 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MONAH: Multi-Modal Narratives for Humans to analyze conversations
Jan 18, 2021
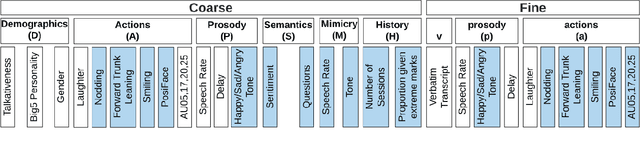
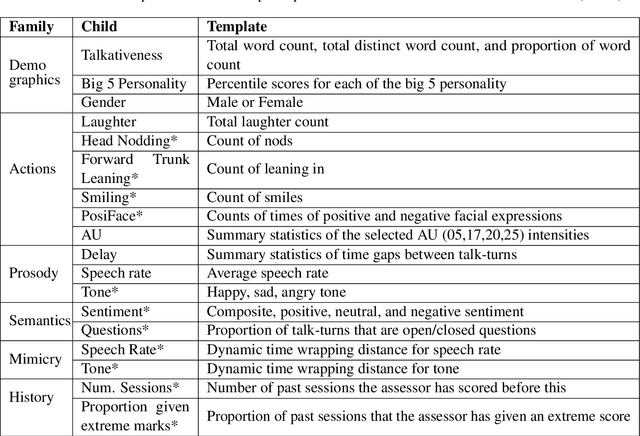
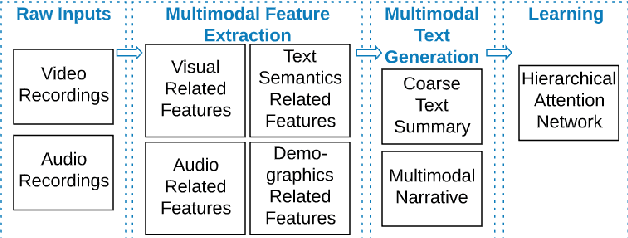
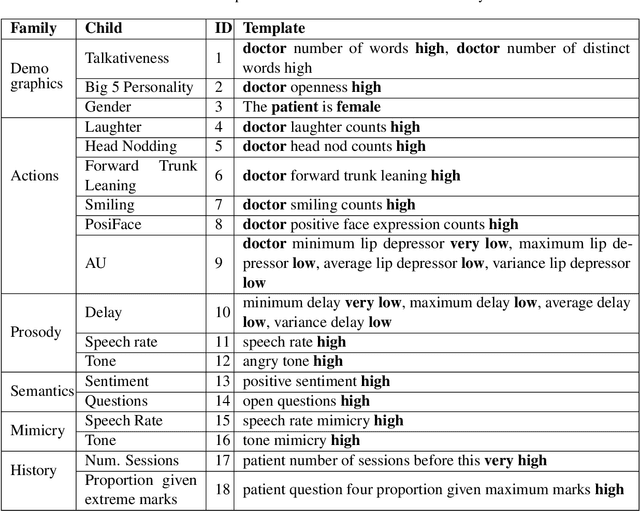
In conversational analyses, humans manually weave multimodal information into the transcripts, which is significantly time-consuming. We introduce a system that automatically expands the verbatim transcripts of video-recorded conversations using multimodal data streams. This system uses a set of preprocessing rules to weave multimodal annotations into the verbatim transcripts and promote interpretability. Our feature engineering contributions are two-fold: firstly, we identify the range of multimodal features relevant to detect rapport-building; secondly, we expand the range of multimodal annotations and show that the expansion leads to statistically significant improvements in detecting rapport-building.
