 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A Balance for Fairness: Fair Distribution Utilising Physics in Games of Characteristic Function Form
Feb 05, 2021

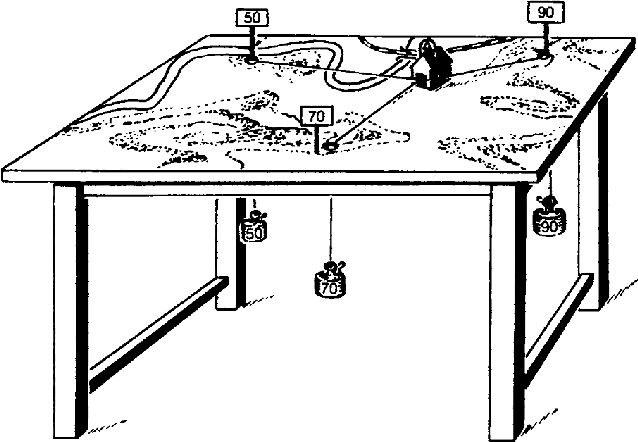
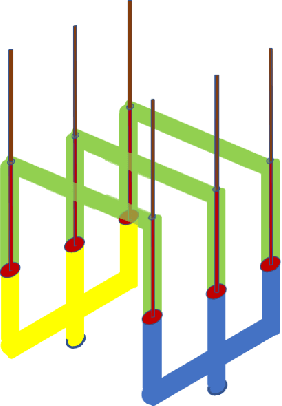
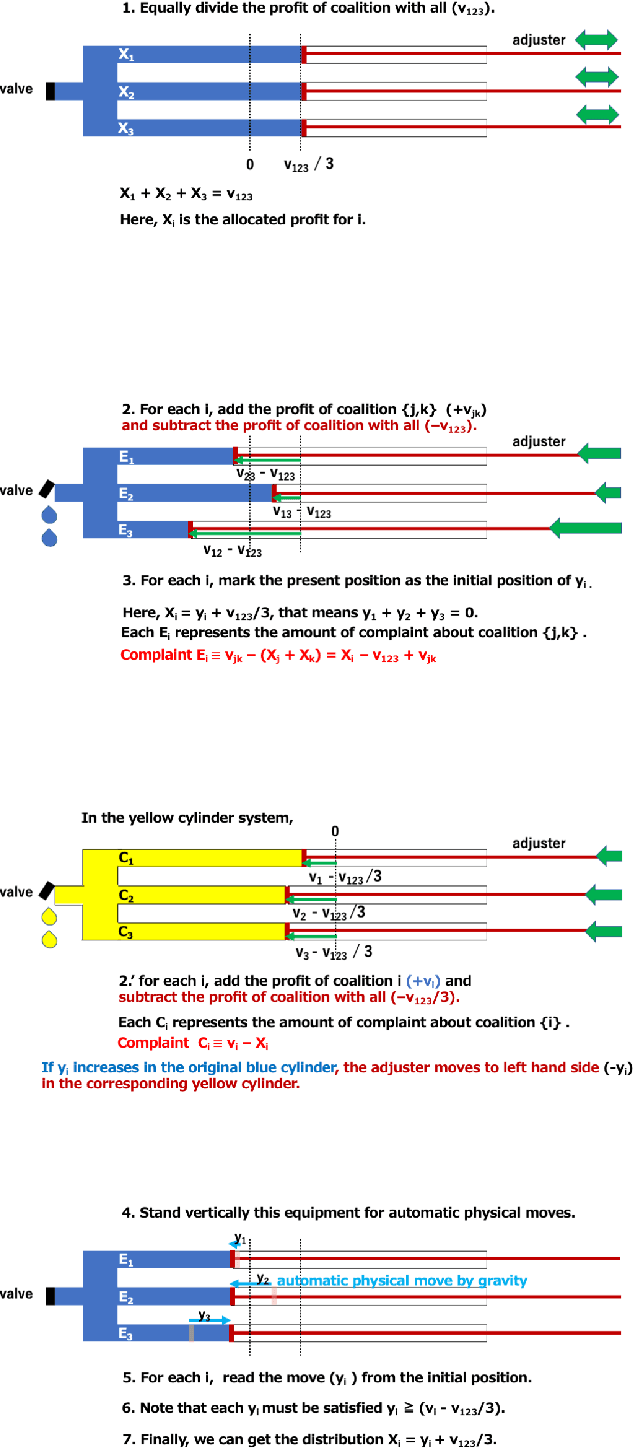
In chaotic modern society, there is an increasing demand for the realization of true 'fairness'. In Greek mythology, Themis, the 'goddess of justice', has a sword in her right hand to protect society from vices, and a 'balance of judgment' in her left hand that measures good and evil. In this study, we propose a fair distribution method 'utilising physics' for the profit in games of characteristic function form. Specifically, we show that the linear programming problem for calculating 'nucleolus' can be efficiently solved by considering it as a physical system in which gravity works. In addition to being able to significantly reduce computational complexity thereby, we believe that this system could have flexibility necessary to respond to real-time changes in the parameter.
