 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Deep Emulator for Secondary Motion of 3D Characters
Mar 03, 2021
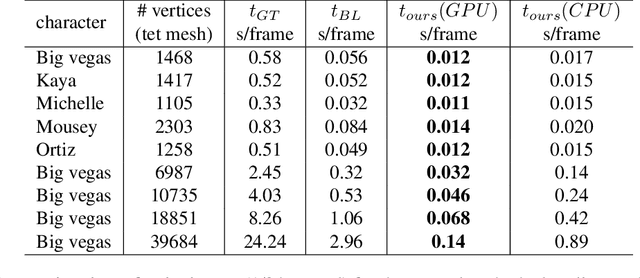
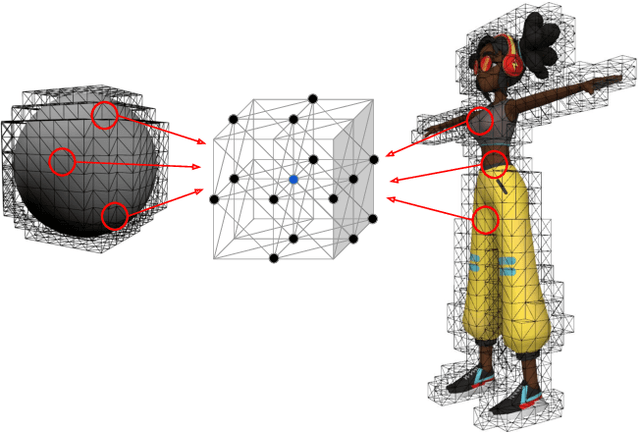
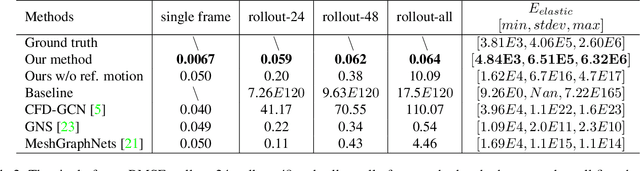
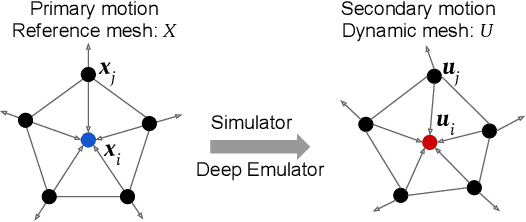
Fast and light-weight methods for animating 3D characters are desirable in various applications such as computer games. We present a learning-based approach to enhance skinning-based animations of 3D characters with vivid secondary motion effects. We design a neural network that encodes each local patch of a character simulation mesh where the edges implicitly encode the internal forces between the neighboring vertices. The network emulates the ordinary differential equations of the character dynamics, predicting new vertex positions from the current accelerations, velocities and positions. Being a local method, our network is independent of the mesh topology and generalizes to arbitrarily shaped 3D character meshes at test time. We further represent per-vertex constraints and material properties such as stiffness, enabling us to easily adjust the dynamics in different parts of the mesh. We evaluate our method on various character meshes and complex motion sequences. Our method can be over 30 times more efficient than ground-truth physically based simulation, and outperforms alternative solutions that provide fast approximations.
