 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Single-Shot Motion Completion with Transformer
Mar 01, 2021

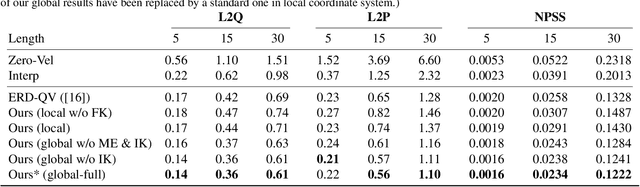
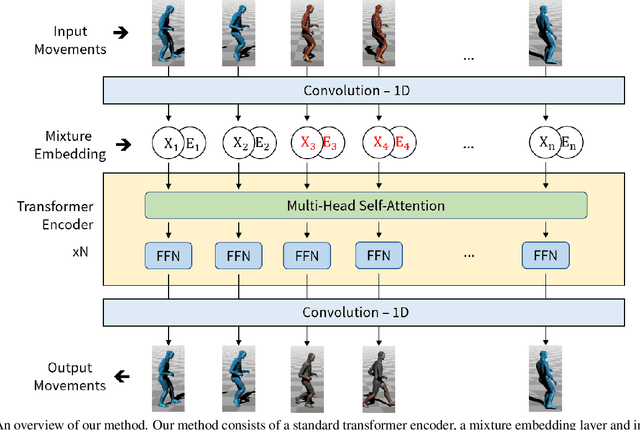
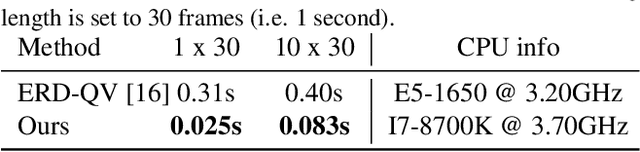
Motion completion is a challenging and long-discussed problem, which is of great significance in film and game applications. For different motion completion scenarios (in-betweening, in-filling, and blending), most previous methods deal with the completion problems with case-by-case designs. In this work, we propose a simple but effective method to solve multiple motion completion problems under a unified framework and achieves a new state of the art accuracy under multiple evaluation settings. Inspired by the recent great success of attention-based models, we consider the completion as a sequence to sequence prediction problem. Our method consists of two modules - a standard transformer encoder with self-attention that learns long-range dependencies of input motions, and a trainable mixture embedding module that models temporal information and discriminates key-frames. Our method can run in a non-autoregressive manner and predict multiple missing frames within a single forward propagation in real time. We finally show the effectiveness of our method in music-dance applications.
Universal Neural Vocoding with Parallel WaveNet
Feb 01, 2021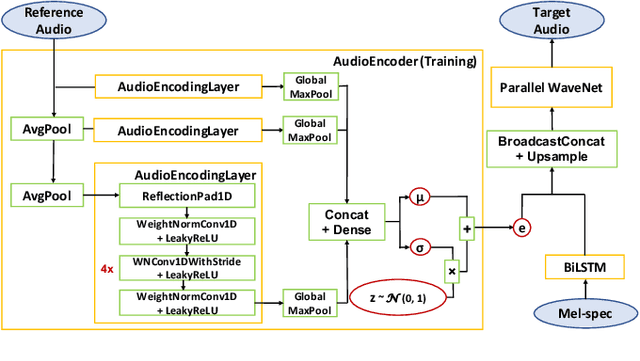

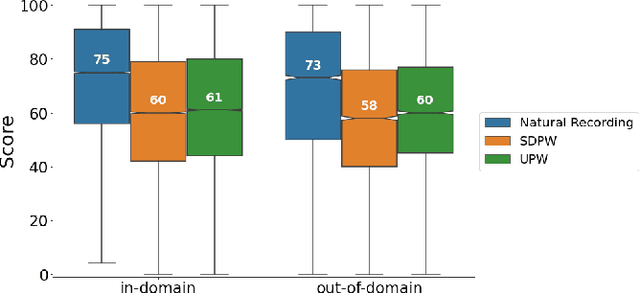
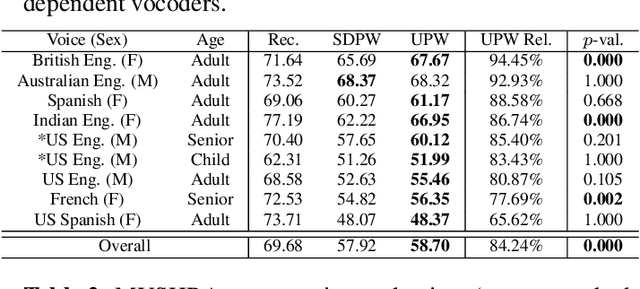
We present a universal neural vocoder based on Parallel WaveNet, with an additional conditioning network called Audio Encoder. Our universal vocoder offers real-time high-quality speech synthesis on a wide range of use cases. We tested it on 43 internal speakers of diverse age and gender, speaking 20 languages in 17 unique styles, of which 7 voices and 5 styles were not exposed during training. We show that the proposed universal vocoder significantly outperforms speaker-dependent vocoders overall. We also show that the proposed vocoder outperforms several existing neural vocoder architectures in terms of naturalness and universality. These findings are consistent when we further test on more than 300 open-source voices.
