 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
DCVNet: Dilated Cost Volume Networks for Fast Optical Flow
Mar 31, 2021
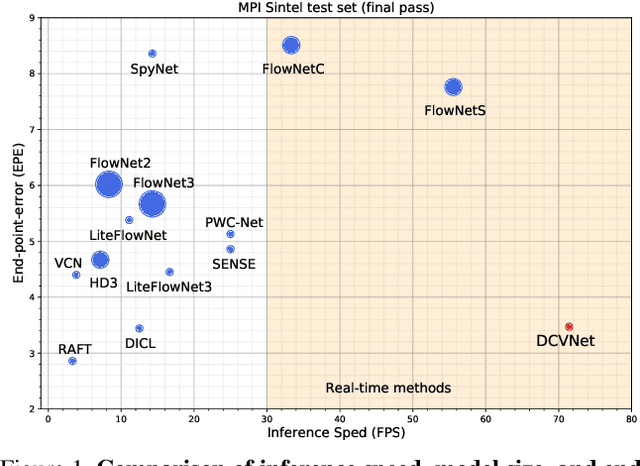
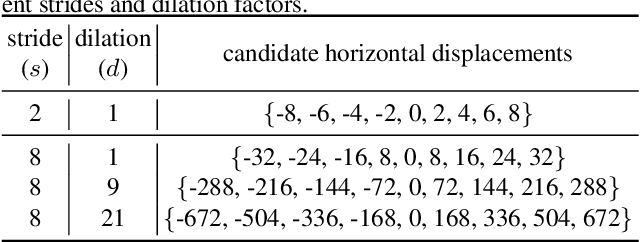
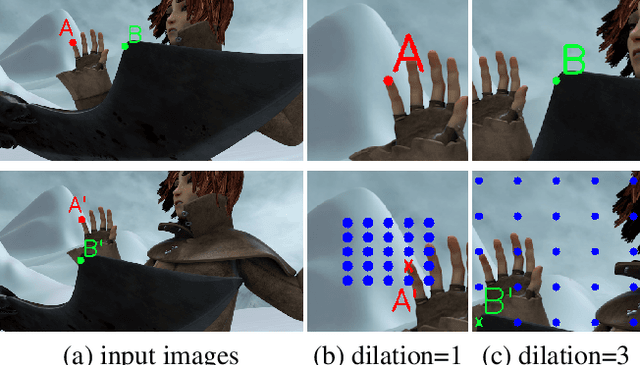
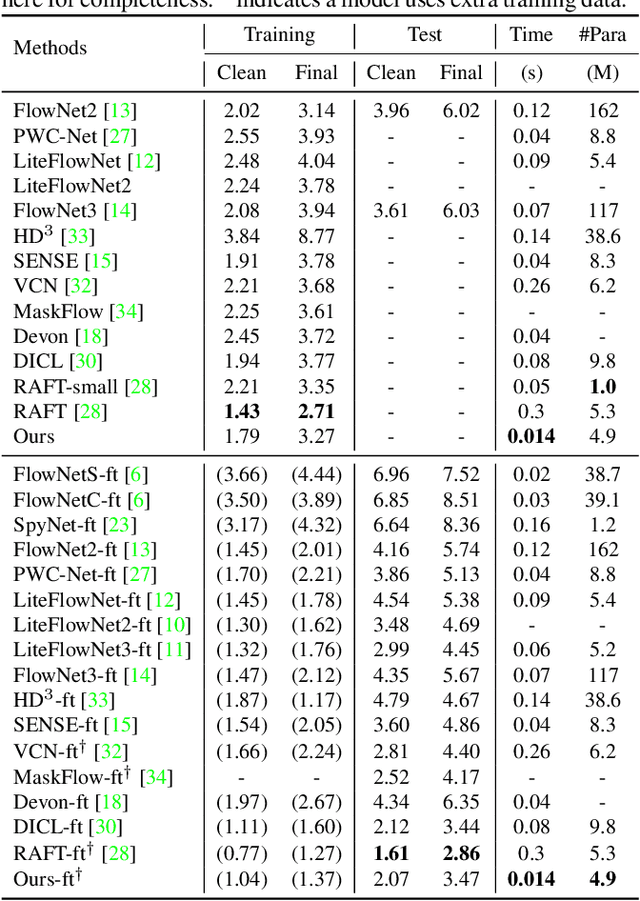
The cost volume, capturing the similarity of possible correspondences across two input images, is a key ingredient in state-of-the-art optical flow approaches. When sampling for correspondences to build the cost volume, a large neighborhood radius is required to deal with large displacements, introducing a significant computational burden. To address this, a sequential strategy is usually adopted, where correspondence sampling in a local neighborhood with a small radius suffices. However, such sequential approaches, instantiated by either a pyramid structure over a deep neural network's feature hierarchy or by a recurrent neural network, are slow due to the inherent need for sequential processing of cost volumes. In this paper, we propose dilated cost volumes to capture small and large displacements simultaneously, allowing optical flow estimation without the need for the sequential estimation strategy. To process the cost volume to get pixel-wise optical flow, existing approaches employ 2D or separable 4D convolutions, which we show either suffer from high GPU memory consumption, inferior accuracy, or large model size. Therefore, we propose using 3D convolutions for cost volume filtering to address these issues. By combining the dilated cost volumes and 3D convolutions, our proposed model DCVNet not only exhibits real-time inference (71 fps on a mid-end 1080ti GPU) but is also compact and obtains comparable accuracy to existing approaches.
