 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Optimal Cost Design for Model Predictive Control
Apr 23, 2021
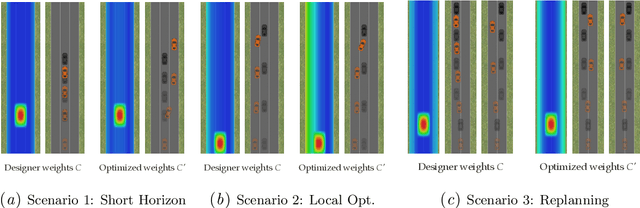
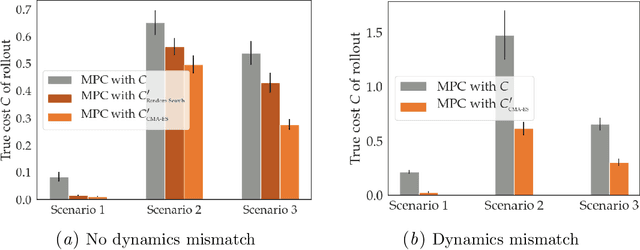
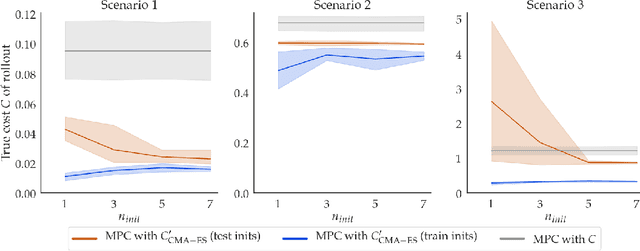
Many robotics domains use some form of nonconvex model predictive control (MPC) for planning, which sets a reduced time horizon, performs trajectory optimization, and replans at every step. The actual task typically requires a much longer horizon than is computationally tractable, and is specified via a cost function that cumulates over that full horizon. For instance, an autonomous car may have a cost function that makes a desired trade-off between efficiency, safety, and obeying traffic laws. In this work, we challenge the common assumption that the cost we optimize using MPC should be the same as the ground truth cost for the task (plus a terminal cost). MPC solvers can suffer from short planning horizons, local optima, incorrect dynamics models, and, importantly, fail to account for future replanning ability. Thus, we propose that in many tasks it could be beneficial to purposefully choose a different cost function for MPC to optimize: one that results in the MPC rollout having low ground truth cost, rather than the MPC planned trajectory. We formalize this as an optimal cost design problem, and propose a zeroth-order optimization-based approach that enables us to design optimal costs for an MPC planning robot in continuous MDPs. We test our approach in an autonomous driving domain where we find costs different from the ground truth that implicitly compensate for replanning, short horizon, incorrect dynamics models, and local minima issues. As an example, the learned cost incentivizes MPC to delay its decision until later, implicitly accounting for the fact that it will get more information in the future and be able to make a better decision. Code and videos available at https://sites.google.com/berkeley.edu/ocd-mpc/.
An underwater binocular stereo matching algorithm based on the best search domain
Feb 09, 2021Binocular stereo vision is an important branch of machine vision, which imitates the human eye and matches the left and right images captured by the camera based on epipolar constraints. The matched disparity map can be calculated according to the camera imaging model to obtain a depth map, and then the depth map is converted to a point cloud image to obtain spatial point coordinates, thereby achieving the purpose of ranging. However, due to the influence of illumination under water, the captured images no longer meet the epipolar constraints, and the changes in imaging models make traditional calibration methods no longer applicable. Therefore, this paper proposes a new underwater real-time calibration method and a matching method based on the best search domain to improve the accuracy of underwater distance measurement using binoculars.
