 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Combining Gaussian processes and polynomial chaos expansions for stochastic nonlinear model predictive control
Mar 09, 2021
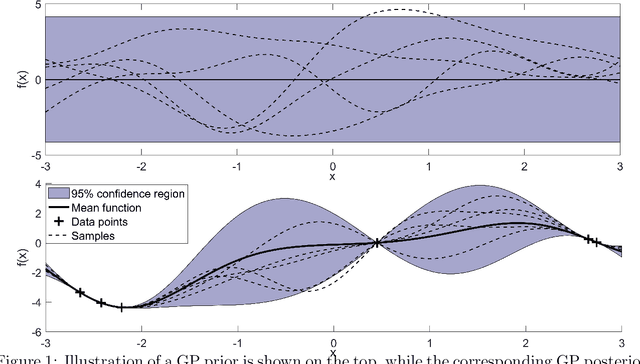
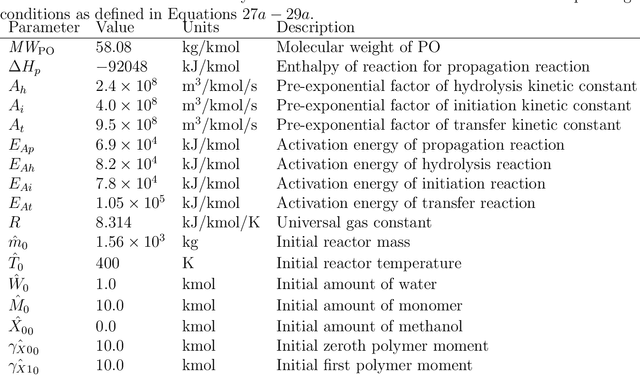
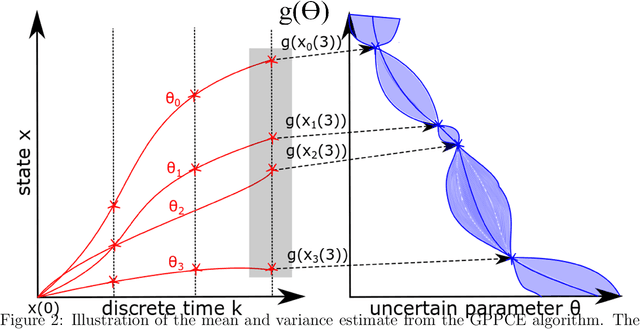
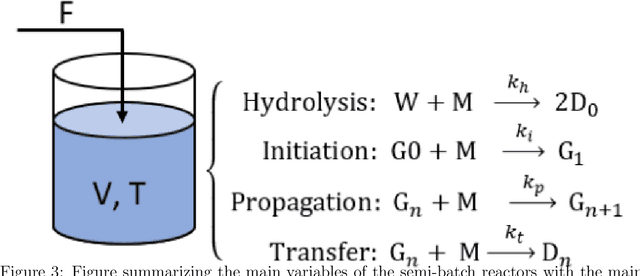
Model predictive control is an advanced control approach for multivariable systems with constraints, which is reliant on an accurate dynamic model. Most real dynamic models are however affected by uncertainties, which can lead to closed-loop performance deterioration and constraint violations. In this paper we introduce a new algorithm to explicitly consider time-invariant stochastic uncertainties in optimal control problems. The difficulty of propagating stochastic variables through nonlinear functions is dealt with by combining Gaussian processes with polynomial chaos expansions. The main novelty in this paper is to use this combination in an efficient fashion to obtain mean and variance estimates of nonlinear transformations. Using this algorithm, it is shown how to formulate both chance-constraints and a probabilistic objective for the optimal control problem. On a batch reactor case study we firstly verify the ability of the new approach to accurately approximate the probability distributions required. Secondly, a tractable stochastic nonlinear model predictive control approach is formulated with an economic objective to demonstrate the closed-loop performance of the method via Monte Carlo simulations.
