 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Learning language variations in news corpora through differential embeddings
Nov 13, 2020




There is an increasing interest in the NLP community in capturing variations in the usage of language, either through time (i.e., semantic drift), across regions (as dialects or variants) or in different social contexts (i.e., professional or media technolects). Several successful dynamical embeddings have been proposed that can track semantic change through time. Here we show that a model with a central word representation and a slice-dependent contribution can learn word embeddings from different corpora simultaneously. This model is based on a star-like representation of the slices. We apply it to The New York Times and The Guardian newspapers, and we show that it can capture both temporal dynamics in the yearly slices of each corpus, and language variations between US and UK English in a curated multi-source corpus. We provide an extensive evaluation of this methodology.
A Cognitive Approach based on the Actionable Knowledge Graph for supporting Maintenance Operations
Nov 18, 2020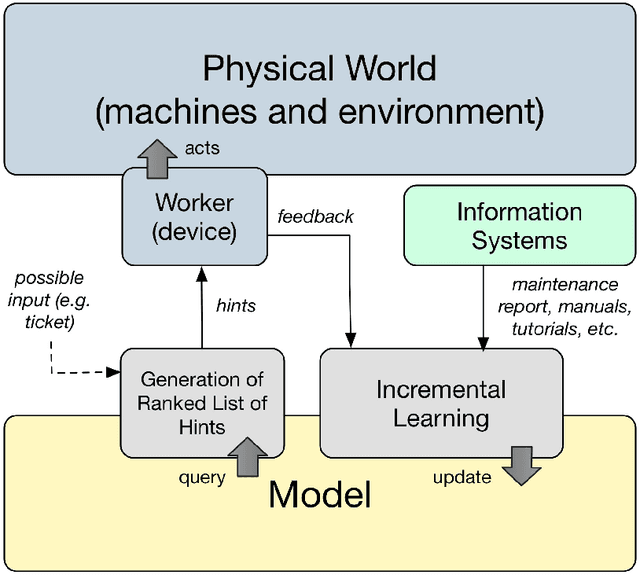
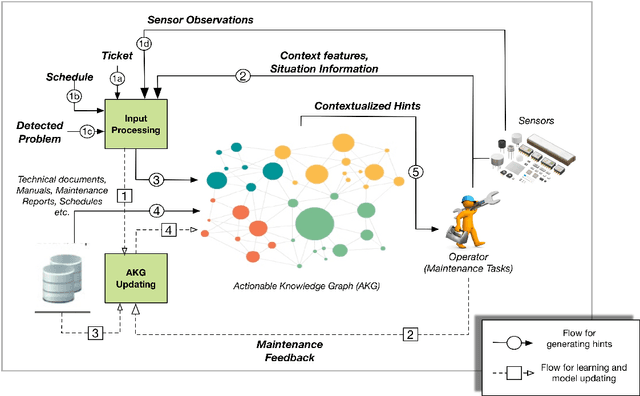
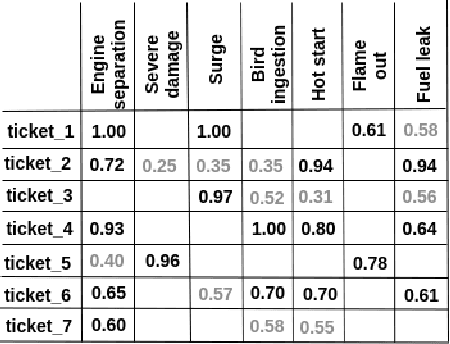
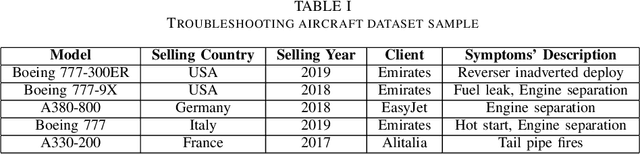
In the era of Industry 4.0, cognitive computing and its enabling technologies (Artificial Intelligence, Machine Learning, etc.) allow to define systems able to support maintenance by providing relevant information, at the right time, retrieved from structured companies' databases, and unstructured documents, like technical manuals, intervention reports, and so on. Moreover, contextual information plays a crucial role in tailoring the support both during the planning and the execution of interventions. Contextual information can be detected with the help of sensors, wearable devices, indoor and outdoor positioning systems, and object recognition capabilities (using fixed or wearable cameras), all of which can collect historical data for further analysis. In this work, we propose a cognitive system that learns from past interventions to generate contextual recommendations for improving maintenance practices in terms of time, budget, and scope. The system uses formal conceptual models, incremental learning, and ranking algorithms to accomplish these objectives.
