 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Reconstructing a single-head formula to facilitate logical forgetting
Dec 18, 2020
Logical forgetting may take exponential time in general, but it does not when its input is a single-head propositional definite Horn formula. Single-head means that no variable is the head of multiple clauses. An algorithm to make a formula single-head if possible is shown. It improves over a previous one by being complete: it always finds a single-head formula equivalent to the given one if any.
DuPLO: A DUal view Point deep Learning architecture for time series classificatiOn
Sep 20, 2018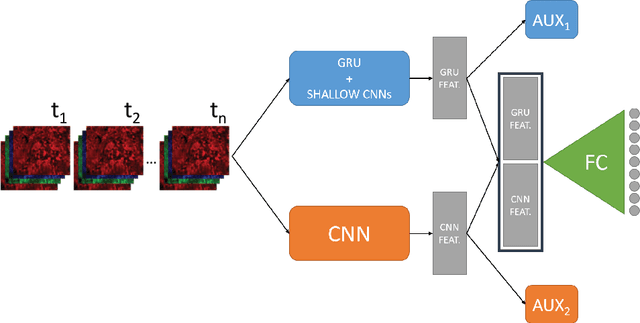
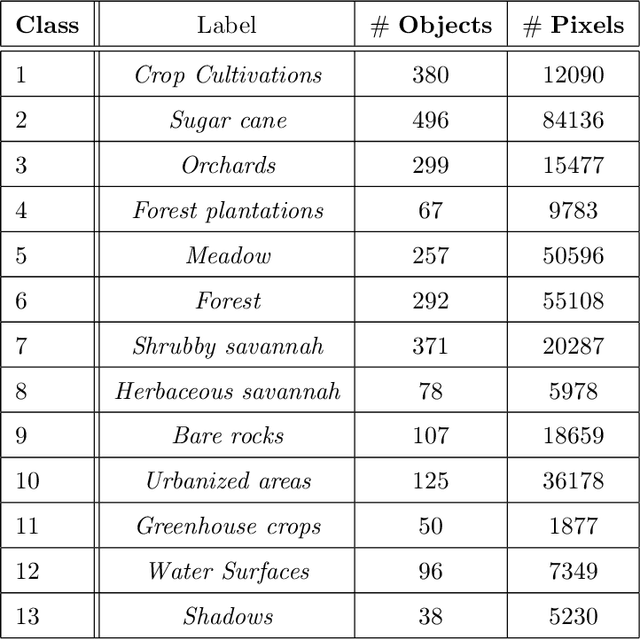
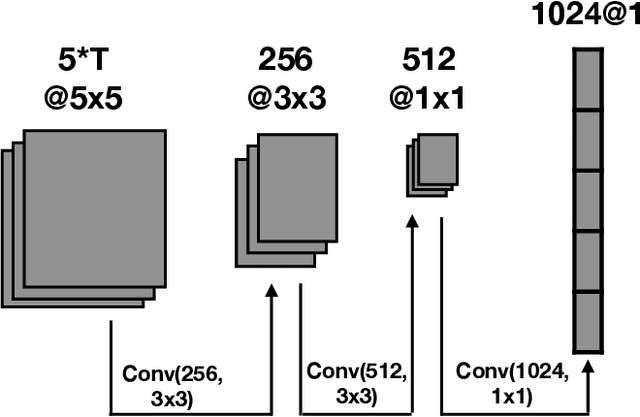
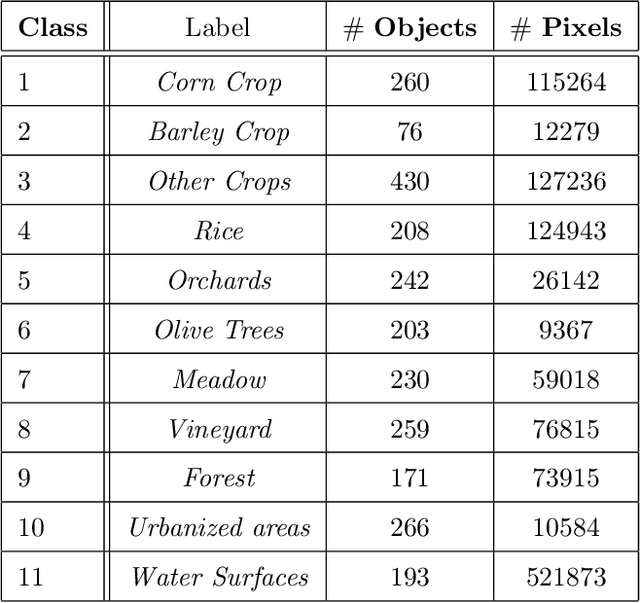
Nowadays, modern Earth Observation systems continuously generate huge amounts of data. A notable example is represented by the Sentinel-2 mission, which provides images at high spatial resolution (up to 10m) with high temporal revisit period (every 5 days), which can be organized in Satellite Image Time Series (SITS). While the use of SITS has been proved to be beneficial in the context of Land Use/Land Cover (LULC) map generation, unfortunately, machine learning approaches commonly leveraged in remote sensing field fail to take advantage of spatio-temporal dependencies present in such data. Recently, new generation deep learning methods allowed to significantly advance research in this field. These approaches have generally focused on a single type of neural network, i.e., Convolutional Neural Networks (CNNs) or Recurrent Neural Networks (RNNs), which model different but complementary information: spatial autocorrelation (CNNs) and temporal dependencies (RNNs). In this work, we propose the first deep learning architecture for the analysis of SITS data, namely \method{} (DUal view Point deep Learning architecture for time series classificatiOn), that combines Convolutional and Recurrent neural networks to exploit their complementarity. Our