WiFiMod: Transformer-based Indoor Human Mobility Modeling using Passive Sensing
Apr 20, 2021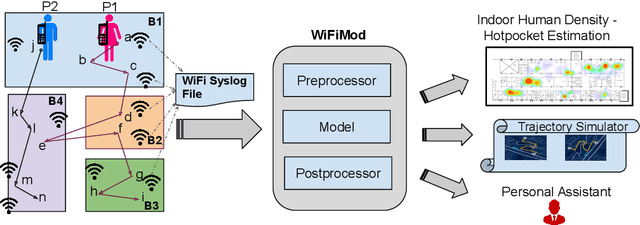

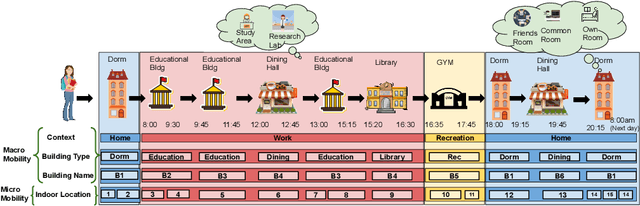
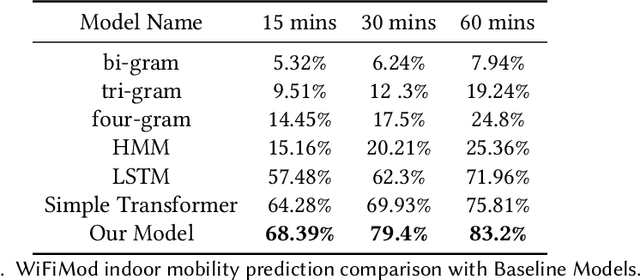
Modeling human mobility has a wide range of applications from urban planning to simulations of disease spread. It is well known that humans spend 80% of their time indoors but modeling indoor human mobility is challenging due to three main reasons: (i) the absence of easily acquirable, reliable, low-cost indoor mobility datasets, (ii) high prediction space in modeling the frequent indoor mobility, and (iii) multi-scalar periodicity and correlations in mobility. To deal with all these challenges, we propose WiFiMod, a Transformer-based, data-driven approach that models indoor human mobility at multiple spatial scales using WiFi system logs. WiFiMod takes as input enterprise WiFi system logs to extract human mobility trajectories from smartphone digital traces. Next, for each extracted trajectory, we identify the mobility features at multiple spatial scales, macro, and micro, to design a multi-modal embedding Transformer that predicts user mobility for several hours to an entire day across multiple spatial granularities. Multi-modal embedding captures the mobility periodicity and correlations across various scales while Transformers capture long-term mobility dependencies boosting model prediction performance. This approach significantly reduces the prediction space by first predicting macro mobility, then modeling indoor scale mobility, micro-mobility, conditioned on the estimated macro mobility distribution, thereby using the topological constraint of the macro-scale. Experimental results show that WiFiMod achieves a prediction accuracy of at least 10% points higher than the current state-of-art models. Additionally, we present 3 real-world applications of WiFiMod - (i) predict high-density hot pockets for policy-making decisions for COVID19 or ILI, (ii) generate a realistic simulation of indoor mobility, (iii) design personal assistants.