Optimising the Performance of Convolutional Neural Networks across Computing Systems using Transfer Learning
Oct 20, 2020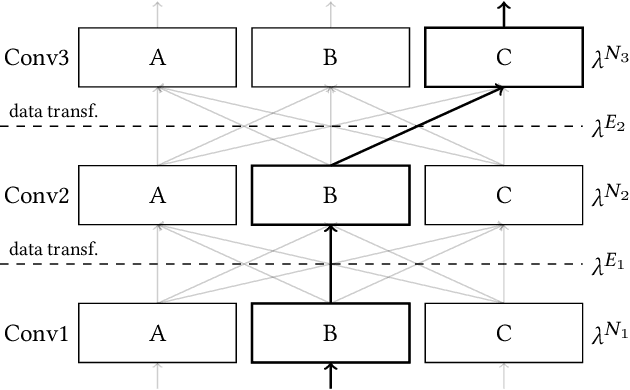
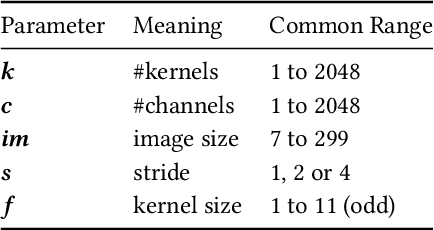
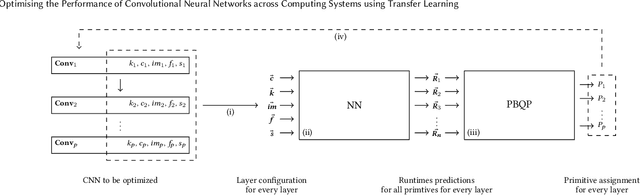

The choice of convolutional routines (primitives) to implement neural networks has a tremendous impact on their inference performance (execution speed) on a given hardware platform. To optimise a neural network by primitive selection, the optimal primitive is identified for each layer of the network. This process requires a lengthy profiling stage, iterating over all the available primitives for each layer configuration, to measure their execution time on the target platform. Because each primitive exploits the hardware in different ways, new profiling is needed to obtain the best performance when moving to another platform. In this work, we propose to replace this prohibitively expensive profiling stage with a machine learning based approach of performance modeling. Our approach speeds up the optimisation time drastically. After training, our performance model can estimate the performance of convolutional primitives in any layer configuration. The time to optimise the execution of large neural networks via primitive selection is reduced from hours to just seconds. Our performance model is easily transferable to other target platforms. We demonstrate this by training a performance model on an Intel platform and performing transfer learning to AMD and ARM processor devices with minimal profiled samples.
