 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 23, 2021

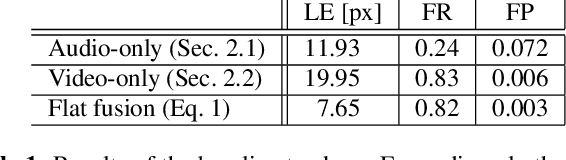
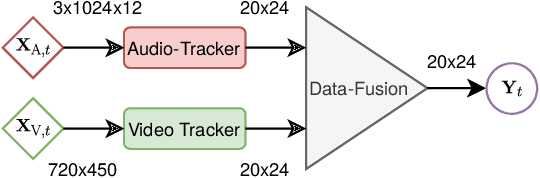
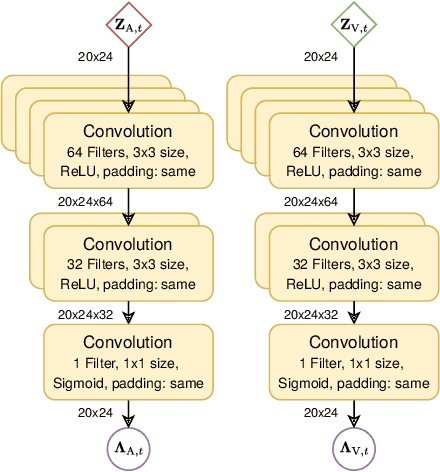
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
CoCoNets: Continuous Contrastive 3D Scene Representations
Apr 08, 2021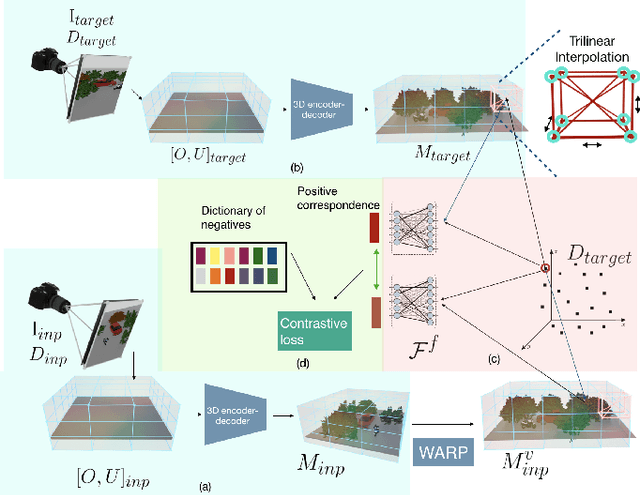
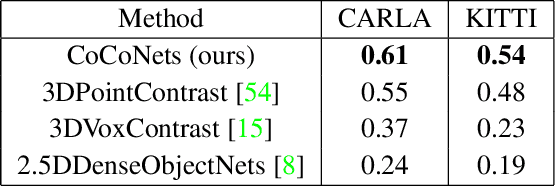
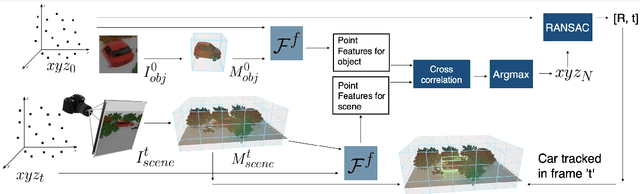

This paper explores self-supervised learning of amodal 3D feature representations from RGB and RGB-D posed images and videos, agnostic to object and scene semantic content, and evaluates the resulting scene representations in the downstream tasks of visual correspondence, object tracking, and object detection. The model infers a latent3D representation of the scene in the form of 3D feature points, where each continuous world 3D point is mapped to its corresponding feature vector. The model is trained for contrastive view prediction by rendering 3D feature clouds in queried viewpoints and matching against the 3D feature point cloud predicted from the query view. Notably, the representation can be queried for any 3D location, even if it is not visible from the input view. Our model brings together three powerful ideas of recent exciting research work: 3D feature grids as a neural bottleneck for view prediction, implicit functions for handling resolution limitations of 3D grids, and contrastive learning for unsupervised training of feature representations. We show the resulting 3D visual feature representations effectively scale across objects and scenes, imagine information occluded or missing from the input viewpoints, track objects over time, align semantically related objects in 3D, and improve 3D object detection. We outperform many existing state-of-the-art methods for 3D feature learning and view prediction, which are either limited by 3D grid spatial resolution, do not attempt to build amodal 3D representations, or do not handle combinatorial scene variability due to their non-convolutional bottlenecks.