CheXbreak: Misclassification Identification for Deep Learning Models Interpreting Chest X-rays
Mar 18, 2021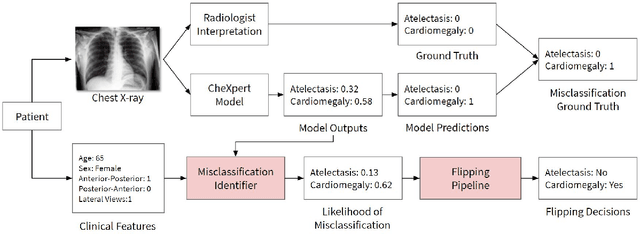
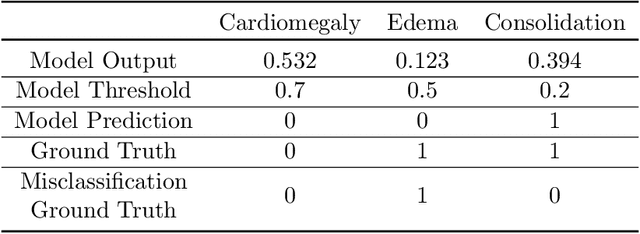
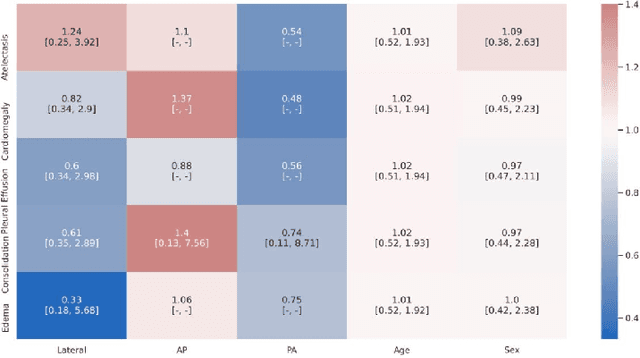
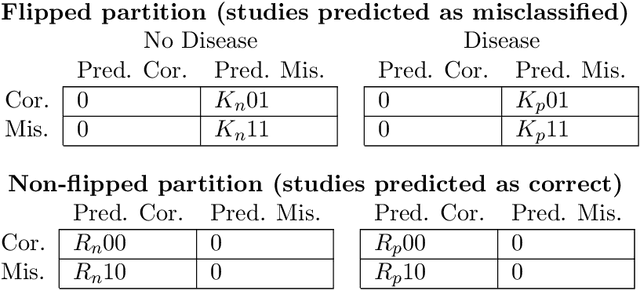
A major obstacle to the integration of deep learning models for chest x-ray interpretation into clinical settings is the lack of understanding of their failure modes. In this work, we first investigate whether there are patient subgroups that chest x-ray models are likely to misclassify. We find that patient age and the radiographic finding of lung lesion or pneumothorax are statistically relevant features for predicting misclassification for some chest x-ray models. Second, we develop misclassification predictors on chest x-ray models using their outputs and clinical features. We find that our best performing misclassification identifier achieves an AUROC close to 0.9 for most diseases. Third, employing our misclassification identifiers, we develop a corrective algorithm to selectively flip model predictions that have high likelihood of misclassification at inference time. We observe F1 improvement on the prediction of Consolidation (0.008 [95\% CI 0.005, 0.010]) and Edema (0.003, [95\% CI 0.001, 0.006]). By carrying out our investigation on ten distinct and high-performing chest x-ray models, we are able to derive insights across model architectures and offer a generalizable framework applicable to other medical imaging tasks.
