 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SALT: A Semi-automatic Labeling Tool for RGB-D Video Sequences
Feb 22, 2021
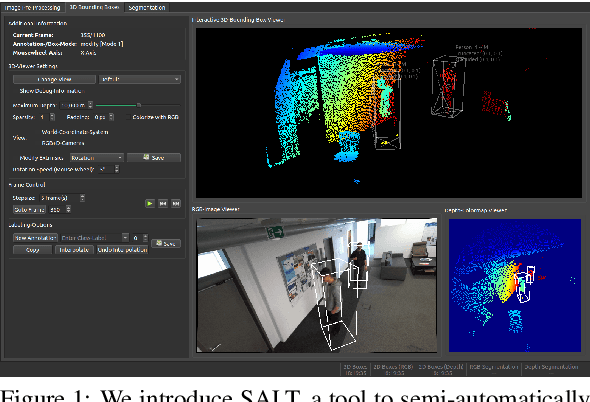
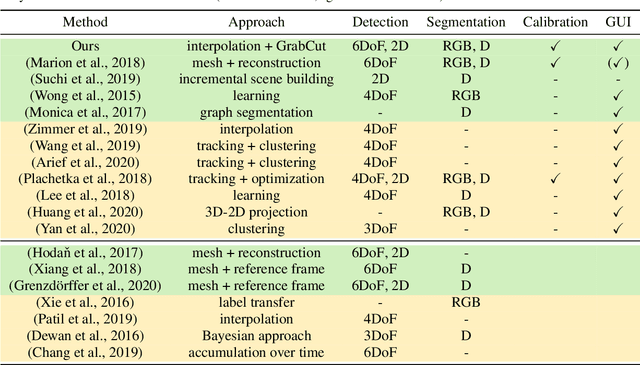
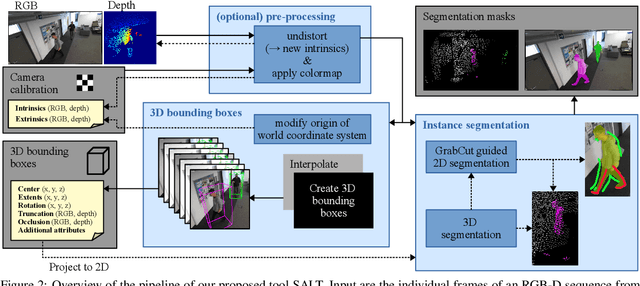
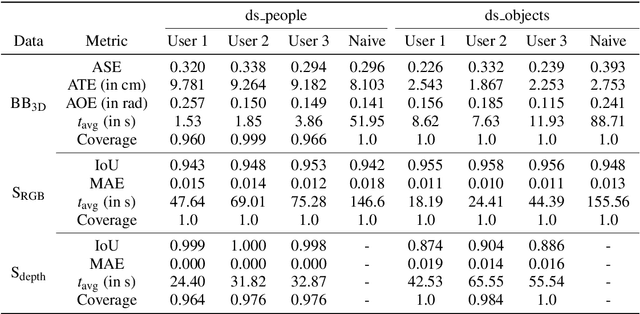
Large labeled data sets are one of the essential basics of modern deep learning techniques. Therefore, there is an increasing need for tools that allow to label large amounts of data as intuitively as possible. In this paper, we introduce SALT, a tool to semi-automatically annotate RGB-D video sequences to generate 3D bounding boxes for full six Degrees of Freedom (DoF) object poses, as well as pixel-level instance segmentation masks for both RGB and depth. Besides bounding box propagation through various interpolation techniques, as well as algorithmically guided instance segmentation, our pipeline also provides built-in pre-processing functionalities to facilitate the data set creation process. By making full use of SALT, annotation time can be reduced by a factor of up to 33.95 for bounding box creation and 8.55 for RGB segmentation without compromising the quality of the automatically generated ground truth.