Artificial Intelligence as an Anti-Corruption Tool (AI-ACT) -- Potentials and Pitfalls for Top-down and Bottom-up Approaches
Feb 23, 2021Corruption continues to be one of the biggest societal challenges of our time. New hope is placed in Artificial Intelligence (AI) to serve as an unbiased anti-corruption agent. Ever more available (open) government data paired with unprecedented performance of such algorithms render AI the next frontier in anti-corruption. Summarizing existing efforts to use AI-based anti-corruption tools (AI-ACT), we introduce a conceptual framework to advance research and policy. It outlines why AI presents a unique tool for top-down and bottom-up anti-corruption approaches. For both approaches, we outline in detail how AI-ACT present different potentials and pitfalls for (a) input data, (b) algorithmic design, and (c) institutional implementation. Finally, we venture a look into the future and flesh out key questions that need to be addressed to develop AI-ACT while considering citizens' views, hence putting "society in the loop".
Anatomy-guided Multimodal Registration by Learning Segmentation without Ground Truth: Application to Intraprocedural CBCT/MR Liver Segmentation and Registration
Apr 14, 2021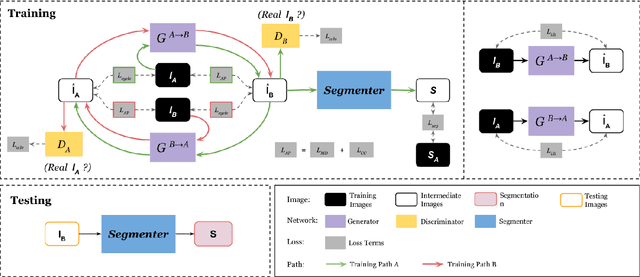
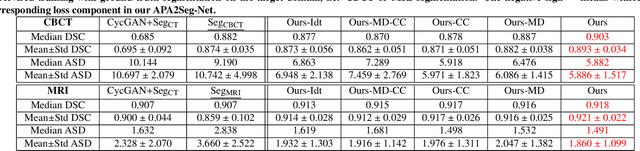
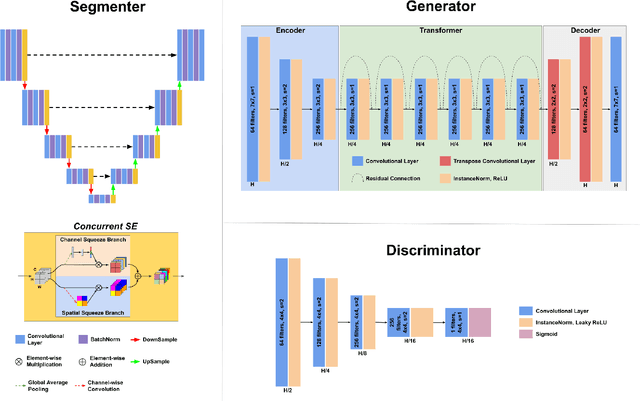
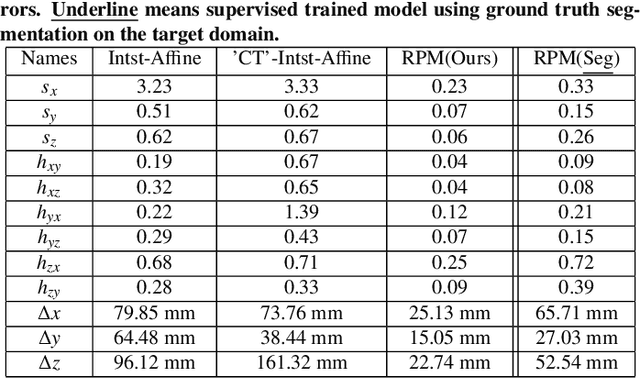
Multimodal image registration has many applications in diagnostic medical imaging and image-guided interventions, such as Transcatheter Arterial Chemoembolization (TACE) of liver cancer guided by intraprocedural CBCT and pre-operative MR. The ability to register peri-procedurally acquired diagnostic images into the intraprocedural