 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Weight-Based Exploration for Unmanned Aerial Teams Searching for Multiple Survivors
Dec 21, 2020
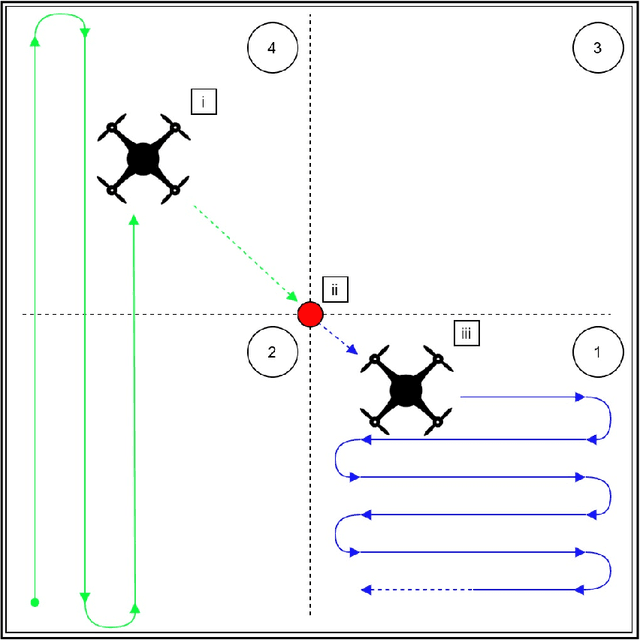
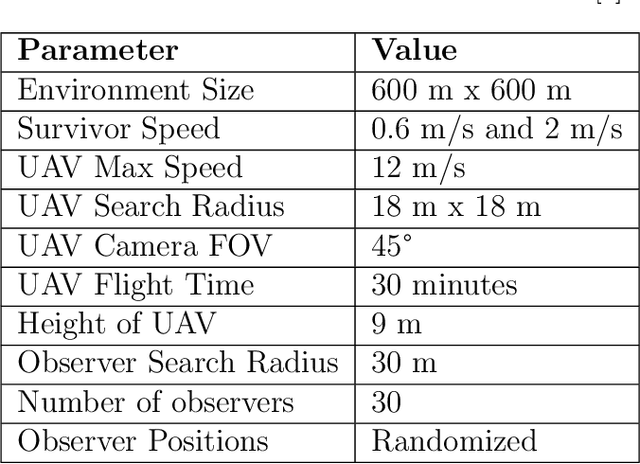
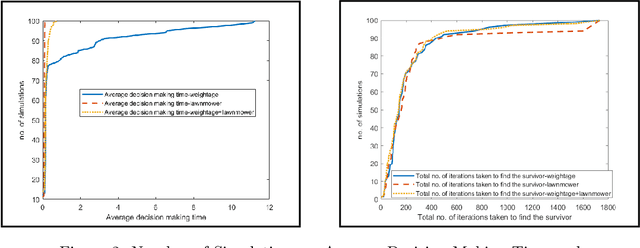
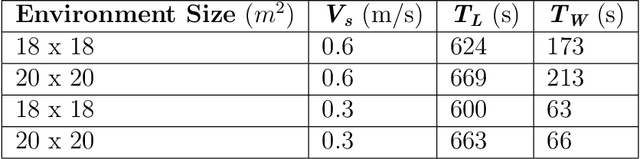
During floods, reaching survivors in the shortest possible time is a priority for rescue teams. Given their ability to explore difficult terrain in short spans of time, Unmanned Aerial Vehicles (UAVs) have become an increasingly valuable aid to search and rescue operations. Traditionally, UAVs utilize exhaustive lawnmower exploration patterns to locate stranded survivors, without any information regarding the survivor's whereabouts. In real life disaster scenarios however, on-ground observers provide valuable information to the rescue effort, such as the survivor's last known location and heading. In earlier work, a Weight Based Exploration (WBE) model, which utilizes this information to generate a prioritized list of waypoints to aid the UAV in its search mission, was proposed. This approach was shown to be effective for a single UAV locating a single survivor. In this paper, we extend the WBE model to a team of UAVs locating multiple survivors. The model initially partitions the search environment amongst the UAVs using Voronoi cells. The UAVs then utilize the WBE model to locate survivors in their partitions. We test this model with varying survivor locations and headings. We demonstrate the scalability of the model developed by testing the model with aerial teams comprising several UAVs.
