 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Recurrent Neural Network Controllers for Signal Temporal Logic Specifications Subject to Safety Constraints
Sep 24, 2020
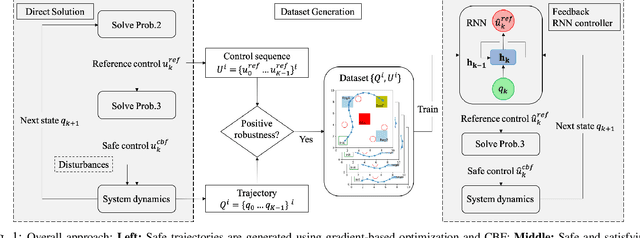
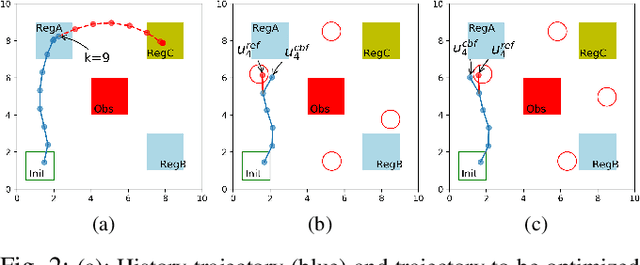
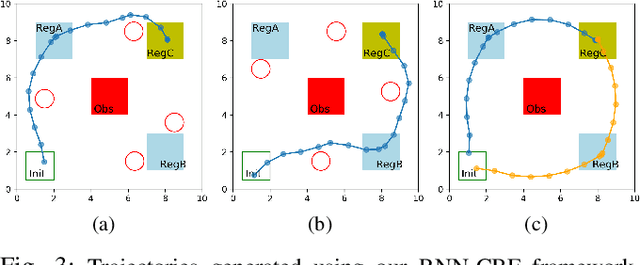
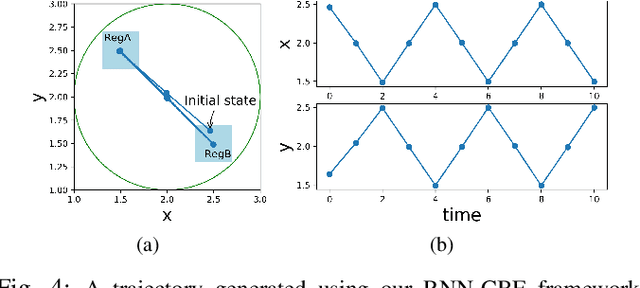
We propose a framework based on Recurrent Neural Networks (RNNs) to determine an optimal control strategy for a discrete-time system that is required to satisfy specifications given as Signal Temporal Logic (STL) formulae. RNNs can store information of a system over time, thus, enable us to determine satisfaction of the dynamic temporal requirements specified in STL formulae. Given a STL formula, a dataset of satisfying system executions and corresponding control policies, we can use RNNs to predict a control policy at each time based on the current and previous states of system. We use Control Barrier Functions (CBFs) to guarantee the safety of the predicted control policy. We validate our theoretical formulation and demonstrate its performance in an optimal control problem subject to partially unknown safety constraints through simulations.
