 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
On the Power of Localized Perceptron for Label-Optimal Learning of Halfspaces with Adversarial Noise
Jan 20, 2021

We study {\em online} active learning of homogeneous halfspaces in $\mathbb{R}^d$ with adversarial noise where the overall probability of a noisy label is constrained to be at most $\nu$. Our main contribution is a Perceptron-like online active learning algorithm that runs in polynomial time, and under the conditions that the marginal distribution is isotropic log-concave and $\nu = \Omega(\epsilon)$, where $\epsilon \in (0, 1)$ is the target error rate, our algorithm PAC learns the underlying halfspace with near-optimal label complexity of $\tilde{O}\big(d \cdot polylog(\frac{1}{\epsilon})\big)$ and sample complexity of $\tilde{O}\big(\frac{d}{\epsilon} \big)$. Prior to this work, existing online algorithms designed for tolerating the adversarial noise are subject to either label complexity polynomial in $\frac{1}{\epsilon}$, or suboptimal noise tolerance, or restrictive marginal distributions. With the additional prior knowledge that the underlying halfspace is $s$-sparse, we obtain attribute-efficient label complexity of $\tilde{O}\big( s \cdot polylog(d, \frac{1}{\epsilon}) \big)$ and sample complexity of $\tilde{O}\big(\frac{s}{\epsilon} \cdot polylog(d) \big)$. As an immediate corollary, we show that under the agnostic model where no assumption is made on the noise rate $\nu$, our active learner achieves an error rate of $O(OPT) + \epsilon$ with the same running time and label and sample complexity, where $OPT$ is the best possible error rate achievable by any homogeneous halfspace.
Measuring Recommender System Effects with Simulated Users
Jan 12, 2021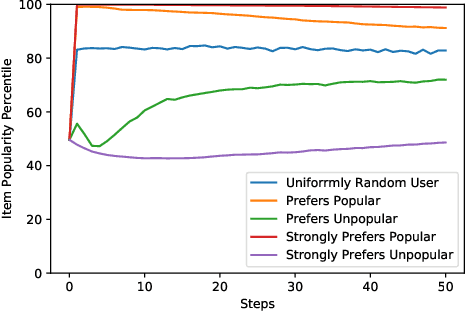

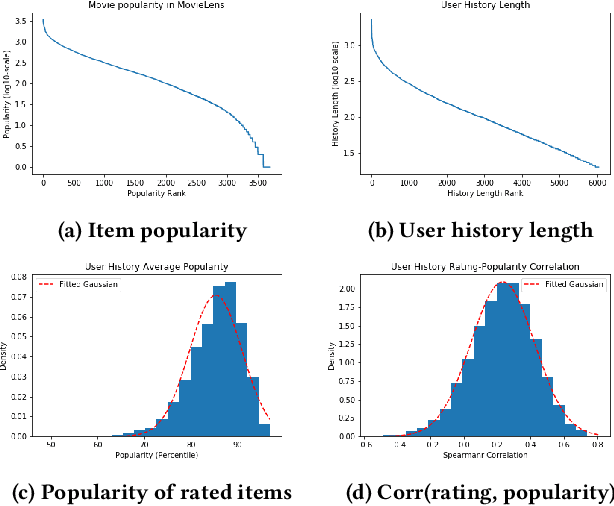
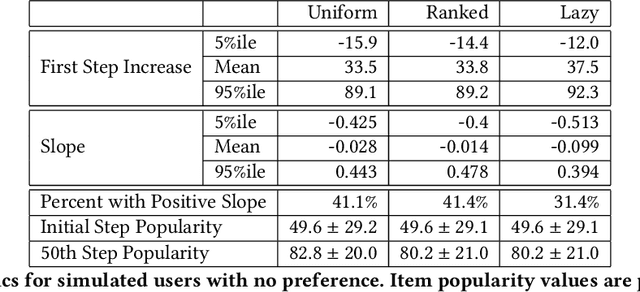
Imagine a food recommender system -- how would we check if it is \emph{causing} and fostering unhealthy eating habits or merely reflecting users' interests? How much of a user's experience over time with a recommender is caused by the recommender system's choices and biases, and how much is based on the user's preferences and biases? Popularity bias and filter bubbles are two of the most well-studied recommender system biases, but most of the prior research has focused on understanding the system behavior in a single recommendation step. How do these biases interplay with user behavior, and what types of user experiences are created from repeated interactions? In this work, we offer a simulation framework for measuring the impact of a recommender system under different types of user behavior. Using this simulation framework, we can (a) isolate the effect of the recommender system from the user preferences, and (b) examine how the system performs not just on average for an "average user" but also the extreme experiences under atypical user behavior. As part of the simulation framework, we propose a set of evaluation metrics over the simulations to understand the recommender system's behavior. Finally, we present two empirical case studies -- one on traditional collaborative filtering in MovieLens and one on a large-scale production recommender system -- to understand how popularity bias manifests over time.
