 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Model-based Reconstruction for Enhanced X-ray CT of Tri-structural Isotropic (TRISO) Particles
Mar 19, 2021
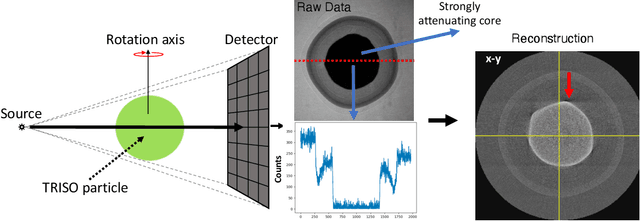
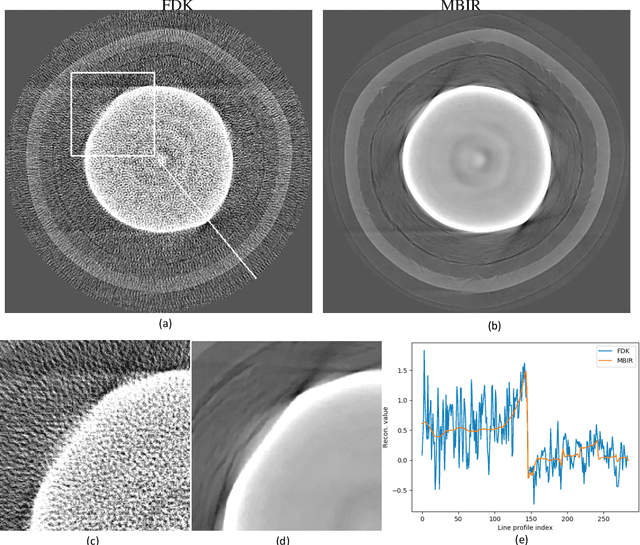
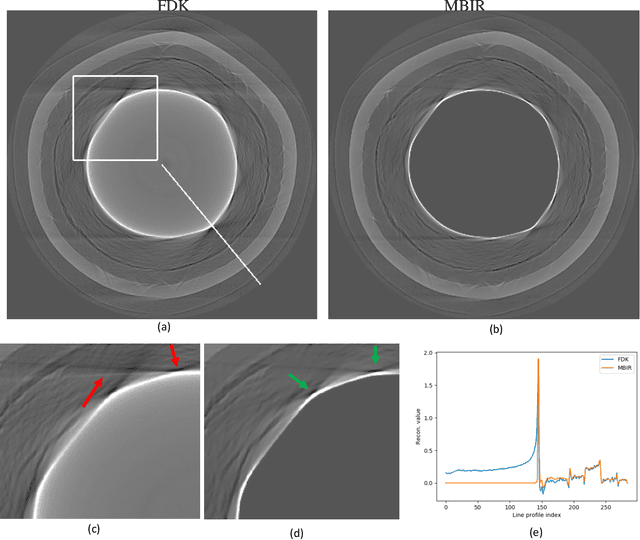

Tri-Structural Isotropic (TRISO) fuel particles are a key component of next generation nuclear fuels. Using X-ray computed tomography (CT) to characterize TRISO particles is challenging because of the strong attenuation of the X-ray beam by the uranium core leading to severe photon starvation in a substantial fraction of the measurements. Furthermore, the overall acquisition time for a high-resolution CT scan can be very long when using conventional lab-based X-ray systems and reconstruction algorithms. Specifically, when analytic methods like the Feldkamp-Davis-Kress (FDK) algorithm is used for reconstruction, it results in severe streaks artifacts and noise in the corresponding 3D volume which make subsequent analysis of the particles challenging. In this article, we develop and apply model-based image reconstruction (MBIR) algorithms for improving the quality of CT reconstructions for TRISO particles in order to facilitate better characterization. We demonstrate that the proposed MBIR algorithms can significantly suppress artifacts with minimal pre-processing compared to the conventional approaches. Furthermore, we demonstrate the proposed MBIR approach can obtain high-quality reconstruction compared to the FDK approach even when using a fraction of the typically acquired measurements, thereby enabling dramatically faster measurement times for TRISO particles.