Spillover Algorithm: A Decentralized Coordination Approach for Multi-Robot Production Planning in Open Shared Factories
Jan 14, 2021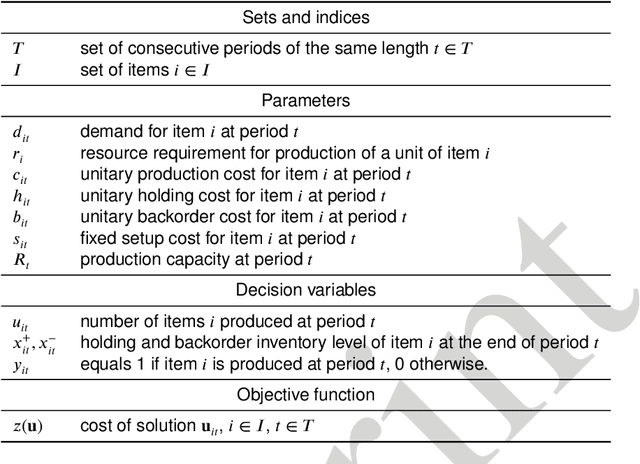
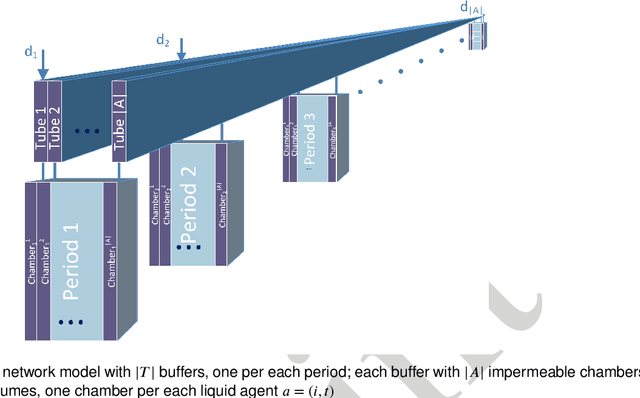

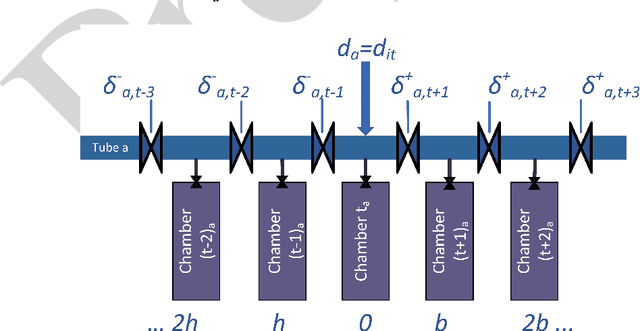
Open and shared manufacturing factories typically dispose of a limited number of robots that should be properly allocated to tasks in time and space for an effective and efficient system performance. In particular, we deal with the dynamic capacitated production planning problem with sequence independent setup costs where quantities of products to manufacture and location of robots need to be determined at consecutive periods within a given time horizon and products can be anticipated or backordered related to the demand period. We consider a decentralized multi-agent variant of this problem in an open factory setting with multiple owners of robots as well as different owners of the items to be produced, both considered self-interested and individually rational. Existing solution approaches to the classic constrained lot-sizing problem are centralized exact methods that require sharing of global knowledge of all the participants' private and sensitive information and are not applicable in the described multi-agent context. Therefore, we propose a computationally efficient decentralized approach based on the spillover effect that solves this NP-hard problem by distributing decisions in an intrinsically decentralized multi-agent system environment while protecting private and sensitive information. To the best of our knowledge, this is the first decentralized algorithm for the solution of the studied problem in intrinsically decentralized environments where production resources and/or products are owned by multiple stakeholders with possibly conflicting objectives. To show its efficiency, the performance of the Spillover Algorithm is benchmarked against state-of-the-art commercial solver CPLEX 12.8.