Modeling Time Series Similarity with Siamese Recurrent Networks
Mar 15, 2016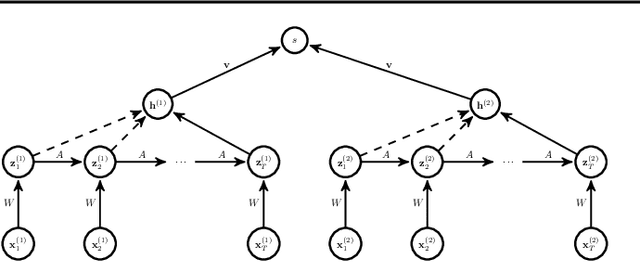
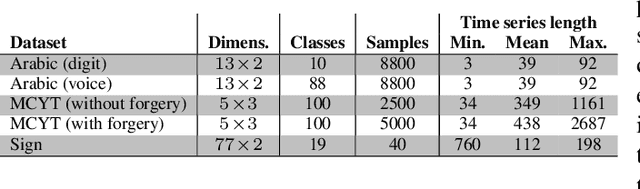
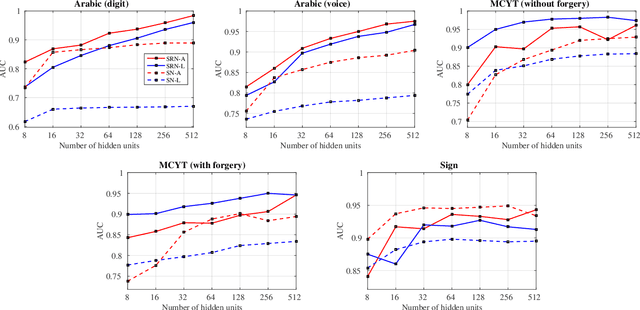
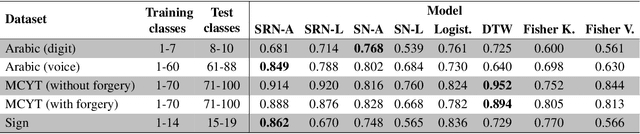
Traditional techniques for measuring similarities between time series are based on handcrafted similarity measures, whereas more recent learning-based approaches cannot exploit external supervision. We combine ideas from time-series modeling and metric learning, and study siamese recurrent networks (SRNs) that minimize a classification loss to learn a good similarity measure between time series. Specifically, our approach learns a vectorial representation for each time series in such a way that similar time series are modeled by similar representations, and dissimilar time series by dissimilar representations. Because it is a similarity prediction models, SRNs are particularly well-suited to challenging scenarios such as signature recognition, in which each person is a separate class and very few examples per class are available. We demonstrate the potential merits of SRNs in within-domain and out-of-domain classification experiments and in one-shot learning experiments on tasks such as signature, voice, and sign language recognition.
Efficient Multi-Stage Video Denoising with Recurrent Spatio-Temporal Fusion
Mar 09, 2021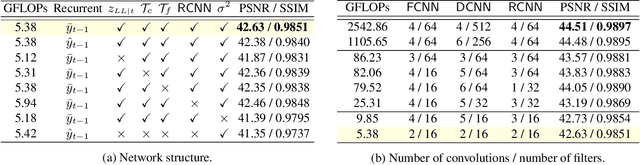
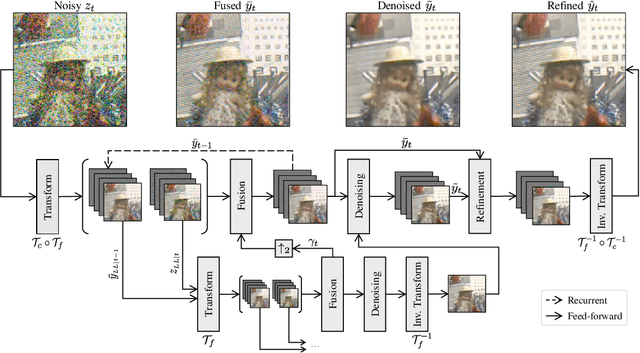
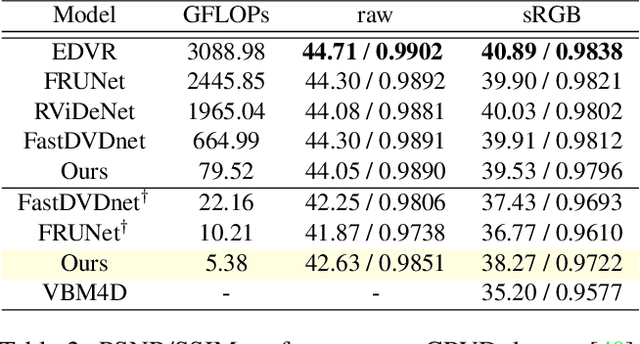
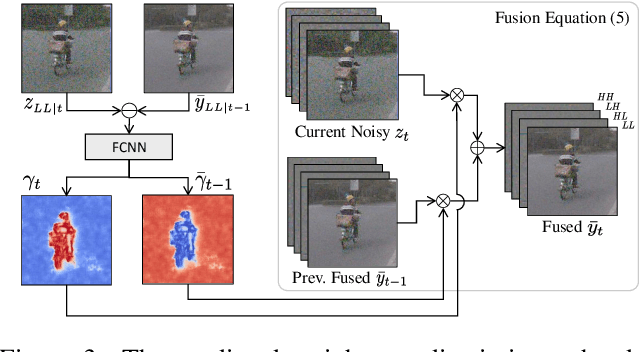
In recent years, methods based on deep learning have achieved unparalleled performance at the cost of large computational complexity. In this work, we propose an Efficient Multi-stage Video Denoising algorithm, called EMVD, to drastically reduce the complexity while maintaining or even improving the performance. First, a fusion stage reduces the noise through a recursive combination of all past frames in the video. Then, a denoising stage removes the noise in the fused frame. Finally, a refinement stage restores the missing high frequency in the denoised frame. All stages operate on a transform-domain representation obtained by learnable and invertible linear operators which