 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Optimal Control Approach to Learning in SIDARTHE Epidemic model
Oct 28, 2020
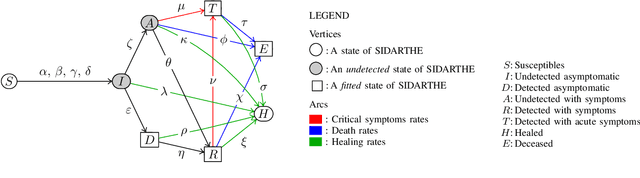
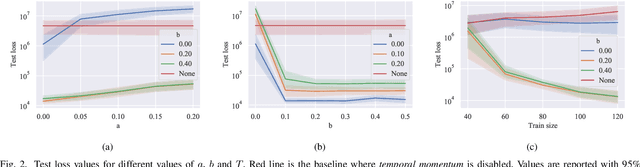
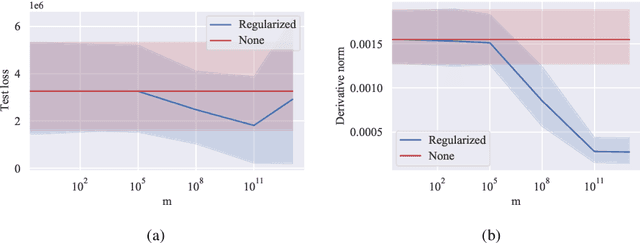
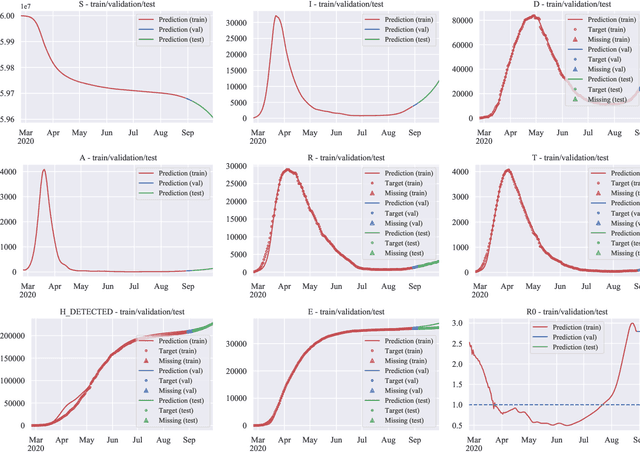
The COVID-19 outbreak has stimulated the interest in the proposal of novel epidemiological models to predict the course of the epidemic so as to help planning effective control strategies. In particular, in order to properly interpret the available data, it has become clear that one must go beyond most classic epidemiological models and consider models that, like the recently proposed SIDARTHE, offer a richer description of the stages of infection. The problem of learning the parameters of these models is of crucial importance especially when assuming that they are time-variant, which further enriches their effectiveness. In this paper we propose a general approach for learning time-variant parameters of dynamic compartmental models from epidemic data. We formulate the problem in terms of a functional risk that depends on the learning variables through the solutions of a dynamic system. The resulting variational problem is then solved by using a gradient flow on a suitable, regularized functional. We forecast the epidemic evolution in Italy and France. Results indicate that the model provides reliable and challenging predictions over all available data as well as the fundamental role of the chosen strategy on the time-variant parameters.