* VISAPP 2021 full paper (9 pages, 6 figures), published by SciTePress: https://www.scitepress.org/PublicationsDetail.aspx?ID=ywQZ3GZrka8=&t=1
Improving Uncertainty Calibration via Prior Augmented Data
Feb 22, 2021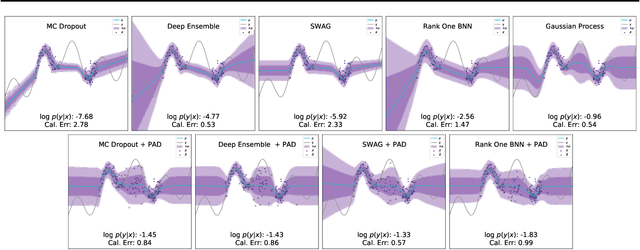
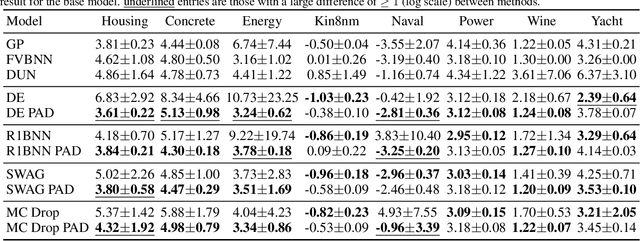
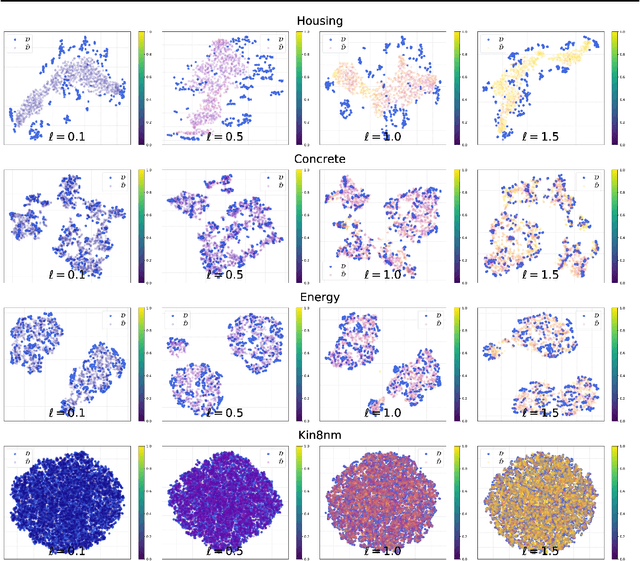
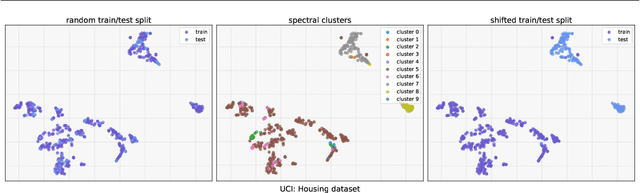
Neural networks have proven successful at learning from complex data distributions by acting as universal function approximators. However, they are often overconfident in their predictions, which leads to inaccurate and miscalibrated probabilistic predictions. The problem of overconfidence becomes especially apparent in cases where the test-time data distribution differs from that which was seen during training. We propose a solution to this problem by seeking out regions of feature space where the model is unjustifiably overconfident, and conditionally raising the entropy of those predictions towards that of the prior distribution of the labels. Our method results in a better calibrated network and is agnostic to the underlying model structure, so it can be applied to any neural network which produces a probability density as an output. We demonstrate the effectiveness of our method and validate its performance on both classification and regression problems, applying it to recent probabilistic neural network models.
Interpretable Clustering on Dynamic Graphs with Recurrent Graph Neural Networks
Dec 16, 2020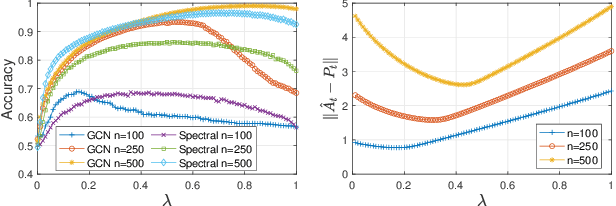
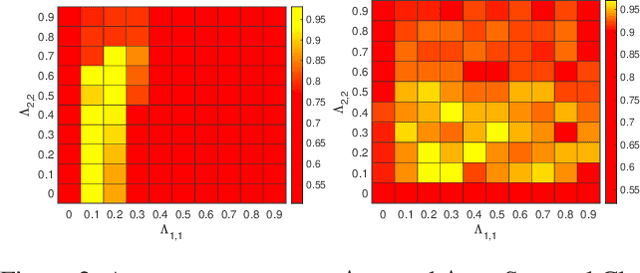
We study the problem of clustering nodes in a dynamic graph, where the connections between nodes and nodes' cluster memberships may change over time, e.g., due to community migration. We first propose a dynamic stochastic block model that captures these changes, and a simple decay-based clustering algorithm that clusters nodes based on weighted connections between them, where the weight decreases at a fixed rate over time. This decay rate can then be interpreted as signifying the importance of including historical connection information in the clustering. However, the optimal decay rate may differ for clusters with different rates of turnover. We characterize the optimal decay rate for each cluster and propose a clustering method that achieves almost exact recovery of the true clusters. We then demonstrate the efficacy of our clustering algorithm with optimized decay rates on simulated graph data. Recurrent neural networks (RNNs), a popular algorithm for sequence learning, use a similar decay-based method, and we use this insight to propose two new RNN-GCN (graph convolutional network) architectures for semi-supervised graph clustering. We finally demonstrate that the proposed architectures perform well on real data compared to state-of-the-art graph clustering algorithms.
