 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Exploiting Attention-based Sequence-to-Sequence Architectures for Sound Event Localization
Feb 28, 2021
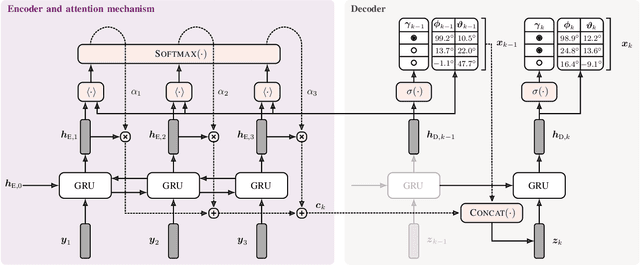
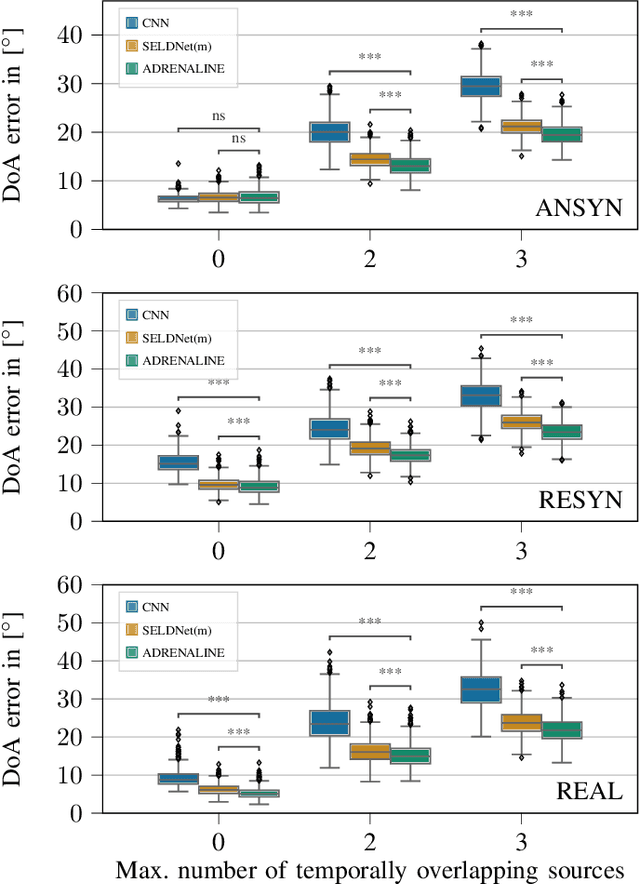
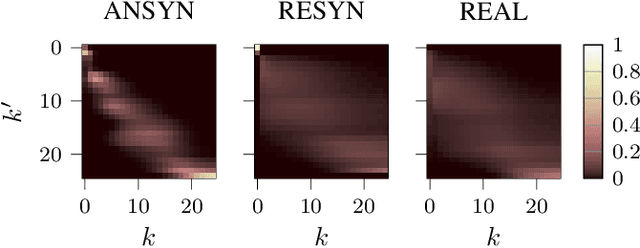
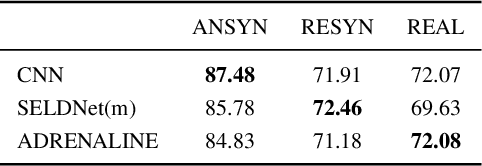
Sound event localization frameworks based on deep neural networks have shown increased robustness with respect to reverberation and noise in comparison to classical parametric approaches. In particular, recurrent architectures that incorporate temporal context into the estimation process seem to be well-suited for this task. This paper proposes a novel approach to sound event localization by utilizing an attention-based sequence-to-sequence model. These types of models have been successfully applied to problems in natural language processing and automatic speech recognition. In this work, a multi-channel audio signal is encoded to a latent representation, which is subsequently decoded to a sequence of estimated directions-of-arrival. Herein, attentions allow for capturing temporal dependencies in the audio signal by focusing on specific frames that are relevant for estimating the activity and direction-of-arrival of sound events at the current time-step. The framework is evaluated on three publicly available datasets for sound event localization. It yields superior localization performance compared to state-of-the-art methods in both anechoic and reverberant conditions.