MaX-DeepLab: End-to-End Panoptic Segmentation with Mask Transformers
Dec 01, 2020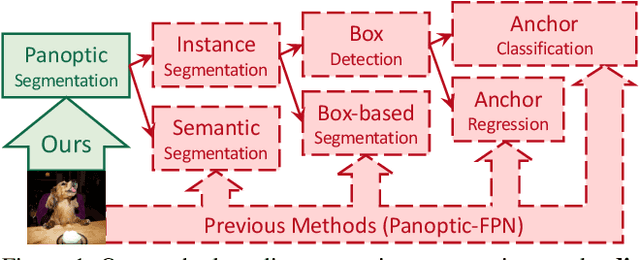
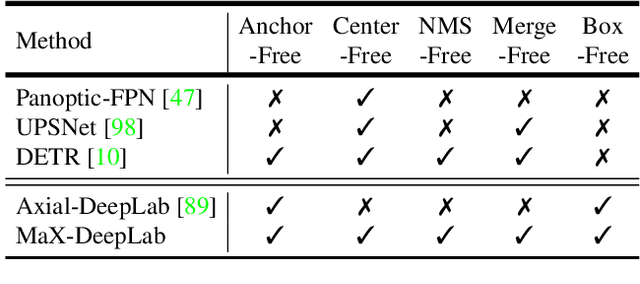

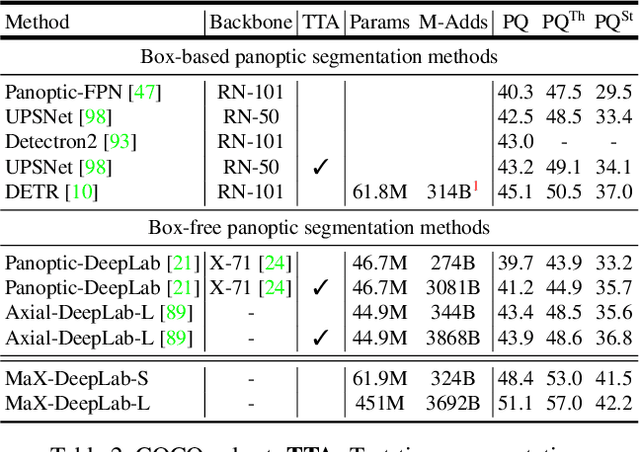
We present MaX-DeepLab, the first end-to-end model for panoptic segmentation. Our approach simplifies the current pipeline that depends heavily on surrogate sub-tasks and hand-designed components, such as box detection, non-maximum suppression, thing-stuff merging, etc. Although these sub-tasks are tackled by area experts, they fail to comprehensively solve the target task. By contrast, our MaX-DeepLab directly predicts class-labeled masks with a mask transformer, and is trained with a panoptic quality inspired loss via bipartite matching. Our mask transformer employs a dual-path architecture that introduces a global memory path in addition to a CNN path, allowing direct communication with any CNN layers. As a result, MaX-DeepLab shows a significant 7.1% PQ gain in the box-free regime on the challenging COCO dataset, closing the gap between box-based and box-free methods for the first time. A small variant of MaX-DeepLab improves 3.0% PQ over DETR with similar parameters and M-Adds. Furthermore, MaX-DeepLab, without test time augmentation, achieves new state-of-the-art 51.3% PQ on COCO test-dev set.
Demo Abstract: Indoor Positioning System in Visually-Degraded Environments with Millimetre-Wave Radar and Inertial Sensors
Oct 26, 2020
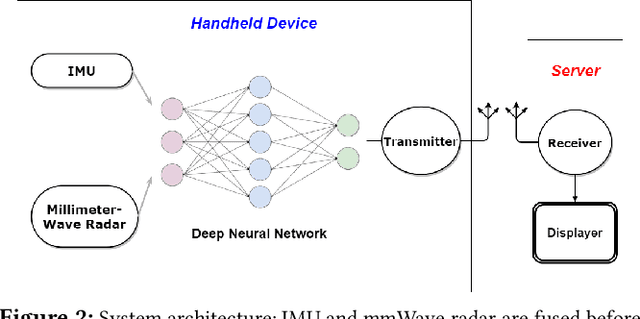
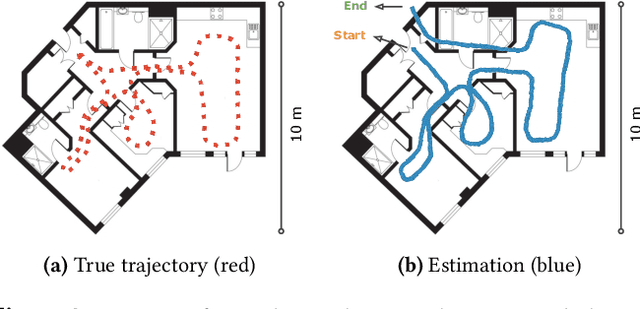
Positional estimation is of great importance in the public safety sector. Emergency responders such as fire fighters, medical rescue teams, and the police will all benefit from a resilient positioning system to deliver safe and effective emergency services. Unfortunately, satellite navigation (e.g., GPS) offers limited coverage in indoor environments. It is also not possible to rely on infrastructure based solutions. To this end, wearable sensor-aided navigation techniques, such as those based on camera and Inertial Measurement Units (IMU), have recently emerged recently as an accurate, infrastructure-free solution. Together with an increase in the computational capabilities of mobile devices, motion estimation can be performed in real-time. In this demonstration, we present a real-time indoor positioning system which fuses millimetre-wave (mmWave) radar and IMU data via deep sensor fusion. We employ mmWave radar rather than an RGB camera as it provides better robustness to visual degradation (e.g., smoke, darkness, etc.) while at the same time requiring lower computational resources to enable runtime computation. We implemented the sensor system on a handheld device and a mobile computer running at 10 FPS to track a user inside an apartment. Good accuracy and resilience were exhibited even in poorly illuminated scenes.