hypothesis is that, since CNNs and RNNs capture different aspects of the data, a combination of both models would produce a more diverse and complete representation of the information for the underlying land cover classification task. Experiments carried out on two study sites characterized by different land cover characteristics (i.e., the \textit{Gard} site in France and the \textit{Reunion Island} in the Indian Ocean), demonstrate the significance of our proposal.
Optimising the Performance of Convolutional Neural Networks across Computing Systems using Transfer Learning
Oct 20, 2020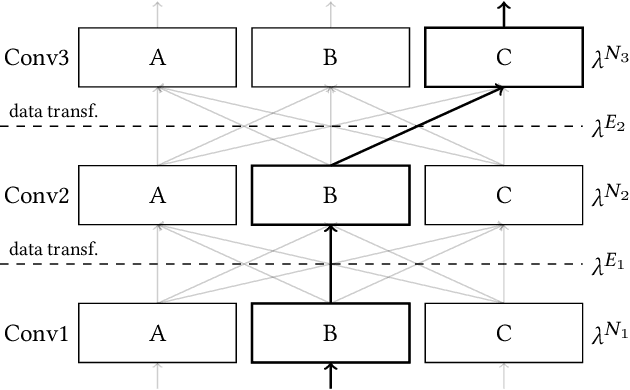
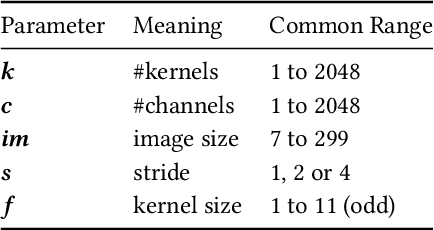
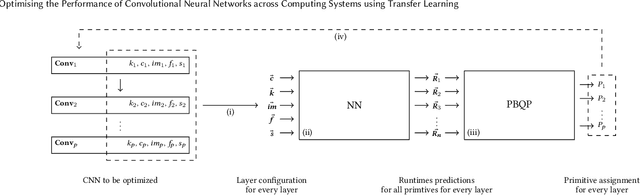

The choice of convolutional routines (primitives) to implement neural networks has a tremendous impact on their inference performance (execution speed) on a given hardware platform. To optimise a neural network by primitive selection, the optimal primitive is identified for each layer of the network. This process requires a lengthy profiling stage, iterating over all the available primitives for each layer configuration, to measure their execution time on the target platform. Because each primitive exploits the hardware in different ways, new profiling is needed to obtain the best performance when moving to another platform. In this work, we propose to replace this prohibitively expensive profiling stage with a machine learning based approach of performance modeling. Our approach speeds up the optimisation time drastically. After training, our performance model can estimate the performance of convolutional primitives in any layer configuration. The time to optimise the execution of large neural networks via primitive selection is reduced from hours to just seconds. Our performance model is easily transferable to other target platforms. We demonstrate this by training a performance model on an Intel platform and performing transfer learning to AMD and ARM processor devices with minimal profiled samples.
