 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Estimating causal effects of time-dependent exposures on a binary endpoint in a high-dimensional setting
Mar 29, 2018
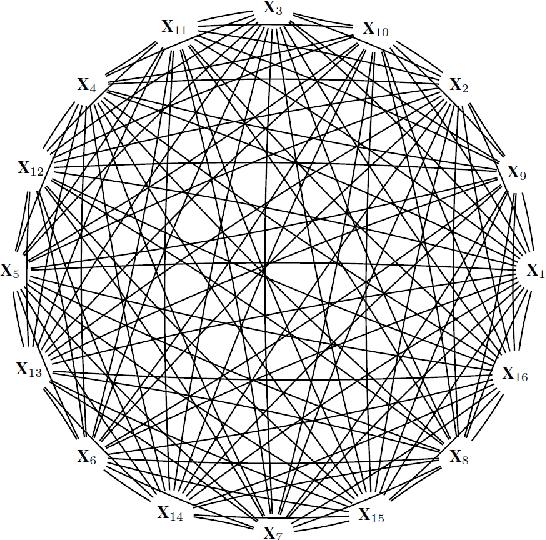
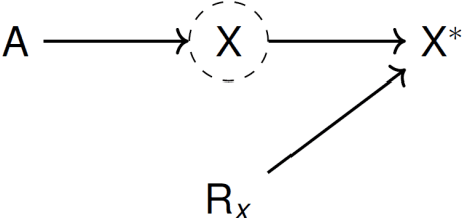
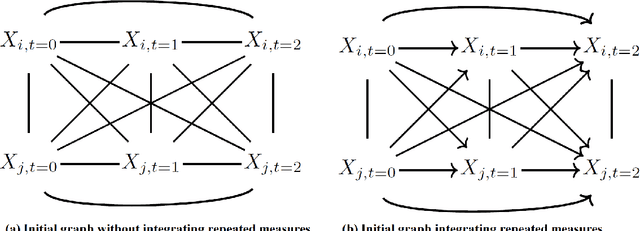
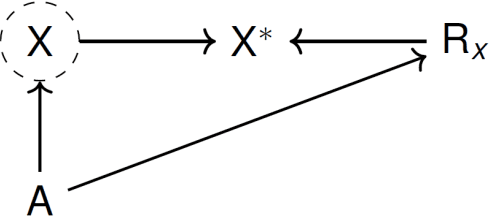
Recently, the intervention calculus when the DAG is absent (IDA) method was developed to estimate lower bounds of causal effects from observational high-dimensional data. Originally it was introduced to assess the effect of baseline biomarkers which do not vary over time. However, in many clinical settings, measurements of biomarkers are repeated at fixed time points during treatment exposure and, therefore, this method need to be extended. The purpose of this paper is then to extend the first step of the IDA, the Peter Clarks (PC)-algorithm, to a time-dependent exposure in the context of a binary outcome. We generalised the PC-algorithm for taking into account the chronological order of repeated measurements of the exposure and propose to apply the IDA with our new version, the chronologically ordered PC-algorithm (COPC-algorithm). A simulation study has been performed before applying the method for estimating causal effects of time-dependent immunological biomarkers on toxicity, death and progression in patients with metastatic melanoma. The simulation study showed that the completed partially directed acyclic graphs (CPDAGs) obtained using COPC-algorithm were structurally closer to the true CPDAG than CPDAGs obtained using PC-algorithm. Also, causal effects were more accurate when they were estimated based on CPDAGs obtained using COPC-algorithm. Moreover, CPDAGs obtained by COPC-algorithm allowed removing non-chronologic arrows with a variable measured at a time t pointing to a variable measured at a time t' where t'< t. Bidirected edges were less present in CPDAGs obtained with the COPC-algorithm, supporting the fact that there was less variability in causal effects estimated from these CPDAGs. The COPC-algorithm provided CPDAGs that keep the chronological structure present in the data, thus allowed to estimate lower bounds of the causal effect of time-dependent biomarkers.
OTCE: A Transferability Metric for Cross-Domain Cross-Task Representations
Mar 25, 2021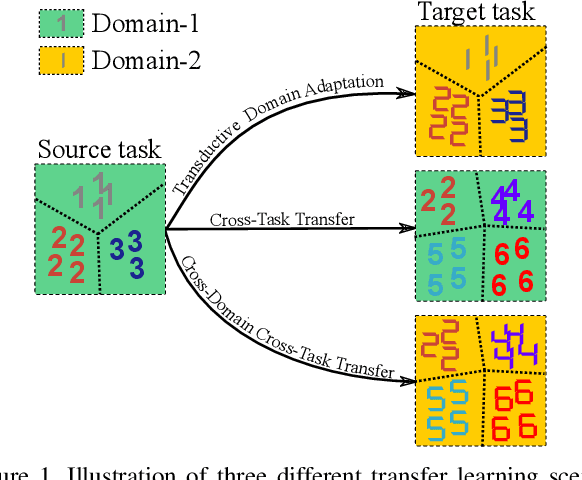
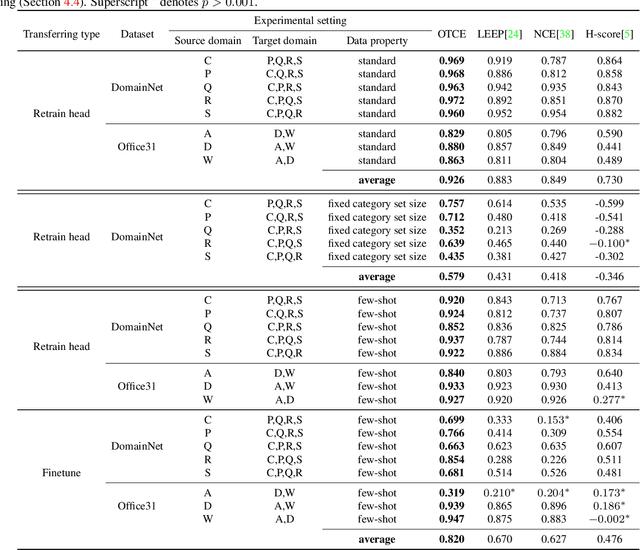
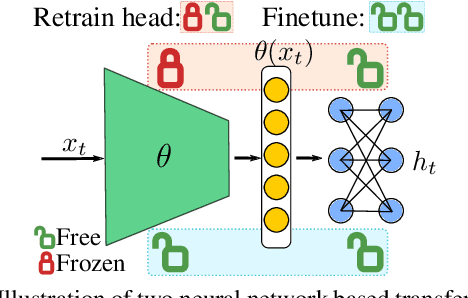
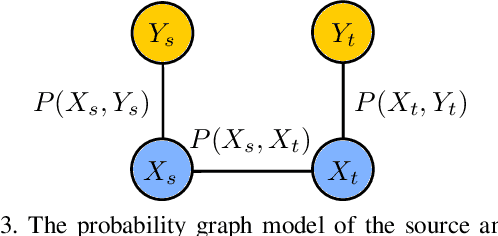