LANA: Towards Personalized Deep Knowledge Tracing Through Distinguishable Interactive Sequences
Apr 21, 2021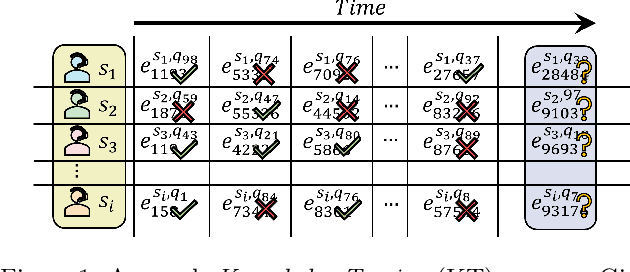

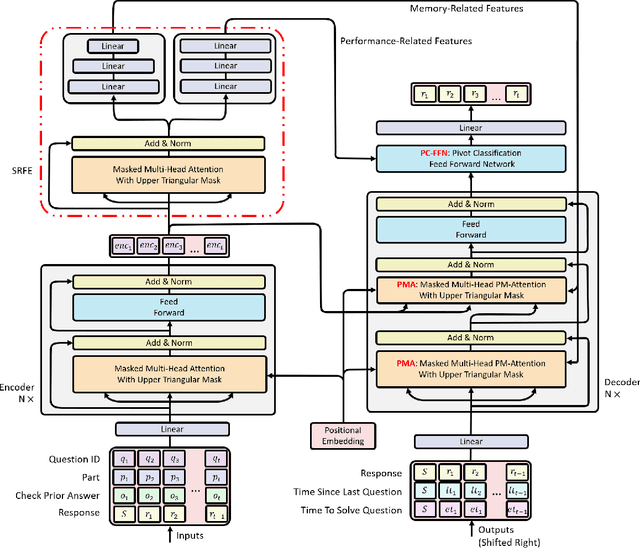
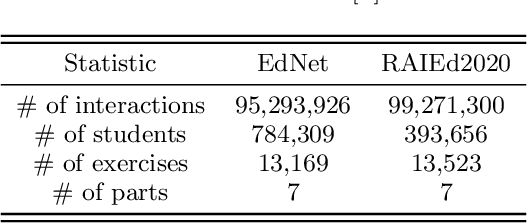
In educational applications, Knowledge Tracing (KT), the problem of accurately predicting students' responses to future questions by summarizing their knowledge states, has been widely studied for decades as it is considered a fundamental task towards adaptive online learning. Among all the proposed KT methods, Deep Knowledge Tracing (DKT) and its variants are by far the most effective ones due to the high flexibility of the neural network. However, DKT often ignores the inherent differences between students (e.g. memory skills, reasoning skills, ...), averaging the performances of all students, leading to the lack of personalization, and therefore was considered insufficient for adaptive learning. To alleviate this problem, in this paper, we proposed Leveled Attentive KNowledge TrAcing (LANA), which firstly uses a novel student-related features extractor (SRFE) to distill students' unique inherent properties from their respective interactive sequences. Secondly, the pivot module was utilized to dynamically reconstruct the decoder of the neural network on attention of the extracted features, successfully distinguishing the performance between students over time. Moreover, inspired by Item Response Theory (IRT), the interpretable Rasch model was used to cluster students by their ability levels, and thereby utilizing leveled learning to assign different encoders to different groups of students. With pivot module reconstructed the decoder for individual students and leveled learning specialized encoders for groups, personalized DKT was achieved. Extensive experiments conducted on two real-world large-scale datasets demonstrated that our proposed LANA improves the AUC score by at least 1.00% (i.e. EdNet 1.46% and RAIEd2020 1.00%), substantially surpassing the other State-Of-The-Art KT methods.