simultaneously increase accuracy and decrease complexity of the model. A single loss on the final output is sufficient for successful convergence, hence making EMVD easy to train. Experiments on real raw data demonstrate that EMVD outperforms the state of the art when complexity is constrained, and even remains competitive against methods whose complexities are several orders of magnitude higher. The low complexity and memory requirements of EMVD enable real-time video denoising on low-powered commercial SoC.
Gender bias in magazines oriented to men and women: a computational approach
Nov 24, 2020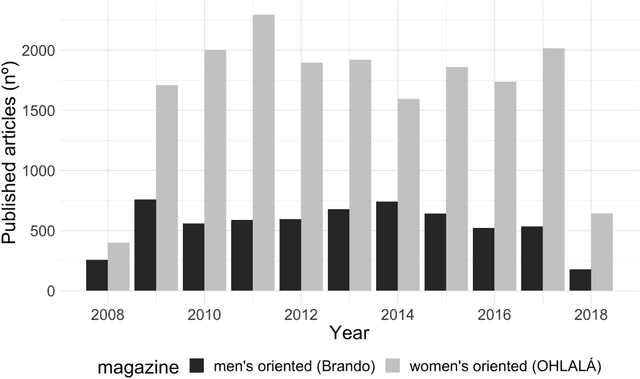

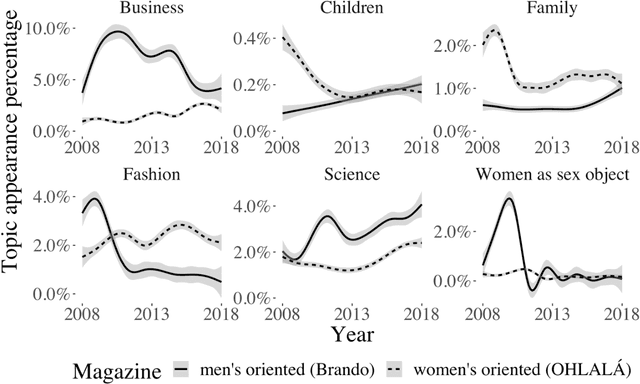

Cultural products are a source to acquire individual values and behaviours. Therefore, the differences in the content of the magazines aimed specifically at women or men are a means to create and reproduce gender stereotypes. In this study, we compare the content of a women-oriented magazine with that of a men-oriented one, both produced by the same editorial group, over a decade (2008-2018). With Topic Modelling techniques we identify the main themes discussed in the magazines and quantify how much the presence of these topics differs between magazines over time. Then, we performed a word-frequency analysis to validate this methodology and extend the analysis to other subjects that did not emerge automatically. Our results show that the frequency of appearance of the topics Family, Business and Women as sex objects, present an initial bias that tends to disappear over time. Conversely, in Fashion and Science topics, the initial differences between both magazines are maintained. Besides, we show that in 2012, the content associated with horoscope increased in the women-oriented magazine, generating a new gap that remained open over time. Also, we show a strong increase in the use of words associated with feminism since 2015 and specifically the word abortion in 2018. Overall, these computational tools allowed us to analyse more than 24,000 articles. Up to our knowledge, this is the first study to compare magazines in such a large dataset, a task that would have been prohibitive using manual content analysis methodologies.
