 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
ClaRe: Practical Class Incremental Learning By Remembering Previous Class Representations
Mar 29, 2021
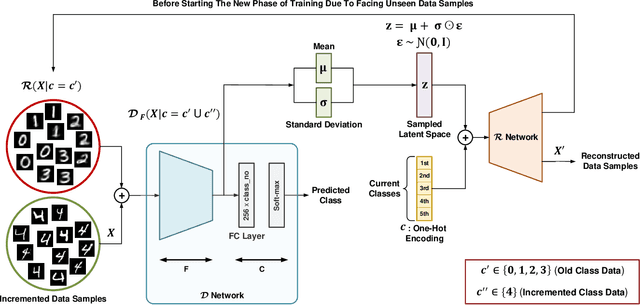

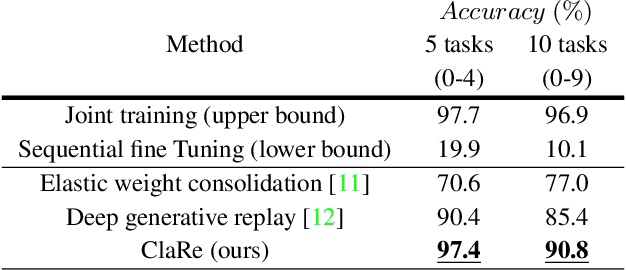
This paper presents a practical and simple yet efficient method to effectively deal with the catastrophic forgetting for Class Incremental Learning (CIL) tasks. CIL tends to learn new concepts perfectly, but not at the expense of performance and accuracy for old data. Learning new knowledge in the absence of data instances from previous classes or even imbalance samples of both old and new classes makes CIL an ongoing challenging problem. These issues can be tackled by storing exemplars belonging to the previous tasks or by utilizing the rehearsal strategy. Inspired by the rehearsal strategy with the approach of using generative models, we propose ClaRe, an efficient solution for CIL by remembering the representations of learned classes in each increment. Taking this approach leads to generating instances with the same distribution of the learned classes. Hence, our model is somehow retrained from the scratch using a new training set including both new and the generated samples. Subsequently, the imbalance data problem is also solved. ClaRe has a better generalization than prior methods thanks to producing diverse instances from the distribution of previously learned classes. We comprehensively evaluate ClaRe on the MNIST benchmark. Results show a very low degradation on accuracy against facing new knowledge over time. Furthermore, contrary to the most proposed solutions, the memory limitation is not problematic any longer which is considered as a consequential issue in this research area.
Train your classifier first: Cascade Neural Networks Training from upper layers to lower layers