environment can potentially improve the intra-procedural tumor targeting, which will significantly improve therapeutic outcomes. However, the intra-procedural CBCT often suffers from suboptimal image quality due to lack of signal calibration for Hounsfield unit, limited FOV, and motion/metal artifacts. These non-ideal conditions make standard intensity-based multimodal registration methods infeasible to generate correct transformation across modalities. While registration based on anatomic structures, such as segmentation or landmarks, provides an efficient alternative, such anatomic structure information is not always available. One can train a deep learning-based anatomy extractor, but it requires large-scale manual annotations on specific modalities, which are often extremely time-consuming to obtain and require expert radiological readers. To tackle these issues, we leverage annotated datasets already existing in a source modality and propose an anatomy-preserving domain adaptation to segmentation network (APA2Seg-Net) for learning segmentation without target modality ground truth. The segmenters are then integrated into our anatomy-guided multimodal registration based on the robust point matching machine. Our experimental results on in-house TACE patient data demonstrated that our APA2Seg-Net can generate robust CBCT and MR liver segmentation, and the anatomy-guided registration framework with these segmenters can provide high-quality multimodal registrations. Our code is available at https://github.com/bbbbbbzhou/APA2Seg-Net.
Combining Gaussian processes and polynomial chaos expansions for stochastic nonlinear model predictive control
Mar 09, 2021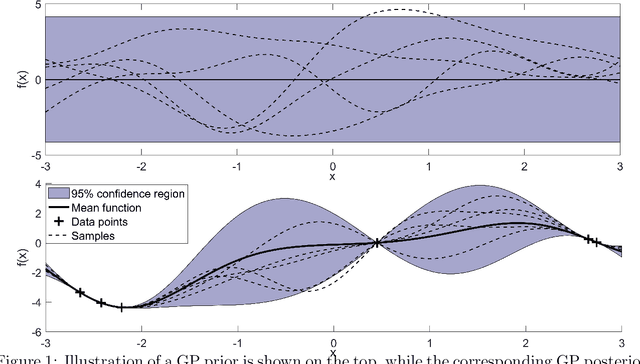
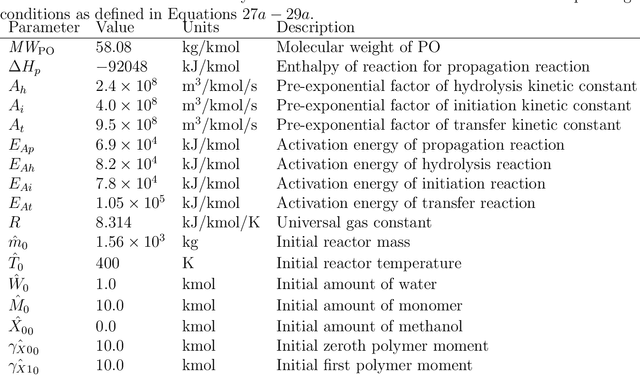