Scaling-up Disentanglement for Image Translation
Mar 25, 2021
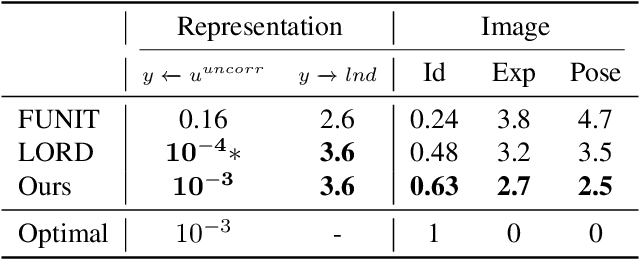

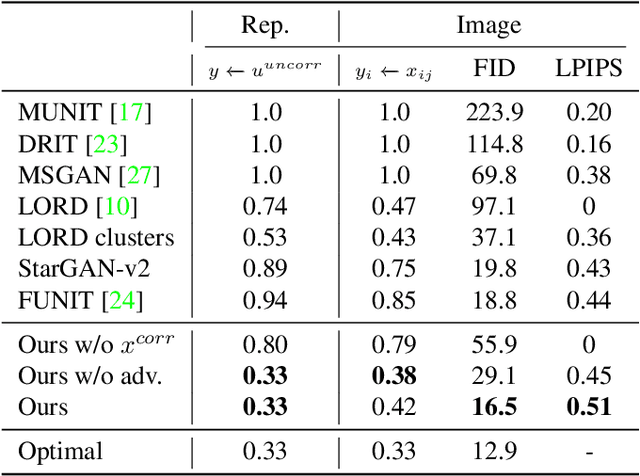
Image translation methods typically aim to manipulate a set of labeled attributes (given as supervision at training time e.g. domain label) while leaving the unlabeled attributes intact. Current methods achieve either: (i) disentanglement, which exhibits low visual fidelity and can only be satisfied where the attributes are perfectly uncorrelated. (ii) visually-plausible translations, which are clearly not disentangled. In this work, we propose OverLORD, a single framework for disentangling labeled and unlabeled attributes as well as synthesizing high-fidelity images, which is composed of two stages; (i) Disentanglement: Learning disentangled representations with latent optimization. Differently from previous approaches, we do not rely on adversarial training or any architectural biases. (ii) Synthesis: Training feed-forward encoders for inferring the learned attributes and tuning the generator in an adversarial manner to increase the perceptual quality. When the labeled and unlabeled attributes are correlated, we model an additional representation that accounts for the correlated attributes and improves disentanglement. We highlight that our flexible framework covers multiple image translation settings e.g. attribute manipulation, pose-appearance translation, segmentation-guided synthesis and shape-texture transfer. In an extensive evaluation, we present significantly better disentanglement with higher translation quality and greater output diversity than state-of-the-art methods.
