 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Sentiment Analysis for Troll Detection on Weibo
Mar 07, 2021

The impact of social media on the modern world is difficult to overstate. Virtually all companies and public figures have social media accounts on popular platforms such as Twitter and Facebook. In China, the micro-blogging service provider, Sina Weibo, is the most popular such service. To influence public opinion, Weibo trolls -- the so called Water Army -- can be hired to post deceptive comments. In this paper, we focus on troll detection via sentiment analysis and other user activity data on the Sina Weibo platform. We implement techniques for Chinese sentence segmentation, word embedding, and sentiment score calculation. In recent years, troll detection and sentiment analysis have been studied, but we are not aware of previous research that considers troll detection based on sentiment analysis. We employ the resulting techniques to develop and test a sentiment analysis approach for troll detection, based on a variety of machine learning strategies. Experimental results are generated and analyzed. A Chrome extension is presented that implements our proposed technique, which enables real-time troll detection when a user browses Sina Weibo.
Denoise and Contrast for Category Agnostic Shape Completion
Mar 30, 2021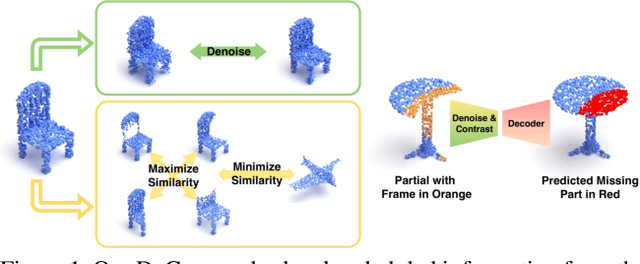
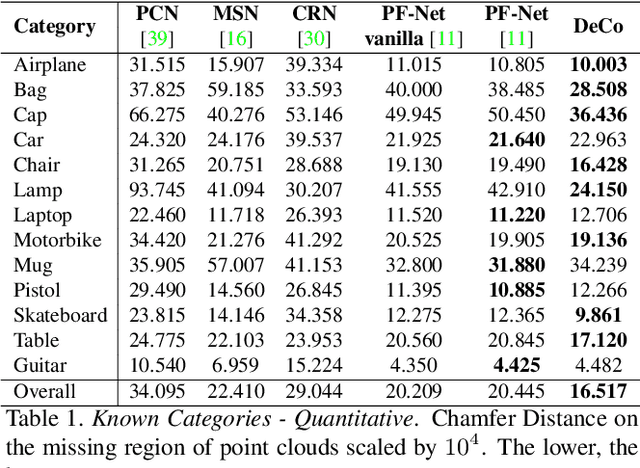
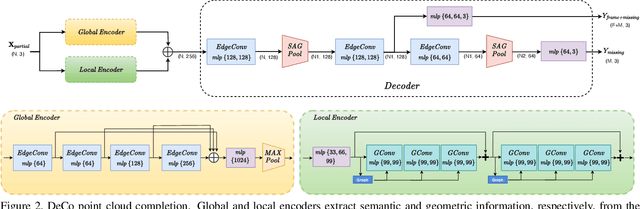
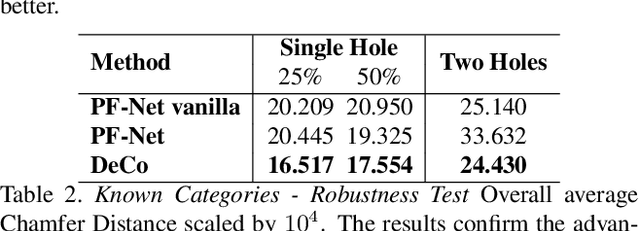
In this paper, we present a deep learning model that exploits the power of self-supervision to perform 3D point cloud completion, estimating the missing part and a context region around it. Local and global information are encoded in a combined embedding. A denoising pretext task provides the network with the needed local cues, decoupled from the high-level semantics and naturally shared over multiple classes. On the other hand, contrastive learning maximizes the agreement between variants of the same shape with different missing portions, thus producing a representation which captures the global appearance of the shape. The combined embedding inherits category-agnostic properties from the chosen pretext tasks. Differently from existing approaches, this allows to better generalize the completion properties to new categories unseen at training time. Moreover, while decoding the obtained joint representation, we better blend the reconstructed missing part with the partial shape by paying attention to its known surrounding region and reconstructing this frame as auxiliary objective. Our extensive experiments and detailed ablation on the ShapeNet dataset show the effectiveness of each part of the method with new state of the art results. Our quantitative and qualitative analysis confirms how our approach is able to work on novel categories without relying neither on classification and shape symmetry priors, nor on adversarial training procedures.
