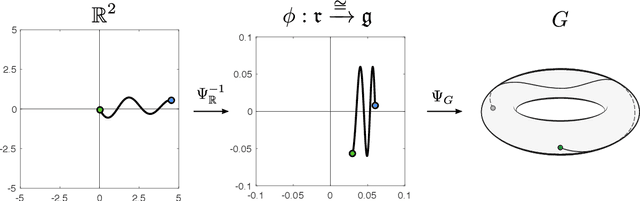
Path signatures are powerful nonparametric tools for time series analysis, shown to form a universal and characteristic feature map for Euclidean valued time series data. We lift the theory of path signatures to the setting of Lie group valued time series, adapting these tools for time series with underlying geometric constraints. We prove that this generalized path signature is universal and characteristic. To demonstrate universality, we analyze the human action recognition problem in computer vision, using $SO(3)$ representations for the time series, providing comparable performance to other shallow learning approaches, while offering an easily interpretable feature set. We also provide a two-sample hypothesis test for Lie group-valued random walks to illustrate its characteristic property. Finally we provide algorithms and a Julia implementation of these methods.
Decomposable Submodular Function Minimization via Maximum Flow
Mar 05, 2021This paper bridges discrete and continuous optimization approaches for decomposable submodular function minimization, in both the standard and parametric settings. We provide improved running times for this problem by reducing it to a number of calls to a maximum flow oracle. When each function in the decomposition acts on $O(1)$ elements of the ground set $V$ and is polynomially bounded, our running time is up to polylogarithmic factors equal to that of solving maximum flow in a sparse graph with $O(\vert V \vert)$ vertices and polynomial integral capacities. We achieve this by providing a simple iterative method which can optimize to high precision any convex function defined on the submodular base polytope, provided we can efficiently minimize it on the base polytope corresponding to the cut function of a certain graph that we construct. We solve this minimization problem by lifting the solutions of a parametric cut problem, which we obtain via a new efficient combinatorial reduction to maximum flow. This reduction is of independent interest and implies some previously unknown bounds for the parametric minimum $s,t$-cut problem in multiple settings.
A Topological Approach for Motion Track Discrimination
Feb 10, 2021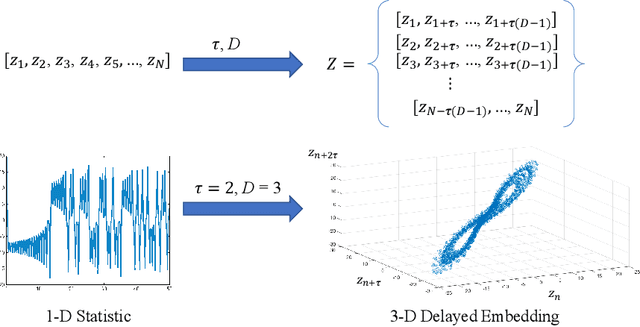
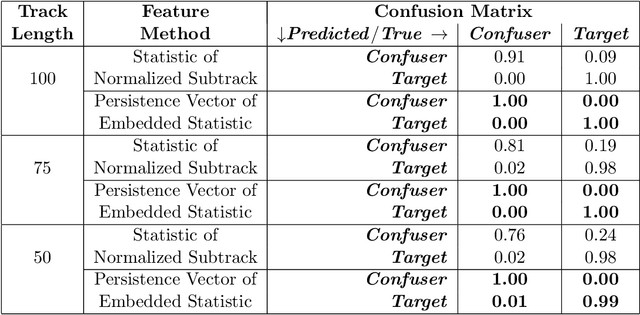
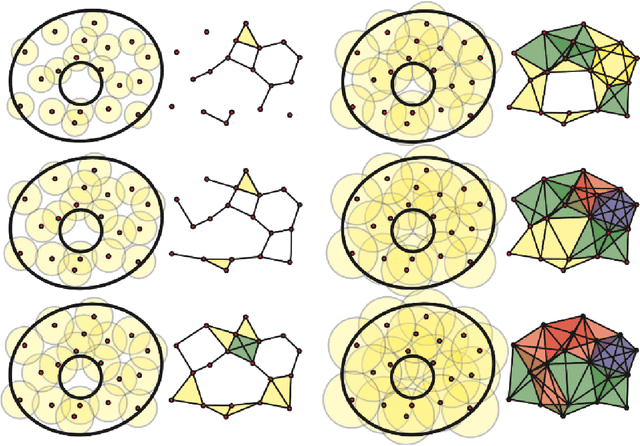
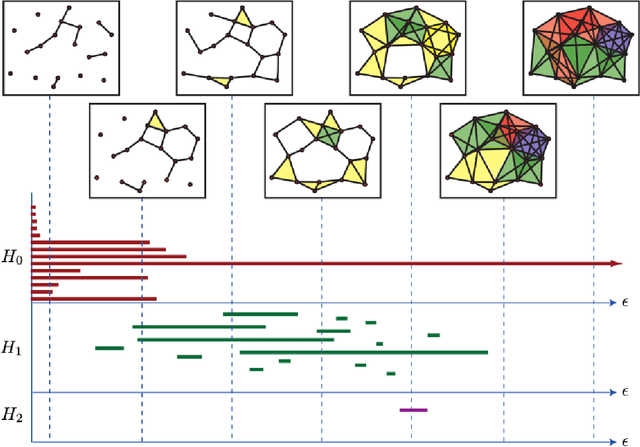