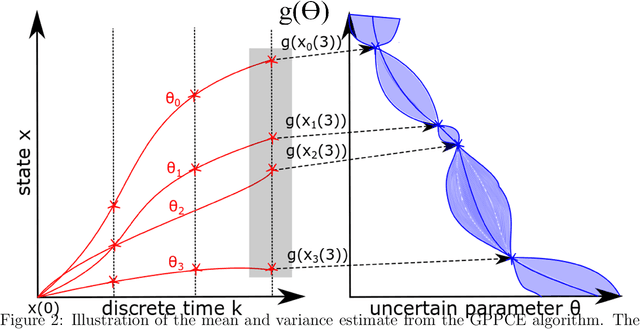
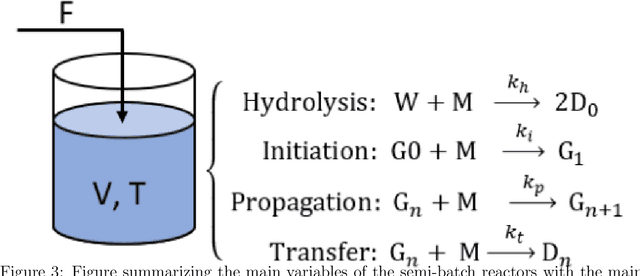
Model predictive control is an advanced control approach for multivariable systems with constraints, which is reliant on an accurate dynamic model. Most real dynamic models are however affected by uncertainties, which can lead to closed-loop performance deterioration and constraint violations. In this paper we introduce a new algorithm to explicitly consider time-invariant stochastic uncertainties in optimal control problems. The difficulty of propagating stochastic variables through nonlinear functions is dealt with by combining Gaussian processes with polynomial chaos expansions. The main novelty in this paper is to use this combination in an efficient fashion to obtain mean and variance estimates of nonlinear transformations. Using this algorithm, it is shown how to formulate both chance-constraints and a probabilistic objective for the optimal control problem. On a batch reactor case study we firstly verify the ability of the new approach to accurately approximate the probability distributions required. Secondly, a tractable stochastic nonlinear model predictive control approach is formulated with an economic objective to demonstrate the closed-loop performance of the method via Monte Carlo simulations.
IIoT-Enabled Health Monitoring for Integrated Heat Pump System Using Mixture Slow Feature Analysis
Apr 20, 2021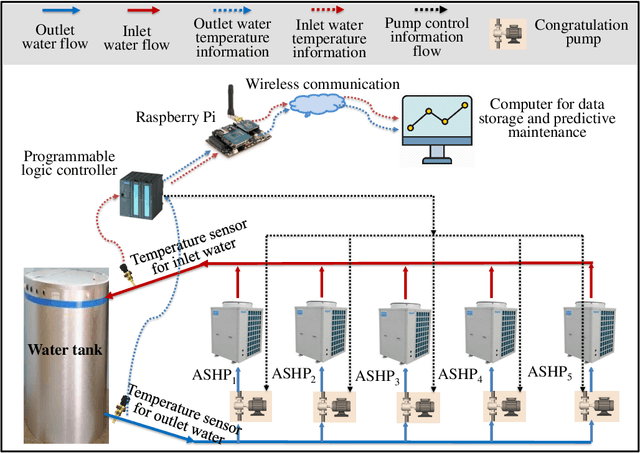
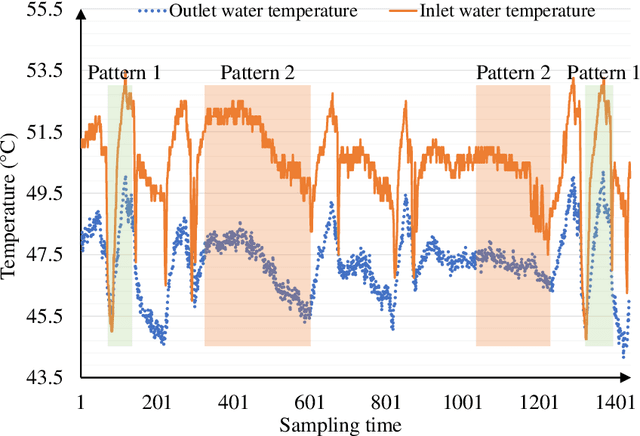
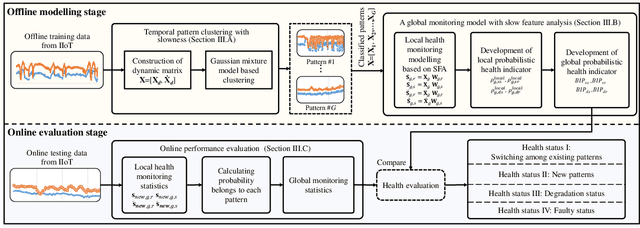
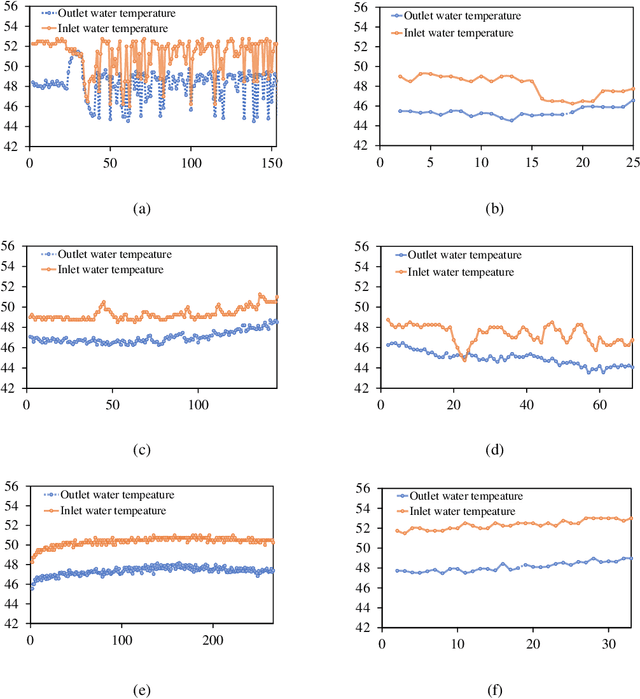
