 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Multiple Run Ensemble Learning withLow-Dimensional Knowledge Graph Embeddings
Apr 11, 2021
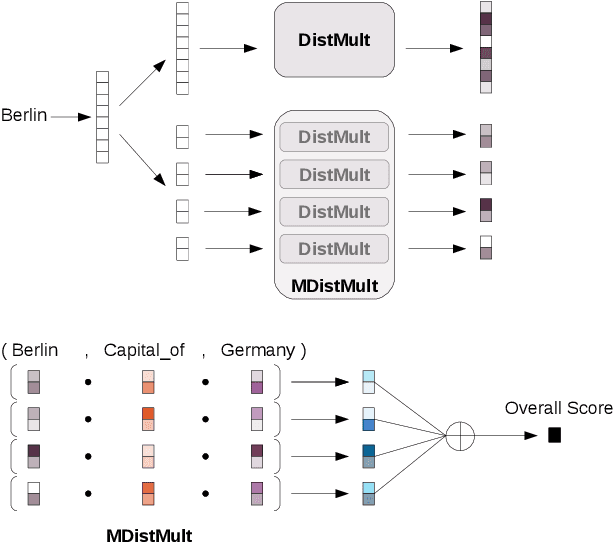
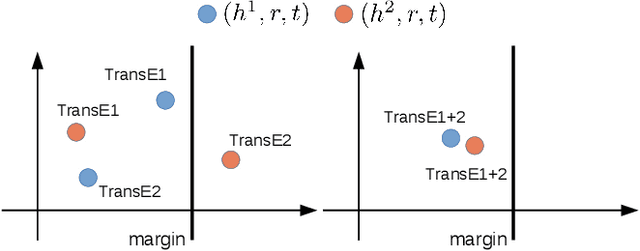
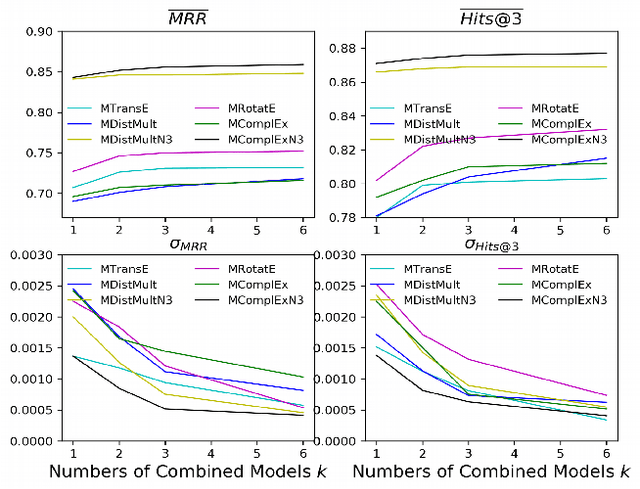
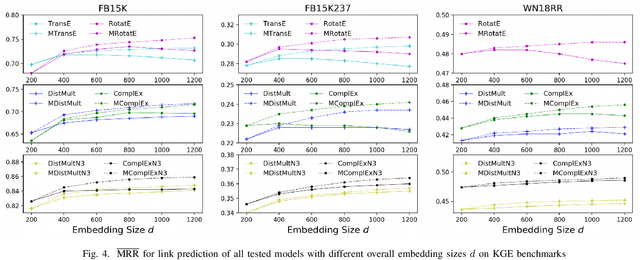
Among the top approaches of recent years, link prediction using knowledge graph embedding (KGE) models has gained significant attention for knowledge graph completion. Various embedding models have been proposed so far, among which, some recent KGE models obtain state-of-the-art performance on link prediction tasks by using embeddings with a high dimension (e.g. 1000) which accelerate the costs of training and evaluation considering the large scale of KGs. In this paper, we propose a simple but effective performance boosting strategy for KGE models by using multiple low dimensions in different repetition rounds of the same model. For example, instead of training a model one time with a large embedding size of 1200, we repeat the training of the model 6 times in parallel with an embedding size of 200 and then combine the 6 separate models for testing while the overall numbers of adjustable parameters are same (6*200=1200) and the total memory footprint remains the same. We show that our approach enables different models to better cope with their expressiveness issues on modeling various graph patterns such as symmetric, 1-n, n-1 and n-n. In order to justify our findings, we conduct experiments on various KGE models. Experimental results on standard benchmark datasets, namely FB15K, FB15K-237 and WN18RR, show that multiple low-dimensional models of the same kind outperform the corresponding single high-dimensional models on link prediction in a certain range and have advantages in training efficiency by using parallel training while the overall numbers of adjustable parameters are same.
