 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Greenhouse: A Zero-Positive Machine Learning System for Time-Series Anomaly Detection
Feb 11, 2018
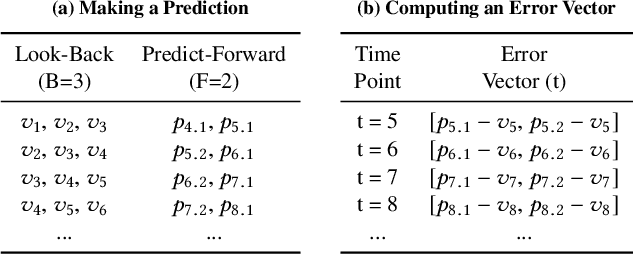
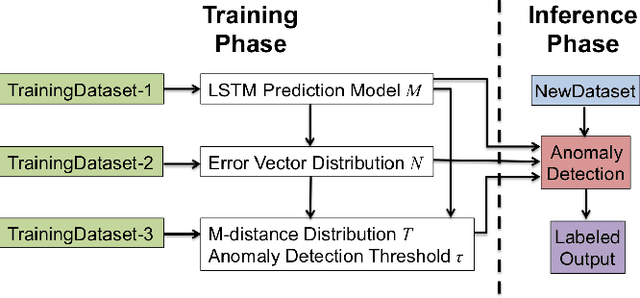
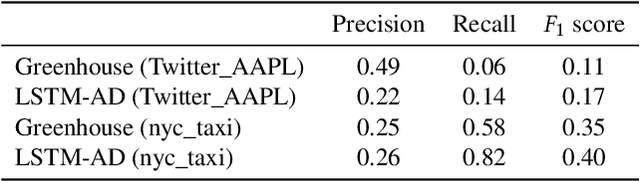
This short paper describes our ongoing research on Greenhouse - a zero-positive machine learning system for time-series anomaly detection.
Model-free prediction of noisy chaotic time series by deep learning
Sep 29, 2017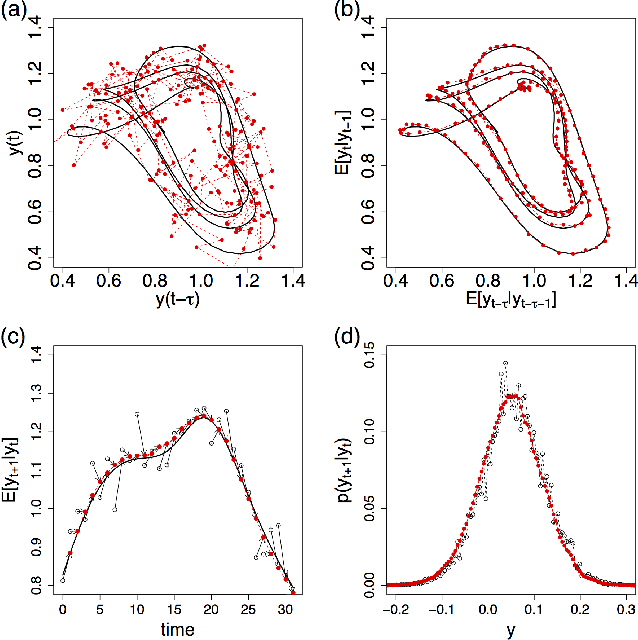
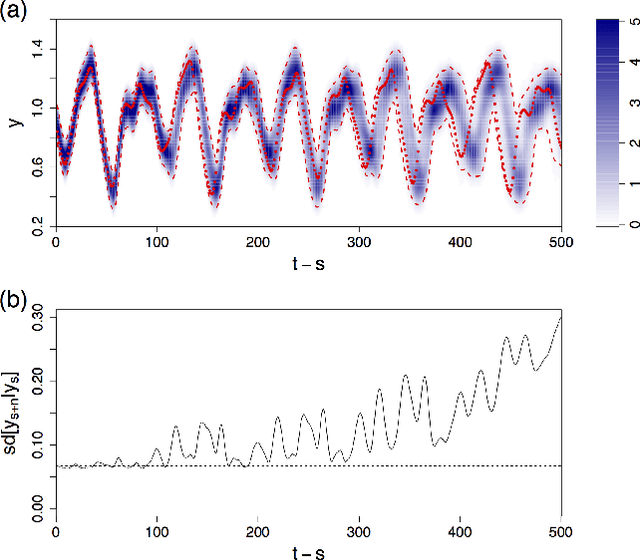
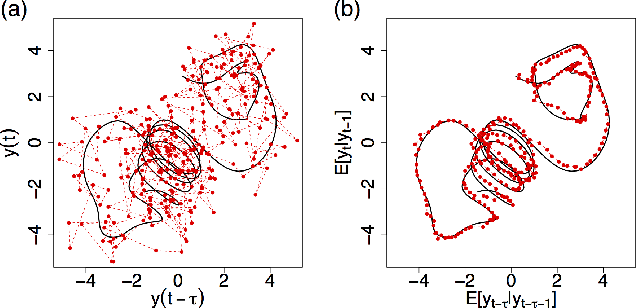
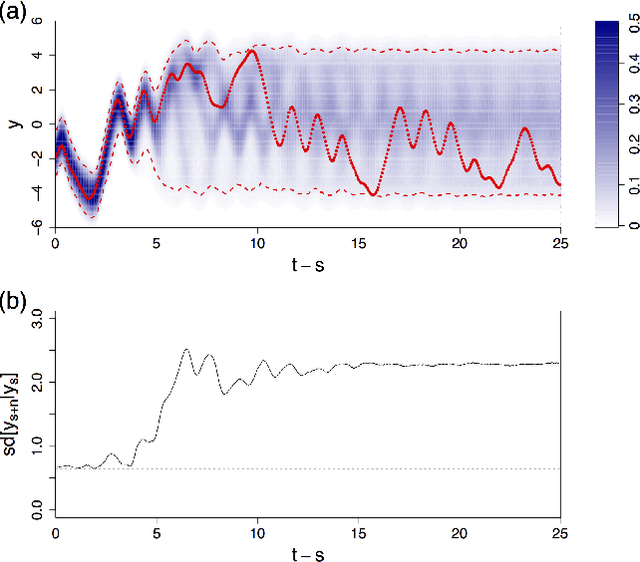
We present a deep neural network for a model-free prediction of a chaotic dynamical system from noisy observations. The proposed deep learning model aims to predict the conditional probability distribution of a state variable. The Long Short-Term Memory network (LSTM) is employed to model the nonlinear dynamics and a softmax layer is used to approximate a probability distribution. The LSTM model is trained by minimizing a regularized cross-entropy function. The LSTM model is validated against delay-time chaotic dynamical systems, Mackey-Glass and Ikeda equations. It is shown that the present LSTM makes a good prediction of the nonlinear dynamics by effectively filtering out the noise. It is found that the prediction uncertainty of a multiple-step forecast of the LSTM model is not a monotonic function of time; the predicted standard deviation may increase or decrease dynamically in time.