Refinement Type Directed Search for Meta-Interpretive-Learning of Higher-Order Logic Programs
Feb 18, 2021


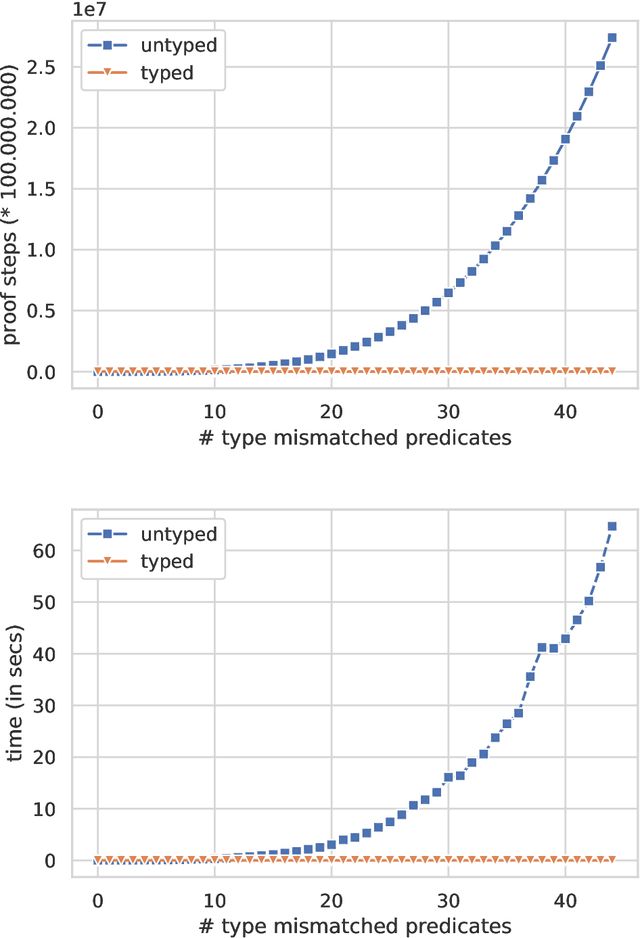
The program synthesis problem within the Inductive Logic Programming (ILP) community has typically been seen as untyped. We consider the benefits of user provided types on background knowledge. Building on the Meta-Interpretive Learning (MIL) framework, we show that type checking is able to prune large parts of the hypothesis space of programs. The introduction of polymorphic type checking to the MIL approach to logic program synthesis is validated by strong theoretical and experimental results, showing a cubic reduction in the size of the search space and synthesis time, in terms of the number of typed background predicates. Additionally we are able to infer polymorphic types of synthesized clauses and of entire programs. The other advancement is in developing an approach to leveraging refinement types in ILP. Here we show that further pruning of the search space can be achieved, though the SMT solving used for refinement type checking comes
Source Code Classification for Energy Efficiency in Parallel Ultra Low-Power Microcontrollers
Dec 12, 2020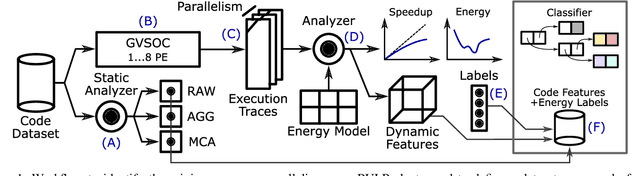
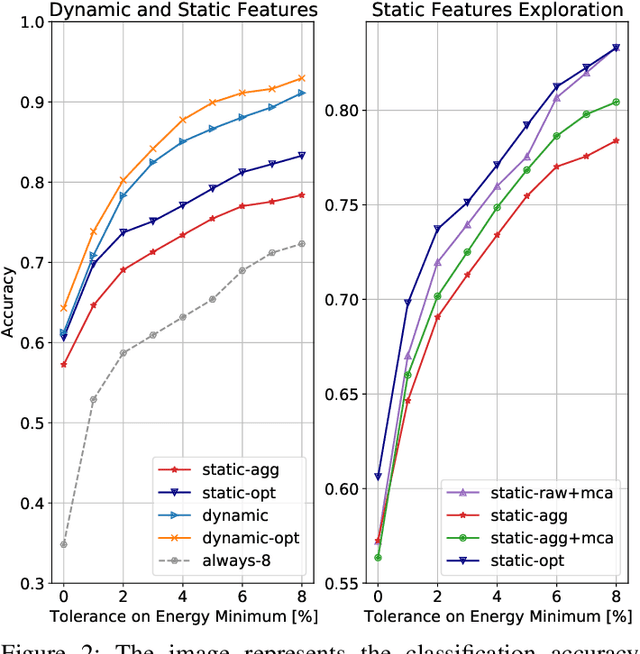
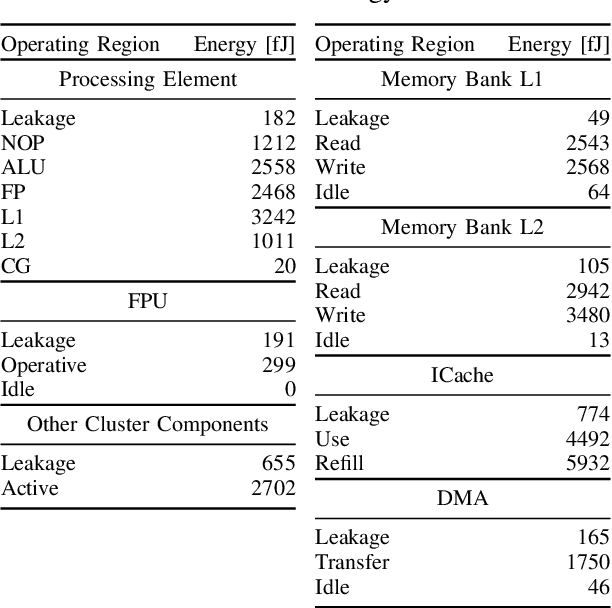

The analysis of source code through machine learning techniques is an increasingly explored research topic aiming at increasing smartness in the software toolchain to exploit modern architectures in the best possible way. In the case of low-power, parallel embedded architectures, this means finding the configuration, for instance in terms of the number of cores, leading to minimum energy consumption. Depending on the kernel to be