Compositional Imitation Learning: Explaining and executing one task at a time
Dec 04, 2018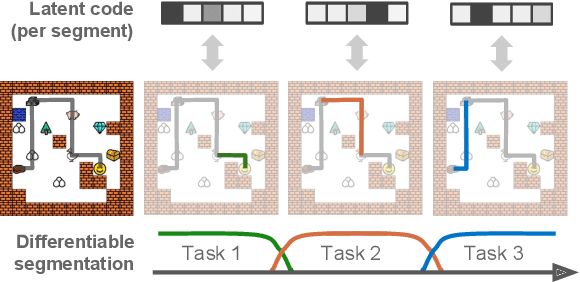
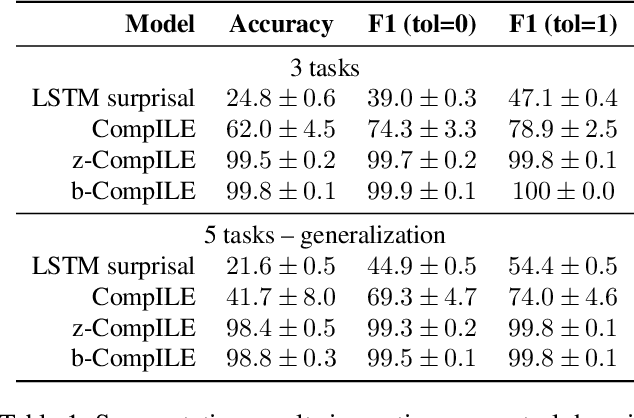
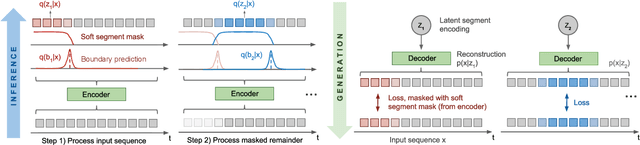
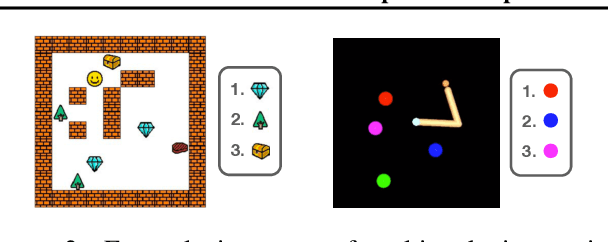
We introduce a framework for Compositional Imitation Learning and Execution (CompILE) of hierarchically-structured behavior. CompILE learns reusable, variable-length segments of behavior from demonstration data using a novel unsupervised, fully-differentiable sequence segmentation module. These learned behaviors can then be re-composed and executed to perform new tasks. At training time, CompILE auto-encodes observed behavior into a sequence of latent codes, each corresponding to a variable-length segment in the input sequence. Once trained, our model generalizes to sequences of longer length and from environment instances not seen during training. We evaluate our model in a challenging 2D multi-task environment and show that CompILE can find correct task boundaries and event encodings in an unsupervised manner without requiring annotated demonstration data. Latent codes and associated behavior policies discovered by CompILE can be used by a hierarchical agent, where the high-level policy selects actions in the latent code space, and the low-level, task-specific policies are simply the learned decoders. We found that our agent could learn given only sparse rewards, where agents without task-specific policies struggle.
Demo Abstract: Indoor Positioning System in Visually-Degraded Environments with Millimetre-Wave Radar and Inertial Sensors
Oct 26, 2020
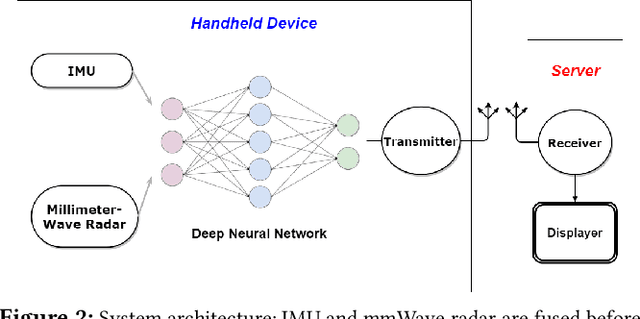
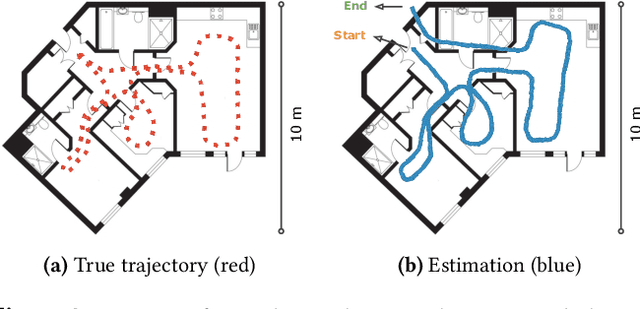
Positional estimation is of great importance in the public safety sector. Emergency responders such as fire fighters, medical rescue teams, and the police will all benefit from a resilient positioning system to deliver safe and effective emergency services. Unfortunately, satellite navigation (e.g., GPS) offers limited coverage in indoor environments. It is also not possible to rely on infrastructure based solutions. To this end, wearable sensor-aided navigation techniques, such as those based on camera and Inertial Measurement Units (IMU), have recently emerged recently as an accurate, infrastructure-free solution. Together with an increase in the computational capabilities of mobile devices, motion estimation can be performed in real-time. In this demonstration, we present a real-time indoor positioning system which fuses millimetre-wave (mmWave) radar and IMU data via deep sensor fusion. We employ mmWave radar rather than an RGB camera as it provides better robustness to visual degradation (e.g., smoke, darkness, etc.) while at the same time requiring lower computational resources to enable runtime computation. We implemented the sensor system on a handheld device and a mobile computer running at 10 FPS to track a user inside an apartment. Good accuracy and resilience were exhibited even in poorly illuminated scenes.
