 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Causal Discovery of a River Network from its Extremes
Feb 11, 2021
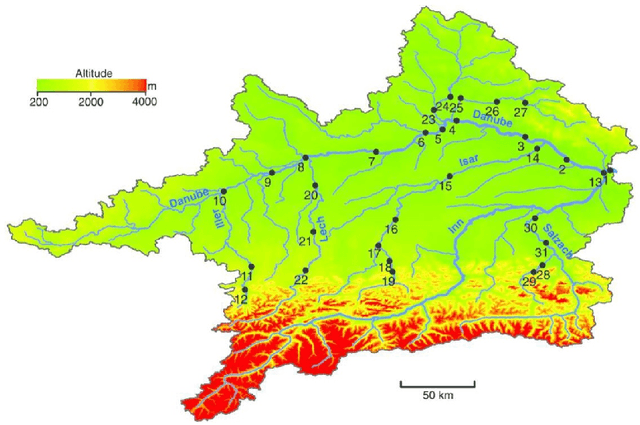
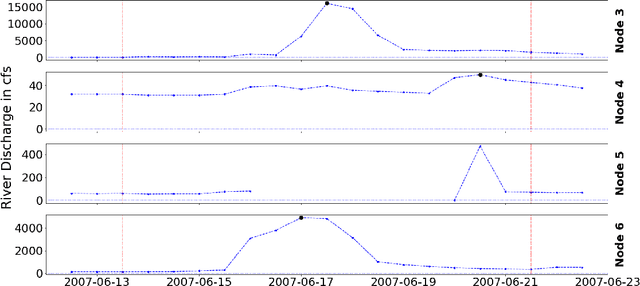
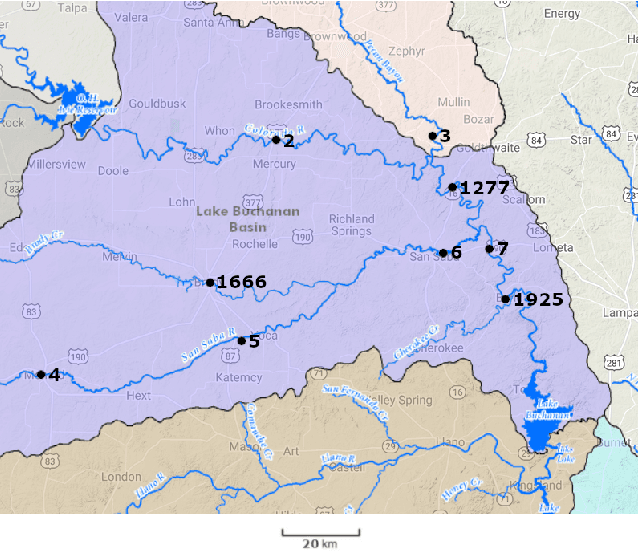

Causal inference for extremes aims to discover cause and effect relations between large observed values of random variables. Over the last years, a number of methods have been proposed for solving the Hidden River Problem, with the Danube data set as benchmark. In this paper, we provide \QTree, a new and simple algorithm to solve the Hidden River Problem that outperforms existing methods. \QTree\ returns a directed graph and achieves almost perfect recovery on the Danube as well as on new data from the Lower Colorado River. It can handle missing data, has an automated parameter tuning procedure, and runs in time $O(n |V|^2)$, where $n$ is the number of observations and $|V|$ the number of nodes in the graph. \QTree\ relies on qualitative aspects of the max-linear Bayesian network model.