Enhanced 3D Human Pose Estimation from Videos by using Attention-Based Neural Network with Dilated Convolutions
Mar 04, 2021
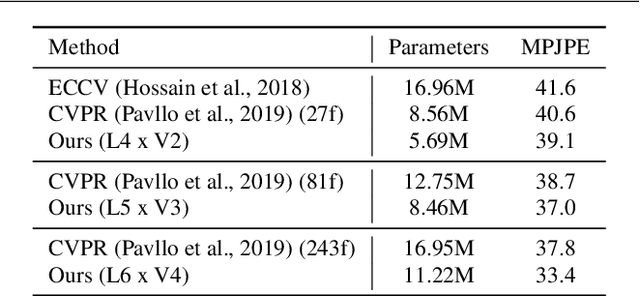
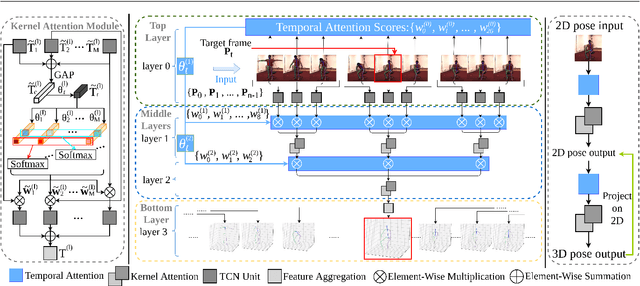
The attention mechanism provides a sequential prediction framework for learning spatial models with enhanced implicit temporal consistency. In this work, we show a systematic design (from 2D to 3D) for how conventional networks and other forms of constraints can be incorporated into the attention framework for learning long-range dependencies for the task of pose estimation. The contribution of this paper is to provide a systematic approach for designing and training of attention-based models for the end-to-end pose estimation, with the flexibility and scalability of arbitrary video sequences as input. We achieve this by adapting temporal receptive field via a multi-scale structure of dilated convolutions. Besides, the proposed architecture can be easily adapted to a causal model enabling real-time performance. Any off-the-shelf 2D pose estimation systems, e.g. Mocap libraries, can be easily integrated in an ad-hoc fashion. Our method achieves the state-of-the-art performance and outperforms existing methods by reducing the mean per joint position error to 33.4 mm on Human3.6M dataset.
Refinement Type Directed Search for Meta-Interpretive-Learning of Higher-Order Logic Programs
Feb 18, 2021


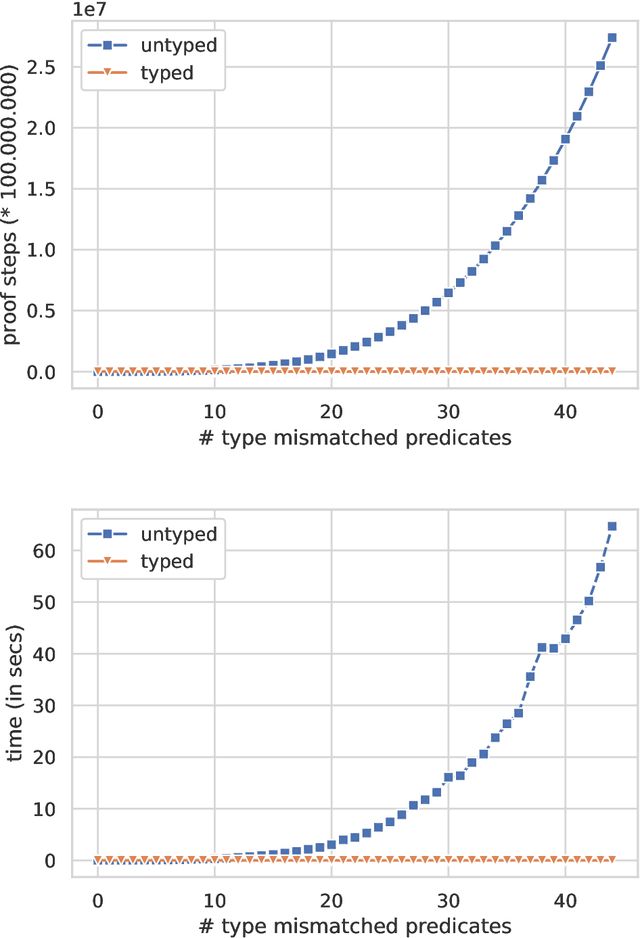
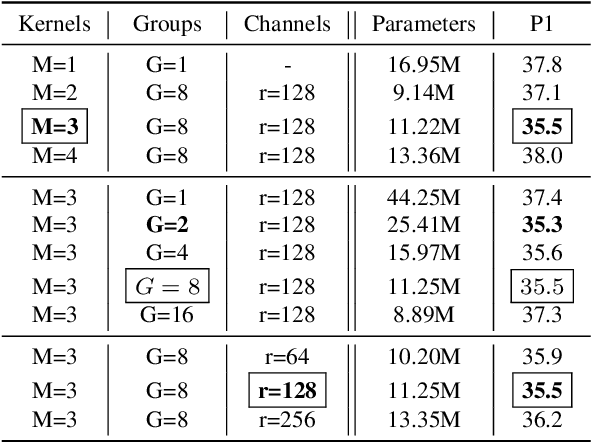