Differentially Private Quantiles
Feb 16, 2021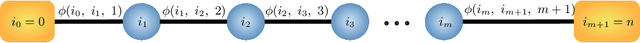

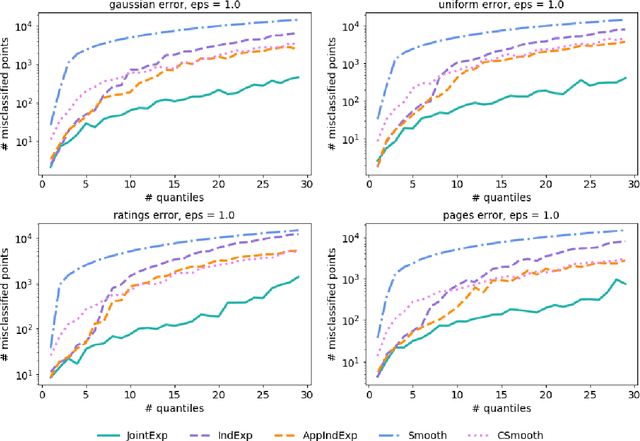
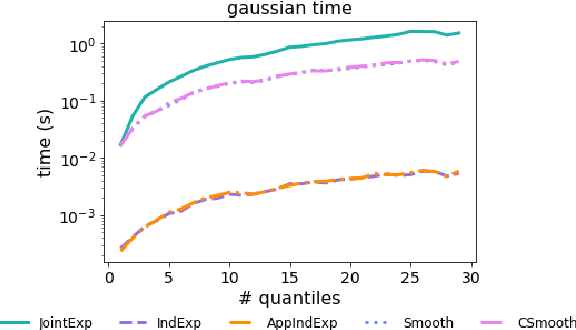
Quantiles are often used for summarizing and understanding data. If that data is sensitive, it may be necessary to compute quantiles in a way that is differentially private, providing theoretical guarantees that the result does not reveal private information. However, in the common case where multiple quantiles are needed, existing differentially private algorithms scale poorly: they compute each quantile individually, splitting their privacy budget and thus decreasing accuracy. In this work we propose an instance of the exponential mechanism that simultaneously estimates $m$ quantiles from $n$ data points while guaranteeing differential privacy. The utility function is carefully structured to allow for an efficient implementation that avoids exponential dependence on $m$ and returns estimates of all $m$ quantiles in time $O(mn^2 + m^2n)$. Experiments show that our method significantly outperforms the current state of the art on both real and synthetic data while remaining efficient enough to be practical.