The sustaining evolution of sensing and advancement in communications technologies have revolutionized prognostics and health management for various electrical equipment towards data-driven ways. This revolution delivers a promising solution for the health monitoring problem of heat pump (HP) system, a vital device widely deployed in modern buildings for heating use, to timely evaluate its operation status to avoid unexpected downtime. Many HPs were practically manufactured and installed many years ago, resulting in fewer sensors available due to technology limitations and cost control at that time. It raises a dilemma to safeguard HPs at an affordable cost. We propose a hybrid scheme by integrating industrial Internet-of-Things (IIoT) and intelligent health monitoring algorithms to handle this challenge. To start with, an IIoT network is constructed to sense and store measurements. Specifically, temperature sensors are properly chosen and deployed at the inlet and outlet of the water tank to measure water temperature. Second, with temperature information, we propose an unsupervised learning algorithm named mixture slow feature analysis (MSFA) to timely evaluate the health status of the integrated HP. Characterized by frequent operation switches of different HPs due to the variable demand for hot water, various heating patterns with different heating speeds are observed. Slowness, a kind of dynamics to measure the varying speed of steady distribution, is properly considered in MSFA for both heating pattern division and health evaluation. Finally, the efficacy of the proposed method is verified through a real integrated HP with five connected HPs installed ten years ago. The experimental results show that MSFA is capable of accurately identifying health status of the system, especially failure at a preliminary stage compared to its competing algorithms.