StressNet: Deep Learning to Predict Stress With Fracture Propagation in Brittle Materials
Nov 20, 2020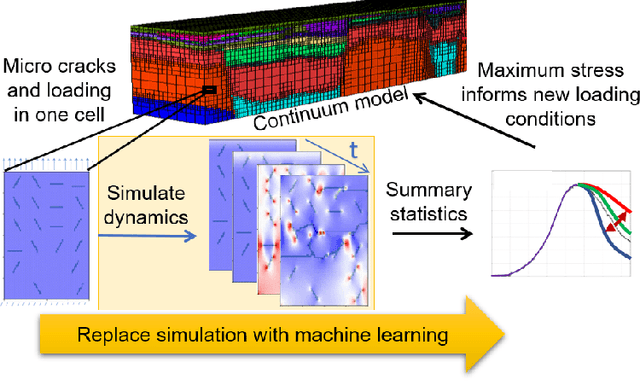

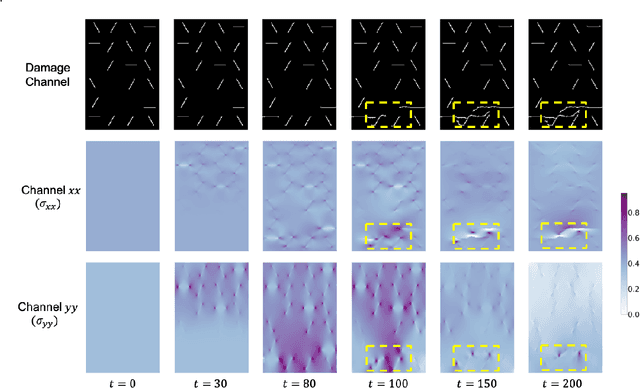

Catastrophic failure in brittle materials is often due to the rapid growth and coalescence of cracks aided by high internal stresses. Hence, accurate prediction of maximum internal stress is critical to predicting time to failure and improving the fracture resistance and reliability of materials. Existing high-fidelity methods, such as the Finite-Discrete Element Model (FDEM), are limited by their high computational cost. Therefore, to reduce computational cost while preserving accuracy, a novel deep learning model, "StressNet," is proposed to predict the entire sequence of maximum internal stress based on fracture propagation and the initial stress data. More specifically, the Temporal Independent Convolutional Neural Network (TI-CNN) is designed to capture the spatial features of fractures like fracture path and spall regions, and the Bidirectional Long Short-term Memory (Bi-LSTM) Network is adapted to capture the temporal features. By fusing these features, the evolution in time of the maximum internal stress can be accurately predicted. Moreover, an adaptive loss function is designed by dynamically integrating the Mean Squared Error (MSE) and the Mean Absolute Percentage Error (MAPE), to reflect the fluctuations in maximum internal stress. After training, the proposed model is able to compute accurate multi-step predictions of maximum internal stress in approximately 20 seconds, as compared to the FDEM run time of 4 hours, with an average MAPE of 2% relative to test data.
