 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Attacks on Camera-LiDAR Models for 3D Car Detection
Mar 17, 2021

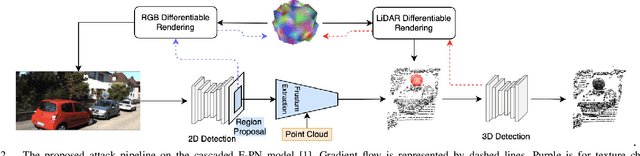
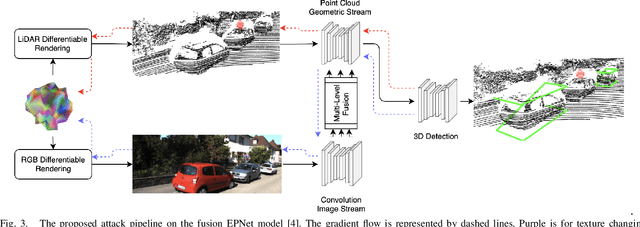
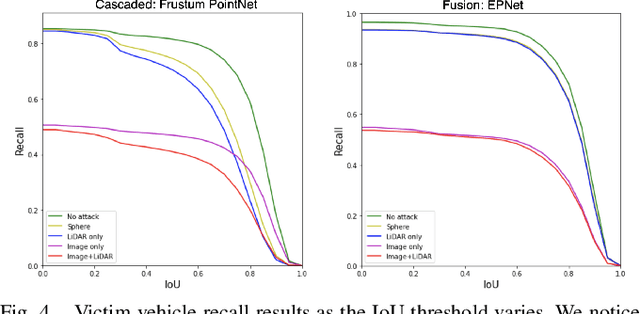
Most autonomous vehicles (AVs) rely on LiDAR and RGB camera sensors for perception. Using these point cloud and image data, perception models based on deep neural nets (DNNs) have achieved state-of-the-art performance in 3D detection. The vulnerability of DNNs to adversarial attacks have been heavily investigated in the RGB image domain and more recently in the point cloud domain, but rarely in both domains simultaneously. Multi-modal perception systems used in AVs can be divided into two broad types: cascaded models which use each modality independently, and fusion models which learn from different modalities simultaneously. We propose a universal and physically realizable adversarial attack for each type, and study and contrast their respective vulnerabilities to attacks. We place a single adversarial object with specific shape and texture on top of a car with the objective of making this car evade detection. Evaluating on the popular KITTI benchmark, our adversarial object made the host vehicle escape detection by each model type nearly 50% of the time. The dense RGB input contributed more to the success of the adversarial attacks on both cascaded and fusion models. We found that the fusion model was relatively more robust to adversarial attacks than the cascaded model.
