 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Artificially Synthesising Data for Audio Classification and Segmentation to Improve Speech and Music Detection in Radio Broadcast
Feb 19, 2021
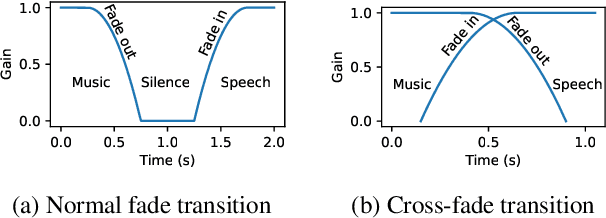
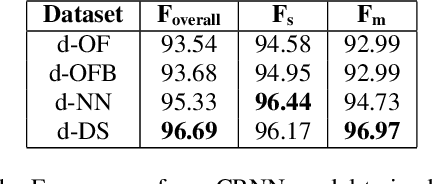
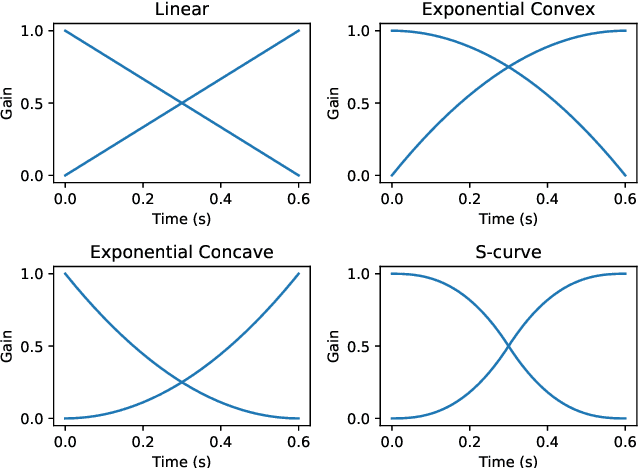
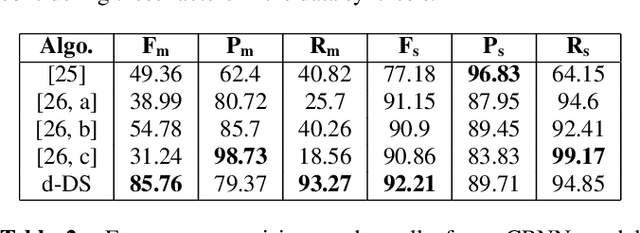
Segmenting audio into homogeneous sections such as music and speech helps us understand the content of audio. It is useful as a pre-processing step to index, store, and modify audio recordings, radio broadcasts and TV programmes. Deep learning models for segmentation are generally trained on copyrighted material, which cannot be shared. Annotating these datasets is time-consuming and expensive and therefore, it significantly slows down research progress. In this study, we present a novel procedure that artificially synthesises data that resembles radio signals. We replicate the workflow of a radio DJ in mixing audio and investigate parameters like fade curves and audio ducking. We trained a Convolutional Recurrent Neural Network (CRNN) on this synthesised data and outperformed state-of-the-art algorithms for music-speech detection. This paper demonstrates the data synthesis procedure as a highly effective technique to generate large datasets to train deep neural networks for audio segmentation.
