 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Robust Bandit Learning with Imperfect Context
Mar 04, 2021

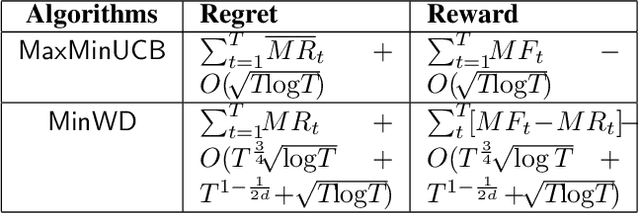
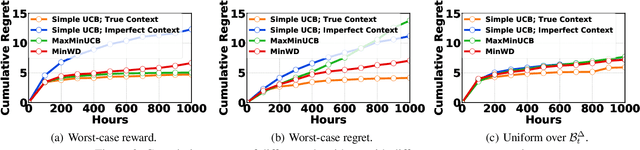

A standard assumption in contextual multi-arm bandit is that the true context is perfectly known before arm selection. Nonetheless, in many practical applications (e.g., cloud resource management), prior to arm selection, the context information can only be acquired by prediction subject to errors or adversarial modification. In this paper, we study a contextual bandit setting in which only imperfect context is available for arm selection while the true context is revealed at the end of each round. We propose two robust arm selection algorithms: MaxMinUCB (Maximize Minimum UCB) which maximizes the worst-case reward, and MinWD (Minimize Worst-case Degradation) which minimizes the worst-case regret. Importantly, we analyze the robustness of MaxMinUCB and MinWD by deriving both regret and reward bounds compared to an oracle that knows the true context. Our results show that as time goes on, MaxMinUCB and MinWD both perform as asymptotically well as their optimal counterparts that know the reward function. Finally, we apply MaxMinUCB and MinWD to online edge datacenter selection, and run synthetic simulations to validate our theoretical analysis.