TrajeVAE -- Controllable Human Motion Generation from Trajectories
Apr 01, 2021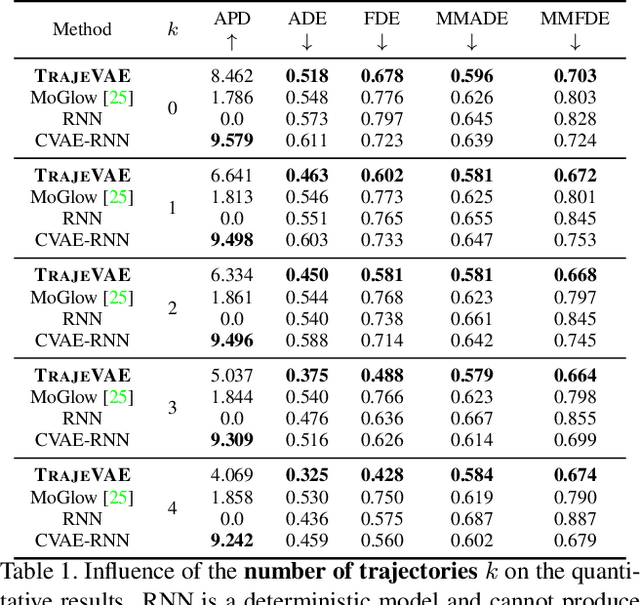
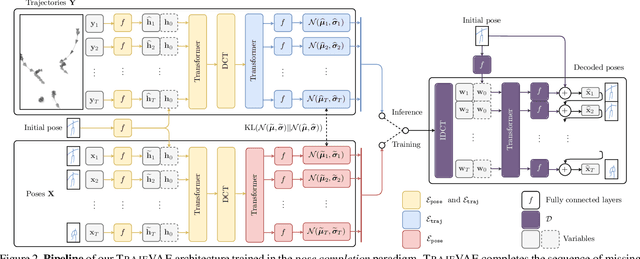
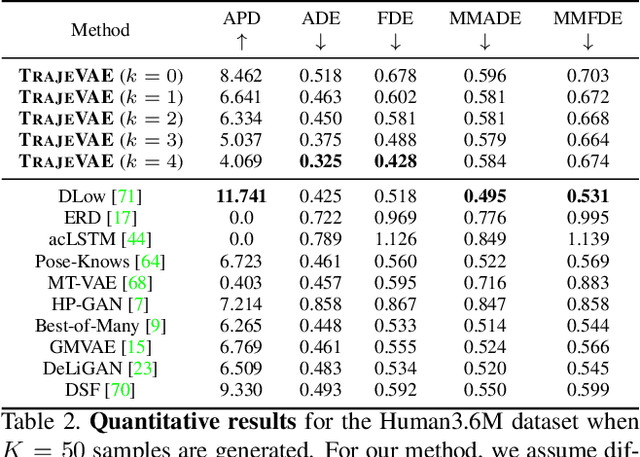
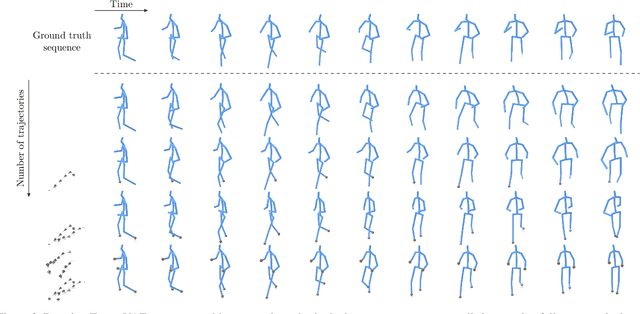
The generation of plausible and controllable 3D human motion animations is a long-standing problem that often requires a manual intervention of skilled artists. Existing machine learning approaches try to semi-automate this process by allowing the user to input partial information about the future movement. However, they are limited in two significant ways: they either base their pose prediction on past prior frames with no additional control over the future poses or allow the user to input only a single trajectory that precludes fine-grained control over the output. To mitigate these two issues, we reformulate the problem of future pose prediction into pose completion in space and time where trajectories are represented as poses with missing joints. We show that such a framework can generalize to other neural networks designed for future pose prediction. Once trained in this framework, a model is capable of predicting sequences from any number of trajectories. To leverage this notion, we propose a novel transformer-like architecture, TrajeVAE, that provides a versatile framework for 3D human animation. We demonstrate that TrajeVAE outperforms trajectory-based reference approaches and methods that base their predictions on past poses in terms of accuracy. We also show that it can predict reasonable future poses even if provided only with an initial pose.