Amata: An Annealing Mechanism for Adversarial Training Acceleration
Dec 15, 2020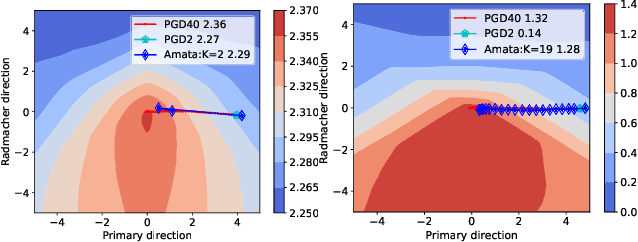
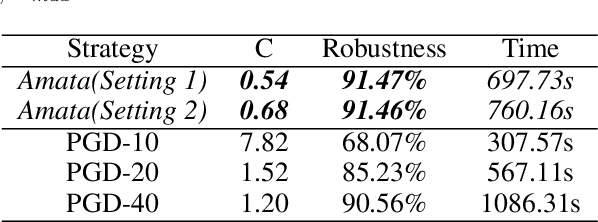
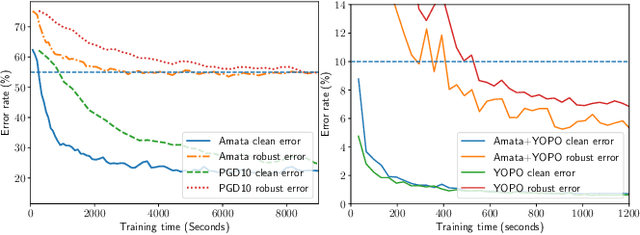
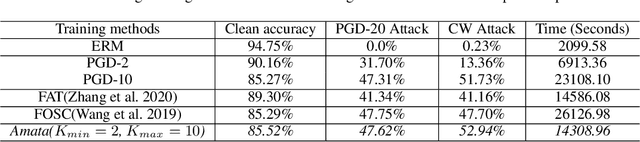
Despite the empirical success in various domains, it has been revealed that deep neural networks are vulnerable to maliciously perturbed input data that much degrade their performance. This is known as adversarial attacks. To counter adversarial attacks, adversarial training formulated as a form of robust optimization has been demonstrated to be effective. However, conducting adversarial training brings much computational overhead compared with standard training. In order to reduce the computational cost, we propose an annealing mechanism, Amata, to reduce the overhead associated with adversarial training. The proposed Amata is provably convergent, well-motivated from the lens of optimal control theory and can be combined with existing acceleration methods to further enhance performance. It is demonstrated that on standard datasets, Amata can achieve similar or better robustness with around 1/3 to 1/2 the computational time compared with traditional methods. In addition, Amata can be incorporated into other adversarial training acceleration algorithms (e.g. YOPO, Free, Fast, and ATTA), which leads to further reduction in computational time on large-scale problems.