Anticipatory Navigation in Crowds by Probabilistic Prediction of Pedestrian Future Movements
Nov 12, 2020
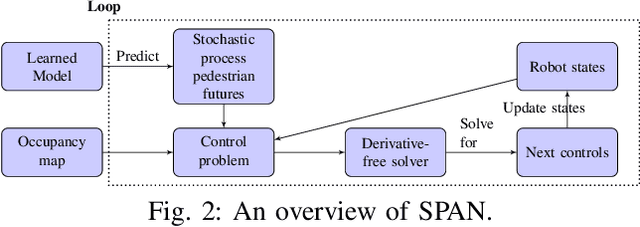

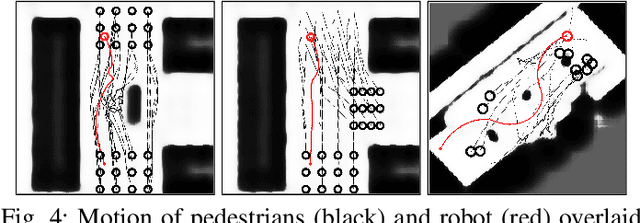
Critical for the coexistence of humans and robots in dynamic environments is the capability for agents to understand each other's actions, and anticipate their movements. This paper presents Stochastic Process Anticipatory Navigation (SPAN), a framework that enables nonholonomic robots to navigate in environments with crowds, while anticipating and accounting for the motion patterns of pedestrians. To this end, we learn a predictive model to predict continuous-time stochastic processes to model future movement of pedestrians. Anticipated pedestrian positions are used to conduct chance constrained collision-checking, and are incorporated into a time-to-collision control problem. An occupancy map is also integrated to allow for probabilistic collision-checking with static obstacles. We demonstrate the capability of SPAN in crowded simulation environments, as well as with a real-world pedestrian dataset.
CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
Mar 18, 2021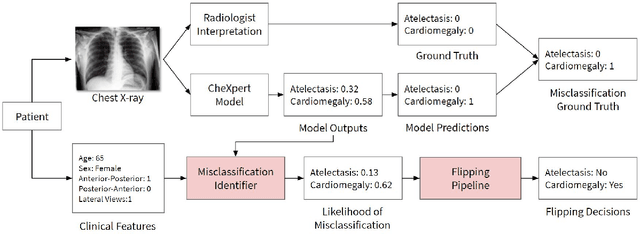
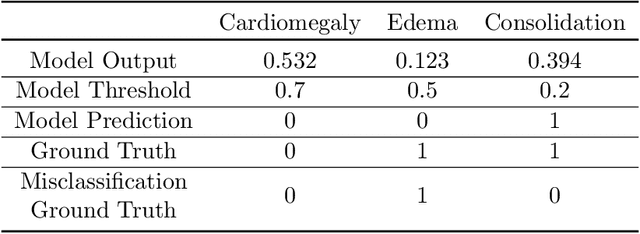
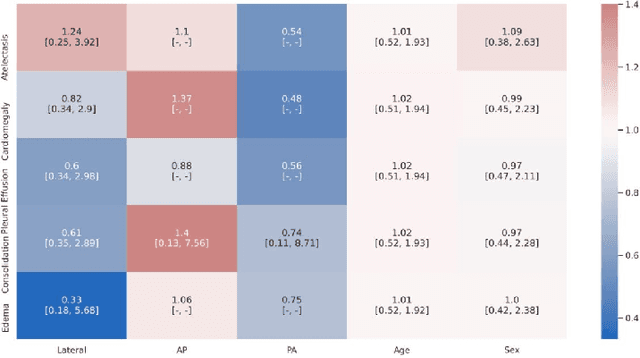
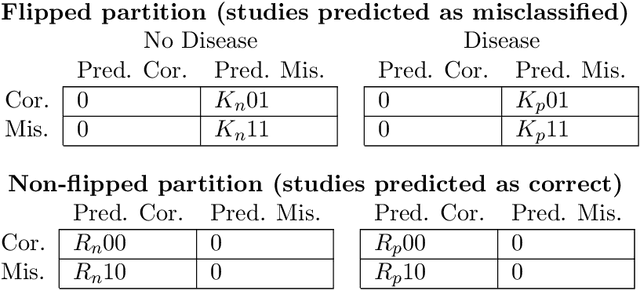
A major obstacle to the integration of deep learning models for chest x-ray interpretation into clinical settings is the lack of understanding of their failure modes. In this work, we first investigate whether there are patient subgroups that chest x-ray models are likely to misclassify. We find that patient age and the radiographic finding of lung lesion or pneumothorax are statistically relevant features for predicting misclassification for some chest x-ray models. Second, we develop misclassification predictors on chest x-ray models using their outputs and clinical features. We find that our best performing misclassification identifier achieves an AUROC close to 0.9 for most diseases. Third, employing our misclassification identifiers, we develop a corrective algorithm to selectively flip model predictions that have high likelihood of misclassification at inference time. We observe F1 improvement on the prediction of Consolidation (0.008 [95\% CI 0.005, 0.010]) and Edema (0.003, [95\% CI 0.001, 0.006]). By carrying out our investigation on ten distinct and high-performing chest x-ray models, we are able to derive insights across model architectures and offer a generalizable framework applicable to other medical imaging tasks.