ASIC Implementation of Time-Domain Digital Backpropagation with Deep-Learned Chromatic Dispersion Filters
Jun 20, 2018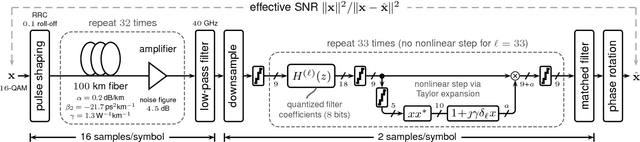
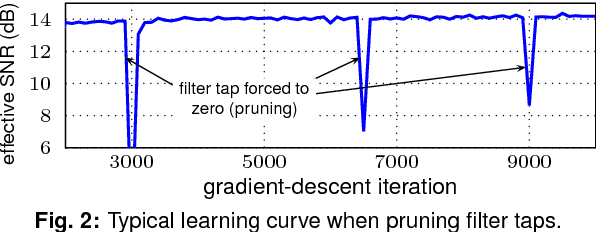
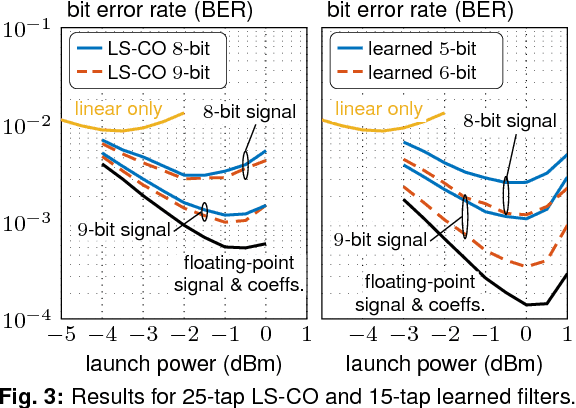
We consider time-domain digital backpropagation with chromatic dispersion filters jointly optimized and quantized using machine-learning techniques. Compared to the baseline implementations, we show improved BER performance and >40% power dissipation reductions in 28-nm CMOS.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 14, 2021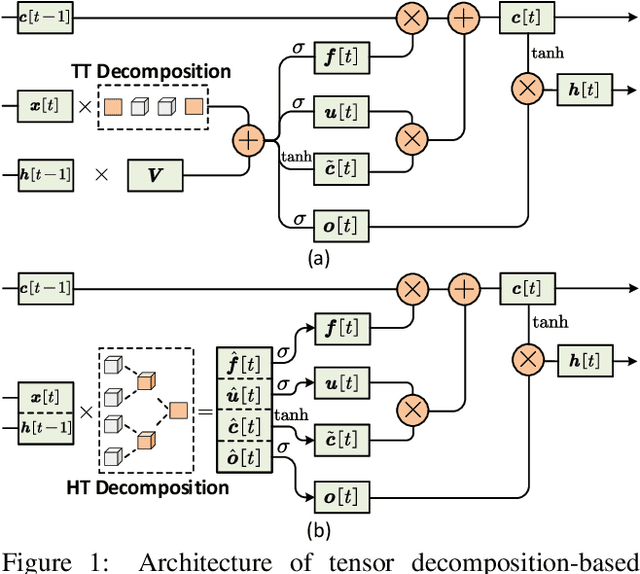
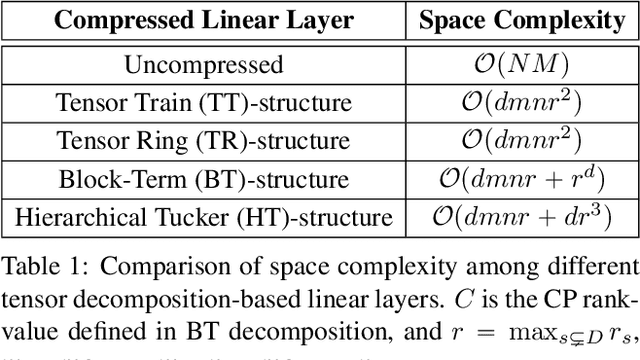
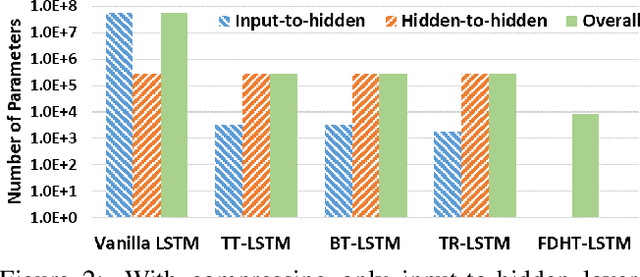
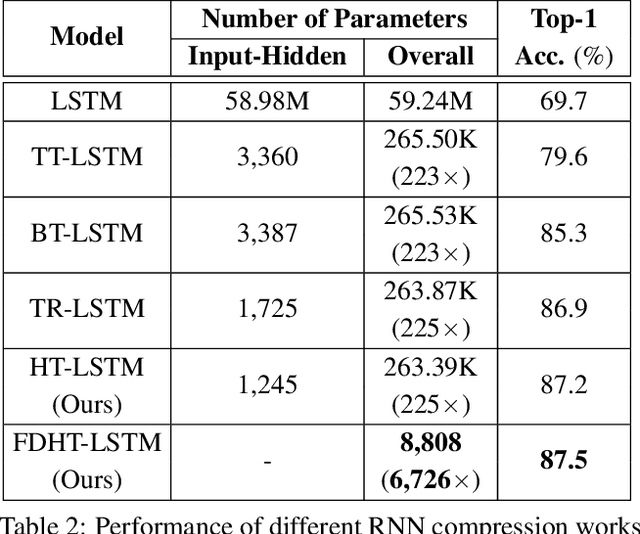
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Self-Supervised Equivariant Scene Synthesis from Video
Feb 01, 2021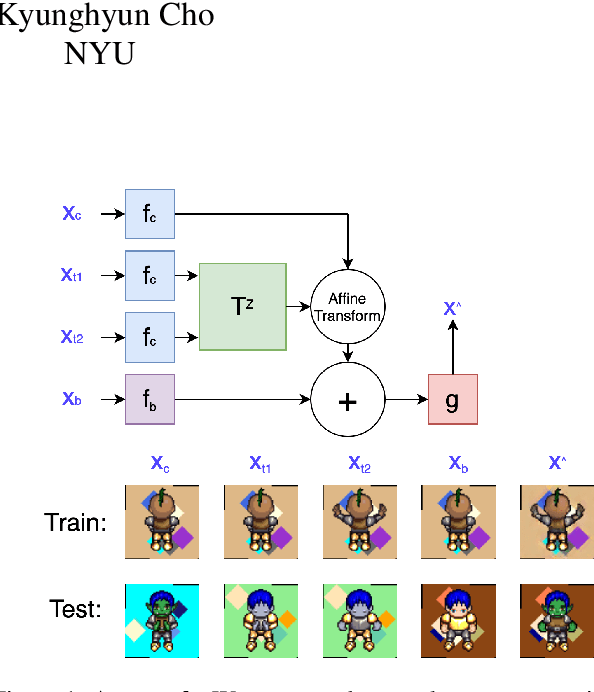
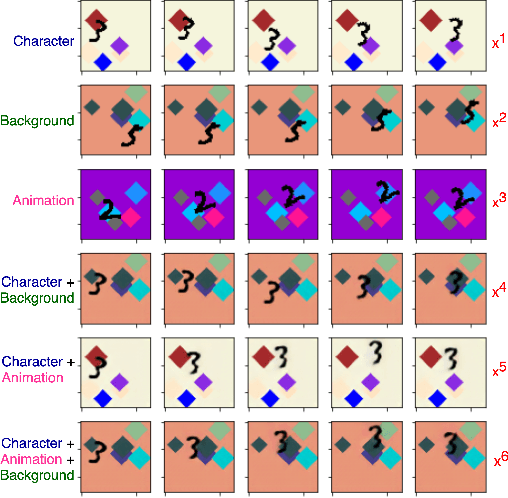
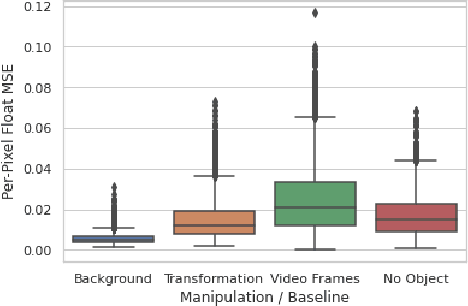
We propose a self-supervised framework to learn scene representations from video that are automatically delineated into background, characters, and their animations. Our method capitalizes on moving characters being equivariant with respect to their transformation across frames and the background being constant with respect to that same transformation. After training, we can manipulate image encodings in real time to create unseen combinations of the delineated components. As far as we know, we are the first method to perform unsupervised extraction and synthesis of interpretable background, character, and animation. We demonstrate results on three datasets: Moving MNIST with backgrounds, 2D video game sprites, and Fashion Modeling.
IMU2Face: Real-time Gesture-driven Facial Reenactment
Dec 18, 2017We present IMU2Face, a gesture-driven facial reenactment system. To this end, we combine recent advances in facial motion capture and inertial measurement units (IMUs) to control the facial expressions of a person in a target video based on intuitive hand gestures. IMUs are omnipresent, since modern smart-phones, smart-watches and drones integrate such sensors, e.g., for changing the orientation of the screen content, counting steps, or for flight stabilization. Face tracking and reenactment is based on the state-of-the-art real-time Face2Face facial reenactment system. Instead of transferring facial expressions from a source to a target actor, we employ an IMU to track the hand gestures of a source actor and use its orientation to modify the target actor's expressions.