A Real-Time Tiny Detection Model for Stem End and Blossom End of Navel Orange
May 24, 2019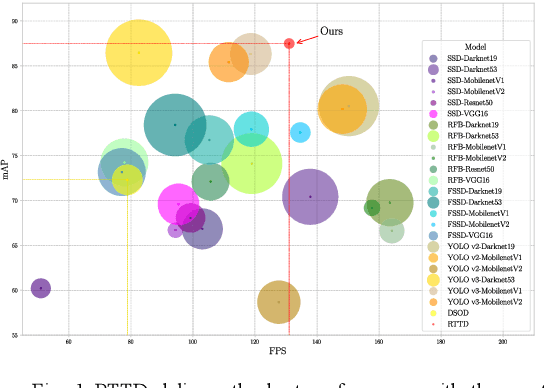
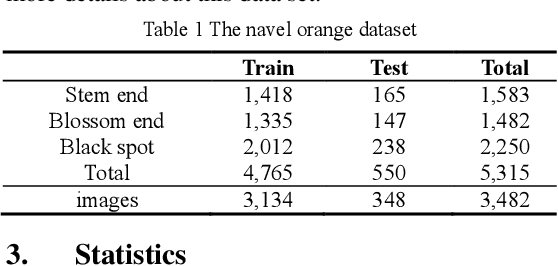
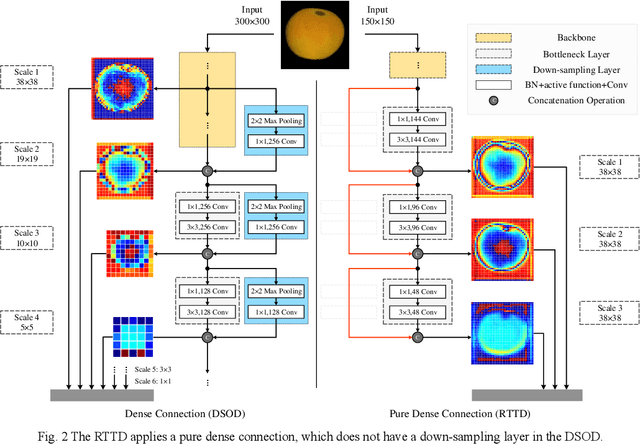
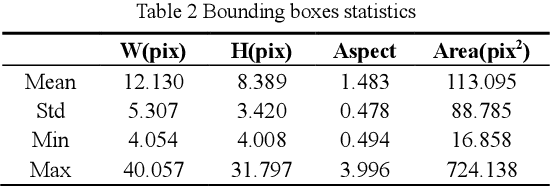
To distinguish the stem end and blossom end of navel orange from its black spot, we propose a real-time tiny detection model (RTTD) with low computational cost, compact architecture and high detection accuracy. In particular, based on the characteristics of the data, we apply pure dense connectivity to limit and simplify the design of the model architecture and use k-means clustering to set the size and aspect ratios of the default boxes. The architecture of model is based on deeply supervised object detectors (DSOD), and which reduces some components like dense block and prediction layers for efficient and adds some auxiliary structure like Squeeze-and-Excitation layer and Swish for accuracy. And we create a dataset in Pascal VOC format annotated the three types of detection targets stem end, blossom end and black spot. Experimental results on our orange data set confirm that RTTD has competitive results to the state-of-the-art one stage detectors like SSD, DSOD, YOLOv2, YOLOv3, RFB and FSSD, and it achieves 87.479%mAP at 131 FPS with only 5.812M parameters.