Transfer learning across heterogeneous data distributions (a.k.a. domains) and distinct tasks is a more general and challenging problem than conventional transfer learning, where either domains or tasks are assumed to be the same. While neural network based feature transfer is widely used in transfer learning applications, finding the optimal transfer strategy still requires time-consuming experiments and domain knowledge. We propose a transferability metric called Optimal Transport based Conditional Entropy (OTCE), to analytically predict the transfer performance for supervised classification tasks in such cross-domain and cross-task feature transfer settings. Our OTCE score characterizes transferability as a combination of domain difference and task difference, and explicitly evaluates them from data in a unified framework. Specifically, we use optimal transport to estimate domain difference and the optimal coupling between source and target distributions, which is then used to derive the conditional entropy of the target task (task difference). Experiments on the largest cross-domain dataset DomainNet and Office31 demonstrate that OTCE shows an average of 21% gain in the correlation with the ground truth transfer accuracy compared to state-of-the-art methods. We also investigate two applications of the OTCE score including source model selection and multi-source feature fusion.
Power Minimization in Vehicular Cloud Architecture
Feb 17, 2021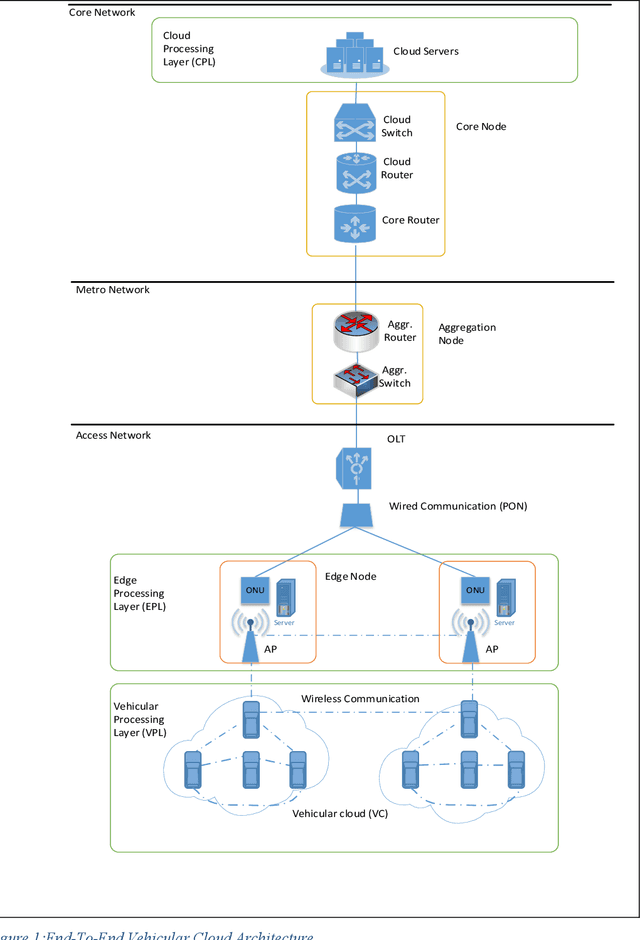
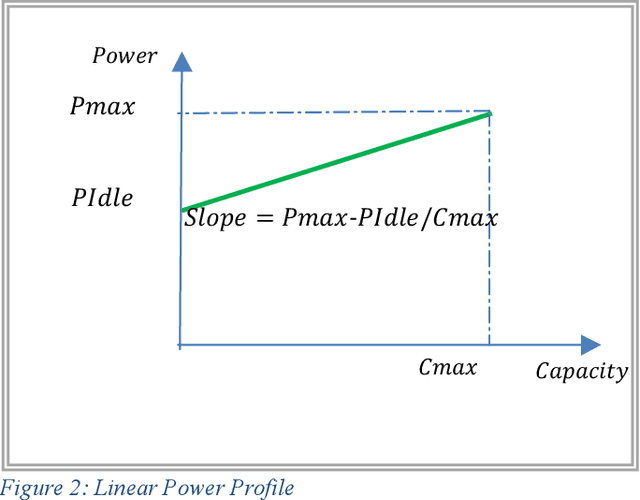
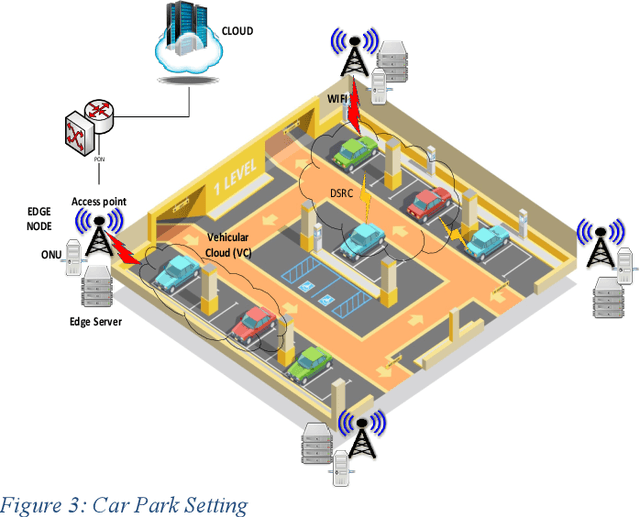
Modern vehicles equipped with on-board units (OBU) are playing an essential role in the smart city revolution. The vehicular processing resources, however, are not used to their fullest potential. The concept of vehicular clouds is proposed to exploit the underutilized vehicular resources to supplement cloud computing services to relieve the burden on cloud data centers and improve quality of service. In this paper we introduce a vehicular cloud architecture supported by fixed edge computing nodes and the central cloud. A mixed integer linear programming (MLP) model is developed to optimize the allocation of the computing demands in the distributed architecture while minimizing power consumption. The results show power savings as high as 84% over processing in the conventional cloud. A heuristic with performance approaching that of the MILP model is developed to allocate computing demands in real time.