Efficient Multi-Stage Video Denoising with Recurrent Spatio-Temporal Fusion
Mar 09, 2021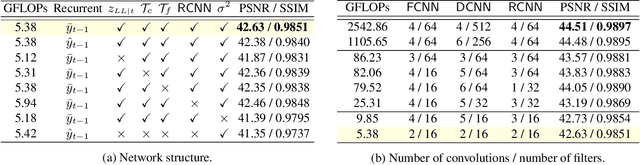
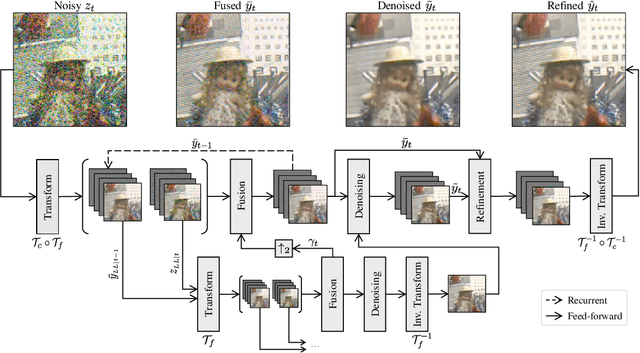
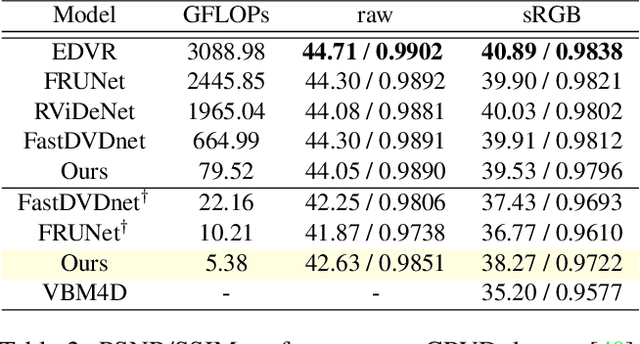
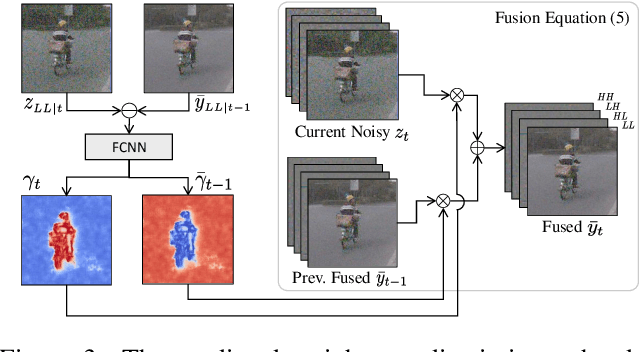
In recent years, methods based on deep learning have achieved unparalleled performance at the cost of large computational complexity. In this work, we propose an Efficient Multi-stage Video Denoising algorithm, called EMVD, to drastically reduce the complexity while maintaining or even improving the performance. First, a fusion stage reduces the noise through a recursive combination of all past frames in the video. Then, a denoising stage removes the noise in the fused frame. Finally, a refinement stage restores the missing high frequency in the denoised frame. All stages operate on a transform-domain representation obtained by learnable and invertible linear operators which simultaneously increase accuracy and decrease complexity of the model. A single loss on the final output is sufficient for successful convergence, hence making EMVD easy to train. Experiments on real raw data demonstrate that EMVD outperforms the state of the art when complexity is constrained, and even remains competitive against methods whose complexities are several orders of magnitude higher. The low complexity and memory requirements of EMVD enable real-time video denoising on low-powered commercial SoC.