Competition analysis on the over-the-counter credit default swap market
Dec 03, 2020
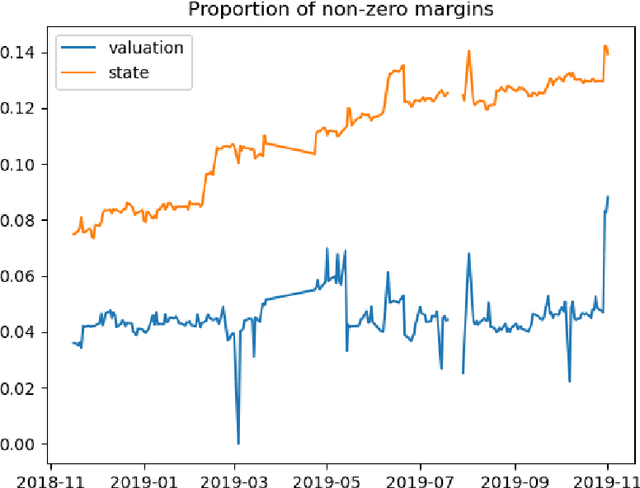
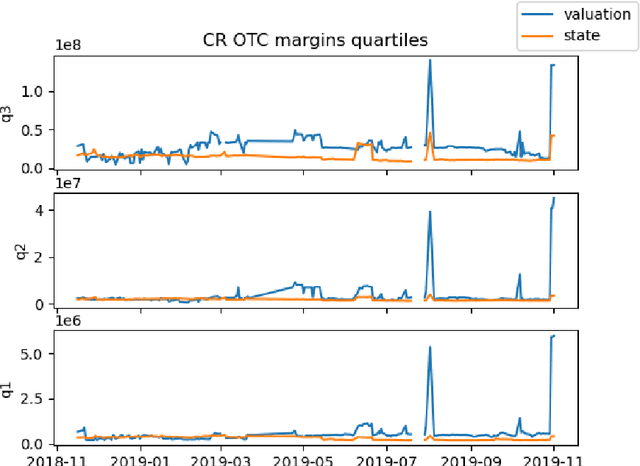
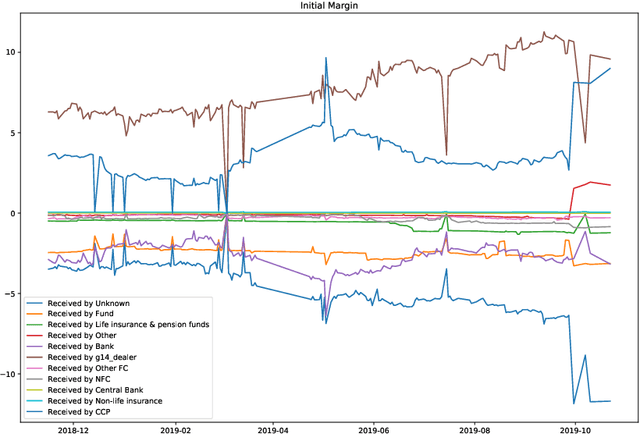
We study two questions related to competition on the OTC CDS market using data collected as part of the EMIR regulation. First, we study the competition between central counterparties through collateral requirements. We present models that successfully estimate the initial margin requirements. However, our estimations are not precise enough to use them as input to a predictive model for CCP choice by counterparties in the OTC market. Second, we model counterpart choice on the interdealer market using a novel semi-supervised predictive task. We present our methodology as part of the literature on model interpretability before arguing for the use of conditional entropy as the metric of interest to derive knowledge from data through a model-agnostic approach. In particular, we justify the use of deep neural networks to measure conditional entropy on real-world datasets. We create the $\textit{Razor entropy}$ using the framework of algorithmic information theory and derive an explicit formula that is identical to our semi-supervised training objective. Finally, we borrow concepts from game theory to define $\textit{top-k Shapley values}$. This novel method of payoff distribution satisfies most of the properties of Shapley values, and is of particular interest when the value function is monotone submodular. Unlike classical Shapley values, top-k Shapley values can be computed in quadratic time of the number of features instead of exponential. We implement our methodology and report the results on our particular task of counterpart choice. Finally, we present an improvement to the $\textit{node2vec}$ algorithm that could for example be used to further study intermediation. We show that the neighbor sampling used in the generation of biased walks can be performed in logarithmic time with a quasilinear time pre-computation, unlike the current implementations that do not scale well.