Improving Training Result of Partially Observable Markov Decision Process by Filtering Beliefs
Jan 05, 2021
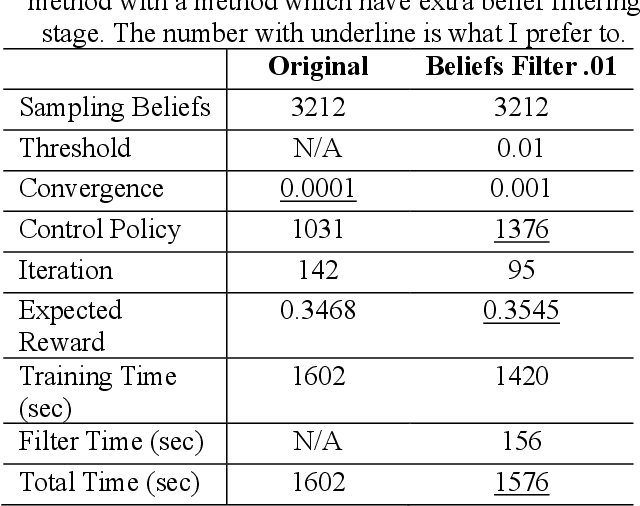
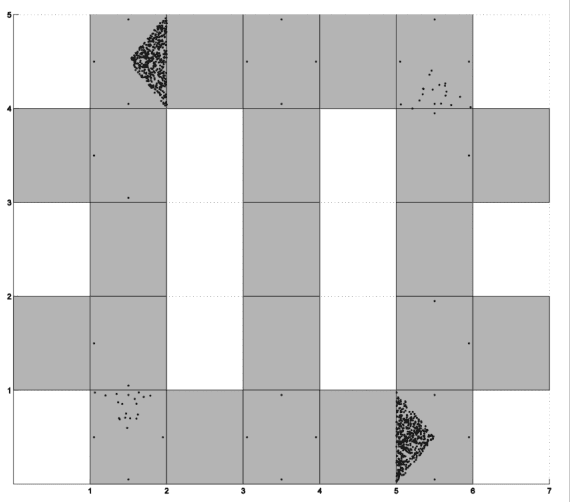
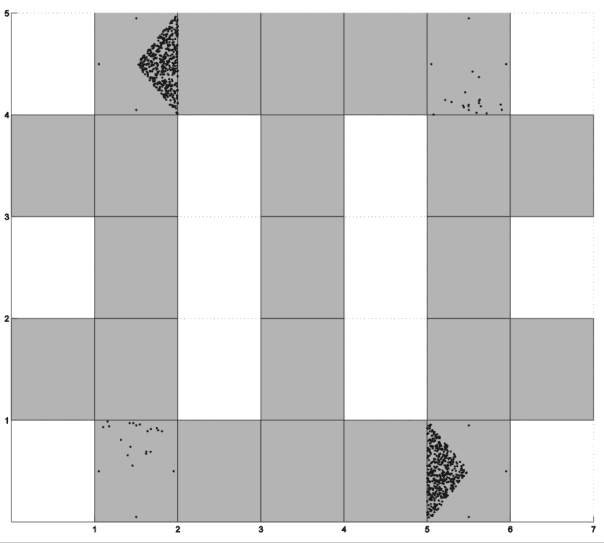
In this study I proposed a filtering beliefs method for improving performance of Partially Observable Markov Decision Processes(POMDPs), which is a method wildly used in autonomous robot and many other domains concerning control policy. My method search and compare every similar belief pair. Because a similar belief have insignificant influence on control policy, the belief is filtered out for reducing training time. The empirical results show that the proposed method outperforms the point-based approximate POMDPs in terms of the quality of training results as well as the efficiency of the method.