CDiNN -Convex Difference Neural Networks
Mar 31, 2021
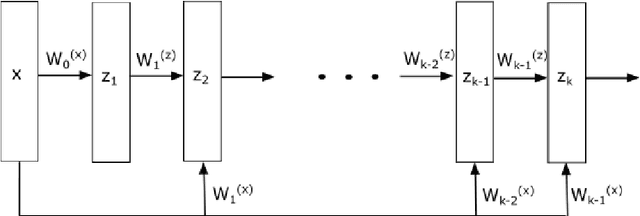
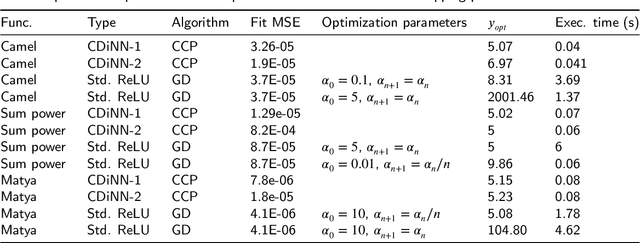
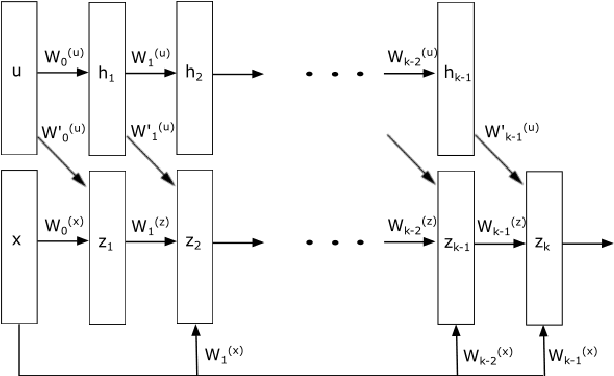
Neural networks with ReLU activation function have been shown to be universal function approximators and learn function mapping as non-smooth functions. Recently, there is considerable interest in the use of neural networks in applications such as optimal control. It is well-known that optimization involving non-convex, non-smooth functions are computationally intensive and have limited convergence guarantees. Moreover, the choice of optimization hyper-parameters used in gradient descent/ascent significantly affect the quality of the obtained solutions. A new neural network architecture called the Input Convex Neural Networks (ICNNs) learn the output as a convex function of inputs thereby allowing the use of efficient convex optimization methods. Use of ICNNs for determining the input for minimizing output has two major problems: learning of a non-convex function as a convex mapping could result in significant function approximation error, and we also note that the existing representations cannot capture simple dynamic structures like linear time delay systems. We attempt to address the above problems by introduction of a new neural network architecture, which we call the CDiNN, which learns the function as a difference of polyhedral convex functions from data. We also discuss that, in some cases, the optimal input can be obtained from CDiNN through difference of convex optimization with convergence guarantees and that at each iteration, the problem is reduced to a linear programming problem.