AEC in a NetShell: On Target and Topology Choices for FCRN Acoustic Echo Cancellation
Mar 16, 2021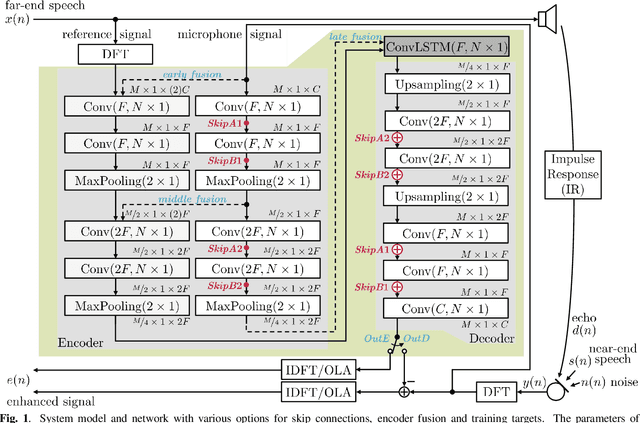
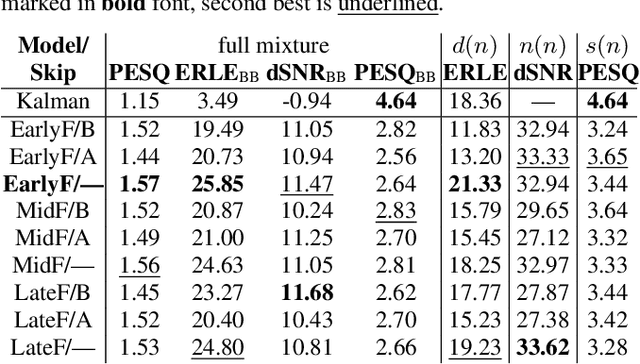
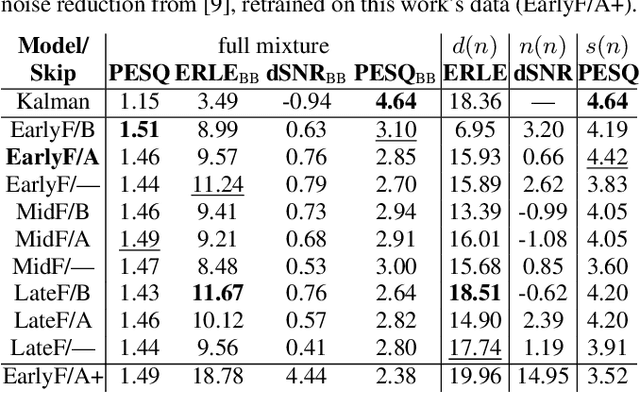
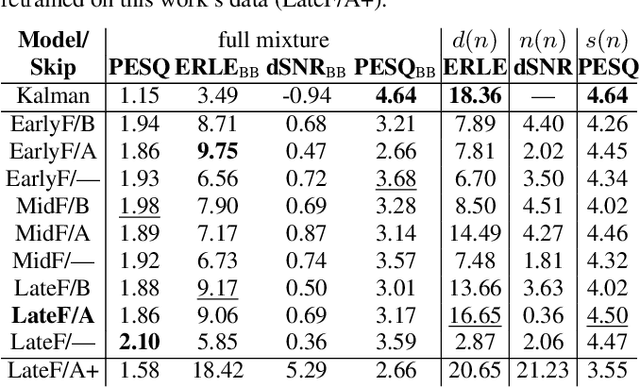
Acoustic echo cancellation (AEC) algorithms have a long-term steady role in signal processing, with approaches improving the performance of applications such as automotive hands-free systems, smart home and loudspeaker devices, or web conference systems. Just recently, very first deep neural network (DNN)-based approaches were proposed with a DNN for joint AEC and residual echo suppression (RES)/noise reduction, showing significant improvements in terms of echo suppression performance. Noise reduction algorithms, on the other hand, have enjoyed already a lot of attention with regard to DNN approaches, with the fully convolutional recurrent network (FCRN) architecture being among state of the art topologies. The recently published impressive echo cancellation performance of joint AEC/RES DNNs, however, so far came along with an undeniable impairment of speech quality. In this work we will heal this issue and significantly improve the near-end speech component quality over existing approaches. Also, we propose for the first time-to the best of our knowledge-a pure DNN AEC in the form of an echo estimator, that is based on a competitive FCRN structure and delivers a quality useful for practical applications.