From Shadow Generation to Shadow Removal
Mar 24, 2021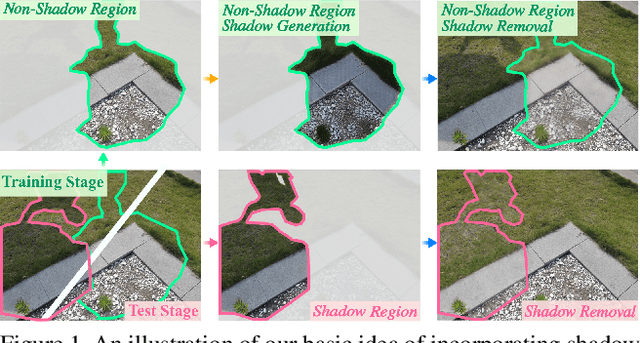
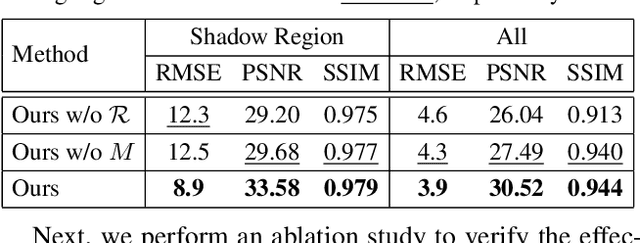
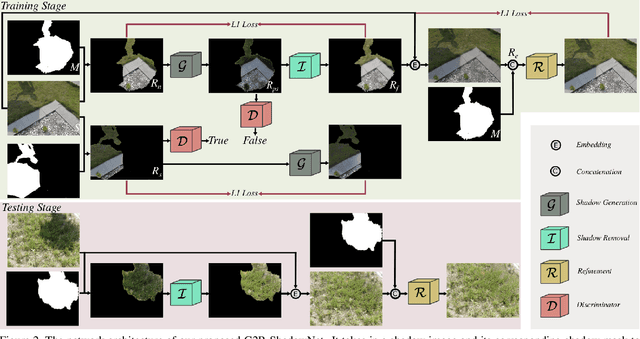
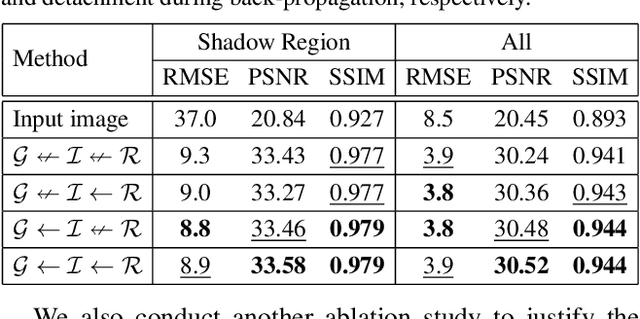
Shadow removal is a computer-vision task that aims to restore the image content in shadow regions. While almost all recent shadow-removal methods require shadow-free images for training, in ECCV 2020 Le and Samaras introduces an innovative approach without this requirement by cropping patches with and without shadows from shadow images as training samples. However, it is still laborious and time-consuming to construct a large amount of such unpaired patches. In this paper, we propose a new G2R-ShadowNet which leverages shadow generation for weakly-supervised shadow removal by only using a set of shadow images and their corresponding shadow masks for training. The proposed G2R-ShadowNet consists of three sub-networks for shadow generation, shadow removal and refinement, respectively and they are jointly trained in an end-to-end fashion. In particular, the shadow generation sub-net stylises non-shadow regions to be shadow ones, leading to paired data for training the shadow-removal sub-net. Extensive experiments on the ISTD dataset and the Video Shadow Removal dataset show that the proposed G2R-ShadowNet achieves competitive performances against the current state of the arts and outperforms Le and Samaras' patch-based shadow-removal method.