Feb 09, 2021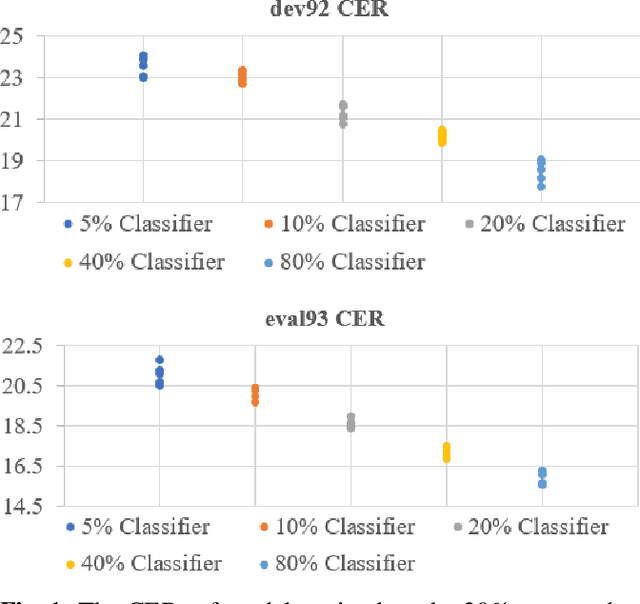
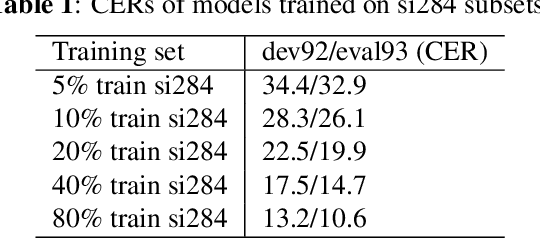
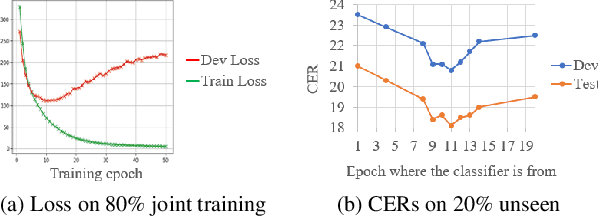
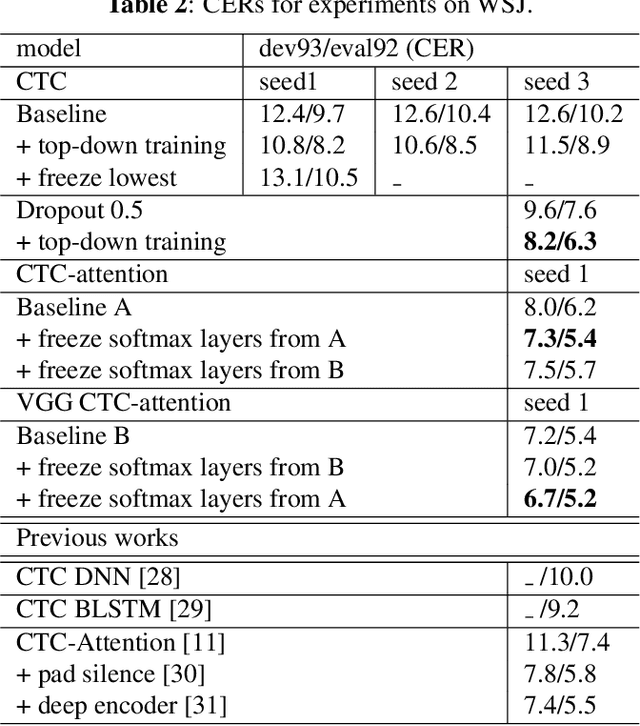
Although the lower layers of a deep neural network learn features which are transferable across datasets, these layers are not transferable within the same dataset. That is, in general, freezing the trained feature extractor (the lower layers) and retraining the classifier (the upper layers) on the same dataset leads to worse performance. In this paper, for the first time, we show that the frozen classifier is transferable within the same dataset. We develop a novel top-down training method which can be viewed as an algorithm for searching for high-quality classifiers. We tested this method on automatic speech recognition (ASR) tasks and language modelling tasks. The proposed method consistently improves recurrent neural network ASR models on Wall Street Journal, self-attention ASR models on Switchboard, and AWD-LSTM language models on WikiText-2.
Variational quantum compiling with double Q-learning
Mar 22, 2021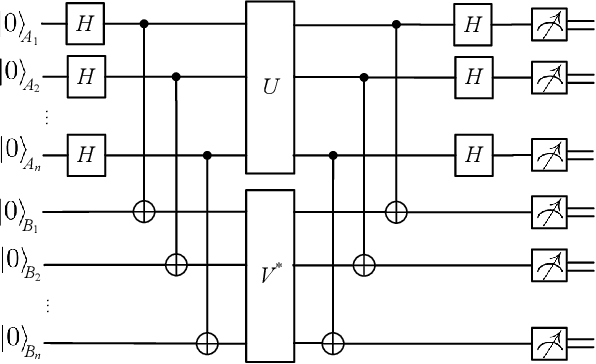

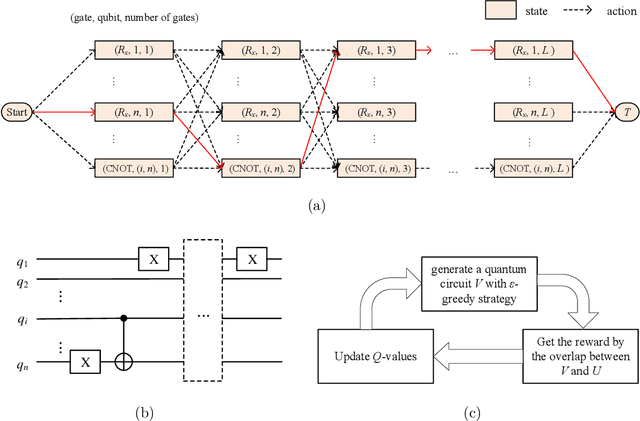
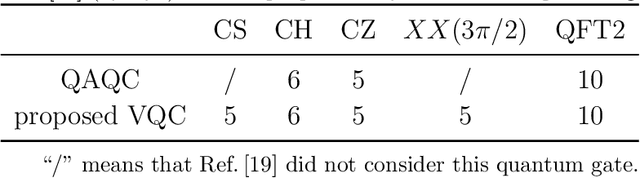
Quantum compiling aims to construct a quantum circuit V by quantum gates drawn from a native gate alphabet, which is functionally equivalent to the target unitary U. It is a crucial stage for the running of quantum algorithms on noisy intermediate-scale quantum (NISQ) devices. However, the space for structure exploration of quantum circuit is enormous, resulting in the requirement of human expertise, hundreds of experimentations or modifications from existing quantum circuits. In this paper, we propose a variational quantum compiling (VQC) algorithm based on