Functional Space Analysis of Local GAN Convergence
Feb 08, 2021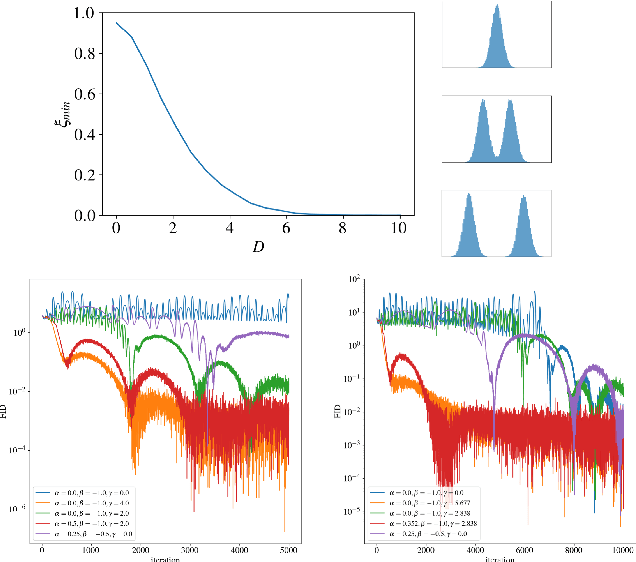


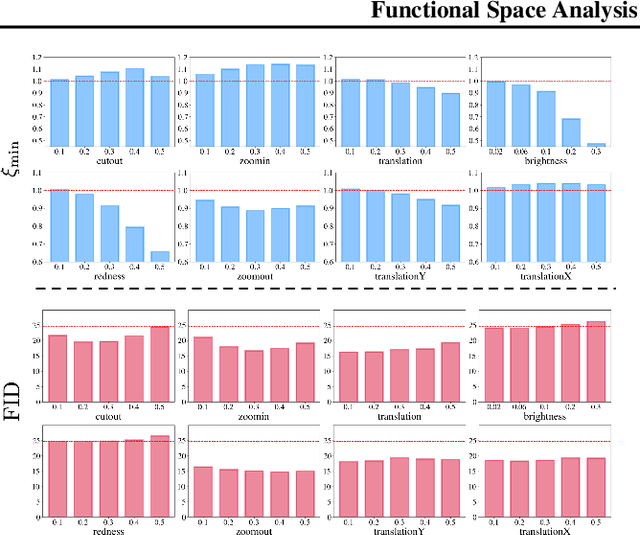
Recent work demonstrated the benefits of studying continuous-time dynamics governing the GAN training. However, this dynamics is analyzed in the model parameter space, which results in finite-dimensional dynamical systems. We propose a novel perspective where we study the local dynamics of adversarial training in the general functional space and show how it can be represented as a system of partial differential equations. Thus, the convergence properties can be inferred from the eigenvalues of the resulting differential operator. We show that these eigenvalues can be efficiently estimated from the target dataset before training. Our perspective reveals several insights on the practical tricks commonly used to stabilize GANs, such as gradient penalty, data augmentation, and advanced integration schemes. As an immediate practical benefit, we demonstrate how one can a priori select an optimal data augmentation strategy for a particular generation task.
Modelling and Control of a Knuckle Boom Crane
Mar 30, 2021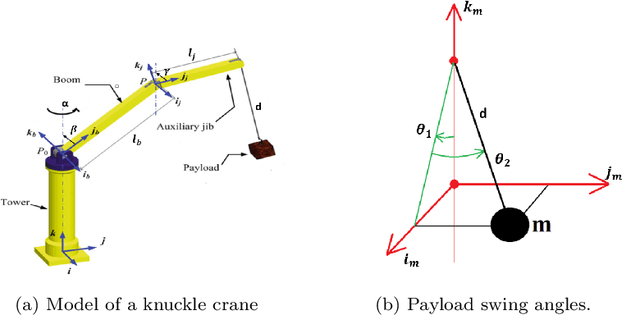


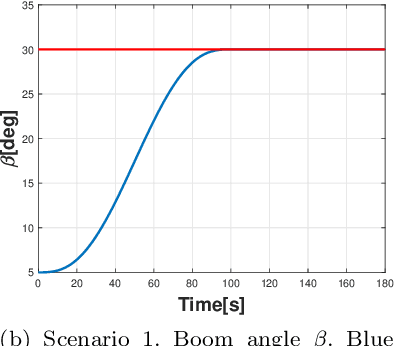
Cranes come in various sizes and designs to perform different tasks. Depending on their dynamic properties, they can be classified as gantry cranes and rotary cranes. In this paper we will focus on the so called 'knuckle boom' cranes which are among the most common types of rotary cranes. Compared with the other kinds of cranes (e.g. boom cranes, tower cranes, overhead cranes, etc), the study of knuckle cranes is still at an early stage and very few control strategies for this kind of crane have been proposed in the literature. Although fairly simple mechanically, from the control viewpoint the knuckle cranes present several challenges. A first result of this paper is to present for the first time a complete mathematical model for this kind of crane where it is possible to control the three rotations of the crane (known as luff, slew, and jib movement), and the cable length. The only simplifying assumption of the model is that the cable is considered rigid. On the basis of this model, we propose a nonlinear control law based on energy considerations which is able to perform position control of the crane while actively damping the oscillations of the load. The corresponding stability and convergence analysis is carefully proved using the LaSalle's invariance principle. The effectiveness of the proposed control approach has been tested in simulation with realistic physical parameters and in the presence of model mismatch.