Generative deep learning for decision making in gas networks
Feb 03, 2021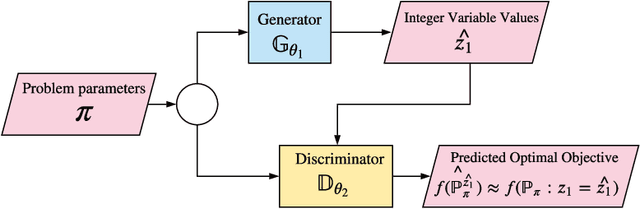
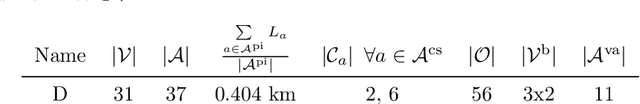
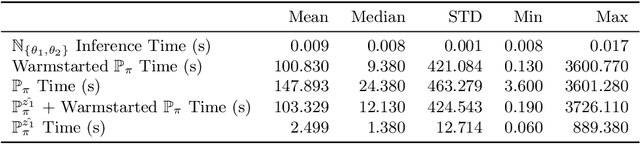
A decision support system relies on frequent re-solving of similar problem instances. While the general structure remains the same in corresponding applications, the input parameters are updated on a regular basis. We propose a generative neural network design for learning integer decision variables of mixed-integer linear programming (MILP) formulations of these problems. We utilise a deep neural network discriminator and a MILP solver as our oracle to train our generative neural network. In this article, we present the results of our design applied to the transient gas optimisation problem. With the trained network we produce a feasible solution in 2.5s, use it as a warm-start solution, and thereby decrease global optimal solution solve time by 60.5%.
Analyze the Effects of Weighting Functions on Cost Function in the Glove Model
Sep 10, 2020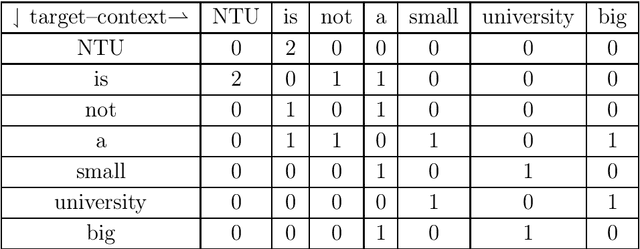
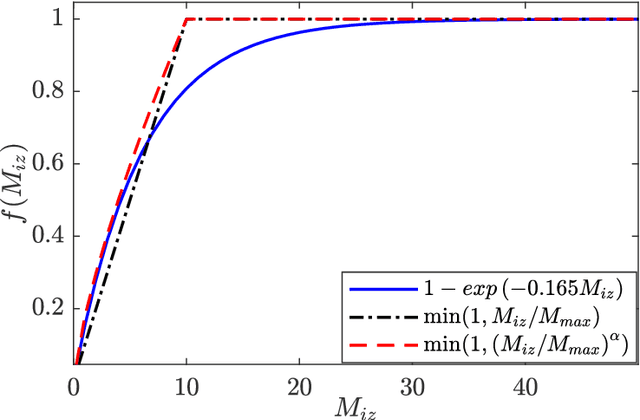
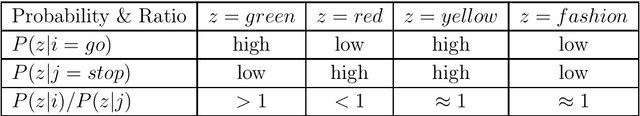
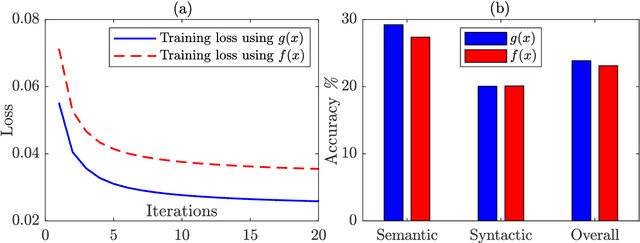
When dealing with the large vocabulary size and corpus size, the run-time for training Glove model is long, it can even be up to several dozen hours for data, which is approximately 500MB in size. As a result, finding and selecting the optimal parameters for the weighting function create many difficulties for weak hardware. Of course, to get the best results, we need to test benchmarks many times. In order to solve this problem, we derive a weighting function, which can save time for choosing parameters and making benchmarks. It also allows one to obtain nearly similar accuracy at the same given time without concern for experimentation.