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements
Apr 15, 2021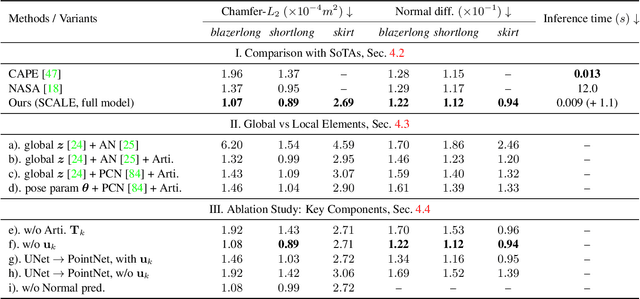
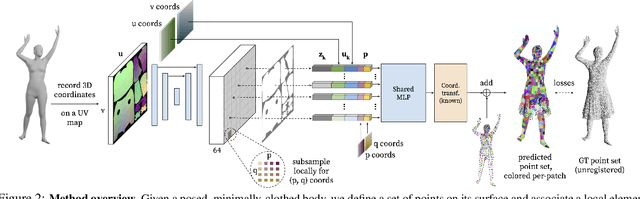
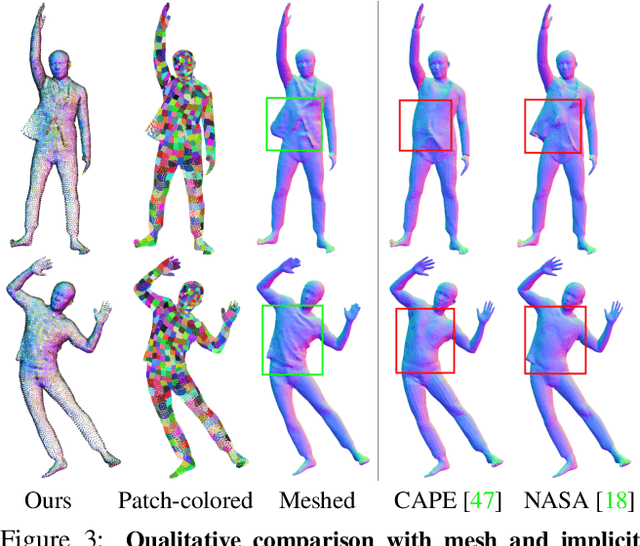

Learning to model and reconstruct humans in clothing is challenging due to articulation, non-rigid deformation, and varying clothing types and topologies. To enable learning, the choice of representation is the key. Recent work uses neural networks to parameterize local surface elements. This approach captures locally coherent geometry and non-planar details, can deal with varying topology, and does not require registered training data. However, naively using such methods to model 3D clothed humans fails to capture fine-grained local deformations and generalizes poorly. To address this, we present three key innovations: First, we deform surface elements based on a human body model such that large-scale deformations caused by articulation are explicitly separated from topological changes and local clothing deformations. Second, we address the limitations of existing neural surface elements by regressing local geometry from local features, significantly improving the expressiveness. Third, we learn a pose embedding on a 2D parameterization space that encodes posed body geometry, improving generalization to unseen poses by reducing non-local spurious correlations. We demonstrate the efficacy of our surface representation by learning models of complex clothing from point clouds. The clothing can change topology and deviate from the topology of the body. Once learned, we can animate previously unseen motions, producing high-quality point clouds, from which we generate realistic images with neural rendering. We assess the importance of each technical contribution and show that our approach outperforms the state-of-the-art methods in terms of reconstruction accuracy and inference time. The code is available for research purposes at https://qianlim.github.io/SCALE .
Spatial-Temporal Tensor Graph Convolutional Network for Traffic Prediction
Mar 10, 2021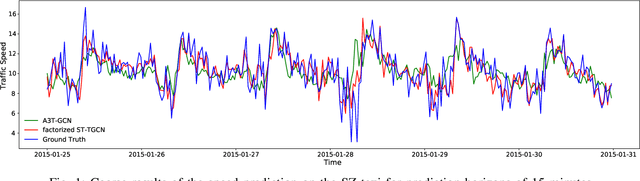
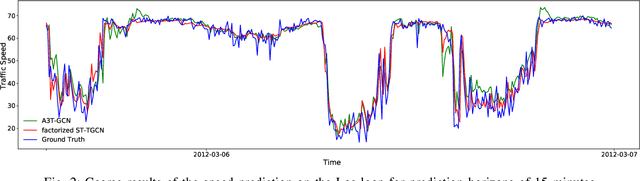
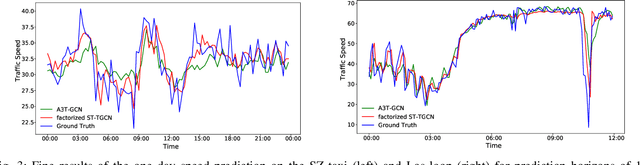
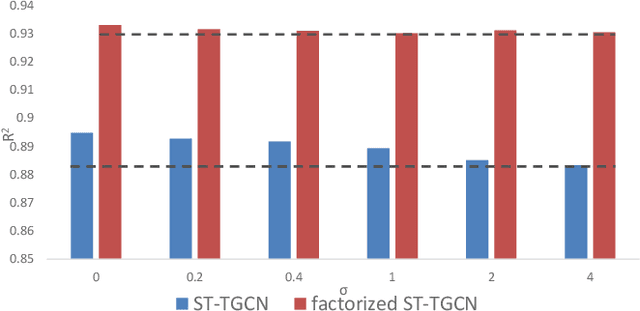
Accurate traffic prediction is crucial to the guidance and management of urban traffics. However, most of the existing traffic prediction models do not consider the computational burden and memory space when they capture spatial-temporal dependence among traffic data. In this work, we propose a factorized Spatial-Temporal Tensor Graph Convolutional Network to deal with traffic speed prediction. Traffic networks are modeled and unified into a graph that integrates spatial