Predicting Nanorobot Shapes via Generative Models
Jan 29, 2021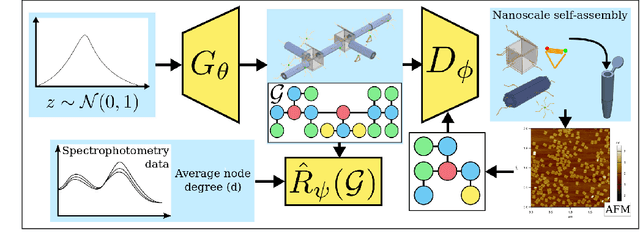
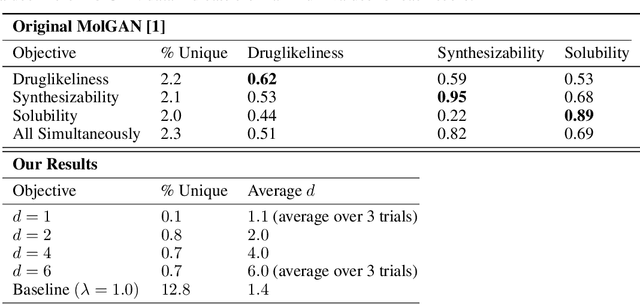
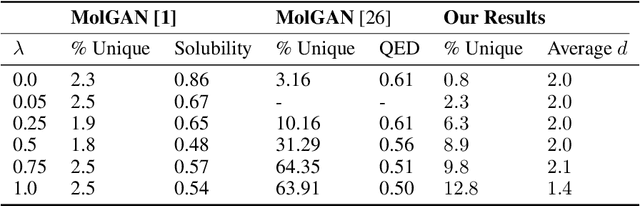
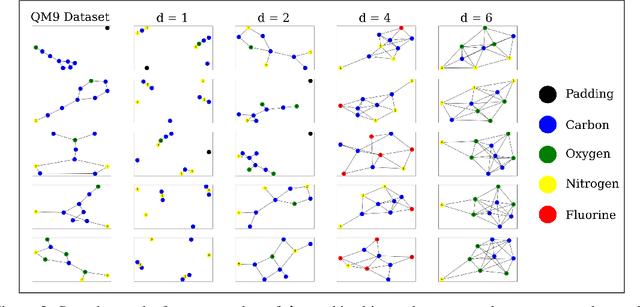
The field of DNA nanotechnology has made it possible to assemble, with high yields, different structures that have actionable properties. For example, researchers have created components that can be actuated. An exciting next step is to combine these components into multifunctional nanorobots that could, potentially, perform complex tasks like swimming to a target location in the human body, detect an adverse reaction and then release a drug load to stop it. However, as we start to assemble more complex nanorobots, the yield of the desired nanorobot begins to decrease as the number of possible component combinations increases. Therefore, the ultimate goal of this work is to develop a predictive model to maximize yield. However, training predictive models typically requires a large dataset. For the nanorobots we are interested in assembling, this will be difficult to collect. This is because high-fidelity data, which allows us to characterize the shape and size of individual structures, is very time-consuming to collect, whereas low-fidelity data is readily available but only captures bulk statistics for different processes. Therefore, this work combines low- and high-fidelity data to train a generative model using a two-step process. We first use a relatively small, high-fidelity dataset to train a generative model. At run time, the model takes low-fidelity data and uses it to approximate the high-fidelity content. We do this by biasing the model towards samples with specific properties as measured by low-fidelity data. In this work we bias our distribution towards a desired node degree of a graphical model that we take as a surrogate representation of the nanorobots that this work will ultimately focus on. We have not yet accumulated a high-fidelity dataset of nanorobots, so we leverage the MolGAN architecture [1] and the QM9 small molecule dataset [2-3] to demonstrate our approach.
Enhancing Transformation-based Defenses against Adversarial Examples with First-Order Perturbations
Mar 08, 2021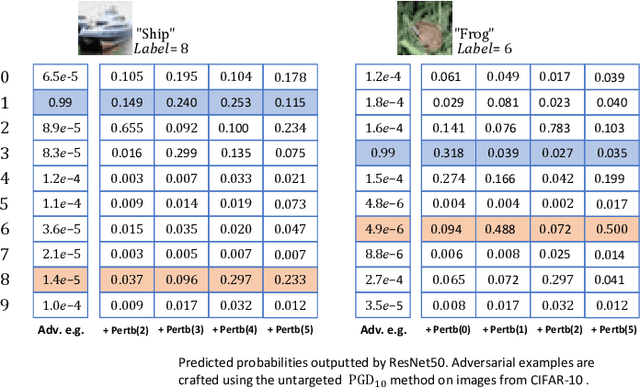
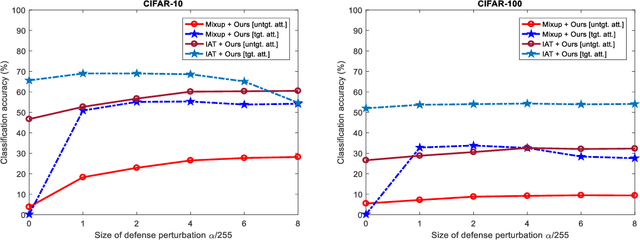
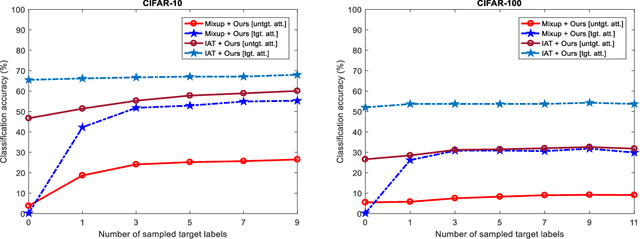
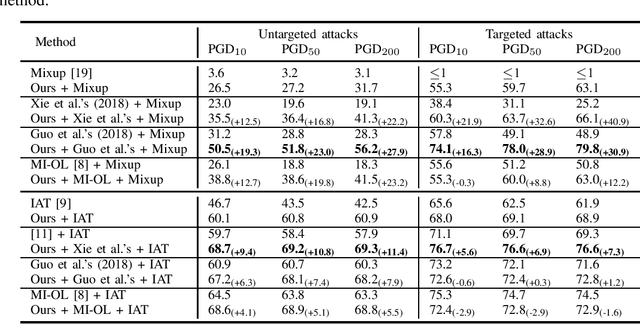
Studies show that neural networks are susceptible to adversarial attacks. This exposes a potential threat to neural network-based artificial intelligence systems. We observe that the probability of the correct result outputted by the neural network increases by applying small perturbations generated for non-predicted class labels to adversarial examples. Based on this observation, we propose a method of counteracting adversarial perturbations to resist adversarial examples. In our method, we randomly select a number of class labels and generate small perturbations for these selected labels. The generated perturbations are added together and then clamped onto a specified space. The obtained perturbation is finally added to the adversarial example to counteract the adversarial perturbation contained in the example. The proposed method is applied at inference time and does not require retraining or finetuning the model. We validate the proposed method on CIFAR-10 and CIFAR-100. The experimental results demonstrate that our method effectively improves the defense performance of the baseline methods, especially against strong adversarial examples generated using more iterations.