Application of Deep Learning in Recognizing Bates Numbers and Confidentiality Stamping from Images
Feb 05, 2021


In eDiscovery, it is critical to ensure that each page produced in legal proceedings conforms with the requirements of court or government agency production requests. Errors in productions could have severe consequences in a case, putting a party in an adverse position. The volume of pages produced continues to increase, and tremendous time and effort has been taken to ensure quality control of document productions. This has historically been a manual and laborious process. This paper demonstrates a novel automated production quality control application which leverages deep learning-based image recognition technology to extract Bates Number and Confidentiality Stamping from legal case production images and validate their correctness. Effectiveness of the method is verified with an experiment using a real-world production data.
SLOE: A Faster Method for Statistical Inference in High-Dimensional Logistic Regression
Mar 23, 2021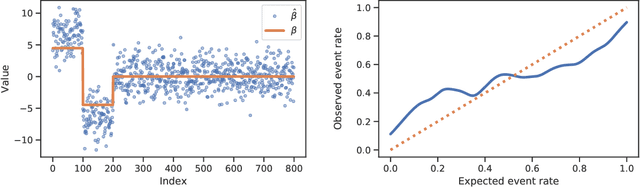
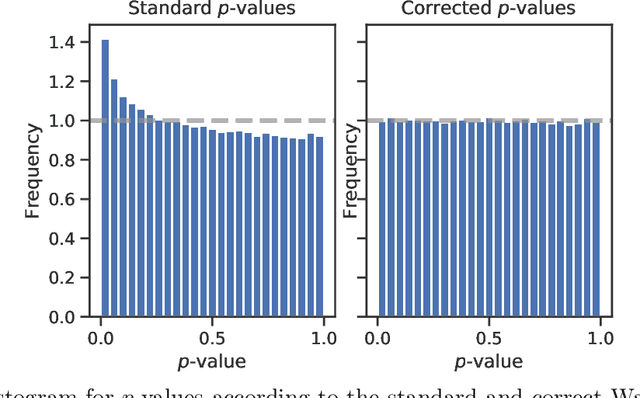
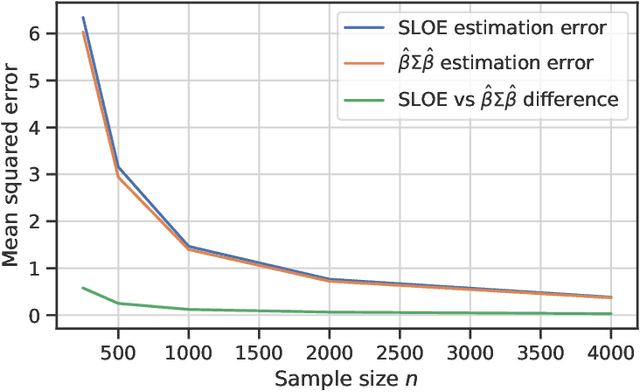
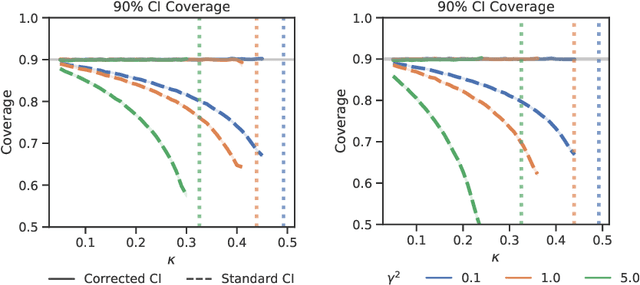
Logistic regression remains one of the most widely used tools in applied statistics, machine learning and data science. Practical datasets often have a substantial number of features $d$ relative to the sample size $n$. In these cases, the logistic regression maximum likelihood estimator (MLE) is biased, and its standard large-sample approximation is poor. In this paper, we develop an improved method for debiasing predictions and estimating frequentist uncertainty for such datasets. We build on recent work characterizing the asymptotic statistical behavior of the MLE in the regime where the aspect ratio $d / n$, instead of the number of features $d$, remains fixed as $n$ grows. In principle, this approximation facilitates bias and uncertainty corrections, but in practice, these corrections require an estimate of the signal strength of the predictors. Our main contribution is SLOE, an estimator of the signal strength with convergence guarantees that reduces the computation time of estimation and inference by orders of magnitude. The bias correction that this facilitates also reduces the variance of the predictions, yielding narrower confidence intervals with higher (valid) coverage of the true underlying probabilities and parameters. We provide an open source package for this method, available at https://github.com/google-research/sloe-logistic.