A multi-modal approach towards mining social media data during natural disasters -- a case study of Hurricane Irma
Jan 02, 2021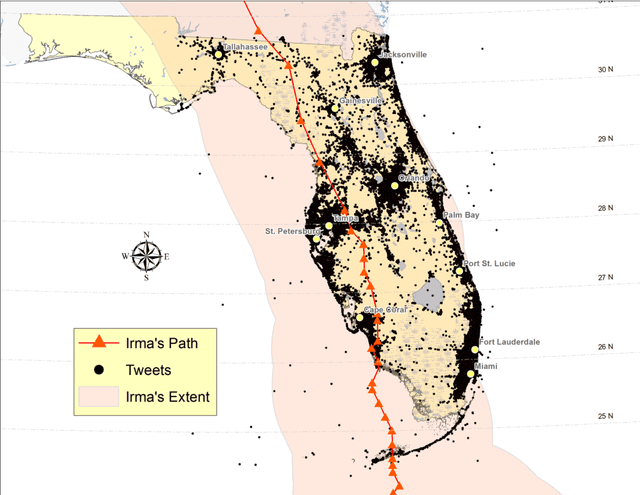
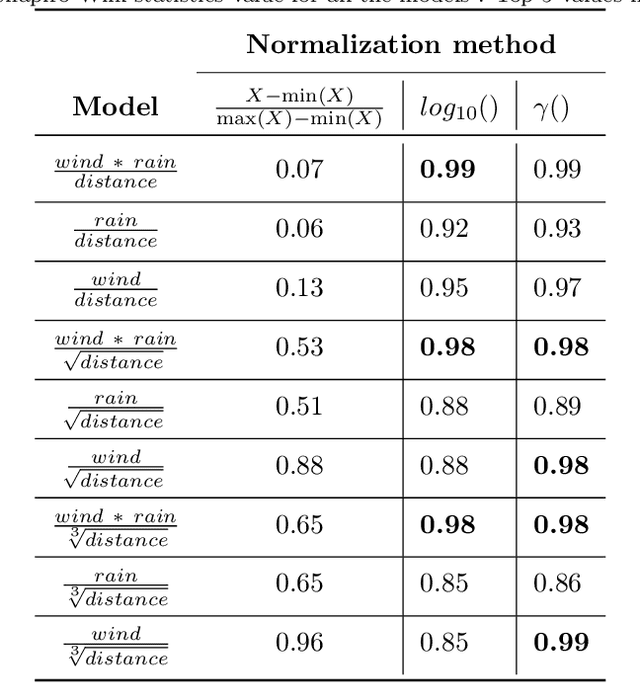
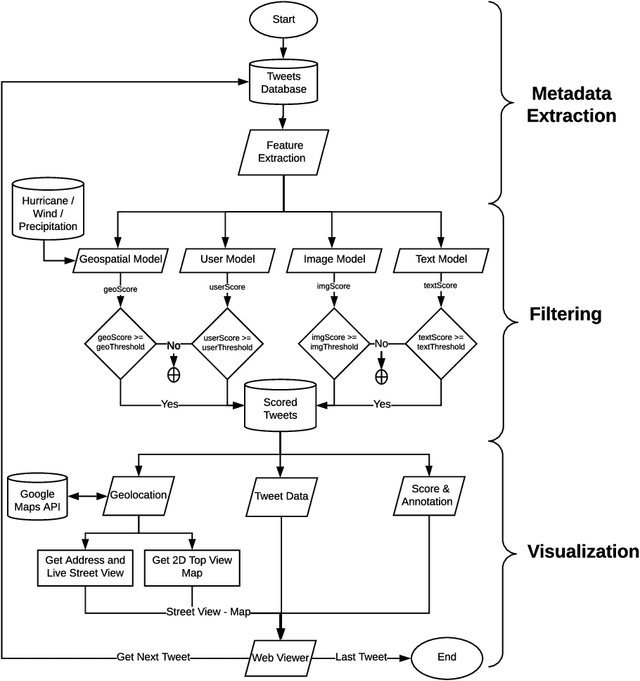
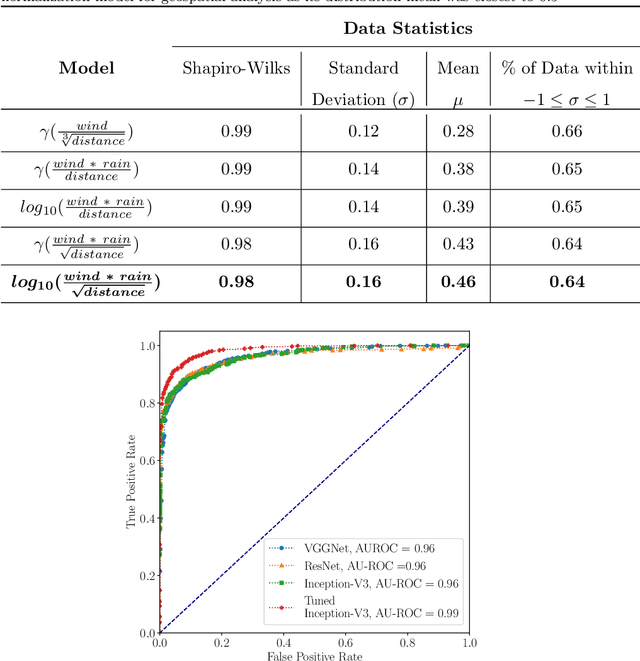
Streaming social media provides a real-time glimpse of extreme weather impacts. However, the volume of streaming data makes mining information a challenge for emergency managers, policy makers, and disciplinary scientists. Here we explore the effectiveness of data learned approaches to mine and filter information from streaming social media data from Hurricane Irma's landfall in Florida, USA. We use 54,383 Twitter messages (out of 784K geolocated messages) from 16,598 users from Sept. 10 - 12, 2017 to develop 4 independent models to filter data for relevance: 1) a geospatial model based on forcing conditions at the place and time of each tweet, 2) an image classification model for tweets that include images, 3) a user model to predict the reliability of the tweeter, and 4) a text model to determine if the text is related to Hurricane Irma. All four models are independently tested, and can be combined to quickly filter and visualize tweets based on user-defined thresholds for each submodel. We envision that this type of filtering and visualization routine can be useful as a base model for data capture from noisy sources such as Twitter. The data can then be subsequently used by policy makers, environmental managers, emergency managers, and domain scientists interested in finding tweets with specific attributes to use during different stages of the disaster (e.g., preparedness, response, and recovery), or for detailed research.
