 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Bandit Learning for Dynamic Colonel Blotto Game with a Budget Constraint
Mar 23, 2021
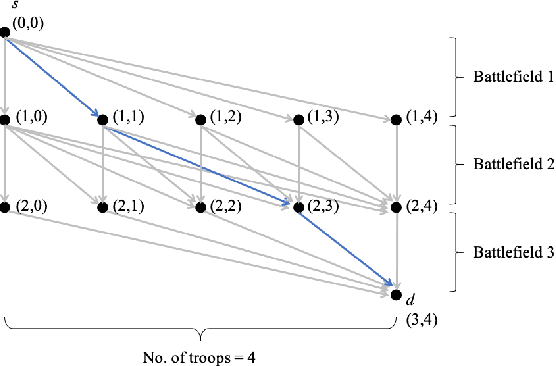
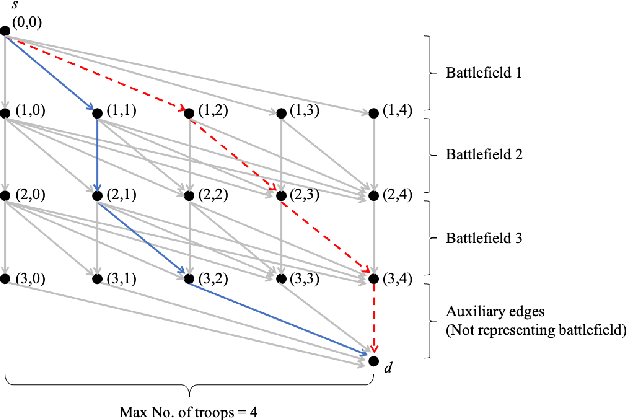
We consider a dynamic Colonel Blotto game (CBG) in which one of the players is the learner and has limited troops (budget) to allocate over a finite time horizon. At each stage, the learner strategically determines the budget and its distribution to allocate among the battlefields based on past observations. The other player is the adversary, who chooses its budget allocation strategies randomly from some fixed but unknown distribution. The learner's objective is to minimize the regret, which is defined as the difference between the optimal payoff in terms of the best dynamic policy and the realized payoff by following a learning algorithm. The dynamic CBG is analyzed under the framework of combinatorial bandit and bandit with knapsacks. We first convert the dynamic CBG with the budget constraint to a path planning problem on a graph. We then devise an efficient dynamic policy for the learner that uses a combinatorial bandit algorithm Edge on the path planning graph as a subroutine for another algorithm LagrangeBwK. A high-probability regret bound is derived, and it is shown that under the proposed policy, the learner's regret in the budget-constrained dynamic CBG matches (up to a logarithmic factor) that of the repeated CBG without budget constraints.
Escaping the Big Data Paradigm with Compact Transformers
Apr 12, 2021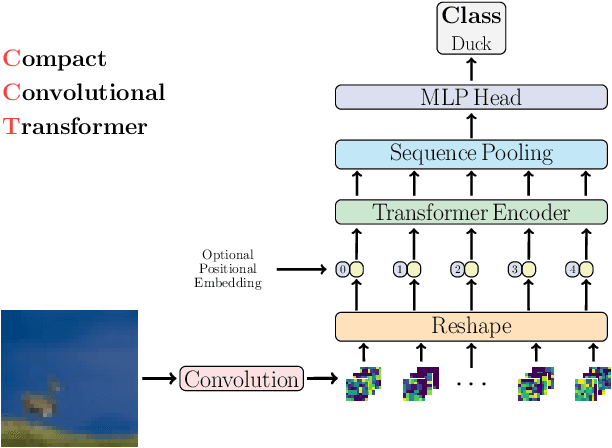
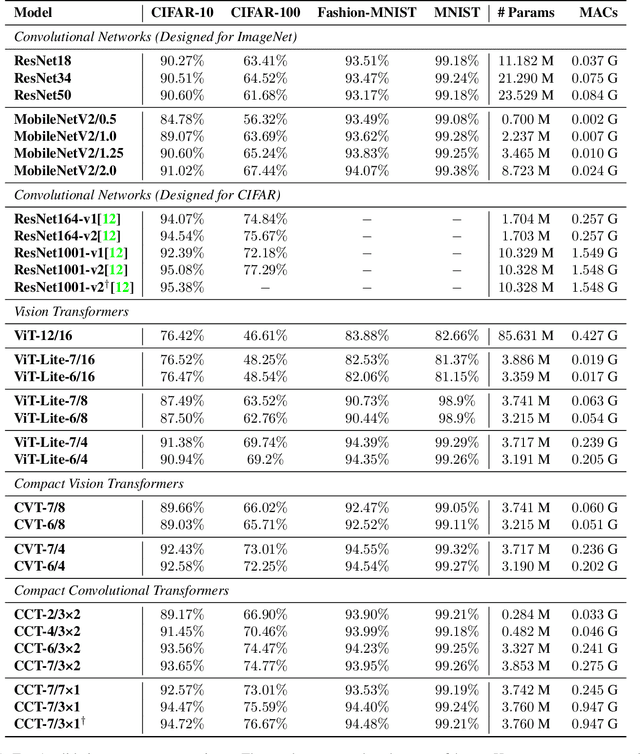
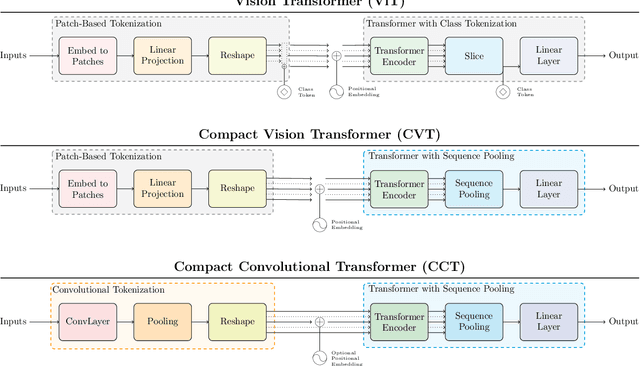
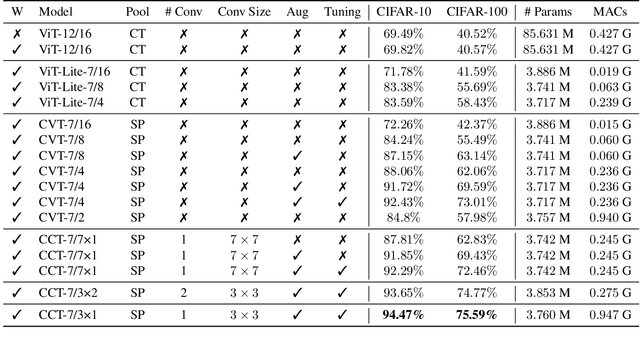