Control of a Tail-Sitter VTOL UAV Based on Recurrent Neural Networks
Apr 05, 2021
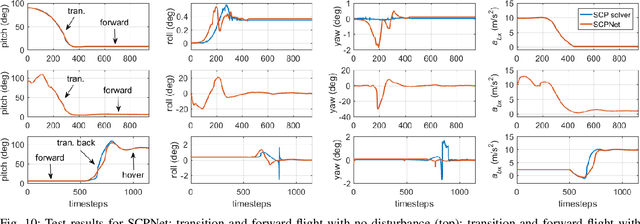
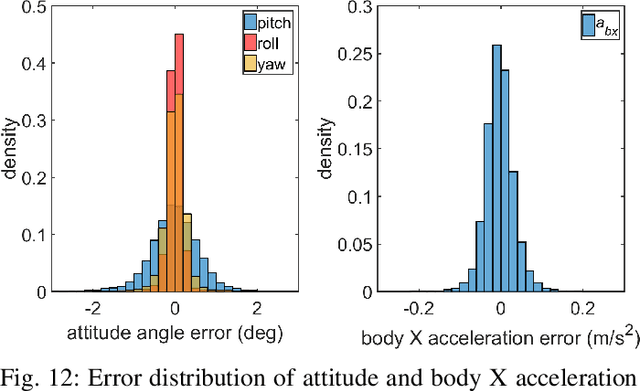
Tail-sitter vertical takeoff and landing (VTOL) unmanned aerial vehicles (UAVs) have the capability of hovering and performing efficient level flight with compact mechanical structures. We present a unified controller design for such UAVs, based on recurrent neural networks. An advantage of this design method is that the various flight modes (i.e., hovering, transition and level flight) of a VTOL UAV are controlled in a unified manner, as opposed to treating them separately and in the runtime switching one from another. The proposed controller consists of an outer-loop position controller and an inner-loop attitude controller. The inner-loop controller is composed of a proportional attitude controller and a loop-shaping linear angular rate controller. For the outer-loop controller, we propose a nonlinear solver to compute the desired attitude and thrust, based on the UAV dynamics and an aerodynamic model, in addition to a cascaded PID controller for the position and velocity tracking. We employ a recurrent neural network (RNN) to approximate the behavior of the nonlinear solver, which suffers from high computational complexity. The proposed RNN has negligible approximation errors, and can be implemented in real-time (e.g., 50 Hz). Moreover, the RNN generates much smoother outputs than the nonlinear solver. We provide an analysis of the stability and robustness of the overall closed-loop system. Simulation and experiments are also presented to demonstrate the effectiveness of the proposed method.
Learning Statistical Texture for Semantic Segmentation
Mar 06, 2021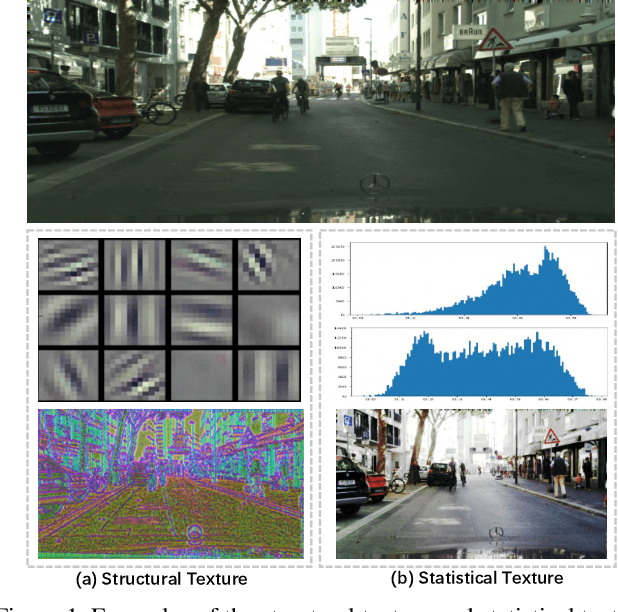
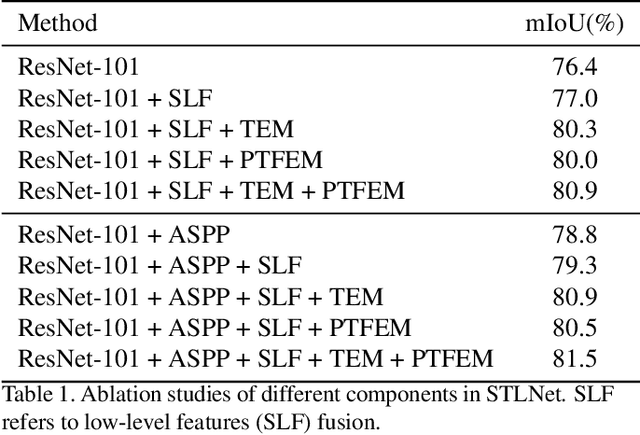
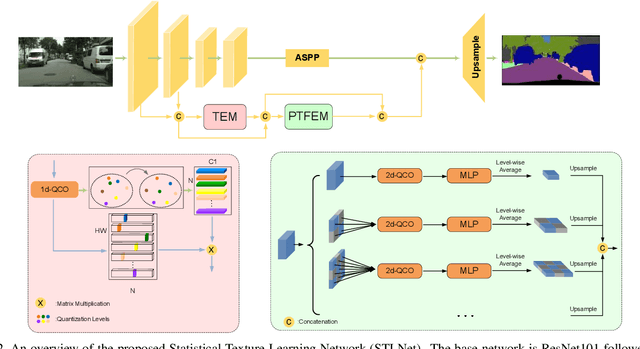

Existing semantic segmentation works mainly focus on learning the contextual information in high-level semantic features with CNNs. In order to maintain a precise boundary, low-level texture features are directly skip-connected into the deeper layers. Nevertheless, texture features are not only about local structure, but also include global statistical