Semi-Structured Deep Piecewise Exponential Models
Nov 11, 2020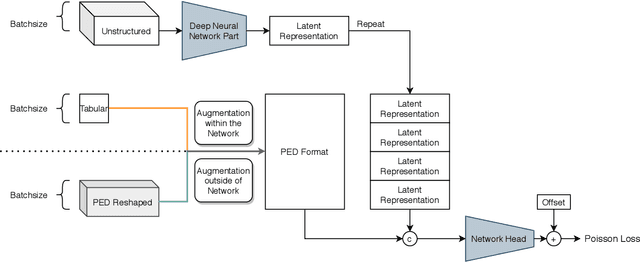
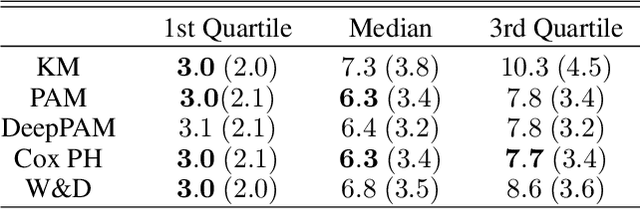
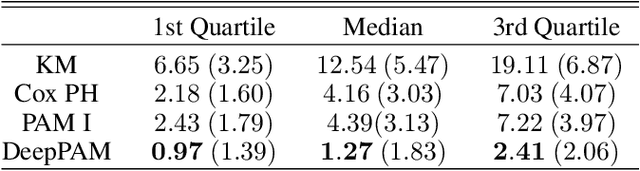

We propose a versatile framework for survival analysis that combines advanced concepts from statistics with deep learning. The presented framework is based on piecewise exponential models and thereby supports various survival tasks, such as competing risks and multi-state modeling, and further allows for estimation of time-varying effects and time-varying features. To also include multiple data sources and higher-order interaction effects into the model, we embed the model class in a neural network and thereby enable the simultaneous estimation of both inherently interpretable structured regression inputs as well as deep neural network components which can potentially process additional unstructured data sources. A proof of concept is provided by using the framework to predict Alzheimer's disease progression based on tabular and 3D point cloud data and applying it to synthetic data.
FROG-measurement based phase retrieval for analytic signals
Mar 08, 2021While frequency-resolved optical gating (FROG) is widely used in characterizing the ultrafast pulse in optics, analytic signals are often considered in time-frequency analysis and signal processing, especially when extracting instantaneous features of events. In this paper we examine the phase retrieval (PR) problem of analytic signals in $\Bbb{C}^N$ by their FROG measurements. After establishing the ambiguity of the FROG-PR of analytic signals, we found that the FROG-PR of analytic signals of even lengths is different from that of analytic signals of odd lengths, and it is also different from the case of $B$-bandlimited signals with $B \leq N/2$. The existing approach to bandlimited signals can be applied to analytic signals of odd lengths, but it does not apply to the even length case. With the help of two relaxed FROG-PR problems and a translation technique, we develop an approach to FROG-PR for the analytic signals of even lengths, and prove that in this case the generic analytic signals can be uniquely (up to the ambiguity) determined by their $(3N/2+1)$ FROG measurements.
Predicting Nanorobot Shapes via Generative Models
Jan 29, 2021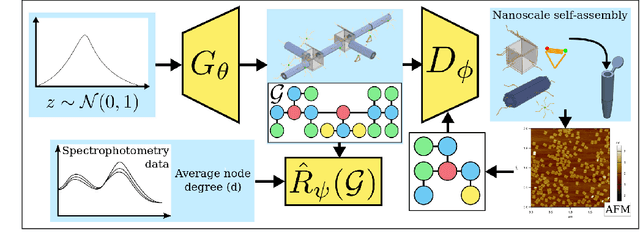
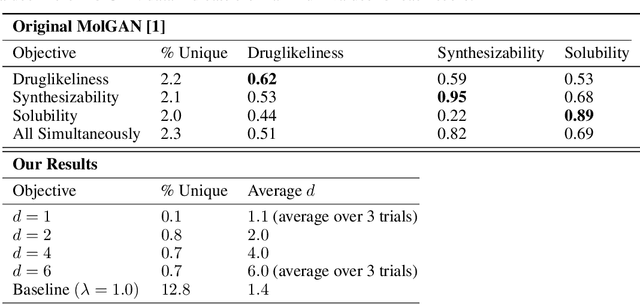
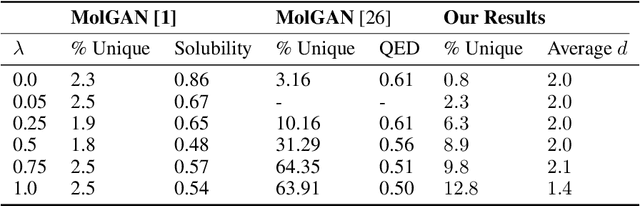
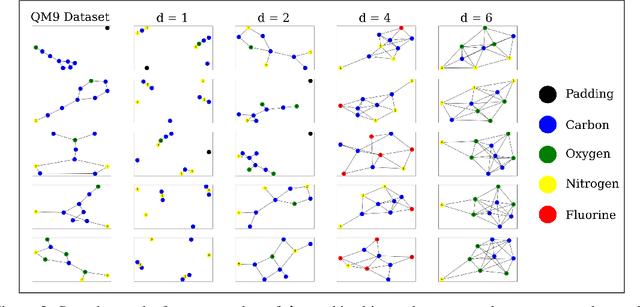
The field of DNA nanotechnology has made it possible to assemble, with high yields, different structures that have actionable properties. For example, researchers have created components that can be actuated. An exciting next step is to combine these components into multifunctional nanorobots that could, potentially, perform complex tasks like swimming to a target location in the human body, detect an adverse reaction and then release a drug load to stop