Panoptic Lintention Network: Towards Efficient Navigational Perception for the Visually Impaired
Mar 06, 2021
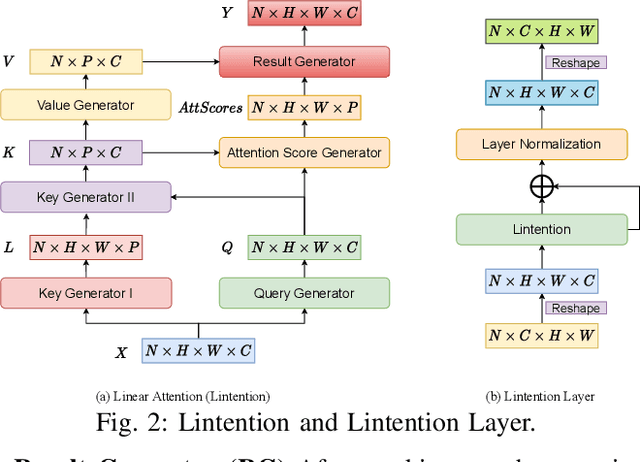


Classic computer vision algorithms, instance segmentation, and semantic segmentation can not provide a holistic understanding of the surroundings for the visually impaired. In this paper, we utilize panoptic segmentation to assist the navigation of visually impaired people by offering both things and stuff awareness in the proximity of the visually impaired efficiently. To this end, we propose an efficient Attention module -- Lintention which can model long-range interactions in linear time using linear space. Based on Lintention, we then devise a novel panoptic segmentation model which we term Panoptic Lintention Net. Experiments on the COCO dataset indicate that the Panoptic Lintention Net raises the Panoptic Quality (PQ) from 39.39 to 41.42 with 4.6\% performance gain while only requiring 10\% fewer GFLOPs and 25\% fewer parameters in the semantic branch. Furthermore, a real-world test via our designed compact wearable panoptic segmentation system, indicates that our system based on the Panoptic Lintention Net accomplishes a relatively stable and exceptionally remarkable panoptic segmentation in real-world scenes.