* This paper has been accepted to International Journal of Control on March 29th 2021. arXiv admin note: text overlap with arXiv:2103.02509
Predicting Early Dropout: Calibration and Algorithmic Fairness Considerations
Mar 16, 2021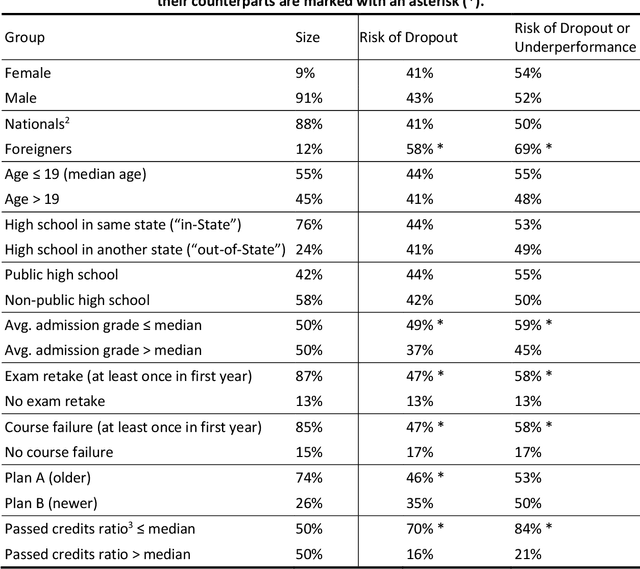
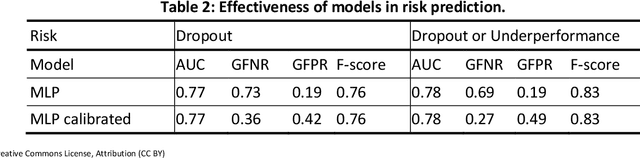
In this work, the problem of predicting dropout risk in undergraduate studies is addressed from a perspective of algorithmic fairness. We develop a machine learning method to predict the risks of university dropout and underperformance. The objective is to understand if such a system can identify students at risk while avoiding potential discriminatory biases. When modeling both risks, we obtain prediction models with an Area Under the ROC Curve (AUC) of 0.77-0.78 based on the data available at the enrollment time, before the first year of studies starts. This data includes the students' demographics, the high school they attended, and their admission (average) grade. Our models are calibrated: they produce estimated probabilities for each risk, not mere scores. We analyze if this method leads to discriminatory outcomes for some sensitive groups in terms of prediction accuracy (AUC) and error rates (Generalized False Positive Rate, GFPR, or Generalized False Negative Rate, GFNR). The models exhibit some equity in terms of AUC and GFNR along groups. The similar GFNR means a similar probability of failing to detect risk for students who drop out. The disparities in GFPR are addressed through a mitigation process that does not affect the calibration of the model.
Avoiding dynamic small obstacles with onboard sensing and computating on aerial robots
Feb 28, 2021

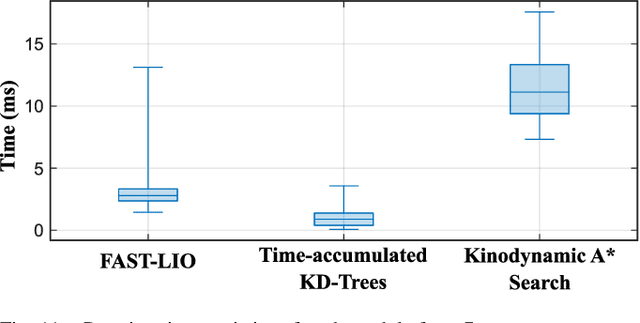

In practical applications, autonomous quadrotors are still facing significant challenges, such as the detection and avoidance of very small and even dynamic obstacles (e.g., tree branches, power lines). In this paper, we propose a compact, integrated, and fully autonomous quadrotor system, which can fly safely in cluttered environments while avoiding dynamic small obstacles. Our quadrotor platform is equipped with a forward-looking three-dimensional (3D) light detection and ranging (lidar) sensor to perceive the environment and an onboard embedded computer to perform all the estimation, mapping, and planning tasks. Specifically, the computer estimates the current pose of the UAV, maintains a local map (time-accumulated point clouds KD-Trees), and computes a safe trajectory using kinodynamic A* search to the goal point. The whole perception and planning system can run onboard at 50Hz with careful optimization. Various indoor and outdoor experiments show that the system can avoid dynamic small obstacles (down to 20mm diameter bar) while flying at 2m/s in cluttered environments. Our codes and hardware design are open-sourced on Github.