Ultra-Fast Shapelets for Time Series Classification
Mar 17, 2015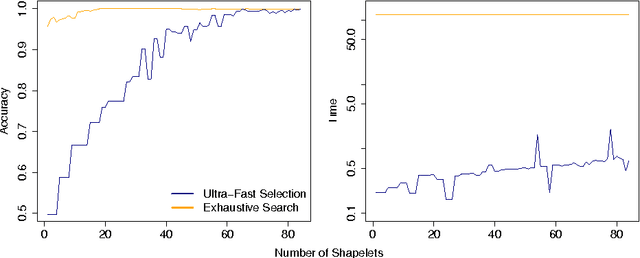
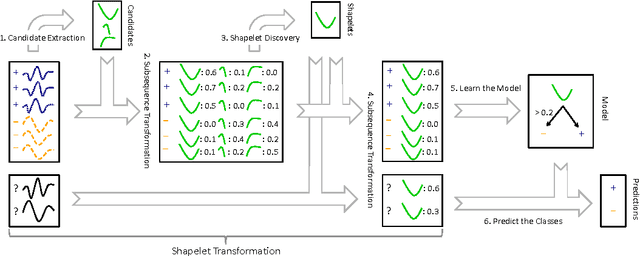
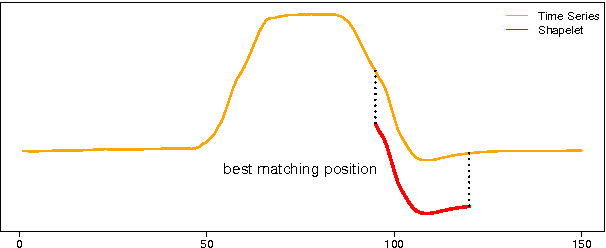
Time series shapelets are discriminative subsequences and their similarity to a time series can be used for time series classification. Since the discovery of time series shapelets is costly in terms of time, the applicability on long or multivariate time series is difficult. In this work we propose Ultra-Fast Shapelets that uses a number of random shapelets. It is shown that Ultra-Fast Shapelets yield the same prediction quality as current state-of-the-art shapelet-based time series classifiers that carefully select the shapelets by being by up to three orders of magnitudes. Since this method allows a ultra-fast shapelet discovery, using shapelets for long multivariate time series classification becomes feasible. A method for using shapelets for multivariate time series is proposed and Ultra-Fast Shapelets is proven to be successful in comparison to state-of-the-art multivariate time series classifiers on 15 multivariate time series datasets from various domains. Finally, time series derivatives that have proven to be useful for other time series classifiers are investigated for the shapelet-based classifiers. It is shown that they have a positive impact and that they are easy to integrate with a simple preprocessing step, without the need of adapting the shapelet discovery algorithm.