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, along with their unprecedented size and amounts of training data, many have come to believe that they are not suitable for small sets of data. This trend leads to great concerns, including but not limited to: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we dispel the myth that transformers are "data hungry" and therefore can only be applied to large sets of data. We show for the first time that with the right size and tokenization, transformers can perform head-to-head with state-of-the-art CNNs on small datasets. Our model eliminates the requirement for class token and positional embeddings through a novel sequence pooling strategy and the use of convolutions. We show that compared to CNNs, our compact transformers have fewer parameters and MACs, while obtaining similar accuracies. Our method is flexible in terms of model size, and can have as little as 0.28M parameters and achieve reasonable results. It can reach an accuracy of 94.72% when training from scratch on CIFAR-10, which is comparable with modern CNN based approaches, and a significant improvement over previous Transformer based models. Our simple and compact design democratizes transformers by making them accessible to those equipped with basic computing resources and/or dealing with important small datasets. Our code and pre-trained models will be made publicly available at https://github.com/SHI-Labs/Compact-Transformers.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021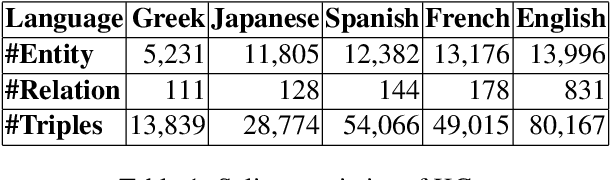
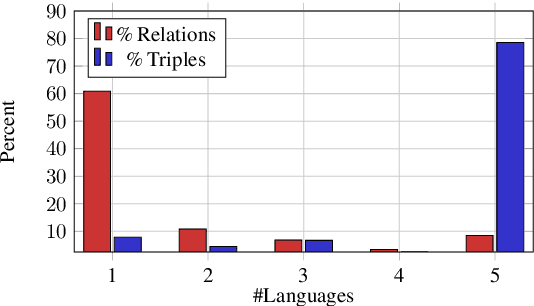
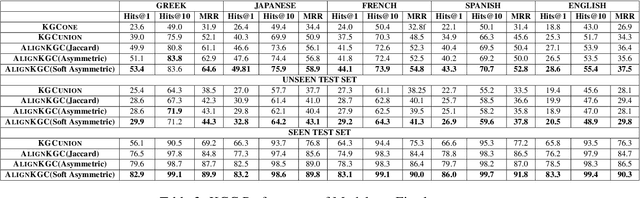

Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
Two Birds with One Network: Unifying Failure Event Prediction and Time-to-failure Modeling