executed, the energy optimal scaling configuration is not trivial. While recent work has focused on general-purpose systems to learn and predict the best execution target in terms of the execution time of a snippet of code or kernel (e.g. offload OpenCL kernel on multicore CPU or GPU), in this work we focus on static compile-time features to assess if they can be successfully used to predict the minimum energy configuration on PULP, an ultra-low-power architecture featuring an on-chip cluster of RISC-V processors. Experiments show that using machine learning models on the source code to select the best energy scaling configuration automatically is viable and has the potential to be used in the context of automatic system configuration for energy minimisation.
Efficient Solution of Boolean Satisfiability Problems with Digital MemComputing
Nov 12, 2020
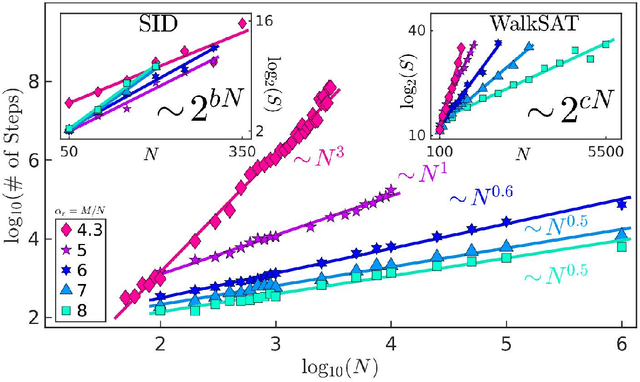
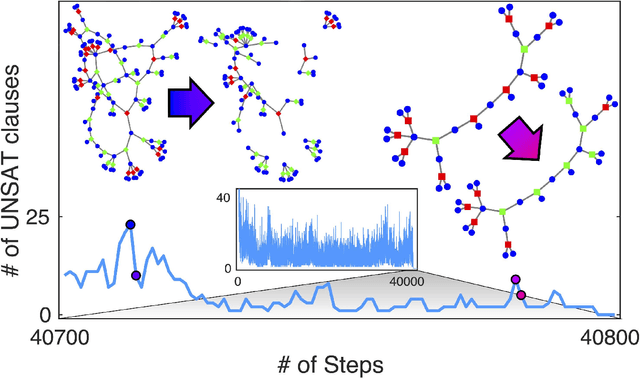
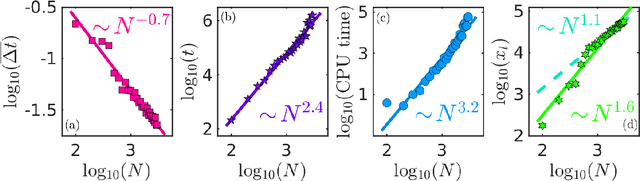
Boolean satisfiability is a propositional logic problem of interest in multiple fields, e.g., physics, mathematics, and computer science. Beyond a field of research, instances of the SAT problem, as it is known, require efficient solution methods in a variety of applications. It is the decision problem of determining whether a Boolean formula has a satisfying assignment, believed to require exponentially growing time for an algorithm to solve for the worst-case instances. Yet, the efficient solution of many classes of Boolean formulae eludes even the most successful algorithms, not only for the worst-case scenarios, but also for typical-case instances. Here, we introduce a memory-assisted physical system (a digital memcomputing machine) that, when its non-linear ordinary