Offshore Software Maintenance Outsourcing Predicting Clients Proposal using Supervised Learning
Mar 01, 2021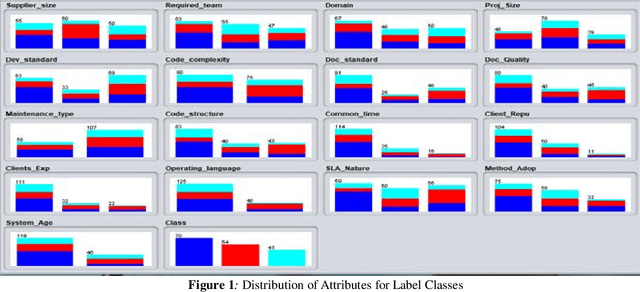
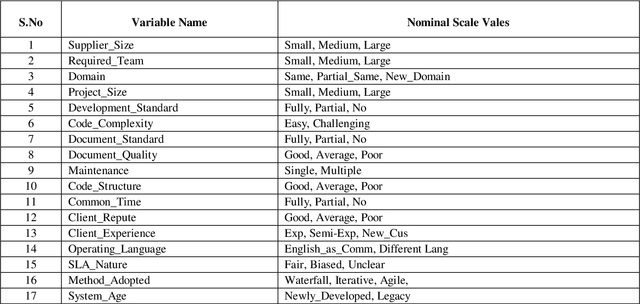
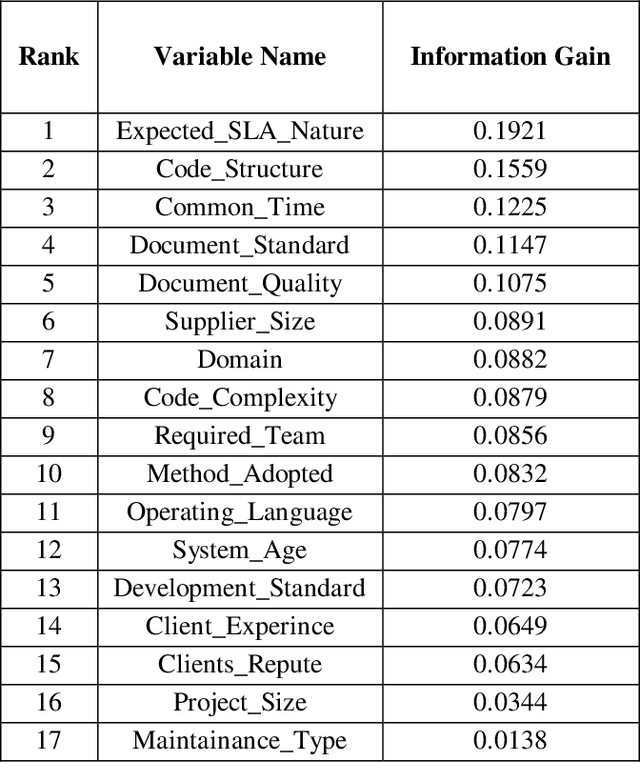
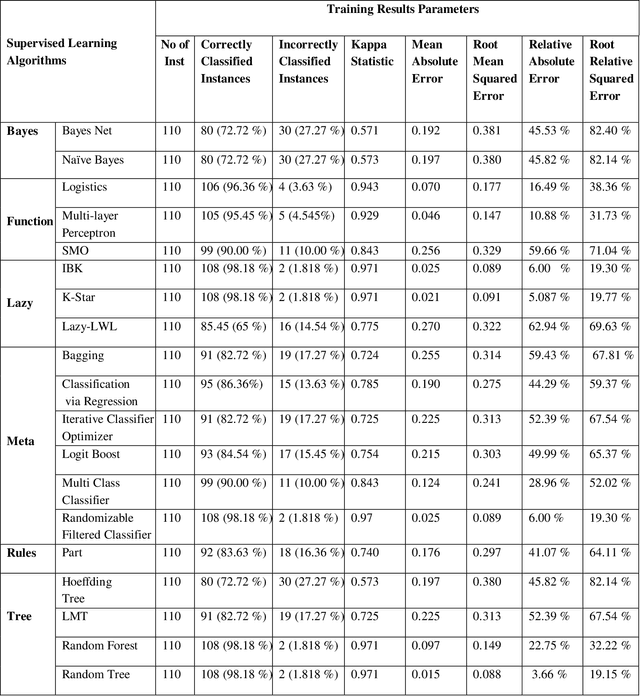
In software engineering, software maintenance is the process of correction, updating, and improvement of software products after handed over to the customer. Through offshore software maintenance outsourcing clients can get advantages like reduce cost, save time, and improve quality. In most cases, the OSMO vendor generates considerable revenue. However, the selection of an appropriate proposal among multiple clients is one of the critical problems for OSMO vendors. The purpose of this paper is to suggest an effective machine learning technique that can be used by OSMO vendors to assess or predict the OSMO client proposal. The dataset is generated through a survey of OSMO vendors working in a developing country. The results showed that supervised learning-based classifiers like Na\"ive Bayesian, SMO, Logistics apprehended 69.75, 81.81, and 87.27 percent testing accuracy respectively. This study concludes that supervised learning is the most suitable technique to predict the OSMO client's proposal.