ThetA -- fast and robust clustering via a distance parameter
Feb 13, 2021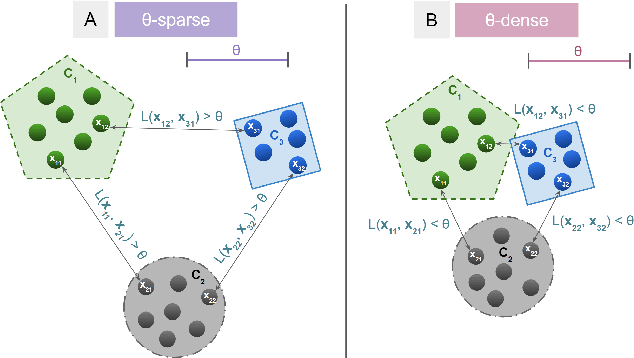
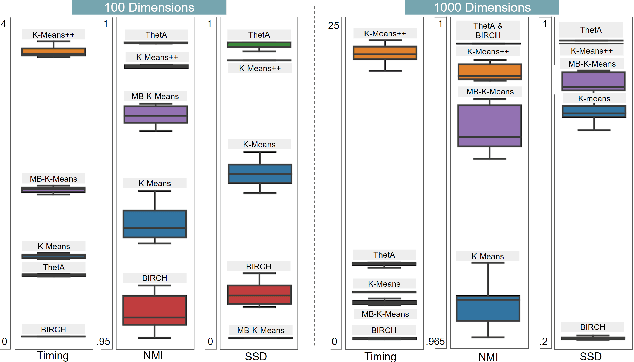
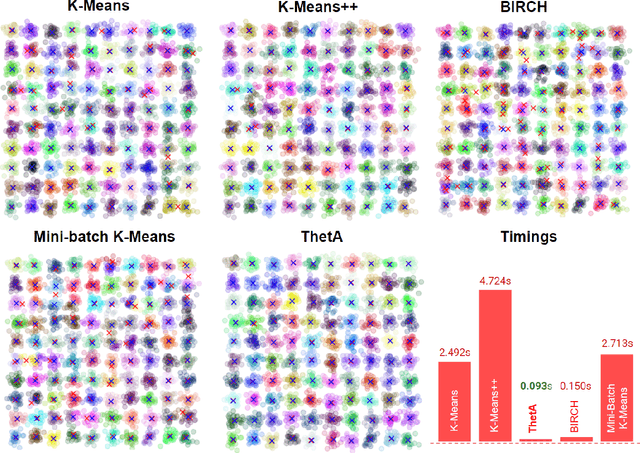
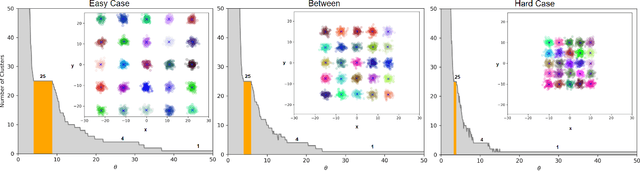
Clustering is a fundamental problem in machine learning where distance-based approaches have dominated the field for many decades. This set of problems is often tackled by partitioning the data into K clusters where the number of clusters is chosen apriori. While significant progress has been made on these lines over the years, it is well established that as the number of clusters or dimensions increase, current approaches dwell in local minima resulting in suboptimal solutions. In this work, we propose a new set of distance threshold methods called Theta-based Algorithms (ThetA). Via experimental comparisons and complexity analyses we show that our proposed approach outperforms existing approaches in: a) clustering accuracy and b) time complexity. Additionally, we show that for a large class of problems, learning the optimal threshold is straightforward in comparison to learning K. Moreover, we show how ThetA can infer the sparsity of datasets in higher dimensions.