differential equations are integrated numerically, shows evidence for polynomially-bounded scalability while solving "hard" planted-solution instances of SAT, known to require exponential time to solve in the typical case for both complete and incomplete algorithms. Furthermore, we analytically demonstrate that the physical system can efficiently solve the SAT problem in continuous time, without the need to introduce chaos or an exponentially growing energy. The efficiency of the simulations is related to the collective dynamical properties of the original physical system that persist in the numerical integration to robustly guide the solution search even in the presence of numerical errors. We anticipate our results to broaden research directions in physics-inspired computing paradigms ranging from theory to application, from simulation to hardware implementation.
High Data Rate Near-Ultrasonic Communication with Consumer Devices
Mar 20, 2021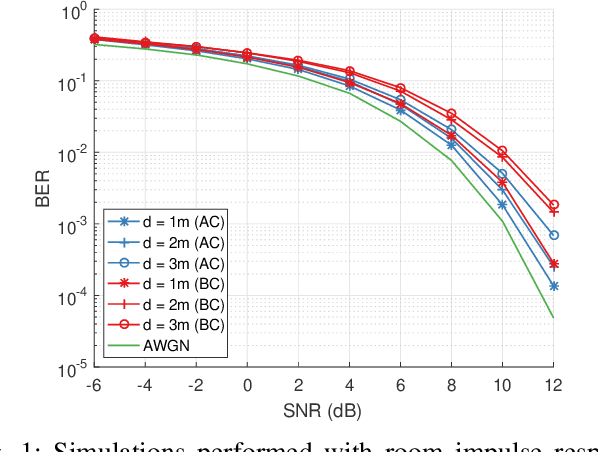
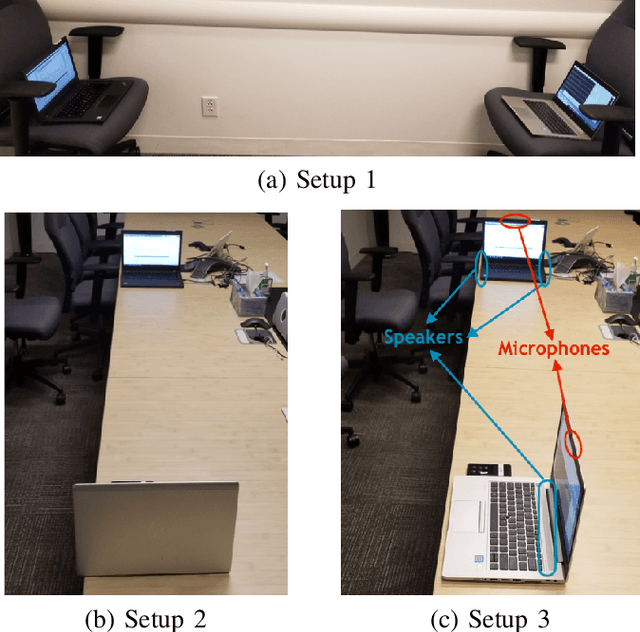
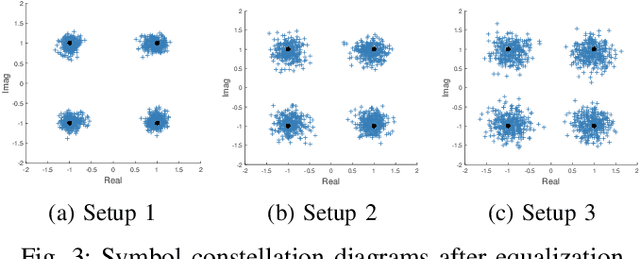
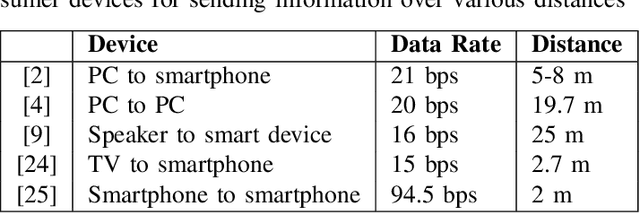
Automating device pairing and credential exchange in consumer devices reduce the time users spend with mundane tasks and improve the user experience. Acoustic communication is gaining traction as a practical alternative to Bluetooth or Wi-Fi because it can enable quick and localized information transfer between consumer devices with built-in hardware. However, achieving high data rates (>1 kbps) in such systems has been a challenge because the systems and methods chosen for communication were not tailored to the application. In this work, a high data rate, near-ultrasonic communication (NUSC) system is proposed to transfer personal identification