GKD: Semi-supervised Graph Knowledge Distillation for Graph-Independent Inference
Apr 08, 2021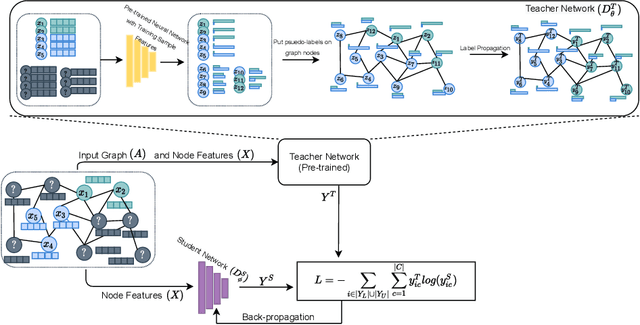
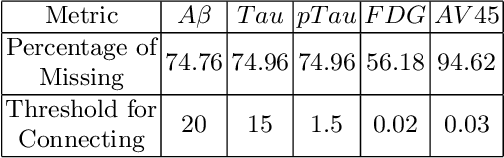
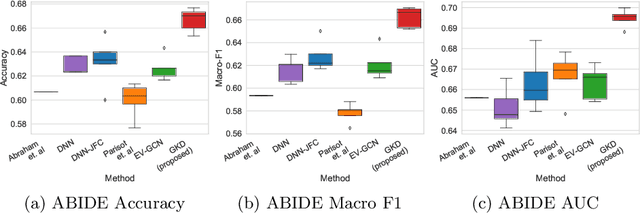
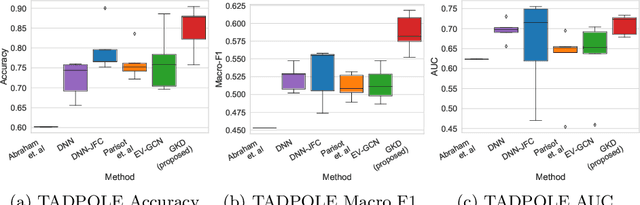
The increased amount of multi-modal medical data has opened the opportunities to simultaneously process various modalities such as imaging and non-imaging data to gain a comprehensive insight into the disease prediction domain. Recent studies using Graph Convolutional Networks (GCNs) provide novel semi-supervised approaches for integrating heterogeneous modalities while investigating the patients' associations for disease prediction. However, when the meta-data used for graph construction is not available at inference time (e.g., coming from a distinct population), the conventional methods exhibit poor performance. To address this issue, we propose a novel semi-supervised approach named GKD based on knowledge distillation. We train a teacher component that employs the label-propagation algorithm besides a deep neural network to benefit from the graph and non-graph modalities only in the training phase. The teacher component embeds all the available information into the soft pseudo-labels. The soft pseudo-labels are then used to train a deep student network for disease prediction of unseen test data for which the graph modality is unavailable. We perform our experiments on two public datasets for diagnosing Autism spectrum disorder, and Alzheimer's disease, along with a thorough analysis on synthetic multi-modal datasets. According to these experiments, GKD outperforms the previous graph-based deep learning methods in terms of accuracy, AUC, and Macro F1.