Variational quantum compiling with double Q-learning
Mar 22, 2021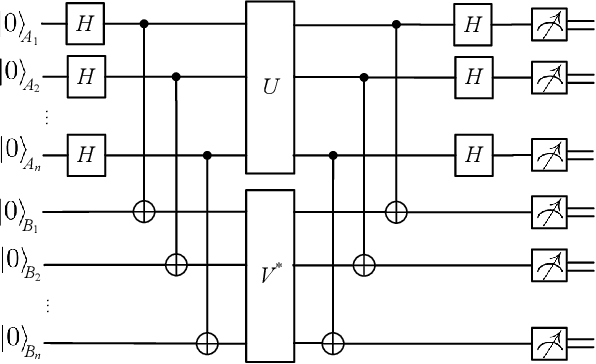

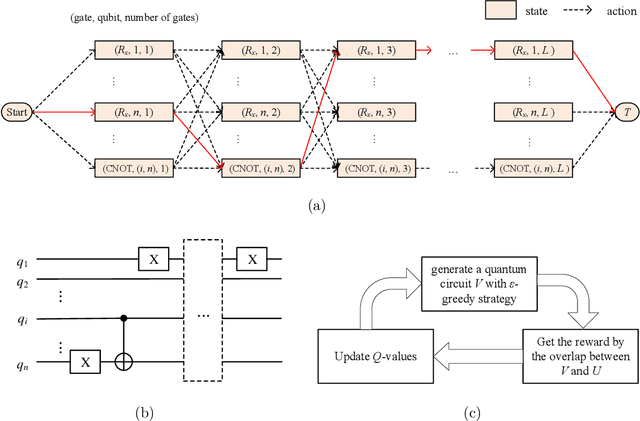
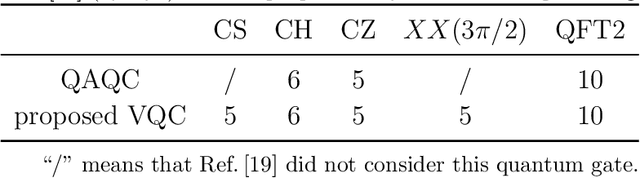
Quantum compiling aims to construct a quantum circuit V by quantum gates drawn from a native gate alphabet, which is functionally equivalent to the target unitary U. It is a crucial stage for the running of quantum algorithms on noisy intermediate-scale quantum (NISQ) devices. However, the space for structure exploration of quantum circuit is enormous, resulting in the requirement of human expertise, hundreds of experimentations or modifications from existing quantum circuits. In this paper, we propose a variational quantum compiling (VQC) algorithm based on reinforcement learning (RL), in order to automatically design the structure of quantum circuit for VQC with no human intervention. An agent is trained to sequentially select quantum gates from the native gate alphabet and the qubits they act on by double Q-learning with \epsilon-greedy exploration strategy and experience replay. At first, the agent randomly explores a number of quantum circuits with different structures, and then iteratively discovers structures with higher performance on the learning task. Simulation results show that the proposed method can make exact compilations with less quantum gates compared to previous VQC algorithms. It can reduce the errors of quantum algorithms due to decoherence process and gate noise in NISQ devices, and enable quantum algorithms especially for complex algorithms to be executed within coherence time.
* 21 pages, 10 figures
Reconstructing a single-head formula to facilitate logical forgetting
Dec 18, 2020Logical forgetting may take exponential time in general, but it does not when its input is a single-head propositional definite Horn formula. Single-head means that no variable is the head of multiple clauses. An algorithm to make a formula single-head if possible is shown. It improves over a previous one by being complete: it always finds a single-head formula equivalent to the given one if any.
Image Augmentation for Multitask Few-Shot Learning: Agricultural Domain Use-Case
Feb 24, 2021


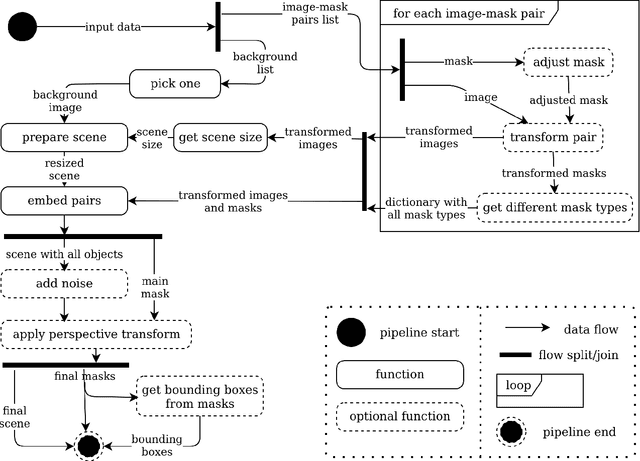
Large datasets' availability is catalyzing a rapid expansion of deep learning in general and computer vision in particular. At the same time, in many domains, a sufficient amount of training data is lacking, which may become an obstacle to the practical application of computer vision techniques. This paper challenges small and imbalanced datasets based on the example of a plant phenomics domain. We introduce an image augmentation framework, which enables us to extremely enlarge the number of training samples while providing the data for such tasks as object detection, semantic segmentation, instance segmentation, object counting, image denoising, and classification. We prove that our augmentation method increases model performance when only a few training samples are available. In our experiment, we use the DeepLabV3 model on semantic segmentation tasks with Arabidopsis and Nicotiana tabacum image dataset. The obtained result shows a 9% relative increase in model performance compared to the basic image augmentation techniques.