An Artificial Intelligence Framework for Bidding Optimization with Uncertainty inMultiple Frequency Reserve Markets
Apr 05, 2021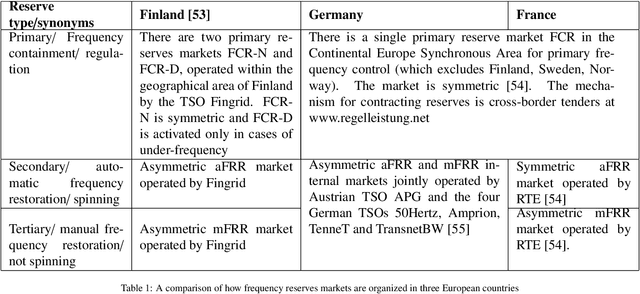
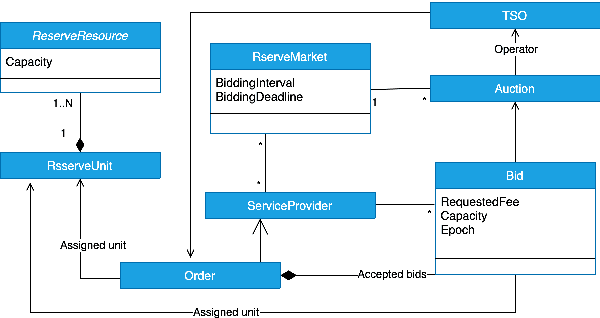
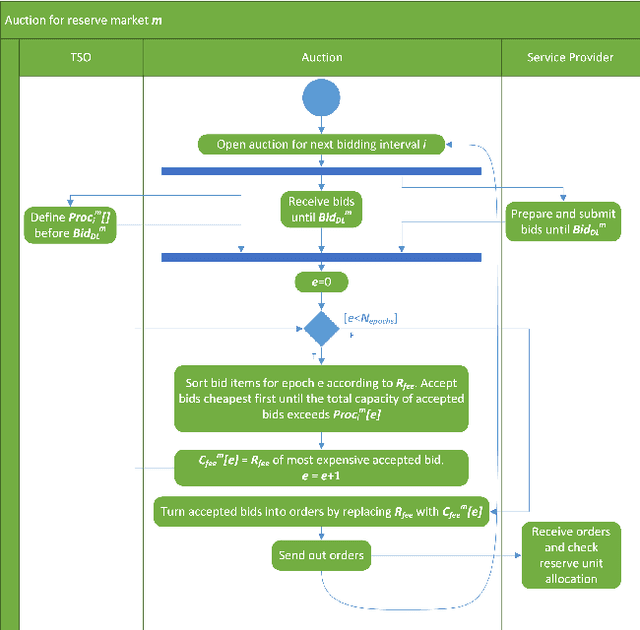
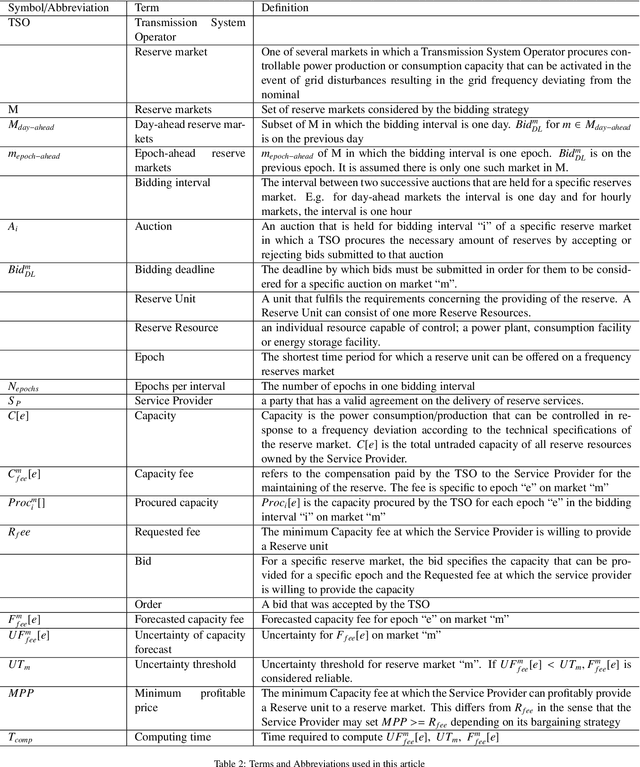
The global ambitions of a carbon-neutral society necessitate a stable and robust smart grid that capitalises on frequency reserves of renewable energy. Frequency reserves are resources that adjust power production or consumption in real time to react to a power grid frequency deviation. Revenue generation motivates the availability of these resources for managing such deviations. However, limited research has been conducted on data-driven decisions and optimal bidding strategies for trading such capacities in multiple frequency reserves markets. We address this limitation by making the following research contributions. Firstly, a generalised model is designed based on an extensive study of critical characteristics of global frequency reserves markets. Secondly, three bidding strategies are proposed, based on this market model, to capitalise on price peaks in multi-stage markets. Two strategies are proposed for non-reschedulable loads, in which case the bidding strategy aims to select the market with the highest anticipated price, and the third bidding strategy focuses on rescheduling loads to hours on which highest reserve market prices are anticipated. The third research contribution is an Artificial Intelligence (AI) based bidding optimization framework that implements these three strategies, with novel uncertainty metrics that supplement data-driven price prediction. Finally, the framework is evaluated empirically using a case study of multiple frequency reserves markets in Finland. The results from this evaluation confirm the effectiveness of the proposed bidding strategies and the AI-based bidding optimization framework in terms of cumulative revenue generation, leading to an increased availability of frequency reserves.