Perspective, Survey and Trends: Public Driving Datasets and Toolsets for Autonomous Driving Virtual Test
Apr 01, 2021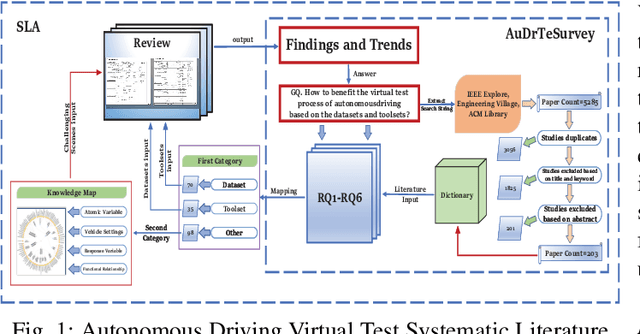
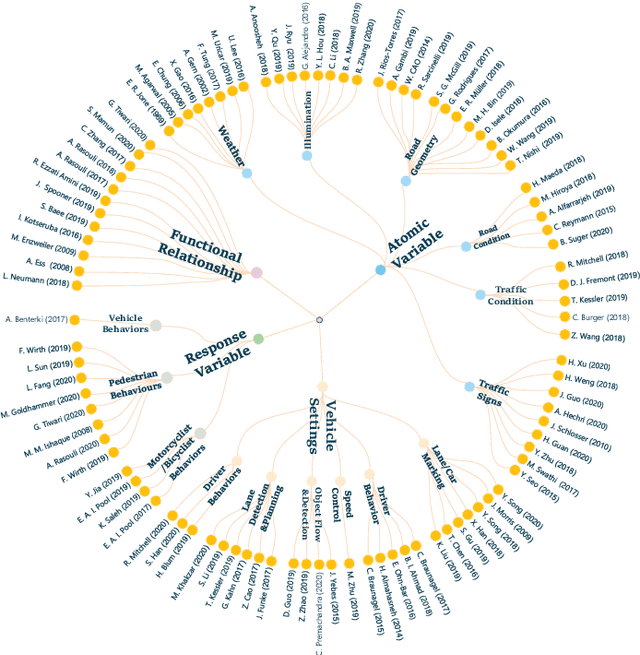
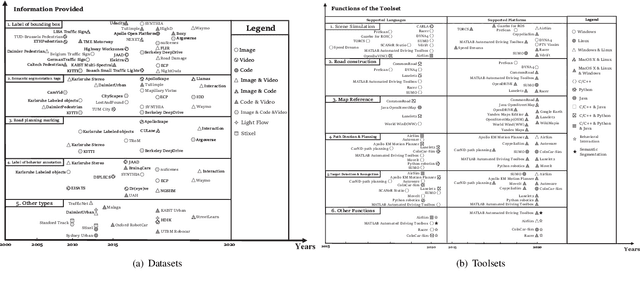
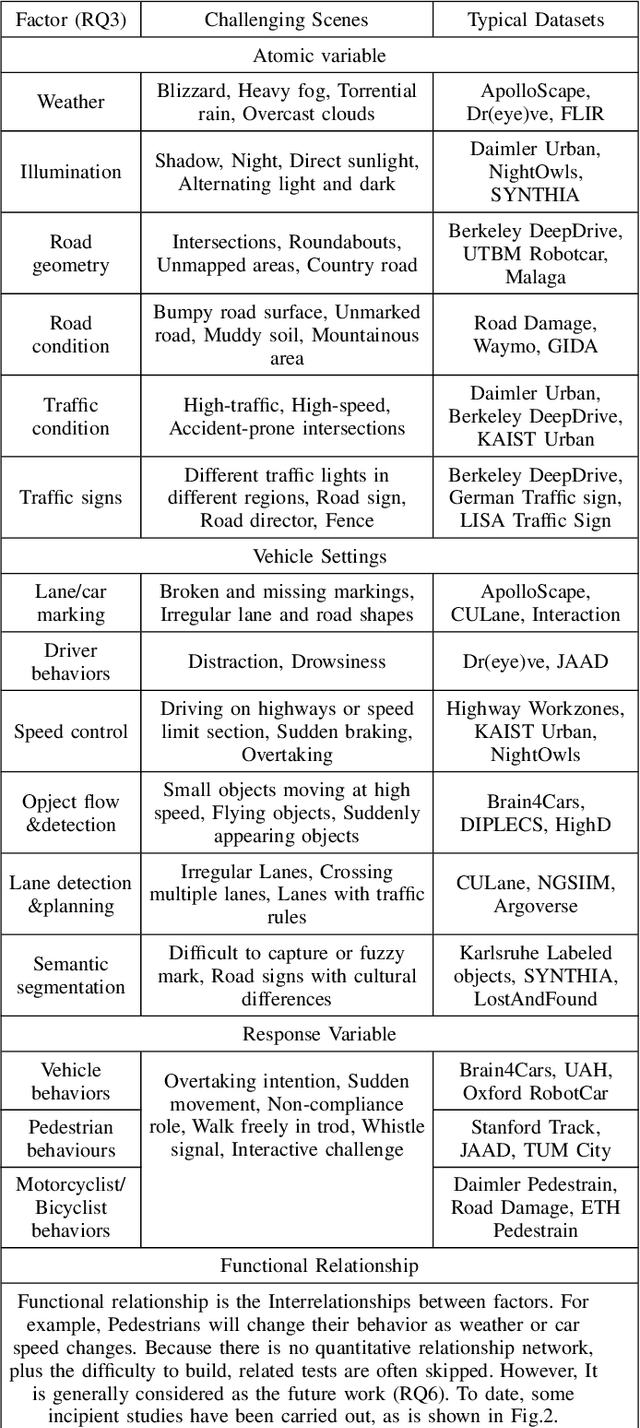
Owing to the merits of early safety and reliability guarantee, autonomous driving virtual testing has recently gains increasing attention compared with closed-loop testing in real scenarios. Although the availability and quality of autonomous driving datasets and toolsets are the premise to diagnose the autonomous driving system bottlenecks and improve the system performance, due to the diversity and privacy of the datasets and toolsets, collecting and featuring the perspective and quality of them become not only time-consuming but also increasingly challenging. This paper first proposes a Systematic Literature Review (SLR) approach for autonomous driving tests, then presents an overview of existing publicly available datasets and toolsets from 2000 to 2020. Quantitative findings with the scenarios concerned, perspectives and trend inferences and suggestions with 35 automated driving test tool sets and 70 test data sets are also presented. To the best of our knowledge, we are the first to perform such recent empirical survey on both the datasets and toolsets using a SLA based survey approach. Our multifaceted analyses and new findings not only reveal insights that we believe are useful for system designers, practitioners and users, but also can promote more researches on a systematic survey analysis in autonomous driving surveys on dataset and toolsets.