numbers (PINs) to establish a connection between consumer laptops using built-in microphones and speakers. The similarities between indoor near-ultrasonic and underwater acoustic communication (UWAC) channels are identified, and appropriate UWAC techniques are tailored to the NUSC system. The proposed system uses the near-ultrasonic band at 18-20 kHz, and employs coherent modulation and phase-coherent adaptive equalization. The capability of the proposed system is explored in simulated and field experiments that span different device orientations and distances. The experiments demonstrate data rates of 4 kbps over distances of up to 5 meters, which is an order of magnitude higher than the data rates reported with similar systems in the literature.
Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
Mar 04, 2021
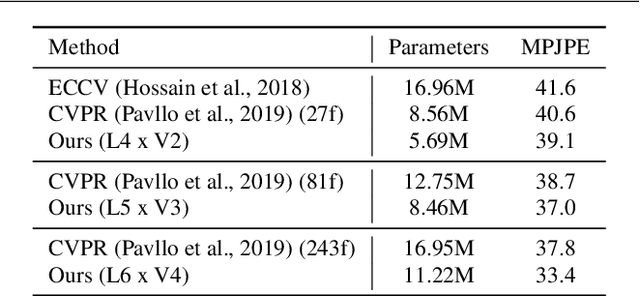
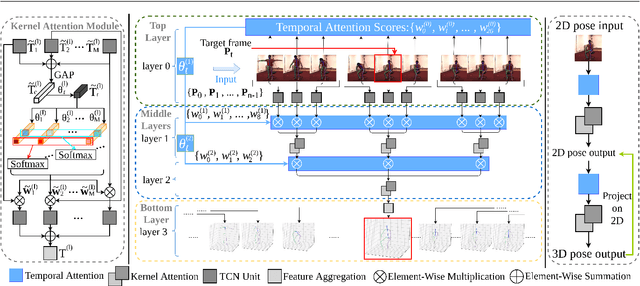
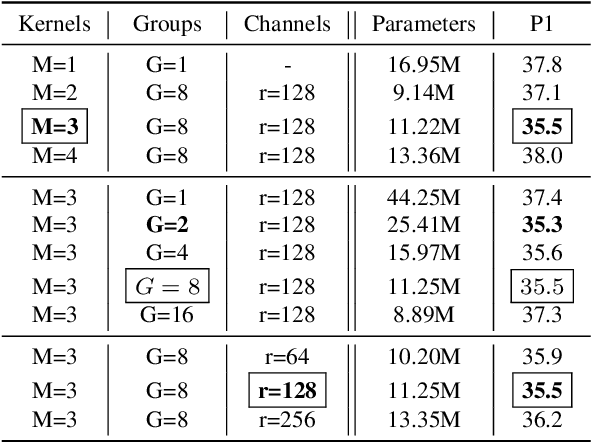
The attention mechanism provides a sequential prediction framework for learning spatial models with enhanced implicit temporal consistency. In this work, we show a systematic design (from 2D to 3D) for how conventional networks and other forms of constraints can be incorporated into the attention framework for learning long-range dependencies for the task of pose estimation. The contribution of this paper is to provide a systematic approach for designing and training of attention-based models for the end-to-end pose estimation, with the flexibility and scalability of arbitrary video sequences as input. We achieve this by adapting temporal receptive field via a multi-scale structure of dilated convolutions. Besides, the proposed architecture can be easily adapted to a causal model enabling real-time performance. Any