Detecting small targets at range is difficult because there is not enough spatial information present in an image sub-region containing the target to use correlation-based methods to differentiate it from dynamic confusers present in the scene. Moreover, this lack of spatial information also disqualifies the use of most state-of-the-art deep learning image-based classifiers. Here, we use characteristics of target tracks extracted from video sequences as data from which to derive distinguishing topological features that help robustly differentiate targets of interest from confusers. In particular, we calculate persistent homology from time-delayed embeddings of dynamic statistics calculated from motion tracks extracted from a wide field-of-view video stream. In short, we use topological methods to extract features related to target motion dynamics that are useful for classification and disambiguation and show that small targets can be detected at range with high probability.
When Bots Take Over the Stock Market: Evasion Attacks Against Algorithmic Traders
Oct 19, 2020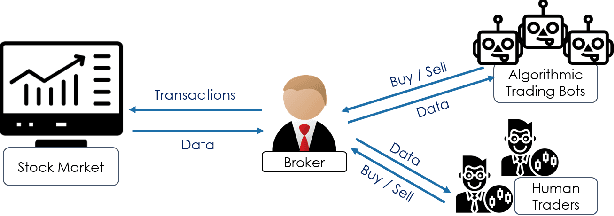
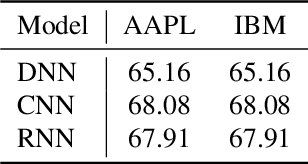
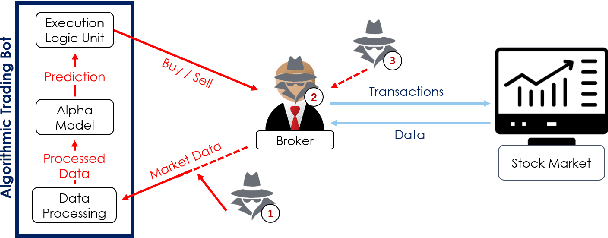
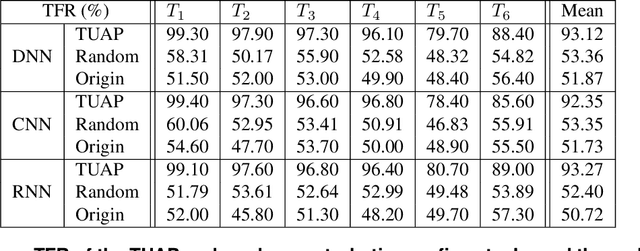
In recent years, machine learning has become prevalent in numerous tasks, including algorithmic trading. Stock market traders utilize learning models to predict the market's behavior and execute an investment strategy accordingly. However, learning models have been shown to be susceptible to input manipulations called adversarial examples. Yet, the trading domain remains largely unexplored in the context of adversarial learning. This is mainly because of the rapid changes in the market which impair the attacker's ability to create a real-time attack. In this study, we present a realistic scenario in which an attacker gains control of an algorithmic trading bots by manipulating the input data stream in real-time. The attacker creates an universal perturbation that is agnostic to the target model and time of use, while also remaining imperceptible. We evaluate our attack on a real-world market data stream and target three different trading architectures. We show that our perturbation can fool the model at future unseen data points, in both white-box and black-box settings. We believe these findings should serve as an alert to the finance community about the threats in this area and prompt further research on the risks associated with using automated learning models in the finance domain.