A deep learning-based ODE solver for chemical kinetics
Nov 24, 2020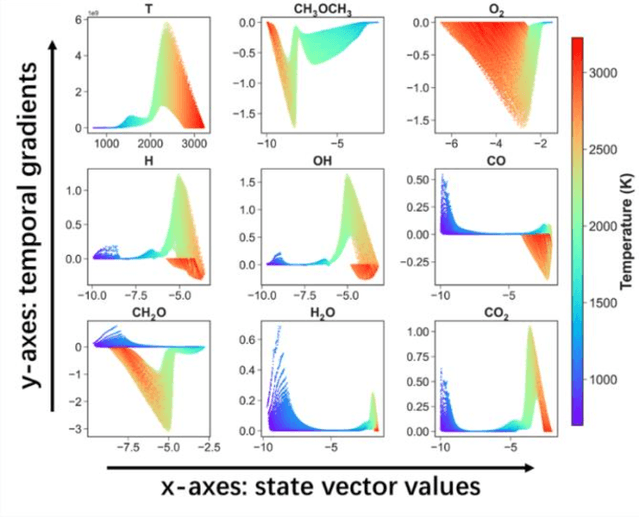
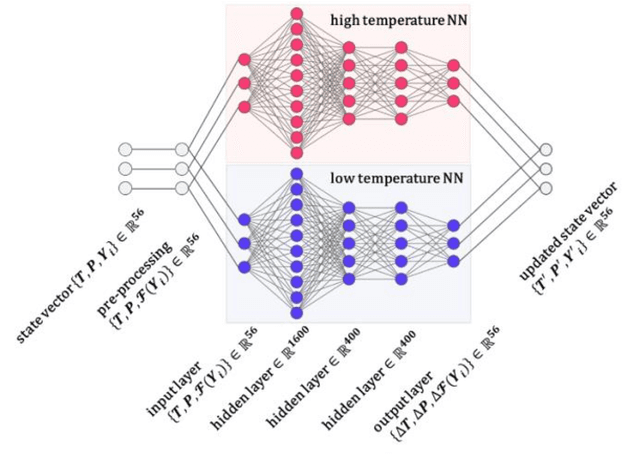
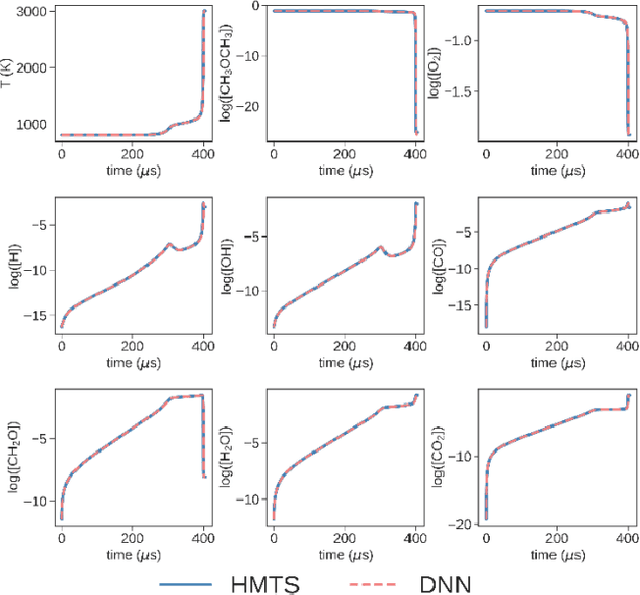
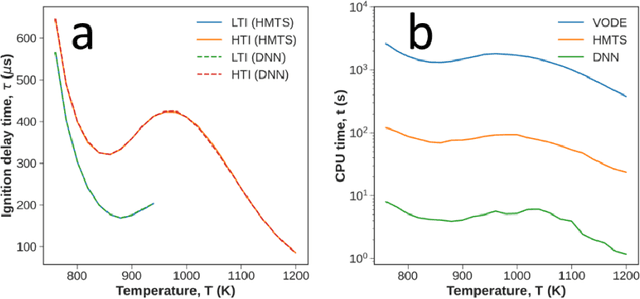
Developing efficient and accurate algorithms for chemistry integration is a challenging task due to its strong stiffness and high dimensionality. The current work presents a deep learning-based numerical method called DeepCombustion0.0 to solve stiff ordinary differential equation systems. The homogeneous autoignition of DME/air mixture, including 54 species, is adopted as an example to illustrate the validity and accuracy of the algorithm. The training and testing datasets cover a wide range of temperature, pressure, and mixture conditions between 750-1200 K, 30-50 atm, and equivalence ratio = 0.7-1.5. Both the first-stage low-temperature ignition (LTI) and the second-stage high-temperature ignition (HTI) are considered. The methodology highlights the importance of the adaptive data sampling techniques, power transform preprocessing, and binary deep neural network (DNN) design. By using the adaptive random samplings and appropriate power transforms, smooth submanifolds in the state vector phase space are observed, on which two three-layer DNNs can be appropriately trained. The neural networks are end-to-end, which predict temporal gradients of the state vectors directly. The results show that temporal evolutions predicted by DNN agree well with traditional numerical methods in all state vector dimensions, including temperature, pressure, and species concentrations. Besides, the ignition delay time differences are within 1%. At the same time, the CPU time is reduced by more than 20 times and 200 times compared with the HMTS and VODE method, respectively. The current work demonstrates the enormous potential of applying the deep learning algorithm in chemical kinetics and combustion modeling.
