 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Functional Space Analysis of Local GAN Convergence
Feb 08, 2021
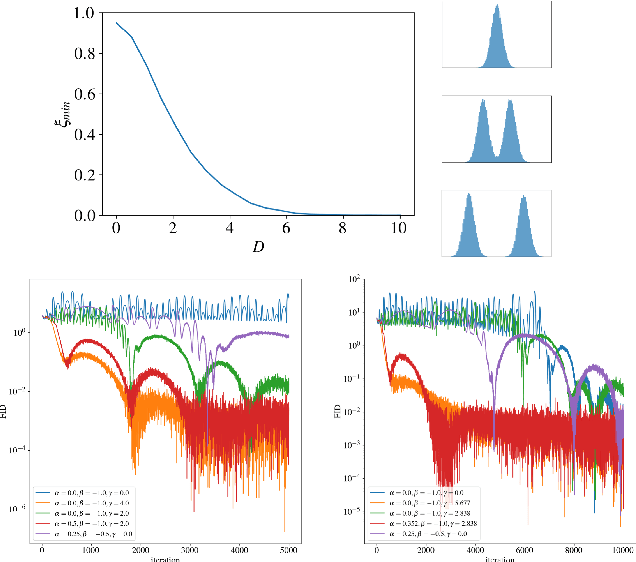


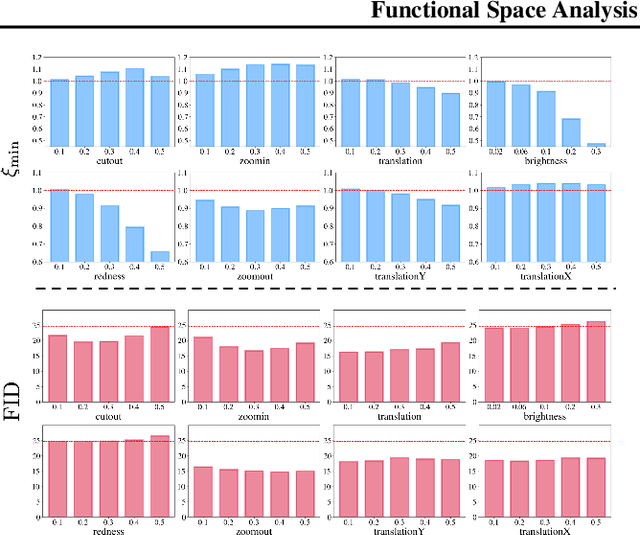
Recent work demonstrated the benefits of studying continuous-time dynamics governing the GAN training. However, this dynamics is analyzed in the model parameter space, which results in finite-dimensional dynamical systems. We propose a novel perspective where we study the local dynamics of adversarial training in the general functional space and show how it can be represented as a system of partial differential equations. Thus, the convergence properties can be inferred from the eigenvalues of the resulting differential operator. We show that these eigenvalues can be efficiently estimated from the target dataset before training. Our perspective reveals several insights on the practical tricks commonly used to stabilize GANs, such as gradient penalty, data augmentation, and advanced integration schemes. As an immediate practical benefit, we demonstrate how one can a priori select an optimal data augmentation strategy for a particular generation task.
Citation Sentiment Changes Analysis
Oct 01, 2020
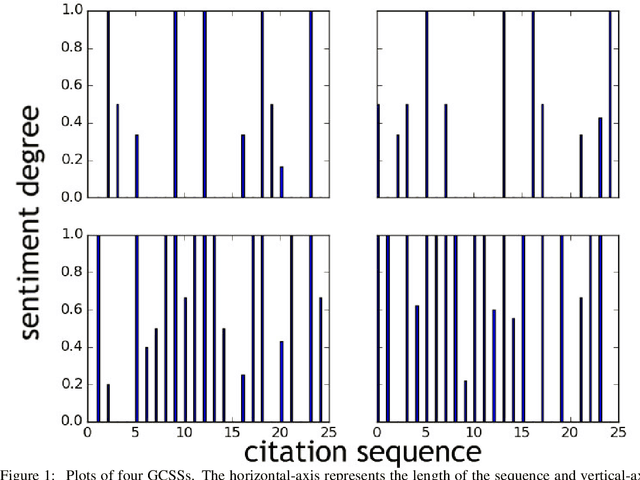

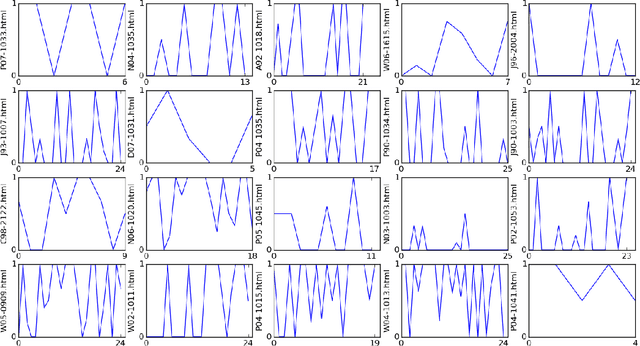
Metrics for measuring the citation sentiment changes were introduced. Citation sentiment changes can be observed from global citation sentiment sequences (GCSSs). With respect to a cited paper, the citation sentiment sequences were analysed across a collection of citing papers ordered by the published time. For analysing GCSSs, Eddy Dissipation Rate (EDR) was adopted, with the hypothesis that the GCSSs pattern differences can be spotted by EDR based method. Preliminary evidence showed that EDR based method holds the potential for analysing a publication's impact in a time series fashion.