Fairness, Semi-Supervised Learning, and More: A General Framework for Clustering with Stochastic Pairwise Constraints
Mar 02, 2021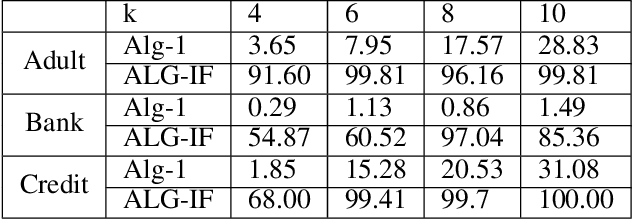
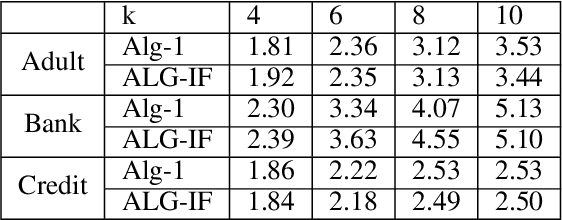
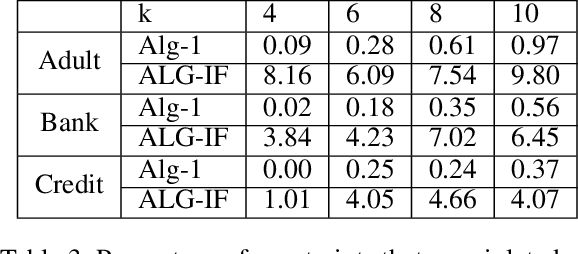
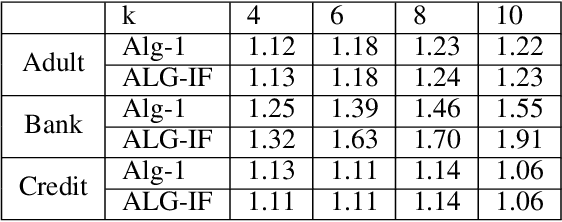
Metric clustering is fundamental in areas ranging from Combinatorial Optimization and Data Mining, to Machine Learning and Operations Research. However, in a variety of situations we may have additional requirements or knowledge, distinct from the underlying metric, regarding which pairs of points should be clustered together. To capture and analyze such scenarios, we introduce a novel family of \emph{stochastic pairwise constraints}, which we incorporate into several essential clustering objectives (radius/median/means). Moreover, we demonstrate that these constraints can succinctly model an intriguing collection of applications, including among others \emph{Individual Fairness} in clustering and \emph{Must-link} constraints in semi-supervised learning. Our main result consists of a general framework that yields approximation algorithms with provable guarantees for important clustering objectives, while at the same time producing solutions that respect the stochastic pairwise constraints. Furthermore, for certain objectives we devise improved results in the case of Must-link constraints, which are also the best possible from a theoretical perspective. Finally, we present experimental evidence that validates the effectiveness of our algorithms.
UAV-ReID: A Benchmark on Unmanned Aerial Vehicle Re-identification
Apr 13, 2021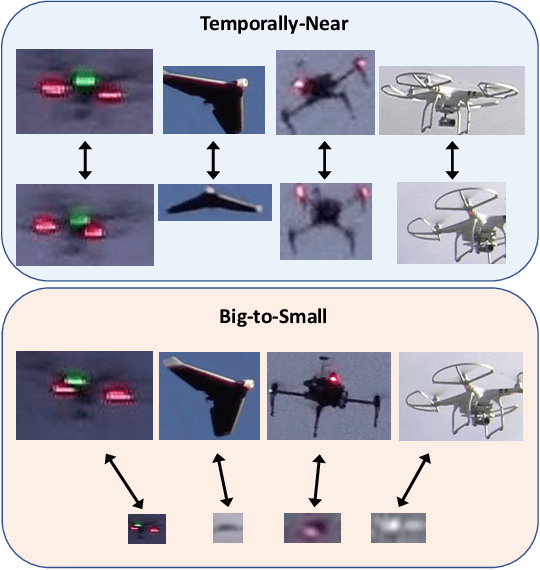
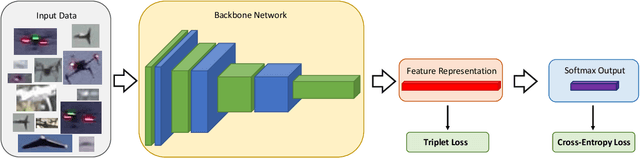

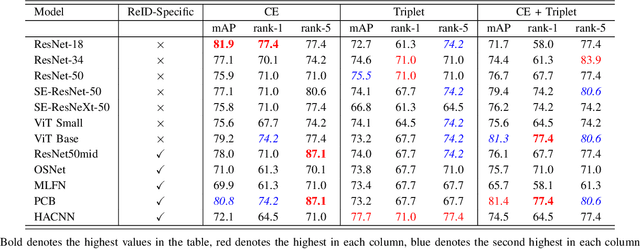
As unmanned aerial vehicles (UAVs) become more accessible with a growing range of applications, the potential risk of UAV disruption increases. Recent development in deep learning allows vision-based counter-UAV systems to detect and track UAVs with a single camera. However, the coverage of a single camera is limited, necessitating the need for multicamera configurations to match UAVs across cameras - a problem known as re-identification (reID). While there has been extensive research on person and vehicle reID to match objects across time and viewpoints, to the best of our knowledge, there has been no research in UAV reID. UAVs are challenging to re-identify: they are much smaller than pedestrians and vehicles and they are often detected in the air so appear at a greater range of angles. Because no UAV data sets currently use multiple cameras, we propose the first new UAV re-identification data set, UAV-reID, that facilitates the development of machine learning solutions in this emerging area. UAV-reID has two settings: Temporally-Near to evaluate performance across views to assist tracking frameworks, and Big-to-Small to evaluate reID performance across scale and to allow early reID when UAVs are detected from a long distance. We conduct a benchmark study by extensively evaluating different reID backbones and loss functions. We demonstrate that with the right setup, deep networks are powerful enough to learn good representations for UAVs, achieving 81.9% mAP on the Temporally-Near setting and 46.5% on the challenging Big-to-Small setting. Furthermore, we find that vision transformers are the most robust to extreme variance of scale.