Hybrid Deep Neural Networks to Infer State Models of Black-Box Systems
Aug 26, 2020

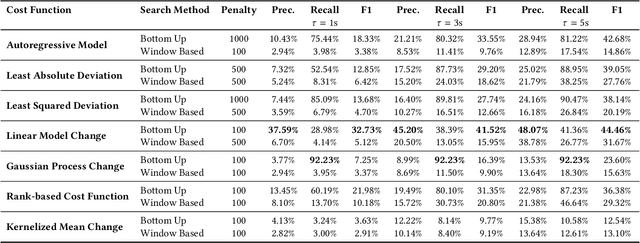
Inferring behavior model of a running software system is quite useful for several automated software engineering tasks, such as program comprehension, anomaly detection, and testing. Most existing dynamic model inference techniques are white-box, i.e., they require source code to be instrumented to get run-time traces. However, in many systems, instrumenting the entire source code is not possible (e.g., when using black-box third-party libraries) or might be very costly. Unfortunately, most black-box techniques that detect states over time are either univariate, or make assumptions on the data distribution, or have limited power for learning over a long period of past behavior. To overcome the above issues, in this paper, we propose a hybrid deep neural network that accepts as input a set of time series, one per input/output signal of the system, and applies a set of convolutional and recurrent layers to learn the non-linear correlations between signals and the patterns, over time. We have applied our approach on a real UAV auto-pilot solution from our industry partner with half a million lines of C code. We ran 888 random recent system-level test cases and inferred states, over time. Our comparison with several traditional time series change point detection techniques showed that our approach improves their performance by up to 102%, in terms of finding state change points, measured by F1 score. We also showed that our state classification algorithm provides on average 90.45% F1 score, which improves traditional classification algorithms by up to 17%.
Measuring Player's Behaviour Change over Time in Public Goods Game
Sep 09, 2016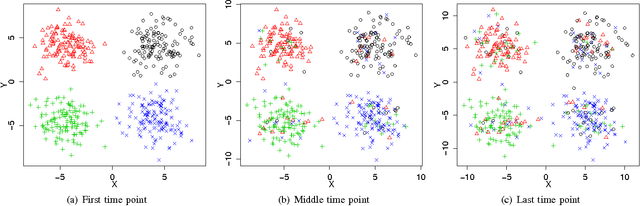
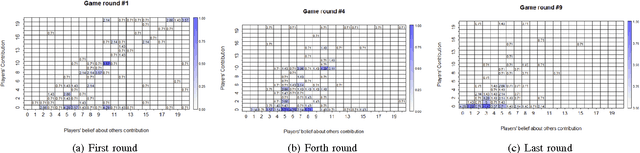
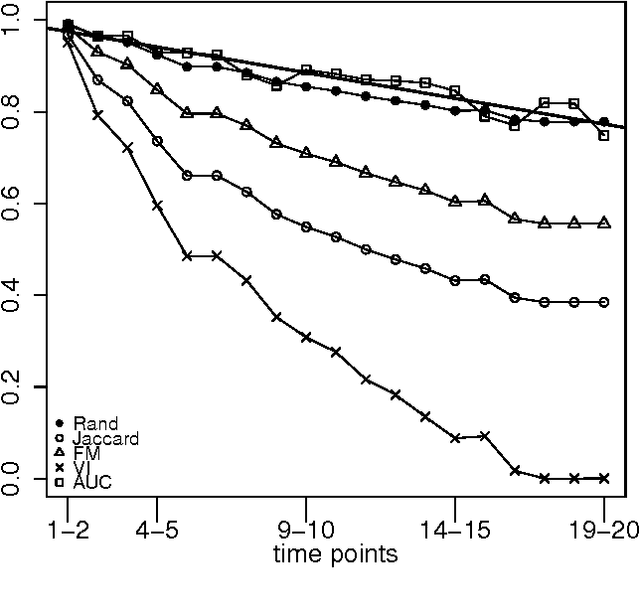
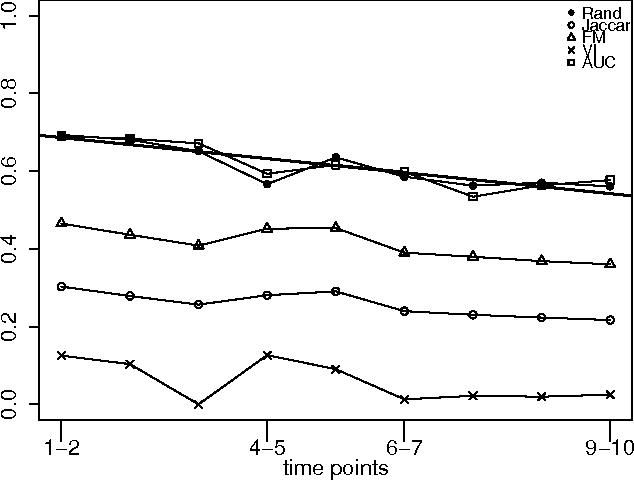
An important issue in public goods game is whether player's behaviour changes over time, and if so, how significant it is. In this game players can be classified into different groups according to the level of their participation in the public good. This problem can be considered as a concept drift problem by asking the amount of change that happens to the clusters of players over a sequence of game rounds. In this study we present a method for measuring changes in clusters with the same items over discrete time points using external clustering validation indices and area under