it. However, as we start to assemble more complex nanorobots, the yield of the desired nanorobot begins to decrease as the number of possible component combinations increases. Therefore, the ultimate goal of this work is to develop a predictive model to maximize yield. However, training predictive models typically requires a large dataset. For the nanorobots we are interested in assembling, this will be difficult to collect. This is because high-fidelity data, which allows us to characterize the shape and size of individual structures, is very time-consuming to collect, whereas low-fidelity data is readily available but only captures bulk statistics for different processes. Therefore, this work combines low- and high-fidelity data to train a generative model using a two-step process. We first use a relatively small, high-fidelity dataset to train a generative model. At run time, the model takes low-fidelity data and uses it to approximate the high-fidelity content. We do this by biasing the model towards samples with specific properties as measured by low-fidelity data. In this work we bias our distribution towards a desired node degree of a graphical model that we take as a surrogate representation of the nanorobots that this work will ultimately focus on. We have not yet accumulated a high-fidelity dataset of nanorobots, so we leverage the MolGAN architecture [1] and the QM9 small molecule dataset [2-3] to demonstrate our approach.
Predicting Parkinson's Disease with Multimodal Irregularly Collected Longitudinal Smartphone Data
Oct 15, 2020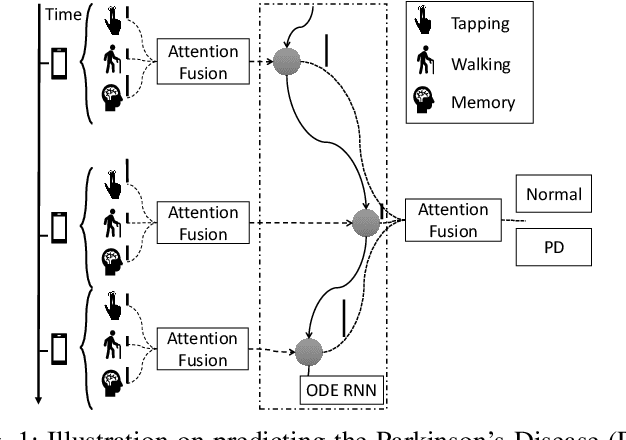
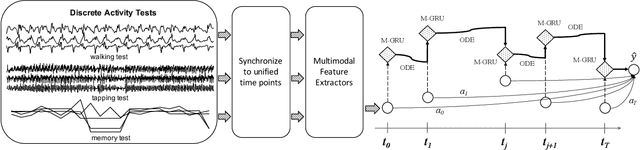
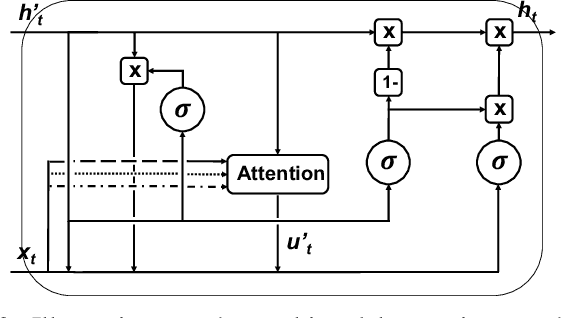
Parkinsons Disease is a neurological disorder and prevalent in elderly people. Traditional ways to diagnose the disease rely on in-person subjective clinical evaluations on the quality of a set of activity tests. The high-resolution longitudinal activity data collected by smartphone applications nowadays make it possible to conduct remote and convenient health assessment. However, out-of-lab tests often suffer from poor quality controls as well as irregularly collected observations, leading to noisy test results. To address these issues, we propose a novel time-series based approach to predicting Parkinson's Disease with raw activity test data collected by smartphones in the wild. The proposed method first synchronizes discrete activity tests into multimodal features at unified time points. Next, it distills and enriches local and global representations from noisy data across modalities and temporal observations by two attention modules. With the proposed mechanisms, our model is capable of handling noisy observations and at the same time extracting refined temporal features for improved prediction performance. Quantitative and qualitative results on a large public dataset demonstrate the effectiveness of the proposed approach.