The program synthesis problem within the Inductive Logic Programming (ILP) community has typically been seen as untyped. We consider the benefits of user provided types on background knowledge. Building on the Meta-Interpretive Learning (MIL) framework, we show that type checking is able to prune large parts of the hypothesis space of programs. The introduction of polymorphic type checking to the MIL approach to logic program synthesis is validated by strong theoretical and experimental results, showing a cubic reduction in the size of the search space and synthesis time, in terms of the number of typed background predicates. Additionally we are able to infer polymorphic types of synthesized clauses and of entire programs. The other advancement is in developing an approach to leveraging refinement types in ILP. Here we show that further pruning of the search space can be achieved, though the SMT solving used for refinement type checking comes
Assessing the effect of advertising expenditures upon sales: a Bayesian structural time series model
Apr 23, 2018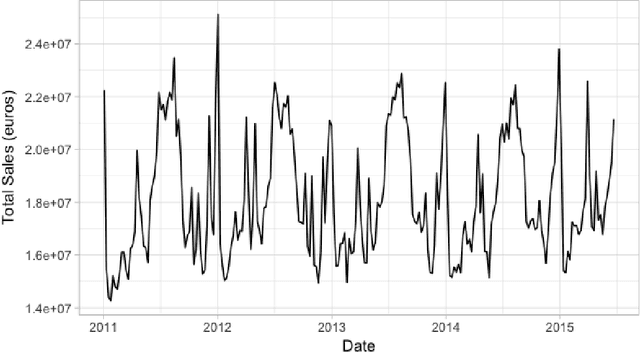
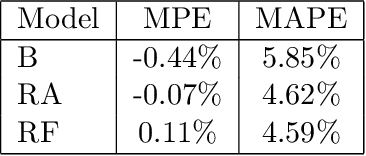
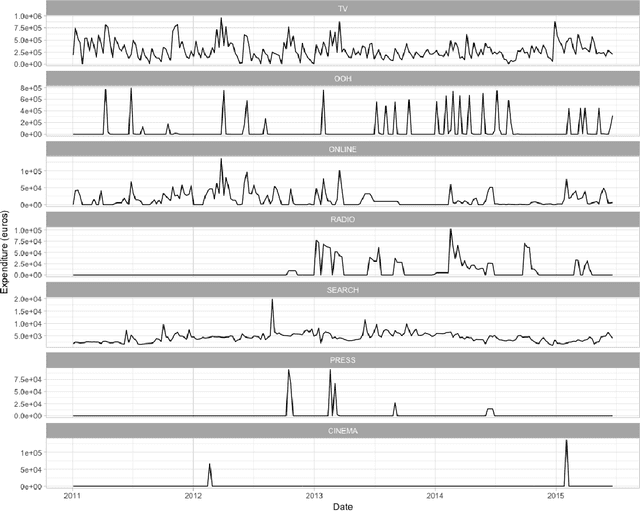
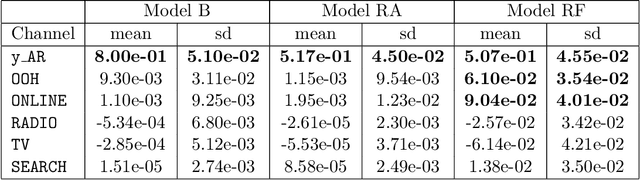
We propose a robust implementation of the Nerlove--Arrow model using a Bayesian structural time series model to explain the relationship between advertising expenditures of a country-wide fast-food franchise network with its weekly sales. Thanks to the flexibility and modularity of the model, it is well suited to generalization to other markets or situations. Its Bayesian nature facilitates incorporating \emph{a priori} information (the manager's views), which can be updated with relevant data. This aspect of the model will be used to present a strategy of budget scheduling across time and channels.