Retrieving Event-related Human Brain Dynamics from Natural Sentence Reading
Mar 29, 2021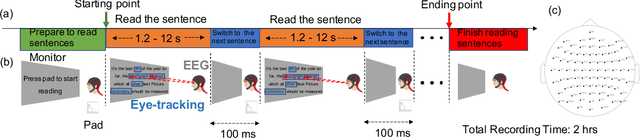
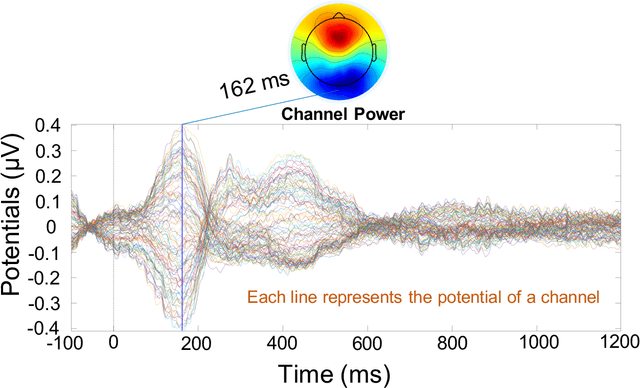
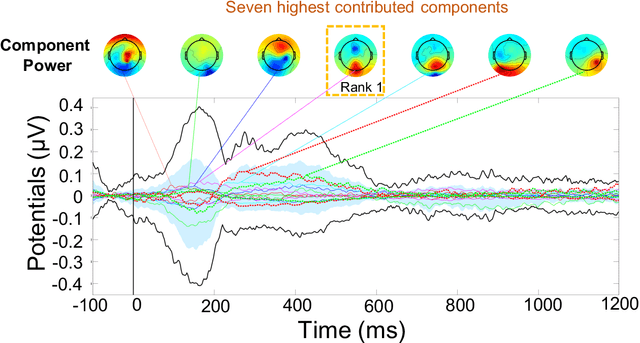
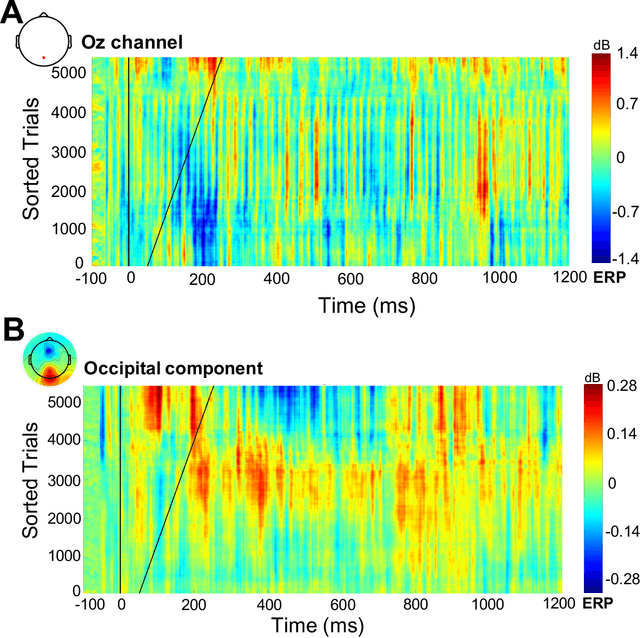
Electroencephalography (EEG) signals recordings when people reading natural languages are commonly used as a cognitive method to interpret human language understanding in neuroscience and psycholinguistics. Previous studies have demonstrated that the human fixation and activation in word reading associated with some brain regions, but it is not clear when and how to measure the brain dynamics across time and frequency domains. In this study, we propose the first analysis of event-related brain potentials (ERPs), and event-related spectral perturbations (ERSPs) on benchmark datasets which consist of sentence-level simultaneous EEG and related eye-tracking recorded from human natural reading experiment tasks. Our results showed peaks evoked at around 162 ms after the stimulus (starting to read each sentence) in the occipital area, indicating the brain retriving lexical and semantic visual information processing approaching 200 ms from the sentence onset. Furthermore, the occipital ERP around 200ms presents negative power and positive power in short and long reaction times. In addition, the occipital ERSP around 200ms demonstrated increased high gamma and decreased low beta and low gamma power, relative to the baseline. Our results implied that most of the semantic-perception responses occurred around the 200ms in alpha, beta and gamma bands of EEG signals. Our findings also provide potential impacts on promoting cognitive natural language processing models evaluation from EEG dynamics.