Conditional Generative Adversarial Networks to Model Urban Outdoor Air Pollution
Oct 05, 2020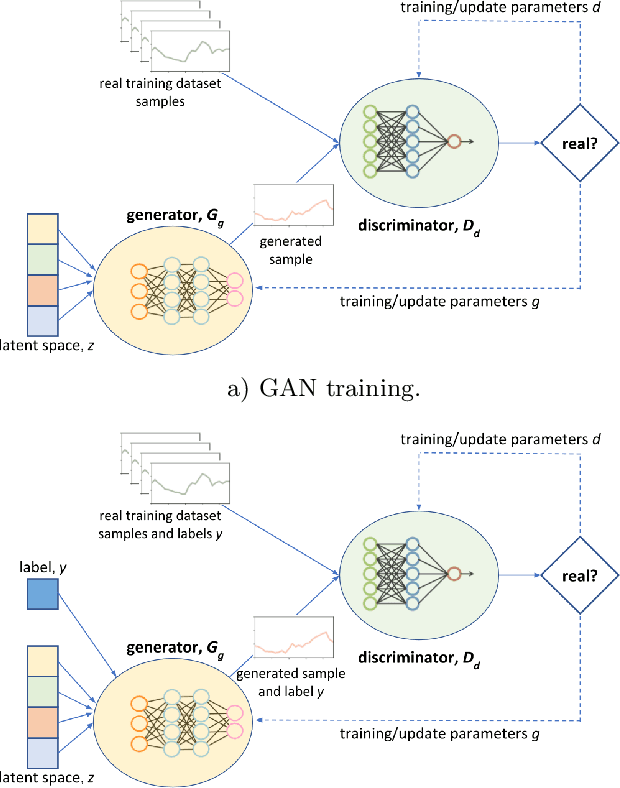

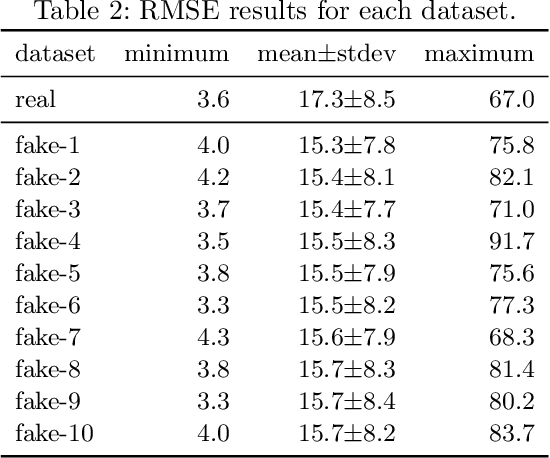
This is a relevant problem because the design of most cities prioritizes the use of motorized vehicles, which has degraded air quality in recent years, having a negative effect on urban health. Modeling, predicting, and forecasting ambient air pollution is an important way to deal with this issue because it would be helpful for decision-makers and urban city planners to understand the phenomena and to take solutions. In general, data-driven methods for modeling, predicting, and forecasting outdoor pollution requires an important amount of data, which may limit their accuracy. In order to deal with such a lack of data, we propose to train models able to generate synthetic nitrogen dioxide daily time series according to a given classification that will allow an unlimited generation of realistic data. The main experimental results indicate that the proposed approach is able to generate accurate and diverse pollution daily time series, while requiring reduced computational time.