Research on Resource Allocation for Efficient Federated Learning
Apr 19, 2021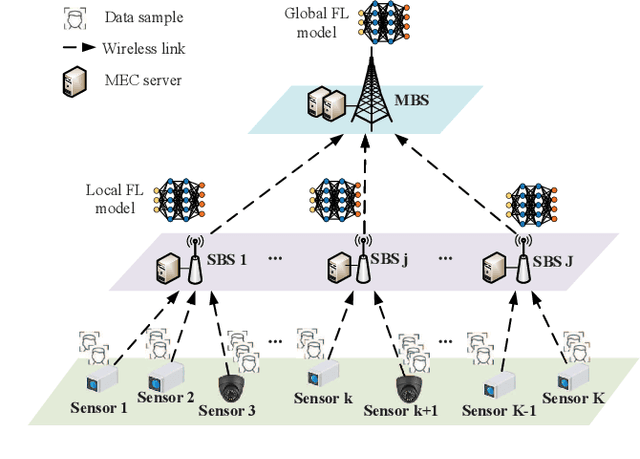
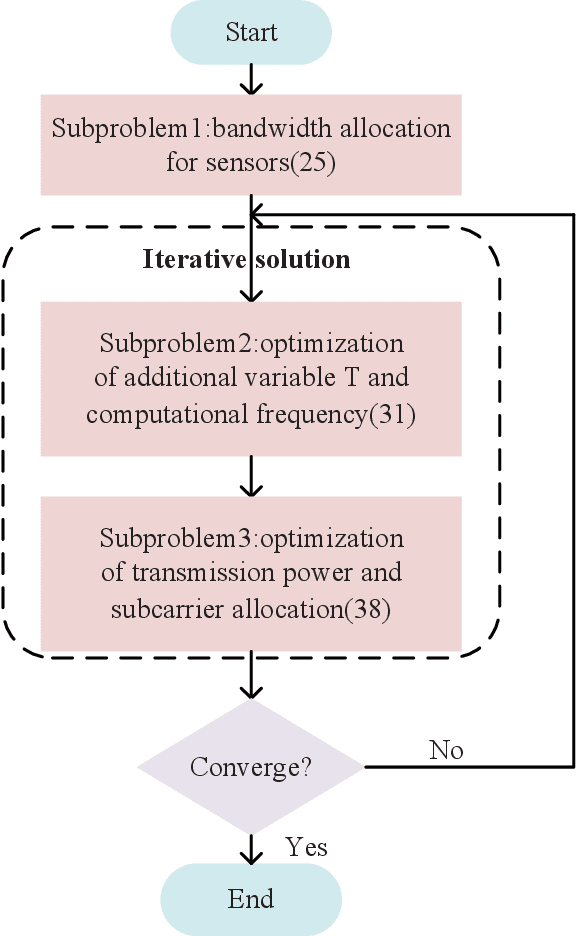
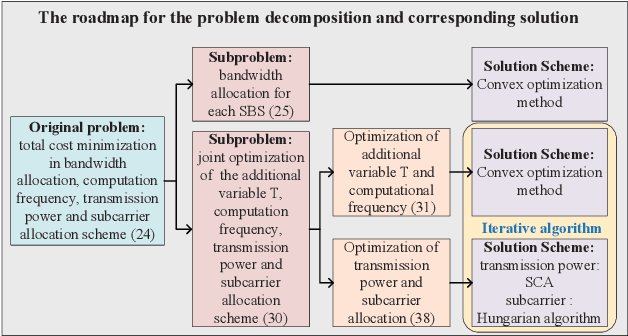
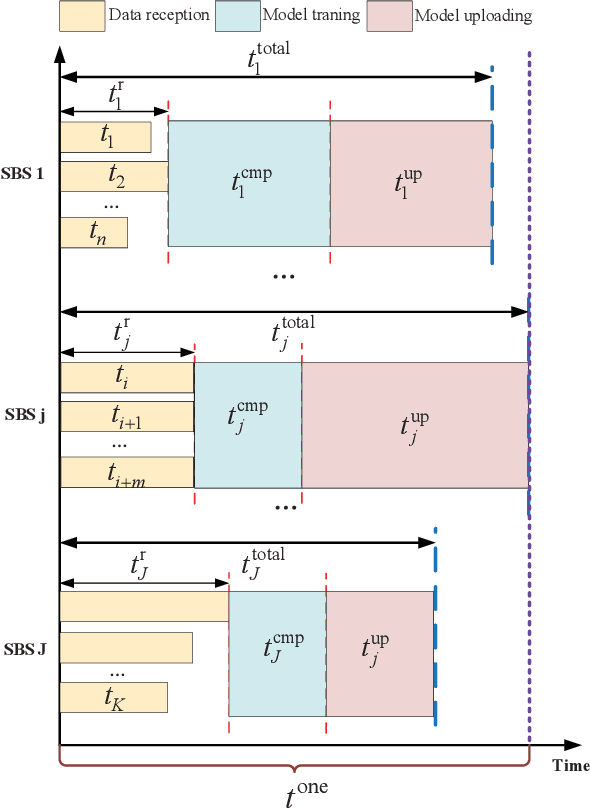
As a promising solution to achieve efficient learning among isolated data owners and solve data privacy issues, federated learning is receiving wide attention. Using the edge server as an intermediary can effectively collect sensor data, perform local model training, and upload model parameters for global aggregation. So this paper proposes a new framework for resource allocation in a hierarchical network supported by edge computing. In this framework, we minimize the weighted sum of system cost and learning cost by optimizing bandwidth, computing frequency, power allocation and subcarrier assignment. To solve this challenging mixed-integer non-linear problem, we first decouple the bandwidth optimization problem(P1) from the whole problem and obtain a closed-form solution. The remaining computational frequency, power, and subcarrier joint optimization problem(P2) can be further decomposed into two sub-problems: latency and computational frequency optimization problem(P3) and transmission power and subcarrier optimization problem(P4). P3 is a convex optimization problem that is easy to solve. In the joint optimization problem(P4), the optimal power under each subcarrier selection can be obtained first through the successive convex approximation(SCA) algorithm. Substituting the optimal power value obtained back to P4, the subproblem can be regarded as an assignment problem, so the Hungarian algorithm can be effectively used to solve it. The solution of problem P2 is accomplished