Dual-Task Mutual Learning for Semi-Supervised Medical Image Segmentation
Mar 08, 2021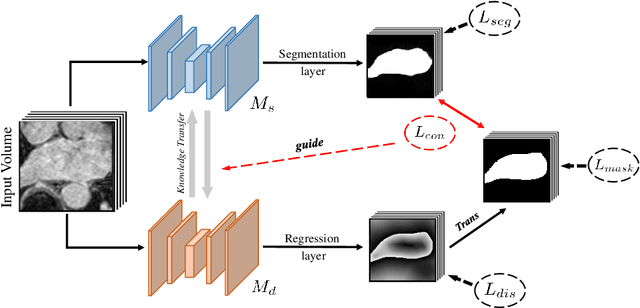
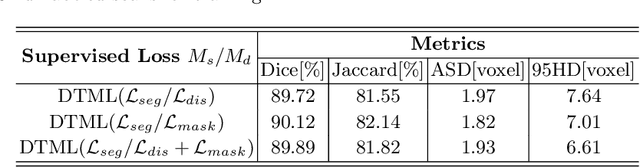
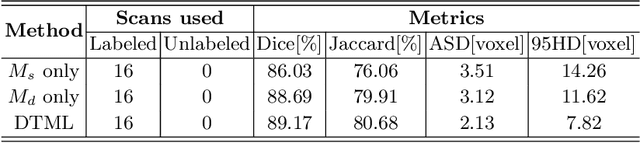
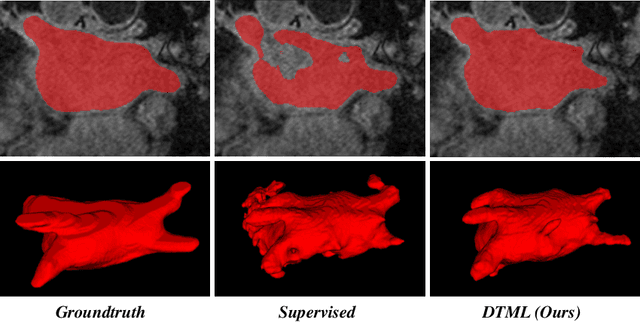
The success of deep learning methods in medical image segmentation tasks usually requires a large amount of labeled data. However, obtaining reliable annotations is expensive and time-consuming. Semi-supervised learning has attracted much attention in medical image segmentation by taking the advantage of unlabeled data which is much easier to acquire. In this paper, we propose a novel dual-task mutual learning framework for semi-supervised medical image segmentation. Our framework can be formulated as an integration of two individual segmentation networks based on two tasks: learning region-based shape constraint and learning boundary-based surface mismatch. Different from the one-way transfer between teacher and student networks, an ensemble of dual-task students can learn collaboratively and implicitly explore useful knowledge from each other during the training process. By jointly learning the segmentation probability maps and signed distance maps of targets, our framework can enforce the geometric shape constraint and learn more reliable information. Experimental results demonstrate that our method achieves performance gains by leveraging unlabeled data and outperforms the state-of-the-art semi-supervised segmentation methods.
Detecting Concrete Abnormality Using Time-series Thermal Imaging and Supervised Learning
Apr 15, 2018
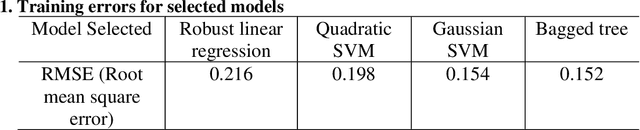
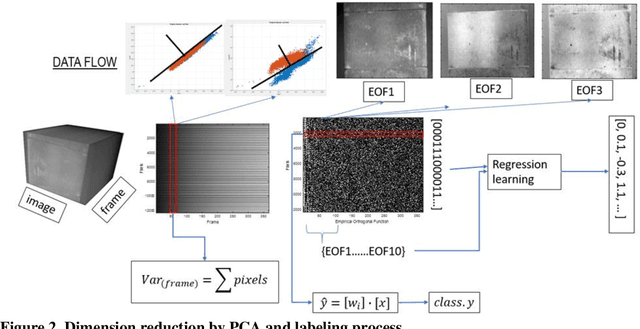
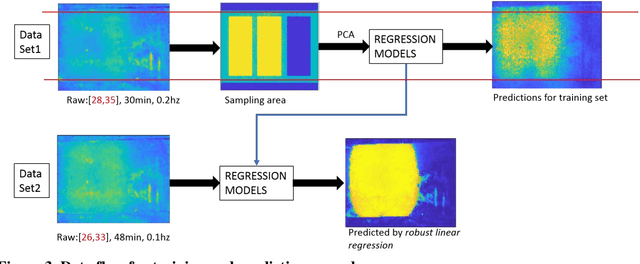
Nondestructive detecting defects (NDD) in concrete structures have been explored for decades. Although limited successes were reported, major limitations still exist. The major limitations are the high noises to signal ratio created from the environmental factors, such as cloud, shadow, water, surface texture etc. and the decision making still relies on the engineering judgment of interpretation of image content. Time-series approach, such as principle component thermography approach has been experimented with some improved results. Recent progress in image processing using machine learning approach made it possible for detecting defects thermal features in more quantitative ways. In this paper, we provide a procedure to represent the thermal feature in the time domain by principal component analysis and regress the prediction of detection by two schemes of supervised learning models. Three independent experiments were conducted in a similar laboratory setup but varied in conditions to illustrate the performance and generalization of models. Results showed the effectiveness for the detection purpose with appropriate tuning for parameters. Future studies will focus on implementing more sophisticated structured models to handle more realistic cases under natural conditions.