Optimization of Undersampling Parameters for 3D Intracranial Compressed Sensing MR Angiography at 7 Tesla
Apr 09, 2021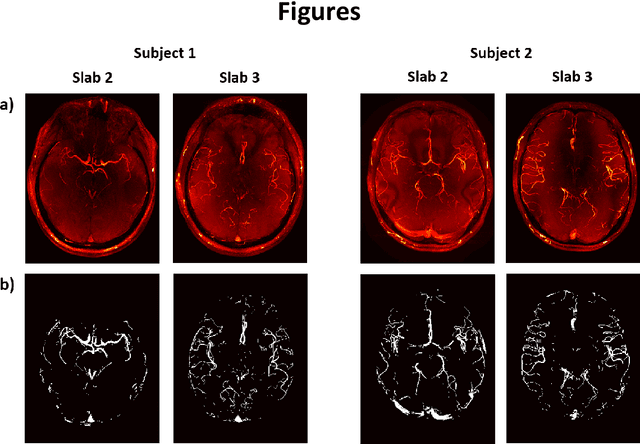
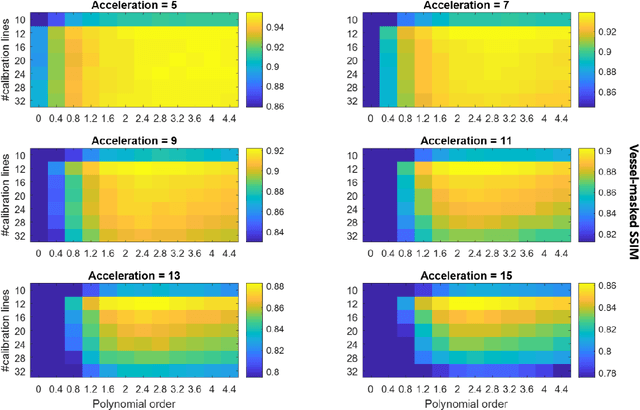
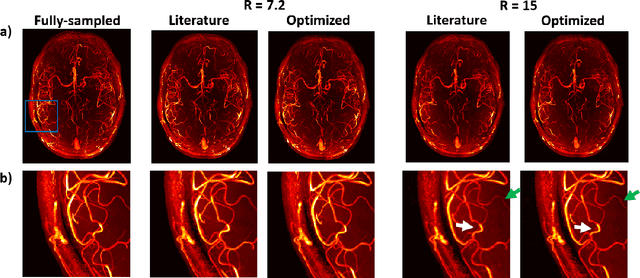
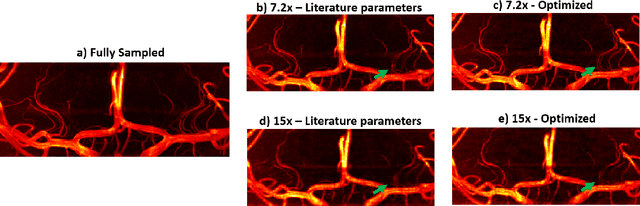
Purpose: 3D Time-of-flight (TOF) MR Angiography (MRA) can accurately visualize the intracranial vasculature, but is limited by long acquisition times. Compressed sensing (CS) reconstruction can be used to substantially accelerate acquisitions. The quality of those reconstructions depends on the undersampling patterns used in the acquisitions. In this work, optimized sets of undersampling parameters using various acceleration factors for Cartesian 3D TOF-MRA are established. Methods: Fully-sampled datasets acquired at 7T were retrospectively undersampled using variable-density Poisson-disk sampling with various autocalibration region sizes, polynomial orders, and acceleration factors. The accuracy of reconstructions from the different undersampled datasets was assessed using the vessel-masked structural similarity index. Results were compared for four imaging volumes, acquired from two different subjects. Optimized undersampling parameters were validated using additional prospectively undersampled datasets. Results: For all acceleration factors, using a fully-sampled calibration area of 12x12 k-space lines and a polynomial order of around 2-2.4 resulted in the highest image quality. The importance of sampling parameter optimization was found to increase for higher acceleration factors. The results were consistent across resolutions and regions of interest with vessels of varying sizes and tortuosity. In prospectively undersampled acquisitions, using optimized undersampling parameters resulted in a 7.2% increase in the number of visible small vessels at R = 7.2. Conclusion: The image quality of CS TOF-MRA can be improved by appropriate choice of undersampling parameters. The optimized sets of parameters are independent of the acceleration factor.