Deep Learning-Based Arrhythmia Detection Using RR-Interval Framed Electrocardiograms
Dec 01, 2020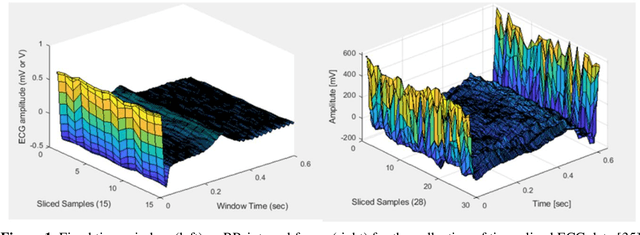
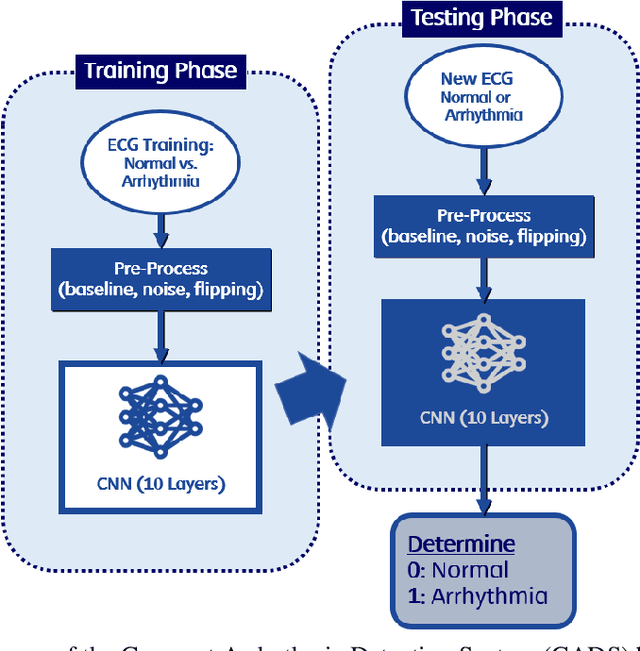
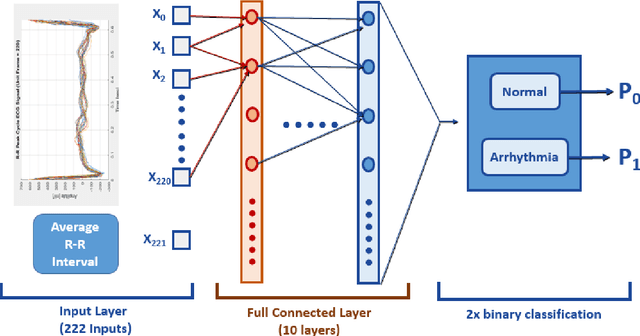
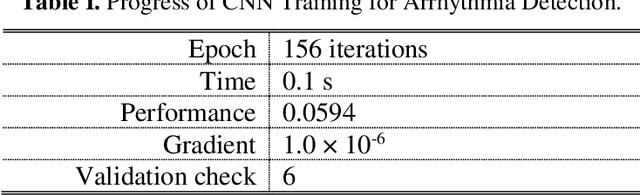
Deep learning applied to electrocardiogram (ECG) data can be used to achieve personal authentication in biometric security applications, but it has not been widely used to diagnose cardiovascular disorders. We developed a deep learning model for the detection of arrhythmia in which time-sliced ECG data representing the distance between successive R-peaks are used as the input for a convolutional neural network (CNN). The main objective is developing the compact deep learning based detect system which minimally uses the dataset but delivers the confident accuracy rate of the Arrhythmia detection. This compact system can be implemented in wearable devices or real-time monitoring equipment because the feature extraction step is not required for complex ECG waveforms, only the R-peak data is needed. The results of both tests indicated that the Compact Arrhythmia Detection System (CADS) matched the performance of conventional systems for the detection of arrhythmia in two consecutive test runs. All features of the CADS are fully implemented and publicly available in MATLAB.
