 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Area Modeling using Stay Information for Large-Scale Users and Analysis for Influence of COVID-19
Jan 19, 2024
Understanding how people use area in a city can be a valuable information in a wide range of fields, from marketing to urban planning. Area usage is subject to change over time due to various events including seasonal shifts and pandemics. Before the spread of smartphones, this data had been collected through questionnaire survey. However, this is not a sustainable approach in terms of time to results and cost. There are many existing studies on area modeling, which characterize an area with some kind of information, using Point of Interest (POI) or inter-area movement data. However, since POI is data that is statically tied to space, and inter-area movement data ignores the behavior of people within an area, existing methods are not sufficient in terms of capturing area usage changes. In this paper, we propose a novel area modeling method named Area2Vec, inspired by Word2Vec, which models areas based on people's location data. This method is based on the discovery that it is possible to characterize an area based on its usage by using people's stay information in the area. And it is a novel method that can reflect the dynamically changing people's behavior in an area in the modeling results. We validated Area2vec by performing a functional classification of areas in a district of Japan. The results show that Area2Vec can be usable in general area analysis. We also investigated area usage changes due to COVID-19 in two districts in Japan. We could find that COVID-19 made people refrain from unnecessary going out, such as visiting entertainment areas.
Learning a Prior for Monte Carlo Search by Replaying Solutions to Combinatorial Problems
Jan 19, 2024Monte Carlo Search gives excellent results in multiple difficult combinatorial problems. Using a prior to perform non uniform playouts during the search improves a lot the results compared to uniform playouts. Handmade heuristics tailored to the combinatorial problem are often used as priors. We propose a method to automatically compute a prior. It uses statistics on solved problems. It is a simple and general method that incurs no computational cost at playout time and that brings large performance gains. The method is applied to three difficult combinatorial problems: Latin Square Completion, Kakuro, and Inverse RNA Folding.
STanHop: Sparse Tandem Hopfield Model for Memory-Enhanced Time Series Prediction
Dec 28, 2023We present STanHop-Net (Sparse Tandem Hopfield Network) for multivariate time series prediction with memory-enhanced capabilities. At the heart of our approach is STanHop, a novel Hopfield-based neural network block, which sparsely learns and stores both temporal and cross-series representations in a data-dependent fashion. In essence, STanHop sequentially learn temporal representation and cross-series representation using two tandem sparse Hopfield layers. In addition, StanHop incorporates two additional external memory modules: a Plug-and-Play module and a Tune-and-Play module for train-less and task-aware memory-enhancements, respectively. They allow StanHop-Net to swiftly respond to certain sudden events. Methodologically, we construct the StanHop-Net by stacking STanHop blocks in a hierarchical fashion, enabling multi-resolution feature extraction with resolution-specific sparsity. Theoretically, we introduce a sparse extension of the modern Hopfield model (Generalized Sparse Modern Hopfield Model) and show that it endows a tighter memory retrieval error compared to the dense counterpart without sacrificing memory capacity. Empirically, we validate the efficacy of our framework on both synthetic and real-world settings.
FedRSU: Federated Learning for Scene Flow Estimation on Roadside Units
Jan 23, 2024Roadside unit (RSU) can significantly improve the safety and robustness of autonomous vehicles through Vehicle-to-Everything (V2X) communication. Currently, the usage of a single RSU mainly focuses on real-time inference and V2X collaboration, while neglecting the potential value of the high-quality data collected by RSU sensors. Integrating the vast amounts of data from numerous RSUs can provide a rich source of data for model training. However, the absence of ground truth annotations and the difficulty of transmitting enormous volumes of data are two inevitable barriers to fully exploiting this hidden value. In this paper, we introduce FedRSU, an innovative federated learning framework for self-supervised scene flow estimation. In FedRSU, we present a recurrent self-supervision training paradigm, where for each RSU, the scene flow prediction of points at every timestamp can be supervised by its subsequent future multi-modality observation. Another key component of FedRSU is federated learning, where multiple devices collaboratively train an ML model while keeping the training data local and private. With the power of the recurrent self-supervised learning paradigm, FL is able to leverage innumerable underutilized data from RSU. To verify the FedRSU framework, we construct a large-scale multi-modality dataset RSU-SF. The dataset consists of 17 RSU clients, covering various scenarios, modalities, and sensor settings. Based on RSU-SF, we show that FedRSU can greatly improve model performance in ITS and provide a comprehensive benchmark under diverse FL scenarios. To the best of our knowledge, we provide the first real-world LiDAR-camera multi-modal dataset and benchmark for the FL community.