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021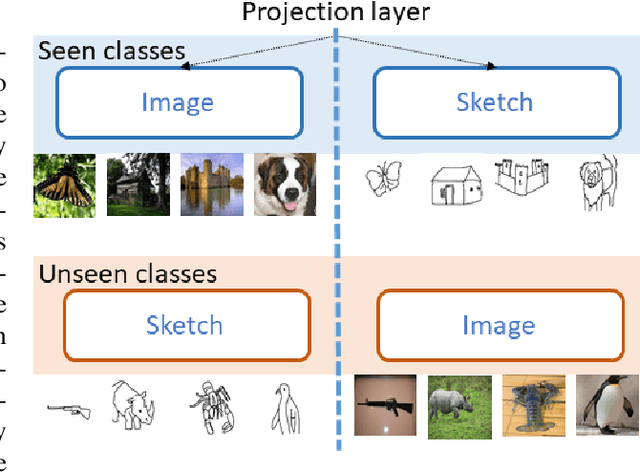
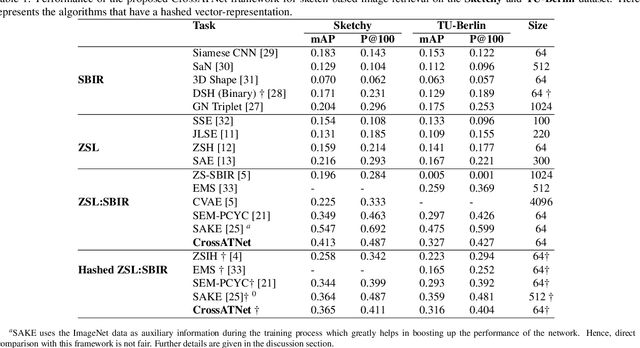
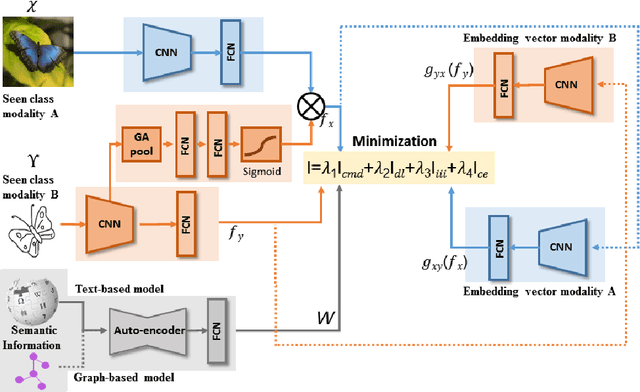
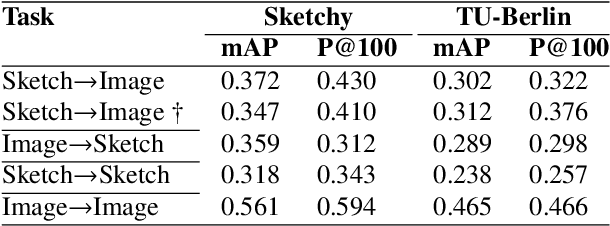
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
TimeCaps: Capturing Time Series Data with Capsule Networks
Nov 26, 2019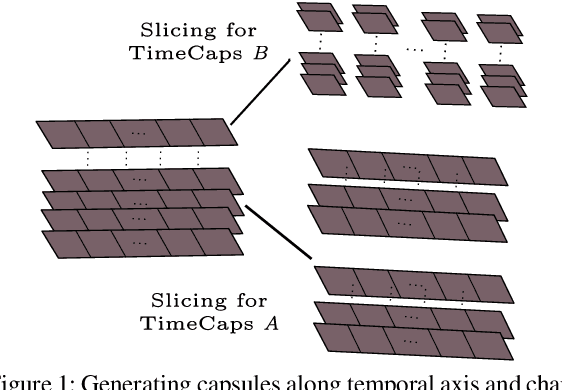
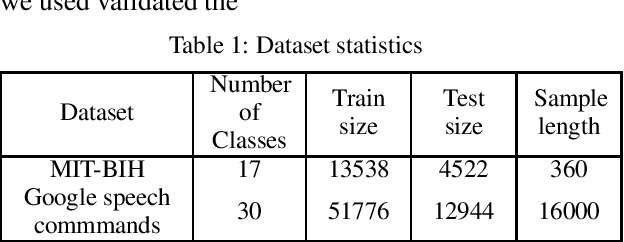
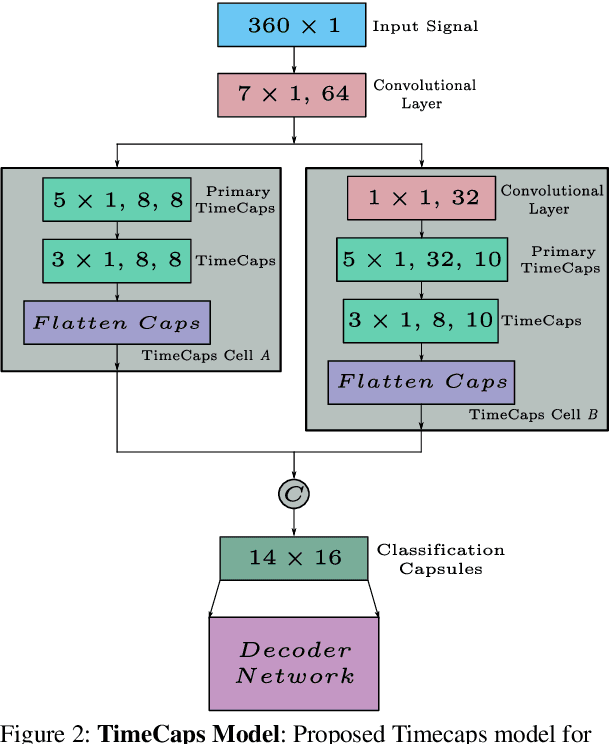
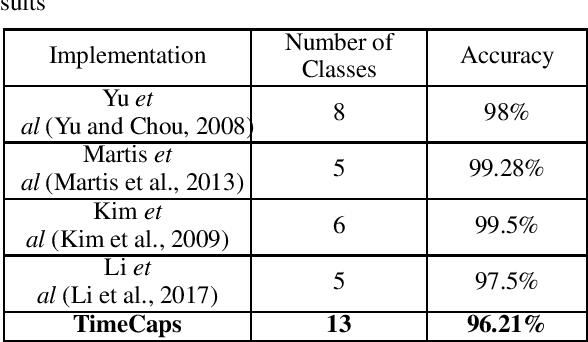
Capsule networks excel in understanding spatial relationships in 2D data for vision related tasks. Even though they are not designed to capture 1D temporal relationships, with TimeCaps we demonstrate that given the ability, capsule networks excel in understanding temporal relationships. To this end, we generate capsules along the temporal and channel dimensions creating two temporal feature detectors which learn contrasting relationships. TimeCaps surpasses the state-of-the-art results by achieving 96.21% accuracy on identifying 13 Electrocardiogram (ECG) signal beat categories, while achieving on-par results on identifying 30 classes of short audio commands. Further, the instantiation parameters inherently learnt by the capsule networks allow us to completely parameterize 1D signals which opens various possibilities in signal processing.