Deep Learning for Real-Time Crime Forecasting and its Ternarization
Nov 23, 2017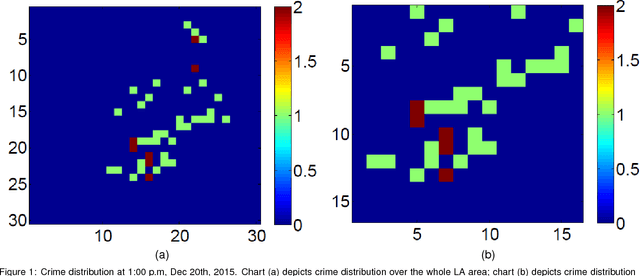
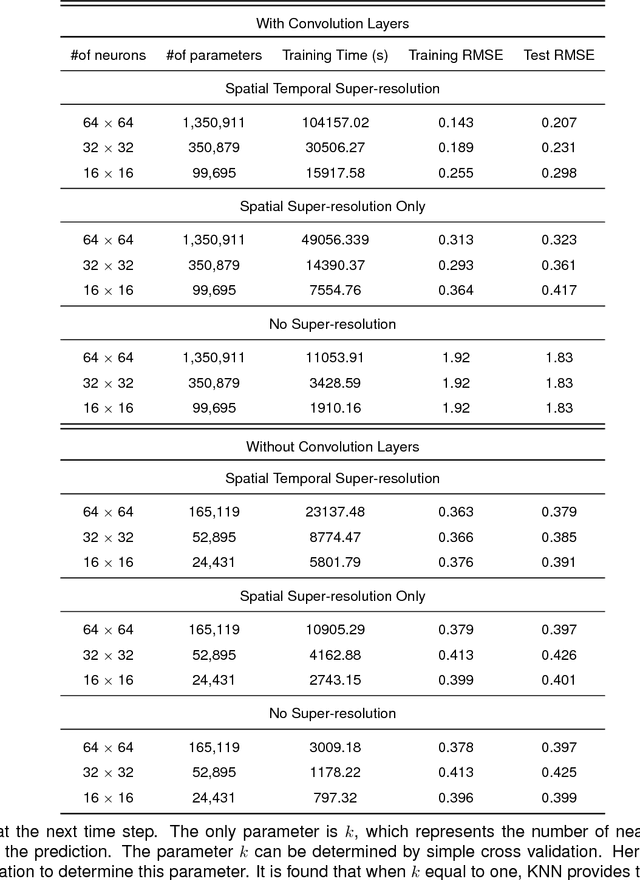
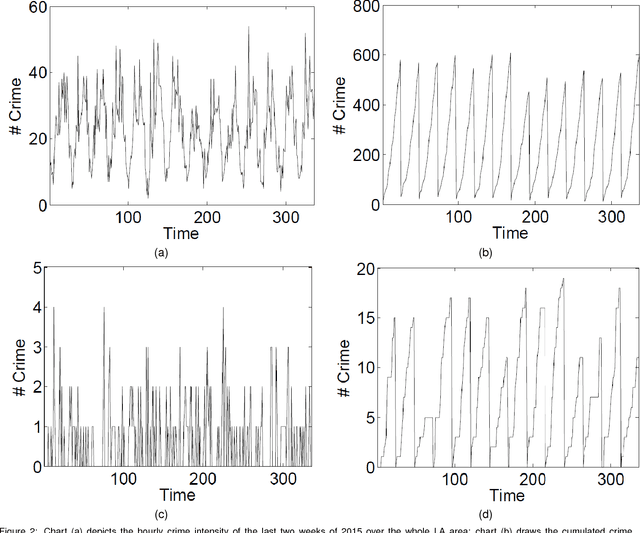
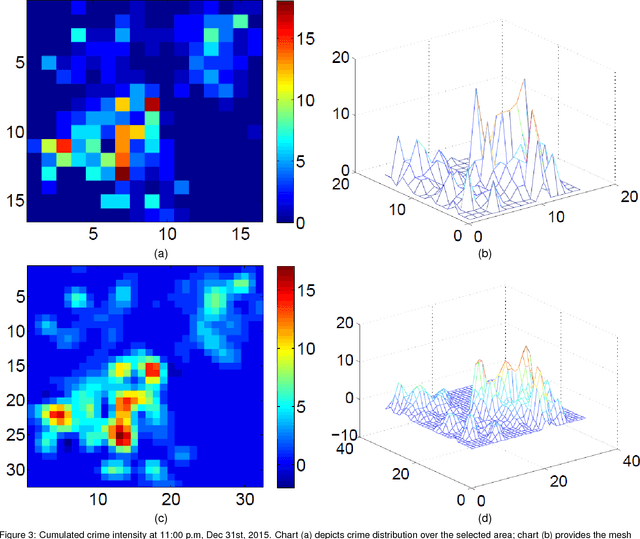
Real-time crime forecasting is important. However, accurate prediction of when and where the next crime will happen is difficult. No known physical model provides a reasonable approximation to such a complex system. Historical crime data are sparse in both space and time and the signal of interests is weak. In this work, we first present a proper representation of crime data. We then adapt the spatial temporal residual network on the well represented data to predict the distribution of crime in Los Angeles at the scale of hours in neighborhood-sized parcels. These experiments as well as comparisons with several existing approaches to prediction demonstrate the superiority of the proposed model in terms of accuracy. Finally, we present a ternarization technique to address the resource consumption issue for its deployment in real world. This work is an extension of our short conference proceeding paper [Wang et al, Arxiv 1707.03340].