Contrastive Learning Improves Critical Event Prediction in COVID-19 Patients
Jan 11, 2021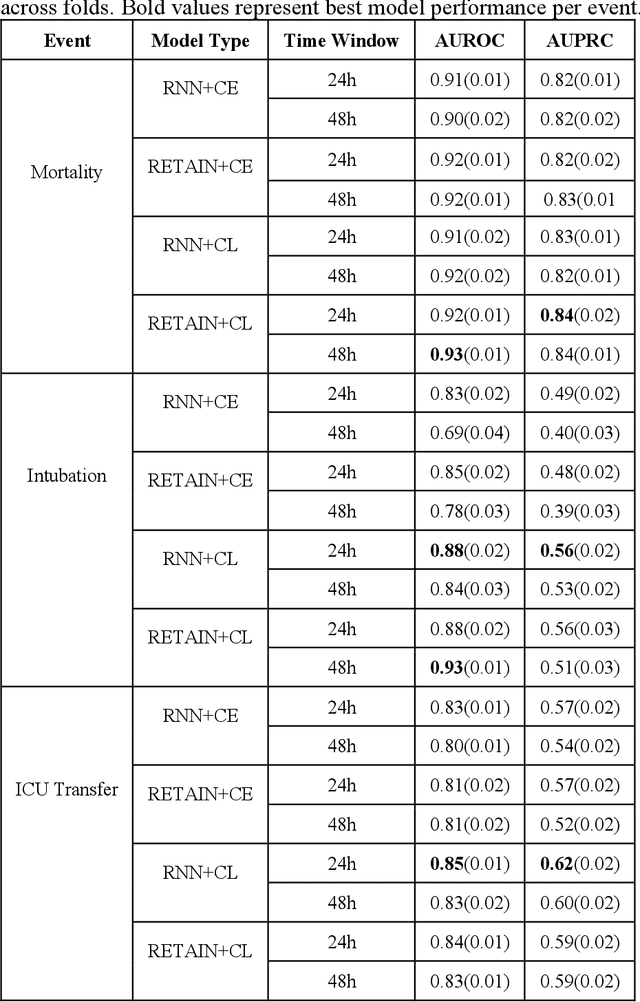
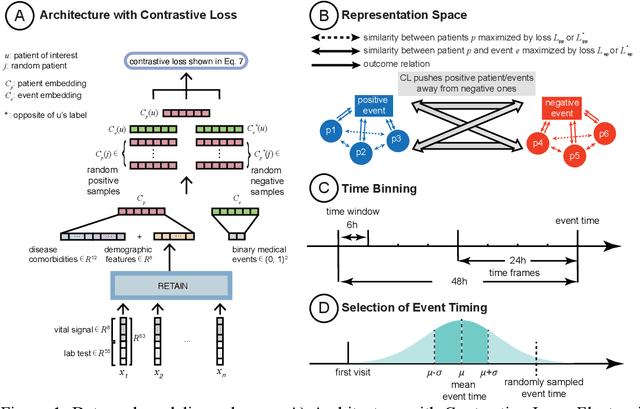
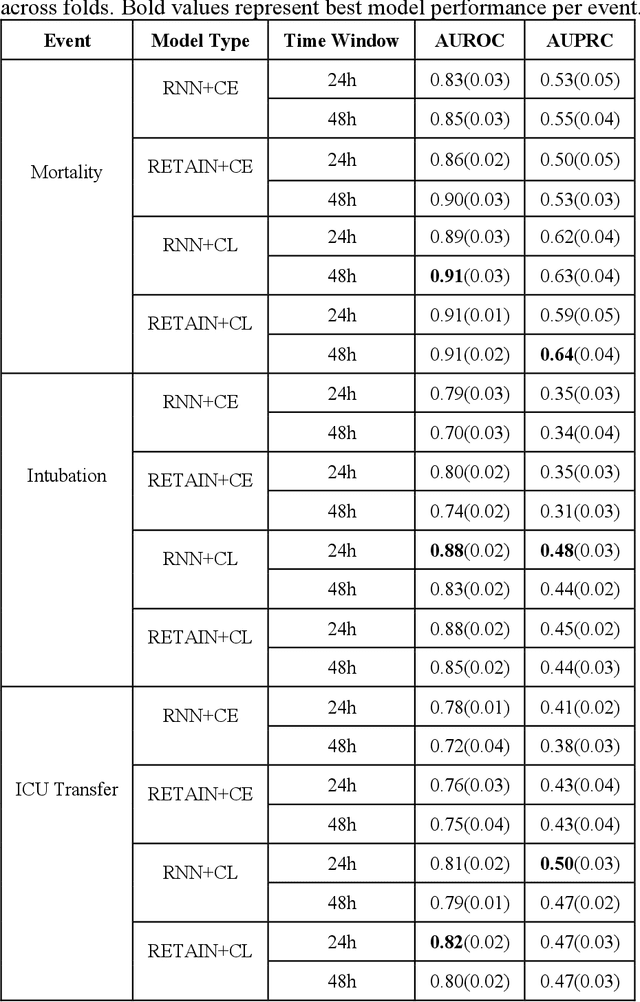
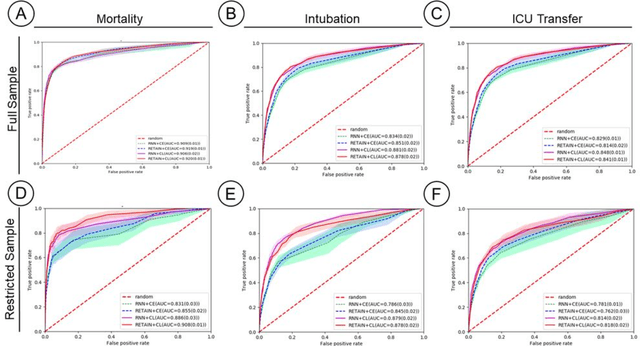
Machine Learning (ML) models typically require large-scale, balanced training data to be robust, generalizable, and effective in the context of healthcare. This has been a major issue for developing ML models for the coronavirus-disease 2019 (COVID-19) pandemic where data is highly imbalanced, particularly within electronic health records (EHR) research. Conventional approaches in ML use cross-entropy loss (CEL) that often suffers from poor margin classification. For the first time, we show that contrastive loss (CL) improves the performance of CEL especially for imbalanced EHR data and the related COVID-19 analyses. This study has been approved by the Institutional Review Board at the Icahn School of Medicine at Mount Sinai. We use EHR data from five hospitals within the Mount Sinai Health System (MSHS) to predict mortality, intubation, and intensive care unit (ICU) transfer in hospitalized COVID-19 patients over 24 and 48 hour time windows. We train two sequential architectures (RNN and RETAIN) using two loss functions (CEL and CL). Models are tested on full sample data set which contain all available data and restricted data set to emulate higher class imbalance.CL models consistently outperform CEL models with the restricted data set on these tasks with differences ranging from 0.04 to 0.15 for AUPRC and 0.05 to 0.1 for AUROC. For the restricted sample, only the CL model maintains proper clustering and is able to identify important features, such as pulse oximetry. CL outperforms CEL in instances of severe class imbalance, on three EHR outcomes with respect to three performance metrics: predictive power, clustering, and feature importance. We believe that the developed CL framework can be expanded and used for EHR ML work in general.