Learning Contact Dynamics using Physically Structured Neural Networks
Feb 22, 2021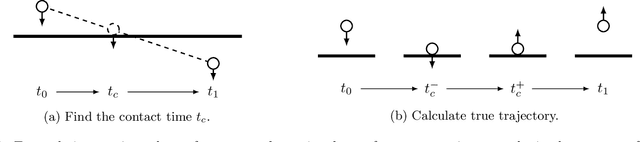

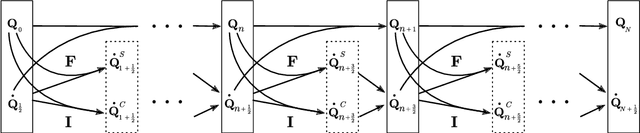

Learning physically structured representations of dynamical systems that include contact between different objects is an important problem for learning-based approaches in robotics. Black-box neural networks can learn to approximately represent discontinuous dynamics, but they typically require large quantities of data and often suffer from pathological behaviour when forecasting for longer time horizons. In this work, we use connections between deep neural networks and differential equations to design a family of deep network architectures for representing contact dynamics between objects. We show that these networks can learn discontinuous contact events in a data-efficient manner from noisy observations in settings that are traditionally difficult for black-box approaches and recent physics inspired neural networks. Our results indicate that an idealised form of touch feedback -- which is heavily relied upon by biological systems -- is a key component of making this learning problem tractable. Together with the inductive biases introduced through the network architectures, our techniques enable accurate learning of contact dynamics from observations.
An Attention-based Weakly Supervised framework for Spitzoid Melanocytic Lesion Diagnosis in WSI
Apr 20, 2021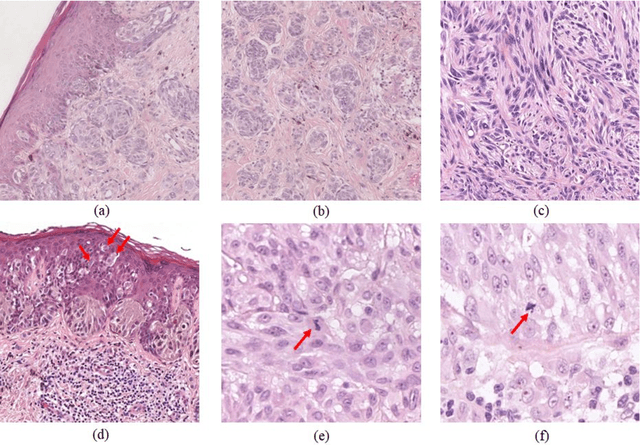

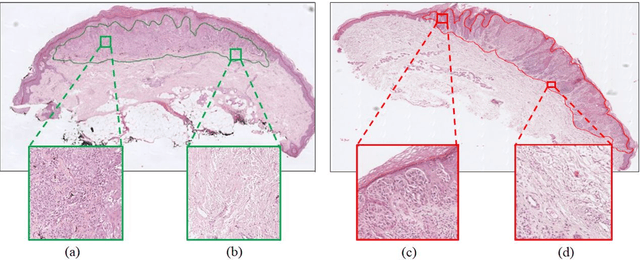
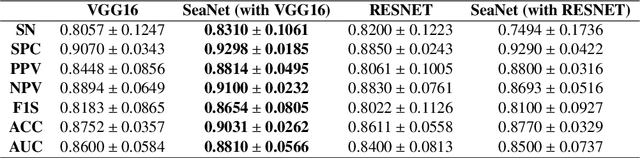