Automatic design of novel potential 3CL$^{\text{pro}}$ and PL$^{\text{pro}}$ inhibitors
Jan 28, 2021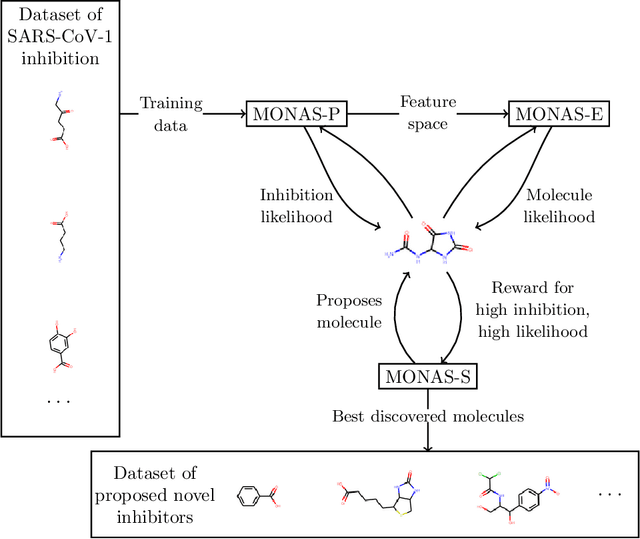
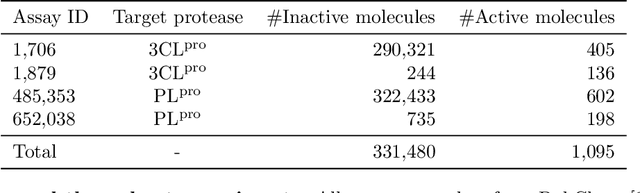
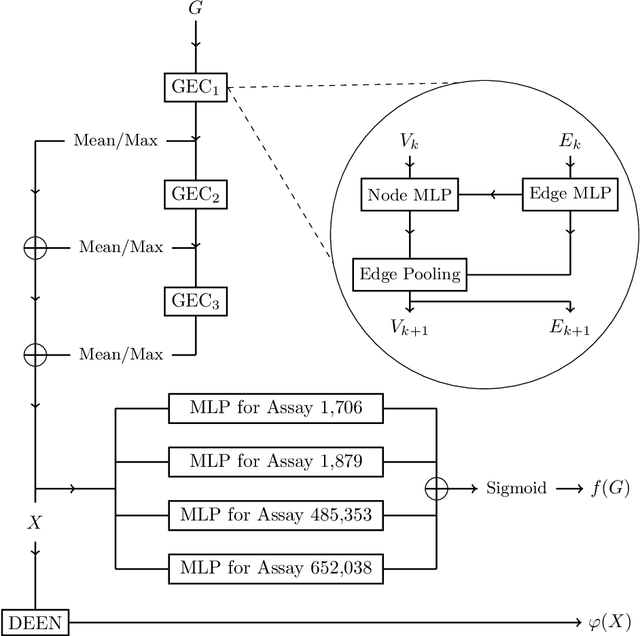
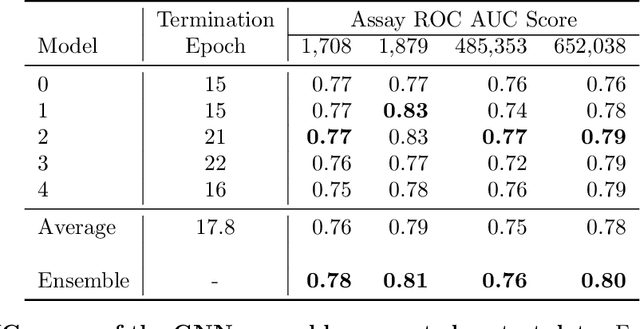
With the goal of designing novel inhibitors for SARS-CoV-1 and SARS-CoV-2, we propose the general molecule optimization framework, Molecular Neural Assay Search (MONAS), consisting of three components: a property predictor which identifies molecules with specific desirable properties, an energy model which approximates the statistical similarity of a given molecule to known training molecules, and a molecule search method. In this work, these components are instantiated with graph neural networks (GNNs), Deep Energy Estimator Networks (DEEN) and Monte Carlo tree search (MCTS), respectively. This implementation is used to identify 120K molecules (out of 40-million explored) which the GNN determined to be likely SARS-CoV-1 inhibitors, and, at the same time, are statistically close to the dataset used to train the GNN.