Fatigued Random Walks in Hypergraphs: A Neuronal Analogy to Improve Retrieval Performance
Apr 12, 2021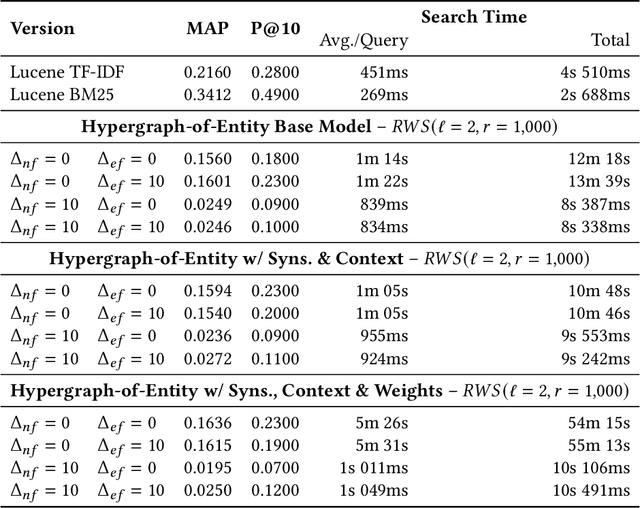
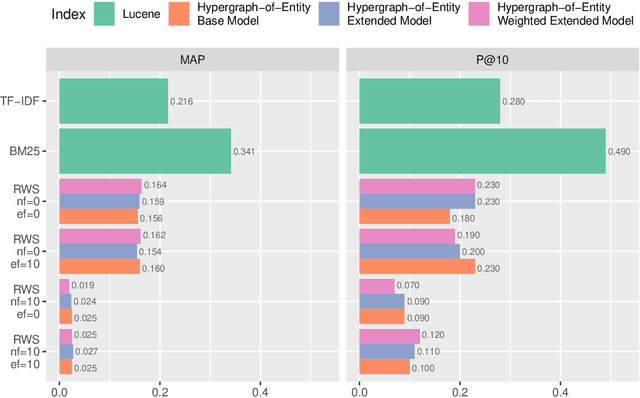
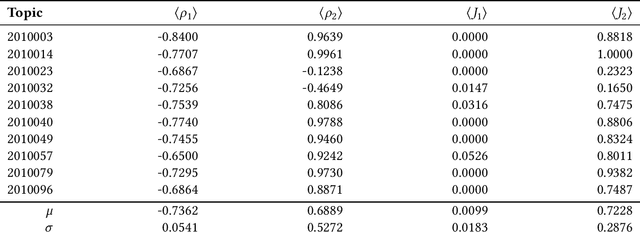
Hypergraphs are data structures capable of capturing supra-dyadic relations. We can use them to model binary relations, but also to model groups of entities, as well as the intersections between these groups or the contained subgroups. In previous work, we explored the usage of hypergraphs as an indexing data structure, in particular one that was capable of seamlessly integrating text, entities and their relations to support entity-oriented search tasks. As more information is added to the hypergraph, however, it not only increases in size, but it also becomes denser, making the task of efficiently ranking nodes or hyperedges more complex. Random walks can effectively capture network structure, without compromising performance, or at least providing a tunable balance between efficiency and effectiveness, within a nondeterministic universe. For a higher effectiveness, a higher number of random walks is usually required, which often results in lower efficiency. Inspired by von Neumann and the neuron in the brain, we propose and study the usage of node and hyperedge fatigue as a way to temporarily constrict random walks during keyword-based ad hoc retrieval. We found that we were able to improve search time by a factor of 32, but also worsen MAP by a factor of 8. Moreover, by distinguishing between fatigue in nodes and hyperedges, we are able to find that, for hyperedge ranking tasks, we consistently obtained lower MAP scores when increasing fatigue for nodes. On the other hand, the overall impact of hyperedge fatigue was slightly positive, although it also slightly worsened efficiency.