the curve. External clustering indices were originally used to measure the difference between suggested clusters in terms of clustering algorithms and ground truth labels for items provided by experts. Instead of different cluster label comparison, we use these indices to compare between clusters of any two consecutive time points or between the first time point and the remaining time points to measure the difference between clusters through time points. In theory, any external clustering indices can be used to measure changes for any traditional (non-temporal) clustering algorithm, due to the fact that any time point alone is not carrying any temporal information. For the public goods game, our results indicate that the players are changing over time but the change is smooth and relatively constant between any two time points.
Adaptive Boosting for Domain Adaptation: Towards Robust Predictions in Scene Segmentation
Mar 29, 2021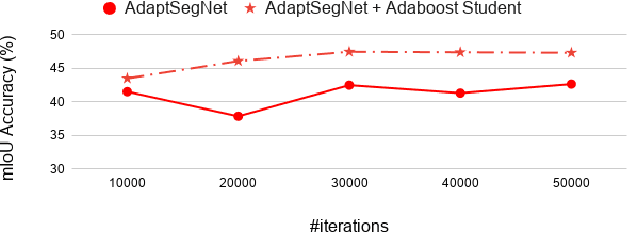

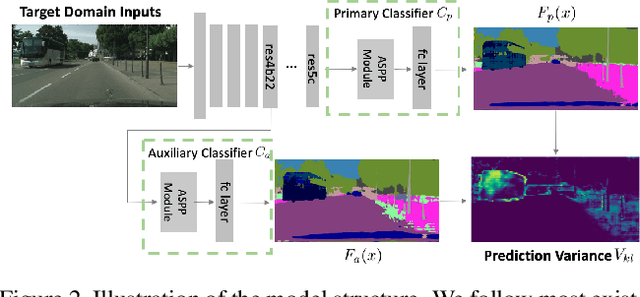

Domain adaptation is to transfer the shared knowledge learned from the source domain to a new environment, i.e., target domain. One common practice is to train the model on both labeled source-domain data and unlabeled target-domain data. Yet the learned models are usually biased due to the strong supervision of the source domain. Most researchers adopt the early-stopping strategy to prevent over-fitting, but when to stop training remains a challenging problem since the lack of the target-domain validation set. In this paper, we propose one efficient bootstrapping method, called Adaboost Student, explicitly learning complementary models during training and liberating users from empirical early stopping. Adaboost Student combines the deep model learning with the conventional training strategy, i.e., adaptive boosting, and enables interactions between learned models and the data sampler. We adopt one adaptive data sampler to progressively facilitate learning on hard samples and aggregate ``weak'' models to prevent over-fitting. Extensive experiments show that (1) Without the need to worry about the stopping time, AdaBoost Student provides one robust solution by efficient complementary model learning during training. (2) AdaBoost Student is orthogonal to most domain adaptation methods, which can be combined with existing approaches to further improve the state-of-the-art performance. We have achieved competitive results on three widely-used scene segmentation domain adaptation benchmarks.