Semantic Contextual Reasoning to Provide Human Behavior
Mar 19, 2021

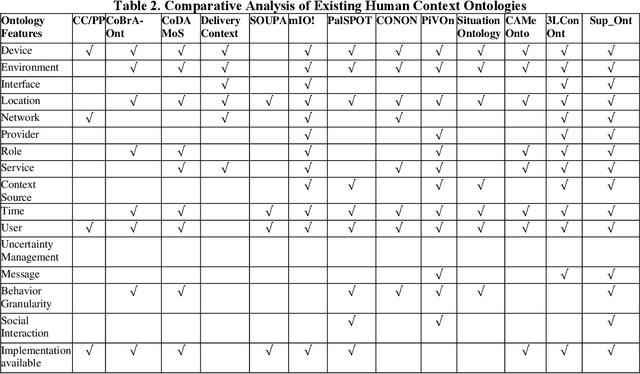
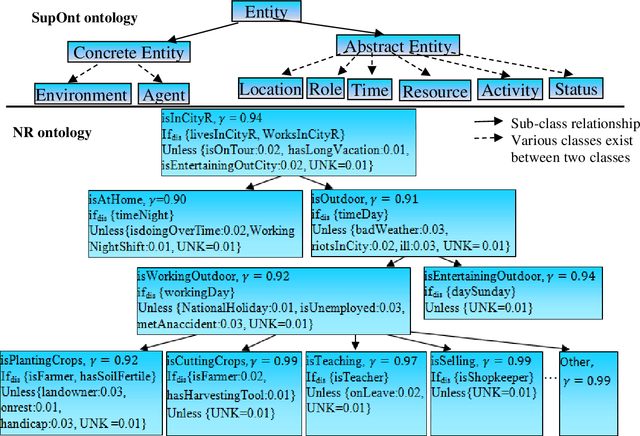
In recent years, the world has witnessed various primitives pertaining to the complexity of human behavior. Identifying an event in the presence of insufficient, incomplete, or tentative premises along with the constraints on resources such as time, data and memory is a vital aspect of an intelligent system. Data explosion presents one of the most challenging research issues for intelligent systems; to optimally represent and store this heterogeneous and voluminous data semantically to provide human behavior. There is a requirement of intelligent but personalized human behavior subject to constraints on resources and priority of the user. Knowledge, when represented in the form of an ontology, procures an intelligent response to a query posed by users; but it does not offer content in accordance with the user context. To this aim, we propose a model to quantify the user context and provide semantic contextual reasoning. A diagnostic belief algorithm (DBA) is also presented that identifies a given event and also computes the confidence of the decision as a function of available resources, premises, exceptions, and desired specificity. We conduct an empirical study in the domain of day-to-day routine queries and the experimental results show that the answer to queries and also its confidence varies with user context.