Demystifying the Effects of Non-Independence in Federated Learning
Mar 20, 2021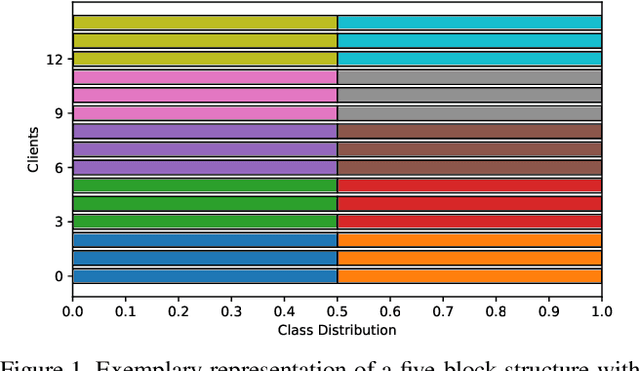
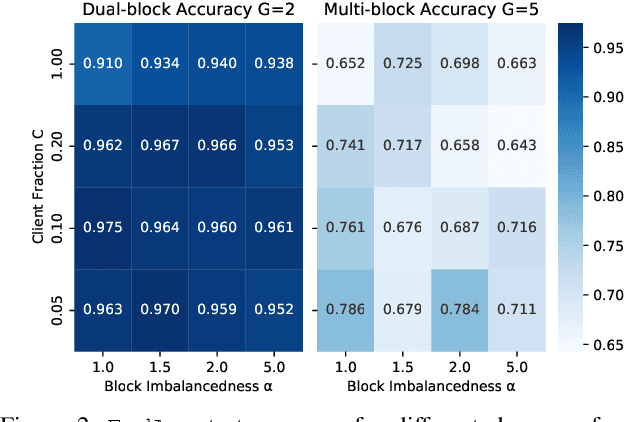
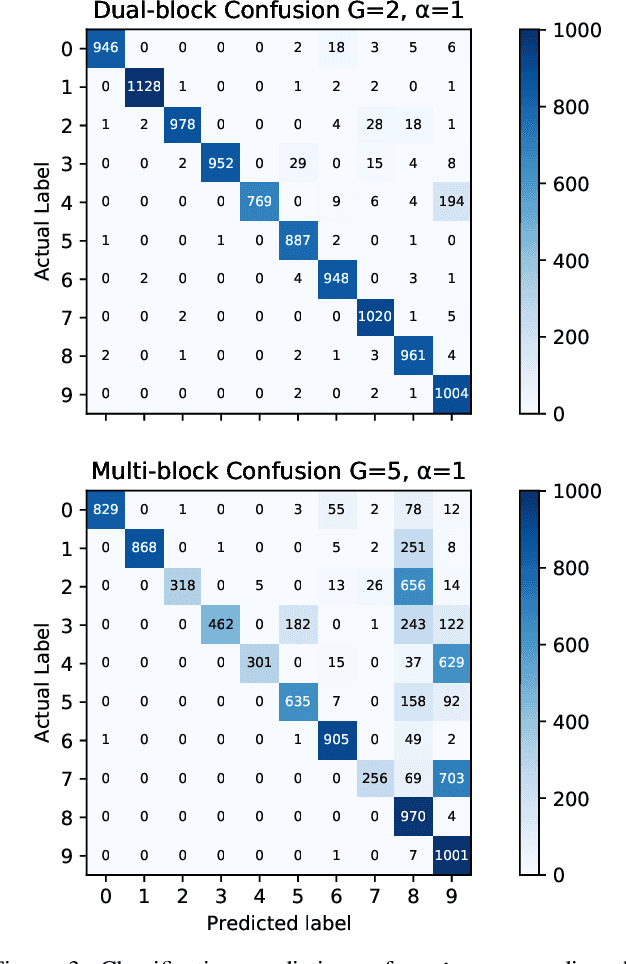
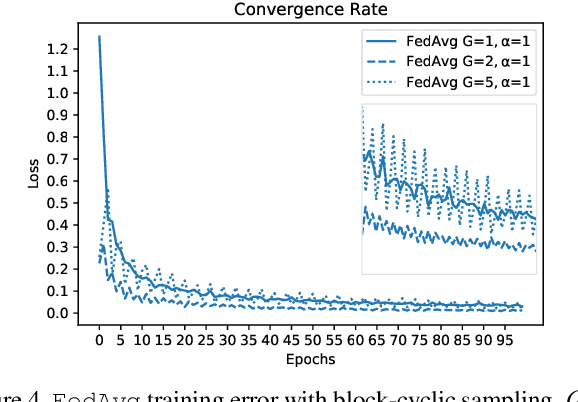
Federated Learning (FL) enables statistical models to be built on user-generated data without compromising data security and user privacy. For this reason, FL is well suited for on-device learning from mobile devices where data is abundant and highly privatized. Constrained by the temporal availability of mobile devices, only a subset of devices is accessible to participate in the iterative protocol consisting of training and aggregation. In this study, we take a step toward better understanding the effect of non-independent data distributions arising from block-cyclic sampling. By conducting extensive experiments on visual classification, we measure the effects of block-cyclic sampling (both standalone and in combination with non-balanced block distributions). Specifically, we measure the alterations induced by block-cyclic sampling from the perspective of accuracy, fairness, and convergence rate. Experimental results indicate robustness to cycling over a two-block structure, e.g., due to time zones. In contrast, drawing data samples dependently from a multi-block structure significantly degrades the performance and rate of convergence by up to 26%. Moreover, we find that this performance degeneration is further aggravated by unbalanced block distributions to a point that can no longer be adequately compensated by higher communication and more frequent synchronization.
Estimating causal effects of time-dependent exposures on a binary endpoint in a high-dimensional setting
Mar 29, 2018
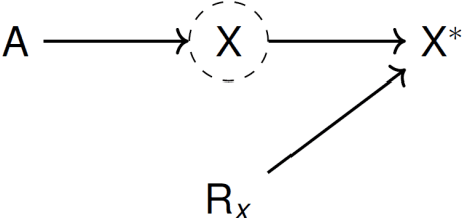
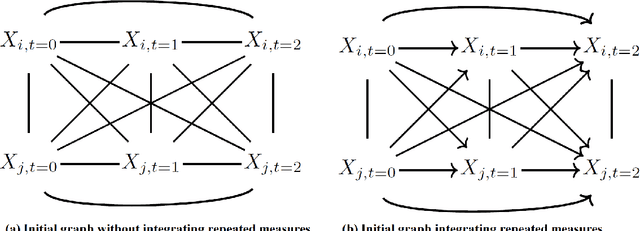
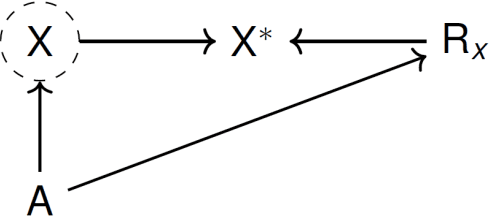