* 10 pages, 2 figures
LRG at TREC 2020: Document Ranking with XLNet-Based Models
Mar 06, 2021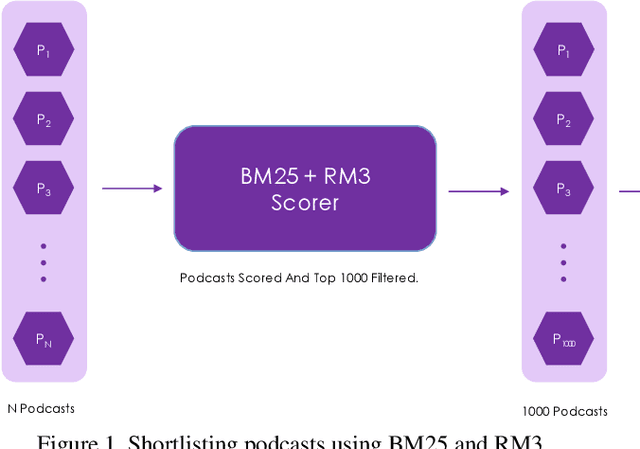

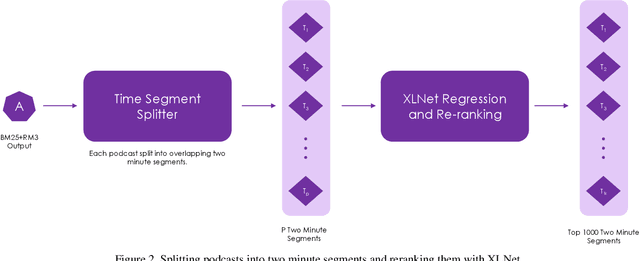
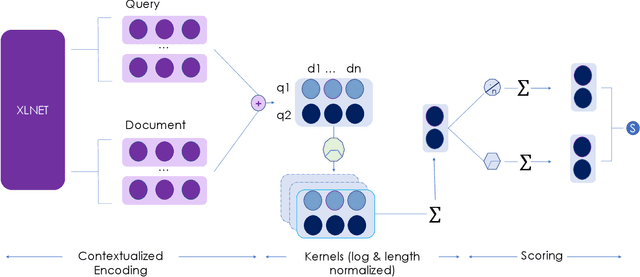
Establishing a good information retrieval system in popular mediums of entertainment is a quickly growing area of investigation for companies and researchers alike. We delve into the domain of information retrieval for podcasts. In Spotify's Podcast Challenge, we are given a user's query with a description to find the most relevant short segment from the given dataset having all the podcasts. Previous techniques that include solely classical Information Retrieval (IR) techniques, perform poorly when descriptive queries are presented. On the other hand, models which exclusively rely on large neural networks tend to perform better. The downside to this technique is that a considerable amount of time and computing power are required to infer the result. We experiment with two hybrid models which first filter out the best podcasts based on user's query with a classical IR technique, and then perform re-ranking on the shortlisted documents based on the detailed description using a transformer-based model.