Position-based Content Attention for Time Series Forecasting with Sequence-to-sequence RNNs
Aug 21, 2017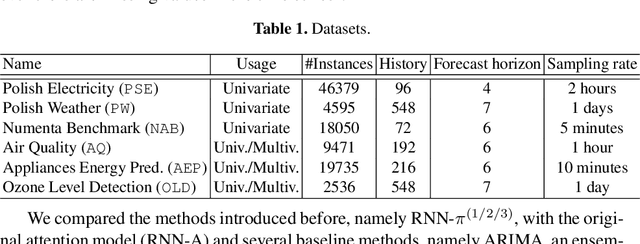
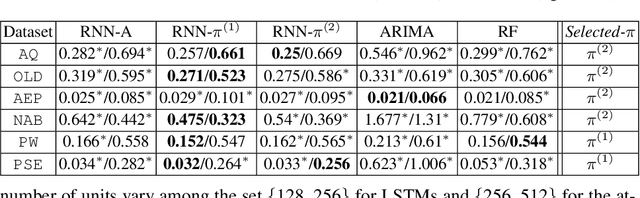
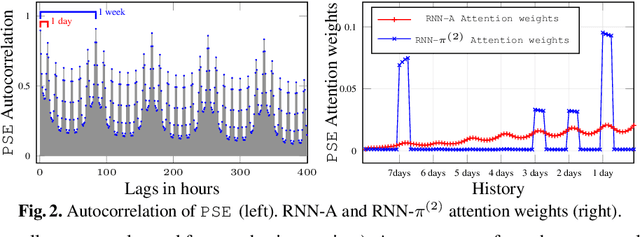
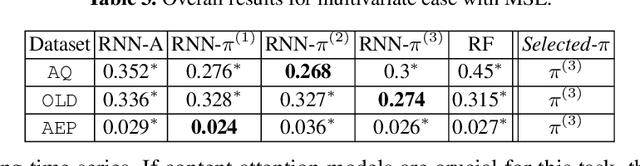
We propose here an extended attention model for sequence-to-sequence recurrent neural networks (RNNs) designed to capture (pseudo-)periods in time series. This extended attention model can be deployed on top of any RNN and is shown to yield state-of-the-art performance for time series forecasting on several univariate and multivariate time series.
DP-Image: Differential Privacy for Image Data in Feature Space
Mar 12, 2021
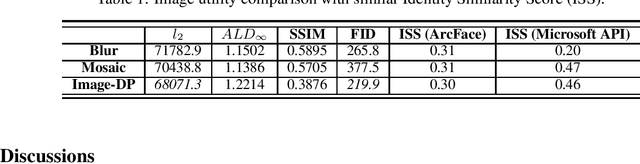
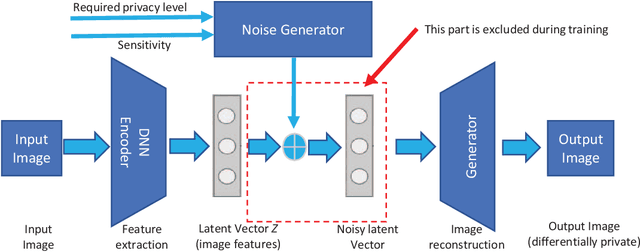
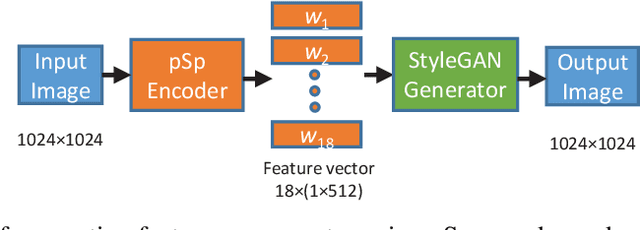
The excessive use of images in social networks, government databases, and industrial applications has posed great privacy risks and raised serious concerns from the public. Even though differential privacy (DP) is a widely accepted criterion that can provide a provable privacy guarantee, the application of DP on unstructured data such as images is not trivial due to the lack of a clear qualification on the meaningful difference between any two images. In this paper, for the first time, we introduce a novel notion of image-aware differential privacy, referred to as DP-image, that can protect user's personal information in images, from both human and AI adversaries. The DP-Image definition is formulated as an extended version of traditional differential privacy, considering the distance measurements between feature space vectors of images. Then we propose a mechanism to achieve DP-Image by adding noise to an image feature vector. Finally, we conduct experiments with a case study on face image privacy. Our results show that the proposed DP-Image method provides excellent DP protection on images, with a controllable distortion to faces.
Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
Jan 12, 2019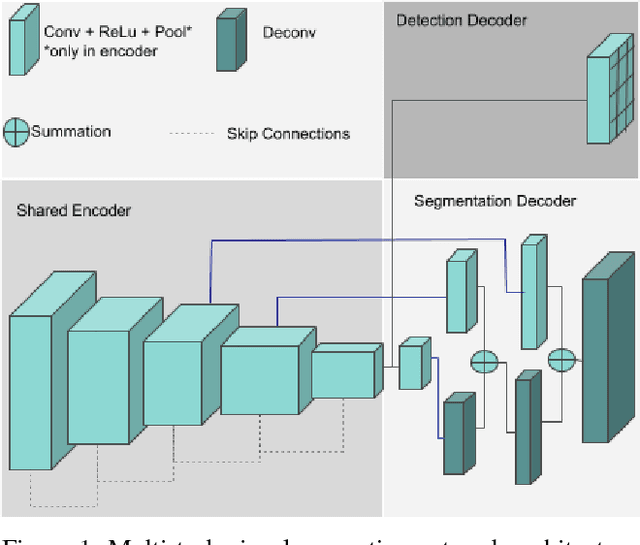
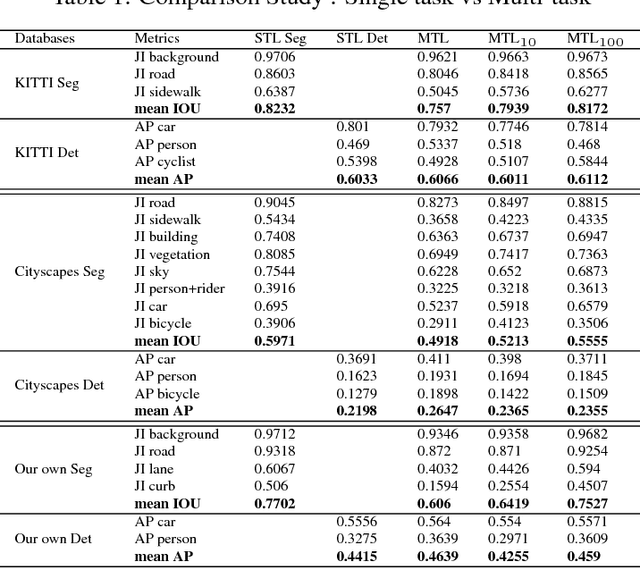

Convolutional Neural Networks (CNN) are successfully used for various visual perception tasks including bounding box object detection, semantic segmentation, optical flow, depth estimation and visual SLAM. Generally these tasks are independently explored and modeled. In this paper, we present a joint multi-task network design for learning object detection and semantic segmentation simultaneously. The main motivation is to achieve real-time performance on a low power embedded SOC by sharing of encoder for both the tasks. We construct an efficient architecture using a small ResNet10 like encoder which is shared for both decoders. Object detection uses YOLO v2 like decoder and semantic segmentation uses FCN8 like decoder. We evaluate the proposed network in two public datasets (KITTI, Cityscapes) and in our private fisheye camera dataset, and demonstrate that joint network provides the same accuracy as that of separate networks. We further optimize the network to achieve 30 fps for 1280x384 resolution image.