Deep Spatiotemporal Clutter Filtering of Transthoracic Echocardiographic Images Using a 3D Convolutional Auto-Encoder
Jan 23, 2024This study presents a deep convolutional auto-encoder network for filtering reverberation artifacts, from transthoracic echocardiographic (TTE) image sequences. Given the spatiotemporal nature of these artifacts, the filtering network was built using 3D convolutional layers to suppress the clutter patterns throughout the cardiac cycle. The network was designed by taking advantage of: i) an attention mechanism to focus primarily on cluttered regions and ii) residual learning to preserve fine structures of the image frames. To train the deep network, a diverse set of artifact patterns was simulated and the simulated patterns were superimposed onto artifact-free ultra-realistic synthetic TTE sequences of six ultrasound vendors to generate input of the filtering network. The artifact-free sequences served as ground-truth. Performance of the filtering network was evaluated using unseen synthetic as well as in-vivo artifactual sequences. Satisfactory results obtained using the latter dataset confirmed the good generalization performance of the proposed network which was trained using the synthetic sequences and simulated artifact patterns. Suitability of the clutter-filtered sequences for further processing was assessed by computing segmental strain curves from them. The results showed that the large discrepancy between the strain profiles computed from the cluttered segments and their corresponding segments in the clutter-free images was significantly reduced after filtering the sequences using the proposed network. The trained deep network could process an artifactual TTE sequence in a fraction of a second and can be used for real-time clutter filtering. Moreover, it can improve the precision of the clinical indexes that are computed from the TTE sequences. The source code of the proposed method is available at: https://github.com/MahdiTabassian/Deep-Clutter-Filtering/tree/main.
CIM-MLC: A Multi-level Compilation Stack for Computing-In-Memory Accelerators
Jan 23, 2024In recent years, various computing-in-memory (CIM) processors have been presented, showing superior performance over traditional architectures. To unleash the potential of various CIM architectures, such as device precision, crossbar size, and crossbar number, it is necessary to develop compilation tools that are fully aware of the CIM architectural details and implementation diversity. However, due to the lack of architectural support in current popular open-source compiling stacks, existing CIM designs either manually deploy networks or build their own compilers, which is time-consuming and labor-intensive. Although some works expose the specific CIM device programming interfaces to compilers, they are often bound to a fixed CIM architecture, lacking the flexibility to support the CIM architectures with different computing granularity. On the other hand, existing compilation works usually consider the scheduling of limited operation types (such as crossbar-bound matrix-vector multiplication). Unlike conventional processors, CIM accelerators are featured by their diverse architecture, circuit, and device, which cannot be simply abstracted by a single level if we seek to fully explore the advantages brought by CIM. Therefore, we propose CIM-MLC, a universal multi-level compilation framework for general CIM architectures. We first establish a general hardware abstraction for CIM architectures and computing modes to represent various CIM accelerators. Based on the proposed abstraction, CIM-MLC can compile tasks onto a wide range of CIM accelerators having different devices, architectures, and programming interfaces. More importantly, compared with existing compilation work, CIM-MLC can explore the mapping and scheduling strategies across multiple architectural tiers, which form a tractable yet effective design space, to achieve better scheduling and instruction generation results.
Towards Scalable and Robust Model Versioning
Jan 17, 2024As the deployment of deep learning models continues to expand across industries, the threat of malicious incursions aimed at gaining access to these deployed models is on the rise. Should an attacker gain access to a deployed model, whether through server breaches, insider attacks, or model inversion techniques, they can then construct white-box adversarial attacks to manipulate the model's classification outcomes, thereby posing significant risks to organizations that rely on these models for critical tasks. Model owners need mechanisms to protect themselves against such losses without the necessity of acquiring fresh training data - a process that typically demands substantial investments in time and capital. In this paper, we explore the feasibility of generating multiple versions of a model that possess different attack properties, without acquiring new training data or changing model architecture. The model owner can deploy one version at a time and replace a leaked version immediately with a new version. The newly deployed model version can resist adversarial attacks generated leveraging white-box access to one or all previously leaked versions. We show theoretically that this can be accomplished by incorporating parameterized hidden distributions into the model training data, forcing the model to learn task-irrelevant features uniquely defined by the chosen data. Additionally, optimal choices of hidden distributions can produce a sequence of model versions capable of resisting compound transferability attacks over time. Leveraging our analytical insights, we design and implement a practical model versioning method for DNN classifiers, which leads to significant robustness improvements over existing methods. We believe our work presents a promising direction for safeguarding DNN services beyond their initial deployment.
Agreement Technologies for Coordination in Smart Cities
Jan 21, 2024Many challenges in today's society can be tackled by distributed open systems. This is particularly true for domains that are commonly perceived under the umbrella of smart cities, such as intelligent transportation, smart energy grids, or participative governance. When designing computer applications for these domains, it is necessary to account for the fact that the elements of such systems, often called software agents, are usually made by different designers and act on behalf of particular stakeholders. Furthermore, it is unknown at design time when such agents will enter or leave the system, and what interests new agents will represent. To instil coordination in such systems is particularly demanding, as usually only part of them can be directly controlled at runtime. Agreement technologies refer to a sandbox of tools and mechanisms for the development of such open multiagent systems, which are based on the notion of agreement. In this paper, we argue that agreement technologies are a suitable means for achieving coordination in smart city domains, and back our claim through examples of several real-world applications.