by solving P3 and P4 iteratively. To verify the performance of the algorithm, we compare the proposed algorithm with five algorithms; namely Equal bandwidth allocation, Learning cost guaranteed, Greedy subcarrier allocation, System cost guaranteed and Time-biased algorithm. Numerical results show the significant performance gain and the robustness of the proposed algorithm in the face of parameter changes.
Splitting Gaussian Process Regression for Streaming Data
Oct 06, 2020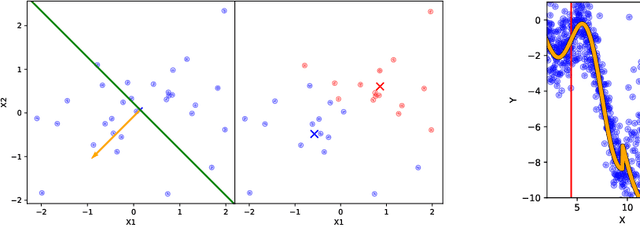
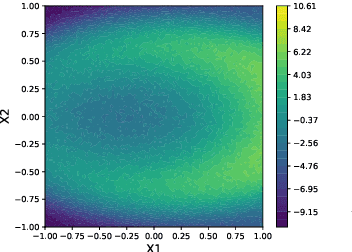
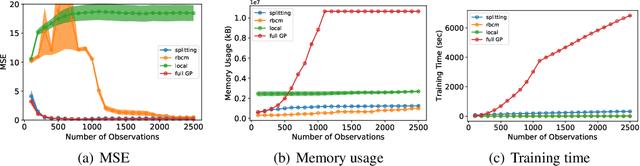
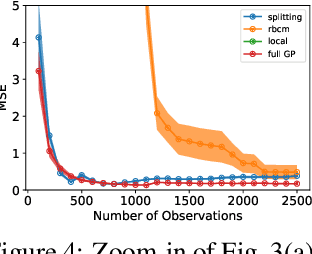
Gaussian processes offer a flexible kernel method for regression. While Gaussian processes have many useful theoretical properties and have proven practically useful, they suffer from poor scaling in the number of observations. In particular, the cubic time complexity of updating standard Gaussian process models make them generally unsuitable for application to streaming data. We propose an algorithm for sequentially partitioning the input space and fitting a localized Gaussian process to each disjoint region. The algorithm is shown to have superior time and space complexity to existing methods, and its sequential nature permits application to streaming data. The algorithm constructs a model for which the time complexity of updating is tightly bounded above by a pre-specified parameter. To the best of our knowledge, the model is the first local Gaussian process regression model to achieve linear memory complexity. Theoretical continuity properties of the model are proven. We demonstrate the efficacy of the resulting model on multi-dimensional regression tasks for streaming data.