Active$^2$ Learning: Actively reducing redundancies in Active Learning methods for Sequence Tagging and Machine Translation
Mar 11, 2021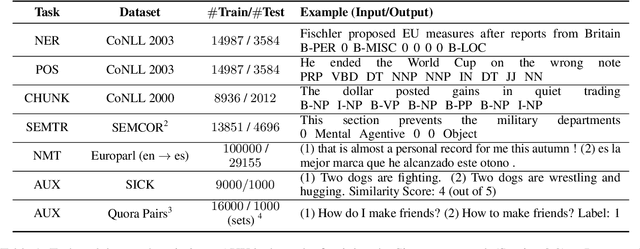
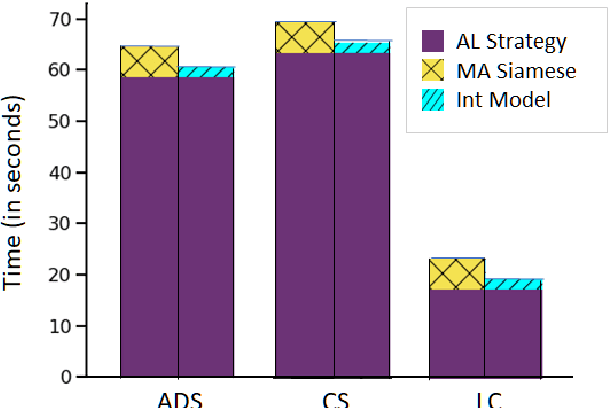
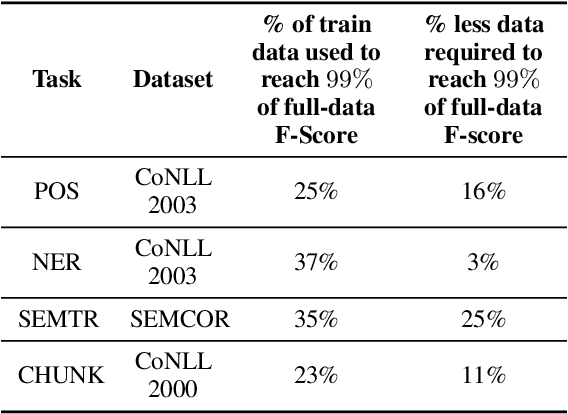
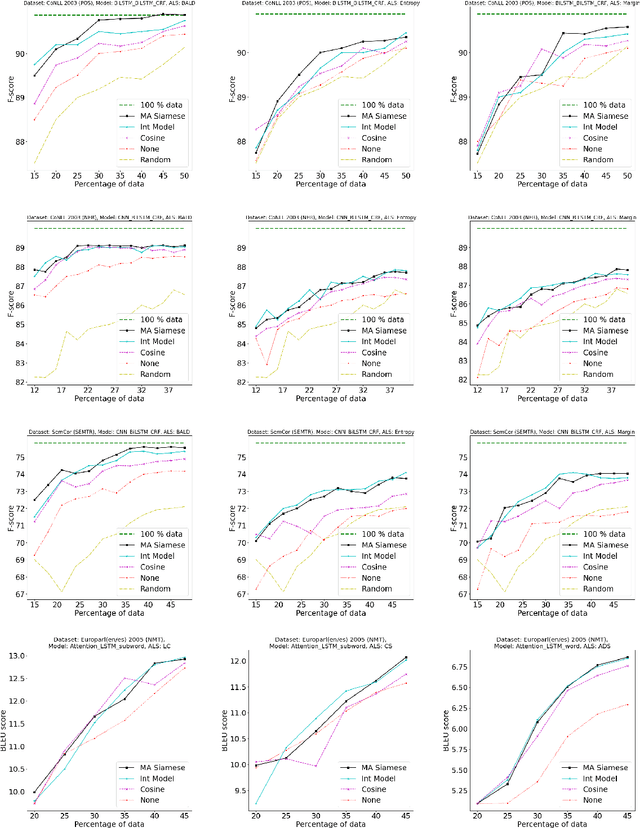
While deep learning is a powerful tool for natural language processing (NLP) problems, successful solutions to these problems rely heavily on large amounts of annotated samples. However, manually annotating data is expensive and time-consuming. Active Learning (AL) strategies reduce the need for huge volumes of labeled data by iteratively selecting a small number of examples for manual annotation based on their estimated utility in training the given model. In this paper, we argue that since AL strategies choose examples independently, they may potentially select similar examples, all of which may not contribute significantly to the learning process. Our proposed approach, Active$\mathbf{^2}$ Learning (A$\mathbf{^2}$L), actively adapts to the deep learning model being trained to eliminate further such redundant examples chosen by an AL strategy. We show that A$\mathbf{^2}$L is widely applicable by using it in conjunction with several different AL strategies and NLP tasks. We empirically demonstrate that the proposed approach is further able to reduce the data requirements of state-of-the-art AL strategies by an absolute percentage reduction of $\approx\mathbf{3-25\%}$ on multiple NLP tasks while achieving the same performance with no additional computation overhead.