knowledge of the input image. In this paper, we fully take advantages of the low-level texture features and propose a novel Statistical Texture Learning Network (STLNet) for semantic segmentation. For the first time, STLNet analyzes the distribution of low level information and efficiently utilizes them for the task. Specifically, a novel Quantization and Counting Operator (QCO) is designed to describe the texture information in a statistical manner. Based on QCO, two modules are introduced: (1) Texture Enhance Module (TEM), to capture texture-related information and enhance the texture details; (2) Pyramid Texture Feature Extraction Module (PTFEM), to effectively extract the statistical texture features from multiple scales. Through extensive experiments, we show that the proposed STLNet achieves state-of-the-art performance on three semantic segmentation benchmarks: Cityscapes, PASCAL Context and ADE20K.
Power Modeling for Effective Datacenter Planning and Compute Management
Mar 22, 2021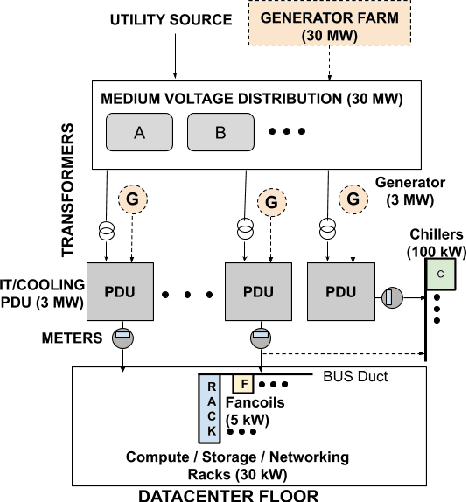
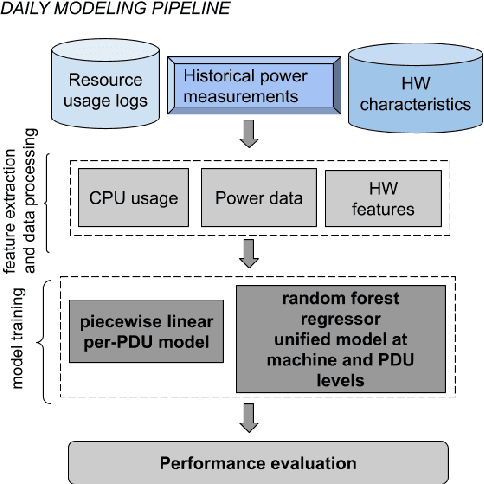
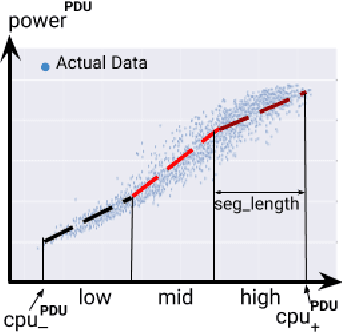
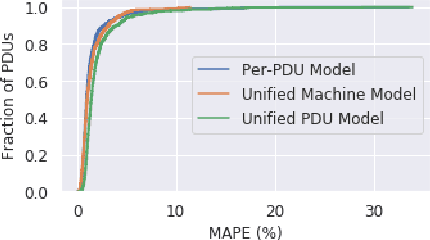
Datacenter power demand has been continuously growing and is the key driver of its cost. An accurate mapping of compute resources (CPU, RAM, etc.) and hardware types (servers, accelerators, etc.) to power consumption has emerged as a critical requirement for major Web and cloud service providers. With the global growth in datacenter capacity and associated power consumption, such models are essential for important decisions around datacenter design and operation. In this paper, we discuss two classes of statistical power models designed and validated to be accurate, simple, interpretable and applicable to all hardware configurations and workloads across hyperscale datacenters of Google fleet. To the best of our knowledge, this is the largest scale power modeling study of this kind, in both the scope of diverse datacenter planning and real-time management use cases, as well as the variety of hardware configurations and workload types used for modeling and validation. We demonstrate that the proposed statistical modeling techniques, while simple and