reinforcement learning (RL), in order to automatically design the structure of quantum circuit for VQC with no human intervention. An agent is trained to sequentially select quantum gates from the native gate alphabet and the qubits they act on by double Q-learning with \epsilon-greedy exploration strategy and experience replay. At first, the agent randomly explores a number of quantum circuits with different structures, and then iteratively discovers structures with higher performance on the learning task. Simulation results show that the proposed method can make exact compilations with less quantum gates compared to previous VQC algorithms. It can reduce the errors of quantum algorithms due to decoherence process and gate noise in NISQ devices, and enable quantum algorithms especially for complex algorithms to be executed within coherence time.
* 21 pages, 10 figures
RAN Slicing in Multi-MVNO Environment under Dynamic Channel Conditions
Apr 11, 2021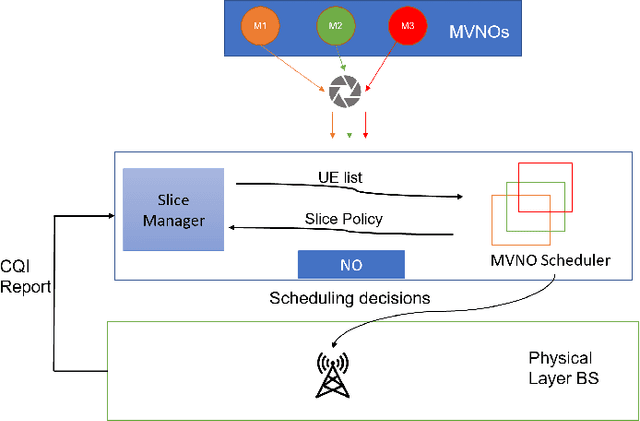
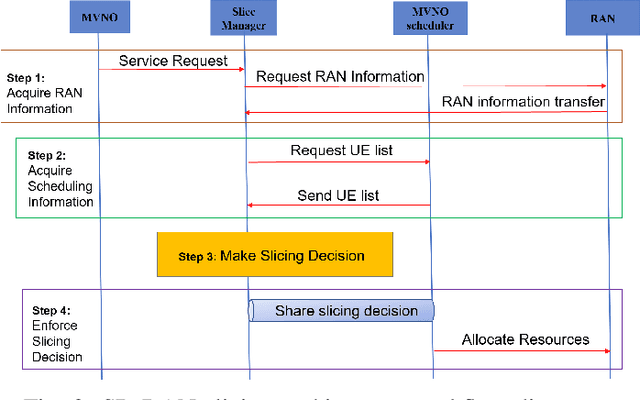
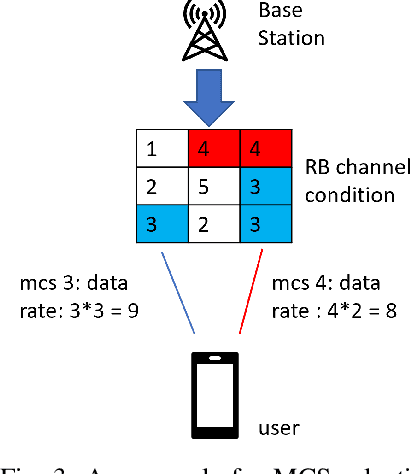
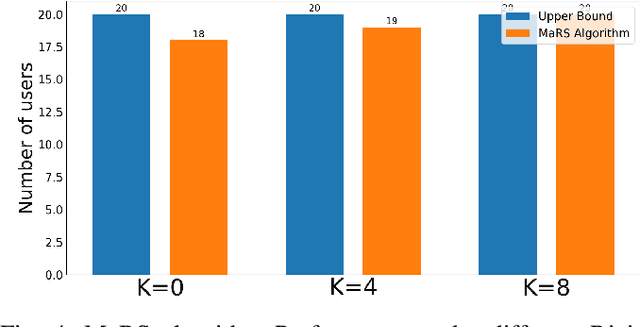
With the increasing diversity in the requirement of wireless services with guaranteed quality of service(QoS), radio access network(RAN) slicing becomes an important aspect in implementation of next generation wireless systems(5G). RAN slicing involves division of network resources into many logical segments where each segment has specific QoS and can serve users of mobile virtual network operator(MVNO) with these requirements. This allows the Network Operator(NO) to provide service to multiple MVNOs each with different service requirements. Efficient allocation of the available resources to slices becomes vital in determining number of users and therefore, number of MVNOs that a NO can