On Riemannian Stochastic Approximation Schemes with Fixed Step-Size
Feb 19, 2021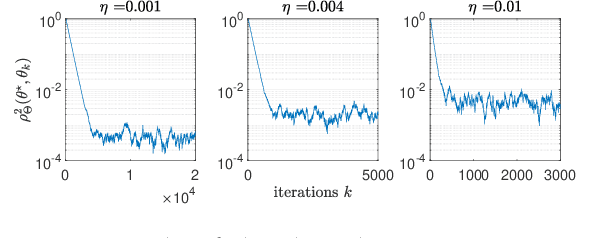
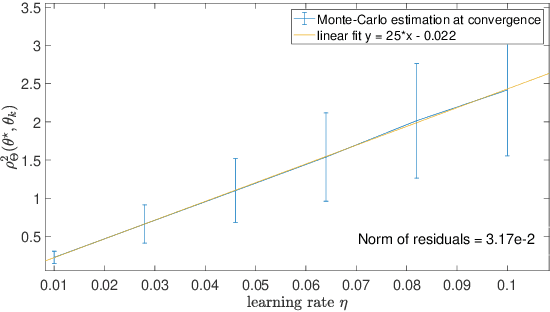
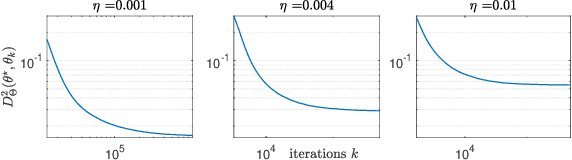
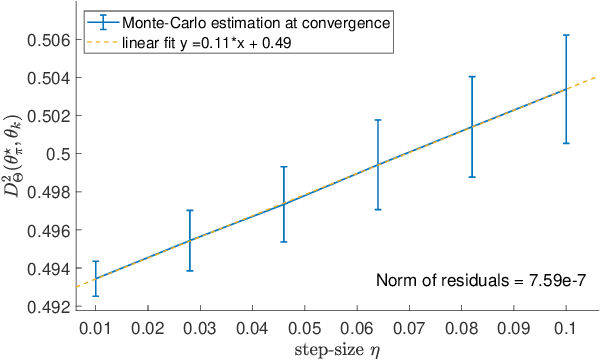
This paper studies fixed step-size stochastic approximation (SA) schemes, including stochastic gradient schemes, in a Riemannian framework. It is motivated by several applications, where geodesics can be computed explicitly, and their use accelerates crude Euclidean methods. A fixed step-size scheme defines a family of time-homogeneous Markov chains, parametrized by the step-size. Here, using this formulation, non-asymptotic performance bounds are derived, under Lyapunov conditions. Then, for any step-size, the corresponding Markov chain is proved to admit a unique stationary distribution, and to be geometrically ergodic. This result gives rise to a family of stationary distributions indexed by the step-size, which is further shown to converge to a Dirac measure, concentrated at the solution of the problem at hand, as the step-size goes to 0. Finally, the asymptotic rate of this convergence is established, through an asymptotic expansion of the bias, and a central limit theorem.
Modelling Early User-Game Interactions for Joint Estimation of Survival Time and Churn Probability
May 31, 2019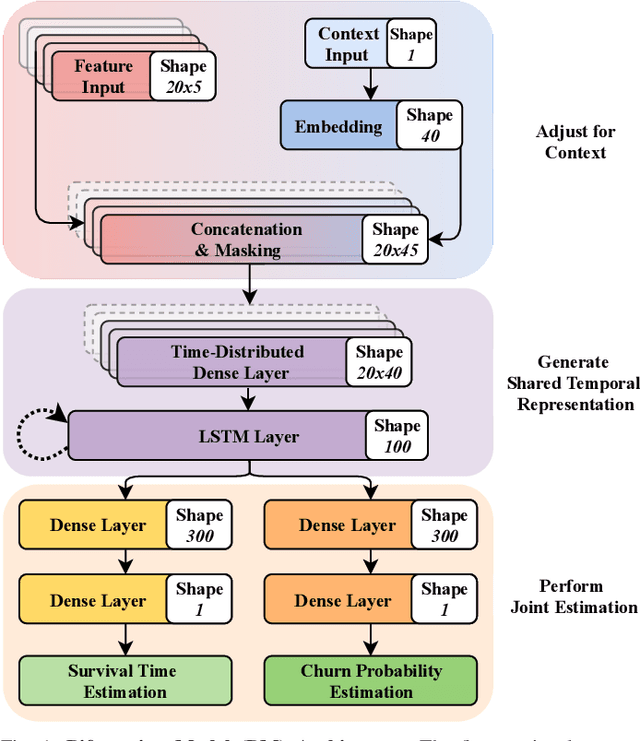
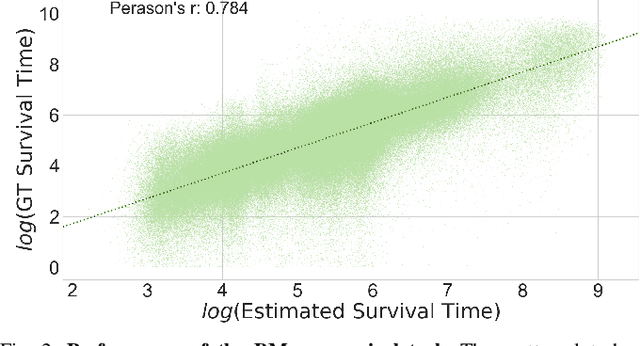
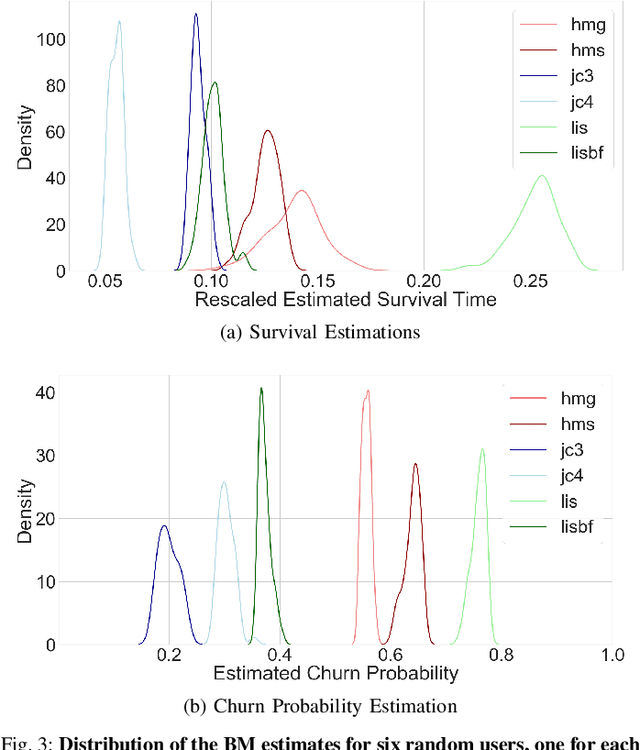

Data-driven approaches which aim to identify and predict player engagement are becoming increasingly popular in games industry contexts. This is due to the growing practice of tracking and storing large volumes of in-game telemetries coupled with a desire to tailor the gaming experience to the end-user's needs. These approaches are particularly useful not just for companies adopting Game-as-a-Service (GaaS) models (e.g. for re-engagement strategies) but also for those working under persistent content-delivery regimes (e.g. for better audience targeting). A major challenge for the latter is to build engagement models of the user which are data-efficient, holistic