Automatic design of novel potential 3CL$^{\text{pro}}$ and PL$^{\text{pro}}$ inhibitors
Jan 28, 2021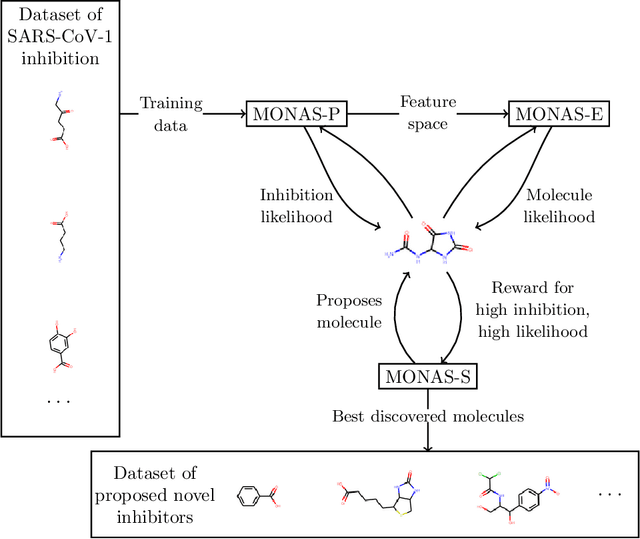
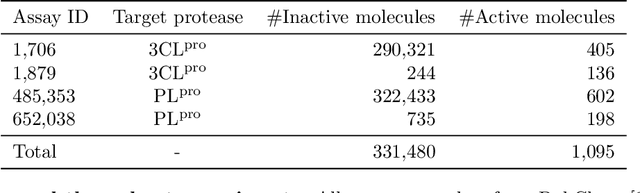
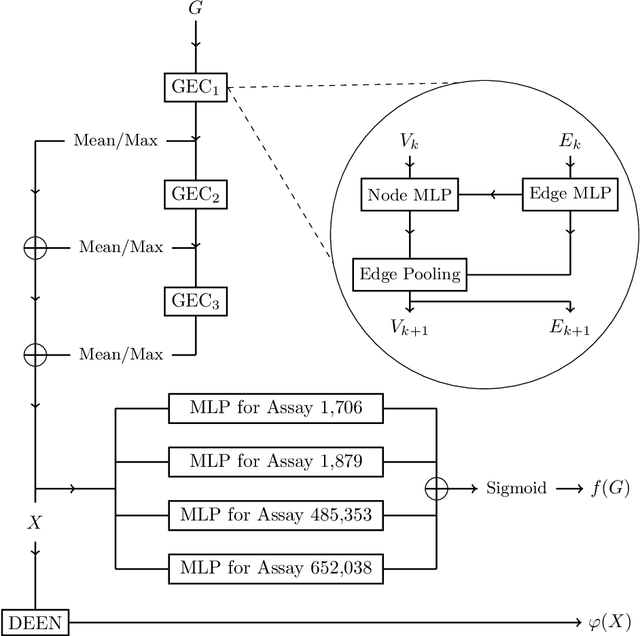
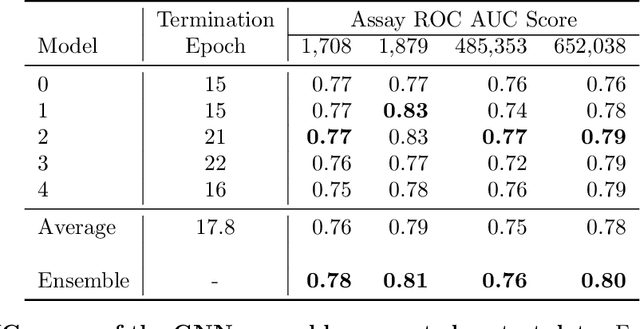
With the goal of designing novel inhibitors for SARS-CoV-1 and SARS-CoV-2, we propose the general molecule optimization framework, Molecular Neural Assay Search (MONAS), consisting of three components: a property predictor which identifies molecules with specific desirable properties, an energy model which approximates the statistical similarity of a given molecule to known training molecules, and a molecule search method. In this work, these components are instantiated with graph neural networks (GNNs), Deep Energy Estimator Networks (DEEN) and Monte Carlo tree search (MCTS), respectively. This implementation is used to identify 120K molecules (out of 40-million explored) which the GNN determined to be likely SARS-CoV-1 inhibitors, and, at the same time, are statistically close to the dataset used to train the GNN.