Cost-Sensitive Convolution based Neural Networks for Imbalanced Time-Series Classification
Jan 13, 2018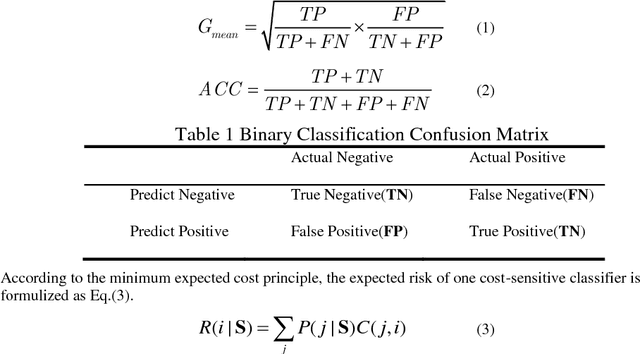
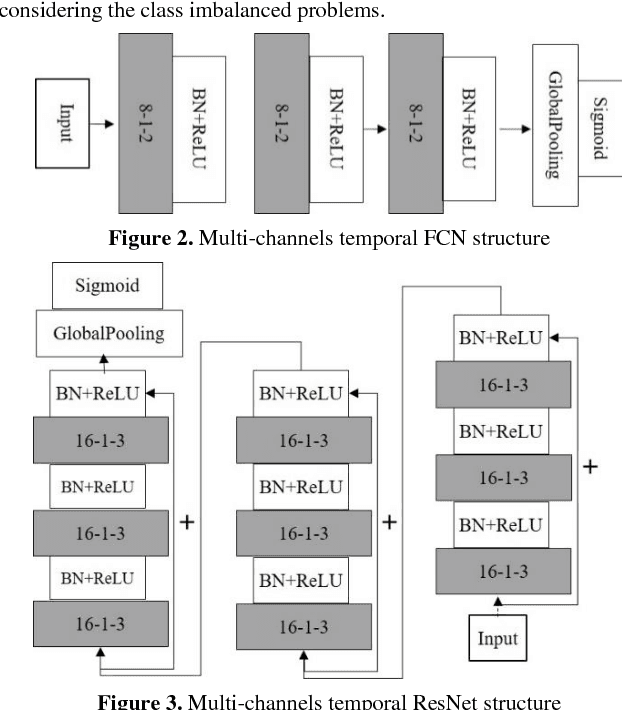
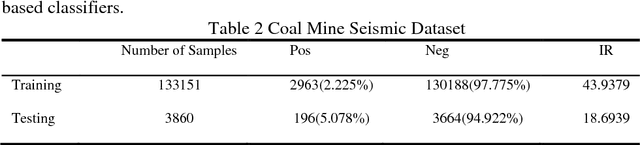
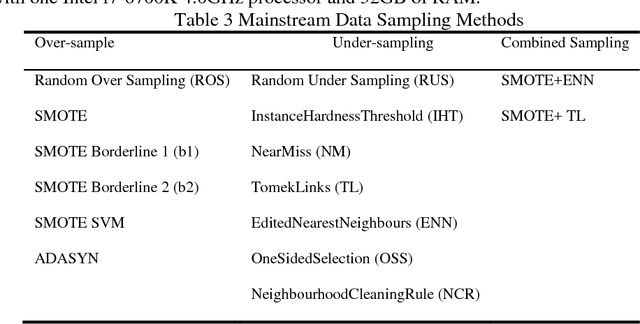
Some deep convolutional neural networks were proposed for time-series classification and class imbalanced problems. However, those models performed degraded and even failed to recognize the minority class of an imbalanced temporal sequences dataset. Minority samples would bring troubles for temporal deep learning classifiers due to the equal treatments of majority and minority class. Until recently, there were few works applying deep learning on imbalanced time-series classification (ITSC) tasks. Here, this paper aimed at tackling ITSC problems with deep learning. An adaptive cost-sensitive learning strategy was proposed to modify temporal deep learning models. Through the proposed strategy, classifiers could automatically assign misclassification penalties to each class. In the experimental section, the proposed method was utilized to modify five neural networks. They were evaluated on a large volume, real-life and imbalanced time-series dataset with six metrics. Each single network was also tested alone and combined with several mainstream data samplers. Experimental results illustrated that the proposed cost-sensitive modified networks worked well on ITSC tasks. Compared to other methods, the cost-sensitive convolution neural network and residual network won out in the terms of all metrics. Consequently, the proposed cost-sensitive learning strategy can be used to modify deep learning classifiers from cost-insensitive to cost-sensitive. Those cost-sensitive convolutional networks can be effectively applied to address ITSC issues.
Deep Learning based Extreme Heatwave Forecast
Mar 17, 2021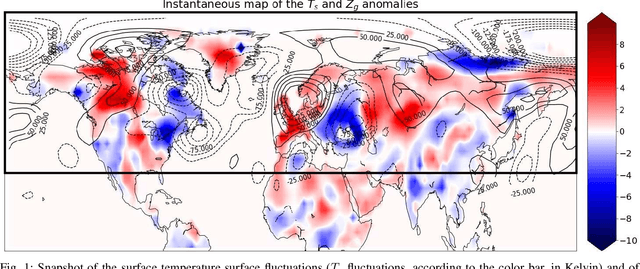
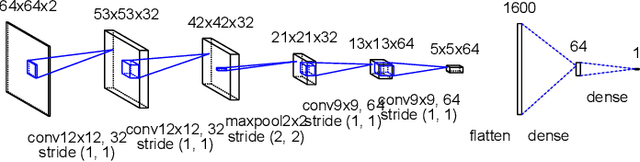
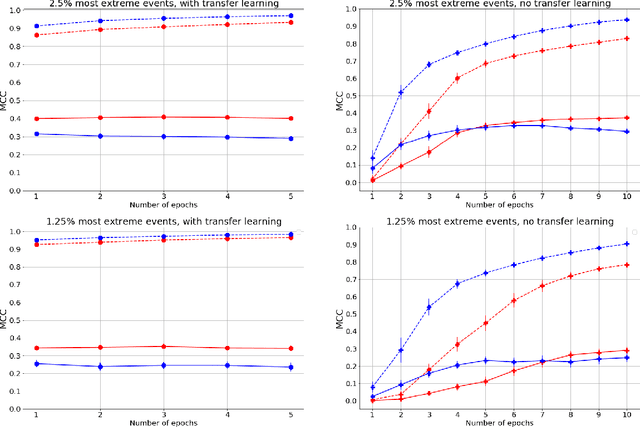
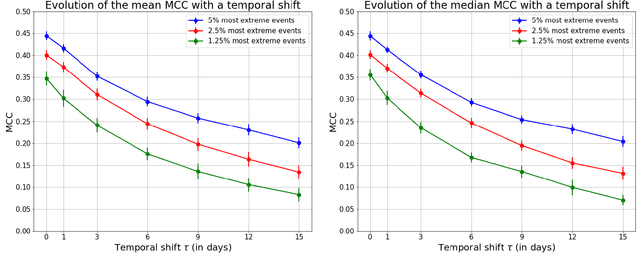
Forecasting the occurrence of heatwaves constitutes a challenging issue, yet of major societal stake, because extreme events are not often observed and (very) costly to simulate from physics-driven numerical models. The present work aims to explore the use of Deep Learning architectures as alternative strategies to predict extreme heatwaves occurrences from a very limited amount of available relevant climate data. This implies addressing issues such as the aggregation of climate data of different natures, the class-size imbalance that is intrinsically associated with rare event prediction, and the potential benefits of transfer learning to address the nested nature of extreme events (naturally included in less extreme ones). Using 1000 years of state-of-the-art PlaSim Planete Simulator Climate Model data, it is shown that Convolutional Neural Network-based Deep Learning frameworks, with large-class undersampling and transfer learning achieve significant performance in forecasting the occurrence of extreme heatwaves, at three different levels of intensity, and as early as 15 days in advance from the restricted observation, for a single time (single snapshoot) of only two spatial fields of climate data, surface temperature and geopotential height.