Dual-Task Mutual Learning for Semi-Supervised Medical Image Segmentation
Mar 08, 2021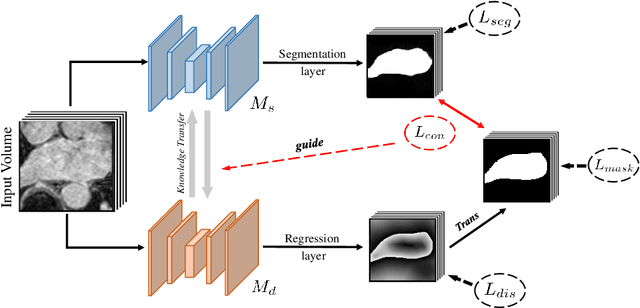
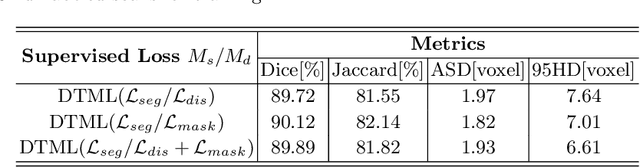
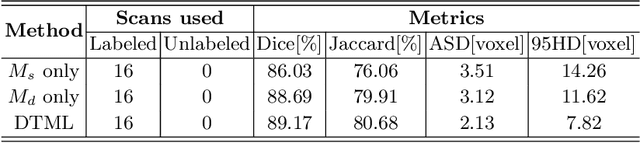
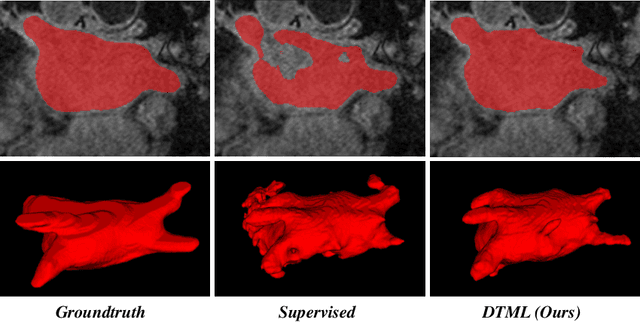
The success of deep learning methods in medical image segmentation tasks usually requires a large amount of labeled data. However, obtaining reliable annotations is expensive and time-consuming. Semi-supervised learning has attracted much attention in medical image segmentation by taking the advantage of unlabeled data which is much easier to acquire. In this paper, we propose a novel dual-task mutual learning framework for semi-supervised medical image segmentation. Our framework can be formulated as an integration of two individual segmentation networks based on two tasks: learning region-based shape constraint and learning boundary-based surface mismatch. Different from the one-way transfer between teacher and student networks, an ensemble of dual-task students can learn collaboratively and implicitly explore useful knowledge from each other during the training process. By jointly learning the segmentation probability maps and signed distance maps of targets, our framework can enforce the geometric shape constraint and learn more reliable information. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms the state-of-the-art semi-supervised segmentation methods.
Predictive Relay Selection: A Cooperative Diversity Scheme Using Deep Learning
Feb 05, 2021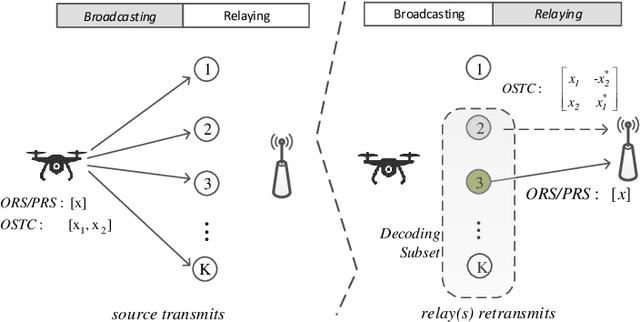
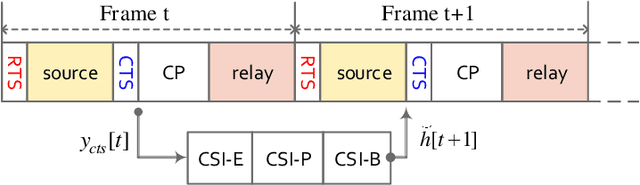
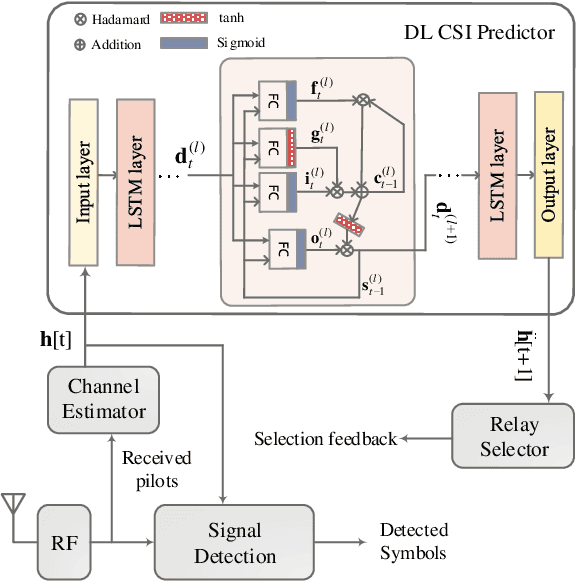
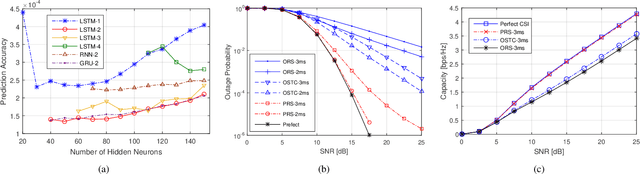