SparsePoint: Fully End-to-End Sparse 3D Object Detector
Mar 18, 2021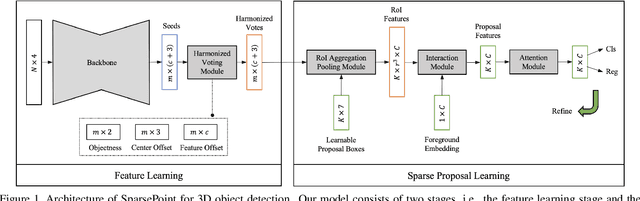
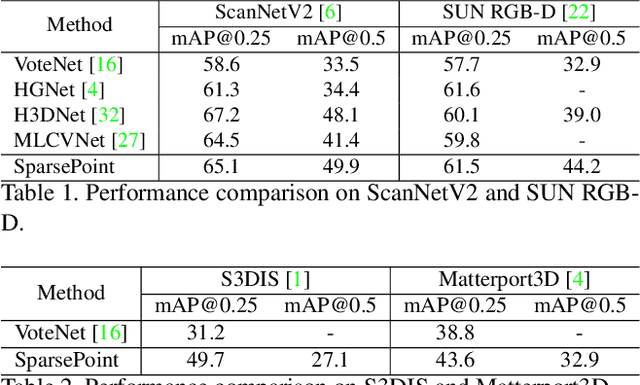
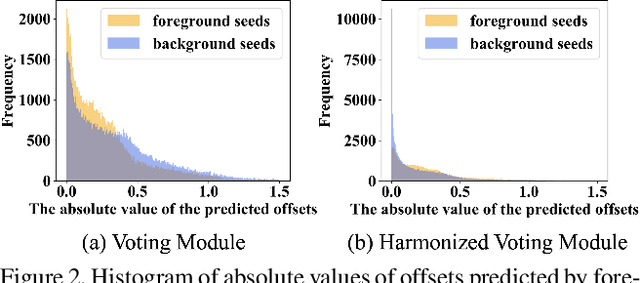
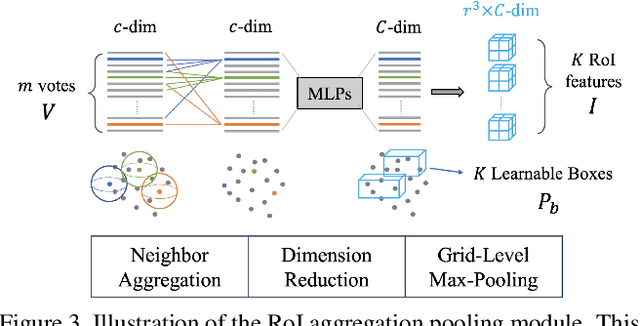
Object detectors based on sparse object proposals have recently been proven to be successful in the 2D domain, which makes it possible to establish a fully end-to-end detector without time-consuming post-processing. This development is also attractive for 3D object detectors. However, considering the remarkably larger search space in the 3D domain, whether it is feasible to adopt the sparse method in the 3D object detection setting is still an open question. In this paper, we propose SparsePoint, the first sparse method for 3D object detection. Our SparsePoint adopts a number of learnable proposals to encode most likely potential positions of 3D objects and a foreground embedding to encode shared semantic features of all objects. Besides, with the attention module to provide object-level interaction for redundant proposal removal and Hungarian algorithm to supply one-one label assignment, our method can produce sparse and accurate predictions. SparsePoint sets a new state-of-the-art on four public datasets, including ScanNetV2, SUN RGB-D, S3DIS, and Matterport3D. Our code will be publicly available soon.