and temporal information simultaneously. We further extend graph convolution into tensor space and propose a tensor graph convolution network to extract more discriminating features from spatial-temporal graph data. To reduce the computational burden, we take Tucker tensor decomposition and derive factorized a tensor convolution, which performs separate filtering in small-scale space, time, and feature modes. Besides, we can benefit from noise suppression of traffic data when discarding those trivial components in the process of tensor decomposition. Extensive experiments on two real-world traffic speed datasets demonstrate our method is more effective than those traditional traffic prediction methods, and meantime achieves state-of-the-art performance.
Deep-Learning Driven Noise Reduction for Reduced Flux Computed Tomography
Jan 18, 2021
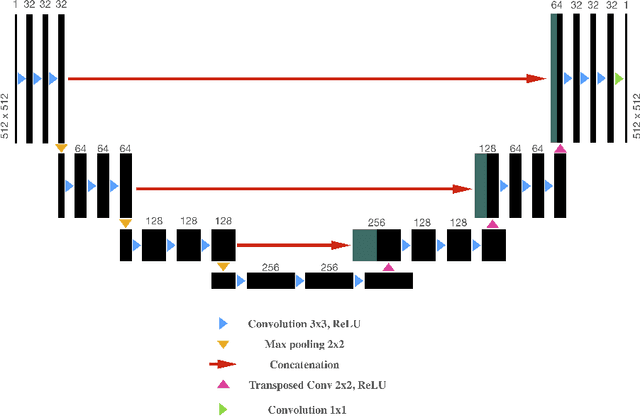
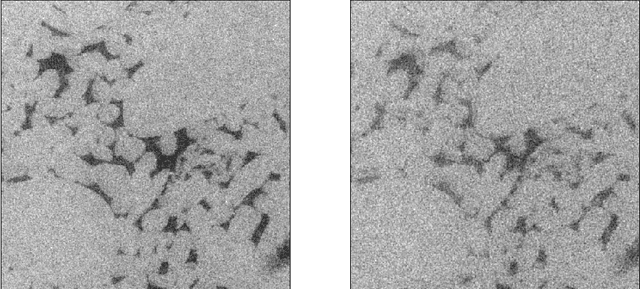
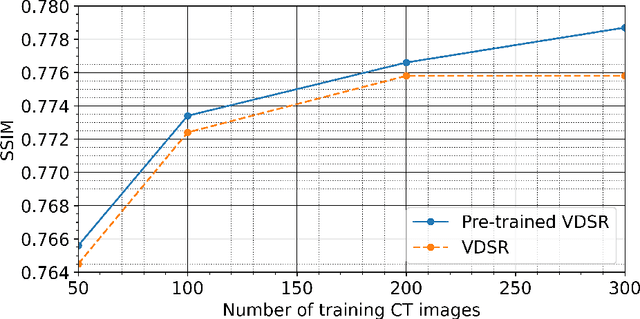
Deep neural networks have received considerable attention in clinical imaging, particularly with respect to the reduction of radiation risk. Lowering the radiation dose by reducing the photon flux inevitably results in the degradation of the scanned image quality. Thus, researchers have sought to exploit deep convolutional neural networks (DCNNs) to map low-quality, low-dose images to higher-dose, higher-quality images thereby minimizing the associated radiation hazard. Conversely, computed tomography (CT) measurements of geomaterials are not limited by the radiation dose. In contrast to the human body, however, geomaterials may be comprised of high-density constituents causing increased attenuation of the X-Rays. Consequently, higher dosage images are required to obtain an acceptable scan quality. The problem of prolonged acquisition times is particularly severe for micro-CT based scanning technologies. Depending on the sample size and exposure time settings, a single scan may require several hours to complete. This is of particular concern if phenomena with an exponential temperature dependency are to be elucidated. A process may happen too fast to be adequately captured by CT scanning. To address the aforementioned issues, we apply DCNNs to improve the quality of rock CT images and reduce exposure times by more than 60\%, simultaneously. We highlight current results based on micro-CT derived datasets and apply transfer learning to improve DCNN results without increasing training time. The approach is applicable to any computed tomography technology. Furthermore, we contrast the performance of the DCNN trained by minimizing different loss functions such as mean squared error and structural similarity index.