Real-time Joint Object Detection and Semantic Segmentation Network for Automated Driving
Jan 12, 2019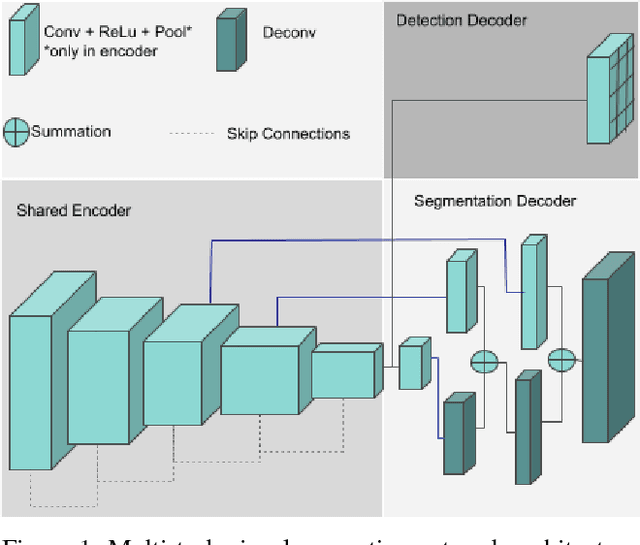
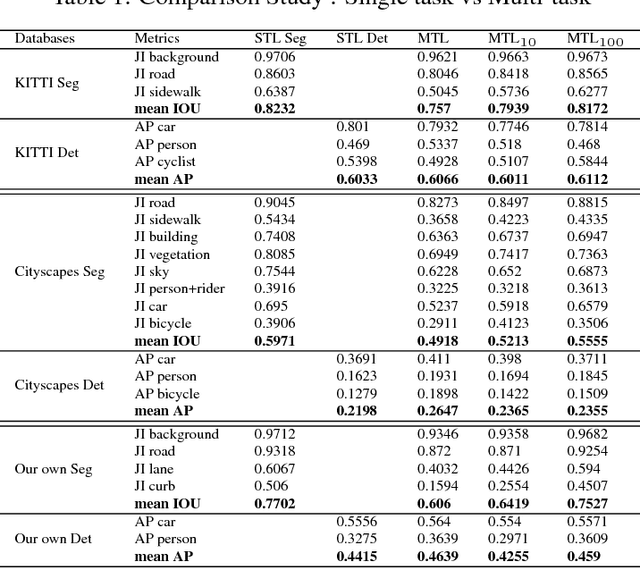

Convolutional Neural Networks (CNN) are successfully used for various visual perception tasks including bounding box object detection, semantic segmentation, optical flow, depth estimation and visual SLAM. Generally these tasks are independently explored and modeled. In this paper, we present a joint multi-task network design for learning object detection and semantic segmentation simultaneously. The main motivation is to achieve real-time performance on a low power embedded SOC by sharing of encoder for both the tasks. We construct an efficient architecture using a small ResNet10 like encoder which is shared for both decoders. Object detection uses YOLO v2 like decoder and semantic segmentation uses FCN8 like decoder. We evaluate the proposed network in two public datasets (KITTI, Cityscapes) and in our private fisheye camera dataset, and demonstrate that joint network provides the same accuracy as that of separate networks. We further optimize the network to achieve 30 fps for 1280x384 resolution image.