Tag-based Genetic Regulation for Genetic Programming
Dec 16, 2020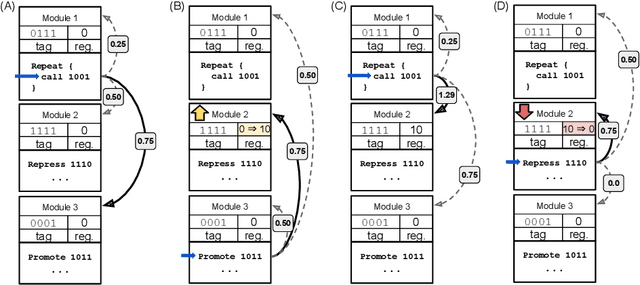
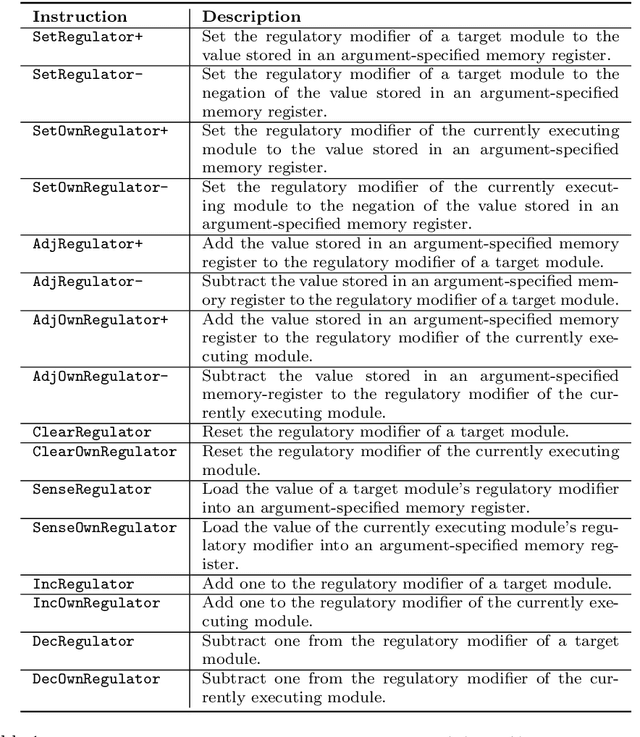
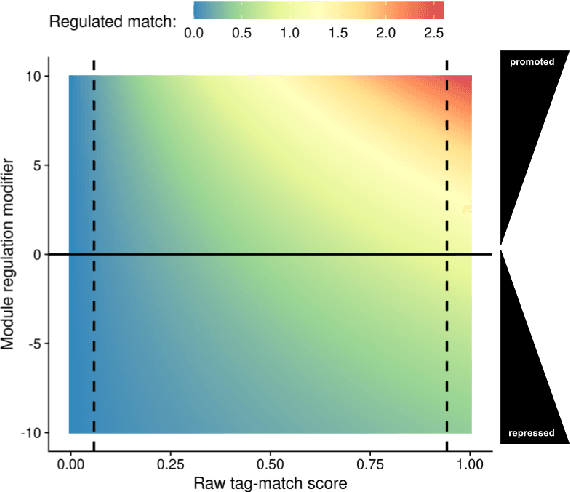
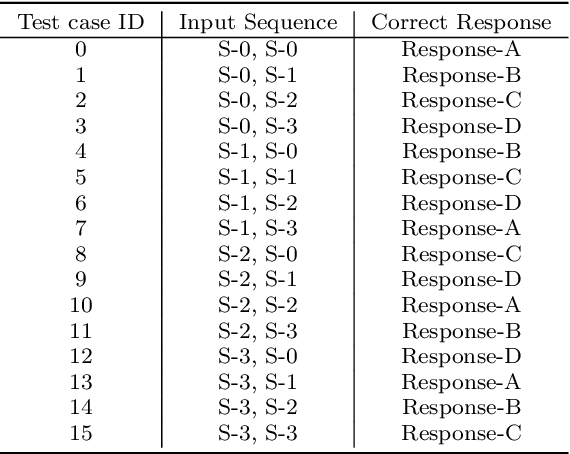
We introduce and experimentally demonstrate tag-based genetic regulation, a new genetic programming (GP) technique that allows evolving programs to conditionally express code modules. Tags are evolvable names that provide a flexible mechanism for labeling and referring to code modules. Tag-based genetic regulation extends existing tag-based naming schemes to allow programs to "promote" and "repress" code modules. This extension allows evolution to structure a program as an arbitrary gene regulatory network where genes are program modules and program instructions mediate regulation. We demonstrate the functionality of tag-based regulation on several diagnostic tasks as well as a more challenging program synthesis problem. We find that tag-based regulation improves problem-solving performance on context-dependent problems where programs must adjust responses to particular inputs over time (e.g., based on local context). We also observe that our implementation of tag-based genetic regulation can impede adaptive evolution when expected outputs are not context-dependent (i.e., the correct response to a particular input remains static over time). Tag-based genetic regulation broadens our repertoire of techniques for evolving more dynamic genetic programs and can easily be incorporated into existing tag-enabled GP systems.