Project-Level Encoding for Neural Source Code Summarization of Subroutines
Mar 22, 2021
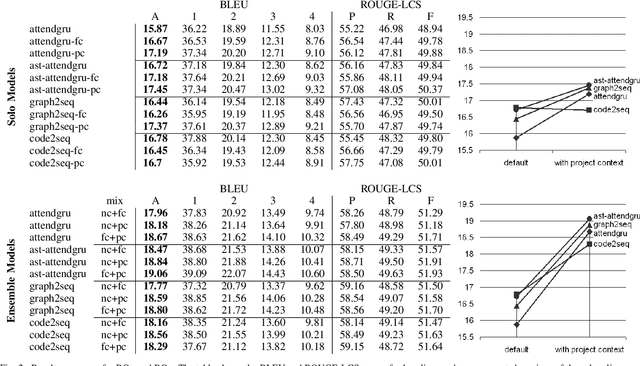
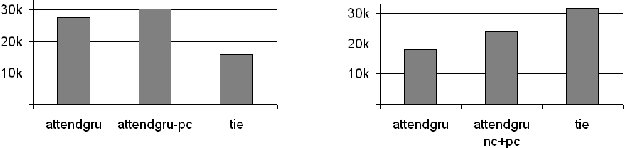
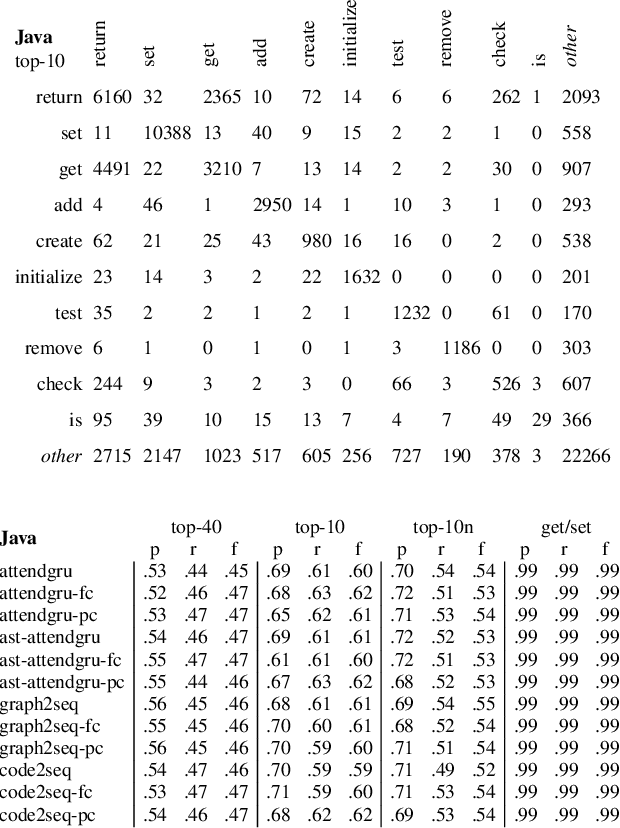
Source code summarization of a subroutine is the task of writing a short, natural language description of that subroutine. The description usually serves in documentation aimed at programmers, where even brief phrase (e.g. "compresses data to a zip file") can help readers rapidly comprehend what a subroutine does without resorting to reading the code itself. Techniques based on neural networks (and encoder-decoder model designs in particular) have established themselves as the state-of-the-art. Yet a problem widely recognized with these models is that they assume the information needed to create a summary is present within the code being summarized itself - an assumption which is at odds with program comprehension literature. Thus a current research frontier lies in the question of encoding source code context into neural models of summarization. In this paper, we present a project-level encoder to improve models of code summarization. By project-level, we mean that we create a vectorized representation of selected code files in a software project, and use that representation to augment the encoder of state-of-the-art neural code summarization techniques. We demonstrate how our encoder improves several existing models, and provide guidelines for maximizing improvement while controlling time and resource costs in model size.