Real-time Fruit Recognition and Grasp Estimation for Autonomous Apple harvesting
Mar 30, 2020


In this research, a fully neural network based visual perception framework for autonomous apple harvesting is proposed. The proposed framework includes a multi-function neural network for fruit recognition and a Pointnet grasp estimation to determine the proper grasp pose to guide the robotic execution. Fruit recognition takes raw input of RGB images from the RGB-D camera to perform fruit detection and instance segmentation, and Pointnet grasp estimation take point cloud of each fruit as input and output the prediction of grasp pose for each of fruits. The proposed framework is validated by using RGB-D images collected from laboratory and orchard environments, a robotic grasping test in a controlled environment is also included in the experiments. Experimental shows that the proposed framework can accurately localise and estimate the grasp pose for robotic grasping.
DCVNet: Dilated Cost Volume Networks for Fast Optical Flow
Mar 31, 2021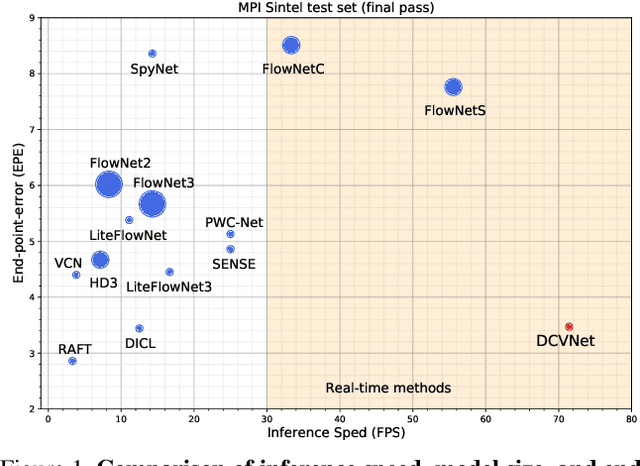
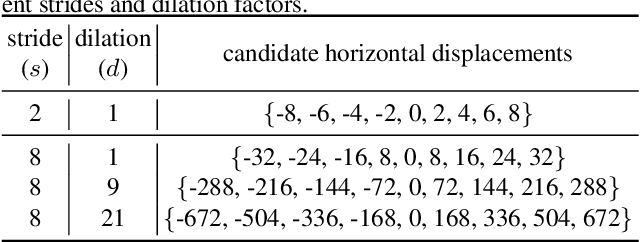
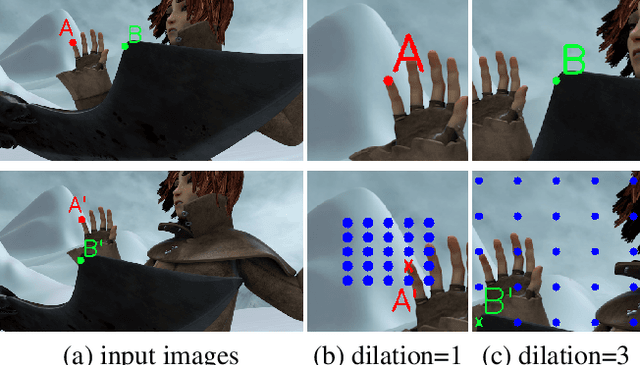
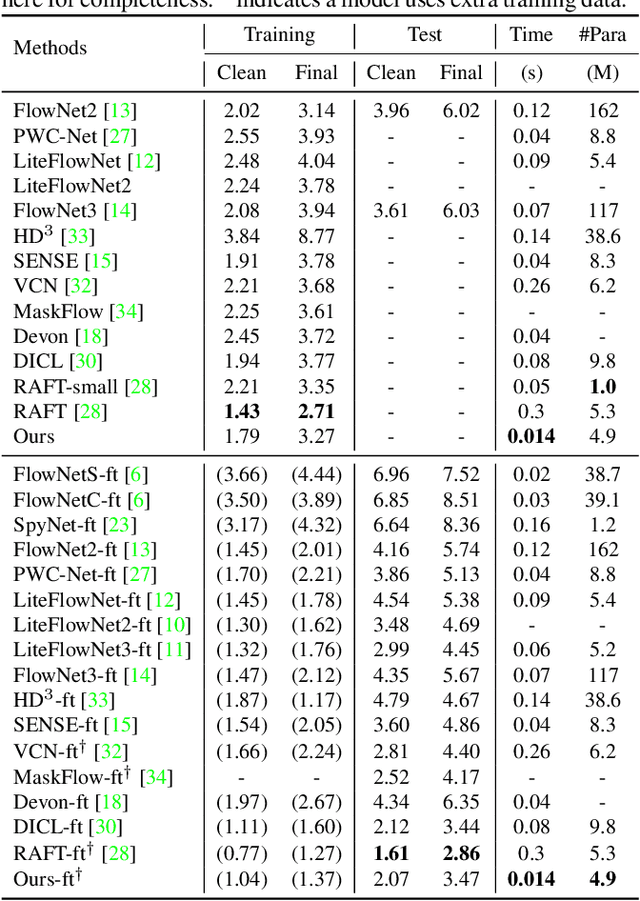
The cost volume, capturing the similarity of possible correspondences across two input images, is a key ingredient in state-of-the-art optical flow approaches. When sampling for correspondences to build the cost volume, a large neighborhood radius is required to deal with large