Estimating Traffic Speeds using Probe Data: A Deep Neural Network Approach
Apr 19, 2021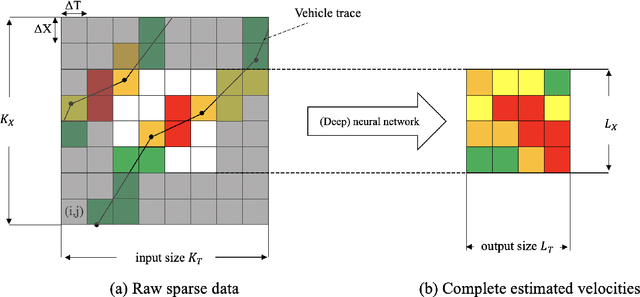
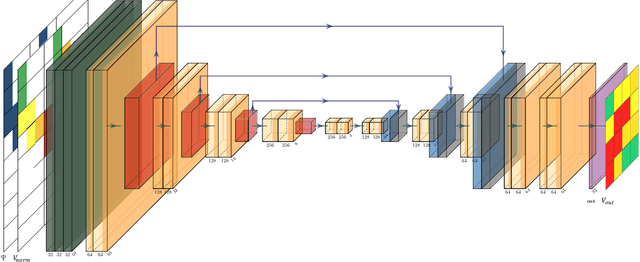
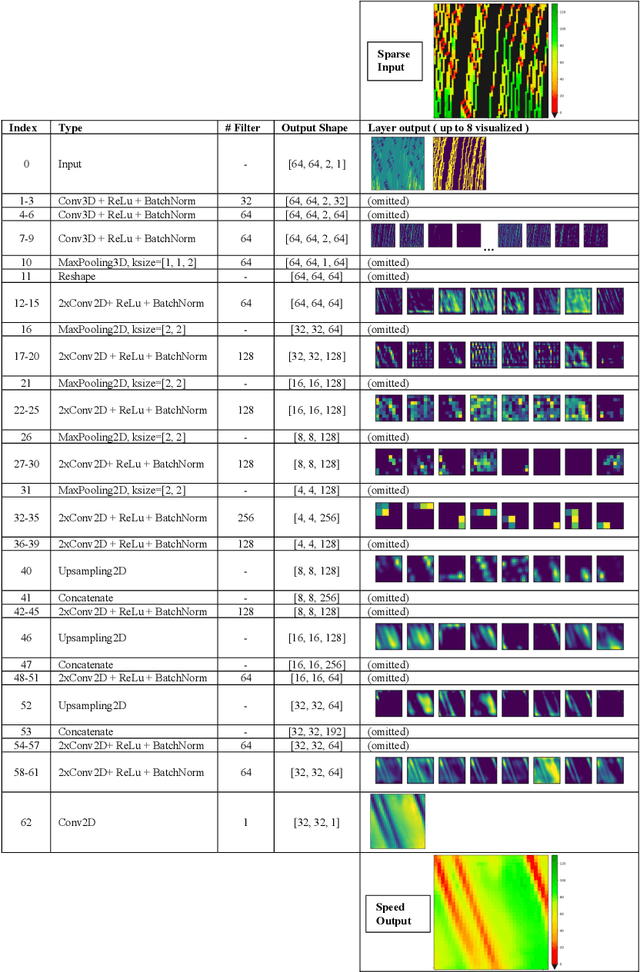

This paper presents a dedicated Deep Neural Network (DNN) architecture that reconstructs space-time traffic speeds on freeways given sparse data. The DNN is constructed in such a way, that it learns heterogeneous congestion patterns using a large dataset of sparse speed data, in particular from probe vehicles. Input to the DNN are two equally sized input matrices: one containing raw measurement data, and the other indicates the cells occupied with data. The DNN, comprising multiple stacked convolutional layers with an encoding-decoding structure and feed-forward paths, transforms the input into a full matrix of traffic speeds. The proposed DNN architecture is evaluated with respect to its ability to accurately reconstruct heterogeneous congestion patterns under varying input data sparsity. Therefore, a large set of empirical Floating-Car Data (FCD) collected on German freeway A9 during two months is utilized. In total, 43 congestion distinct scenarios are observed which comprise moving and stationary congestion patterns. A data augmentation technique is applied to generate input-output samples of the data, which makes the DNN shift-invariant as well as capable of managing varying data sparsities. The DNN is trained and subsequently applied to sparse data of an unseen congestion scenario. The results show that the DNN is able to apply learned patterns, and reconstructs moving as well as stationary congested traffic with high accuracy; even given highly sparse input data. Reconstructed speeds are compared qualitatively and quantitatively with the results of several state-of-the-art methods such as the Adaptive Smoothing Method (ASM), the Phase-Based Smoothing Method (PSM) and a standard Convolutional Neural Network (CNN) architecture. As a result, the DNN outperforms the other methods significantly.