Benchmarks for Deep Off-Policy Evaluation
Mar 30, 2021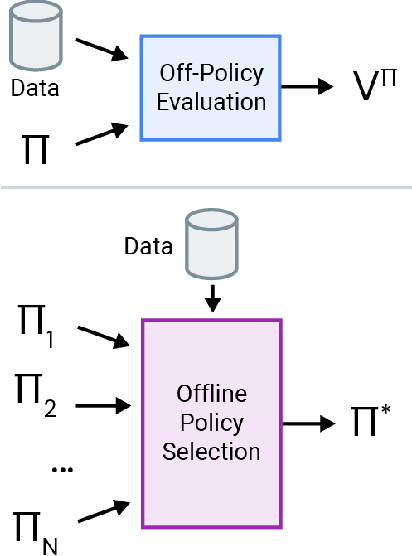
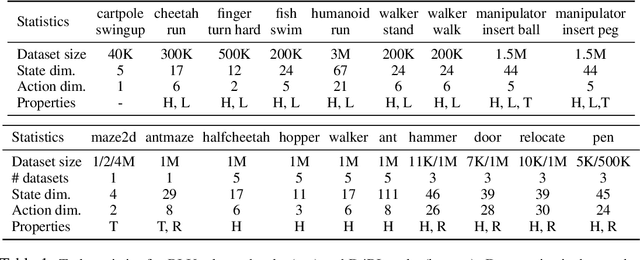
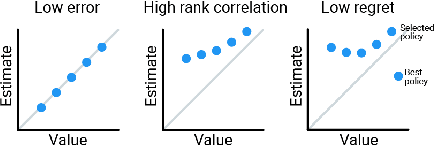
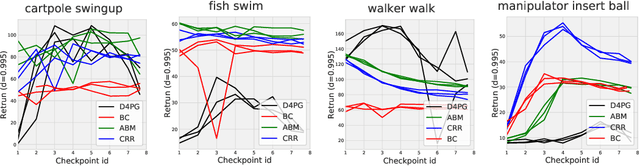
Off-policy evaluation (OPE) holds the promise of being able to leverage large, offline datasets for both evaluating and selecting complex policies for decision making. The ability to learn offline is particularly important in many real-world domains, such as in healthcare, recommender systems, or robotics, where online data collection is an expensive and potentially dangerous process. Being able to accurately evaluate and select high-performing policies without requiring online interaction could yield significant benefits in safety, time, and cost for these applications. While many OPE methods have been proposed in recent years, comparing results between papers is difficult because currently there is a lack of a comprehensive and unified benchmark, and measuring algorithmic progress has been challenging due to the lack of difficult evaluation tasks. In order to address this gap, we present a collection of policies that in conjunction with existing offline datasets can be used for benchmarking off-policy evaluation. Our tasks include a range of challenging high-dimensional continuous control problems, with wide selections of datasets and policies for performing policy selection. The goal of our benchmark is to provide a standardized measure of progress that is motivated from a set of principles designed to challenge and test the limits of existing OPE methods. We perform an evaluation of state-of-the-art algorithms and provide open-source access to our data and code to foster future research in this area.