Melanoma is an aggressive neoplasm responsible for the majority of deaths from skin cancer. Specifically, spitzoid melanocytic tumors are one of the most challenging melanocytic lesions due to their ambiguous morphological features. The gold standard for its diagnosis and prognosis is the analysis of skin biopsies. In this process, dermatopathologists visualize skin histology slides under a microscope, in a high time-consuming and subjective task. In the last years, computer-aided diagnosis (CAD) systems have emerged as a promising tool that could support pathologists in daily clinical practice. Nevertheless, no automatic CAD systems have yet been proposed for the analysis of spitzoid lesions. Regarding common melanoma, no proposed system allows both the selection of the tumoral region and the prediction of the diagnosis as benign or malignant. Motivated by this, we propose a novel end-to-end weakly-supervised deep learning model, based on inductive transfer learning with an improved convolutional neural network (CNN) to refine the embedding features of the latent space. The framework is composed of a source model in charge of finding the tumor patch-level patterns, and a target model focuses on the specific diagnosis of a biopsy. The latter retrains the backbone of the source model through a multiple instance learning workflow to obtain the biopsy-level scoring. To evaluate the performance of the proposed methods, we perform extensive experiments on a private skin database with spitzoid lesions. Test results reach an accuracy of 0.9231 and 0.80 for the source and the target models, respectively. Besides, the heat map findings are directly in line with the clinicians' medical decision and even highlight, in some cases, patterns of interest that were overlooked by the pathologist due to the huge workload.
Model-based Learning Network for 3-D Localization in mmWave Communications