WiFiMod: Transformer-based Indoor Human Mobility Modeling using Passive Sensing
Apr 20, 2021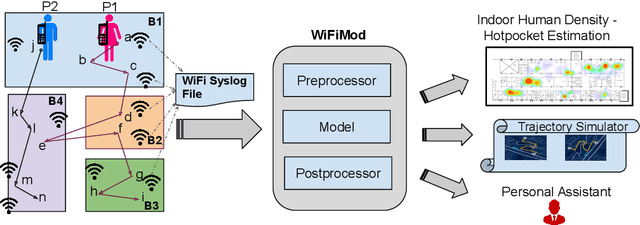

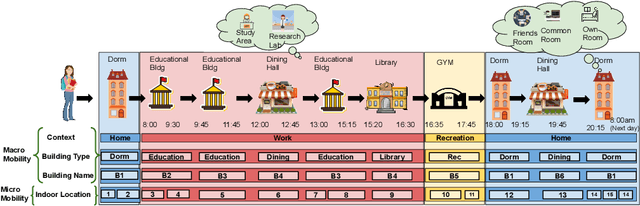
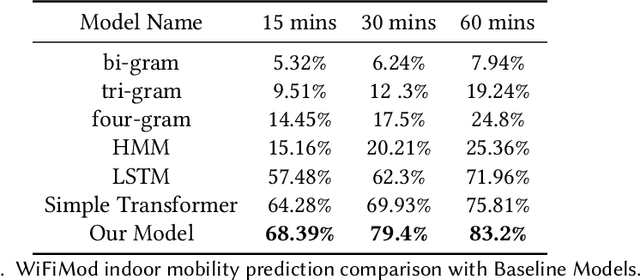
Modeling human mobility has a wide range of applications from urban planning to simulations of disease spread. It is well known that humans spend 80% of their time indoors but modeling indoor human mobility is challenging due to three main reasons: (i) the absence of easily acquirable, reliable, low-cost indoor mobility datasets, (ii) high prediction space in modeling the frequent indoor mobility, and (iii) multi-scalar periodicity and correlations in mobility. To deal with all these challenges, we propose WiFiMod, a Transformer-based, data-driven approach that models indoor human mobility at multiple spatial scales using WiFi system logs. WiFiMod takes as input enterprise WiFi system logs to extract human mobility trajectories from smartphone digital traces. Next, for each extracted trajectory, we identify the mobility features at multiple spatial scales, macro, and micro, to design a multi-modal embedding Transformer that predicts user mobility for several hours to an entire day across multiple spatial granularities. Multi-modal embedding captures the mobility periodicity and correlations across various scales while Transformers capture long-term mobility dependencies boosting model prediction performance. This approach significantly reduces the prediction space by first predicting macro mobility, then modeling indoor scale mobility, micro-mobility, conditioned on the estimated macro mobility distribution, thereby using the topological constraint of the macro-scale. Experimental results show that WiFiMod achieves a prediction accuracy of at least 10% points higher than the current state-of-art models. Additionally, we present 3 real-world applications of WiFiMod - (i) predict high-density hot pockets for policy-making decisions for COVID19 or ILI, (ii) generate a realistic simulation of indoor mobility, (iii) design personal assistants.