Dec 18, 2018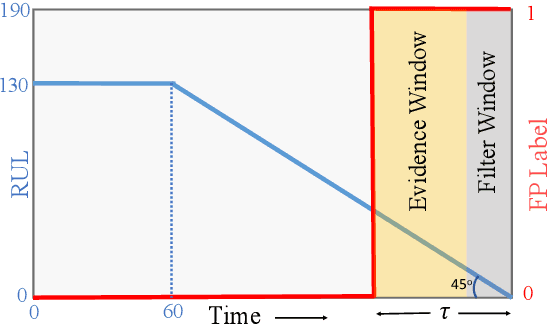
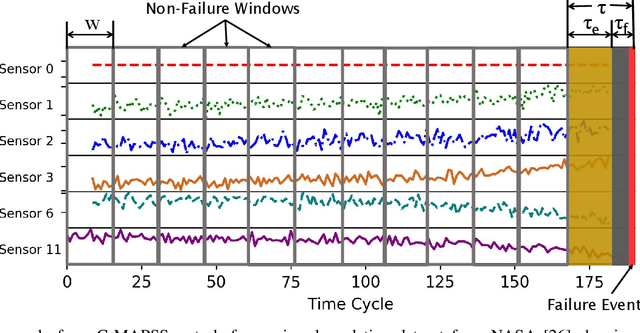
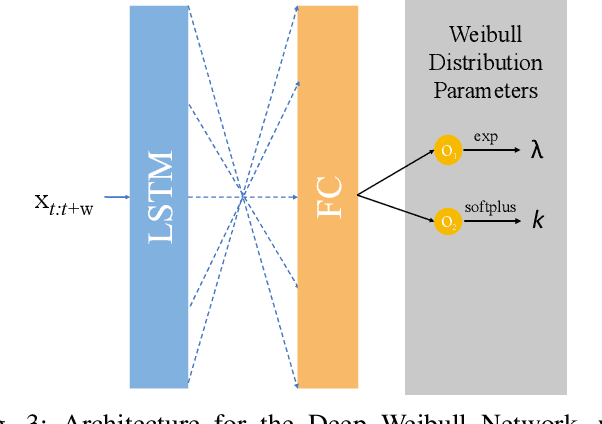
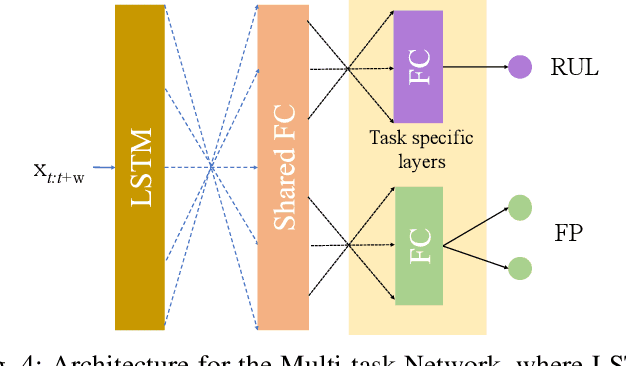
One of the key challenges in predictive maintenance is to predict the impending downtime of an equipment with a reasonable prediction horizon so that countermeasures can be put in place. Classically, this problem has been posed in two different ways which are typically solved independently: (1) Remaining useful life (RUL) estimation as a long-term prediction task to estimate how much time is left in the useful life of the equipment and (2) Failure prediction (FP) as a short-term prediction task to assess the probability of a failure within a pre-specified time window. As these two tasks are related, performing them separately is sub-optimal and might results in inconsistent predictions for the same equipment. In order to alleviate these issues, we propose two methods: Deep Weibull model (DW-RNN) and multi-task learning (MTL-RNN). DW-RNN is able to learn the underlying failure dynamics by fitting Weibull distribution parameters using a deep neural network, learned with a survival likelihood, without training directly on each task. While DW-RNN makes an explicit assumption on the data distribution, MTL-RNN exploits the implicit relationship between the long-term RUL and short-term FP tasks to learn the underlying distribution. Additionally, both our methods can leverage the non-failed equipment data for RUL estimation. We demonstrate that our methods consistently outperform baseline RUL methods that can be used for FP while producing consistent results for RUL and FP. We also show that our methods perform at par with baselines trained on the objectives optimized for either of the two tasks.