Insight about Detection, Prediction and Weather Impact of Coronavirus (Covid-19) using Neural Network
Apr 05, 2021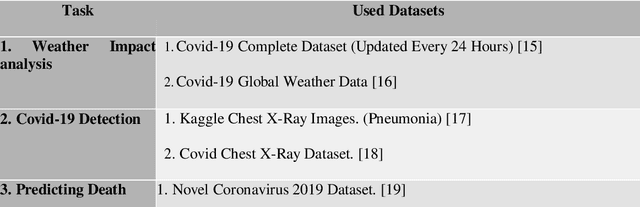
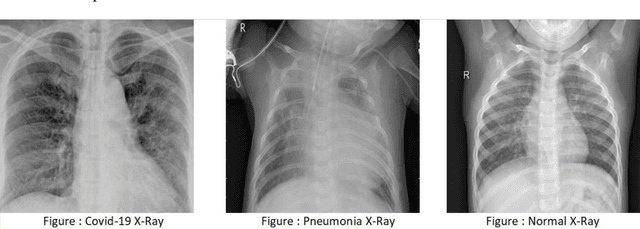
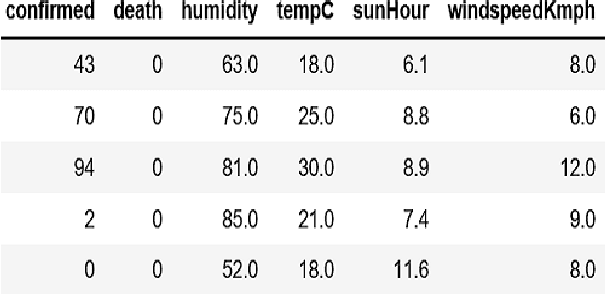

The world is facing a tough situation due to the catastrophic pandemic caused by novel coronavirus (COVID-19). The number people affected by this virus are increasing exponentially day by day and the number has already crossed 6.4 million. As no vaccine has been discovered yet, the early detection of patients and isolation is the only and most effective way to reduce the spread of the virus. Detecting infected persons from chest X-Ray by using Deep Neural Networks, can be applied as a time and laborsaving solution. In this study, we tried to detect Covid-19 by classification of Covid-19, pneumonia and normal chest X-Rays. We used five different Convolutional Pre-Trained Neural Network models (VGG16, VGG19, Xception, InceptionV3 and Resnet50) and compared their performance. VGG16 and VGG19 shows precise performance in classification. Both models can classify between three kinds of X-Rays with an accuracy over 92%. Another part of our study was to find the impact of weather factors (temperature, humidity, sun hour and wind speed) on this pandemic using Decision Tree Regressor. We found that temperature, humidity and sun-hour jointly hold 85.88% impact on escalation of Covid-19 and 91.89% impact on death due to Covid-19 where humidity has 8.09% impact on death. We also tried to predict the death of an individual based on age, gender, country, and location due to COVID-19 using the LogisticRegression, which can predict death of an individual with a model accuracy of 94.40%.