Computation and Bribery of Voting Power in Delegative Simple Games
Apr 08, 2021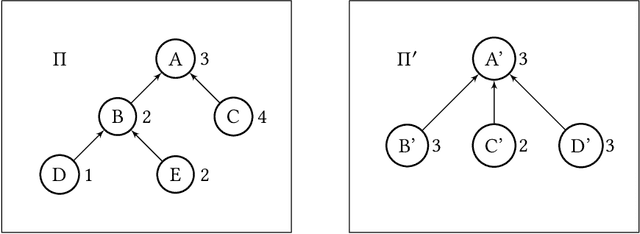
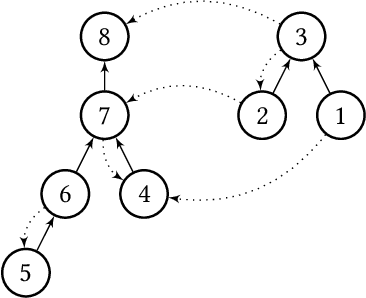

Weighted voting games is one of the most important classes of cooperative games. Recently, Zhang and Grossi [53] proposed a variant of this class, called delegative simple games, which is well suited to analyse the relative importance of each voter in liquid democracy elections. Moreover, they defined a power index, called the delagative Banzhaf index to compute the importance of each agent (i.e., both voters and delegators) in a delegation graph based on two key parameters: the total voting weight she has accumulated and the structure of supports she receives from her delegators. We obtain several results related to delegative simple games. We first propose a pseudo-polynomial time algorithm to compute the delegative Banzhaf and Shapley-Shubik values in delegative simple games. We then investigate a bribery problem where the goal is to maximize/minimize the voting power/weight of a given voter in a delegation graph by changing at most a fixed number of delegations. We show that the problems of minimizing/maximizing a voter's power index value are strongly NP-hard. Furthermore, we prove that having a better approximation guarantee than $1-1/e$ to maximize the voting weight of a voter is not possible, unless $P = NP$, then we provide some parameterized complexity results for this problem. Finally, we show that finding a delegation graph with a given number of gurus that maximizes the minimum power index value an agent can have is a computationally hard problem.
Inferring the time-varying functional connectivity of large-scale computer networks from emitted events
Feb 12, 2018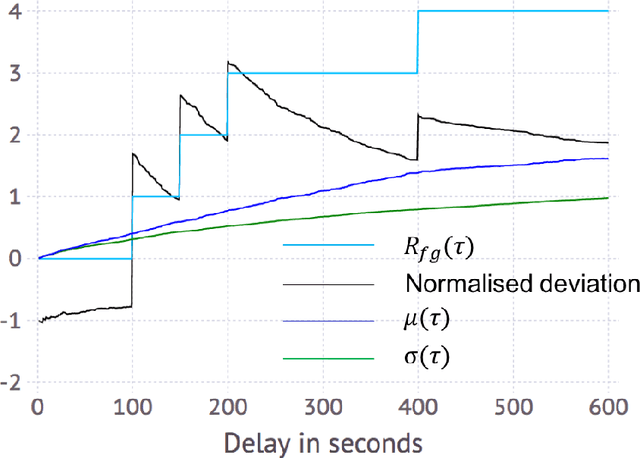
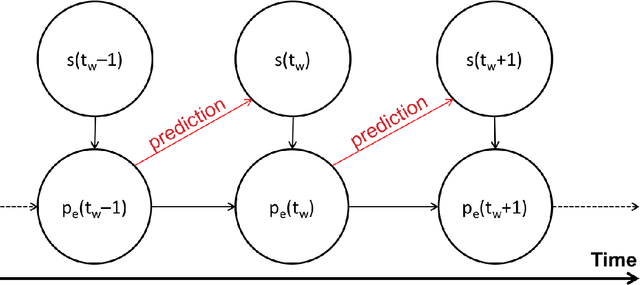
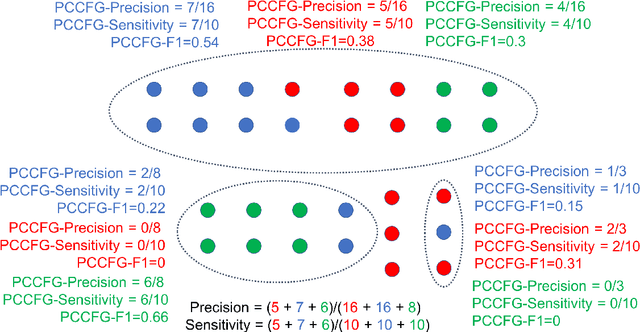
We consider the problem of inferring the functional connectivity of a large-scale computer network from sparse time series of events emitted by its nodes. We do so under the following three domain-specific constraints: (a) non-stationarity of the functional connectivity due to unknown temporal changes in the network, (b) sparsity of the time-series of events that limits the effectiveness of classical correlation-based analysis, and (c) lack of an explicit model describing how events propagate through the network. Under the assumption that the probability of two nodes being functionally connected correlates with the mean delay between their respective events, we develop an inference method whose output is an undirected weighted network where the weight of an edge between two nodes denotes the probability of these nodes being functionally connected. Using a combination of windowing and convolution to calculate at each time window a score quantifying the likelihood of a pair of nodes emitting events in quick succession, we develop a model of time-varying connectivity whose parameters are determined by maximising the model's predictive power from one time window to the next. To assess the effectiveness of our inference method, we construct synthetic data for which ground truth is available and use these data to benchmark our approach against three state-of-the-art inference methods. We conclude by discussing its application to data from a real-world large-scale computer network.