An NCAP-like Safety Indicator for Self-Driving Cars
Apr 02, 2021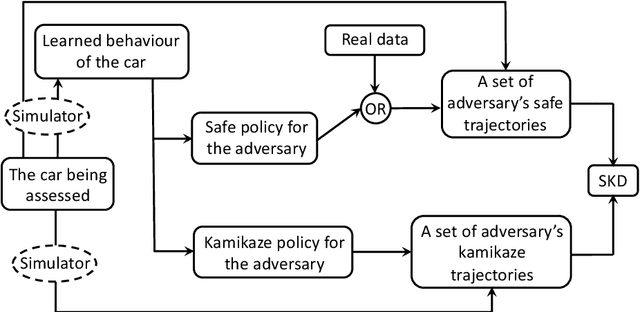

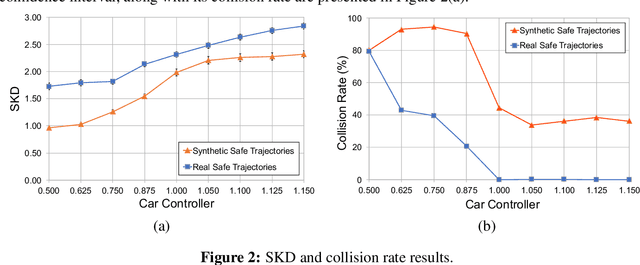
This paper proposes a mechanism to assess the safety of autonomous cars. It assesses the car's safety in scenarios where the car must avoid collision with an adversary. Core to this mechanism is a safety measure, called Safe-Kamikaze Distance (SKD), which computes the average similarity between sets of safe adversary's trajectories and kamikaze trajectories close to the safe trajectories. The kamikaze trajectories are generated based on planning under uncertainty techniques, namely the Partially Observable Markov Decision Processes, to account for the partially observed car policy from the point of view of the adversary. We found that SKD is inversely proportional to the upper bound on the probability that a small deformation changes a collision-free trajectory of the adversary into a colliding one. We perform systematic tests on a scenario where the adversary is a pedestrian crossing a single-lane road in front of the car being assessed --which is, one of the scenarios in the Euro-NCAP's Vulnerable Road User (VRU) tests on Autonomous Emergency Braking. Simulation results on assessing cars with basic controllers and a test on a Machine-Learning controller using a high-fidelity simulator indicates promising results for SKD to measure the safety of autonomous cars. Moreover, the time taken for each simulation test is under 11 seconds, enabling a sufficient statistics to compute SKD from simulation to be generated on a quad-core desktop in less than 25 minutes.
Robust Place Recognition using an Imaging Lidar
Mar 03, 2021

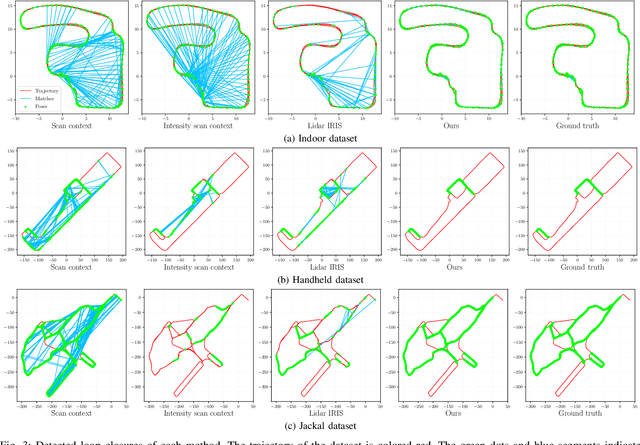