Interpretable Clustering on Dynamic Graphs with Recurrent Graph Neural Networks
Dec 16, 2020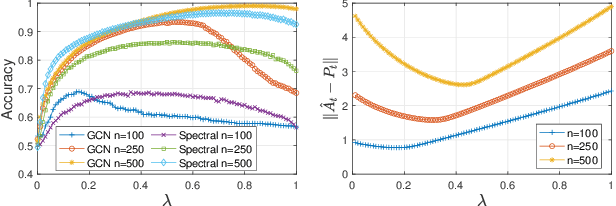
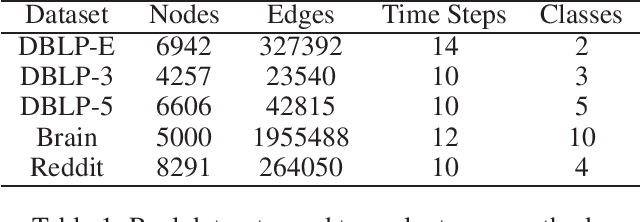
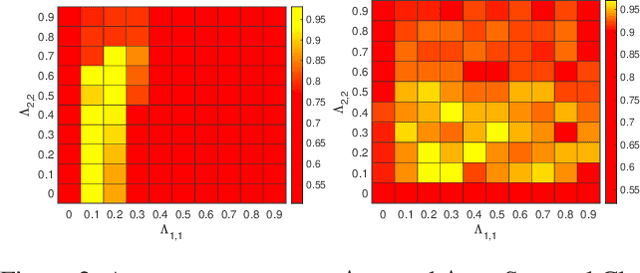
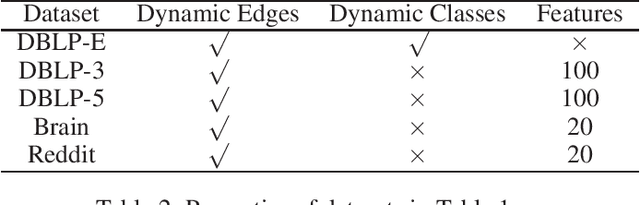
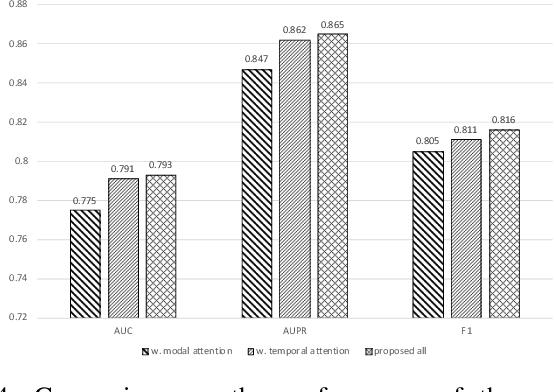
We study the problem of clustering nodes in a dynamic graph, where the connections between nodes and nodes' cluster memberships may change over time, e.g., due to community migration. We first propose a dynamic stochastic block model that captures these changes, and a simple decay-based clustering algorithm that clusters nodes based on weighted connections between them, where the weight decreases at a fixed rate over time. This decay rate can then be interpreted as signifying the importance of including historical connection information in the clustering. However, the optimal decay rate may differ for clusters with different rates of turnover. We characterize the optimal decay rate for each cluster and propose a clustering method that achieves almost exact recovery of the true clusters. We then demonstrate the efficacy of our clustering algorithm with optimized decay rates on simulated graph data. Recurrent neural networks (RNNs), a popular algorithm for sequence learning, use a similar decay-based method, and we use this insight to propose two new RNN-GCN (graph convolutional network) architectures for semi-supervised graph clustering. We finally demonstrate that the proposed architectures perform well on real data compared to state-of-the-art graph clustering algorithms.