Anticipatory Navigation in Crowds by Probabilistic Prediction of Pedestrian Future Movements
Nov 12, 2020
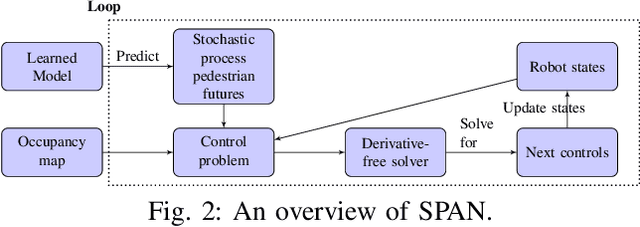

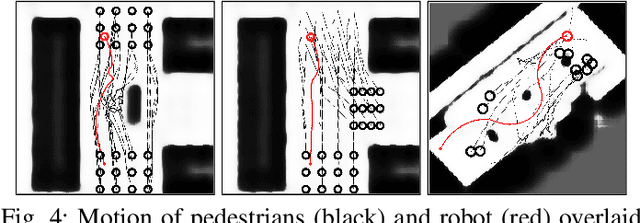
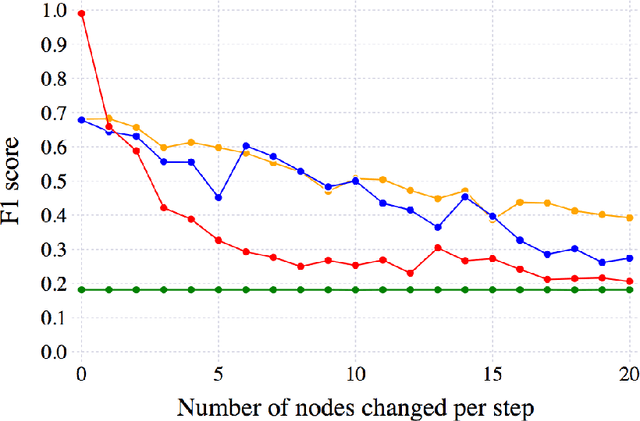
Critical for the coexistence of humans and robots in dynamic environments is the capability for agents to understand each other's actions, and anticipate their movements. This paper presents Stochastic Process Anticipatory Navigation (SPAN), a framework that enables nonholonomic robots to navigate in environments with crowds, while anticipating and accounting for the motion patterns of pedestrians. To this end, we learn a predictive model to predict continuous-time stochastic processes to model future movement of pedestrians. Anticipated pedestrian positions are used to conduct chance constrained collision-checking, and are incorporated into a time-to-collision control problem. An occupancy map is also integrated to allow for probabilistic collision-checking with static obstacles. We demonstrate the capability of SPAN in crowded simulation environments, as well as with a real-world pedestrian dataset.