Grounding Physical Concepts of Objects and Events Through Dynamic Visual Reasoning
Mar 30, 2021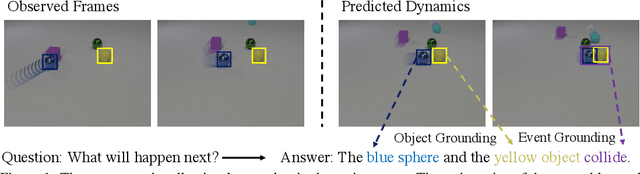
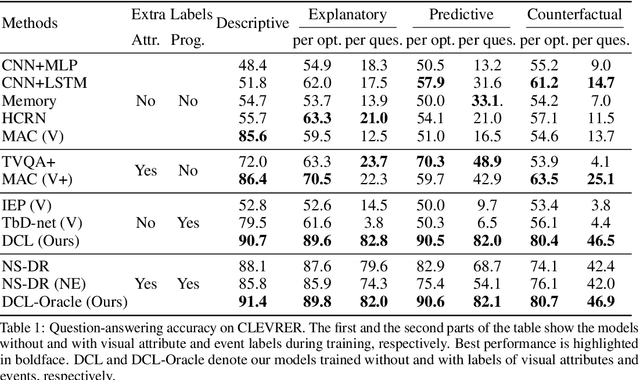
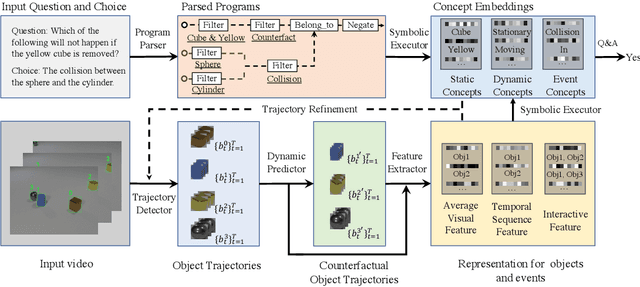

We study the problem of dynamic visual reasoning on raw videos. This is a challenging problem; currently, state-of-the-art models often require dense supervision on physical object properties and events from simulation, which are impractical to obtain in real life. In this paper, we present the Dynamic Concept Learner (DCL), a unified framework that grounds physical objects and events from video and language. DCL first adopts a trajectory extractor to track each object over time and to represent it as a latent, object-centric feature vector. Building upon this object-centric representation, DCL learns to approximate the dynamic interaction among objects using graph networks. DCL further incorporates a semantic parser to parse questions into semantic programs and, finally, a program executor to run the program to answer the question, levering the learned dynamics model. After training, DCL can detect and associate objects across the frames, ground visual properties, and physical events, understand the causal relationship between events, make future and counterfactual predictions, and leverage these extracted presentations for answering queries. DCL achieves state-of-the-art performance on CLEVRER, a challenging causal video reasoning dataset, even without using ground-truth attributes and collision labels from simulations for training. We further test DCL on a newly proposed video-retrieval and event localization dataset derived from CLEVRER, showing its strong generalization capacity.