off-the-shelf 2D pose estimation systems, e.g. Mocap libraries, can be easily integrated in an ad-hoc fashion. Our method achieves the state-of-the-art performance and outperforms existing methods by reducing the mean per joint position error to 33.4 mm on Human3.6M dataset.
Restless-UCB, an Efficient and Low-complexity Algorithm for Online Restless Bandits
Nov 05, 2020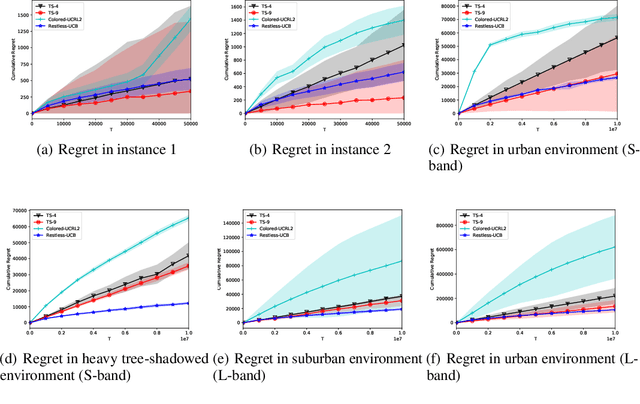
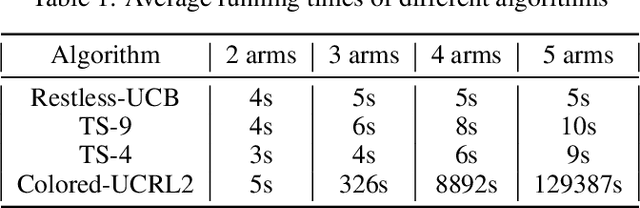
We study the online restless bandit problem, where the state of each arm evolves according to a Markov chain, and the reward of pulling an arm depends on both the pulled arm and the current state of the corresponding Markov chain. In this paper, we propose Restless-UCB, a learning policy that follows the explore-then-commit framework. In Restless-UCB, we present a novel method to construct offline instances, which only requires $O(N)$ time-complexity ($N$ is the number of arms) and is exponentially better than the complexity of existing learning policy. We also prove that Restless-UCB achieves a regret upper bound of $\tilde{O}((N+M^3)T^{2\over 3})$, where $M$ is the Markov chain state space size and $T$ is the time horizon. Compared to existing algorithms, our result eliminates the exponential factor (in $M,N$) in the regret upper bound, due to a novel exploitation of the sparsity in transitions in general restless bandit problems. As a result, our analysis technique can also be adopted to tighten the regret bounds of existing algorithms. Finally, we conduct experiments based on real-world dataset, to compare the Restless-UCB policy with state-of-the-art benchmarks. Our results show that Restless-UCB outperforms existing algorithms in regret, and significantly reduces the running time.