CloudAAE: Learning 6D Object Pose Regression with On-line Data Synthesis on Point Clouds
Mar 02, 2021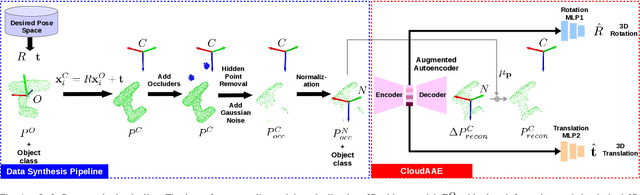
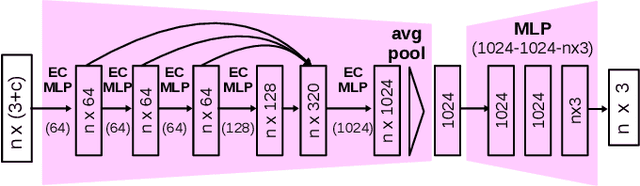
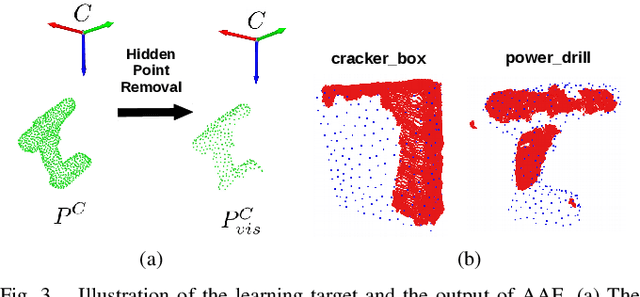
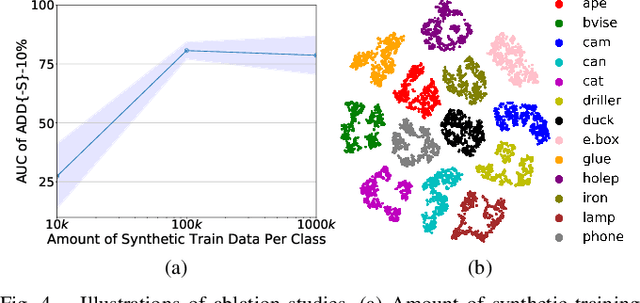
It is often desired to train 6D pose estimation systems on synthetic data because manual annotation is expensive. However, due to the large domain gap between the synthetic and real images, synthesizing color images is expensive. In contrast, this domain gap is considerably smaller and easier to fill for depth information. In this work, we present a system that regresses 6D object pose from depth information represented by point clouds, and a lightweight data synthesis pipeline that creates synthetic point cloud segments for training. We use an augmented autoencoder (AAE) for learning a latent code that encodes 6D object pose information for pose regression. The data synthesis pipeline only requires texture-less 3D object models and desired viewpoints, and it is cheap in terms of both time and hardware storage. Our data synthesis process is up to three orders of magnitude faster than commonly applied approaches that render RGB image data. We show the effectiveness of our system on the LineMOD, LineMOD Occlusion, and YCB Video datasets. The implementation of our system is available at: https://github.com/GeeeG/CloudAAE.