support. In this work, we study the problem of Modulation and Coding Scheme(MCS) aware RAN slicing(MaRS) in the context of a wireless system having MVNOs which have users with minimum data rate requirement. Channel Quality Indicator(CQI) report sent from each user in the network determines the MCS selected, which in turn determines the achievable data rate. But the channel conditions might not remain the same for the entire duration of user being served. For this reason, we consider the channel conditions to be dynamic where the choice of MCS level varies at each time instant. We model the MaRS problem as a Non-Linear Programming problem and show that it is NP-Hard. Next, we propose a solution based on greedy algorithm paradigm. We then develop an upper performance bound for this problem and finally evaluate the performance of proposed solution by comparing against the upper bound under various channel and network configurations.
Assessing the effect of advertising expenditures upon sales: a Bayesian structural time series model
Apr 23, 2018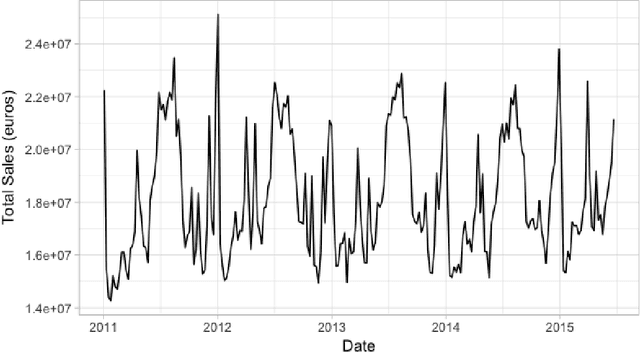
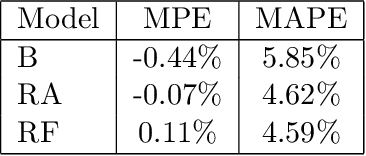
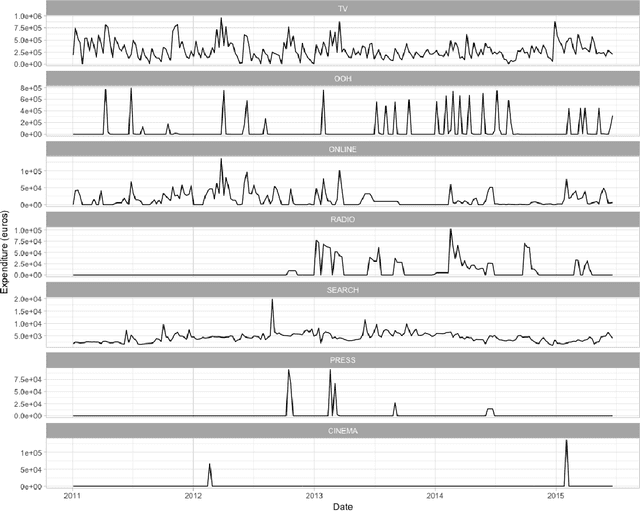
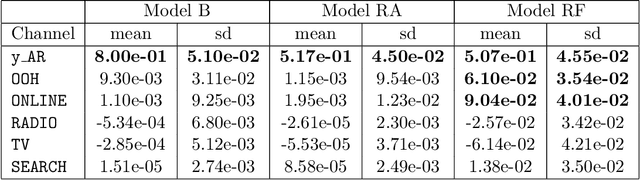
We propose a robust implementation of the Nerlove--Arrow model using a Bayesian structural time series model to explain the relationship between advertising expenditures of a country-wide fast-food franchise network with its weekly sales. Thanks to the flexibility and modularity of the model, it is well suited to generalization to other markets or situations. Its Bayesian nature facilitates incorporating \emph{a priori} information (the manager's views), which can be updated with relevant data. This aspect of the model will be used to present a strategy of budget scheduling across time and channels.