scalable, predict power with less than 5% Mean Absolute Percent Error (MAPE) for more than 95% diverse Power Distribution Units (more than 2000) using only 4 features. This performance matches the reported accuracy of the previous started-of-the-art methods, while using significantly less features and covering a wider range of use cases.
Needmining: Designing Digital Support to Elicit Needs from Social Media
Jan 14, 2021


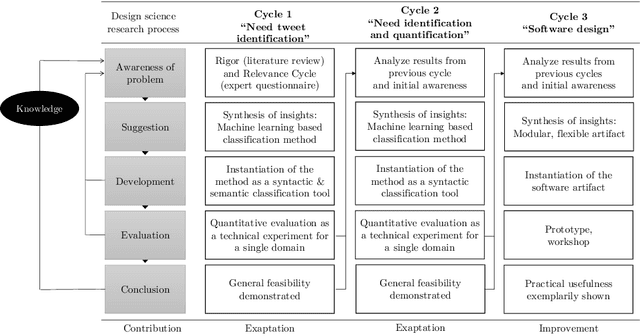
Today's businesses face a high pressure to innovate in order to succeed in highly competitive markets. Successful innovations, though, typically require the identification and analysis of customer needs. While traditional, established need elicitation methods are time-proven and have demonstrated their capabilities to deliver valuable insights, they lack automation and scalability and, thus, are expensive and time-consuming. In this article, we propose an approach to automatically identify and quantify customer needs by utilizing a novel data source: Users voluntarily and publicly expose information about themselves via social media, as for instance Facebook or Twitter. These posts may contain valuable information about the needs, wants, and demands of their authors. We apply a Design Science Research (DSR) methodology to add design knowledge and artifacts for the digitalization of innovation processes, in particular to provide digital support for the elicitation of customer needs. We want to investigate whether automated, speedy, and scalable need elicitation from social media is feasible. We concentrate on Twitter as a data source and on e-mobility as an application domain. In a first design cycle we conceive, implement and evaluate a method to demonstrate the feasibility of identifying those social media posts that actually express customer needs. In a second cycle, we build on this artifact to additionally quantify the need information elicited, and prove its feasibility. Third, we integrate both developed methods into an end-user software artifact and test usability in an industrial use case. Thus, we add new methods for need elicitation to the body of knowledge, and introduce concrete tooling for innovation management in practice.