Meta-Reinforcement Learning for Reliable Communication in THz/VLC Wireless VR Networks
Jan 29, 2021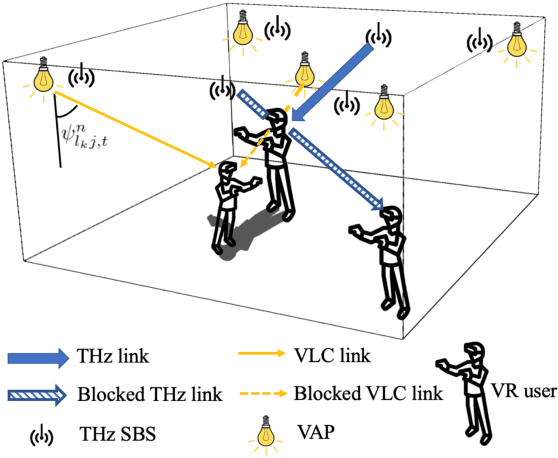
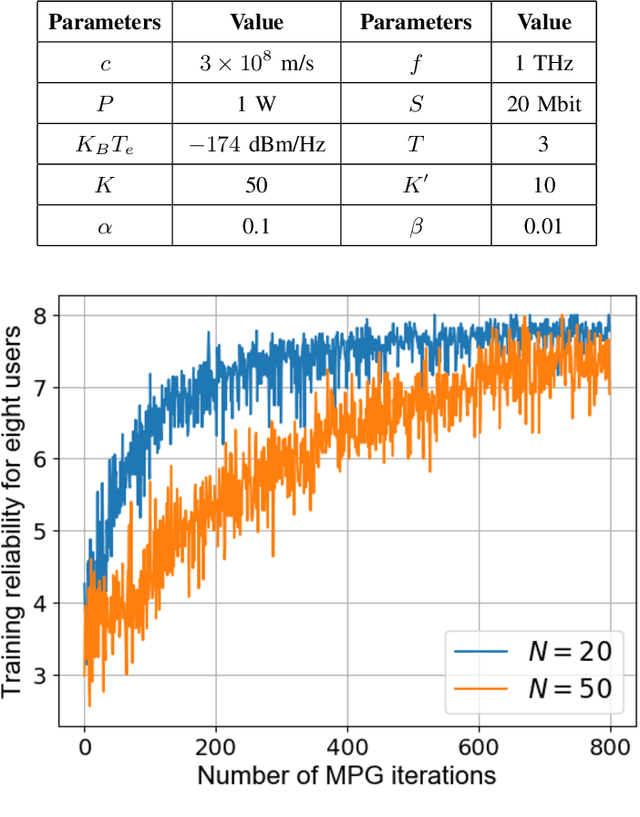
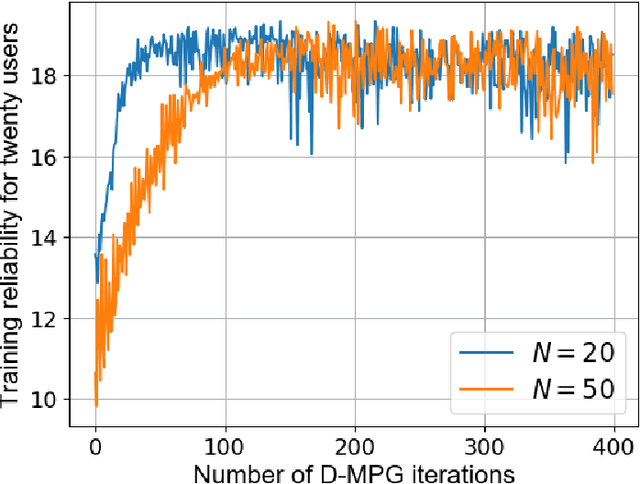
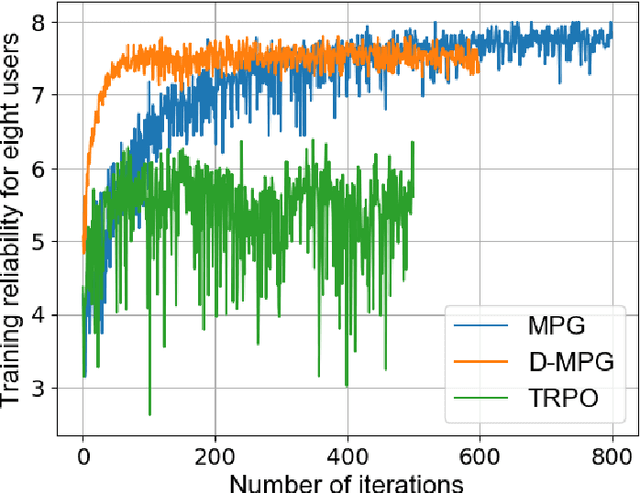
In this paper, the problem of enhancing the quality of virtual reality (VR) services is studied for an indoor terahertz (THz)/visible light communication (VLC) wireless network. In the studied model, small base stations (SBSs) transmit high-quality VR images to VR users over THz bands and light-emitting diodes (LEDs) provide accurate indoor positioning services for them using VLC. Here, VR users move in real time and their movement patterns change over time according to their applications. Both THz and VLC links can be blocked by the bodies of VR users. To control the energy consumption of the studied THz/VLC wireless VR network, VLC access points (VAPs) must be selectively turned on so as to ensure accurate and extensive positioning for VR users. Based on the user positions, each SBS must generate corresponding VR images and establish THz links without body blockage to transmit the VR content. The problem is formulated as an optimization problem whose goal is to maximize the average number of successfully served VR users by selecting the appropriate VAPs to be turned on and controlling the user association with SBSs. To solve this problem, a meta policy gradient (MPG) algorithm that enables the trained policy to quickly adapt to new user movement patterns is proposed. In order to solve the problem for VR scenarios with a large number of users, a dual method based MPG algorithm (D-MPG) with a low complexity is proposed. Simulation results demonstrate that, compared to a baseline trust region policy optimization algorithm (TRPO), the proposed MPG and D-MPG algorithms yield up to 38.2% and 33.8% improvement in the average number of successfully served users as well as 75% and 87.5% gains in the convergence speed, respectively.