Learning language variations in news corpora through differential embeddings
Nov 13, 2020



There is an increasing interest in the NLP community in capturing variations in the usage of language, either through time (i.e., semantic drift), across regions (as dialects or variants) or in different social contexts (i.e., professional or media technolects). Several successful dynamical embeddings have been proposed that can track semantic change through time. Here we show that a model with a central word representation and a slice-dependent contribution can learn word embeddings from different corpora simultaneously. This model is based on a star-like representation of the slices. We apply it to The New York Times and The Guardian newspapers, and we show that it can capture both temporal dynamics in the yearly slices of each corpus, and language variations between US and UK English in a curated multi-source corpus. We provide an extensive evaluation of this methodology.
A Cognitive Approach based on the Actionable Knowledge Graph for supporting Maintenance Operations
Nov 18, 2020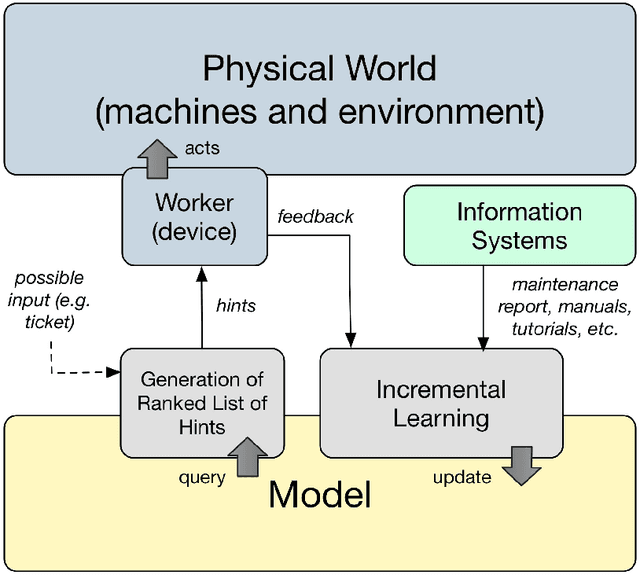
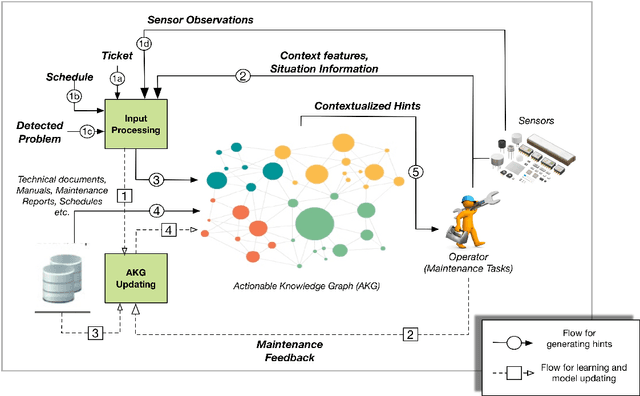
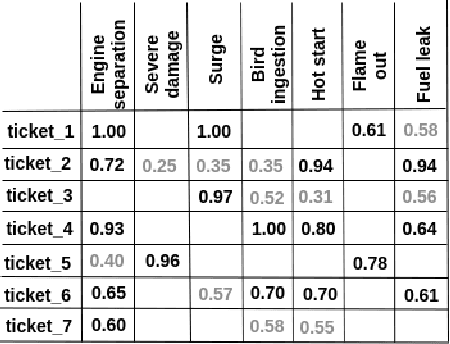
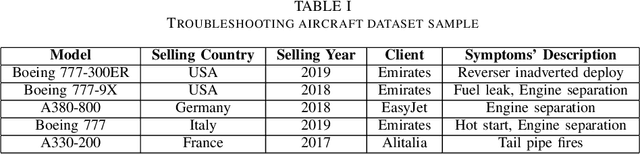
In the era of Industry 4.0, cognitive computing and its enabling technologies (Artificial Intelligence, Machine Learning, etc.) allow to define systems able to support maintenance by providing relevant information, at the right time, retrieved from structured companies' databases, and unstructured documents, like technical manuals, intervention reports, and so on. Moreover, contextual information plays a crucial role in tailoring the support both during the planning and the execution of interventions. Contextual information can be detected with the help of sensors, wearable devices, indoor and outdoor positioning systems, and object recognition capabilities (using fixed or wearable cameras), all of which can collect historical data for further analysis. In this work, we propose a cognitive system that learns from past interventions to generate contextual recommendations for improving maintenance practices in terms of time, budget, and scope. The system uses formal conceptual models, incremental learning, and ranking algorithms to accomplish these objectives.