Recently, the intervention calculus when the DAG is absent (IDA) method was developed to estimate lower bounds of causal effects from observational high-dimensional data. Originally it was introduced to assess the effect of baseline biomarkers which do not vary over time. However, in many clinical settings, measurements of biomarkers are repeated at fixed time points during treatment exposure and, therefore, this method need to be extended. The purpose of this paper is then to extend the first step of the IDA, the Peter Clarks (PC)-algorithm, to a time-dependent exposure in the context of a binary outcome. We generalised the PC-algorithm for taking into account the chronological order of repeated measurements of the exposure and propose to apply the IDA with our new version, the chronologically ordered PC-algorithm (COPC-algorithm). A simulation study has been performed before applying the method for estimating causal effects of time-dependent immunological biomarkers on toxicity, death and progression in patients with metastatic melanoma. The simulation study showed that the completed partially directed acyclic graphs (CPDAGs) obtained using COPC-algorithm were structurally closer to the true CPDAG than CPDAGs obtained using PC-algorithm. Also, causal effects were more accurate when they were estimated based on CPDAGs obtained using COPC-algorithm. Moreover, CPDAGs obtained by COPC-algorithm allowed removing non-chronologic arrows with a variable measured at a time t pointing to a variable measured at a time t' where t'< t. Bidirected edges were less present in CPDAGs obtained with the COPC-algorithm, supporting the fact that there was less variability in causal effects estimated from these CPDAGs. The COPC-algorithm provided CPDAGs that keep the chronological structure present in the data, thus allowed to estimate lower bounds of the causal effect of time-dependent biomarkers.