Pre-training strategies and datasets for facial representation learning
Mar 30, 2021
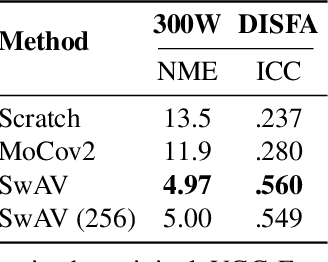
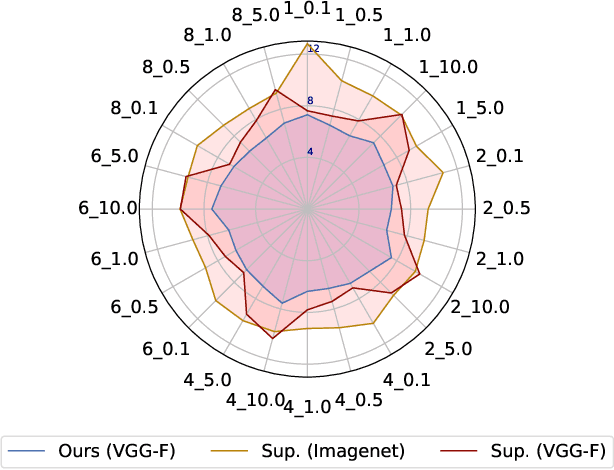
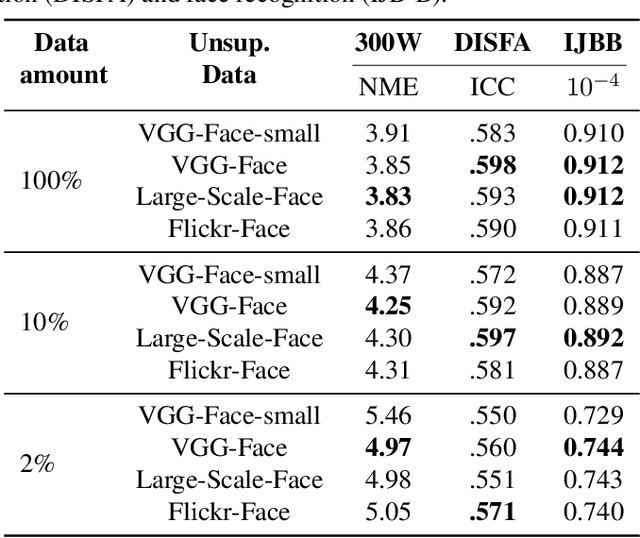
What is the best way to learn a universal face representation? Recent work on Deep Learning in the area of face analysis has focused on supervised learning for specific tasks of interest (e.g. face recognition, facial landmark localization etc.) but has overlooked the overarching question of how to find a facial representation that can be readily adapted to several facial analysis tasks and datasets. To this end, we make the following 4 contributions: (a) we introduce, for the first time, a comprehensive evaluation benchmark for facial representation learning consisting of 5 important face analysis tasks. (b) We systematically investigate two ways of large-scale representation learning applied to faces: supervised and unsupervised pre-training. Importantly, we focus our evaluations on the case of few-shot facial learning. (c) We investigate important properties of the training datasets including their size and quality (labelled, unlabelled or even uncurated). (d) To draw our conclusions, we conducted a very large number of experiments. Our main two findings are: (1) Unsupervised pre-training on completely in-the-wild, uncurated data provides consistent and, in some cases, significant accuracy improvements for all facial tasks considered. (2) Many existing facial video datasets seem to have a large amount of redundancy. We will release code, pre-trained models and data to facilitate future research.