SLOE: A Faster Method for Statistical Inference in High-Dimensional Logistic Regression
Mar 23, 2021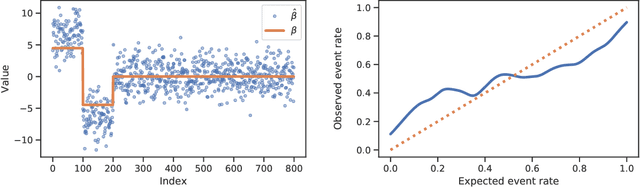
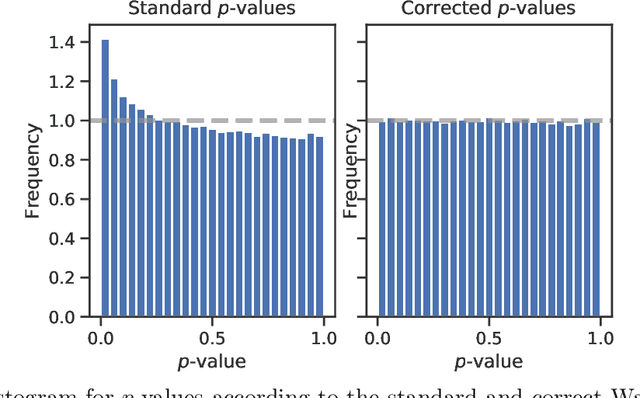
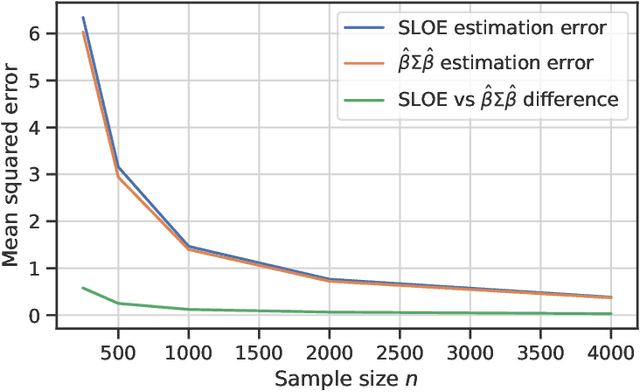
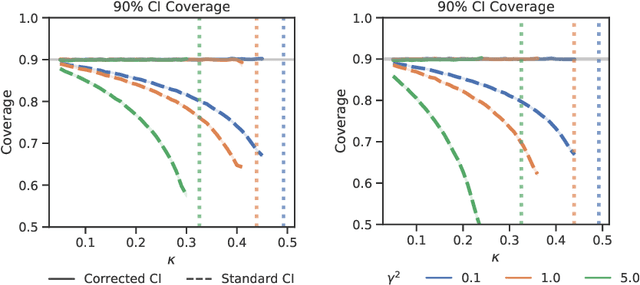
Logistic regression remains one of the most widely used tools in applied statistics, machine learning and data science. Practical datasets often have a substantial number of features $d$ relative to the sample size $n$. In these cases, the logistic regression maximum likelihood estimator (MLE) is biased, and its standard large-sample approximation is poor. In this paper, we develop an improved method for debiasing predictions and estimating frequentist uncertainty for such datasets. We build on recent work characterizing the asymptotic statistical behavior of the MLE in the regime where the aspect ratio $d / n$, instead of the number of features $d$, remains fixed as $n$ grows. In principle, this approximation facilitates bias and uncertainty corrections, but in practice, these corrections require an estimate of the signal strength of the predictors. Our main contribution is SLOE, an estimator of the signal strength with convergence guarantees that reduces the computation time of estimation and inference by orders of magnitude. The bias correction that this facilitates also reduces the variance of the predictions, yielding narrower confidence intervals with higher (valid) coverage of the true underlying probabilities and parameters. We provide an open source package for this method, available at https://github.com/google-research/sloe-logistic.