and can generalize across multiple game titles and genres with minimal adjustments. This work leverages a theoretical framework rooted in engagement and behavioural science research for building a model able to estimate engagement-related behaviours employing only a minimal set of game-agnostic metrics. Through a series of experiments we show how, by modelling early user-game interactions, this approach can make joint estimates of long-term survival time and churn probability across several single-player games in a range of genres. The model proposed is very suitable for industry applications since it relies on a minimal set of metrics and observations, scales well with the number of users and is explicitly designed to work across a diverse range of titles.
Continual Density Ratio Estimation in an Online Setting
Mar 09, 2021
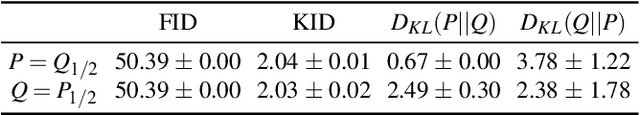
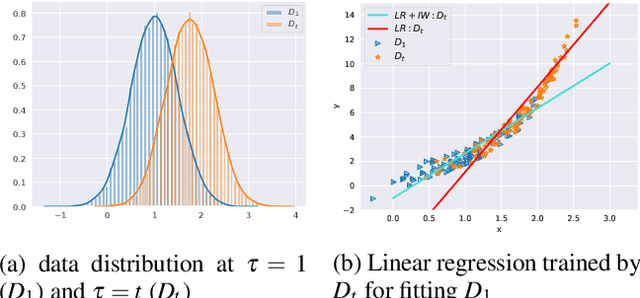
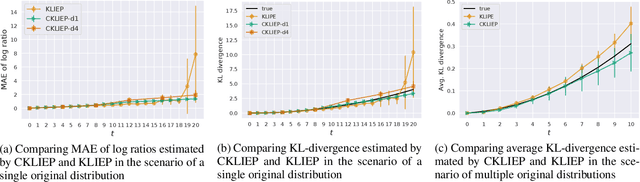
In online applications with streaming data, awareness of how far the training or test set has shifted away from the original dataset can be crucial to the performance of the model. However, we may not have access to historical samples in the data stream. To cope with such situations, we propose a novel method, Continual Density Ratio Estimation (CDRE), for estimating density ratios between the initial and current distributions ($p/q_t$) of a data stream in an iterative fashion without the need of storing past samples, where $q_t$ is shifting away from $p$ over time $t$. We demonstrate that CDRE can be more accurate than standard DRE in terms of estimating divergences between distributions, despite not requiring samples from the original distribution. CDRE can be applied in scenarios of online learning, such as importance weighted covariate shift, tracing dataset changes for better decision making. In addition, (CDRE) enables the evaluation of generative models under the setting of continual learning. To the best of our knowledge, there is no existing method that can evaluate generative models in continual learning without storing samples from the original distribution.