Objective-Based Hierarchical Clustering of Deep Embedding Vectors
Dec 15, 2020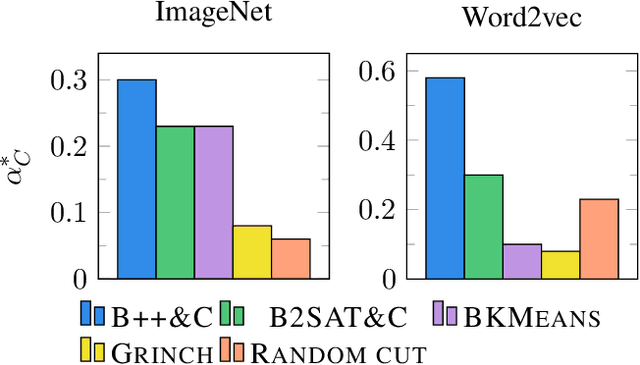
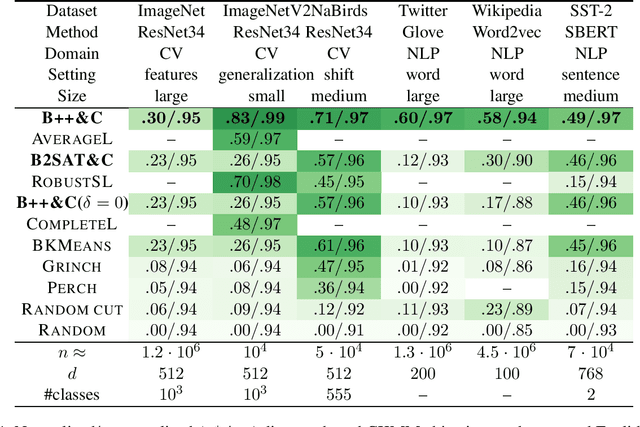
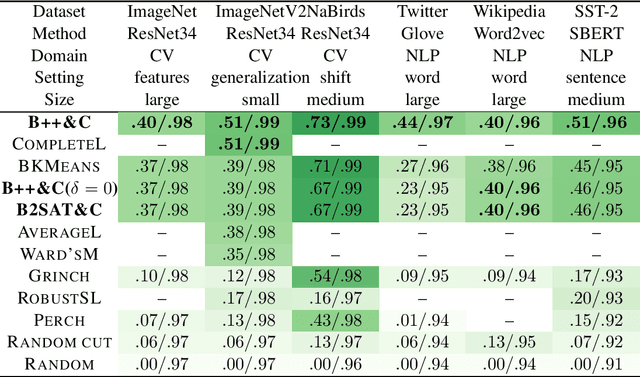
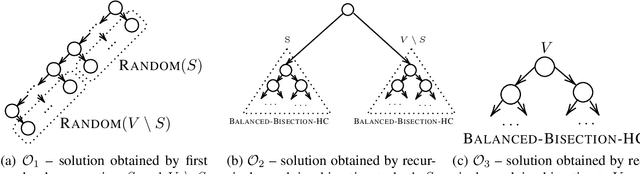
We initiate a comprehensive experimental study of objective-based hierarchical clustering methods on massive datasets consisting of deep embedding vectors from computer vision and NLP applications. This includes a large variety of image embedding (ImageNet, ImageNetV2, NaBirds), word embedding (Twitter, Wikipedia), and sentence embedding (SST-2) vectors from several popular recent models (e.g. ResNet, ResNext, Inception V3, SBERT). Our study includes datasets with up to $4.5$ million entries with embedding dimensions up to $2048$. In order to address the challenge of scaling up hierarchical clustering to such large datasets we propose a new practical hierarchical clustering algorithm B++&C. It gives a 5%/20% improvement on average for the popular Moseley-Wang (MW) / Cohen-Addad et al. (CKMM) objectives (normalized) compared to a wide range of classic methods and recent heuristics. We also introduce a theoretical algorithm B2SAT&C which achieves a $0.74$-approximation for the CKMM objective in polynomial time. This is the first substantial improvement over the trivial $2/3$-approximation achieved by a random binary tree. Prior to this work, the best poly-time approximation of $\approx 2/3 + 0.0004$ was due to Charikar et al. (SODA'19).