Weight-Based Exploration for Unmanned Aerial Teams Searching for Multiple Survivors
Dec 21, 2020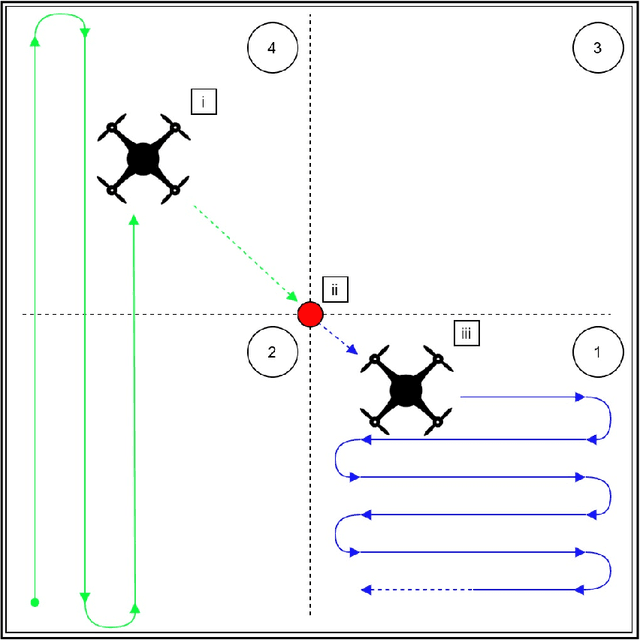
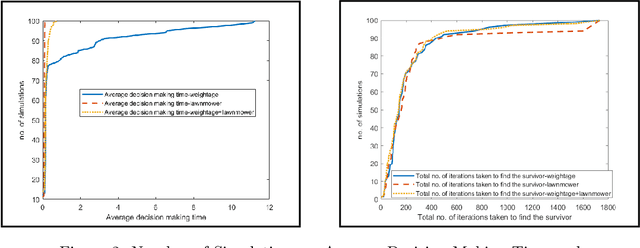
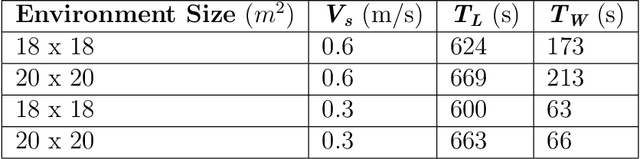
During floods, reaching survivors in the shortest possible time is a priority for rescue teams. Given their ability to explore difficult terrain in short spans of time, Unmanned Aerial Vehicles (UAVs) have become an increasingly valuable aid to search and rescue operations. Traditionally, UAVs utilize exhaustive lawnmower exploration patterns to locate stranded survivors, without any information regarding the survivor's whereabouts. In real life disaster scenarios however, on-ground observers provide valuable information to the rescue effort, such as the survivor's last known location and heading. In earlier work, a Weight Based Exploration (WBE) model, which utilizes this information to generate a prioritized list of waypoints to aid the UAV in its search mission, was proposed. This approach was shown to be effective for a single UAV locating a single survivor. In this paper, we extend the WBE model to a team of UAVs locating multiple survivors. The model initially partitions the search environment amongst the UAVs using Voronoi cells. The UAVs then utilize the WBE model to locate survivors in their partitions. We test this model with varying survivor locations and headings. We demonstrate the scalability of the model developed by testing the model with aerial teams comprising several UAVs.