LAMP: Learning a Motion Policy to Repeatedly Navigate in an Uncertain Environment
Dec 03, 2020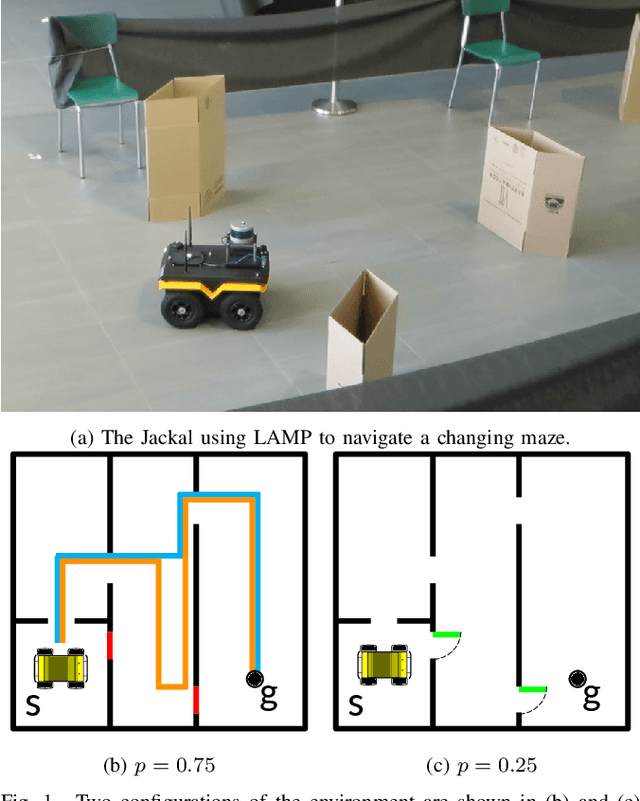
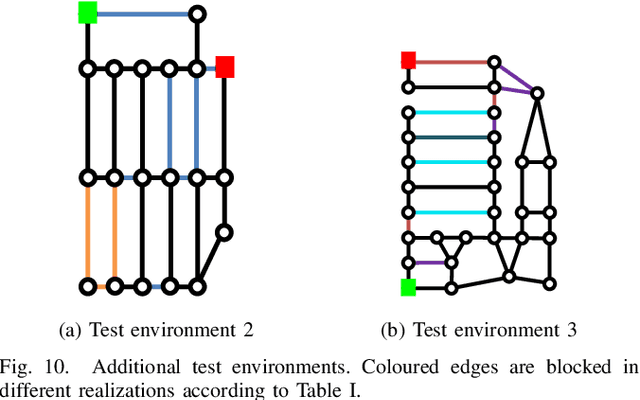
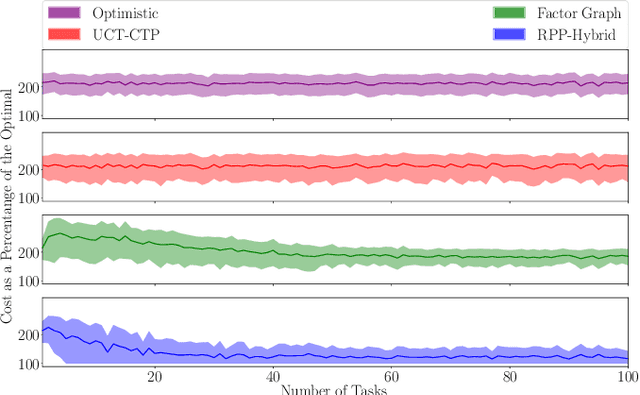
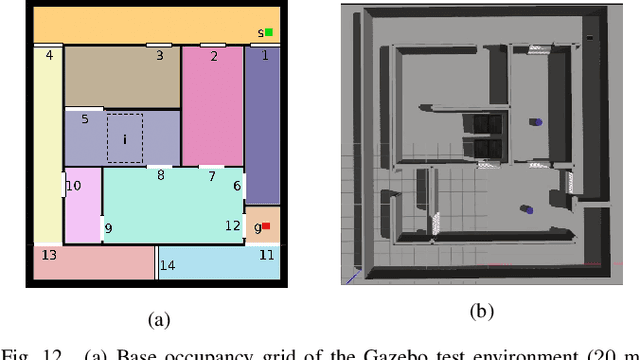
Mobile robots are often tasked with repeatedly navigating through an environment whose traversability changes over time. These changes may exhibit some hidden structure, which can be learned. Many studies consider reactive algorithms for online planning, however, these algorithms do not take advantage of the past executions of the navigation task for future tasks. In this paper, we formalize the problem of minimizing the total expected cost to perform multiple start-to-goal navigation tasks on a roadmap by introducing the Learned Reactive Planning Problem. We propose a method that captures information from past executions to learn a motion policy to handle obstacles that the robot has seen before. We propose the LAMP framework, which integrates the generated motion policy with an existing navigation stack. Finally, an extensive set of experiments in simulated and real-world environments show that the proposed method outperforms the state-of-the-art algorithms by 10% to 40% in terms of expected time to travel from start to goal. We also evaluate the robustness of the proposed method in the presence of localization and mapping errors on a real robot.