* 15 Pages, 13 Figures and 4 Tables
Learning-Based Phase Compression and Quantization for Massive MIMO CSI Feedback with Magnitude-Aided Information
Feb 28, 2021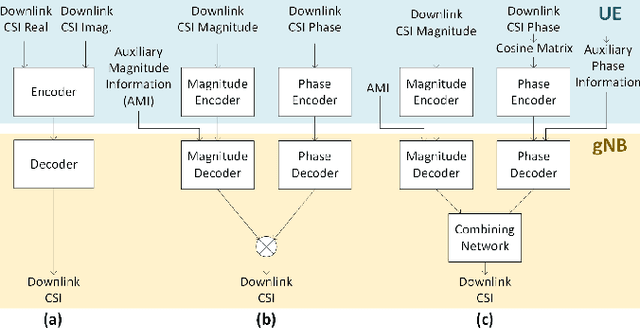
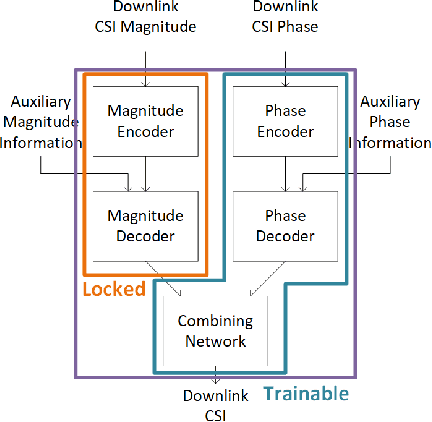
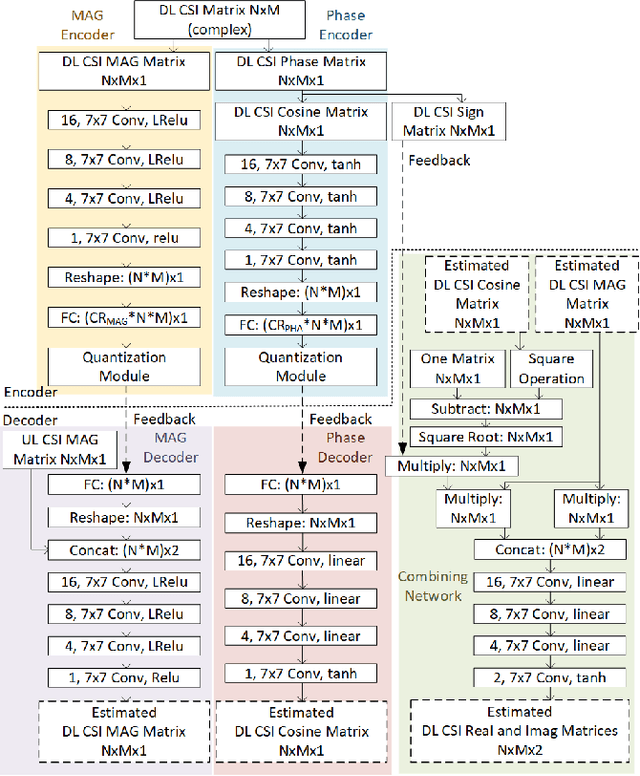
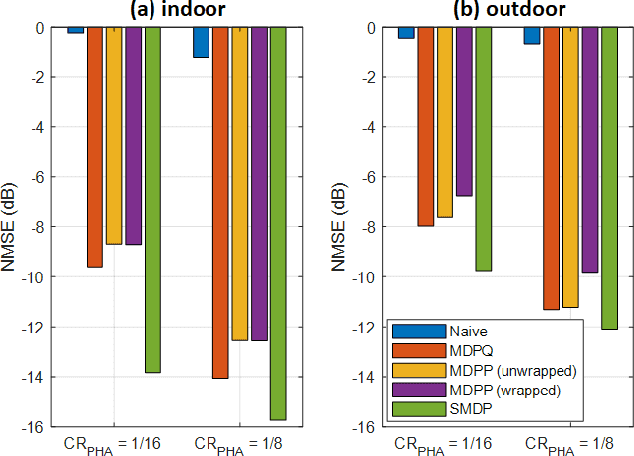
In frequency-division duplexing (FDD) massive multiple-input multiple-output (MIMO) wireless systems, deep learning techniques are regarded as one of the most efficient solutions for CSI recovery. In recent times, to achieve better CSI magnitude recovery at base stations, advanced learning-based CSI feedback solutions decouple magnitude and phase recovery to fully leverage the strong correlation between current CSI magnitudes and those of previous time slots, uplink band, and near locations. However, the CSI phase recovery is a major challenge to further enhance the CSI recovery owing to its complicated patterns. In this letter, we propose a learning-based CSI feedback framework based on limited feedback and magnitude-aided information. In contrast to previous works, our proposed framework with a proposed loss function enables end-to-end learning to jointly optimize the CSI magnitude and phase recovery performance. Numerical simulations show that, the proposed loss function outperform alternate approaches for phase recovery over the overall CSI recovery in both indoor and outdoor scenarios. The performance of the proposed framework was also examined using different core layer designs.