Empirical comparison between autoencoders and traditional dimensionality reduction methods
Mar 08, 2021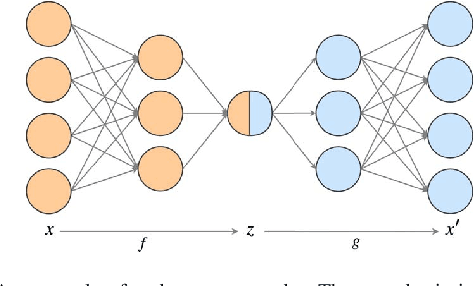
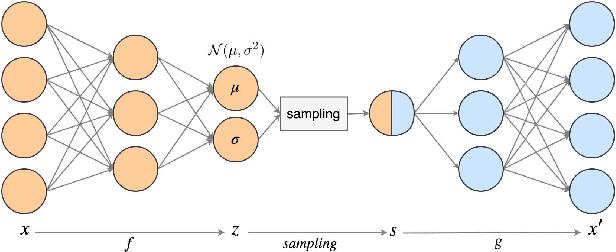
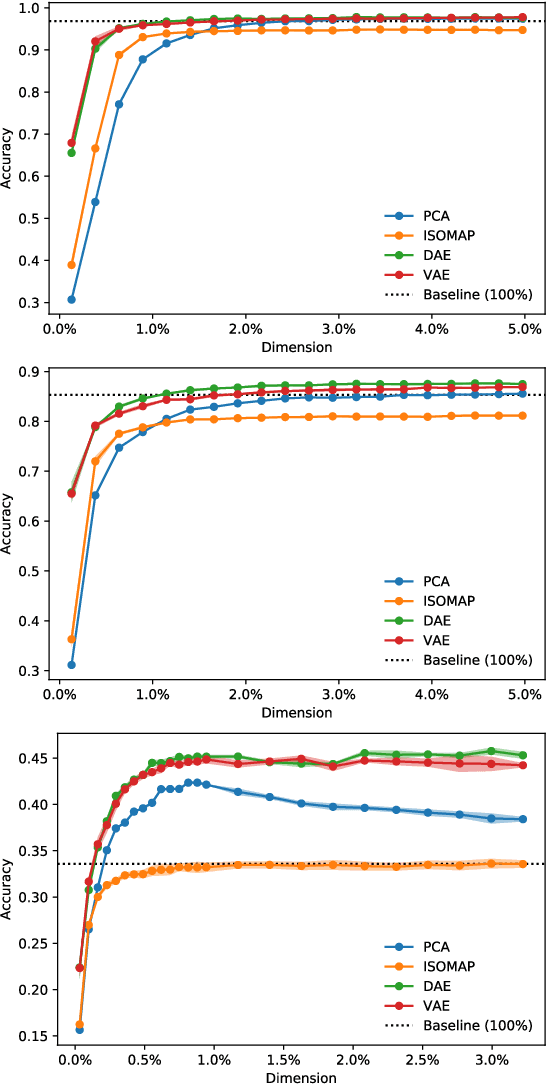
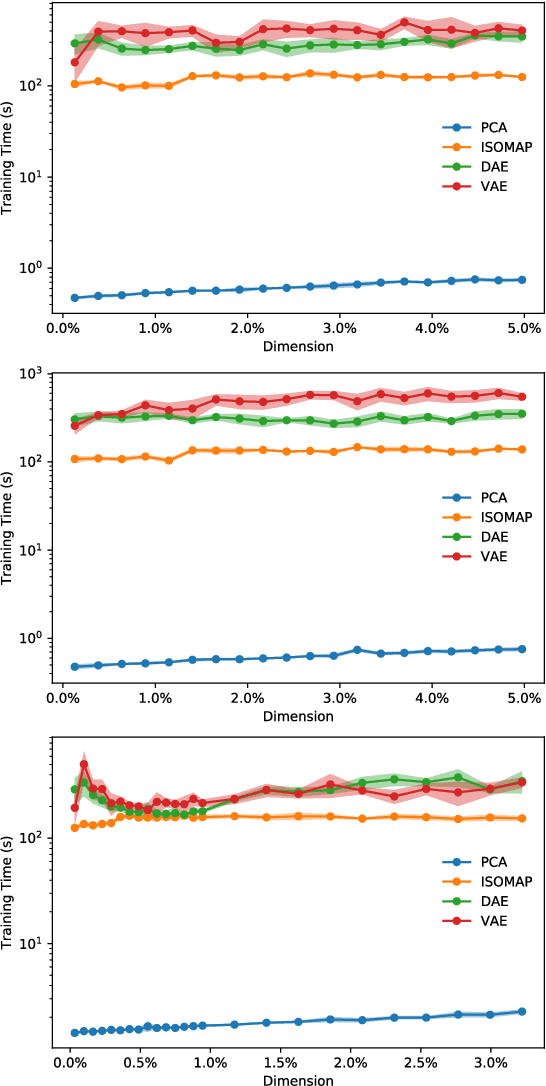
In order to process efficiently ever-higher dimensional data such as images, sentences, or audio recordings, one needs to find a proper way to reduce the dimensionality of such data. In this regard, SVD-based methods including PCA and Isomap have been extensively used. Recently, a neural network alternative called autoencoder has been proposed and is often preferred for its higher flexibility. This work aims to show that PCA is still a relevant technique for dimensionality reduction in the context of classification. To this purpose, we evaluated the performance of PCA compared to Isomap, a deep autoencoder, and a variational autoencoder. Experiments were conducted on three commonly used image datasets: MNIST, Fashion-MNIST, and CIFAR-10. The four different dimensionality reduction techniques were separately employed on each dataset to project data into a low-dimensional space. Then a k-NN classifier was trained on each projection with a cross-validated random search over the number of neighbours. Interestingly, our experiments revealed that k-NN achieved comparable accuracy on PCA and both autoencoders' projections provided a big enough dimension. However, PCA computation time was two orders of magnitude faster than its neural network counterparts.