ClaRe: Practical Class Incremental Learning By Remembering Previous Class Representations
Mar 29, 2021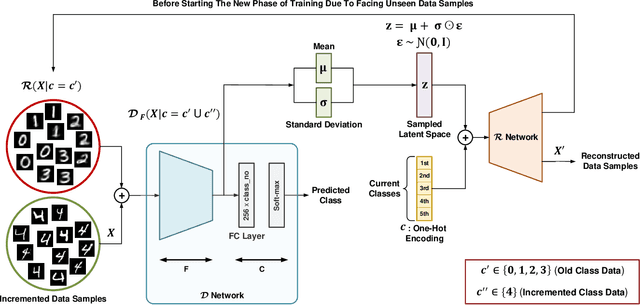

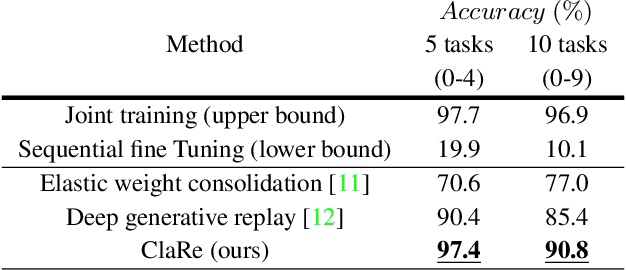
This paper presents a practical and simple yet efficient method to effectively deal with the catastrophic forgetting for Class Incremental Learning (CIL) tasks. CIL tends to learn new concepts perfectly, but not at the expense of performance and accuracy for old data. Learning new knowledge in the absence of data instances from previous classes or even imbalance samples of both old and new classes makes CIL an ongoing challenging problem. These issues can be tackled by storing exemplars belonging to the previous tasks or by utilizing the rehearsal strategy. Inspired by the rehearsal strategy with the approach of using generative models, we propose ClaRe, an efficient solution for CIL by remembering the representations of learned classes in each increment. Taking this approach leads to generating instances with the same distribution of the learned classes. Hence, our model is somehow retrained from the scratch using a new training set including both new and the generated samples. Subsequently, the imbalance data problem is also solved. ClaRe has a better generalization than prior methods thanks to producing diverse instances from the distribution of previously learned classes. We comprehensively evaluate ClaRe on the MNIST benchmark. Results show a very low degradation on accuracy against facing new knowledge over time. Furthermore, contrary to the most proposed solutions, the memory limitation is not problematic any longer which is considered as a consequential issue in this research area.
ELMo and BERT in semantic change detection for Russian
Oct 07, 2020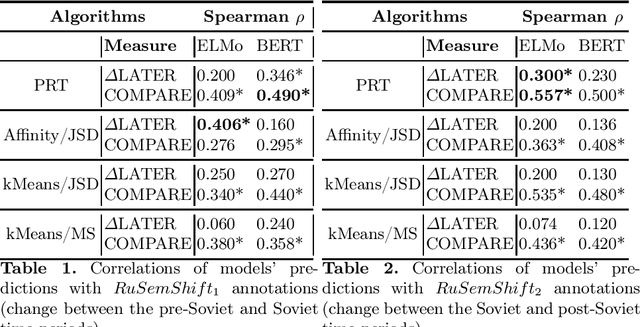
We study the effectiveness of contextualized embeddings for the task of diachronic semantic change detection for Russian language data. Evaluation test sets consist of Russian nouns and adjectives annotated based on their occurrences in texts created in pre-Soviet, Soviet and post-Soviet time periods. ELMo and BERT architectures are compared on the task of ranking Russian words according to the degree of their semantic change over time. We use several methods for aggregation of contextualized embeddings from these architectures and evaluate their performance. Finally, we compare unsupervised and supervised techniques in this task.