Mar 20, 2021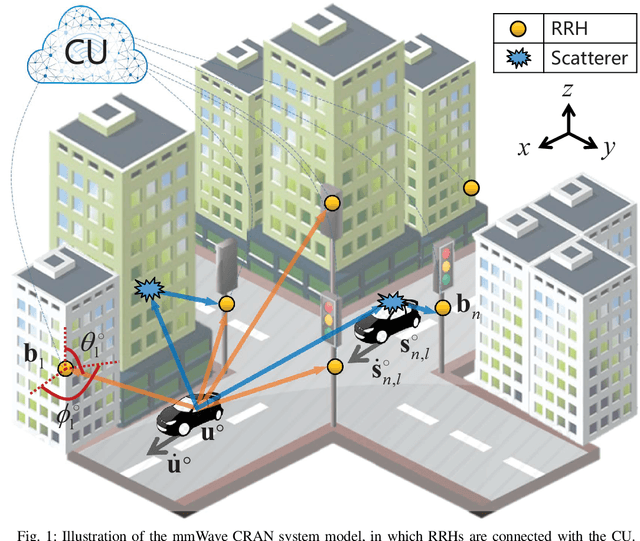
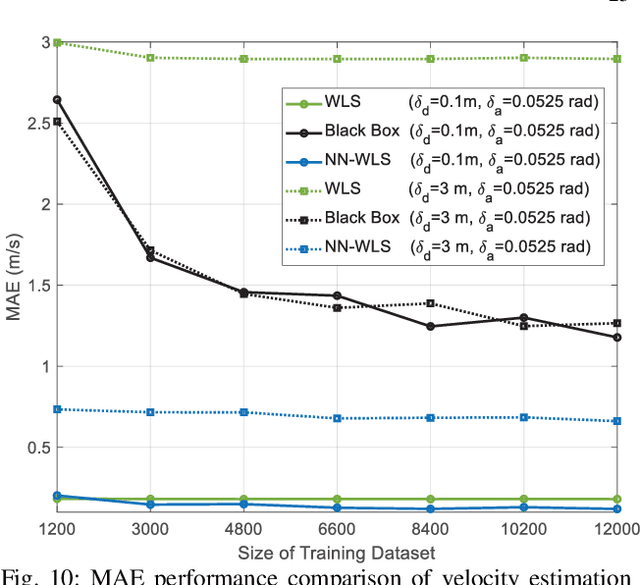
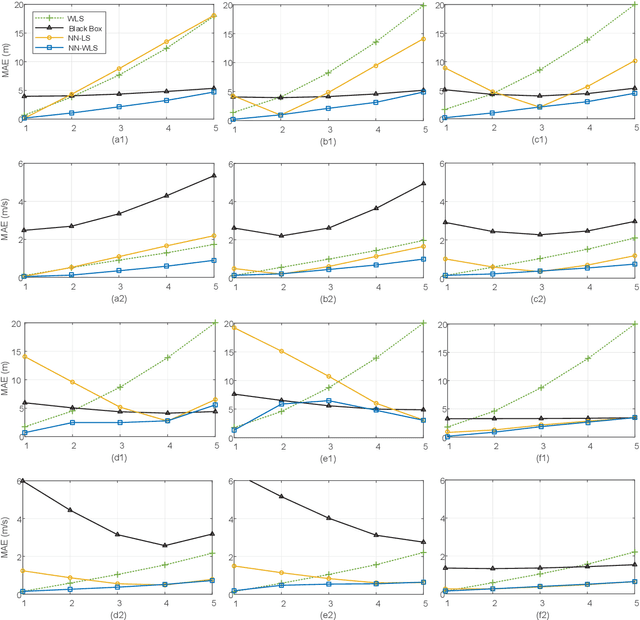
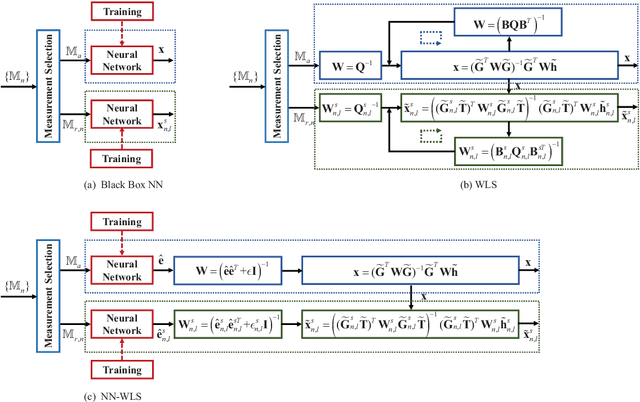
This study considers the joint location and velocity estimation of UE and scatterers in a three-dimensional mmWave CRAN architecture. Several existing works have achieved satisfactory results with neural networks (NNs) for localization. However, the black box NN localization method has limited performance and relies on a prohibitive amount of training data. Thus, we propose a model-based learning network for localization by combining NNs with geometric models. Specifically, we first develop an unbiased WLS estimator by utilizing hybrid delay/angular measurements, which determine the location and velocity of the UE in only one estimator, and can obtain the location and velocity of scatterers further. The proposed estimator can achieve the CRLB and outperforms state-of-the-art methods. Second, we establish a NN-assisted localization method (NN-WLS) by replacing the linear approximations in the proposed WLS localization model with NNs to learn higher-order error components, thereby enhancing the performance of the estimator. The solution possesses the powerful learning ability of the NN and the robustness of the proposed geometric model. Moreover, the ensemble learning is applied to improve the localization accuracy further. Comprehensive simulations show that the proposed NN-WLS is superior to the benchmark methods in terms of localization accuracy, robustness, and required time resources.
Exploiting Multiple Timescales in Hierarchical Echo State Networks
Jan 11, 2021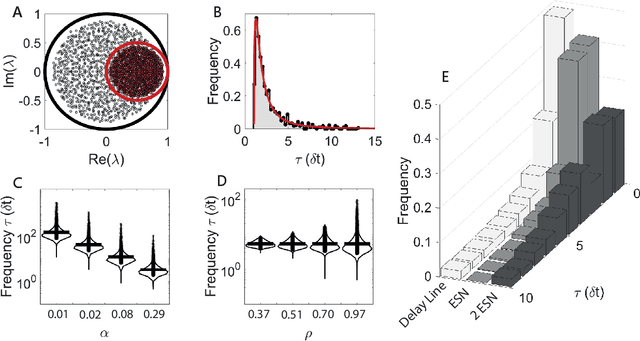
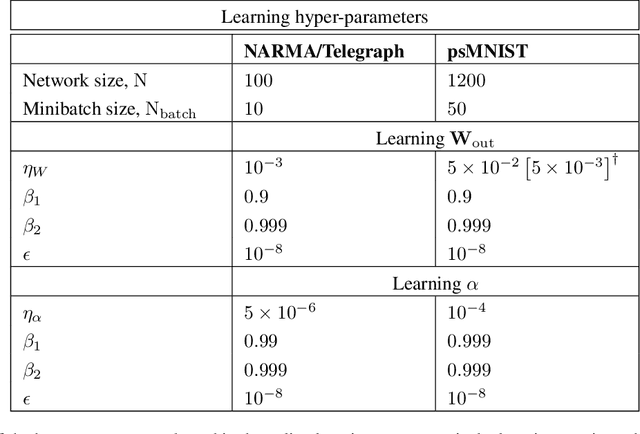
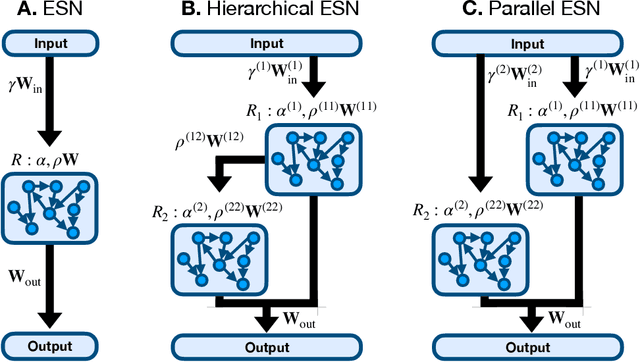