Super-Resolution based on Image-Adapted CNN Denoisers: Incorporating Generalization of Training Data and Internal Learning in Test Time
Nov 30, 2018
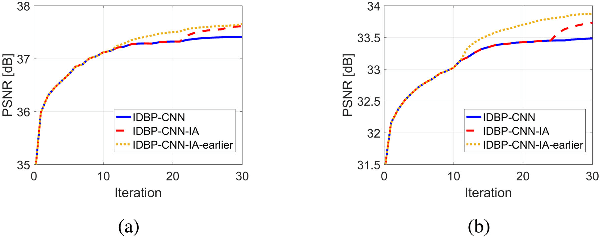
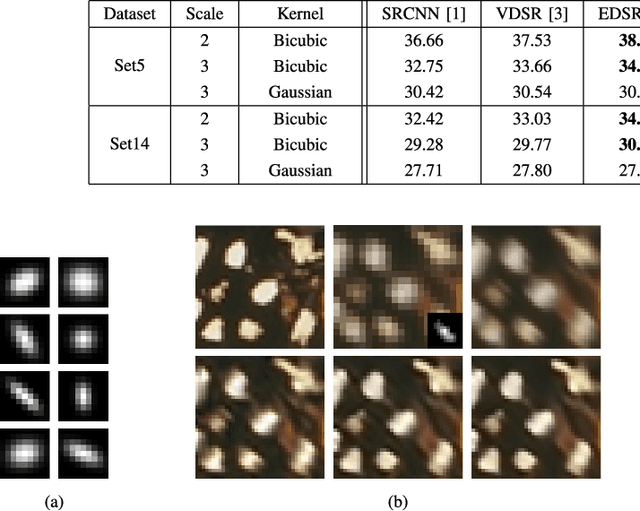
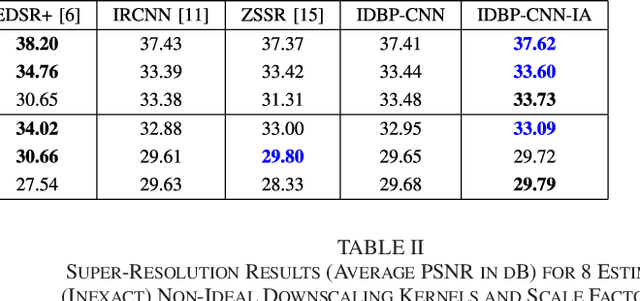
While deep neural networks exhibit state-of-the-art results in the task of image super-resolution (SR) with a fixed known acquisition process (e.g., a bicubic downscaling kernel), they experience a huge performance loss when the real observation model mismatches the one used in training. Recently, two different techniques suggested to mitigate this deficiency, i.e., enjoy the advantages of deep learning without being restricted by the prior training. The first one follows the plug-and-play (P&P) approach that solves general inverse problems (e.g., SR) by plugging Gaussian denoisers into model-based optimization schemes. The second builds on internal recurrence of information inside a single image, and trains a super-resolver network at test time on examples synthesized from the low-resolution image. Our work incorporates the two strategies, enjoying the impressive generalization capabilities of deep learning, captured by the first, and further improving it through internal learning at test time. First, we apply a recent P&P strategy to SR. Then, we show how it may become image-adaptive in test time. This technique outperforms the above two strategies on popular datasets and gives better results than other state-of-the-art methods on real images.
Social Networks Analysis to Retrieve Critical Comments on Online Platforms
Feb 21, 2021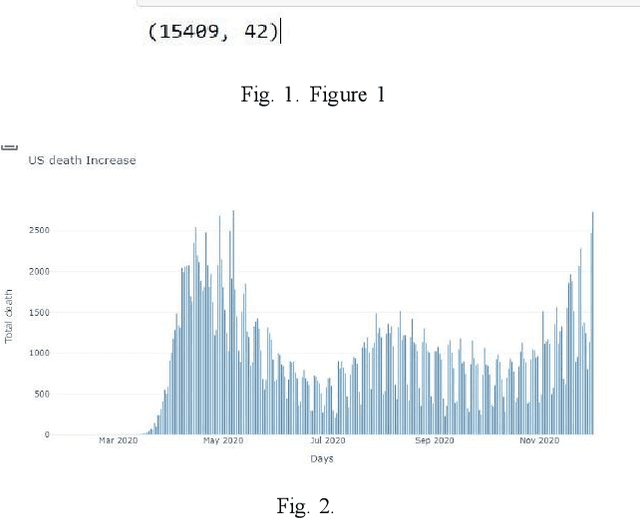
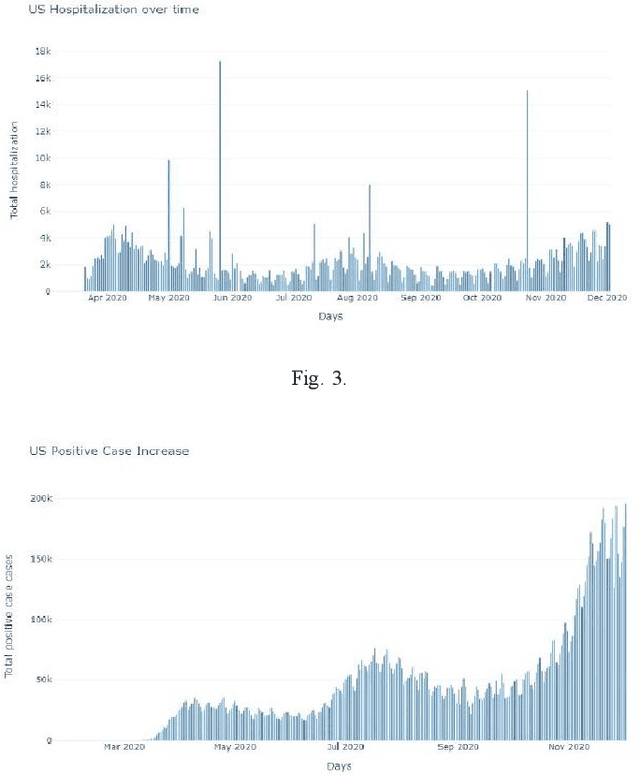
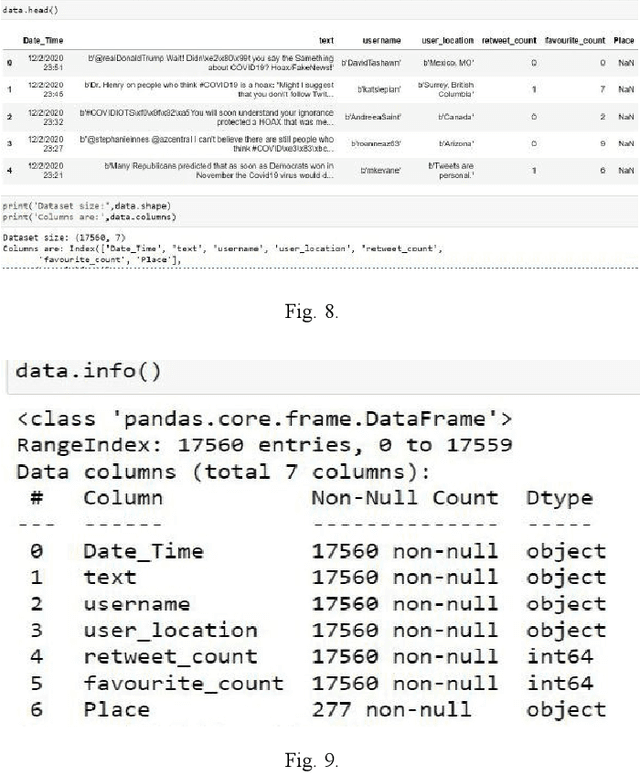

Social networks are rich source of data to analyze user habits in all aspects of life. User's behavior is decisive component of a health system in various countries. Promoting good behavior can improve the public health significantly. In this work, we develop a new model for social network analysis by using text analysis approach. We define each user reaction to global pandemic with analyzing his online behavior. Clustering