Just a Momentum: Analytical Study of Momentum-Based Acceleration Methods in Paradigmatic High-Dimensional Non-Convex Problem
Feb 24, 2021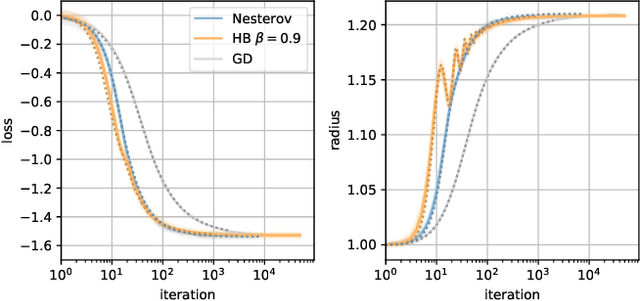
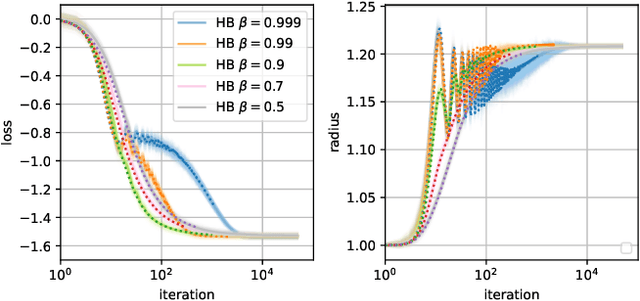
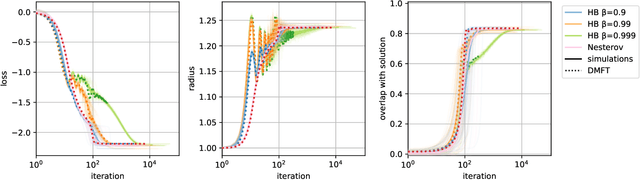

When optimizing over loss functions it is common practice to use momentum-based accelerated methods rather than vanilla gradient-based method. Despite widely applied to arbitrary loss function, their behaviour in generically non-convex, high dimensional landscapes is poorly understood. In this work we used dynamical mean field theory techniques to describe analytically the average behaviour of these methods in a prototypical non-convex model: the (spiked) matrix-tensor model. We derive a closed set of equations that describe the behaviours of several algorithms including heavy-ball momentum and Nesterov acceleration. Additionally we characterize the evolution of a mathematically equivalent physical system of massive particles relaxing toward the bottom of an energetic landscape. Under the correct mapping the two dynamics are equivalent and it can be noticed that having a large mass increases the effective time step of the heavy ball dynamics leading to a speed up.