Learn-n-Route: Learning implicit preferences for vehicle routing
Jan 11, 2021
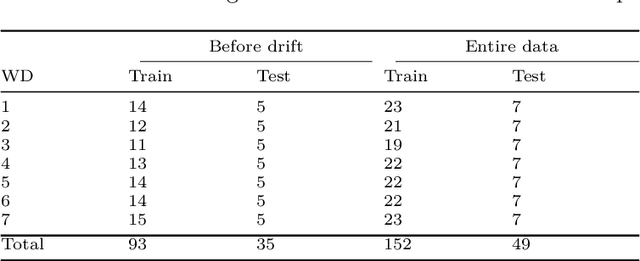
We investigate a learning decision support system for vehicle routing, where the routing engine learns implicit preferences that human planners have when manually creating route plans (or routings). The goal is to use these learned subjective preferences on top of the distance-based objective criterion in vehicle routing systems. This is an alternative to the practice of distinctively formulating a custom VRP for every company with its own routing requirements. Instead, we assume the presence of past vehicle routing solutions over similar sets of customers, and learn to make similar choices. The learning approach is based on the concept of learning a Markov model, which corresponds to a probabilistic transition matrix, rather than a deterministic distance matrix. This nevertheless allows us to use existing arc routing VRP software in creating the actual routings, and to optimize over both distances and preferences at the same time. For the learning, we explore different schemes to construct the probabilistic transition matrix that can co-evolve with changing preferences over time. Our results on a use-case with a small transportation company show that our method is able to generate results that are close to the manually created solutions, without needing to characterize all constraints and sub-objectives explicitly. Even in the case of changes in the customer sets, our method is able to find solutions that are closer to the actual routings than when using only distances, and hence, solutions that require fewer manual changes when transformed into practical routings.
Non-normal Recurrent Neural Network (nnRNN): learning long time dependencies while improving expressivity with transient dynamics
May 28, 2019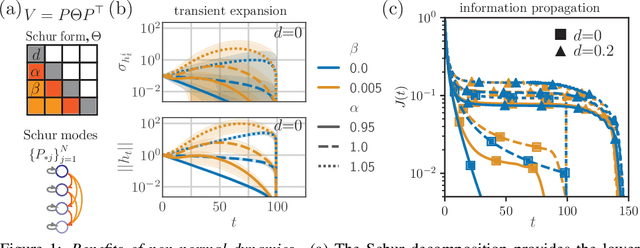

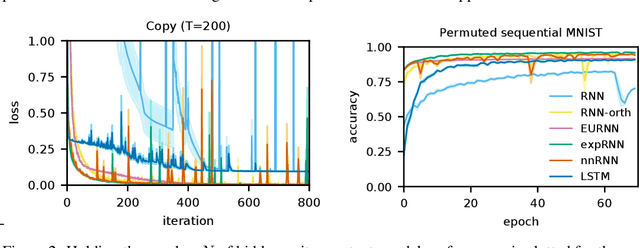
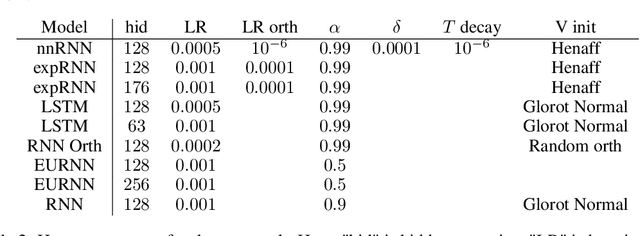
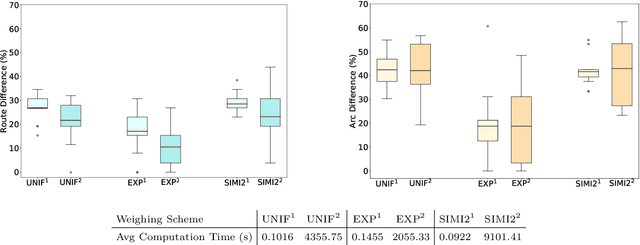