Hybrid Deep Neural Networks to Infer State Models of Black-Box Systems
Aug 26, 2020
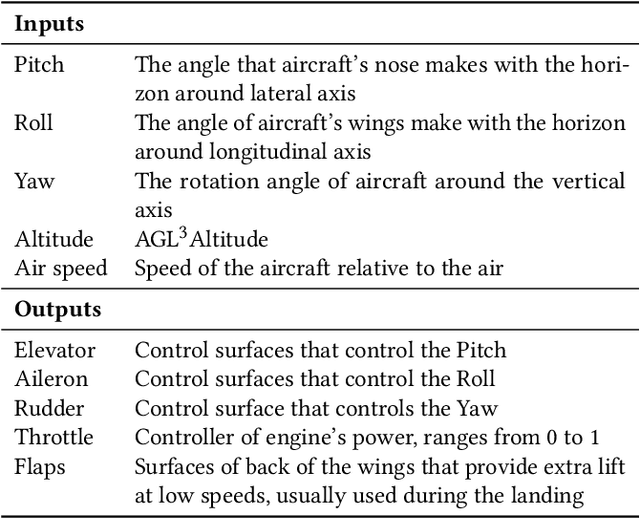

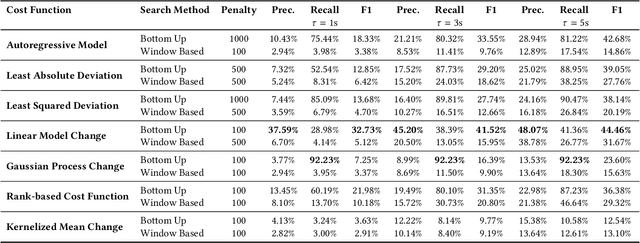
Inferring behavior model of a running software system is quite useful for several automated software engineering tasks, such as program comprehension, anomaly detection, and testing. Most existing dynamic model inference techniques are white-box, i.e., they require source code to be instrumented to get run-time traces. However, in many systems, instrumenting the entire source code is not possible (e.g., when using black-box third-party libraries) or might be very costly. Unfortunately, most black-box techniques that detect states over time are either univariate, or make assumptions on the data distribution, or have limited power for learning over a long period of past behavior. To overcome the above issues, in this paper, we propose a hybrid deep neural network that accepts as input a set of time series, one per input/output signal of the system, and applies a set of convolutional and recurrent layers to learn the non-linear correlations between signals and the patterns, over time. We have applied our approach on a real UAV auto-pilot solution from our industry partner with half a million lines of C code. We ran 888 random recent system-level test cases and inferred states, over time. Our comparison with several traditional time series change point detection techniques showed that our approach improves their performance by up to 102%, in terms of finding state change points, measured by F1 score. We also showed that our state classification algorithm provides on average 90.45% F1 score, which improves traditional classification algorithms by up to 17%.
ELMo and BERT in semantic change detection for Russian
Oct 07, 2020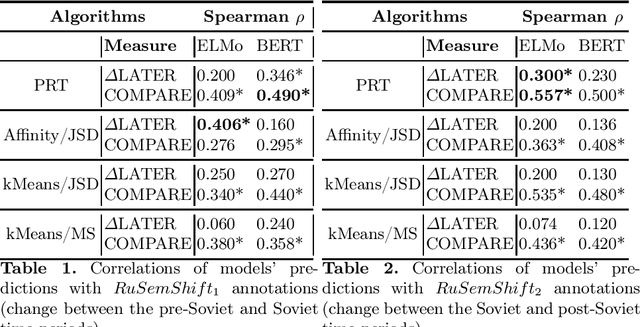
We study the effectiveness of contextualized embeddings for the task of diachronic semantic change detection for Russian language data. Evaluation test sets consist of Russian nouns and adjectives annotated based on their occurrences in texts created in pre-Soviet, Soviet and post-Soviet time periods. ELMo and BERT architectures are compared on the task of ranking Russian words according to the degree of their semantic change over time. We use several methods for aggregation of contextualized embeddings from these architectures and evaluate their performance. Finally, we compare unsupervised and supervised techniques in this task.