CoreDiag: Eliminating Redundancy in Constraint Sets
Feb 24, 2021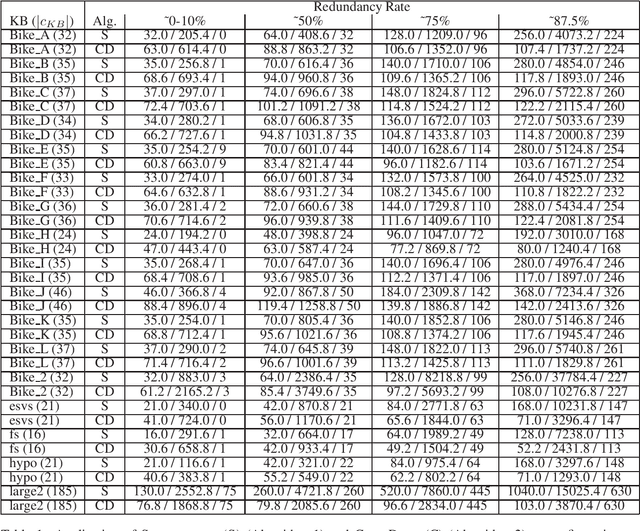
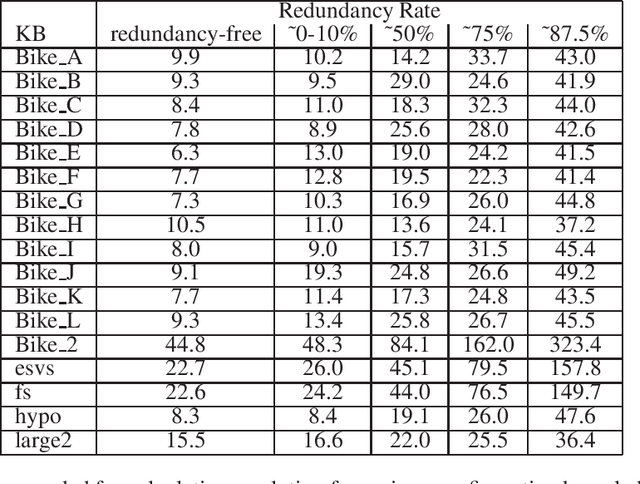
Constraint-based environments such as configuration systems, recommender systems, and scheduling systems support users in different decision making scenarios. These environments exploit a knowledge base for determining solutions of interest for the user. The development and maintenance of such knowledge bases is an extremely time-consuming and error-prone task. Users often specify constraints which do not reflect the real-world. For example, redundant constraints are specified which often increase both, the effort for calculating a solution and efforts related to knowledge base development and maintenance. In this paper we present a new algorithm (CoreDiag) which can be exploited for the determination of minimal cores (minimal non-redundant constraint sets). The algorithm is especially useful for distributed knowledge engineering scenarios where the degree of redundancy can become high. In order to show the applicability of our approach, we present an empirical study conducted with commercial configuration knowledge bases.
Enhancement for Robustness of Koopman Operator-based Data-driven Mobile Robotic Systems
Mar 01, 2021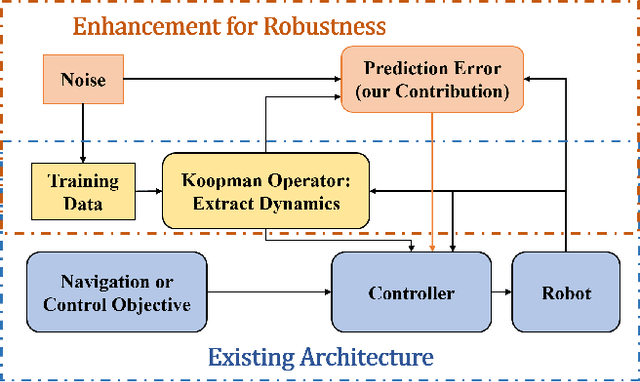
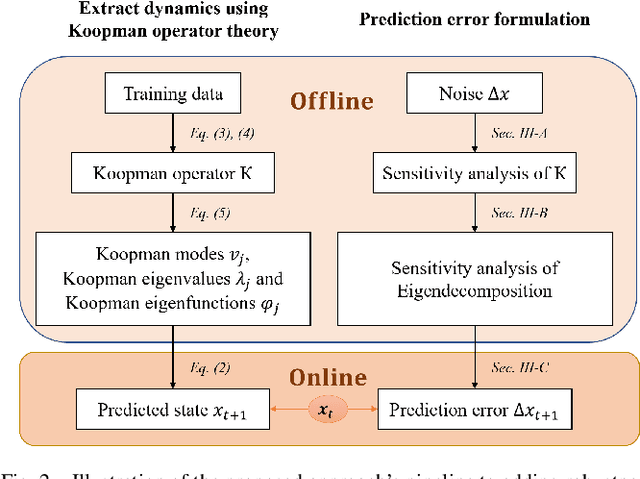
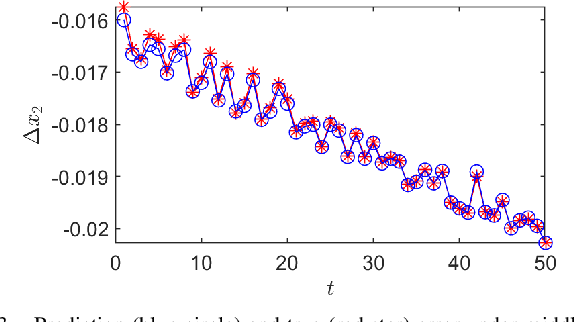
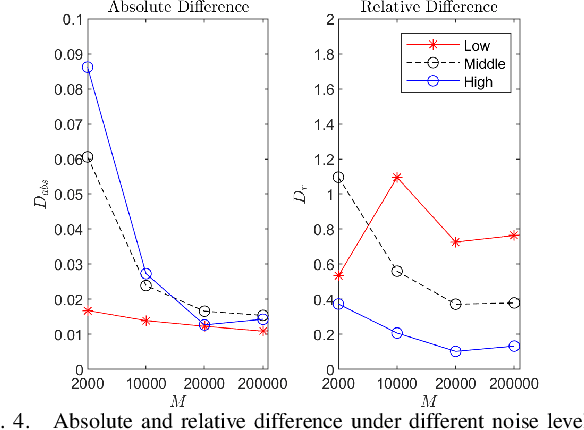