Project-Level Encoding for Neural Source Code Summarization of Subroutines
Mar 22, 2021
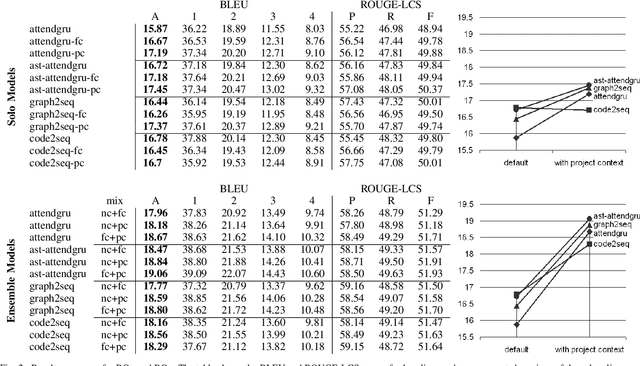
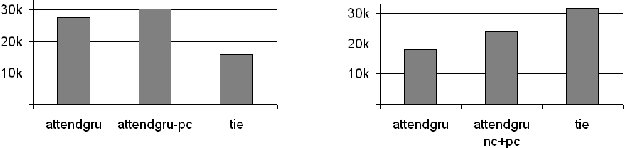
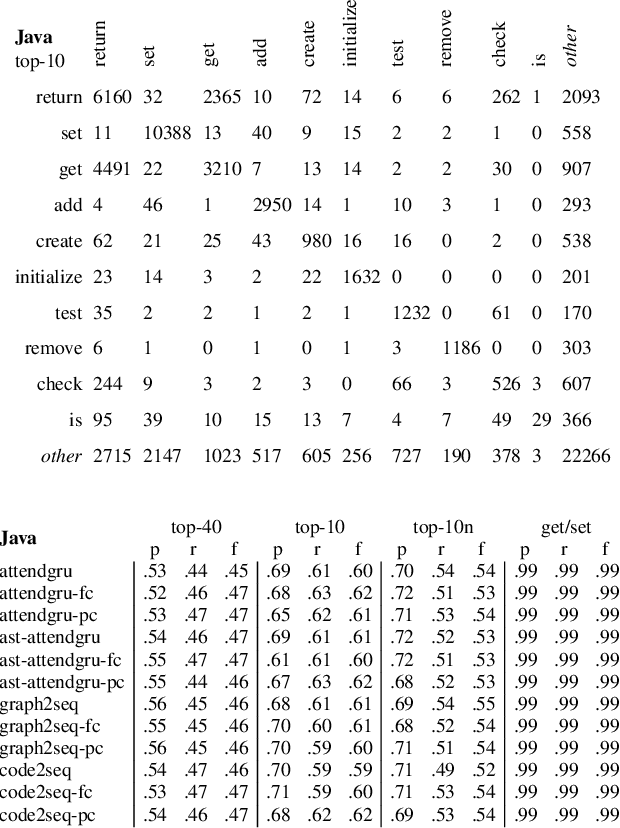
Source code summarization of a subroutine is the task of writing a short, natural language description of that subroutine. The description usually serves in documentation aimed at programmers, where even brief phrase (e.g. "compresses data to a zip file") can help readers rapidly comprehend what a subroutine does without resorting to reading the code itself. Techniques based on neural networks (and encoder-decoder model designs in particular) have established themselves as the state-of-the-art. Yet a problem widely recognized with these models is that they assume the information needed to create a summary is present within the code being summarized itself - an assumption which is at odds with program comprehension literature. Thus a current research frontier lies in the question of encoding source code context into neural models of summarization. In this paper, we present a project-level encoder to improve models of code summarization. By project-level, we mean that we create a vectorized representation of selected code files in a software project, and use that representation to augment the encoder of state-of-the-art neural code summarization techniques. We demonstrate how our encoder improves several existing models, and provide guidelines for maximizing improvement while controlling time and resource costs in model size.