Real-Time Inference of User Types to Assist with More Inclusive Social Media Activism Campaigns
Apr 25, 2018
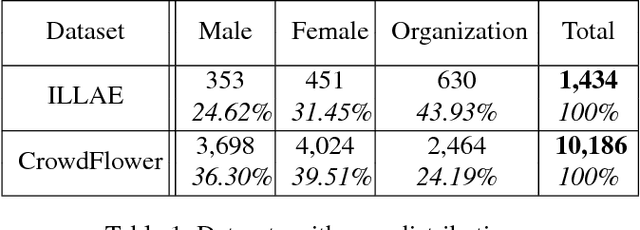
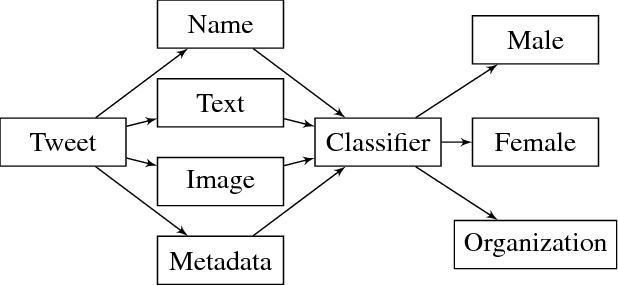
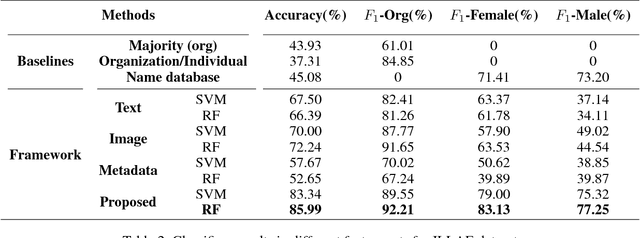
Social media provides a mechanism for people to engage with social causes across a range of issues. It also provides a strategic tool to those looking to advance a cause to exchange, promote or publicize their ideas. In such instances, AI can be either an asset if used appropriately or a barrier. One of the key issues for a workforce diversity campaign is to understand in real-time who is participating - specifically, whether the participants are individuals or organizations, and in case of individuals, whether they are male or female. In this paper, we present a study to demonstrate a case for AI for social good that develops a model to infer in real-time the different user types participating in a cause-driven hashtag campaign on Twitter, ILookLikeAnEngineer (ILLAE). A generic framework is devised to classify a Twitter user into three classes: organization, male and female in a real-time manner. The framework is tested against two datasets (ILLAE and a general dataset) and outperforms the baseline binary classifiers for categorizing organization/individual and male/female. The proposed model can be applied to future social cause-driven campaigns to get real-time insights on the macro-level social behavior of participants.
Stability and Generalization of the Decentralized Stochastic Gradient Descent
Feb 09, 2021
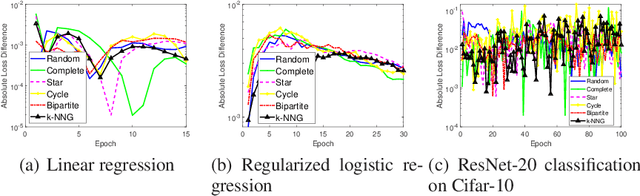
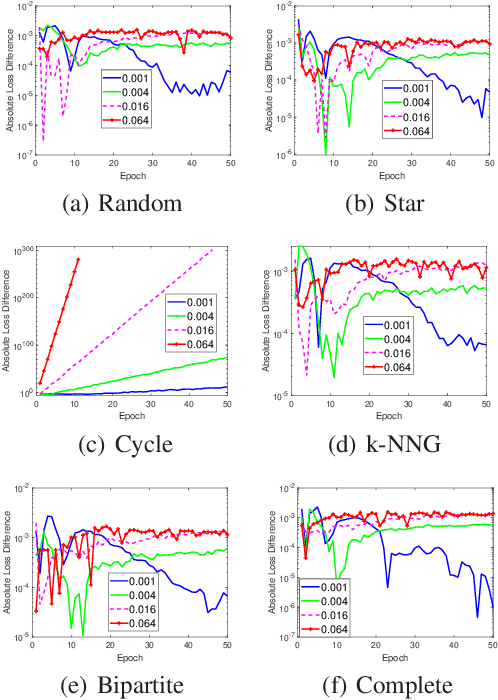
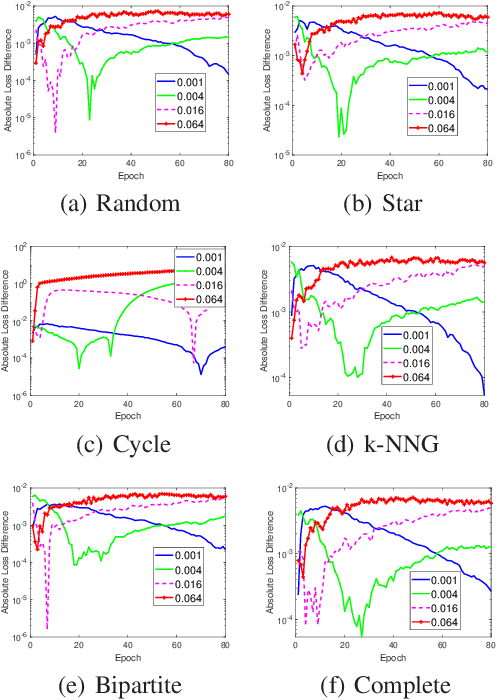
The stability and generalization of stochastic gradient-based methods provide valuable insights into understanding the algorithmic performance of machine learning models. As the main workhorse for deep learning, stochastic gradient descent has received a considerable amount of studies. Nevertheless, the community paid little attention to its decentralized variants. In