Koopman operator theory has served as the basis to extract dynamics for nonlinear system modeling and control across settings, including non-holonomic mobile robot control. Despite its widespread use, research on safety guarantees for systems the dynamics of which are extracted via the Koopman operator, has started receiving attention only recently. In this paper, we propose a way to quantify the prediction error because of noisy measurements when the Koopman operator is approximated via Extended Dynamic Mode Decomposition. We further develop an enhanced robot control strategy to endow robustness to a class of data-driven (robotic) systems that rely on Koopman operator theory, and we show how part of the strategy can happen offline in an effort to make our algorithm capable of real-time implementation. We perform a parametric study to evaluate the (theoretical) performance of the algorithm using a Van der Pol oscillator, and conduct a series of simulated experiments in Gazebo using a non-holonomic wheeled robot.
DANAE: a denoising autoencoder for underwater attitude estimation
Nov 13, 2020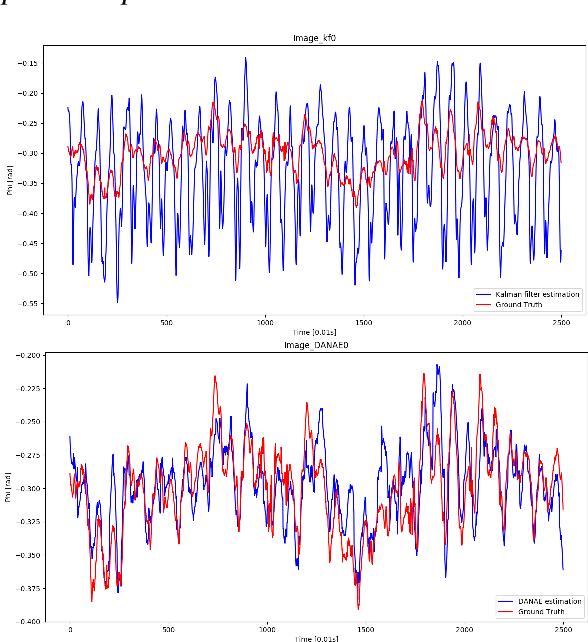
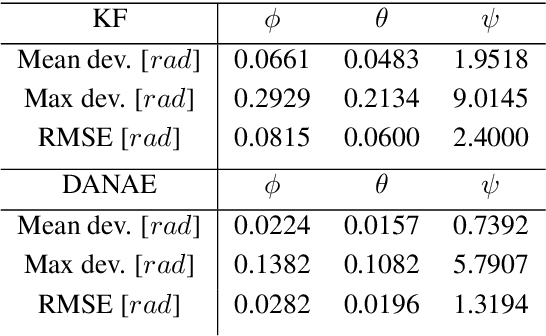
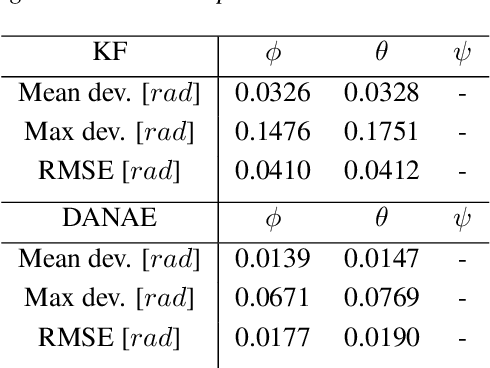
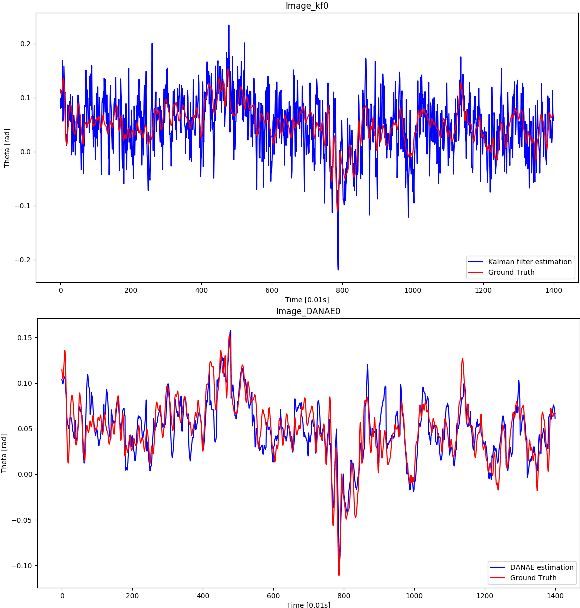
One of the main issues for underwater robots navigation is their accurate positioning, which heavily depends on the orientation estimation phase. The systems employed to this scope are affected by different noise typologies, mainly related to the sensors and to the irregular noise of the underwater environment. Filtering algorithms can reduce their effect if opportunely configured, but this process usually requires fine techniques and time. In this paper we propose DANAE, a deep Denoising AutoeNcoder for Attitude Estimation which works on Kalman