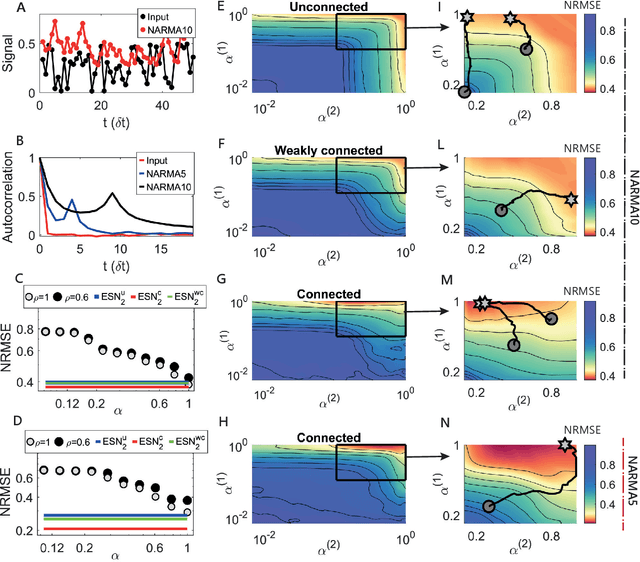
Echo state networks (ESNs) are a powerful form of reservoir computing that only require training of linear output weights whilst the internal reservoir is formed of fixed randomly connected neurons. With a correctly scaled connectivity matrix, the neurons' activity exhibits the echo-state property and responds to the input dynamics with certain timescales. Tuning the timescales of the network can be necessary for treating certain tasks, and some environments require multiple timescales for an efficient representation. Here we explore the timescales in hierarchical ESNs, where the reservoir is partitioned into two smaller linked reservoirs with distinct properties. Over three different tasks (NARMA10, a reconstruction task in a volatile environment, and psMNIST), we show that by selecting the hyper-parameters of each partition such that they focus on different timescales, we achieve a significant performance improvement over a single ESN. Through a linear analysis, and under the assumption that the timescales of the first partition are much shorter than the second's (typically corresponding to optimal operating conditions), we interpret the feedforward coupling of the partitions in terms of an effective representation of the input signal, provided by the first partition to the second, whereby the instantaneous input signal is expanded into a weighted combination of its time derivatives. Furthermore, we propose a data-driven approach to optimise the hyper-parameters through a gradient descent optimisation method that is an online approximation of backpropagation through time. We demonstrate the application of the online learning rule across all the tasks considered.