Meta-Reinforcement Learning for Reliable Communication in THz/VLC Wireless VR Networks
Jan 29, 2021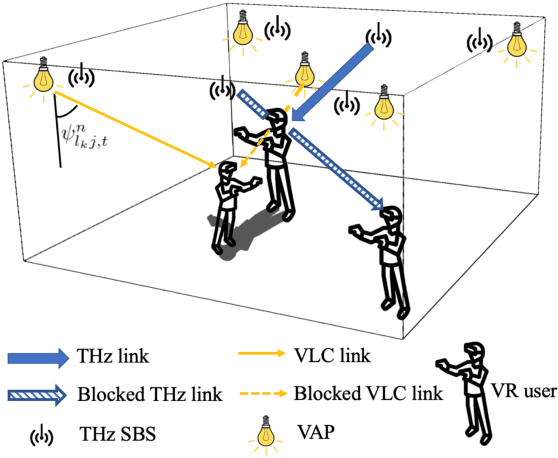
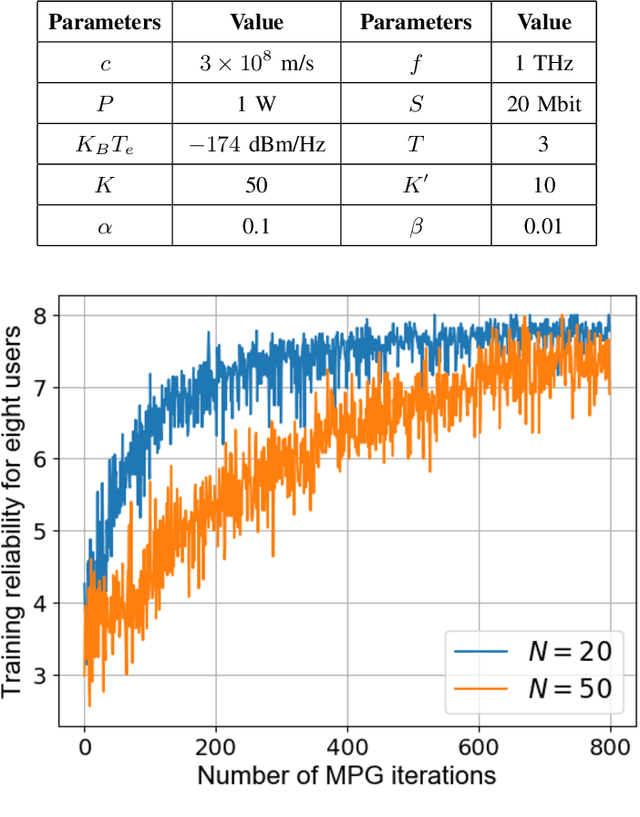
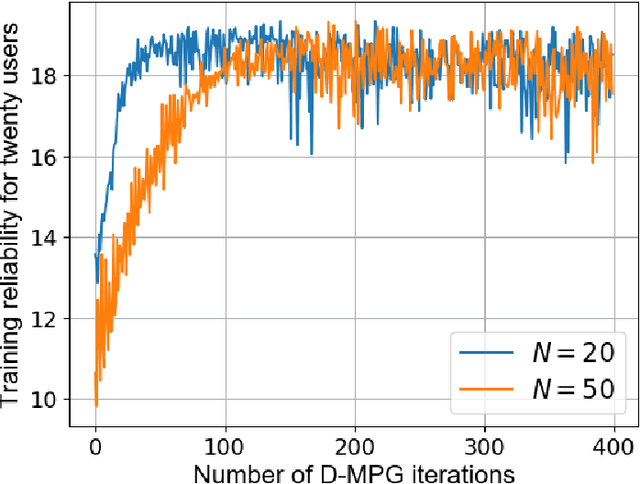
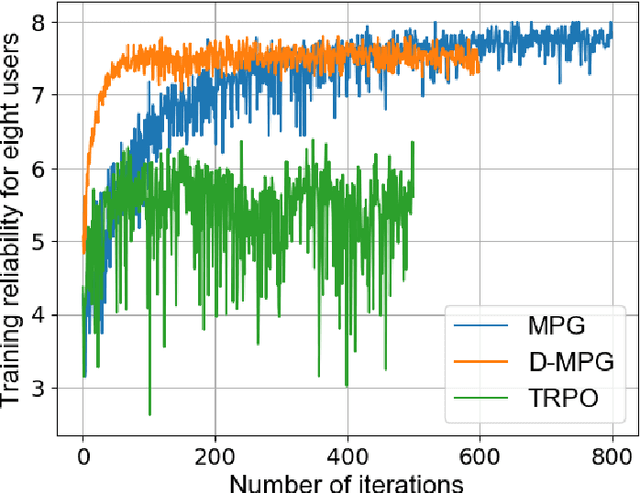
In this paper, the problem of enhancing the quality of virtual reality (VR) services is studied for an indoor terahertz (THz)/visible light communication (VLC) wireless network. In the studied model, small base stations (SBSs) transmit high-quality VR images to VR users over THz bands and light-emitting diodes (LEDs) provide accurate indoor positioning services for them using VLC. Here, VR users move in real time and their movement patterns change over time according to their applications. Both THz and VLC links can be blocked by the bodies of VR users. To control the energy consumption of the studied THz/VLC wireless VR network, VLC access points (VAPs) must be selectively turned on so as to ensure accurate and extensive positioning for VR users. Based on the user positions, each SBS must generate corresponding VR images and establish THz links without body blockage to transmit the VR content. The problem is formulated as an optimization problem whose goal is to maximize the average number of successfully served VR users by selecting the appropriate VAPs to be turned on and controlling the user association with SBSs. To solve this problem, a meta policy gradient (MPG) algorithm that enables the trained policy to quickly adapt to new user movement patterns is proposed. In order to solve the problem for VR scenarios with a large number of users, a dual method based MPG algorithm (D-MPG) with a low complexity is proposed. Simulation results demonstrate that, compared to a baseline trust region policy optimization algorithm (TRPO), the proposed MPG and D-MPG algorithms yield up to 38.2% and 33.8% improvement in the average number of successfully served users as well as 75% and 87.5% gains in the convergence speed, respectively.