A 3D Non-stationary MmWave Channel Model for Vacuum Tube Ultra-High-Speed Train Channels
Feb 09, 2021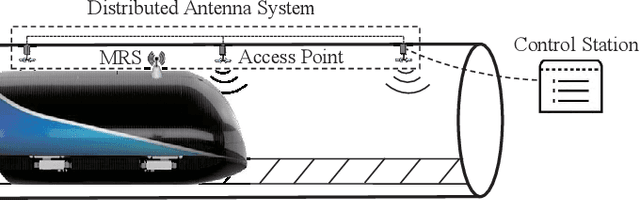
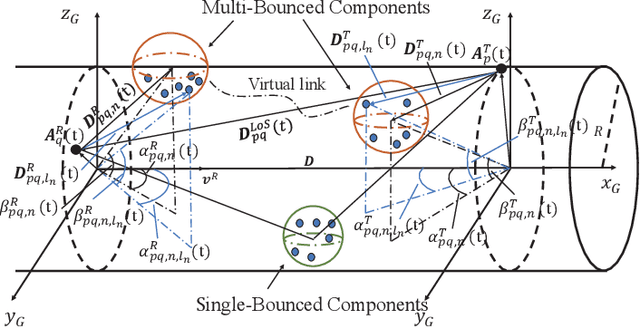
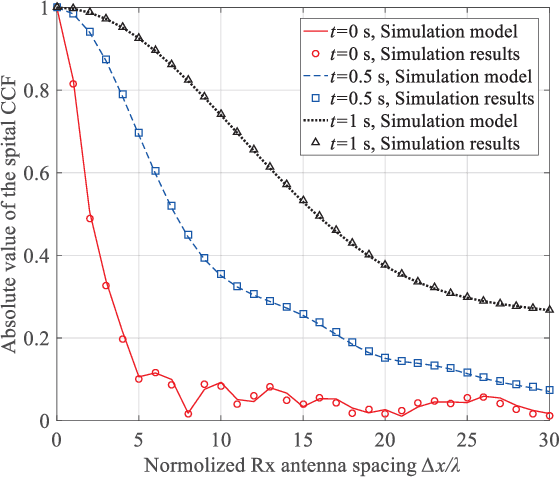
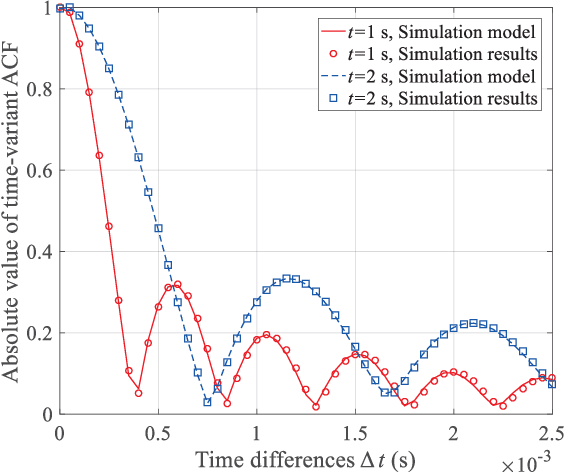
As a potential development direction of future transportation, the vacuum tube ultra-high-speed train (UHST) wireless communication systems have newly different channel characteristics from existing high-speed train (HST) scenarios. In this paper, a three-dimensional non-stationary millimeter wave (mmWave) geometry-based stochastic model (GBSM) is proposed to investigate the channel characteristics of UHST channels in vacuum tube scenarios, taking into account the waveguide effect and the impact of tube wall roughness on channel. Then, based on the proposed model, some important time-variant channel statistical properties are studied and compared with those in existing HST and tunnel channels. The results obtained show that the multipath effect in vacuum tube scenarios will be more obvious than tunnel scenarios but less than existing HST scenarios, which will provide some insights for future research on vacuum tube UHST wireless communications.