Deep Transfer Learning for WiFi Localization
Mar 08, 2021
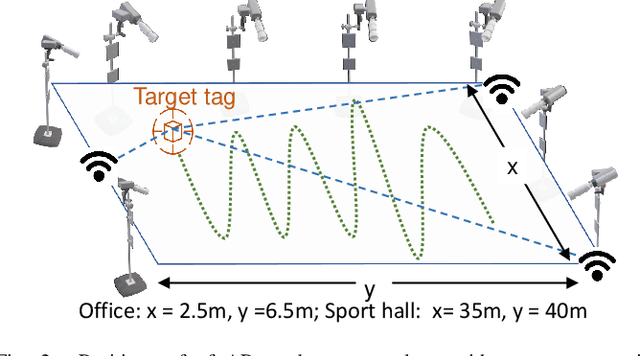
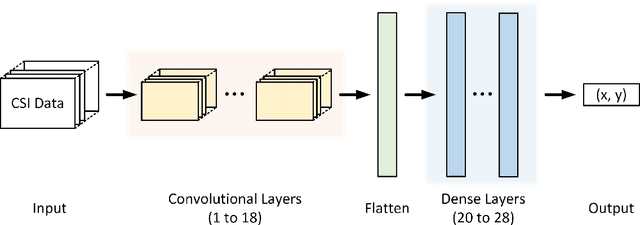
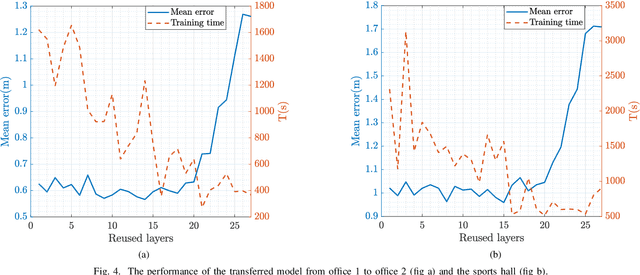
This paper studies a WiFi indoor localisation technique based on using a deep learning model and its transfer strategies. We take CSI packets collected via the WiFi standard channel sounding as the training dataset and verify the CNN model on the subsets collected in three experimental environments. We achieve a localisation accuracy of 46.55 cm in an ideal $(6.5m \times 2.5m)$ office with no obstacles, 58.30 cm in an office with obstacles, and 102.8 cm in a sports hall $(40 \times 35m)$. Then, we evaluate the transfer ability of the proposed model to different environments. The experimental results show that, for a trained localisation model, feature extraction layers can be directly transferred to other models and only the fully connected layers need to be retrained to achieve the same baseline accuracy with non-transferred base models. This can save 60% of the training parameters and reduce the training time by more than half. Finally, an ablation study of the training dataset shows that, in both office and sport hall scenarios, after reusing the feature extraction layers of the base model, only 55% of the training data is required to obtain the models' accuracy similar to the base models.
ThetA -- fast and robust clustering via a distance parameter
Feb 13, 2021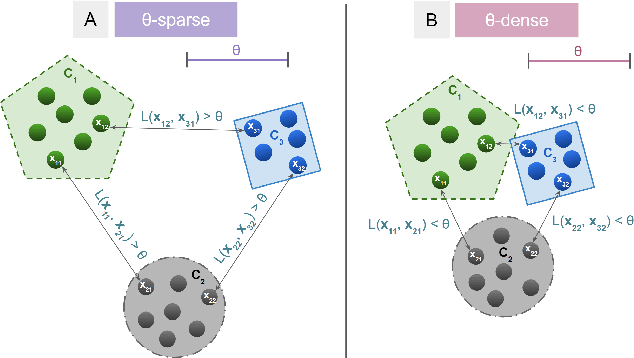
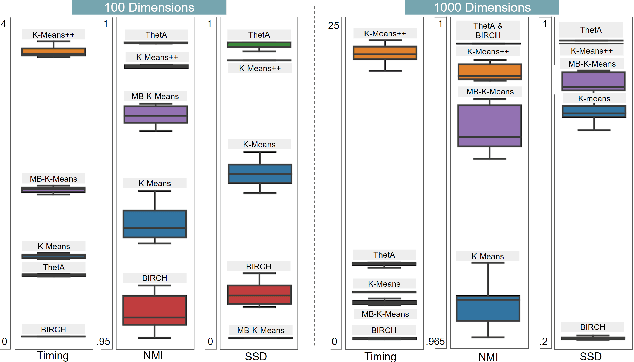
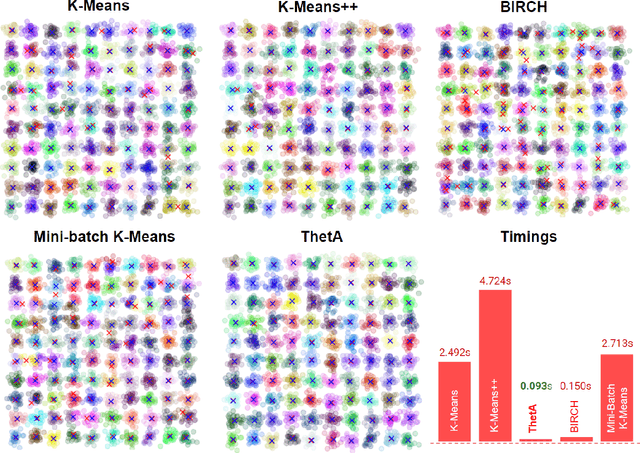
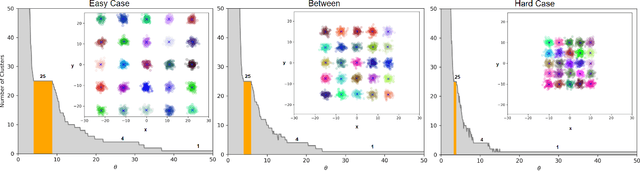
Clustering is a fundamental problem in machine learning where distance-based approaches have dominated the field for many decades. This set of problems is often tackled by partitioning the data into K clusters where the number of clusters is chosen apriori. While significant progress has been made on these lines over the years, it is well established that as the number of clusters or dimensions increase, current approaches dwell in local minima resulting in suboptimal solutions. In this work, we propose a new set of distance threshold methods called Theta-based Algorithms (ThetA). Via experimental comparisons and complexity analyses we show that our proposed approach outperforms existing approaches in: a) clustering accuracy and b) time complexity. Additionally, we show that for a large class of problems, learning the optimal threshold is straightforward in comparison to learning K. Moreover, we show how ThetA can infer the sparsity of datasets in higher dimensions.