filter IMU/AHRS data integration with the aim of reducing any kind of noise, independently of its nature. This deep learning-based architecture showed to be robust and reliable, significantly improving the Kalman filter results. Further tests could make this method suitable for real-time applications on navigation tasks.
Data Fusion for Audiovisual Speaker Localization: Extending Dynamic Stream Weights to the Spatial Domain
Feb 24, 2021
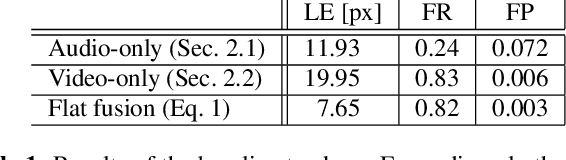
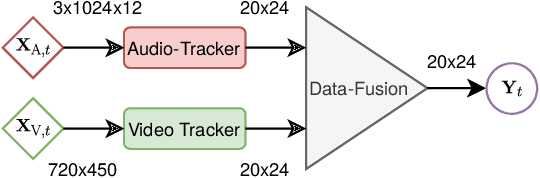
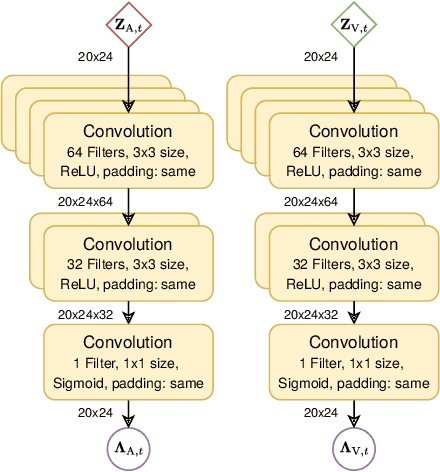
Estimating the positions of multiple speakers can be helpful for tasks like automatic speech recognition or speaker diarization. Both applications benefit from a known speaker position when, for instance, applying beamforming or assigning unique speaker identities. Recently, several approaches utilizing acoustic signals augmented with visual data have been proposed for this task. However, both the acoustic and the visual modality may be corrupted in specific spatial regions, for instance due to poor lighting conditions or to the presence of background noise. This paper proposes a novel audiovisual data fusion framework for speaker localization by assigning individual dynamic stream weights to specific regions in the localization space. This fusion is achieved via a neural network, which combines the predictions of individual audio and video trackers based on their time- and location-dependent reliability. A performance evaluation using audiovisual recordings yields promising results, with the proposed fusion approach outperforming all baseline models.