displacements, introducing a significant computational burden. To address this, a sequential strategy is usually adopted, where correspondence sampling in a local neighborhood with a small radius suffices. However, such sequential approaches, instantiated by either a pyramid structure over a deep neural network's feature hierarchy or by a recurrent neural network, are slow due to the inherent need for sequential processing of cost volumes. In this paper, we propose dilated cost volumes to capture small and large displacements simultaneously, allowing optical flow estimation without the need for the sequential estimation strategy. To process the cost volume to get pixel-wise optical flow, existing approaches employ 2D or separable 4D convolutions, which we show either suffer from high GPU memory consumption, inferior accuracy, or large model size. Therefore, we propose using 3D convolutions for cost volume filtering to address these issues. By combining the dilated cost volumes and 3D convolutions, our proposed model DCVNet not only exhibits real-time inference (71 fps on a mid-end 1080ti GPU) but is also compact and obtains comparable accuracy to existing approaches.
Tag-based Genetic Regulation for Genetic Programming
Dec 16, 2020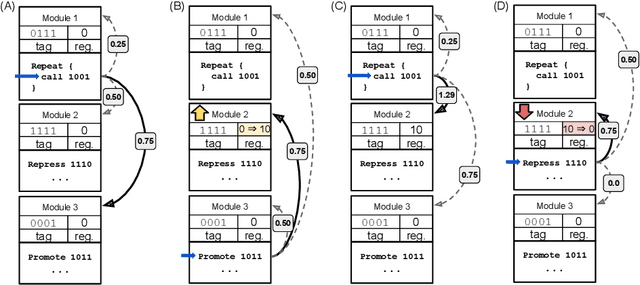
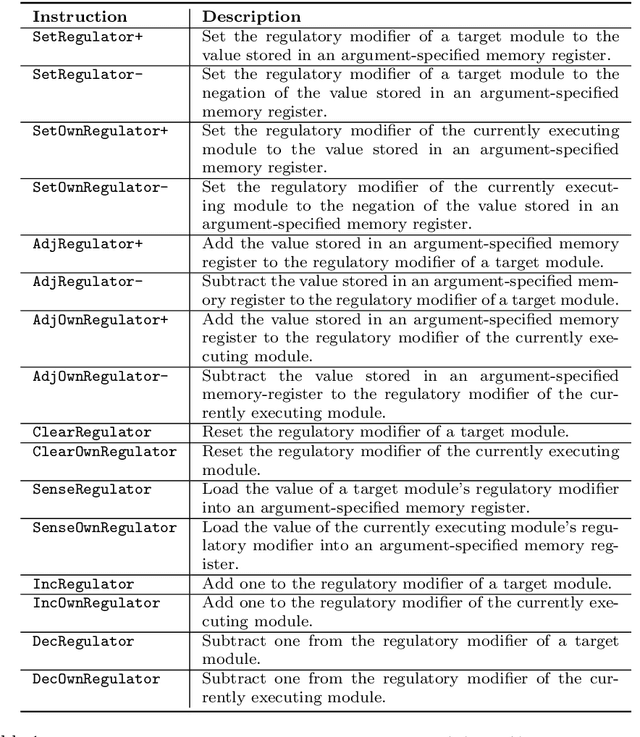
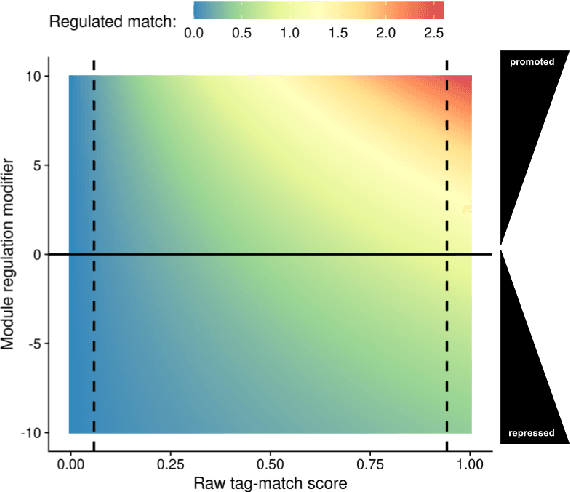