Minimum Length Scheduling for Multi-cell Full Duplex Wireless Powered Communication Networks
Jan 20, 2021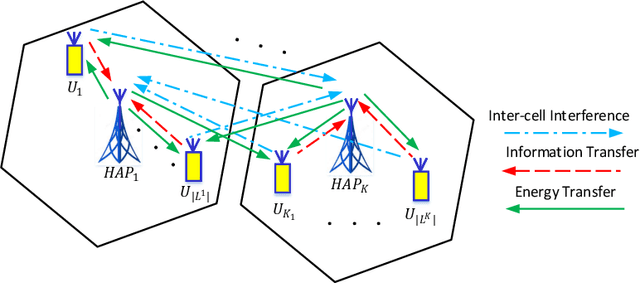
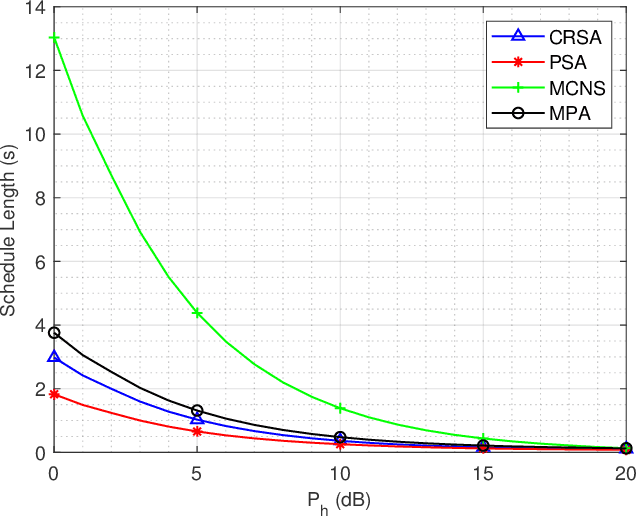
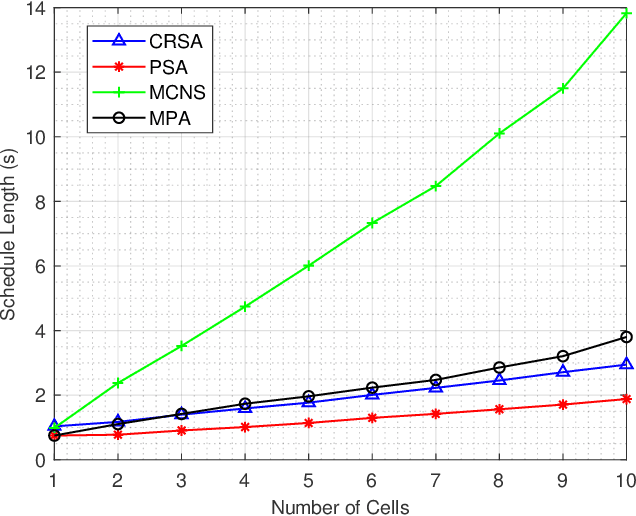
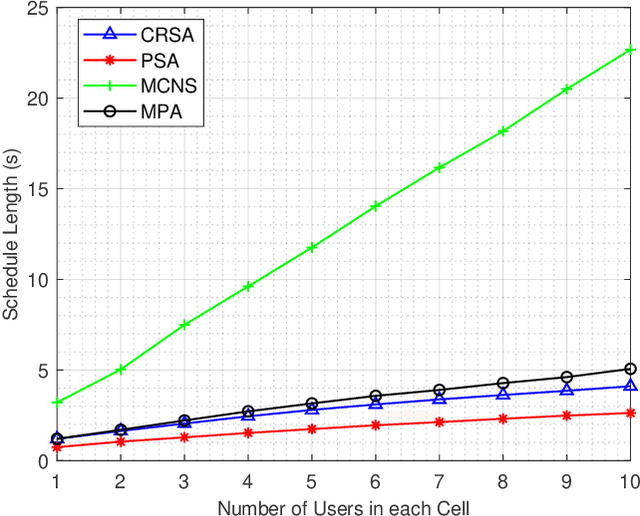
In this paper, we investigate a novel minimum length scheduling problem to determine the optimal power control, and scheduling for constant and continuous rate models, while considering concurrent transmission of users, energy causality, maximum transmit power and traffic demand constraints. The formulated optimization problems are shown to be non-convex and combinatorial in nature, thus, difficult to solve for the global optimum. As a solution strategy, first, we propose optimal polynomial time algorithms for the power control problem considering constant and continuous rate models based on the evaluation of Perron-Frobenius conditions and usage of bisection method, respectively. Then, the proposed optimal power control solutions are used to determine the optimal transmission time for a subset of users that will be scheduled by the scheduling algorithms. For the constant rate scheduling problem, we propose a heuristic algorithm that aims to maximize the number of concurrently transmitting users by maximizing the allowable interference on each user without violating the signal-to-noise-ratio (SNR) requirements. For the continuous rate scheduling problem, we define a penalty function representing the advantage of concurrent transmission over individual transmission of the users. Following the optimality analysis of the penalty metric and demonstration of the equivalence between schedule length minimization and minimization of the sum of penalties, we propose a heuristic algorithm based on the allocation of the concurrently transmitting users with the goal of minimizing the sum penalties over the schedule. Through extensive simulations, we demonstrate that the proposed algorithm outperforms the successive transmission and concurrent transmission of randomly selected users for different HAP transmit powers, network densities and network size.