Crop Classification under Varying Cloud Cover with Neural Ordinary Differential Equations
Dec 04, 2020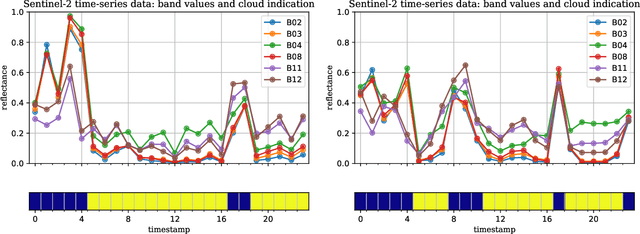

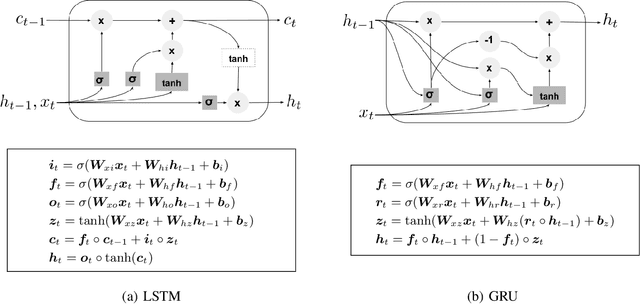
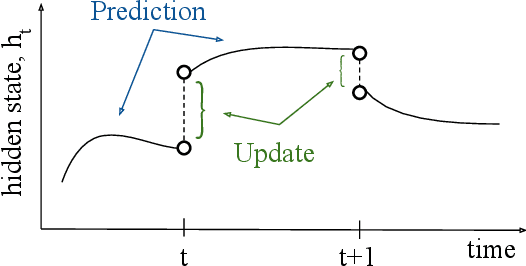
Optical satellite sensors cannot see the Earth's surface through clouds. Despite the periodic revisit cycle, image sequences acquired by Earth observation satellites are therefore irregularly sampled in time. State-of-the-art methods for crop classification (and other time series analysis tasks) rely on techniques that implicitly assume regular temporal spacing between observations, such as recurrent neural networks (RNNs). We propose to use neural ordinary differential equations (NODEs) in combination with RNNs to classify crop types in irregularly spaced image sequences. The resulting ODE-RNN models consist of two steps: an update step, where a recurrent unit assimilates new input data into the model's hidden state; and a prediction step, in which NODE propagates the hidden state until the next observation arrives. The prediction step is based on a continuous representation of the latent dynamics, which has several advantages. At the conceptual level, it is a more natural way to describe the mechanisms that govern the phenological cycle. From a practical point of view, it makes it possible to sample the system state at arbitrary points in time, such that one can integrate observations whenever they are available, and extrapolate beyond the last observation. Our experiments show that ODE-RNN indeed improves classification accuracy over common baselines such as LSTM, GRU, and temporal convolution. The gains are most prominent in the challenging scenario where only few observations are available (i.e., frequent cloud cover). Moreover, we show that the ability to extrapolate translates to better classification performance early in the season, which is important for forecasting.