External Forces Resilient Safe Motion Planning for Quadrotor
Mar 20, 2021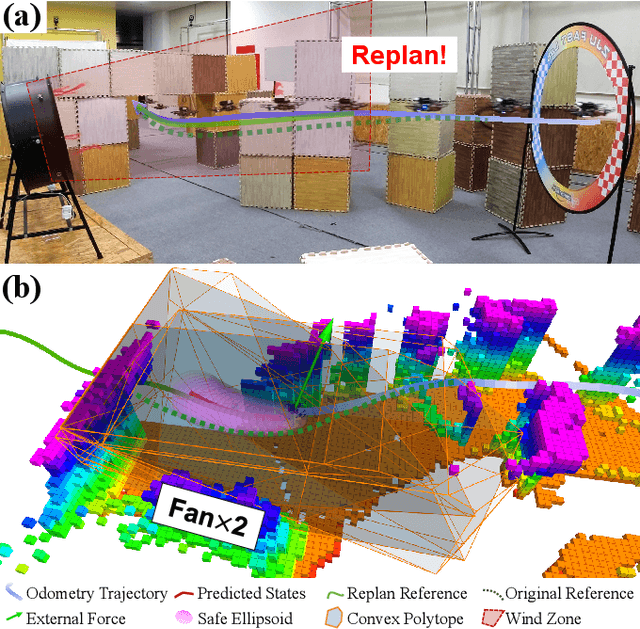
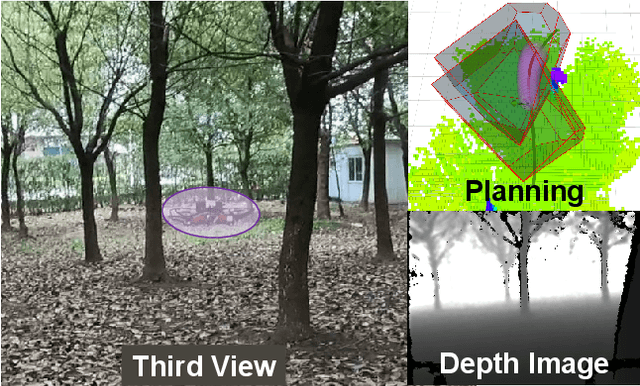
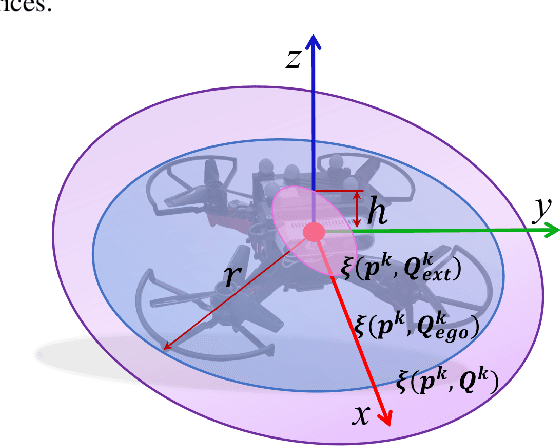
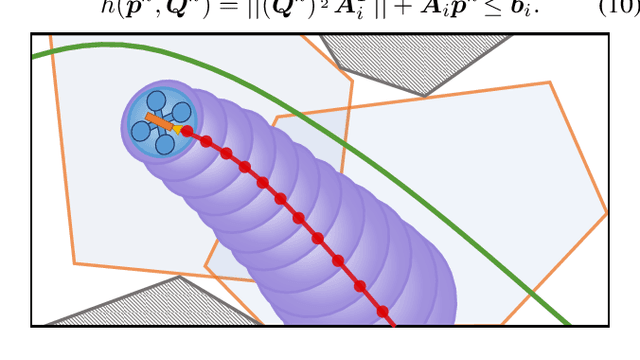
Adaptive autonomous navigation with no prior knowledge of extraneous disturbance is of great significance for quadrotors in a complex and unknown environment. The mainstream that considers external disturbance is to implement disturbance-rejected control and path tracking. However, the robust control to compensate for tracking deviations is not well-considered regarding energy consumption, and even the reference path will become risky and intractable with disturbance. As recent external forces estimation advances, it is possible to incorporate a real-time force estimator to develop more robust and safe planning frameworks. This paper proposes a systematic (re)planning framework that can resiliently generate safe trajectories under volatile conditions. Firstly, a front-end kinodynamic path is searched with force-biased motion primitives. Then we develop a nonlinear model predictive control (NMPC) as a local planner with Hamilton-Jacobi (HJ) forward reachability analysis for error dynamics caused by external forces. It guarantees collision-free by constraining the ellipsoid of the quadrotor body expanded with the forward reachable sets (FRSs) within safe convex polytopes. Our method is validated in simulations and real-world experiments with different sources of external forces.