Medical data wrangling with sequential variational autoencoders
Mar 12, 2021

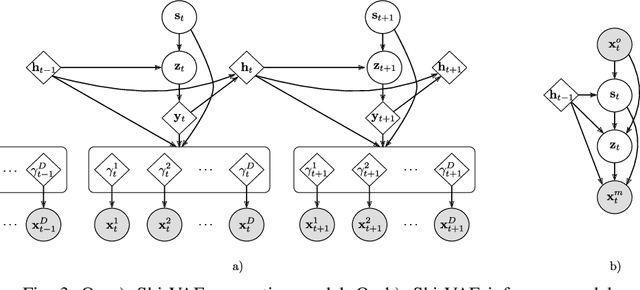
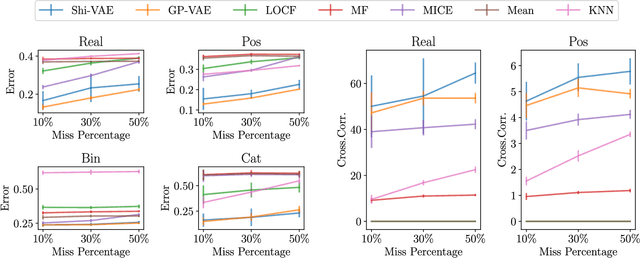
Medical data sets are usually corrupted by noise and missing data. These missing patterns are commonly assumed to be completely random, but in medical scenarios, the reality is that these patterns occur in bursts due to sensors that are off for some time or data collected in a misaligned uneven fashion, among other causes. This paper proposes to model medical data records with heterogeneous data types and bursty missing data using sequential variational autoencoders (VAEs). In particular, we propose a new methodology, the Shi-VAE, which extends the capabilities of VAEs to sequential streams of data with missing observations. We compare our model against state-of-the-art solutions in an intensive care unit database (ICU) and a dataset of passive human monitoring. Furthermore, we find that standard error metrics such as RMSE are not conclusive enough to assess temporal models and include in our analysis the cross-correlation between the ground truth and the imputed signal. We show that Shi-VAE achieves the best performance in terms of using both metrics, with lower computational complexity than the GP-VAE model, which is the state-of-the-art method for medical records.
A Review of Hidden Markov Models and Recurrent Neural Networks for Event Detection and Localization in Biomedical Signals
Dec 11, 2020
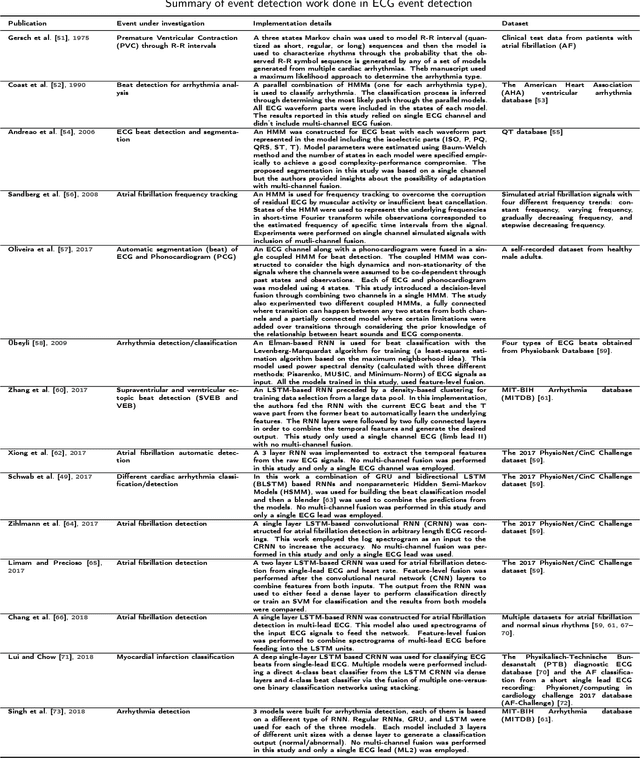
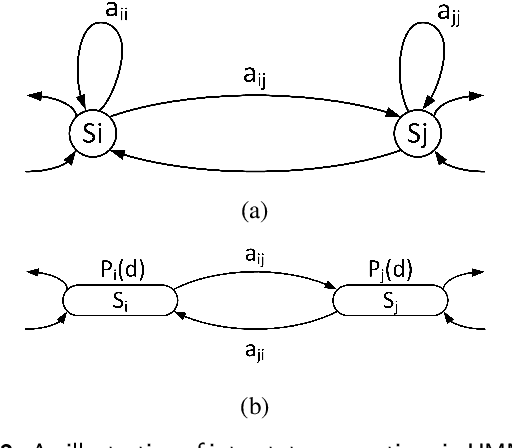
Biomedical signals carry signature rhythms of complex physiological processes that control our daily bodily activity. The properties of these rhythms indicate the nature of interaction dynamics among physiological processes that maintain a homeostasis. Abnormalities associated with diseases or disorders usually appear as disruptions in the structure of the rhythms which makes isolating these rhythms and the ability to differentiate between them, indispensable. Computer aided diagnosis systems are ubiquitous nowadays in almost every medical facility and more closely in wearable technology, and rhythm or event detection is the first of many intelligent steps that they perform. How these rhythms are isolated? How to develop a model that can describe the transition between processes in time? Many methods exist in the literature that address these questions and perform the decoding of biomedical signals into separate rhythms. In here, we demystify the most effective methods that are used for detection and isolation of rhythms or events in time series and highlight the way in which they were applied to different biomedical signals and how they contribute to information fusion. The key strengths and limitations of these methods are also discussed as well as the challenges encountered with application in biomedical signals.