Objective-Based Hierarchical Clustering of Deep Embedding Vectors
Dec 15, 2020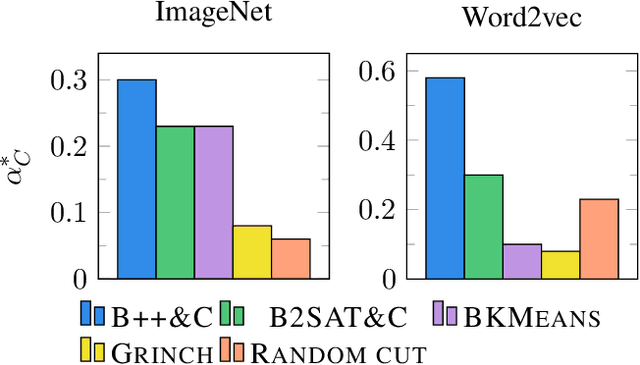
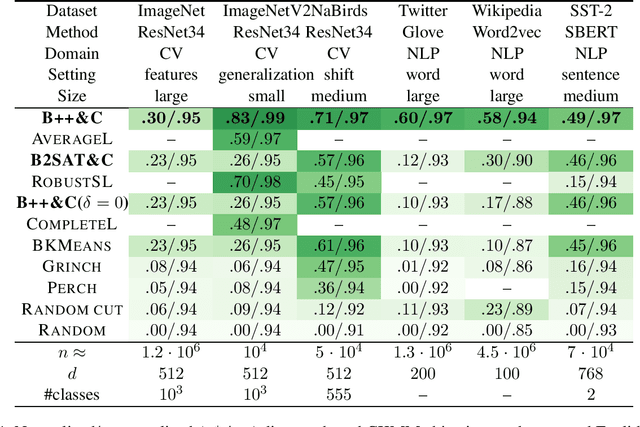
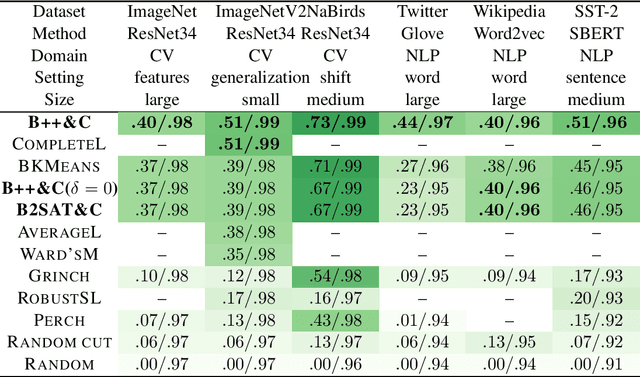
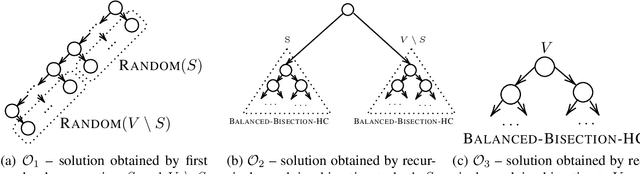
We initiate a comprehensive experimental study of objective-based hierarchical clustering methods on massive datasets consisting of deep embedding vectors from computer vision and NLP applications. This includes a large variety of image embedding (ImageNet, ImageNetV2, NaBirds), word embedding (Twitter, Wikipedia), and sentence embedding (SST-2) vectors from several popular recent models (e.g. ResNet, ResNext, Inception V3, SBERT). Our study includes datasets with up to $4.5$ million entries with embedding dimensions up to $2048$. In order to address the challenge of scaling up hierarchical clustering to such large datasets we propose a new practical hierarchical clustering algorithm B++&C. It gives a 5%/20% improvement on average for the popular Moseley-Wang (MW) / Cohen-Addad et al. (CKMM) objectives (normalized) compared to a wide range of classic methods and recent heuristics. We also introduce a theoretical algorithm B2SAT&C which achieves a $0.74$-approximation for the CKMM objective in polynomial time. This is the first substantial improvement over the trivial $2/3$-approximation achieved by a random binary tree. Prior to this work, the best poly-time approximation of $\approx 2/3 + 0.0004$ was due to Charikar et al. (SODA'19).