Supervised Feature Selection Techniques in Network Intrusion Detection: a Critical Review
Apr 11, 2021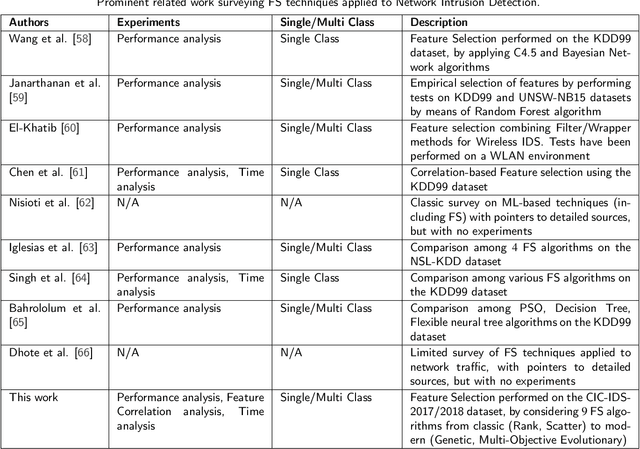
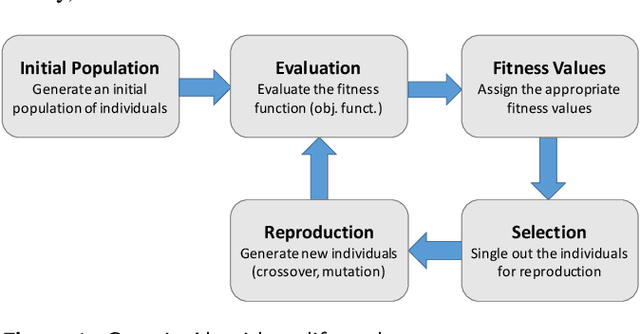
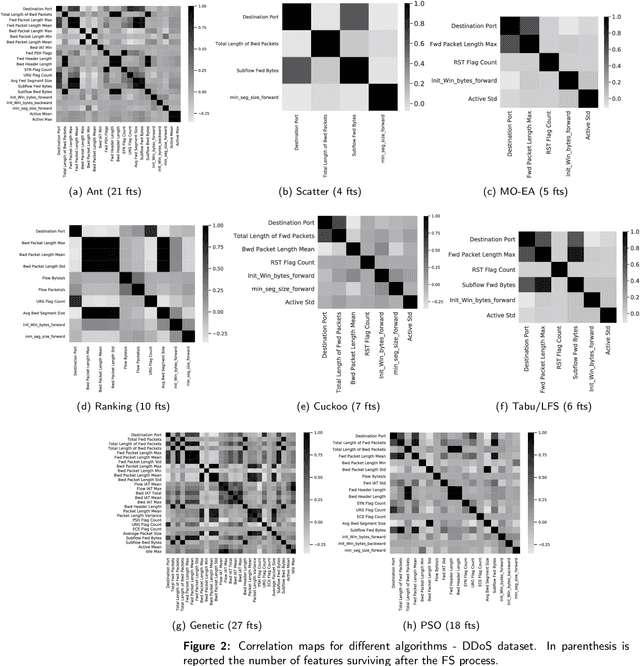
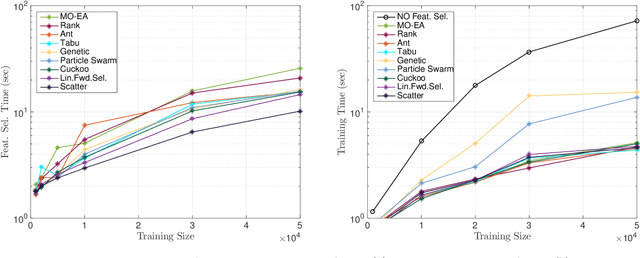
Machine Learning (ML) techniques are becoming an invaluable support for network intrusion detection, especially in revealing anomalous flows, which often hide cyber-threats. Typically, ML algorithms are exploited to classify/recognize data traffic on the basis of statistical features such as inter-arrival times, packets length distribution, mean number of flows, etc. Dealing with the vast diversity and number of features that typically characterize data traffic is a hard problem. This results in the following issues: i) the presence of so many features leads to lengthy training processes (particularly when features are highly correlated), while prediction accuracy does not proportionally improve; ii) some of the features may introduce bias during the classification process, particularly those that have scarce relation with the data traffic to be classified. To this end, by reducing the feature space and retaining only the most significant features, Feature Selection (FS) becomes a crucial pre-processing step in network management and, specifically, for the purposes of network intrusion detection. In this review paper, we complement other surveys in multiple ways: i) evaluating more recent datasets (updated w.r.t. obsolete KDD 99) by means of a designed-from-scratch Python-based procedure; ii) providing a synopsis of most credited FS approaches in the field of intrusion detection, including Multi-Objective Evolutionary techniques; iii) assessing various experimental analyses such as feature correlation, time complexity, and performance. Our comparisons offer useful guidelines to network/security managers who are considering the incorporation of ML concepts into network intrusion detection, where trade-offs between performance and resource consumption are crucial.