The Variational Bayesian Inference for Network Autoregression Models
Feb 18, 2021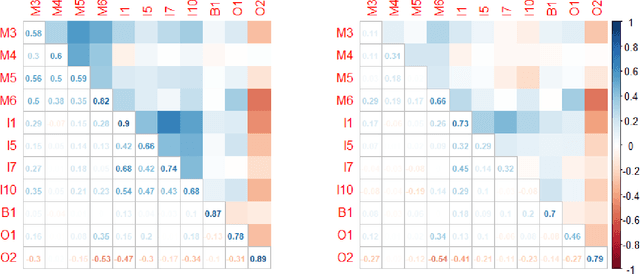
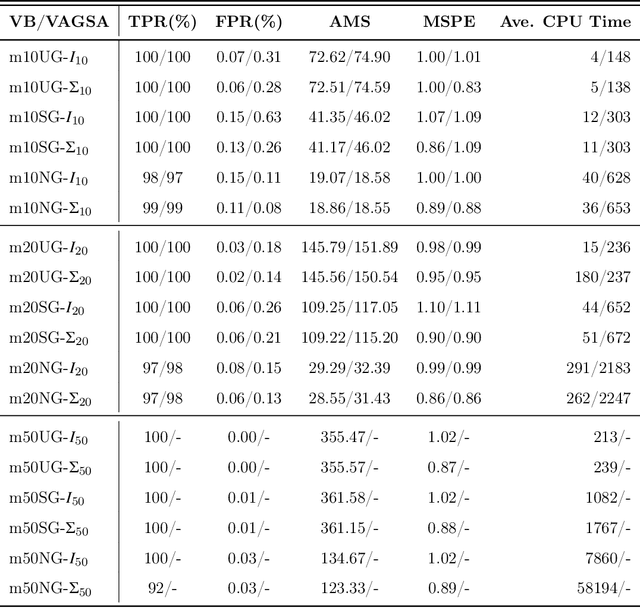
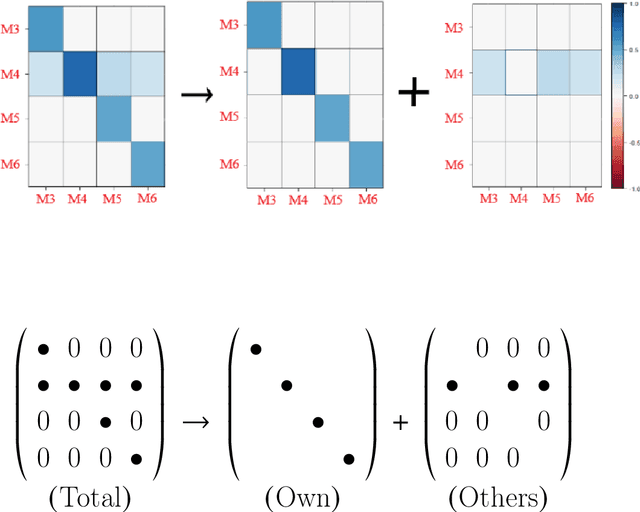
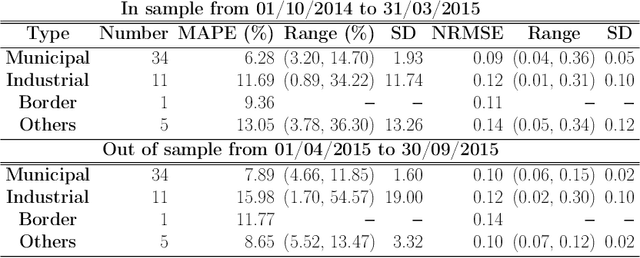
We develop a variational Bayesian (VB) approach for estimating large-scale dynamic network models in the network autoregression framework. The VB approach allows for the automatic identification of the dynamic structure of such a model and obtains a direct approximation of the posterior density. Compared to Markov Chain Monte Carlo (MCMC) based sampling approaches, the VB approach achieves enhanced computational efficiency without sacrificing estimation accuracy. In the simulation study conducted here, the proposed VB approach detects various types of proper active structures for dynamic network models. Compared to the alternative approach, the proposed method achieves similar or better accuracy, and its computational time is halved. In a real data analysis scenario of day-ahead natural gas flow prediction in the German gas transmission network with 51 nodes between October 2013 and September 2015, the VB approach delivers promising forecasting accuracy along with clearly detected structures in terms of dynamic dependence.