A recent strategy to circumvent the exploding and vanishing gradient problem in RNNs, and to allow the stable propagation of signals over long time scales, is to constrain recurrent connectivity matrices to be orthogonal or unitary. This ensures eigenvalues with unit norm and thus stable dynamics and training. However this comes at the cost of reduced expressivity due to the limited variety of orthogonal transformations. We propose a novel connectivity structure based on the Schur decomposition and a splitting of the Schur form into normal and non-normal parts. This allows to parametrize matrices with unit-norm eigenspectra without orthogonality constraints on eigenbases. The resulting architecture ensures access to a larger space of spectrally constrained matrices, of which orthogonal matrices are a subset. This crucial difference retains the stability advantages and training speed of orthogonal RNNs while enhancing expressivity, especially on tasks that require computations over ongoing input sequences.
Modeling Time Series Similarity with Siamese Recurrent Networks
Mar 15, 2016
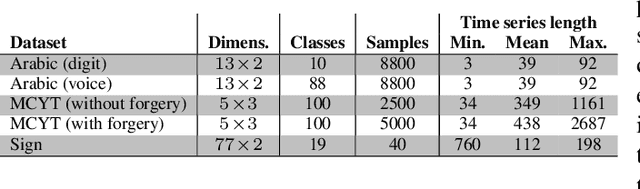
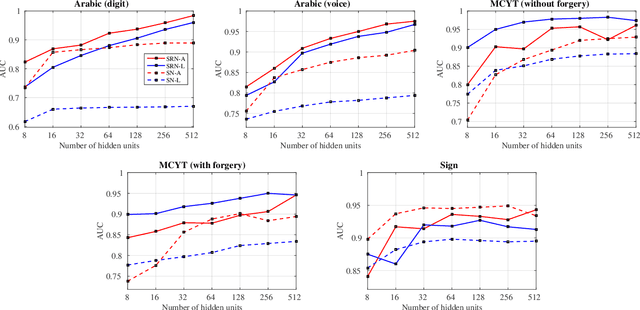
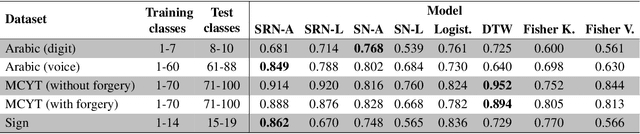
Traditional techniques for measuring similarities between time series are based on handcrafted similarity measures, whereas more recent learning-based approaches cannot exploit external supervision. We combine ideas from time-series modeling and metric learning, and study siamese recurrent networks (SRNs) that minimize a classification loss to learn a good similarity measure between time series. Specifically, our approach learns a vectorial representation for each time series in such a way that similar time series are modeled by similar representations, and dissimilar time series by dissimilar representations. Because it is a similarity prediction models, SRNs are particularly well-suited to challenging scenarios such as signature recognition, in which each person is a separate class and very few examples per class are available. We demonstrate the potential merits of SRNs in within-domain and out-of-domain classification experiments and in one-shot learning experiments on tasks such as signature, voice, and sign language recognition.