Contrastive Learning of Musical Representations
Mar 17, 2021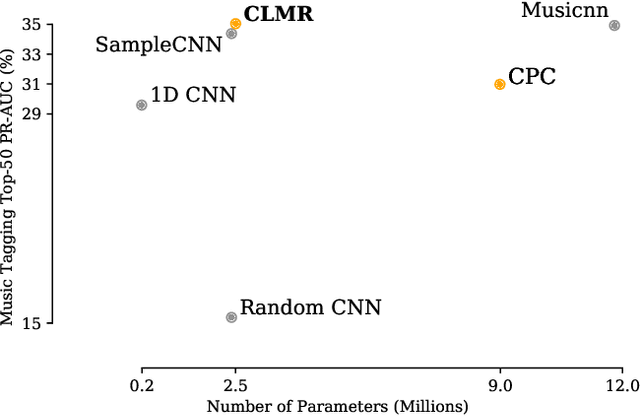
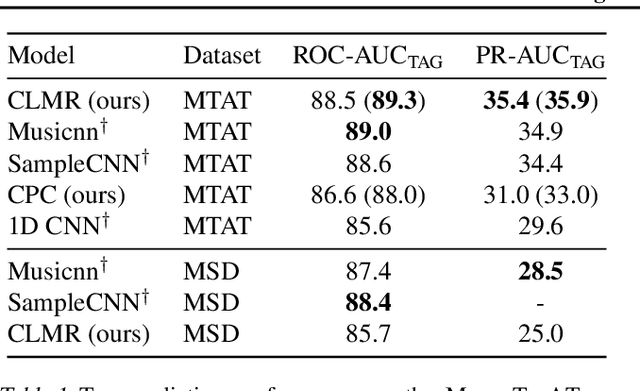
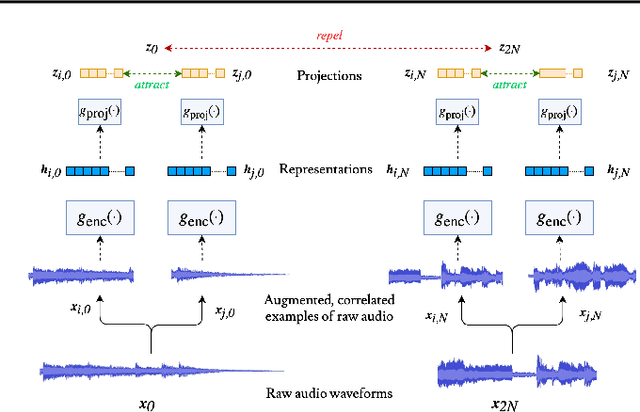
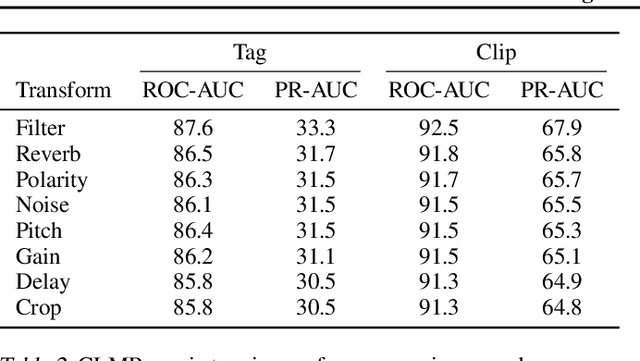
While supervised learning has enabled great advances in many areas of music, labeled music datasets remain especially hard, expensive and time-consuming to create. In this work, we introduce SimCLR to the music domain and contribute a large chain of audio data augmentations, to form a simple framework for self-supervised learning of raw waveforms of music: CLMR. This approach requires no manual labeling and no preprocessing of music to learn useful representations. We evaluate CLMR in the downstream task of music classification on the MagnaTagATune and Million Song datasets. A linear classifier fine-tuned on representations from a pre-trained CLMR model achieves an average precision of 35.4% on the MagnaTagATune dataset, superseding fully supervised models that currently achieve a score of 34.9%. Moreover, we show that CLMR's representations are transferable using out-of-domain datasets, indicating that they capture important musical knowledge. Lastly, we show that self-supervised pre-training allows us to learn efficiently on smaller labeled datasets: we still achieve a score of 33.1% despite using only 259 labeled songs during fine-tuning. To foster reproducibility and future research on self-supervised learning in music, we publicly release the pre-trained models and the source code of all experiments of this paper on GitHub.