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 05, 2019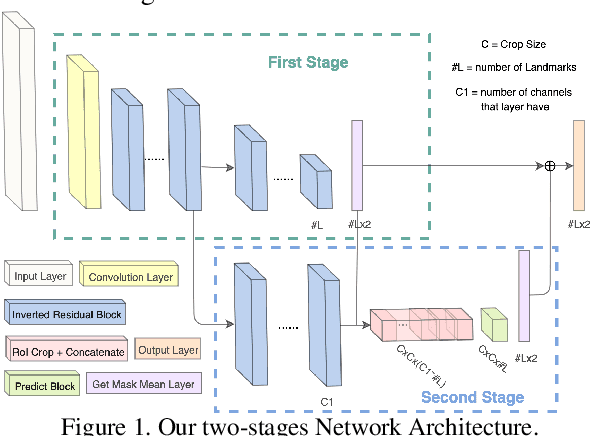

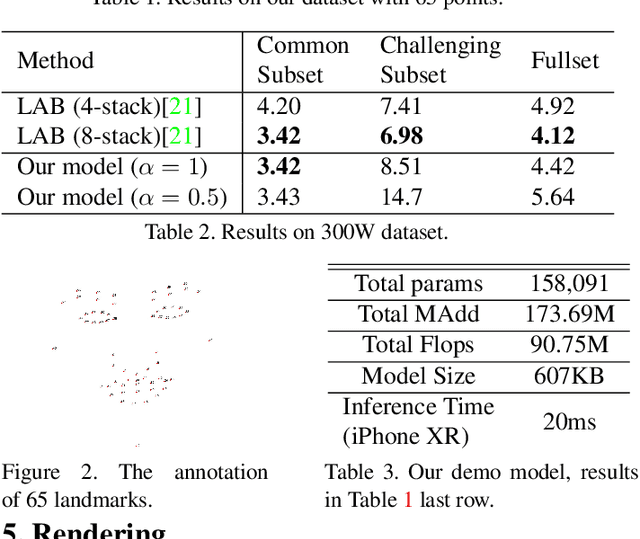
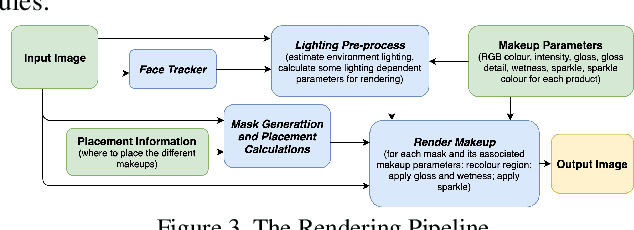
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. We prepared a demo link to our Web demo that can be tested in Chrome and Firefox on Android, or in Safari on iOS: https://s3.amazonaws.com/makeup-paper-demo/index.html
Verifiable Planning in Expected Reward Multichain MDPs
Dec 03, 2020
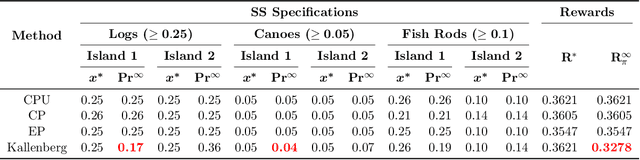
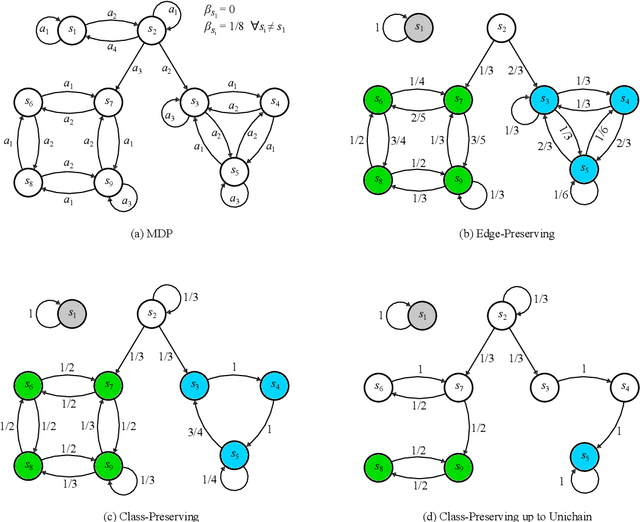
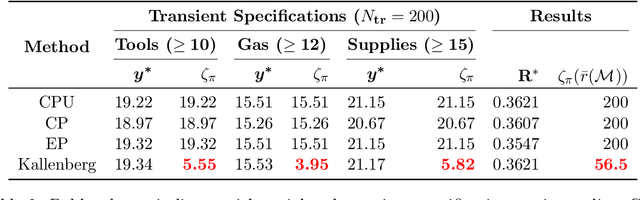
The planning domain has experienced increased interest in the formal synthesis of decision-making policies. This formal synthesis typically entails finding a policy which satisfies formal specifications in the form of some well-defined logic, such as Linear Temporal Logic (LTL) or Computation Tree Logic (CTL), among others. While such logics are very powerful and expressive in their capacity to capture desirable agent behavior, their value is limited when deriving decision-making policies which satisfy certain types of asymptotic behavior. In particular, we are interested in specifying constraints on the steady-state behavior of an agent, which captures the proportion of time an agent spends in each state as it interacts for an indefinite period of time with its environment. This is sometimes called the average or expected behavior of the agent. In this paper, we explore the steady-state planning problem of deriving a decision-making policy for an agent such