Child-directed Listening: How Caregiver Inference Enables Children's Early Verbal Communication
Feb 09, 2021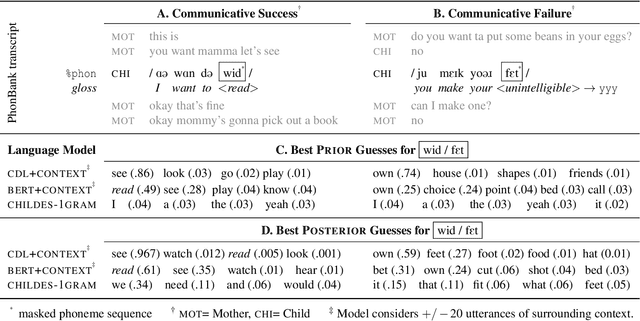
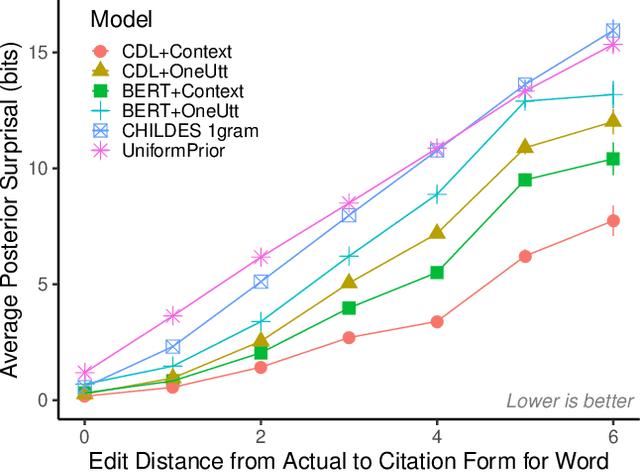
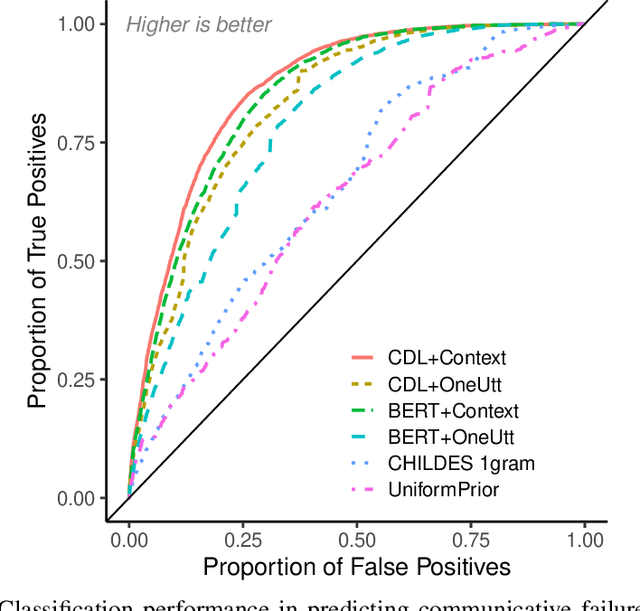
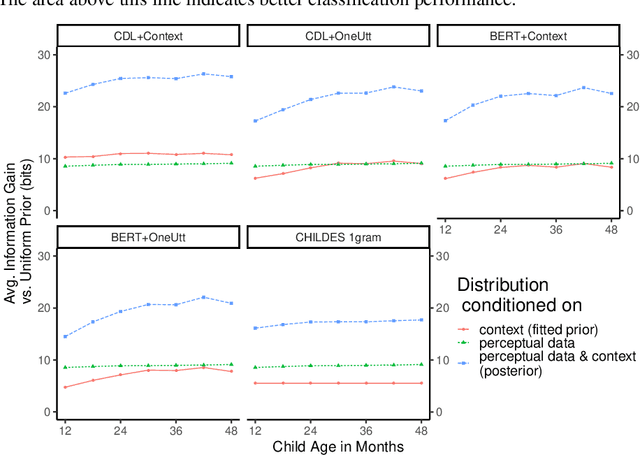
How do adults understand children's speech? Children's productions over the course of language development often bear little resemblance to typical adult pronunciations, yet caregivers nonetheless reliably recover meaning from them. Here, we employ a suite of Bayesian models of spoken word recognition to understand how adults overcome the noisiness of child language, showing that communicative success between children and adults relies heavily on adult inferential processes. By evaluating competing models on phonetically-annotated corpora, we show that adults' recovered meanings are best predicted by prior expectations fitted specifically to the child language environment, rather than to typical adult-adult language. After quantifying the contribution of this "child-directed listening" over developmental time, we discuss the consequences for theories of language acquisition, as well as the implications for commonly-used methods for assessing children's linguistic proficiency.