Learning language variations in news corpora through differential embeddings
Nov 13, 2020



There is an increasing interest in the NLP community in capturing variations in the usage of language, either through time (i.e., semantic drift), across regions (as dialects or variants) or in different social contexts (i.e., professional or media technolects). Several successful dynamical embeddings have been proposed that can track semantic change through time. Here we show that a model with a central word representation and a slice-dependent contribution can learn word embeddings from different corpora simultaneously. This model is based on a star-like representation of the slices. We apply it to The New York Times and The Guardian newspapers, and we show that it can capture both temporal dynamics in the yearly slices of each corpus, and language variations between US and UK English in a curated multi-source corpus. We provide an extensive evaluation of this methodology.
Regret-optimal measurement-feedback control
Nov 24, 2020We consider measurement-feedback control in linear dynamical systems from the perspective of regret minimization. Unlike most prior work in this area, we focus on the problem of designing an online controller which competes with the optimal dynamic sequence of control actions selected in hindsight, instead of the best controller in some specific class of controllers. This formulation of regret is attractive when the environment changes over time and no single controller achieves good performance over the entire time horizon. We show that in the measurement-feedback setting, unlike in the full-information setting, there is no single offline controller which outperforms every other offline controller on every disturbance, and propose a new $H_2$-optimal offline controller as a benchmark for the online controller to compete against. We show that the corresponding regret-optimal online controller can be found via a novel reduction to the classical Nehari problem from robust control and present a tight data-dependent bound on its regret.