SIMstack: A Generative Shape and Instance Model for Unordered Object Stacks
Mar 30, 2021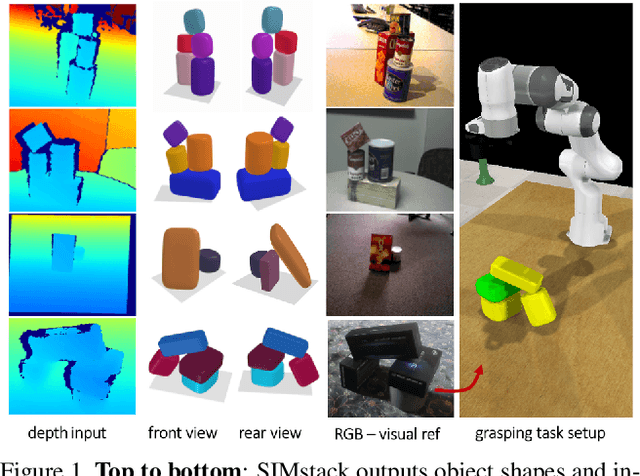
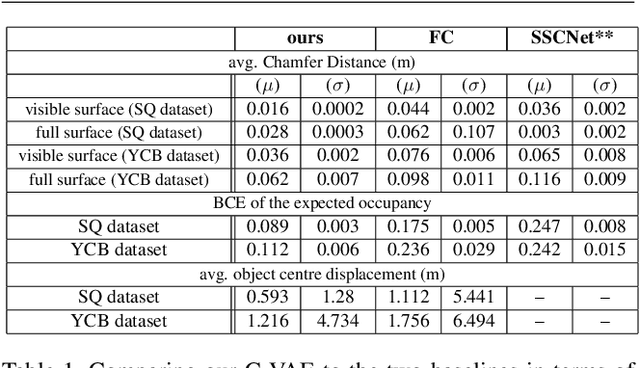
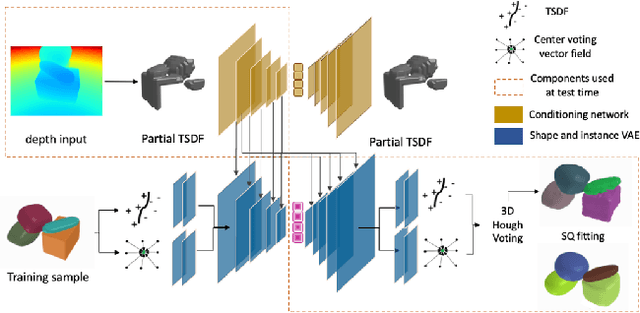

By estimating 3D shape and instances from a single view, we can capture information about an environment quickly, without the need for comprehensive scanning and multi-view fusion. Solving this task for composite scenes (such as object stacks) is challenging: occluded areas are not only ambiguous in shape but also in instance segmentation; multiple decompositions could be valid. We observe that physics constrains decomposition as well as shape in occluded regions and hypothesise that a latent space learned from scenes built under physics simulation can serve as a prior to better predict shape and instances in occluded regions. To this end we propose SIMstack, a depth-conditioned Variational Auto-Encoder (VAE), trained on a dataset of objects stacked under physics simulation. We formulate instance segmentation as a centre voting task which allows for class-agnostic detection and doesn't require setting the maximum number of objects in the scene. At test time, our model can generate 3D shape and instance segmentation from a single depth view, probabilistically sampling proposals for the occluded region from the learned latent space. Our method has practical applications in providing robots some of the ability humans have to make rapid intuitive inferences of partially observed scenes. We demonstrate an application for precise (non-disruptive) object grasping of unknown objects from a single depth view.
Financial Series Prediction: Comparison Between Precision of Time Series Models and Machine Learning Methods
Dec 25, 2017

Precise financial series predicting has long been a difficult problem because of unstableness and many noises within the series. Although Traditional time series models like ARIMA and GARCH have been researched and proved to be effective in predicting, their performances are still far from satisfying. Machine Learning, as an emerging research field in recent years, has brought about many incredible improvements in tasks such as regressing and classifying, and it's also promising to exploit the methodology in financial time series predicting. In this paper, the predicting precision of financial time series between traditional time series models and mainstream machine learning models including some state-of-the-art ones of deep learning are compared through experiment using real stock index data from history. The result shows that machine learning as a modern method far surpasses traditional models in precision.