a group of online users with similar habits, help to find how virus spread in different societies. Promoting the healthy life style in the high risk online users of social media have significant effect on public health and reducing the effect of global pandemic. In this work, we introduce a new approach to clustering habits based on user activities on social media in the time of pandemic and recommend a machine learning model to promote health in the online platforms.
Denoise and Contrast for Category Agnostic Shape Completion
Mar 30, 2021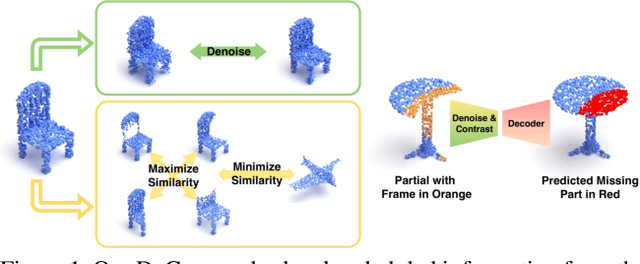
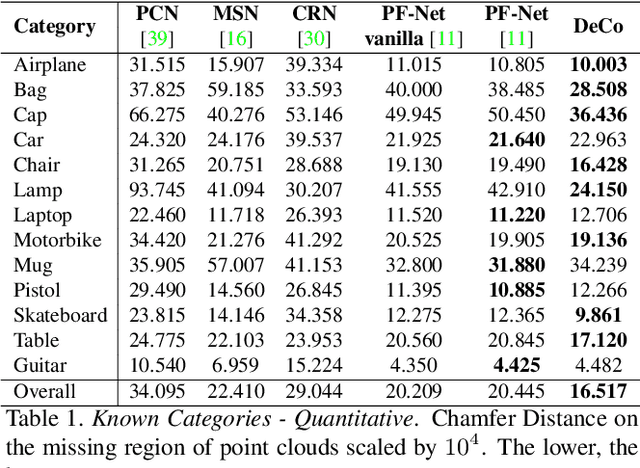
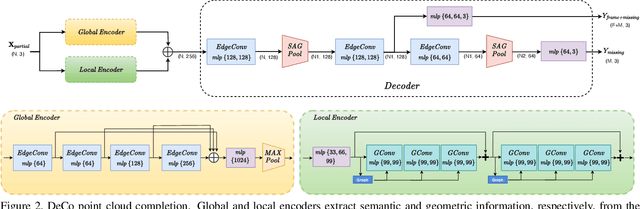
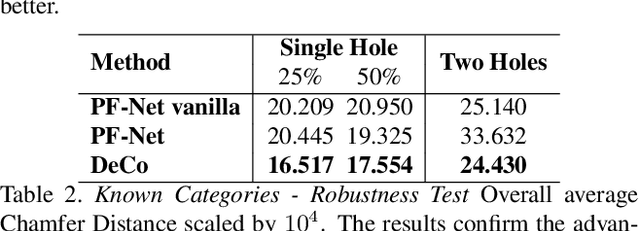
In this paper, we present a deep learning model that exploits the power of self-supervision to perform 3D point cloud completion, estimating the missing part and a context region around it. Local and global information are encoded in a combined embedding. A denoising pretext task provides the network with the needed local cues, decoupled from the high-level semantics and naturally shared over multiple classes. On the other hand, contrastive learning maximizes the agreement between variants of the same shape with different missing portions, thus producing a representation which captures the global appearance of the shape. The combined embedding inherits category-agnostic properties from the chosen pretext tasks. Differently from existing approaches, this allows to better generalize the completion properties to new categories unseen at training time. Moreover, while decoding the obtained joint representation, we better blend the reconstructed missing part with the partial shape by paying attention to its known surrounding region and reconstructing this frame as auxiliary objective. Our extensive experiments and detailed ablation on the ShapeNet dataset show the effectiveness of each part of the method with new state of the art results. Our quantitative and qualitative analysis confirms how our approach is able to work on novel categories without relying neither on classification and shape symmetry priors, nor on adversarial training procedures.