A Cognitive Approach based on the Actionable Knowledge Graph for supporting Maintenance Operations
Nov 18, 2020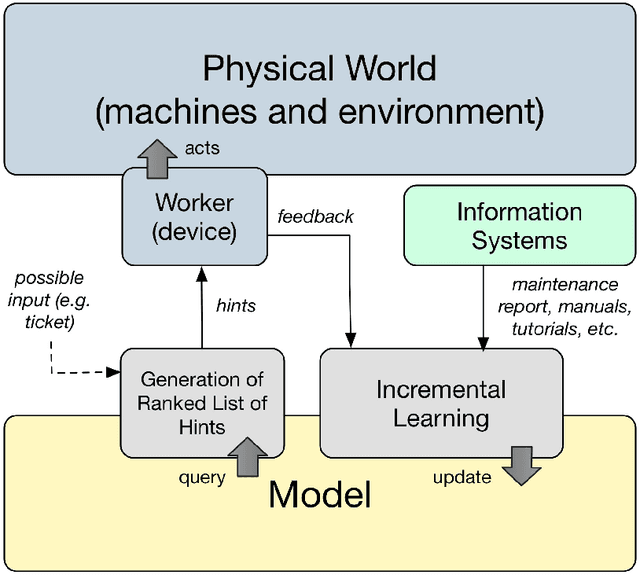
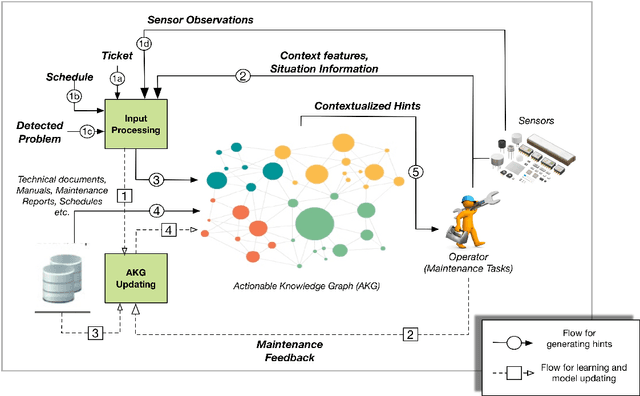
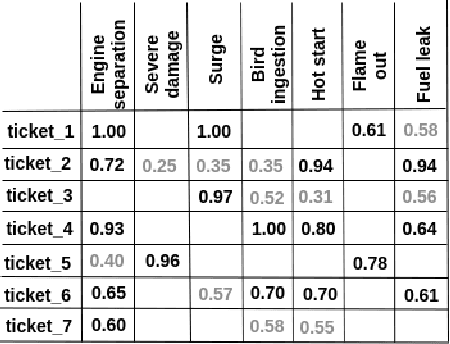
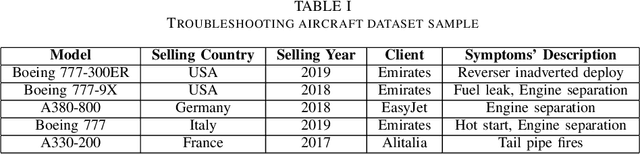
In the era of Industry 4.0, cognitive computing and its enabling technologies (Artificial Intelligence, Machine Learning, etc.) allow to define systems able to support maintenance by providing relevant information, at the right time, retrieved from structured companies' databases, and unstructured documents, like technical manuals, intervention reports, and so on. Moreover, contextual information plays a crucial role in tailoring the support both during the planning and the execution of interventions. Contextual information can be detected with the help of sensors, wearable devices, indoor and outdoor positioning systems, and object recognition capabilities (using fixed or wearable cameras), all of which can collect historical data for further analysis. In this work, we propose a cognitive system that learns from past interventions to generate contextual recommendations for improving maintenance practices in terms of time, budget, and scope. The system uses formal conceptual models, incremental learning, and ranking algorithms to accomplish these objectives.