In this paper, we propose a novel cooperative multi-relay transmission scheme for mobile terminals to exploit spatial diversity. By improving the timeliness of measured channel state information (CSI) through deep learning (DL)-based channel prediction, the proposed scheme remarkably lowers the probability of wrong relay selection arising from outdated CSI in fast time-varying channels. It inherits the simplicity of opportunistic relaying by selecting a single relay, avoiding the complexity of multi-relay coordination and synchronization. Numerical results reveal that it can achieve full diversity gain in slow-fading channels and substantially outperforms the existing schemes in fast-fading wireless environments. Moreover, the computational complexity brought by the DL predictor is negligible compared to off-the-shelf computing hardware.
Path Dependent Structural Equation Models
Aug 24, 2020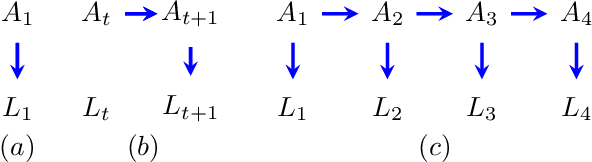
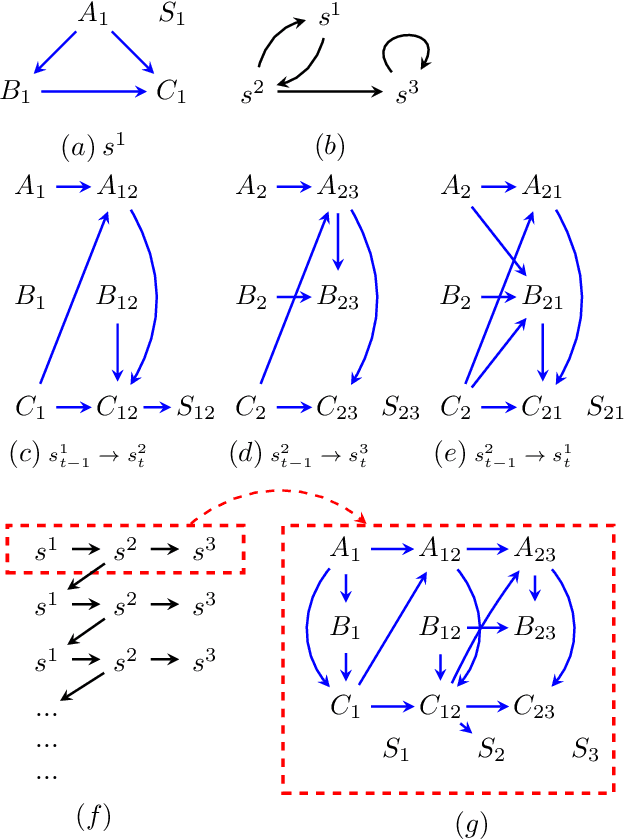
Causal analyses of longitudinal data generally assume structure that is invariant over time. Graphical causal models describe these data using a single causal diagram repeated at every time step. In structured systems that transition between qualitatively different states in discrete time steps, such an approach is deficient on two fronts. First, time-varying variables may have state-specific causal relationships that need to be captured. Second, an intervention can result in state transitions downstream of the intervention different from thoseactually observed in the data. In other words, interventions may counterfactually alter the subsequent temporal evolution of the system. We introduce a generalization of causal graphical models, Path Dependent Structural Equation Models (PDSEMs), that can describe such systems. We show how causal inference may be performed in such models and illustrate its use in simulations and data obtained from a septoplasty surgical procedure.