Machine Learning Methods for Histopathological Image Analysis: A Review
Feb 07, 2021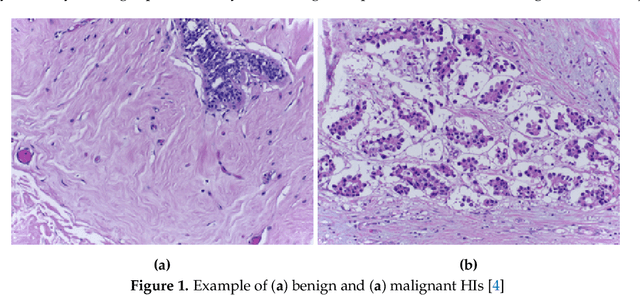
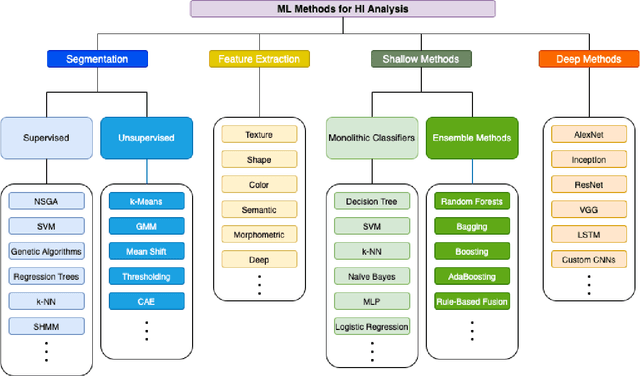
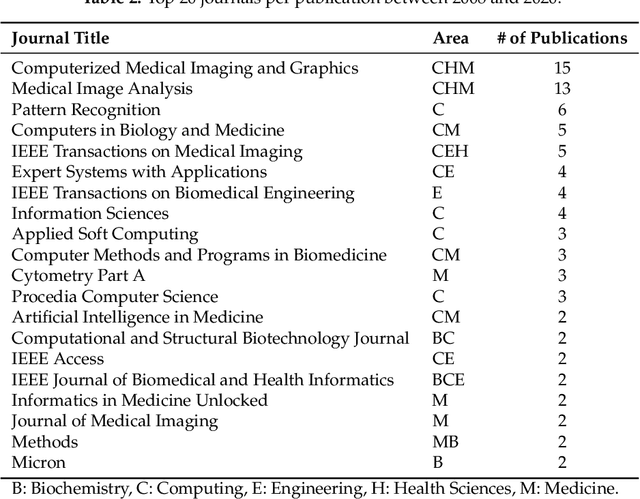
Histopathological images (HIs) are the gold standard for evaluating some types of tumors for cancer diagnosis. The analysis of such images is not only time and resource consuming, but also very challenging even for experienced pathologists, resulting in inter- and intra-observer disagreements. One of the ways of accelerating such an analysis is to use computer-aided diagnosis (CAD) systems. In this paper, we present a review on machine learning methods for histopathological image analysis, including shallow and deep learning methods. We also cover the most common tasks in HI analysis, such as segmentation and feature extraction. In addition, we present a list of publicly available and private datasets that have been used in HI research.