Regret-optimal measurement-feedback control
Nov 24, 2020We consider measurement-feedback control in linear dynamical systems from the perspective of regret minimization. Unlike most prior work in this area, we focus on the problem of designing an online controller which competes with the optimal dynamic sequence of control actions selected in hindsight, instead of the best controller in some specific class of controllers. This formulation of regret is attractive when the environment changes over time and no single controller achieves good performance over the entire time horizon. We show that in the measurement-feedback setting, unlike in the full-information setting, there is no single offline controller which outperforms every other offline controller on every disturbance, and propose a new $H_2$-optimal offline controller as a benchmark for the online controller to compete against. We show that the corresponding regret-optimal online controller can be found via a novel reduction to the classical Nehari problem from robust control and present a tight data-dependent bound on its regret.
Competition analysis on the over-the-counter credit default swap market
Dec 03, 2020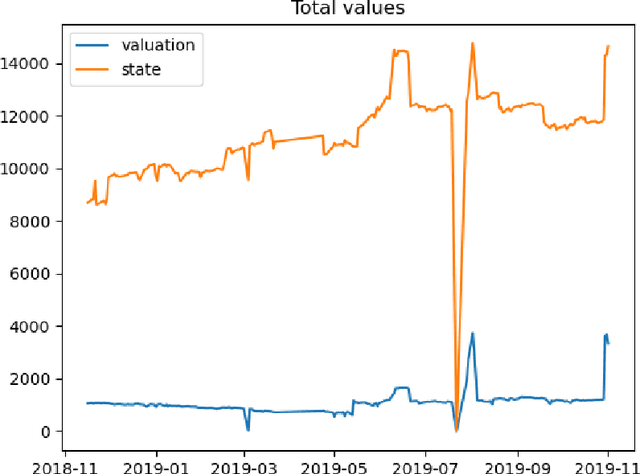
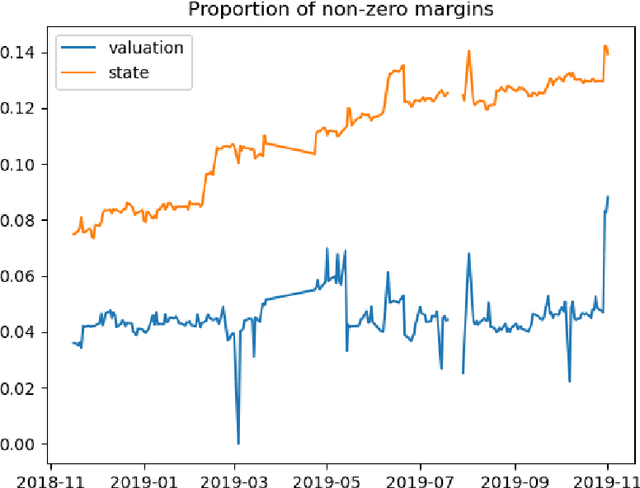
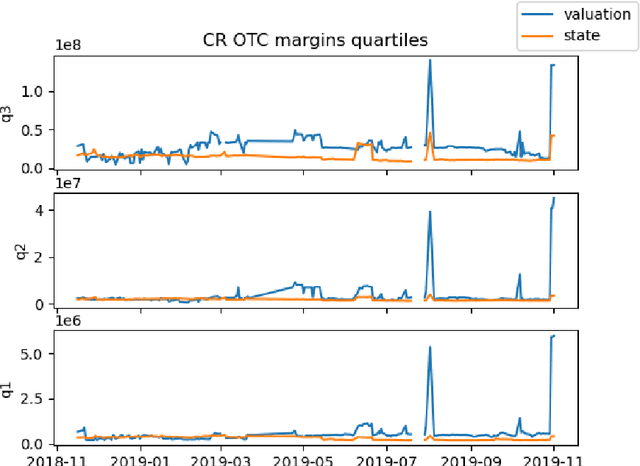
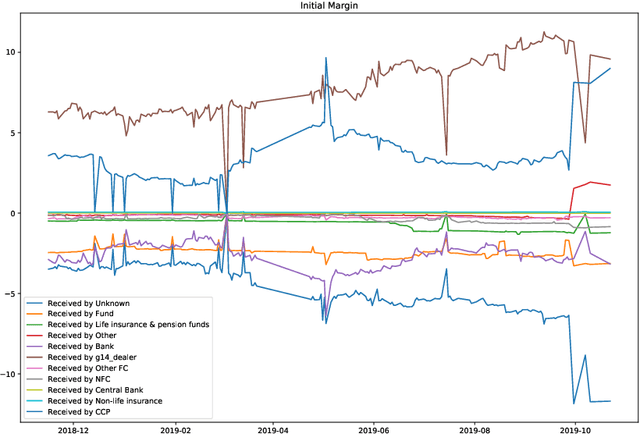
We study two questions related to competition on the OTC CDS market using data collected as part of the EMIR regulation. First, we study the competition between central counterparties through collateral requirements. We present models that successfully estimate the initial margin requirements. However, our estimations are not precise enough to use them as input to a predictive model for CCP choice by counterparties in the OTC market. Second, we model counterpart choice on the interdealer market using a novel semi-supervised predictive task. We present our methodology as part of the literature on model interpretability before arguing for the use of conditional entropy as the metric of interest to derive knowledge from data through a model-agnostic approach. In particular, we justify the use of deep neural networks to measure conditional entropy on real-world datasets. We create the $\textit{Razor entropy}$ using the framework of algorithmic information theory and derive an explicit formula