Demo Abstract: Indoor Positioning System in Visually-Degraded Environments with Millimetre-Wave Radar and Inertial Sensors
Oct 26, 2020
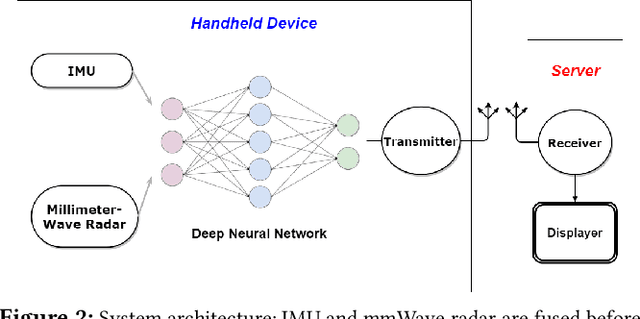
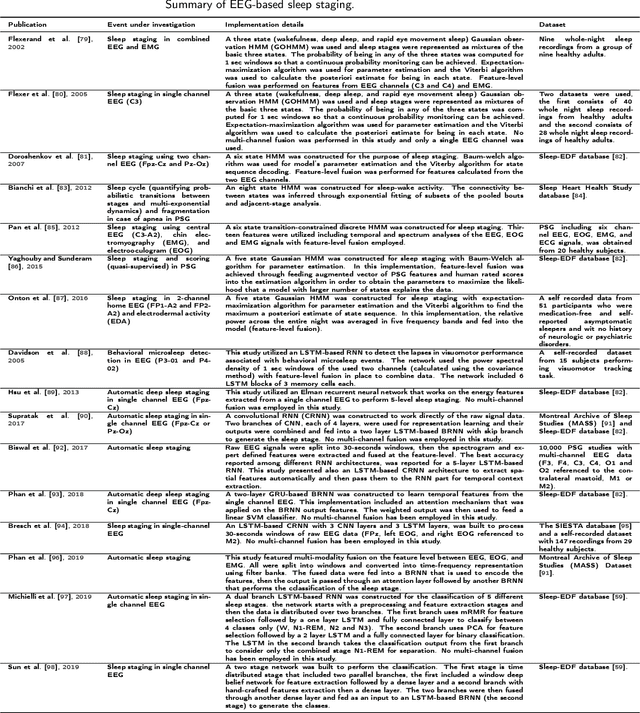
Positional estimation is of great importance in the public safety sector. Emergency responders such as fire fighters, medical rescue teams, and the police will all benefit from a resilient positioning system to deliver safe and effective emergency services. Unfortunately, satellite navigation (e.g., GPS) offers limited coverage in indoor environments. It is also not possible to rely on infrastructure based solutions. To this end, wearable sensor-aided navigation techniques, such as those based on camera and Inertial Measurement Units (IMU), have recently emerged recently as an accurate, infrastructure-free solution. Together with an increase in the computational capabilities of mobile devices, motion estimation can be performed in real-time. In this demonstration, we present a real-time indoor positioning system which fuses millimetre-wave (mmWave) radar and IMU data via deep sensor fusion. We employ mmWave radar rather than an RGB camera as it provides better robustness to visual degradation (e.g., smoke, darkness, etc.) while at the same time requiring lower computational resources to enable runtime computation. We implemented the sensor system on a handheld device and a mobile computer running at 10 FPS to track a user inside an apartment. Good accuracy and resilience were exhibited even in poorly illuminated scenes.