Fast and Accurate Time Series Classification with WEASEL
Jan 26, 2017
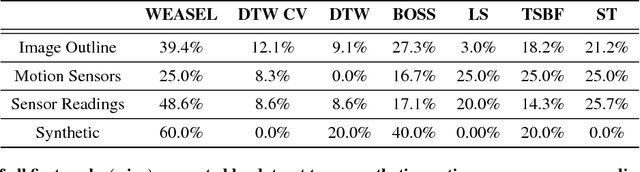
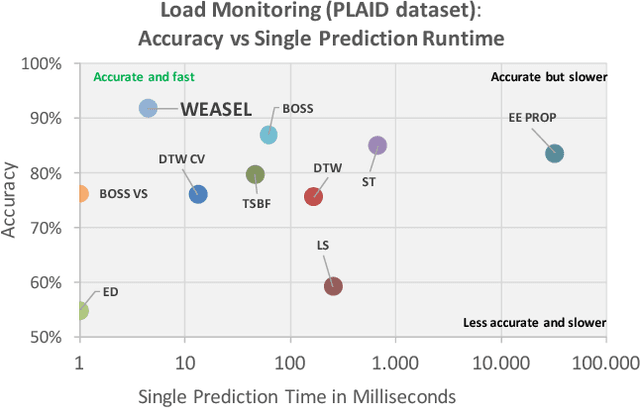
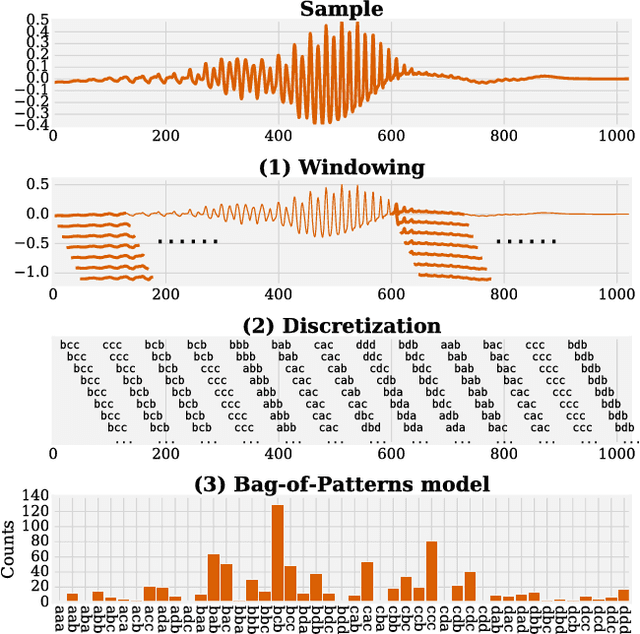
Time series (TS) occur in many scientific and commercial applications, ranging from earth surveillance to industry automation to the smart grids. An important type of TS analysis is classification, which can, for instance, improve energy load forecasting in smart grids by detecting the types of electronic devices based on their energy consumption profiles recorded by automatic sensors. Such sensor-driven applications are very often characterized by (a) very long TS and (b) very large TS datasets needing classification. However, current methods to time series classification (TSC) cannot cope with such data volumes at acceptable accuracy; they are either scalable but offer only inferior classification quality, or they achieve state-of-the-art classification quality but cannot scale to large data volumes. In this paper, we present WEASEL (Word ExtrAction for time SEries cLassification), a novel TSC method which is both scalable and accurate. Like other state-of-the-art TSC methods, WEASEL transforms time series into feature vectors, using a sliding-window approach, which are then analyzed through a machine learning classifier. The novelty of WEASEL lies in its specific method for deriving features, resulting in a much smaller yet much more discriminative feature set. On the popular UCR benchmark of 85 TS datasets, WEASEL is more accurate than the best current non-ensemble algorithms at orders-of-magnitude lower classification and training times, and it is almost as accurate as ensemble classifiers, whose computational complexity makes them inapplicable even for mid-size datasets. The outstanding robustness of WEASEL is also confirmed by experiments on two real smart grid datasets, where it out-of-the-box achieves almost the same accuracy as highly tuned, domain-specific methods.