Learning optimal multigrid smoothers via neural networks
Feb 24, 2021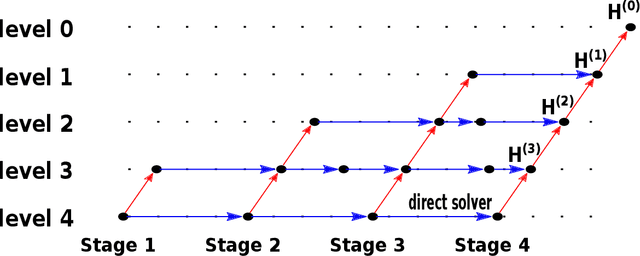
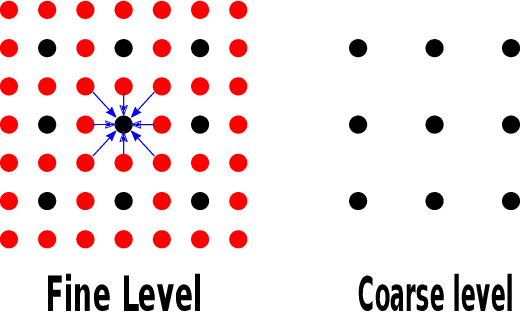
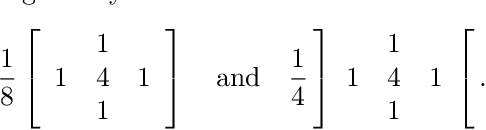
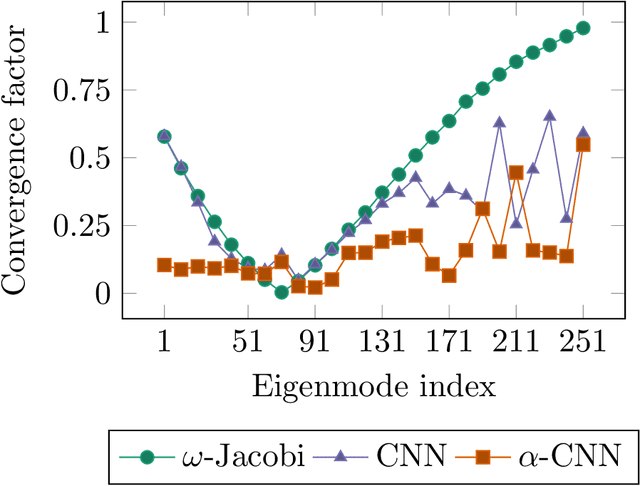
Multigrid methods are one of the most efficient techniques for solving linear systems arising from Partial Differential Equations (PDEs) and graph Laplacians from machine learning applications. One of the key components of multigrid is smoothing, which aims at reducing high-frequency errors on each grid level. However, finding optimal smoothing algorithms is problem-dependent and can impose challenges for many problems. In this paper, we propose an efficient adaptive framework for learning optimized smoothers from operator stencils in the form of convolutional neural networks (CNNs). The CNNs are trained on small-scale problems from a given type of PDEs based on a supervised loss function derived from multigrid convergence theories, and can be applied to large-scale problems of the same class of PDEs. Numerical results on anisotropic rotated Laplacian problems demonstrate improved convergence rates and solution time compared with classical hand-crafted relaxation methods.
Protecting Intellectual Property of Generative Adversarial Networks from Ambiguity Attack
Mar 01, 2021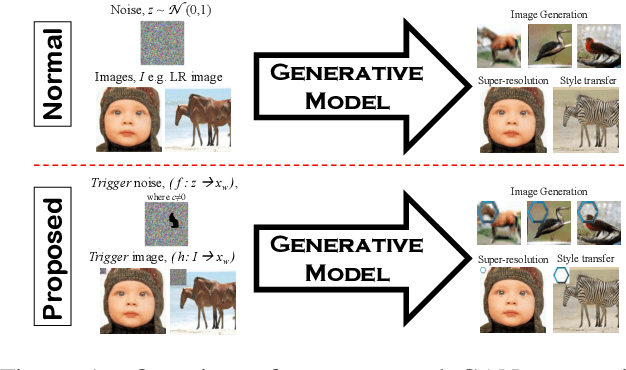



Ever since Machine Learning as a Service (MLaaS) emerges as a viable business that utilizes deep learning models to generate lucrative revenue, Intellectual Property Right (IPR) has become a major concern because these deep learning models can easily be replicated, shared, and re-distributed by any unauthorized third parties. To the best of our knowledge, one of the prominent deep learning models - Generative Adversarial Networks (GANs) which has been widely used to create photorealistic image are totally unprotected despite the existence of pioneering IPR protection methodology for Convolutional Neural Networks (CNNs). This paper therefore presents a complete protection framework in both black-box and white-box settings to enforce IPR protection on GANs. Empirically, we show that the proposed method does not compromise the original GANs performance (i.e. image generation, image super-resolution, style transfer), and at the same time, it is able to withstand both removal and ambiguity attacks against embedded watermarks.