A Novel Multi-Stage Training Approach for Human Activity Recognition from Multimodal Wearable Sensor Data Using Deep Neural Network
Jan 03, 2021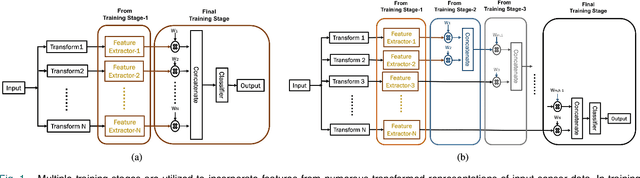
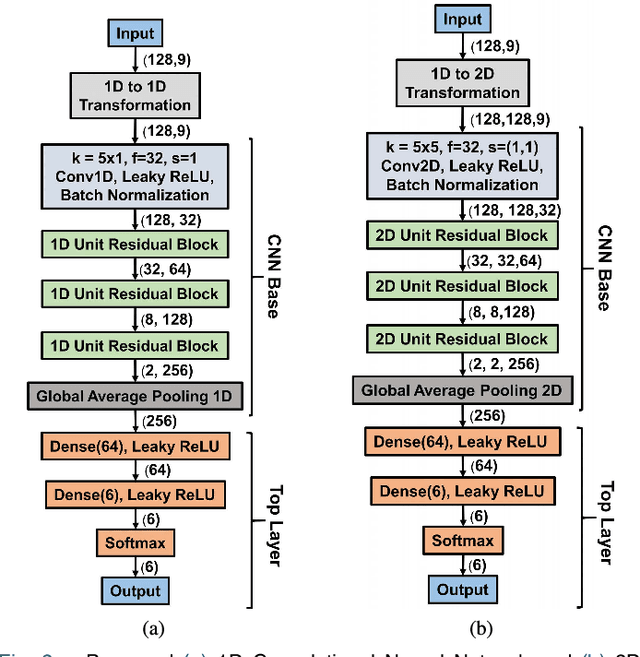
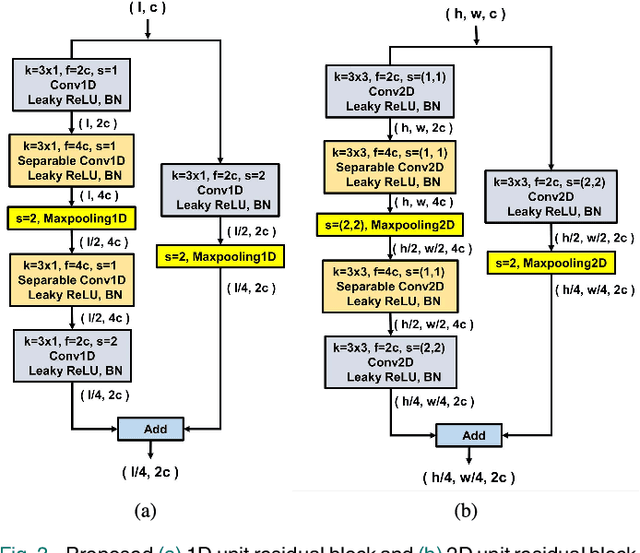
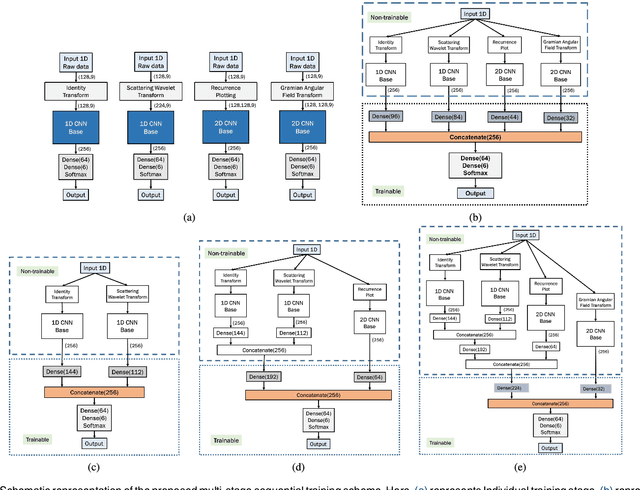
Deep neural network is an effective choice to automatically recognize human actions utilizing data from various wearable sensors. These networks automate the process of feature extraction relying completely on data. However, various noises in time series data with complex inter-modal relationships among sensors make this process more complicated. In this paper, we have proposed a novel multi-stage training approach that increases diversity in this feature extraction process to make accurate recognition of actions by combining varieties of features extracted from diverse perspectives. Initially, instead of using single type of transformation, numerous transformations are employed on time series data to obtain variegated representations of the features encoded in raw data. An efficient deep CNN architecture is proposed that can be individually trained to extract features from different transformed spaces. Later, these CNN feature extractors are merged into an optimal architecture finely tuned for optimizing diversified extracted features through a combined training stage or multiple sequential training stages. This approach offers the opportunity to explore the encoded features in raw sensor data utilizing multifarious observation windows with immense scope for efficient selection of features for final convergence. Extensive