Randomization-based Machine Learning in Renewable Energy Prediction Problems: Critical Literature Review, New Results and Perspectives
Mar 26, 2021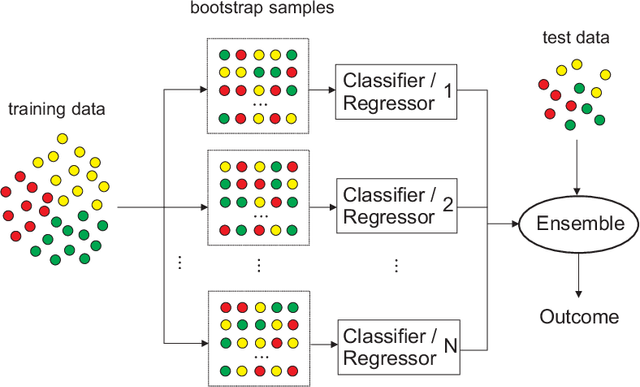
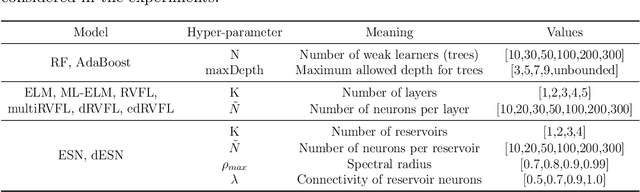
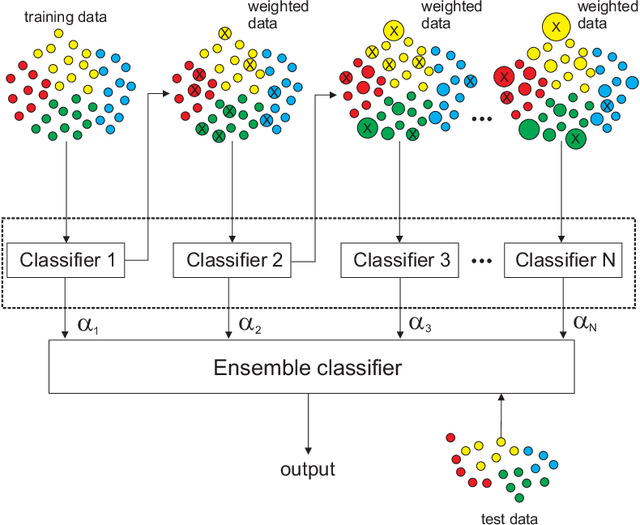

Randomization-based Machine Learning methods for prediction are currently a hot topic in Artificial Intelligence, due to their excellent performance in many prediction problems, with a bounded computation time. The application of randomization-based approaches to renewable energy prediction problems has been massive in the last few years, including many different types of randomization-based approaches, their hybridization with other techniques and also the description of new versions of classical randomization-based algorithms, including deep and ensemble approaches. In this paper we review the most important characteristics of randomization-based machine learning approaches and their application to renewable energy prediction problems. We describe the most important methods and algorithms of this family of modeling methods, and perform a critical literature review, examining prediction problems related to solar, wind, marine/ocean and hydro-power renewable sources. We support our critical analysis with an extensive experimental study, comprising real-world problems related to solar, wind and hydro-power energy, where randomization-based algorithms are found to achieve superior results at a significantly lower computational cost than other modeling counterparts. We end our survey with a prospect of the most important challenges and research directions that remain open this field, along with an outlook motivating further research efforts in this exciting research field.