The U-Net based GLOW for Optical-Flow-free Video Interframe Generation
Apr 06, 2021
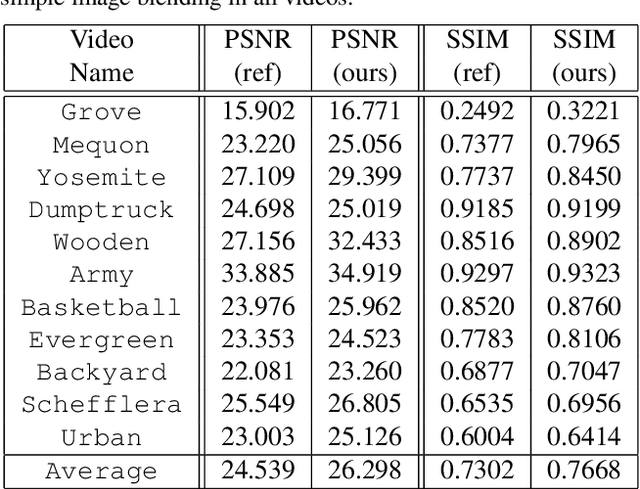
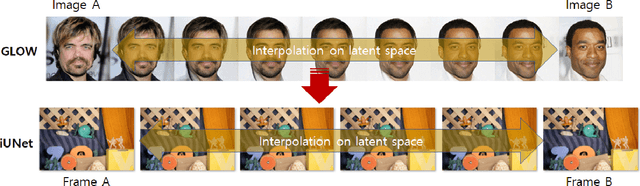
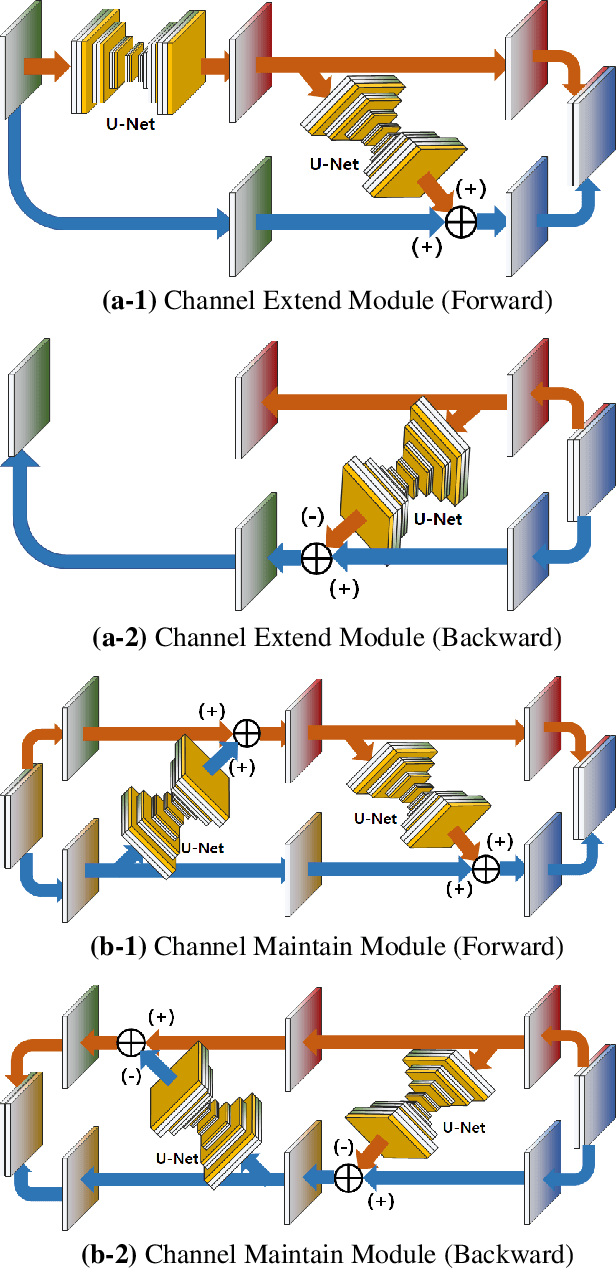
Video frame interpolation is the task of creating an interframe between two adjacent frames along the time axis. So, instead of simply averaging two adjacent frames to create an intermediate image, this operation should maintain semantic continuity with the adjacent frames. Most conventional methods use optical flow, and various tools such as occlusion handling and object smoothing are indispensable. Since the use of these various tools leads to complex problems, we tried to tackle the video interframe generation problem without using problematic optical flow . To enable this , we have tried to use a deep neural network with an invertible structure, and developed an U-Net based Generative Flow which is a modified normalizing flow. In addition, we propose a learning method with a new consistency loss in the latent space to maintain semantic temporal consistency between frames. The resolution of the generated image is guaranteed to be identical to that of the original images by using an invertible network. Furthermore, as it is not a random image like the ones by generative models, our network guarantees stable outputs without flicker. Through experiments, we \sam {confirmed the feasibility of the proposed algorithm and would like to suggest the U-Net based Generative Flow as a new possibility for baseline in video frame interpolation. This paper is meaningful in that it is the world's first attempt to use invertible networks instead of optical flows for video interpolation.