Multilingual Knowledge Graph Completion with Joint Relation and Entity Alignment
Apr 18, 2021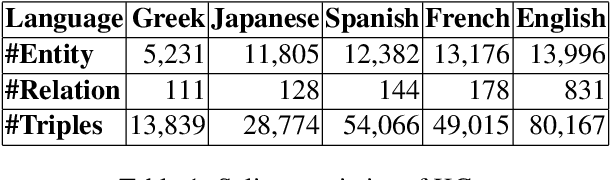
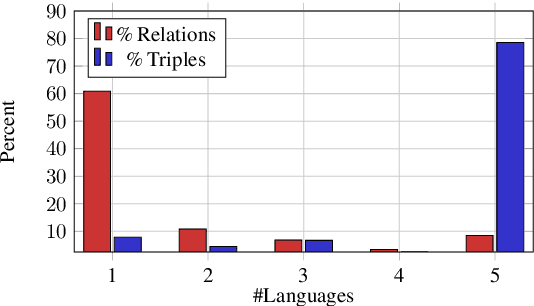
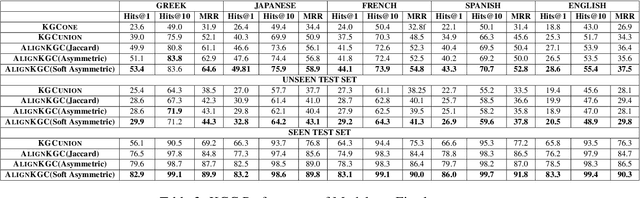

Knowledge Graph Completion (KGC) predicts missing facts in an incomplete Knowledge Graph. Almost all of existing KGC research is applicable to only one KG at a time, and in one language only. However, different language speakers may maintain separate KGs in their language and no individual KG is expected to be complete. Moreover, common entities or relations in these KGs have different surface forms and IDs, leading to ID proliferation. Entity alignment (EA) and relation alignment (RA) tasks resolve this by recognizing pairs of entity (relation) IDs in different KGs that represent the same entity (relation). This can further help prediction of missing facts, since knowledge from one KG is likely to benefit completion of another. High confidence predictions may also add valuable information for the alignment tasks. In response, we study the novel task of jointly training multilingual KGC, relation alignment and entity alignment models. We present ALIGNKGC, which uses some seed alignments to jointly optimize all three of KGC, EA and RA losses. A key component of ALIGNKGC is an embedding based soft notion of asymmetric overlap defined on the (subject, object) set signatures of relations this aids in better predicting relations that are equivalent to or implied by other relations. Extensive experiments with DBPedia in five languages establish the benefits of joint training for all tasks, achieving 10-32 MRR improvements of ALIGNKGC over a strong state-of-the-art single-KGC system completion model over each monolingual KG . Further, ALIGNKGC achieves reasonable gains in EA and RA tasks over a vanilla completion model over a KG that combines all facts without alignment, underscoring the value of joint training for these tasks.