Discovering Emotion and Reasoning its Flip in Multi-Party Conversations using Masked Memory Network and Transformer
Mar 24, 2021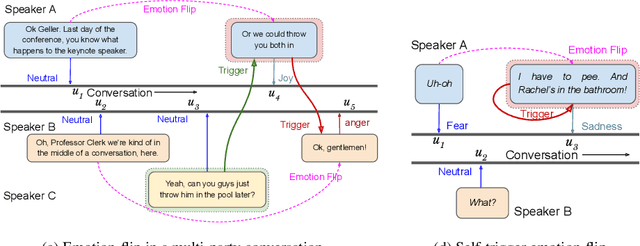
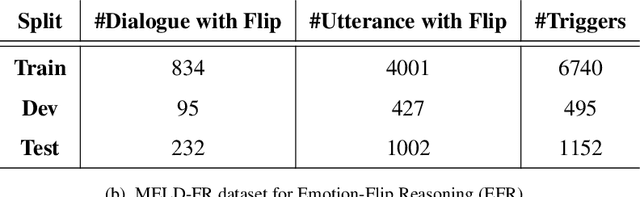
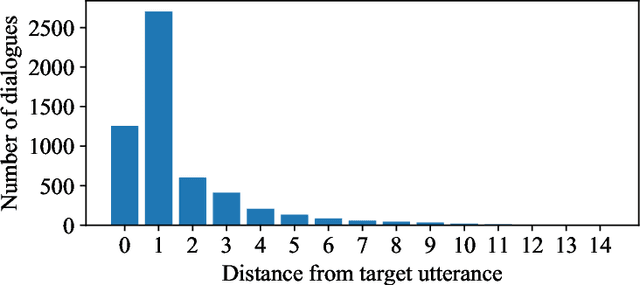
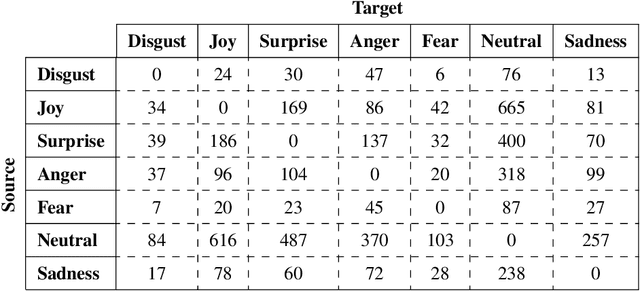
Efficient discovery of emotion states of speakers in a multi-party conversation is highly important to design human-like conversational agents. During the conversation, the cognitive state of a speaker often alters due to certain past utterances, which may lead to a flip in her emotion state. Therefore, discovering the reasons (triggers) behind one's emotion flip during conversation is important to explain the emotion labels of individual utterances. In this paper, along with addressing the task of emotion recognition in conversations (ERC), we introduce a novel task -- Emotion Flip Reasoning (EFR) that aims to identify past utterances which have triggered one's emotion state to flip at a certain time. We propose a masked memory network to address the former and a Transformer-based network for the latter task. To this end, we consider MELD, a benchmark emotion recognition dataset in multi-party conversations for the task of ERC and augment it with new ground-truth labels for EFR. An extensive comparison with four state-of-the-art models suggests improved performances of our models for both the tasks. We further present anecdotal evidences and both qualitative and quantitative error analyses to support the superiority of our models compared to the baselines.