experimentations have been carried out in three publicly available datasets that provide outstanding performance consistently with average five-fold cross-validation accuracy of 99.29% on UCI HAR database, 99.02% on USC HAR database, and 97.21% on SKODA database outperforming other state-of-the-art approaches.
* 12 Pages, 7 Figures. This article has been published in IEEE Sensors Journal
Learning Student-Friendly Teacher Networks for Knowledge Distillation
Feb 16, 2021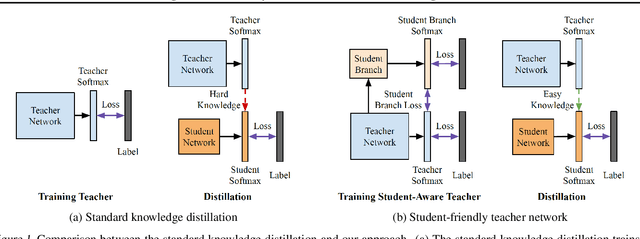
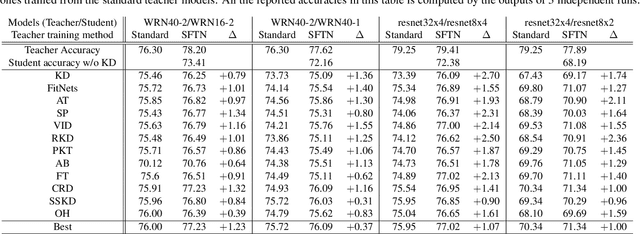
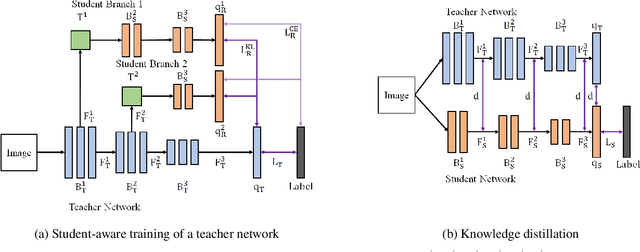
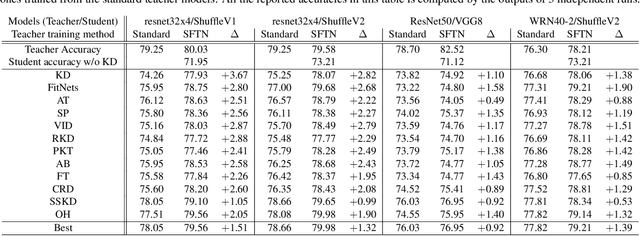
We propose a novel knowledge distillation approach to facilitate the transfer of dark knowledge from a teacher to a student. Contrary to most of the existing methods that rely on effective training of student models given pretrained teachers, we aim to learn the teacher models that are friendly to students and, consequently, more appropriate for knowledge transfer. In other words, even at the time of optimizing a teacher model, the proposed algorithm learns the student branches jointly to obtain student-friendly representations. Since the main goal of our approach lies in training teacher models and the subsequent knowledge distillation procedure is straightforward, most of the existing knowledge distillation algorithms can adopt this technique to improve the performance of the student models in terms of accuracy and convergence speed. The proposed algorithm demonstrates outstanding accuracy in several well-known knowledge distillation techniques with various combinations of teacher and student architectures.