Escaping the Big Data Paradigm with Compact Transformers
Apr 12, 2021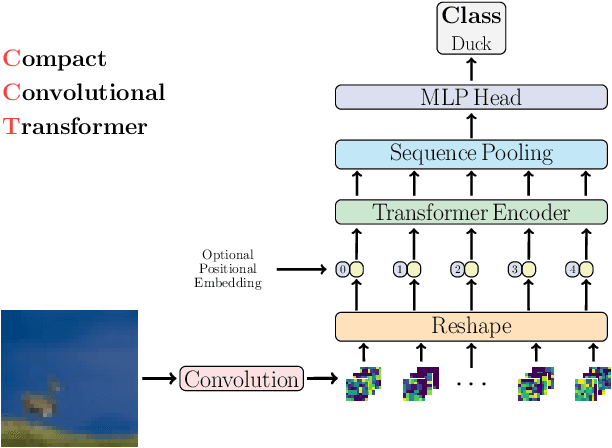
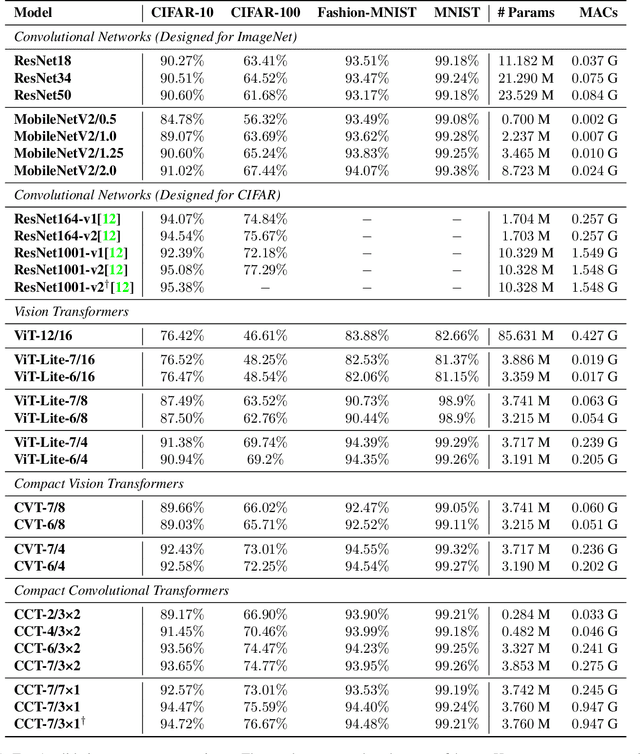
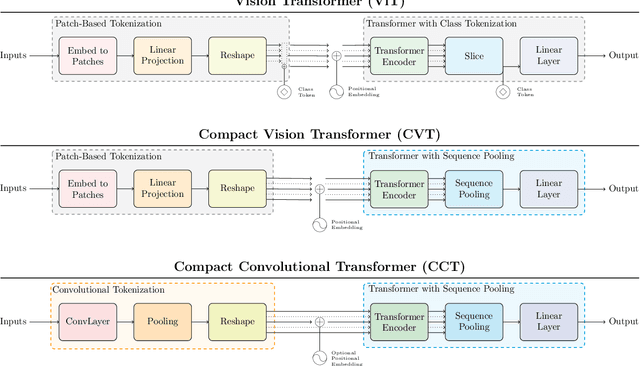
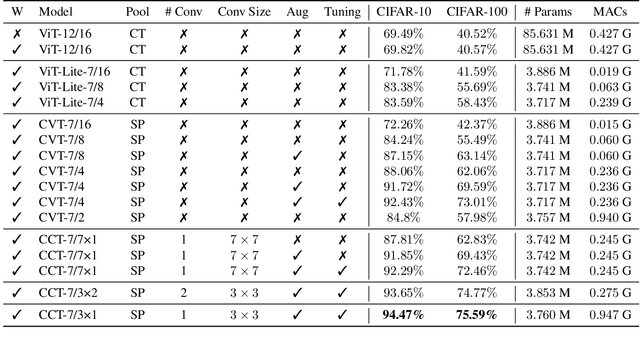
With the rise of Transformers as the standard for language processing, and their advancements in computer vision, along with their unprecedented size and amounts of training data, many have come to believe that they are not suitable for small sets of data. This trend leads to great concerns, including but not limited to: limited availability of data in certain scientific domains and the exclusion of those with limited resource from research in the field. In this paper, we dispel the myth that transformers are "data hungry" and therefore can only be applied to large sets of data. We show for the first time that with the right size and tokenization, transformers can perform head-to-head with state-of-the-art CNNs on small datasets. Our model eliminates the requirement for class token and positional embeddings through a novel sequence pooling strategy and the use of convolutions. We show that compared to CNNs, our compact transformers have fewer parameters and MACs, while obtaining similar accuracies. Our method is flexible in terms of model size, and can have as little as 0.28M parameters and achieve reasonable results. It can reach an accuracy of 94.72% when training from scratch on CIFAR-10, which is comparable with modern CNN based approaches, and a significant improvement over previous Transformer based models. Our simple and compact design democratizes transformers by making them accessible to those equipped with basic computing resources and/or dealing with important small datasets. Our code and pre-trained models will be made publicly available at https://github.com/SHI-Labs/Compact-Transformers.