MPPI-VS: Sampling-Based Model Predictive Control Strategy for Constrained Image-Based and Position-Based Visual Servoing
Apr 11, 2021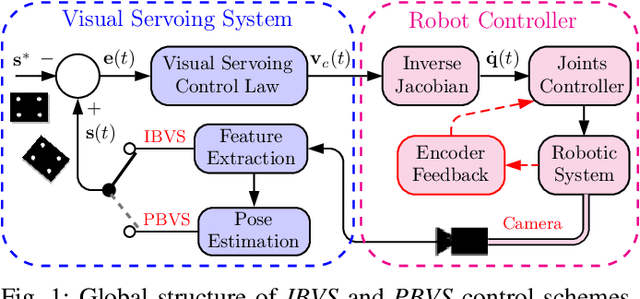
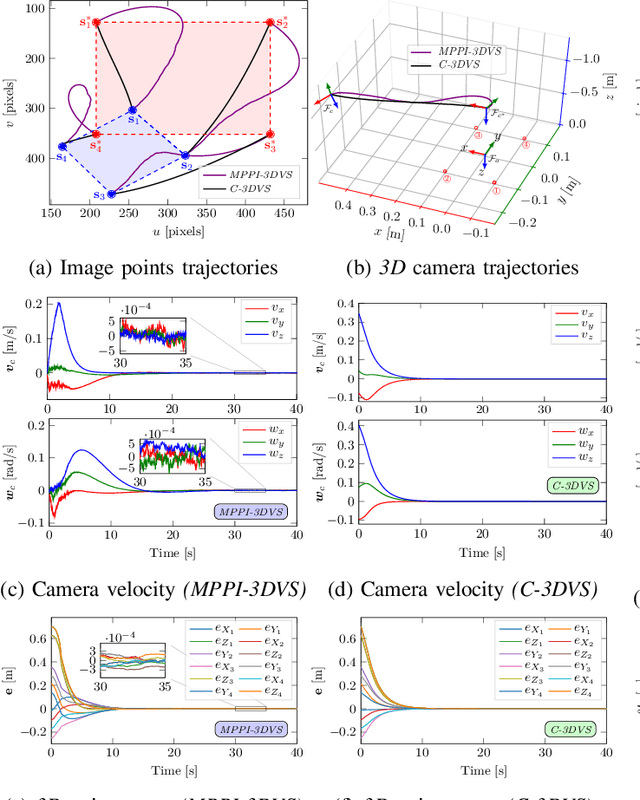
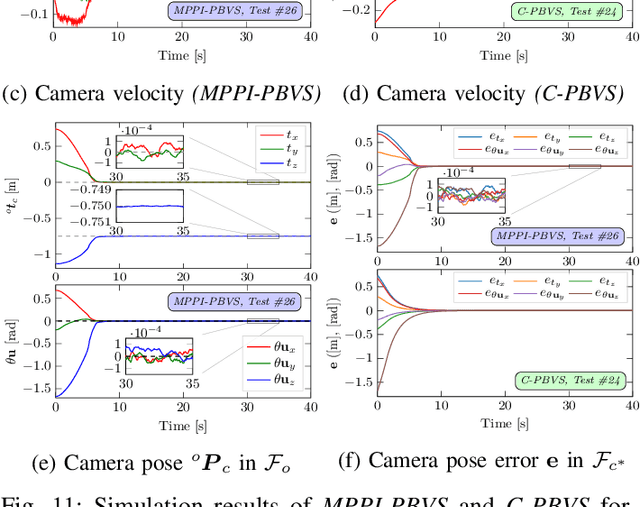
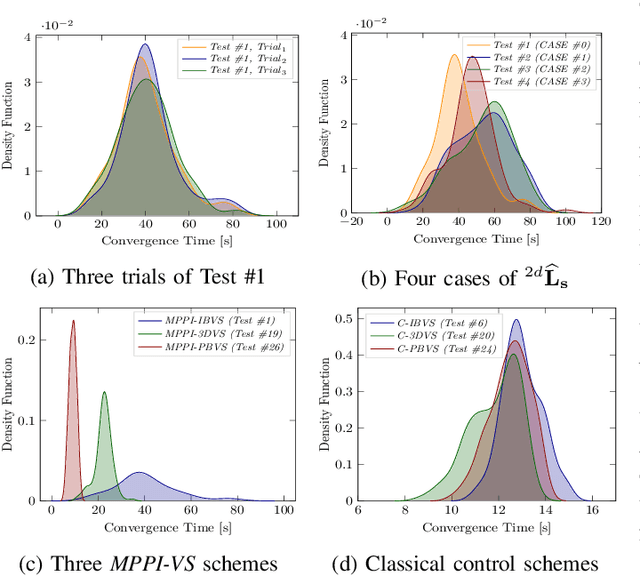
In this paper, we open up new avenues for visual servoing systems built upon the Path Integral (PI) optimal control theory, in which the non-linear partial differential equation (PDE) can be transformed into an expectation over all possible trajectories using the Feynman-Kac (FK) lemma. More precisely, we propose an MPPI-VS control strategy, a real-time and inversion-free control strategy on the basis of sampling-based model predictive control (namely, Model Predictive Path Integral (MPPI) control) algorithm, for both image-based, 3D point, and position-based visual servoing techniques, taking into account the system constraints (such as visibility, 3D, and control constraints) and parametric uncertainties associated with the robot and camera models as well as measurement noise. Contrary to classical visual servoing control schemes, our control strategy directly utilizes the approximation of the interaction matrix, without the need for estimating the interaction matrix inversion or performing the pseudo-inversion. We validate the MPPI-VS control strategy as well as the classical control schemes on a 6-DoF Cartesian robot with an eye-in-hand camera based on the utilization of four points in the image plane as visual features. To better assess and demonstrate the robustness and potential advantages of our proposed control strategy compared to classical schemes, intensive simulations under various operating conditions are carried out and then discussed. The obtained results demonstrate the effectiveness and capability of the proposed scheme in coping easily with the system constraints, as well as its robustness in the presence of large errors in camera parameters and measurements.