Cost-Sensitive Convolution based Neural Networks for Imbalanced Time-Series Classification
Jan 13, 2018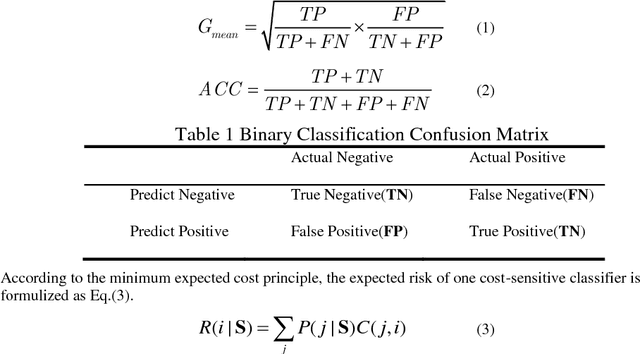
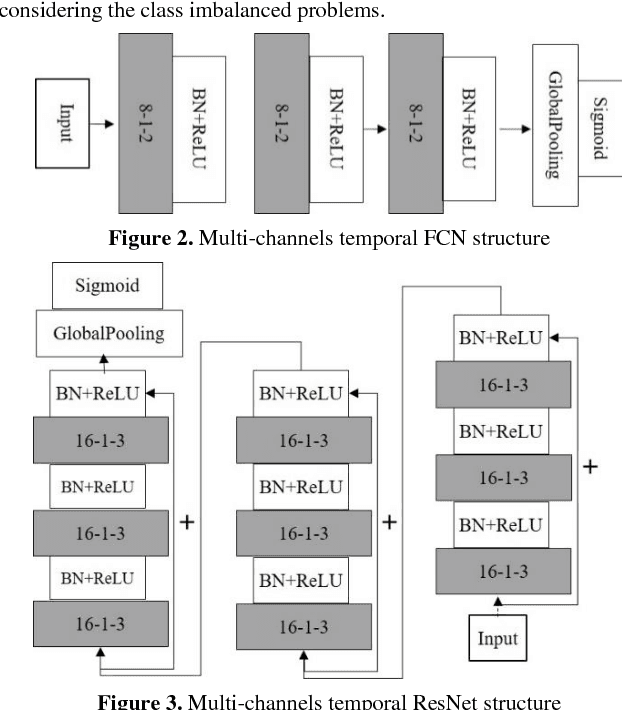
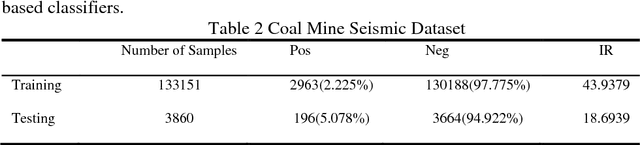
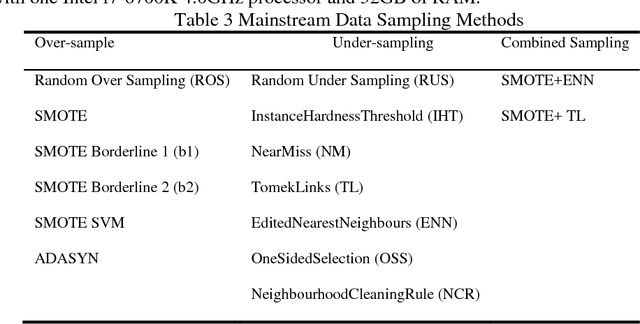
Some deep convolutional neural networks were proposed for time-series classification and class imbalanced problems. However, those models performed degraded and even failed to recognize the minority class of an imbalanced temporal sequences dataset. Minority samples would bring troubles for temporal deep learning classifiers due to the equal treatments of majority and minority class. Until recently, there were few works applying deep learning on imbalanced time-series classification (ITSC) tasks. Here, this paper aimed at tackling ITSC problems with deep learning. An adaptive cost-sensitive learning strategy was proposed to modify temporal deep learning models. Through the proposed strategy, classifiers could automatically assign misclassification penalties to each class. In the experimental section, the proposed method was utilized to modify five neural networks. They were evaluated on a large volume, real-life and imbalanced time-series dataset with six metrics. Each single network was also tested alone and combined with several mainstream data samplers. Experimental results illustrated that the proposed cost-sensitive modified networks worked well on ITSC tasks. Compared to other methods, the cost-sensitive convolution neural network and residual network won out in the terms of all metrics. Consequently, the proposed cost-sensitive learning strategy can be used to modify deep learning classifiers from cost-insensitive to cost-sensitive. Those cost-sensitive convolutional networks can be effectively applied to address ITSC issues.