We propose a methodology for robust, real-time place recognition using an imaging lidar, which yields image-quality high-resolution 3D point clouds. Utilizing the intensity readings of an imaging lidar, we project the point cloud and obtain an intensity image. ORB feature descriptors are extracted from the image and encoded into a bag-of-words vector. The vector, used to identify the point cloud, is inserted into a database that is maintained by DBoW for fast place recognition queries. The returned candidate is further validated by matching visual feature descriptors. To reject matching outliers, we apply PnP, which minimizes the reprojection error of visual features' positions in Euclidean space with their correspondences in 2D image space, using RANSAC. Combining the advantages from both camera and lidar-based place recognition approaches, our method is truly rotation-invariant and can tackle reverse revisiting and upside-down revisiting. The proposed method is evaluated on datasets gathered from a variety of platforms over different scales and environments. Our implementation is available at https://git.io/imaging-lidar-place-recognition
Speech enhancement with mixture-of-deep-experts with clean clustering pre-training
Feb 11, 2021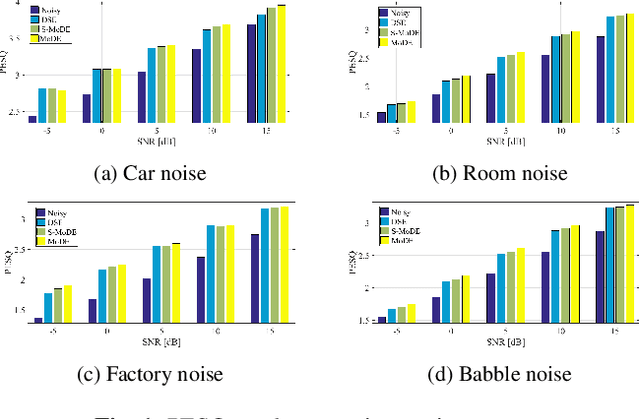

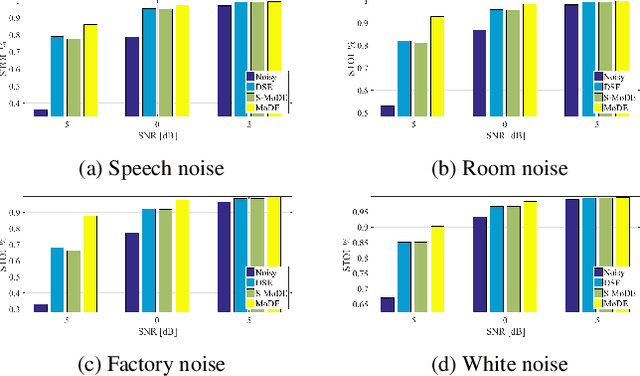
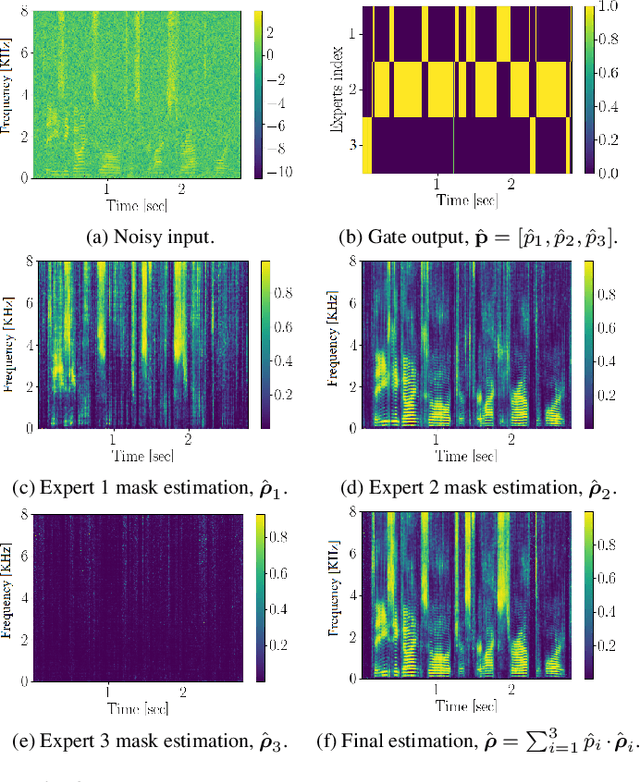
In this study we present a mixture of deep experts (MoDE) neural-network architecture for single microphone speech enhancement. Our architecture comprises a set of deep neural networks (DNNs), each of which is an 'expert' in a different speech spectral pattern such as phoneme. A gating DNN is responsible for the latent variables which are the weights assigned to each expert's output given a speech segment. The experts estimate a mask from the noisy input and the final mask is then obtained as a weighted average of the experts' estimates, with the weights determined by the gating DNN. A soft spectral attenuation, based on the estimated mask, is then applied to enhance the noisy speech signal. As a byproduct, we gain reduction at the complexity in test time. We show that the experts specialization allows better robustness to unfamiliar noise types.