this paper, we provide a novel formulation of the decentralized stochastic gradient descent. Leveraging this formulation together with (non)convex optimization theory, we establish the first stability and generalization guarantees for the decentralized stochastic gradient descent. Our theoretical results are built on top of a few common and mild assumptions and reveal that the decentralization deteriorates the stability of SGD for the first time. We verify our theoretical findings by using a variety of decentralized settings and benchmark machine learning models.
Restless-UCB, an Efficient and Low-complexity Algorithm for Online Restless Bandits
Nov 06, 2020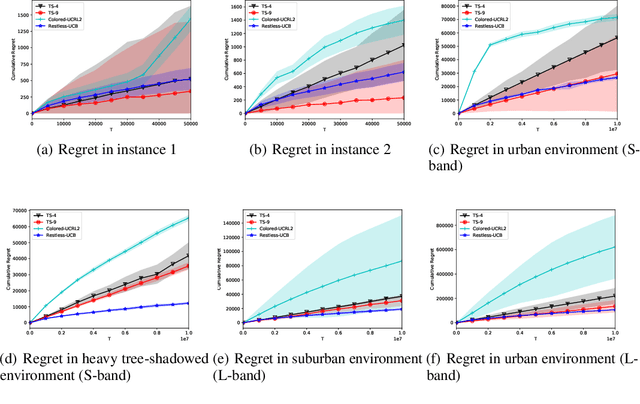
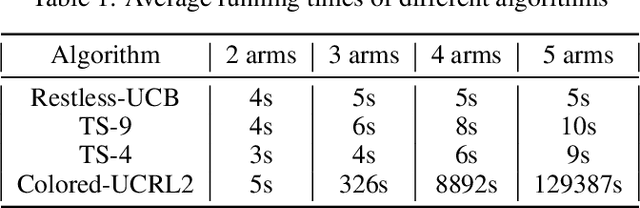
We study the online restless bandit problem, where the state of each arm evolves according to a Markov chain, and the reward of pulling an arm depends on both the pulled arm and the current state of the corresponding Markov chain. In this paper, we propose Restless-UCB, a learning policy that follows the explore-then-commit framework. In Restless-UCB, we present a novel method to construct offline instances, which only requires $O(N)$ time-complexity ($N$ is the number of arms) and is exponentially better than the complexity of existing learning policy. We also prove that Restless-UCB achieves a regret upper bound of $\tilde{O}((N+M^3)T^{2\over 3})$, where $M$ is the Markov chain state space size and $T$ is the time horizon. Compared to existing algorithms, our result eliminates the exponential factor (in $M,N$) in the regret upper bound, due to a novel exploitation of the sparsity in transitions in general restless bandit problems. As a result, our analysis technique can also be adopted to tighten the regret bounds of existing algorithms. Finally, we conduct experiments based on real-world dataset, to compare the Restless-UCB policy with state-of-the-art benchmarks. Our results show that Restless-UCB outperforms existing algorithms in regret, and significantly reduces the running time.