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021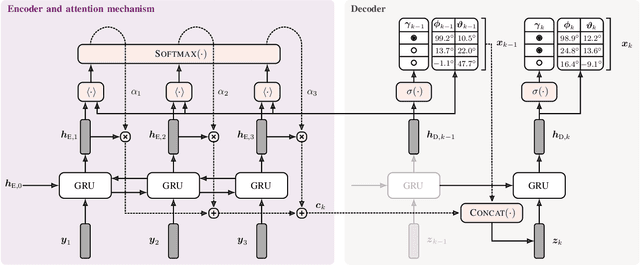
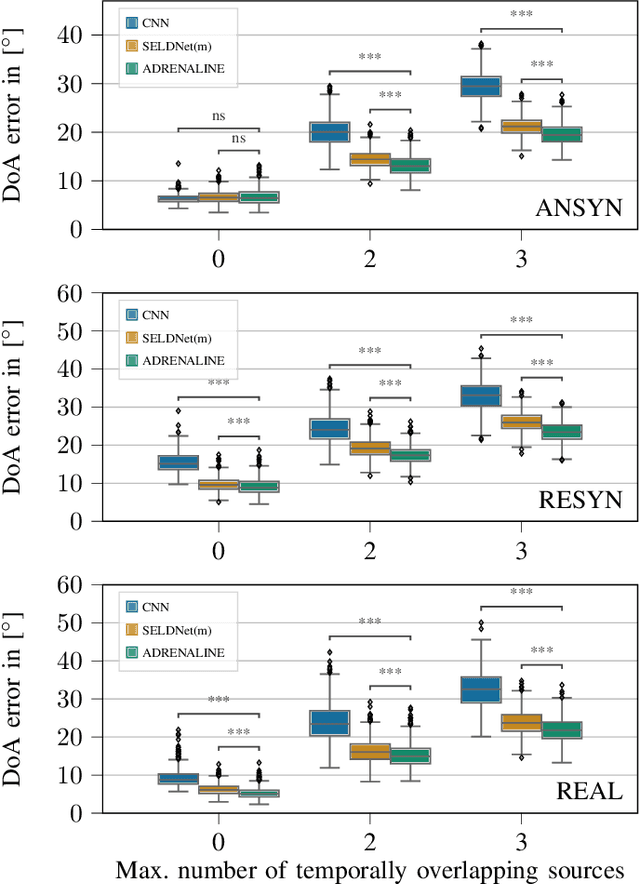
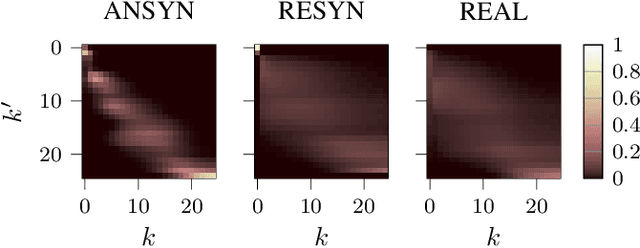
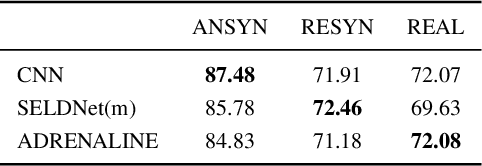
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.