Hallucination of speech recognition errors with sequence to sequence learning
Mar 31, 2021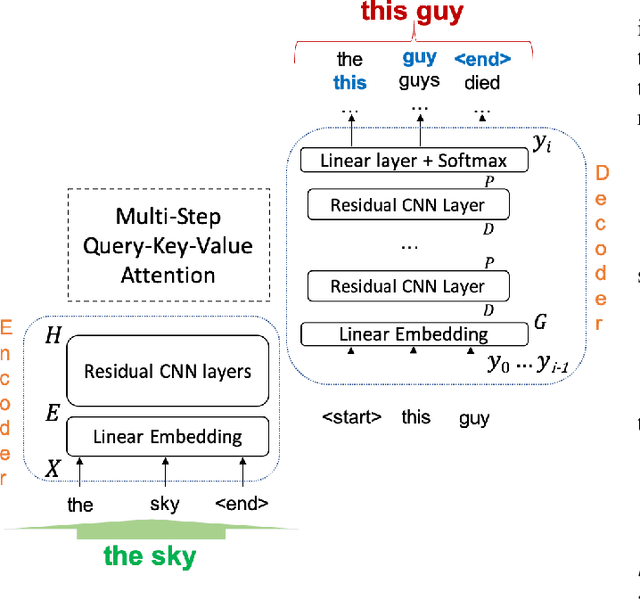
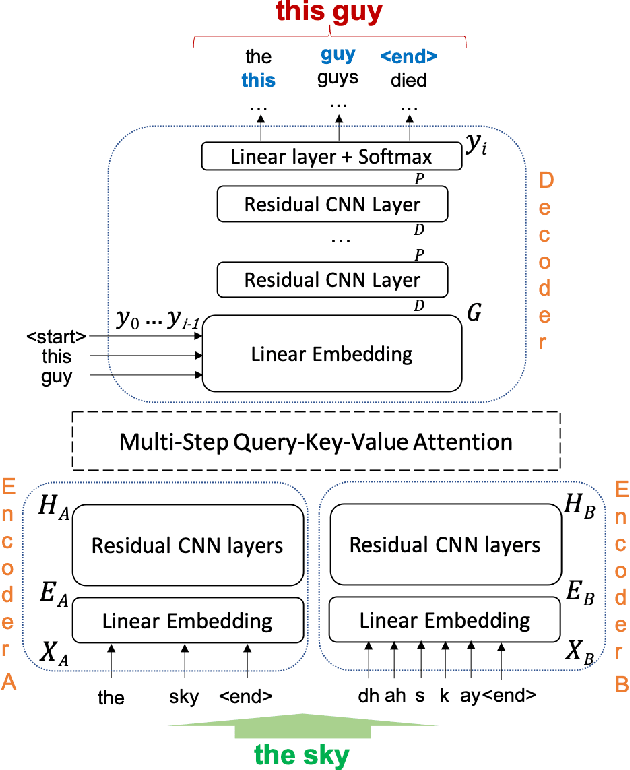
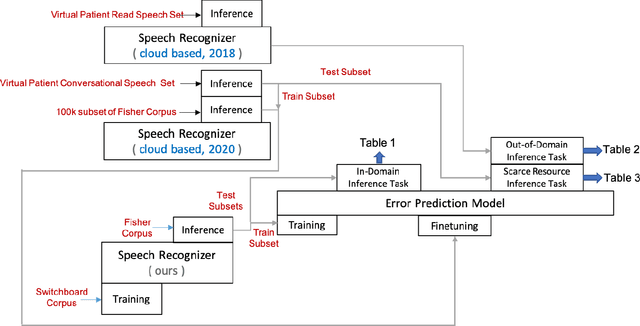
Automatic Speech Recognition (ASR) is an imperfect process that results in certain mismatches in ASR output text when compared to plain written text or transcriptions. When plain text data is to be used to train systems for spoken language understanding or ASR, a proven strategy to reduce said mismatch and prevent degradations, is to hallucinate what the ASR outputs would be given a gold transcription. Prior work in this domain has focused on modeling errors at the phonetic level, while using a lexicon to convert the phones to words, usually accompanied by an FST Language model. We present novel end-to-end models to directly predict hallucinated ASR word sequence outputs, conditioning on an input word sequence as well as a corresponding phoneme sequence. This improves prior published results for recall of errors from an in-domain ASR system's transcription of unseen data, as well as an out-of-domain ASR system's transcriptions of audio from an unrelated task, while additionally exploring an in-between scenario when limited characterization data from the test ASR system is obtainable. To verify the extrinsic validity of the method, we also use our hallucinated ASR errors to augment training for a spoken question classifier, finding that they enable robustness to real ASR errors in a downstream task, when scarce or even zero task-specific audio was available at train-time.