* Published at TREC 2020
Separating Stimulus-Induced and Background Components of Dynamic Functional Connectivity in Naturalistic fMRI
Jan 24, 2021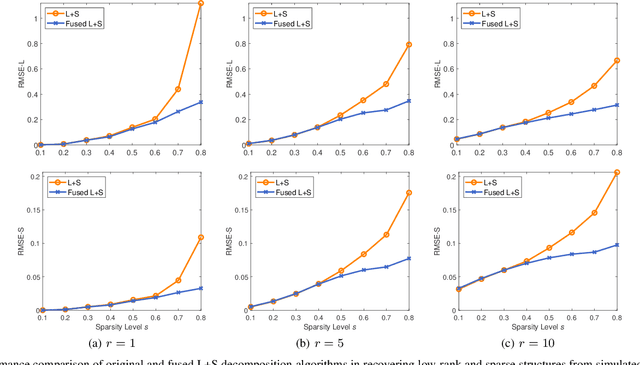
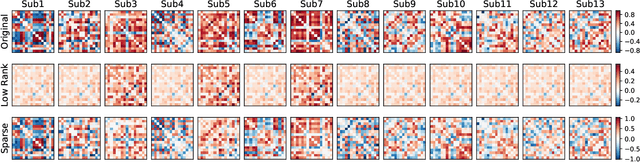
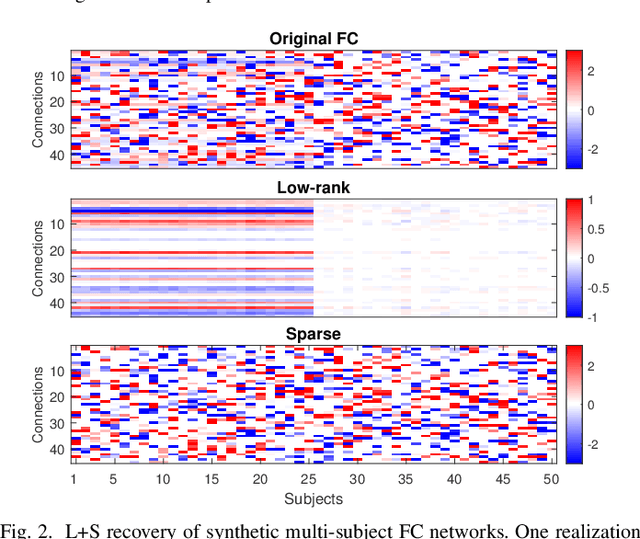
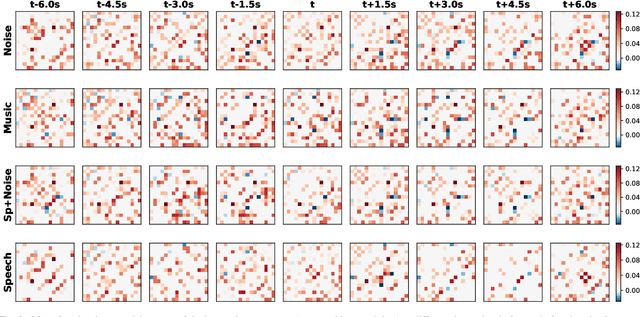
We consider the challenges in extracting stimulus-related neural dynamics from other intrinsic processes and noise in naturalistic functional magnetic resonance imaging (fMRI). Most studies rely on inter-subject correlations (ISC) of low-level regional activity and neglect varying responses in individuals. We propose a novel, data-driven approach based on low-rank plus sparse (L+S) decomposition to isolate stimulus-driven dynamic changes in brain functional connectivity (FC) from the background noise, by exploiting shared network structure among subjects receiving the same naturalistic stimuli. The time-resolved multi-subject FC matrices are modeled as a sum of a low-rank component of correlated FC patterns across subjects, and a sparse component of subject-specific, idiosyncratic background activities. To recover the shared low-rank subspace, we introduce a fused version of principal component pursuit (PCP) by adding a fusion-type penalty on the differences between the rows of the low-rank matrix. The method improves the detection of stimulus-induced group-level homogeneity in the FC profile while capturing inter-subject variability. We develop an efficient algorithm via a linearized alternating direction method of multipliers to solve the fused-PCP. Simulations show accurate recovery by the fused-PCP even when a large fraction of FC edges are severely corrupted. When applied to natural fMRI data, our method reveals FC changes that were time-locked to auditory processing during movie watching, with dynamic engagement of sensorimotor systems for speech-in-noise. It also provides a better mapping to auditory content in the movie than ISC.