We introduce and experimentally demonstrate tag-based genetic regulation, a new genetic programming (GP) technique that allows evolving programs to conditionally express code modules. Tags are evolvable names that provide a flexible mechanism for labeling and referring to code modules. Tag-based genetic regulation extends existing tag-based naming schemes to allow programs to "promote" and "repress" code modules. This extension allows evolution to structure a program as an arbitrary gene regulatory network where genes are program modules and program instructions mediate regulation. We demonstrate the functionality of tag-based regulation on several diagnostic tasks as well as a more challenging program synthesis problem. We find that tag-based regulation improves problem-solving performance on context-dependent problems where programs must adjust responses to particular inputs over time (e.g., based on local context). We also observe that our implementation of tag-based genetic regulation can impede adaptive evolution when expected outputs are not context-dependent (i.e., the correct response to a particular input remains static over time). Tag-based genetic regulation broadens our repertoire of techniques for evolving more dynamic genetic programs and can easily be incorporated into existing tag-enabled GP systems.
CDiNN -Convex Difference Neural Networks
Mar 31, 2021
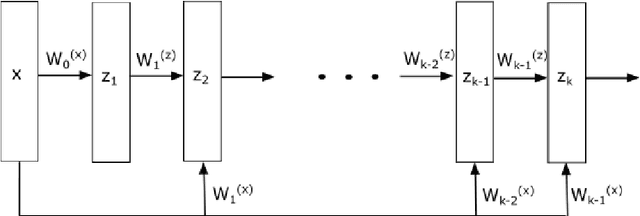
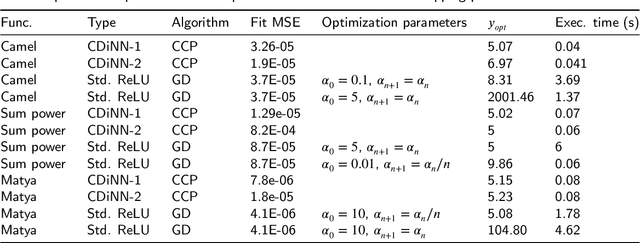
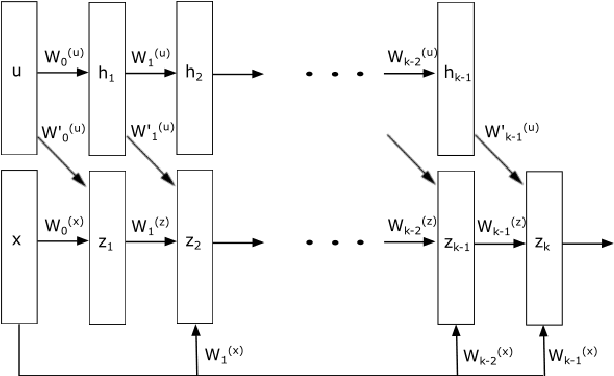