Dynamic Graph Modeling of Simultaneous EEG and Eye-tracking Data for Reading Task Identification
Feb 21, 2021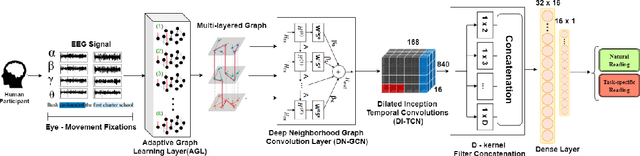
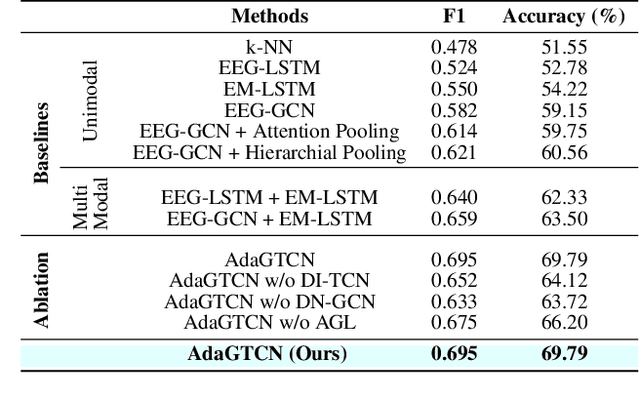
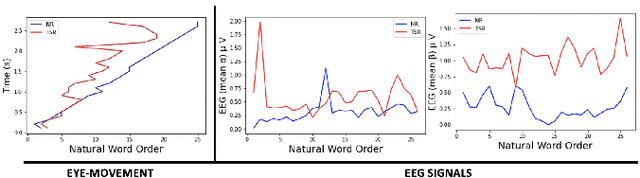
We present a new approach, that we call AdaGTCN, for identifying human reader intent from Electroencephalogram~(EEG) and Eye movement~(EM) data in order to help differentiate between normal reading and task-oriented reading. Understanding the physiological aspects of the reading process~(the cognitive load and the reading intent) can help improve the quality of crowd-sourced annotated data. Our method, Adaptive Graph Temporal Convolution Network (AdaGTCN), uses an Adaptive Graph Learning Layer and Deep Neighborhood Graph Convolution Layer for identifying the reading activities using time-locked EEG sequences recorded during word-level eye-movement fixations. Adaptive Graph Learning Layer dynamically learns the spatial correlations between the EEG electrode signals while the Deep Neighborhood Graph Convolution Layer exploits temporal features from a dense graph neighborhood to establish the state of the art in reading task identification over other contemporary approaches. We compare our approach with several baselines to report an improvement of 6.29% on the ZuCo 2.0 dataset, along with extensive ablation experiments
Trust and Safety
Apr 13, 2021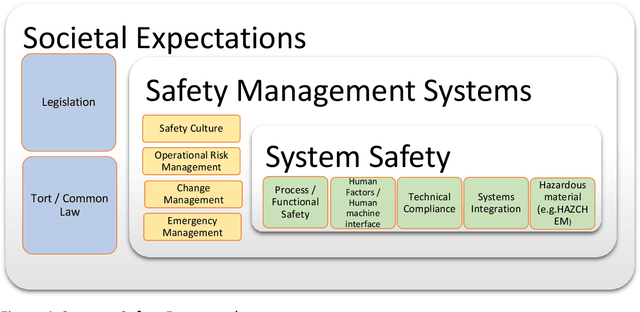


Robotics in Australia have a long history of conforming with safety standards and risk managed practices. This chapter articulates the current state of trust and safety in robotics including society's expectations, safety management systems and system safety as well as emerging issues and methods for ensuring safety in increasingly autonomous robotics. The future of trust and safety will combine standards with iterative, adaptive and responsive regulatory and assurance methods for diverse applications of robotics, autonomous systems and artificial intelligence (RAS-AI). Robotics will need novel technical and social approaches to achieve assurance, particularly for game-changing innovations. The ability for users to easily update algorithms and software, which alters the performance of a system, implies that traditional machine assurance performed prior to deployment or sale, will no longer be viable. Moreover, the high frequency of updates implies that traditional certification that requires substantial time will no longer be practical. To alleviate these difficulties, automation of assurance will likely be needed; something like 'ASsurance-as-a-Service' (ASaaS), where APIs constantly ping RAS-AI to ensure abidance with various rules, frameworks and behavioural expectations. There are exceptions to this, such as in contested or communications denied environments, or in underground or undersea mining; and these systems need their own risk assessments and limitations imposed. Indeed, self-monitors are already operating within some systems. To ensure safe operations of future robotics systems, Australia needs to invest in RAS-AI assurance research, stakeholder engagement and continued development and refinement of robust frameworks, methods, guidelines and policy in order to educate and prepare its technology developers, certifiers, and general population.