Towards Latent Space Based Manipulation of Elastic Rods using Autoencoder Models and Robust Centerline Extractions
Feb 09, 2021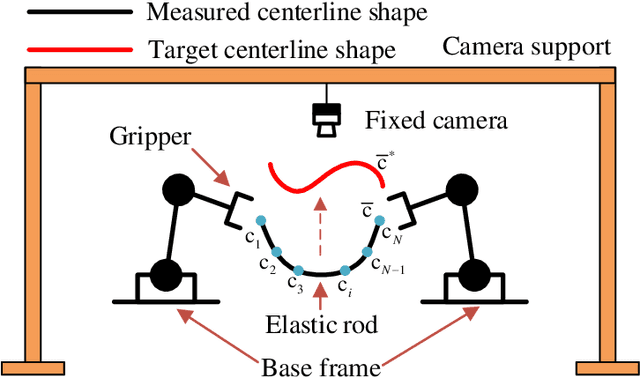
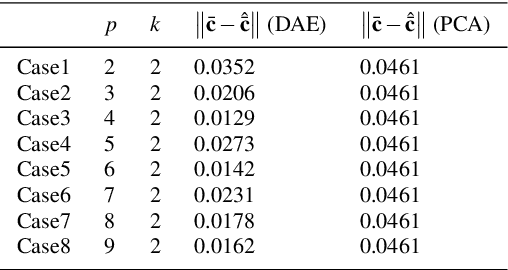
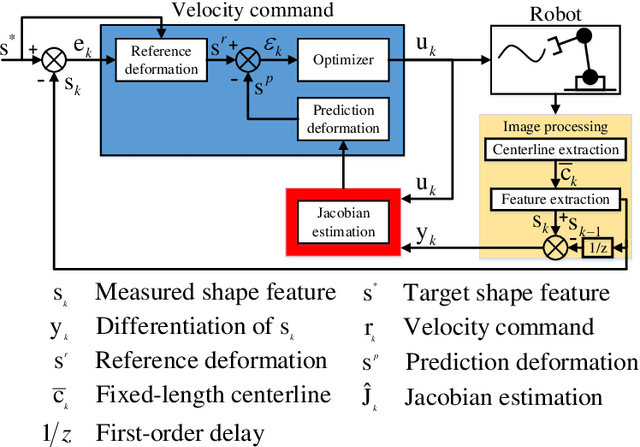
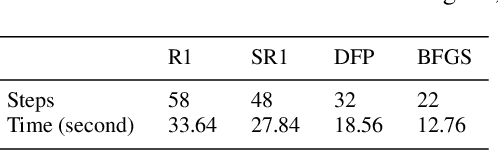
The automatic shape control of deformable objects is a challenging (and currently hot) manipulation problem due to their high-dimensional geometric features and complex physical properties. In this study, a new methodology to manipulate elastic rods automatically into 2D desired shapes is presented. An efficient vision-based controller that uses a deep autoencoder network is designed to compute a compact representation of the object's infinite-dimensional shape. An online algorithm that approximates the sensorimotor mapping between the robot's configuration and the object's shape features is used to deal with the latter's (typically unknown) mechanical properties. The proposed approach computes the rod's centerline from raw visual data in real-time by introducing an adaptive algorithm on the basis of a self-organizing network. Its effectiveness is thoroughly validated with simulations and experiments.