Neural networks with ReLU activation function have been shown to be universal function approximators and learn function mapping as non-smooth functions. Recently, there is considerable interest in the use of neural networks in applications such as optimal control. It is well-known that optimization involving non-convex, non-smooth functions are computationally intensive and have limited convergence guarantees. Moreover, the choice of optimization hyper-parameters used in gradient descent/ascent significantly affect the quality of the obtained solutions. A new neural network architecture called the Input Convex Neural Networks (ICNNs) learn the output as a convex function of inputs thereby allowing the use of efficient convex optimization methods. Use of ICNNs for determining the input for minimizing output has two major problems: learning of a non-convex function as a convex mapping could result in significant function approximation error, and we also note that the existing representations cannot capture simple dynamic structures like linear time delay systems. We attempt to address the above problems by introduction of a new neural network architecture, which we call the CDiNN, which learns the function as a difference of polyhedral convex functions from data. We also discuss that, in some cases, the optimal input can be obtained from CDiNN through difference of convex optimization with convergence guarantees and that at each iteration, the problem is reduced to a linear programming problem.
SALT: A Semi-automatic Labeling Tool for RGB-D Video Sequences
Feb 22, 2021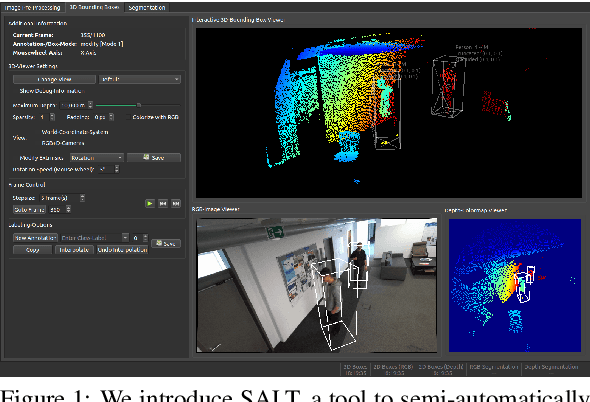
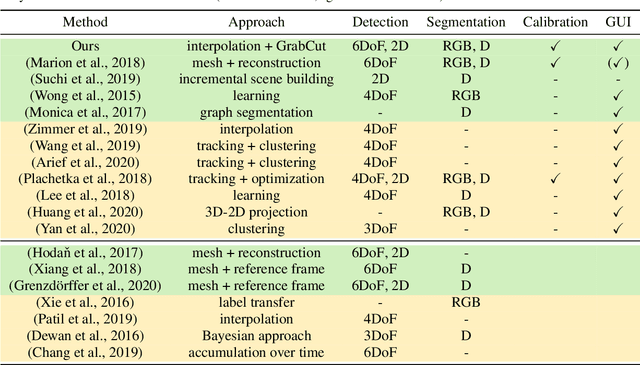
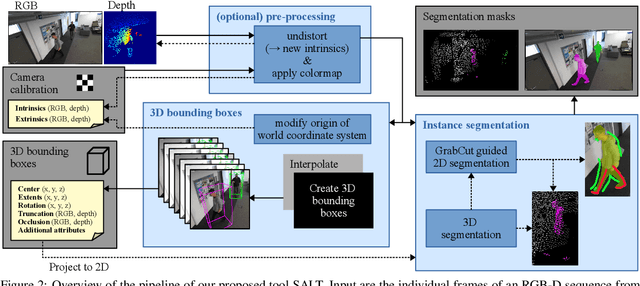
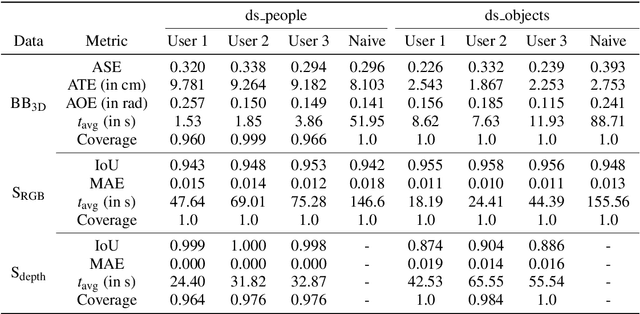
Large labeled data sets are one of the essential basics of modern deep learning techniques. Therefore, there is an increasing need for tools that allow to label large amounts of data as intuitively as possible. In this paper, we introduce SALT, a tool to semi-automatically annotate RGB-D video sequences to generate 3D bounding boxes for full six Degrees of Freedom (DoF) object poses, as well as pixel-level instance segmentation masks for both RGB and depth. Besides bounding box propagation through various interpolation techniques, as well as algorithmically guided instance segmentation, our pipeline also provides built-in pre-processing functionalities to facilitate the data set creation process. By making full use of SALT, annotation time can be reduced by a factor of up to 33.95 for bounding box creation and 8.55 for RGB segmentation without compromising the quality of the automatically generated ground truth.
* VISAPP 2021 full paper (9 pages, 6 figures), published by SciTePress: https://www.scitepress.org/PublicationsDetail.aspx?ID=ywQZ3GZrka8=&t=1
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019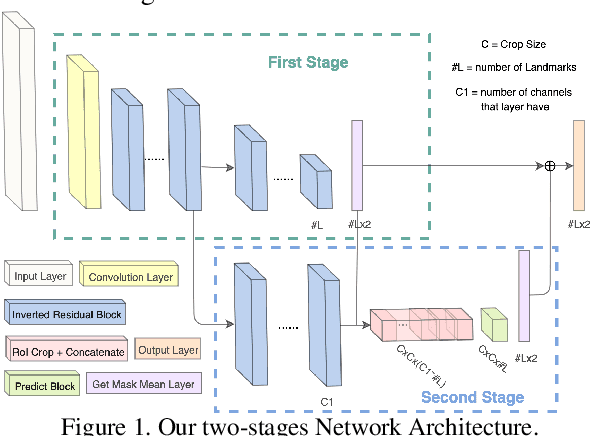

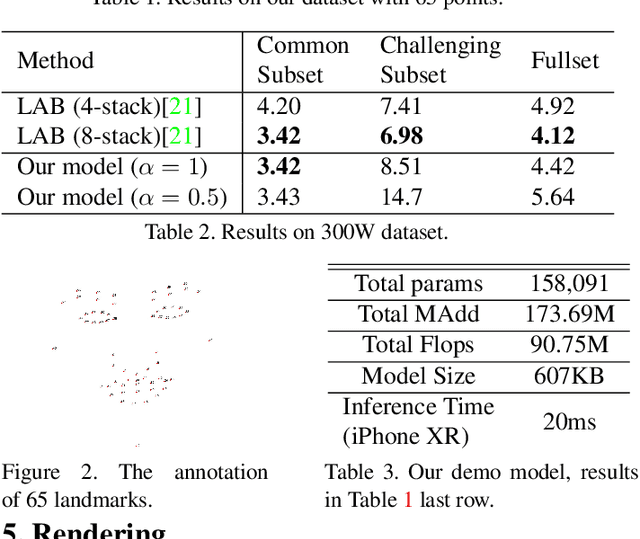
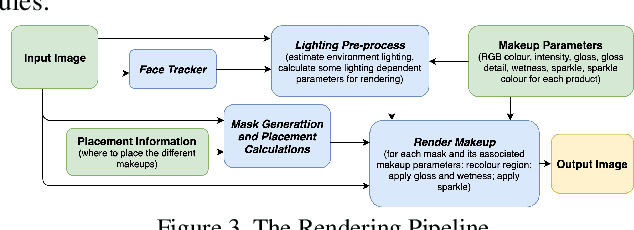
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/