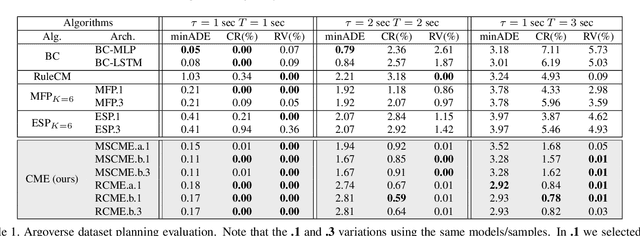
Learn-to-Race: A Multimodal Control Environment for Autonomous Racing
Mar 31, 2021
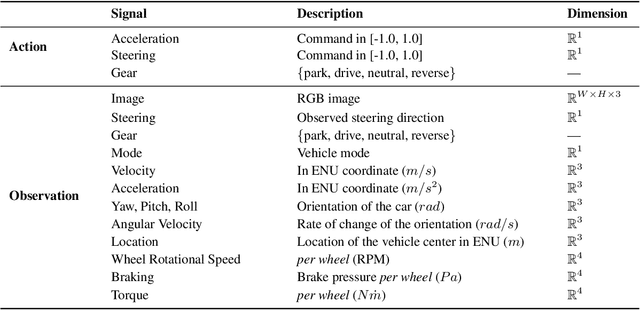
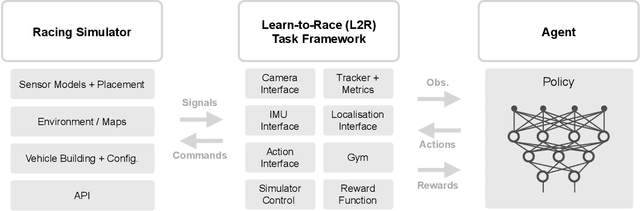

Existing research on autonomous driving primarily focuses on urban driving, which is insufficient for characterising the complex driving behaviour underlying high-speed racing. At the same time, existing racing simulation frameworks struggle in capturing realism, with respect to visual rendering, vehicular dynamics, and task objectives, inhibiting the transfer of learning agents to real-world contexts. We introduce a new environment, where agents Learn-to-Race (L2R) in simulated competition-style racing, using multimodal information--from virtual cameras to a comprehensive array of inertial measurement sensors. Our environment, which includes a simulator and an interfacing training framework, accurately models vehicle dynamics and racing conditions. In this paper, we release the Arrival simulator for autonomous racing. Next, we propose the L2R task with challenging metrics, inspired by learning-to-drive challenges, Formula-style racing, and multimodal trajectory prediction for autonomous driving. Additionally, we provide the L2R framework suite, facilitating simulated racing on high-precision models of real-world tracks, such as the famed Thruxton Circuit and the Las Vegas Motor Speedway. Finally, we provide an official L2R task dataset of expert demonstrations, as well as a series of baseline experiments and reference implementations. We make all code available: https://github.com/hermgerm29/learn-to-race
Self-Supervised Simultaneous Multi-Step Prediction of Road Dynamics and Cost Map
Mar 01, 2021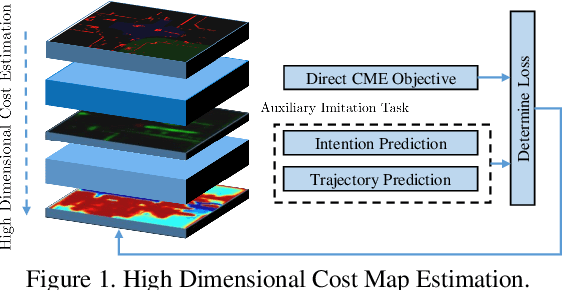
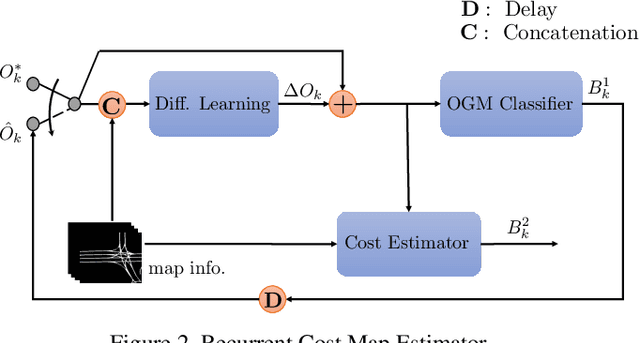
While supervised learning is widely used for perception modules in conventional autonomous driving solutions, scalability is hindered by the huge amount of data labeling needed. In contrast, while end-to-end architectures do not require labeled data and are potentially more scalable, interpretability is sacrificed. We introduce a novel architecture that is trained in a fully self-supervised fashion for simultaneous multi-step prediction of space-time cost map and road dynamics. Our solution replaces the manually designed cost function for motion planning with a learned high dimensional cost map that is naturally interpretable and allows diverse contextual information to be integrated without manual data labeling. Experiments on real world driving data show that our solution leads to lower number of collisions and road violations in long planning horizons in comparison to baselines, demonstrating the feasibility of fully self-supervised prediction without sacrificing either scalability or interpretability.