Convex Online Video Frame Subset Selection using Multiple Criteria for Data Efficient Autonomous Driving
Mar 24, 2021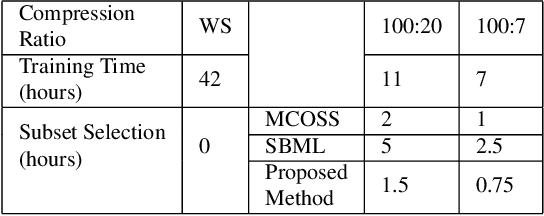
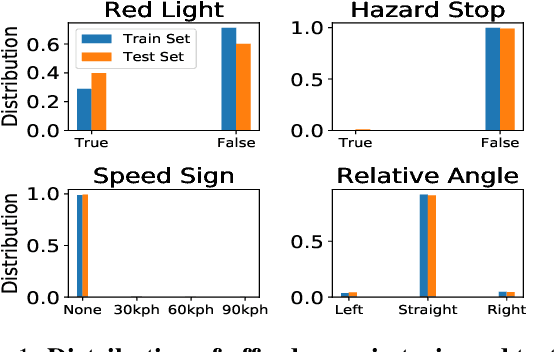
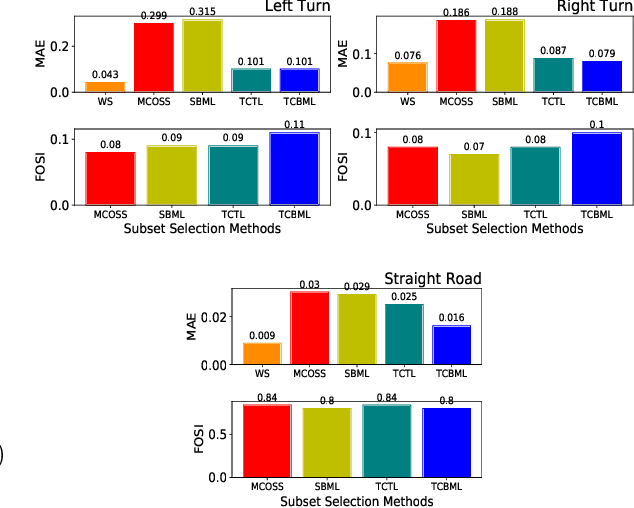
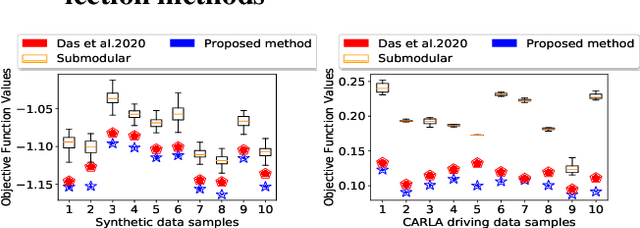
Training vision-based Urban Autonomous driving models is a challenging problem, which is highly researched in recent times. Training such models is a data-intensive task requiring the storage and processing of vast volumes of (possibly redundant) driving video data. In this paper, we study the problem of developing data-efficient autonomous driving systems. In this context, we study the problem of multi-criteria online video frame subset selection. We study convex optimization-based solutions and show that they are unable to provide solutions with high weightage to the loss of selected video frames. We design a novel convex optimization-based multi-criteria online subset selection algorithm that uses a thresholded concave function of selection variables. We also propose and study a submodular optimization-based algorithm. Extensive experiments using the driving simulator CARLA show that we are able to drop 80% of the frames while succeeding to complete 100% of the episodes w.r.t. the model trained on 100% data, in the most difficult task of taking turns. This results in a training time of less than 30% compared to training on the whole dataset. We also perform detailed experiments on prediction performances of various affordances used by the Conditional Affordance Learning (CAL) model and show that our subset selection improves performance on the crucial affordance "Relative Angle" during turns.