that constraints on its steady-state behavior are satisfied. A linear programming solution for the general case of multichain Markov Decision Processes (MDPs) is proposed and we prove that optimal solutions to the proposed programs yield stationary policies with rigorous guarantees of behavior.
Improved Regret Bound and Experience Replay in Regularized Policy Iteration
Feb 25, 2021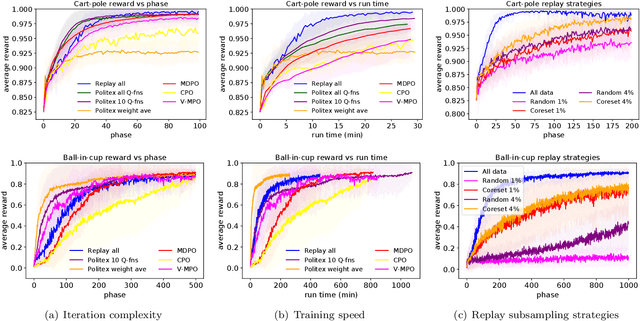
In this work, we study algorithms for learning in infinite-horizon undiscounted Markov decision processes (MDPs) with function approximation. We first show that the regret analysis of the Politex algorithm (a version of regularized policy iteration) can be sharpened from $O(T^{3/4})$ to $O(\sqrt{T})$ under nearly identical assumptions, and instantiate the bound with linear function approximation. Our result provides the first high-probability $O(\sqrt{T})$ regret bound for a computationally efficient algorithm in this setting. The exact implementation of Politex with neural network function approximation is inefficient in terms of memory and computation. Since our analysis suggests that we need to approximate the average of the action-value functions of past policies well, we propose a simple efficient implementation where we train a single Q-function on a replay buffer with past data. We show that this often leads to superior performance over other implementation choices, especially in terms of wall-clock time. Our work also provides a novel theoretical justification for using experience replay within policy iteration algorithms.