Grounding Physical Concepts of Objects and Events Through Dynamic Visual Reasoning
Mar 30, 2021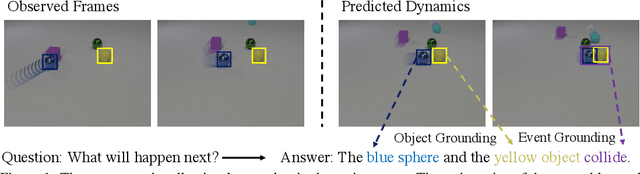
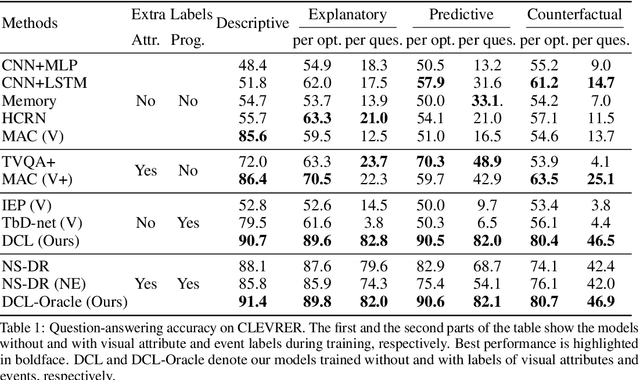
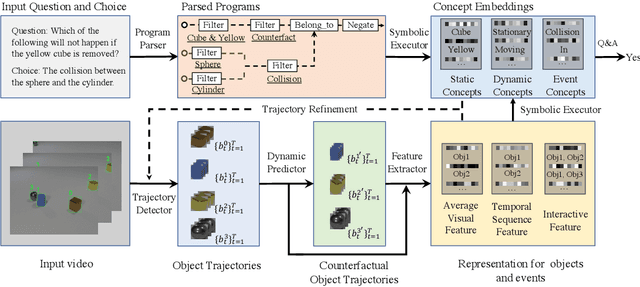

We study the problem of dynamic visual reasoning on raw videos. This is a challenging problem; currently, state-of-the-art models often require dense supervision on physical object properties and events from simulation, which are impractical to obtain in real life. In this paper, we present the Dynamic Concept Learner (DCL), a unified framework that grounds physical objects and events from video and language. DCL first adopts a trajectory extractor to track each object over time and to represent it as a latent, object-centric feature vector. Building upon this object-centric representation, DCL learns to approximate the dynamic interaction among objects using graph networks. DCL further incorporates a semantic parser to parse questions into semantic programs and, finally, a program executor to run the program to answer the question, levering the learned dynamics model. After training, DCL can detect and associate objects across the frames, ground visual properties, and physical events, understand the causal relationship between events, make future and counterfactual predictions, and leverage these extracted presentations for answering queries. DCL achieves state-of-the-art performance on CLEVRER, a challenging causal video reasoning dataset, even without using ground-truth attributes and collision labels from simulations for training. We further test DCL on a newly proposed video-retrieval and event localization dataset derived from CLEVRER, showing its strong generalization capacity.