X-view: Non-egocentric Multi-View 3D Object Detector
Mar 24, 2021
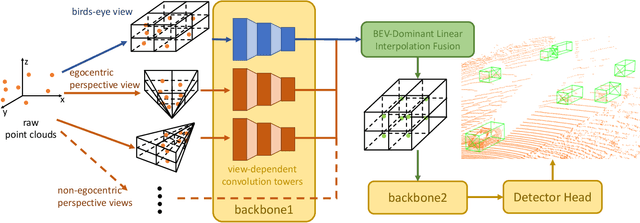

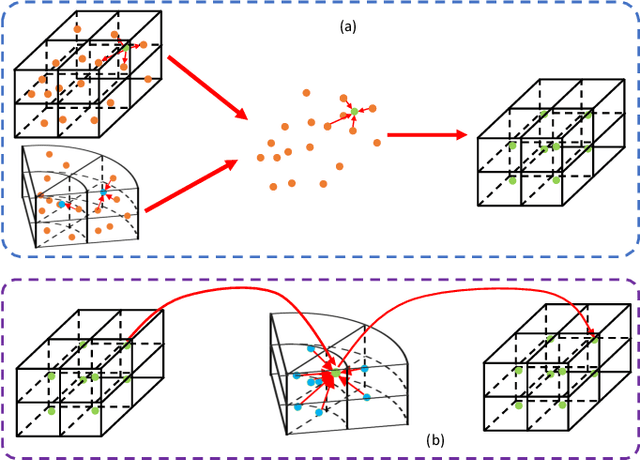
3D object detection algorithms for autonomous driving reason about 3D obstacles either from 3D birds-eye view or perspective view or both. Recent works attempt to improve the detection performance via mining and fusing from multiple egocentric views. Although the egocentric perspective view alleviates some weaknesses of the birds-eye view, the sectored grid partition becomes so coarse in the distance that the targets and surrounding context mix together, which makes the features less discriminative. In this paper, we generalize the research on 3D multi-view learning and propose a novel multi-view-based 3D detection method, named X-view, to overcome the drawbacks of the multi-view methods. Specifically, X-view breaks through the traditional limitation about the perspective view whose original point must be consistent with the 3D Cartesian coordinate. X-view is designed as a general paradigm that can be applied on almost any 3D detectors based on LiDAR with only little increment of running time, no matter it is voxel/grid-based or raw-point-based. We conduct experiments on KITTI and NuScenes datasets to demonstrate the robustness and effectiveness of our proposed X-view. The results show that X-view obtains consistent improvements when combined with four mainstream state-of-the-art 3D methods: SECOND, PointRCNN, Part-A^2, and PV-RCNN.
Stochastic Attention Head Removal: A Simple and Effective Method for Improving Automatic Speech Recognition with Transformers
Nov 08, 2020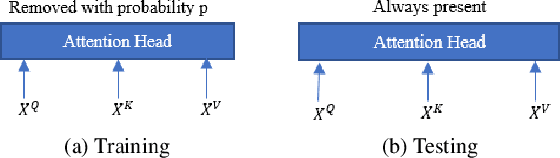
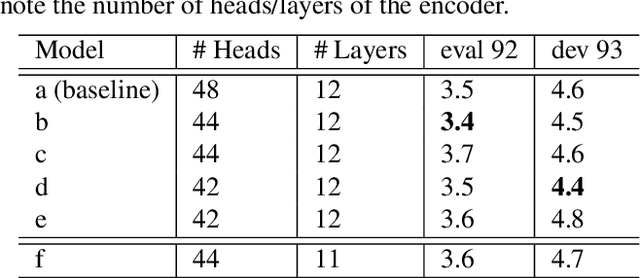
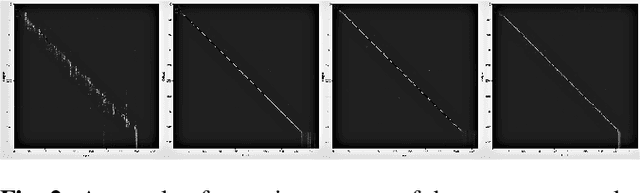
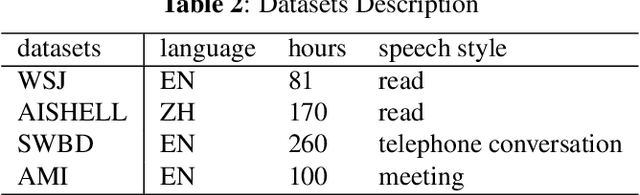
Recently, Transformers have shown competitive automatic speech recognition (ASR) results. One key factor to the success of these models is the multi-head attention mechanism. However, we observed in trained models, the diagonal attention matrices indicating the redundancy of the corresponding attention heads. Furthermore, we found some architectures with reduced numbers of attention heads have better performance. Since the search for the best structure is time prohibitive, we propose to randomly remove attention heads during training and keep all attention heads at test time, thus the final model can be viewed as an average of models with different architectures. This method gives consistent performance gains on the Wall Street Journal, AISHELL, Switchboard and AMI ASR tasks. On the AISHELL dev/test sets, the proposed method achieves state-of-the-art Transformer results with 5.8%/6.3% word error rates.