that is identical to our semi-supervised training objective. Finally, we borrow concepts from game theory to define $\textit{top-k Shapley values}$. This novel method of payoff distribution satisfies most of the properties of Shapley values, and is of particular interest when the value function is monotone submodular. Unlike classical Shapley values, top-k Shapley values can be computed in quadratic time of the number of features instead of exponential. We implement our methodology and report the results on our particular task of counterpart choice. Finally, we present an improvement to the $\textit{node2vec}$ algorithm that could for example be used to further study intermediation. We show that the neighbor sampling used in the generation of biased walks can be performed in logarithmic time with a quasilinear time pre-computation, unlike the current implementations that do not scale well.
Principled Ultrasound Data Augmentation for Classification of Standard Planes
Mar 14, 2021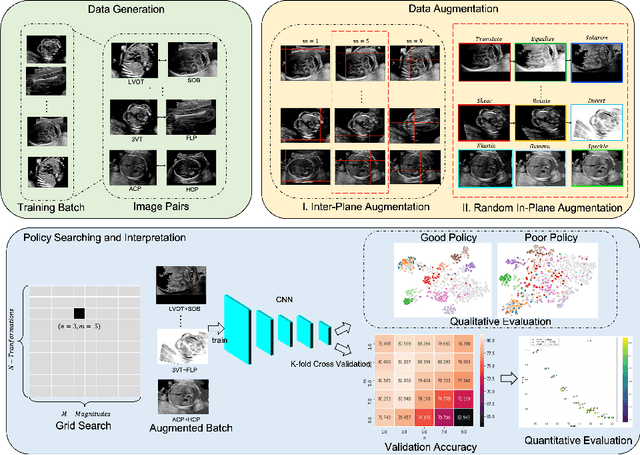



Deep learning models with large learning capacities often overfit to medical imaging datasets. This is because training sets are often relatively small due to the significant time and financial costs incurred in medical data acquisition and labelling. Data augmentation is therefore often used to expand the availability of training data and to increase generalization. However, augmentation strategies are often chosen on an ad-hoc basis without justification. In this paper, we present an augmentation policy search method with the goal of improving model classification performance. We include in the augmentation policy search additional transformations that are often used in medical image analysis and evaluate their performance. In addition, we extend the augmentation policy search to include non-linear mixed-example data augmentation strategies. Using these learned policies, we show that principled data augmentation for medical image model training can lead to significant improvements in ultrasound standard plane detection, with an an average F1-score improvement of 7.0% overall over naive data augmentation strategies in ultrasound fetal standard plane classification. We find that the learned representations of ultrasound images are better clustered and defined with optimized data augmentation.