Optimal Time-Series Motifs
May 03, 2015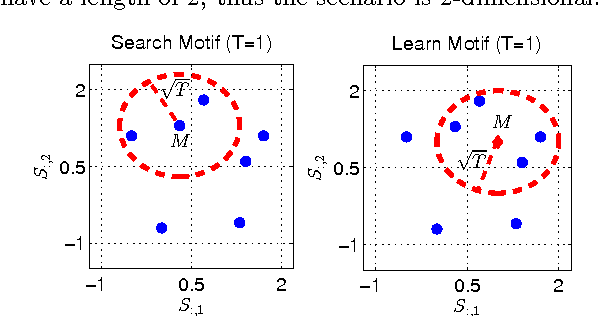
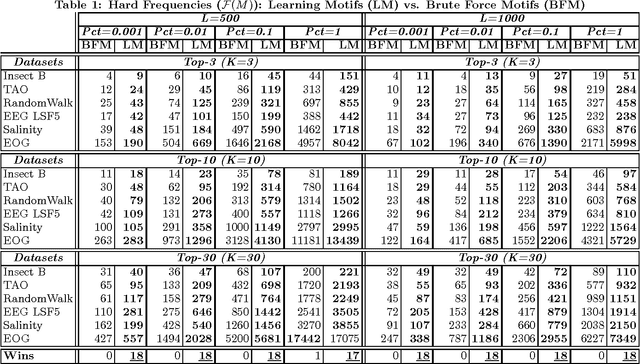
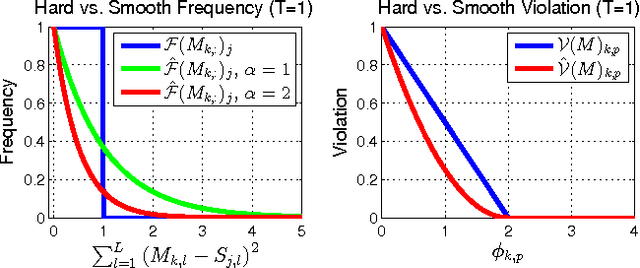
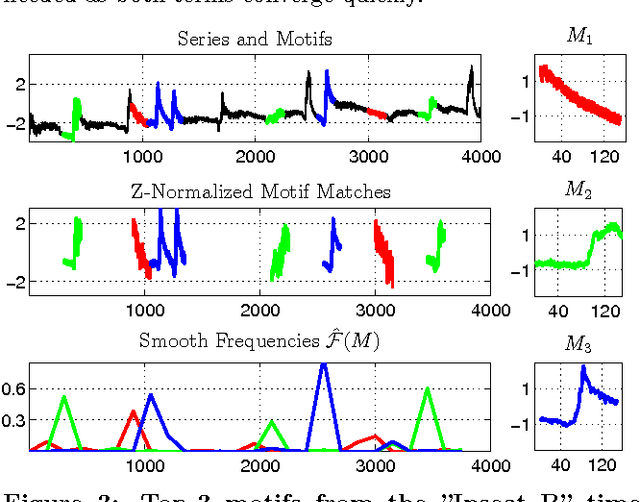
Motifs are the most repetitive/frequent patterns of a time-series. The discovery of motifs is crucial for practitioners in order to understand and interpret the phenomena occurring in sequential data. Currently, motifs are searched among series sub-sequences, aiming at selecting the most frequently occurring ones. Search-based methods, which try out series sub-sequence as motif candidates, are currently believed to be the best methods in finding the most frequent patterns. However, this paper proposes an entirely new perspective in finding motifs. We demonstrate that searching is non-optimal since the domain of motifs is restricted, and instead we propose a principled optimization approach able to find optimal motifs. We treat the occurrence frequency as a function and time-series motifs as its parameters, therefore we \textit{learn} the optimal motifs that maximize the frequency function. In contrast to searching, our method is able to discover the most repetitive patterns (hence optimal), even in cases where they do not explicitly occur as sub-sequences. Experiments on several real-life time-series datasets show that the motifs found by our method are highly more frequent than the ones found through searching, for exactly the same distance threshold.