Principled Ultrasound Data Augmentation for Classification of Standard Planes
Mar 14, 2021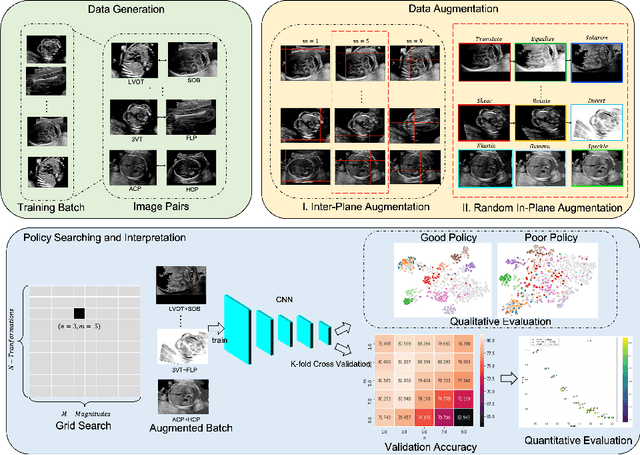



Deep learning models with large learning capacities often overfit to medical imaging datasets. This is because training sets are often relatively small due to the significant time and financial costs incurred in medical data acquisition and labelling. Data augmentation is therefore often used to expand the availability of training data and to increase generalization. However, augmentation strategies are often chosen on an ad-hoc basis without justification. In this paper, we present an augmentation policy search method with the goal of improving model classification performance. We include in the augmentation policy search additional transformations that are often used in medical image analysis and evaluate their performance. In addition, we extend the augmentation policy search to include non-linear mixed-example data augmentation strategies. Using these learned policies, we show that principled data augmentation for medical image model training can lead to significant improvements in ultrasound standard plane detection, with an an average F1-score improvement of 7.0% overall over naive data augmentation strategies in ultrasound fetal standard plane classification. We find that the learned representations of ultrasound images are better clustered and defined with optimized data augmentation.
Estimating causal effects of time-dependent exposures on a binary endpoint in a high-dimensional setting
Mar 29, 2018
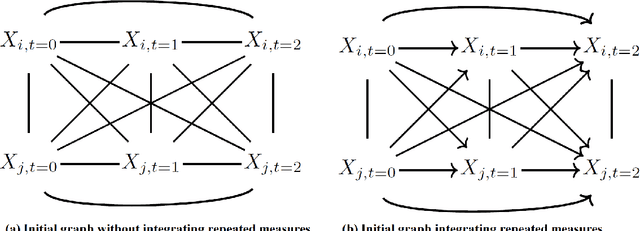
Recently, the intervention calculus when the DAG is absent (IDA) method was developed to estimate lower bounds of causal effects from observational high-dimensional data. Originally it was introduced to assess the effect of baseline biomarkers which do not vary over time. However, in many clinical settings, measurements of biomarkers are repeated at fixed time points during treatment exposure and, therefore, this method need to be extended. The purpose of this paper is then to extend the first step of the IDA, the Peter Clarks (PC)-algorithm, to a time-dependent exposure in the context of a binary outcome. We generalised the PC-algorithm for taking into account the chronological order of repeated measurements of the exposure and propose to apply the IDA with our new version, the chronologically ordered PC-algorithm (COPC-algorithm). A simulation study has been performed before applying the method for estimating causal effects of time-dependent immunological biomarkers on toxicity, death and progression in patients with metastatic melanoma. The simulation study showed that the completed partially directed acyclic graphs (CPDAGs) obtained using COPC-algorithm were structurally closer to the true CPDAG than CPDAGs obtained using PC-algorithm. Also, causal effects were more accurate when they were estimated based on CPDAGs obtained using COPC-algorithm. Moreover, CPDAGs obtained by COPC-algorithm allowed removing non-chronologic arrows with a variable measured at a time t pointing to a variable measured at a time t' where t'< t. Bidirected edges were less present in CPDAGs obtained with the COPC-algorithm, supporting the fact that there was less variability in causal effects estimated from these CPDAGs. The COPC-algorithm provided CPDAGs that keep the chronological structure present in the data, thus allowed to estimate lower bounds of the causal effect of time-dependent biomarkers.