Quantum Inspired Adaptive Boosting
Feb 01, 2021
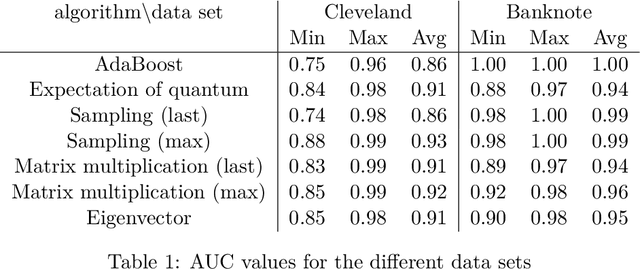
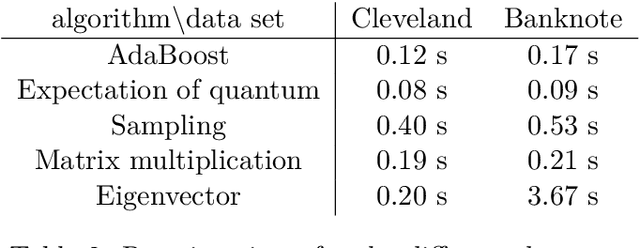
Building on the quantum ensemble based classifier algorithm of Schuld and Petruccione [arXiv:1704.02146v1], we devise equivalent classical algorithms which show that this quantum ensemble method does not have advantage over classical algorithms. Essentially, we simplify their algorithm until it is intuitive to come up with an equivalent classical version. One of the classical algorithms is extremely simple and runs in constant time for each input to be classified. We further develop the idea and, as the main contribution of the paper, we propose methods inspired by combining the quantum ensemble method with adaptive boosting. The algorithms were tested and found to be comparable to the AdaBoost algorithm on publicly available data sets.
Lasso Guarantees for Time Series Estimation Under Subgaussian Tails and $ β$-Mixing
Feb 05, 2018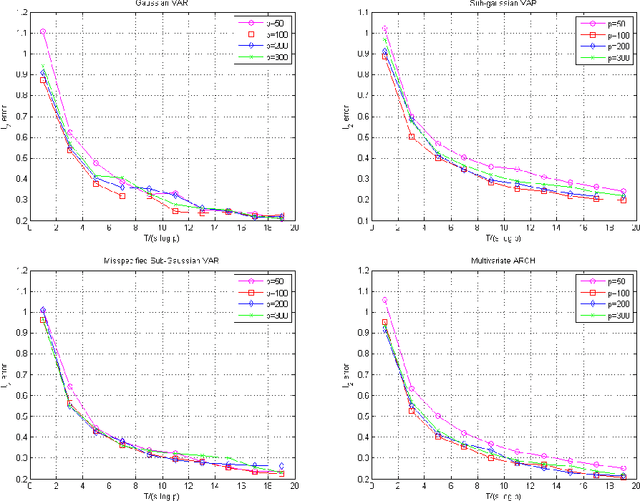
Many theoretical results on estimation of high dimensional time series require specifying an underlying data generating model (DGM). Instead, along the footsteps of~\cite{wong2017lasso}, this paper relies only on (strict) stationarity and $ \beta $-mixing condition to establish consistency of lasso when data comes from a $\beta$-mixing process with marginals having subgaussian tails. Because of the general assumptions, the data can come from DGMs different than standard time series models such as VAR or ARCH. When the true DGM is not VAR, the lasso estimates correspond to those of the best linear predictors using the past observations. We establish non-asymptotic inequalities for estimation and prediction errors of the lasso estimates. Together with~\cite{wong2017lasso}, we provide lasso guarantees that cover full spectrum of the parameters in specifications of $ \beta $-mixing subgaussian time series. Applications of these results potentially extend to non-Gaussian, non-Markovian and non-linear times series models as the examples we provide demonstrate. In order to prove our results, we derive a novel Hanson-Wright type concentration inequality for $\beta$-mixing subgaussian random vectors that may be of independent interest.