* 4 pages, 4 figures, IEEE AIKE 2019
Centroid Transformers: Learning to Abstract with Attention
Mar 08, 2021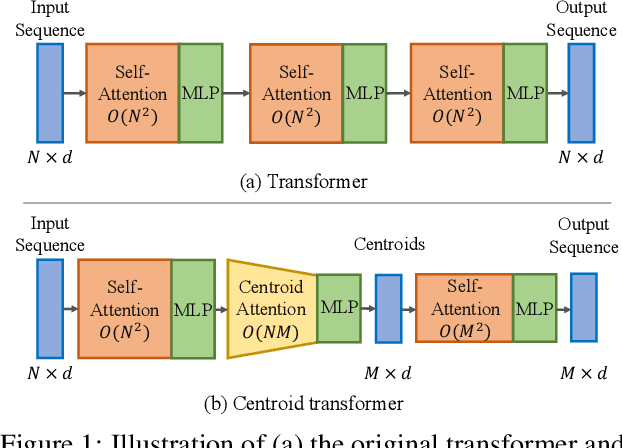

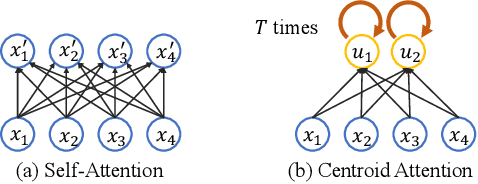
Self-attention, as the key block of transformers, is a powerful mechanism for extracting features from the inputs. In essence, what self-attention does is to infer the pairwise relations between the elements of the inputs, and modify the inputs by propagating information between input pairs. As a result, it maps inputs to N outputs and casts a quadratic $O(N^2)$ memory and time complexity. We propose centroid attention, a generalization of self-attention that maps N inputs to M outputs $(M\leq N)$, such that the key information in the inputs are summarized in the smaller number of outputs (called centroids). We design centroid attention by amortizing the gradient descent update rule of a clustering objective function on the inputs, which reveals an underlying connection between attention and clustering. By compressing the inputs to the centroids, we extract the key information useful for prediction and also reduce the computation of the attention module and the subsequent layers. We apply our method to various applications, including abstractive text summarization, 3D vision, and image processing. Empirical results demonstrate the effectiveness of our method over the standard transformers.