Batch Normalization Embeddings for Deep Domain Generalization
Nov 26, 2020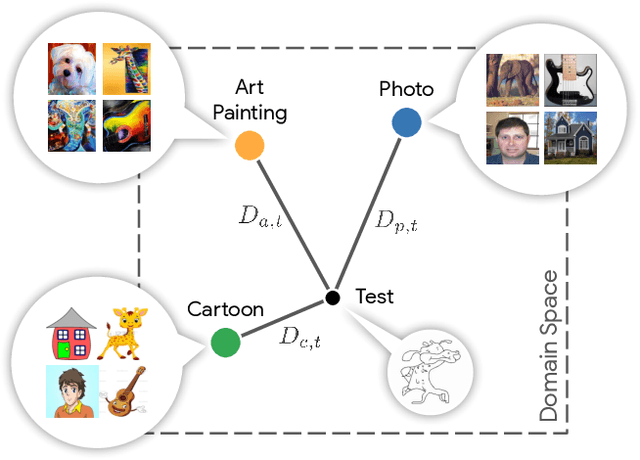
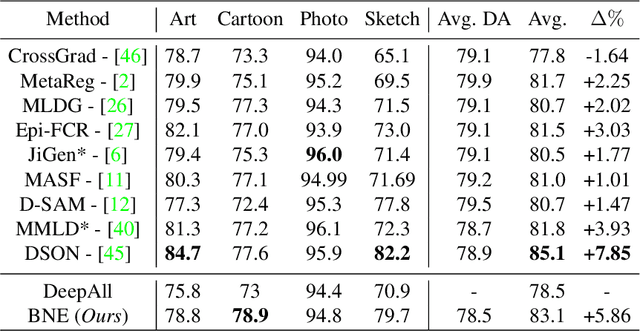
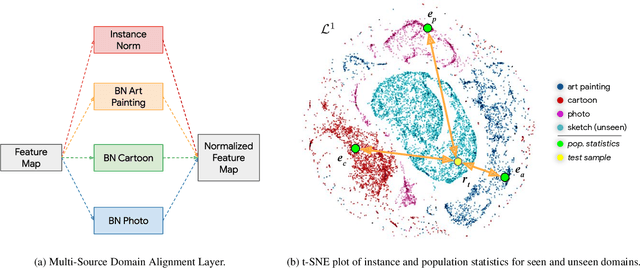
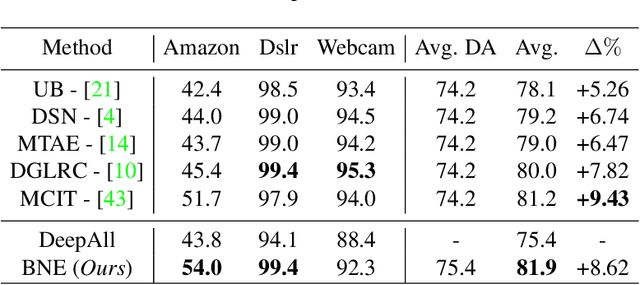
Domain generalization aims at training machine learning models to perform robustly across different and unseen domains. Several recent methods use multiple datasets to train models to extract domain-invariant features, hoping to generalize to unseen domains. Instead, first we explicitly train domain-dependant representations by using ad-hoc batch normalization layers to collect independent domain's statistics. Then, we propose to use these statistics to map domains in a shared latent space, where membership to a domain can be measured by means of a distance function. At test time, we project samples from an unknown domain into the same space and infer properties of their domain as a linear combination of the known ones. We apply the same mapping strategy at training and test time, learning both a latent representation and a powerful but lightweight ensemble model. We show a significant increase in classification accuracy over current state-of-the-art techniques on popular domain generalization benchmarks: PACS, Office-31 and Office-Caltech.
Safety Verification of Neural Network Controlled Systems
Nov 10, 2020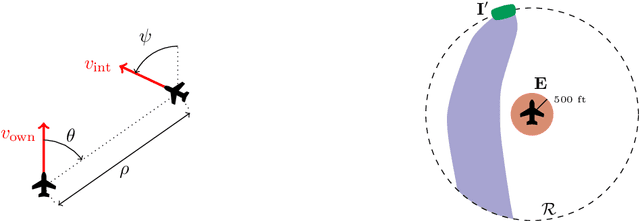
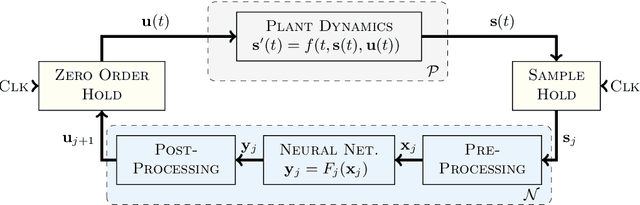
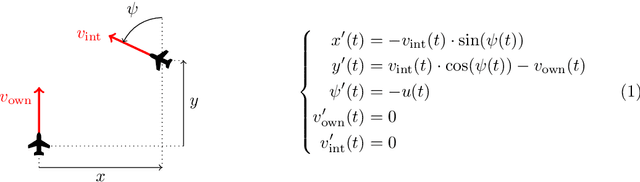
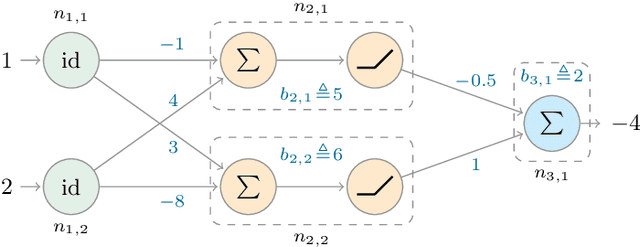
In this paper, we propose a system-level approach for verifying the safety of neural network controlled systems, combining a continuous-time physical system with a discrete-time neural network based controller. We assume a generic model for the controller that can capture both simple and complex behaviours involving neural networks. Based on this model, we perform a reachability analysis that soundly approximates the reachable states of the overall system, allowing to achieve a formal proof of safety. To this end, we leverage both validated simulation to approximate the behaviour of the physical system and abstract interpretation to approximate the behaviour of the controller. We evaluate the applicability of our approach using a real-world use case. Moreover, we show that our approach can provide valuable information when the system cannot be proved totally safe.