ES-Net: An Efficient Stereo Matching Network
Mar 05, 2021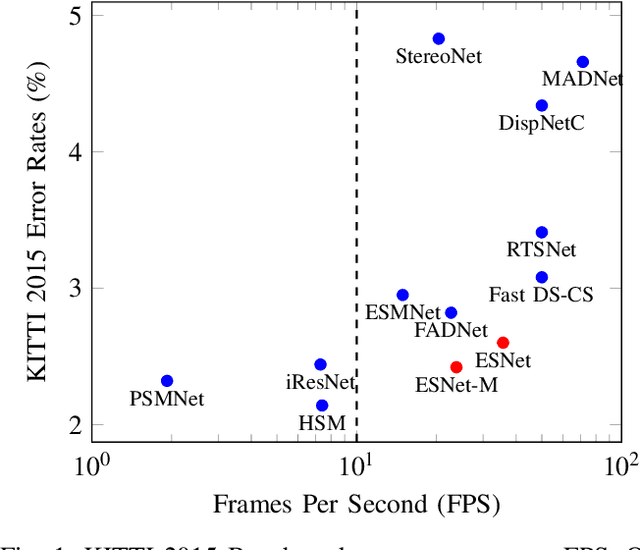
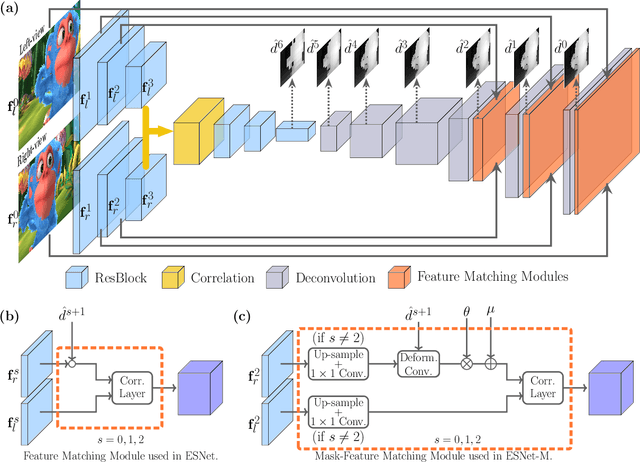

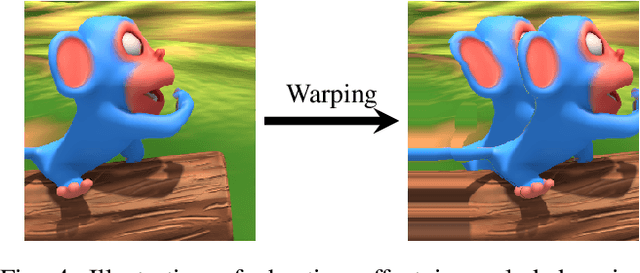
Dense stereo matching with deep neural networks is of great interest to the research community. Existing stereo matching networks typically use slow and computationally expensive 3D convolutions to improve the performance, which is not friendly to real-world applications such as autonomous driving. In this paper, we propose the Efficient Stereo Network (ESNet), which achieves high performance and efficient inference at the same time. ESNet relies only on 2D convolution and computes multi-scale cost volume efficiently using a warping-based method to improve the performance in regions with fine-details. In addition, we address the matching ambiguity issue in the occluded region by proposing ESNet-M, a variant of ESNet that additionally estimates an occlusion mask without supervision. We further improve the network performance by proposing a new training scheme that includes dataset scheduling and unsupervised pre-training. Compared with other low-cost dense stereo depth estimation methods, our proposed approach achieves state-of-the-art performance on the Scene Flow [1], DrivingStereo [2], and KITTI-2015 dataset [3]. Our code will be made available.