Entropy Causal Graphs for Multivariate Time Series Anomaly Detection
Dec 15, 2023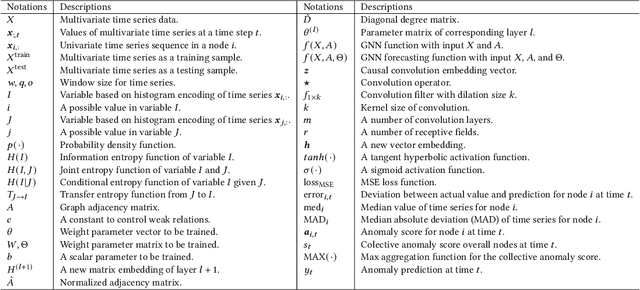
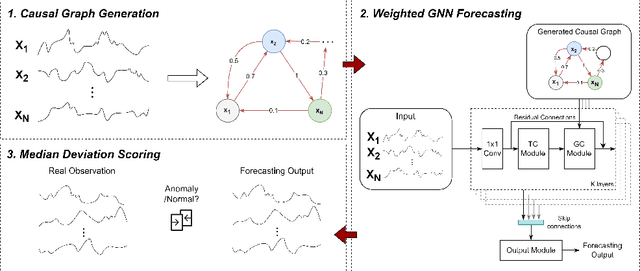
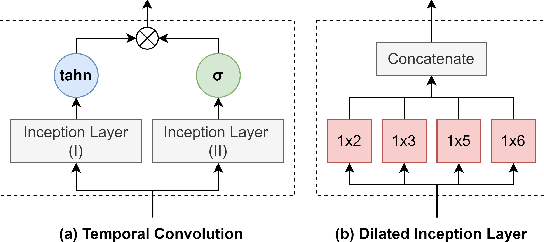
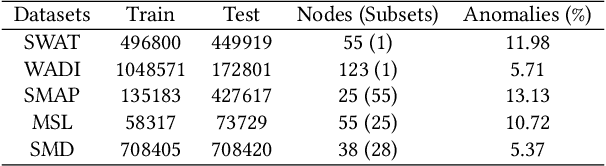
Many multivariate time series anomaly detection frameworks have been proposed and widely applied. However, most of these frameworks do not consider intrinsic relationships between variables in multivariate time series data, thus ignoring the causal relationship among variables and degrading anomaly detection performance. This work proposes a novel framework called CGAD, an entropy Causal Graph for multivariate time series Anomaly Detection. CGAD utilizes transfer entropy to construct graph structures that unveil the underlying causal relationships among time series data. Weighted graph convolutional networks combined with causal convolutions are employed to model both the causal graph structures and the temporal patterns within multivariate time series data. Furthermore, CGAD applies anomaly scoring, leveraging median absolute deviation-based normalization to improve the robustness of the anomaly identification process. Extensive experiments demonstrate that CGAD outperforms state-of-the-art methods on real-world datasets with a 15% average improvement based on three different multivariate time series anomaly detection metrics.
Energy-aware Trajectory Optimization for UAV-mounted RIS and Full-duplex Relay
Jan 22, 2024In the evolving landscape of sixth-generation (6G) wireless networks, unmanned aerial vehicles (UAVs) have emerged as transformative tools for dynamic and adaptive connectivity. However, dynamically adjusting their position to offer favorable communication channels introduces operational challenges in terms of energy consumption, especially when integrating advanced communication technologies like reconfigurable intelligent surfaces (RISs) and full-duplex relays (FDRs). To this end, by recognizing the pivotal role of UAV mobility, the paper introduces an energy-aware trajectory design for UAV-mounted RISs and UAV-mounted FDRs using the decode and forward (DF) protocol, aiming to maximize the network minimum rate and enhance user fairness, while taking into consideration the available on-board energy. Specifically, this work highlights their distinct energy consumption characteristics and their associated integration challenges by developing appropriate energy consumption models for both UAV-mounted RISs and FDRs that capture the intricate relationship between key factors such as weight, and their operational characteristics. Furthermore, a joint time-division multiple access (TDMA) user scheduling-UAV trajectory optimization problem is formulated, considering the power dynamics of both systems, while assuring that the UAV energy is not depleted mid-air. Finally, simulation results underscore the importance of energy considerations in determining the optimal trajectory and scheduling and provide insights into the performance comparison of UAV-mounted RISs and FDRs in UAV-assisted wireless networks.