A Balance for Fairness: Fair Distribution Utilising Physics in Games of Characteristic Function Form
Feb 05, 2021
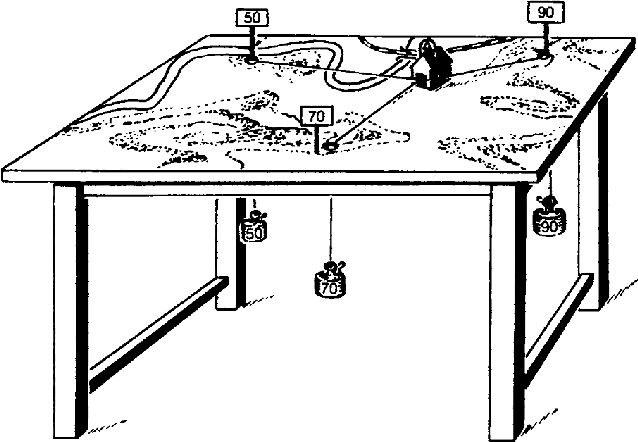
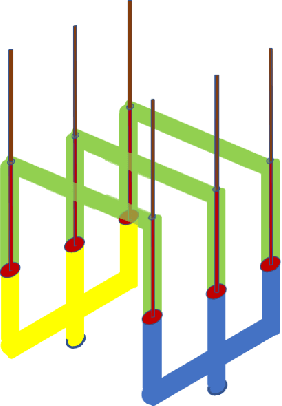
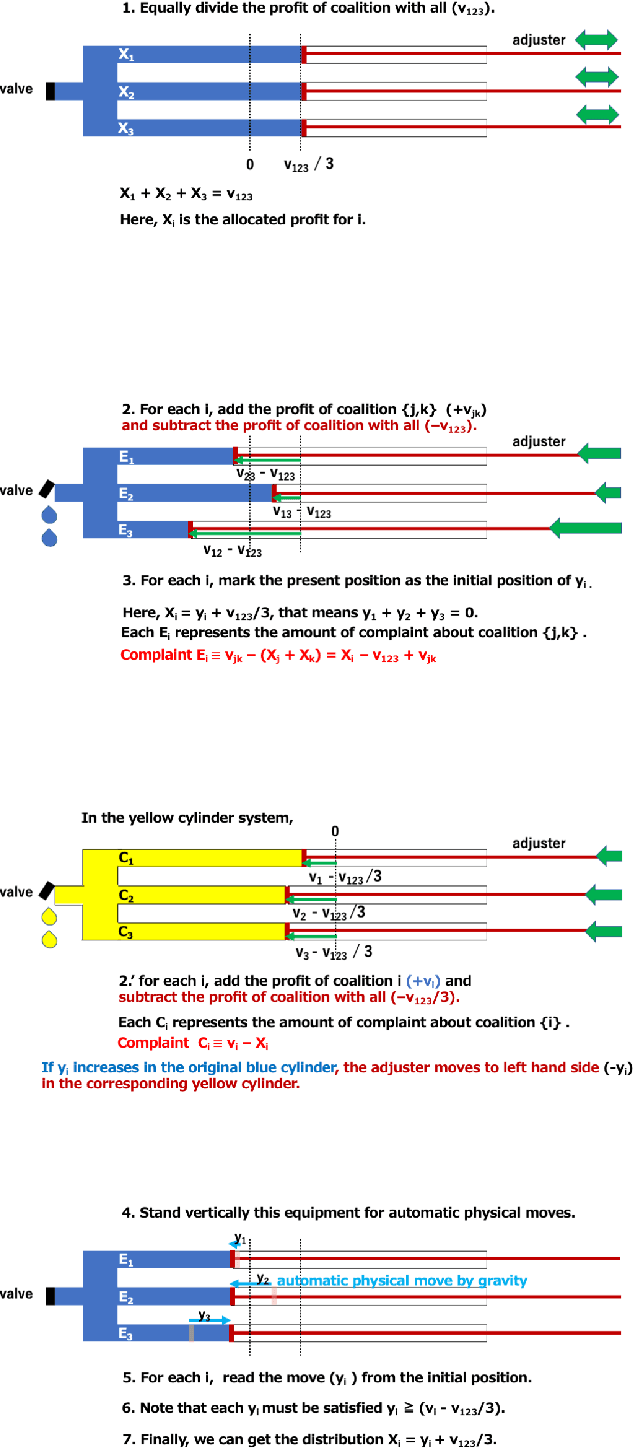
In chaotic modern society, there is an increasing demand for the realization of true 'fairness'. In Greek mythology, Themis, the 'goddess of justice', has a sword in her right hand to protect society from vices, and a 'balance of judgment' in her left hand that measures good and evil. In this study, we propose a fair distribution method 'utilising physics' for the profit in games of characteristic function form. Specifically, we show that the linear programming problem for calculating 'nucleolus' can be efficiently solved by considering it as a physical system in which gravity works. In addition to being able to significantly reduce computational complexity thereby, we believe that this system could have flexibility necessary to respond to real-time changes in the parameter.