Removing Pixel Noises and Spatial Artifacts with Generative Diversity Denoising Methods
Apr 03, 2021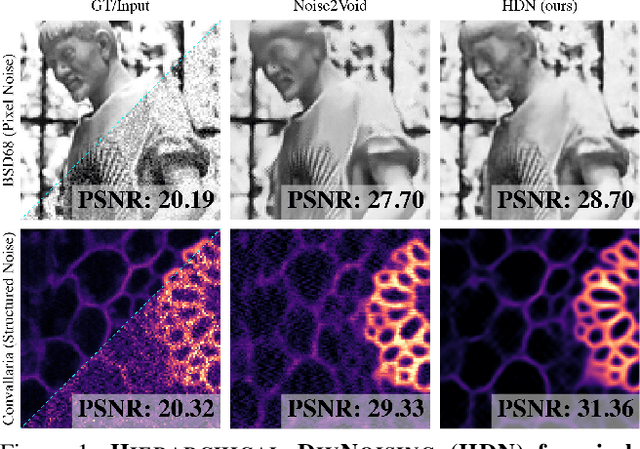
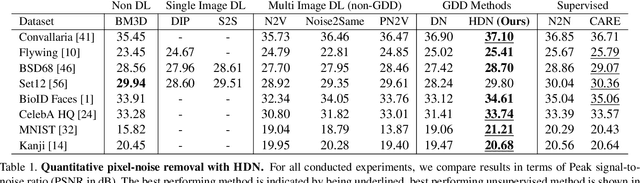
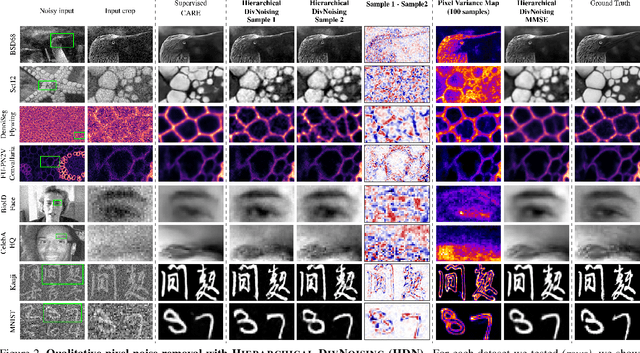

Image denoising and artefact removal are complex inverse problems admitting many potential solutions. Variational Autoencoders (VAEs) can be used to learn a whole distribution of sensible solutions, from which one can sample efficiently. However, such a generative approach to image restoration is only studied in the context of pixel-wise noise removal (e.g. Poisson or Gaussian noise). While important, a plethora of application domains suffer from imaging artefacts (structured noises) that alter groups of pixels in correlated ways. In this work we show, for the first time, that generative diversity denoising (GDD) approaches can learn to remove structured noises without supervision. To this end, we investigate two existing GDD architectures, introduce a new one based on hierarchical VAEs, and compare their performances against a total of seven state-of-the-art baseline methods on five sources of structured noise (including tomography reconstruction artefacts and microscopy artefacts). We find that GDD methods outperform all unsupervised baselines and in many cases not lagging far behind supervised results (in some occasions even superseding them). In addition to structured noise removal, we also show that our new GDD method produces new state-of-the-art (SOTA) results on seven out of eight benchmark datasets for pixel-noise removal. Finally, we offer insights into the daunting question of how GDD methods distinguish structured noise, which we like to see removed, from image signals, which we want to see retained.