Learning Continuous Cost-to-Go Functions for Non-holonomic Systems
Mar 20, 2021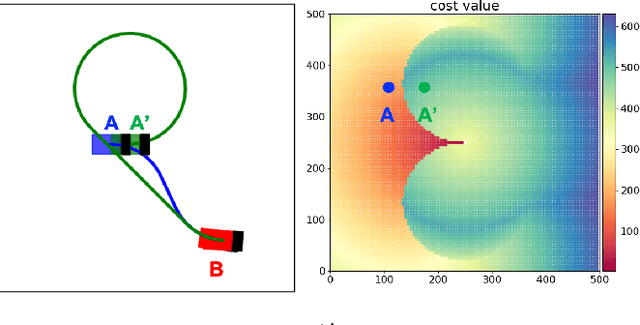

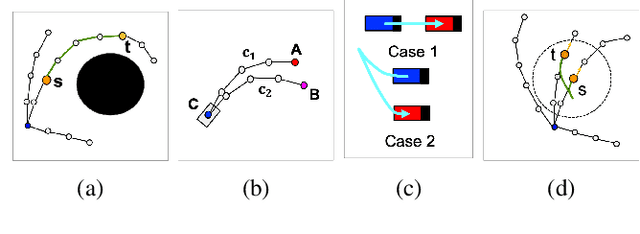
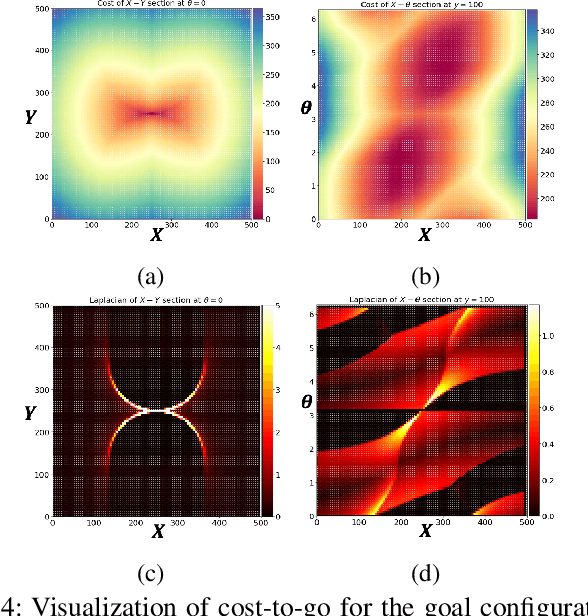
This paper presents a supervised learning method to generate continuous cost-to-go functions of non-holonomic systems directly from the workspace description. Supervision from informative examples reduces training time and improves network performance. The manifold representing the optimal trajectories of a non-holonomic system has high-curvature regions which can not be efficiently captured with uniform sampling. To address this challenge, we present an adaptive sampling method which makes use of sampling-based planners along with local, closed-form solutions to generate training samples. The cost-to-go function over a specific workspace is represented as a neural network whose weights are generated by a second, higher order network. The networks are trained in an end-to-end fashion. In our previous work, this architecture was shown to successfully learn to generate the cost-to-go functions of holonomic systems using uniform sampling. In this work, we show that uniform sampling fails for non-holonomic systems. However, with the proposed adaptive sampling methodology, our network can generate near-optimal trajectories for non-holonomic systems while avoiding obstacles. Experiments show that our method is two orders of magnitude faster compared to traditional approaches in cluttered environments.