Reliable Fleet Analytics for Edge IoT Solutions
Jan 12, 2021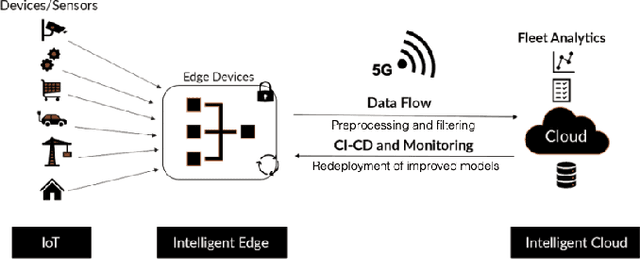
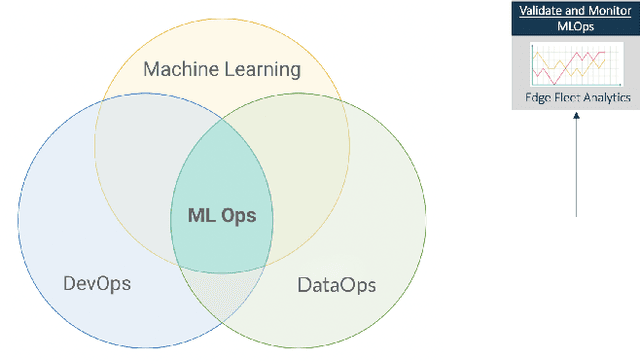
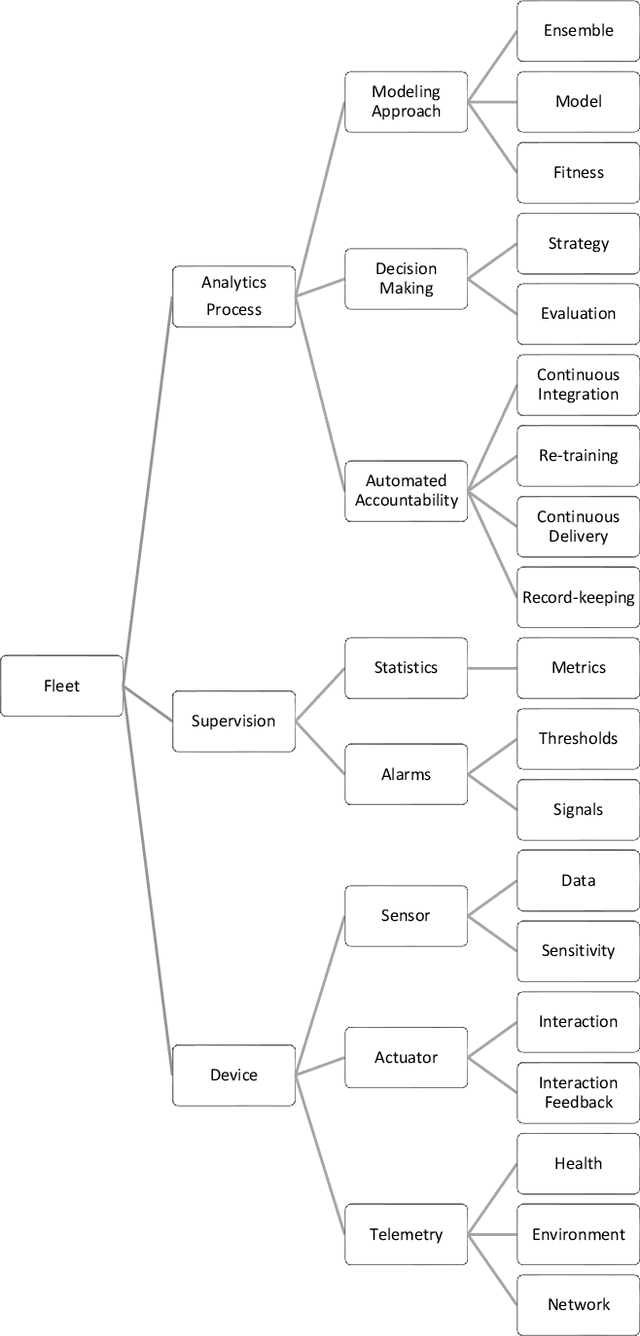
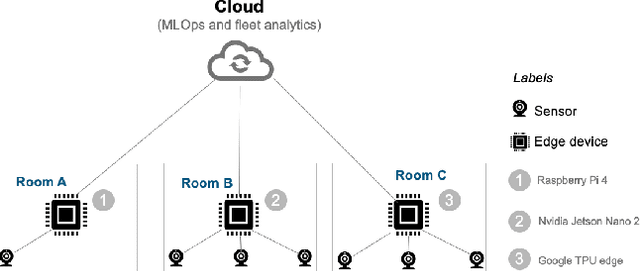
In recent years we have witnessed a boom in Internet of Things (IoT) device deployments, which has resulted in big data and demand for low-latency communication. This shift in the demand for infrastructure is also enabling real-time decision making using artificial intelligence for IoT applications. Artificial Intelligence of Things (AIoT) is the combination of Artificial Intelligence (AI) technologies and the IoT infrastructure to provide robust and efficient operations and decision making. Edge computing is emerging to enable AIoT applications. Edge computing enables generating insights and making decisions at or near the data source, reducing the amount of data sent to the cloud or a central repository. In this paper, we propose a framework for facilitating machine learning at the edge for AIoT applications, to enable continuous delivery, deployment, and monitoring of machine learning models at the edge (Edge MLOps). The contribution is an architecture that includes services, tools, and methods for delivering fleet analytics at scale. We present a preliminary validation of the framework by performing experiments with IoT devices on a university campus's rooms. For the machine learning experiments, we forecast multivariate time series for predicting air quality in the respective rooms by using the models deployed in respective edge devices. By these experiments, we validate the proposed fleet analytics framework for efficiency and robustness.
On the Consistency of Maximum Likelihood Estimators for Causal Network Identification
Oct 17, 2020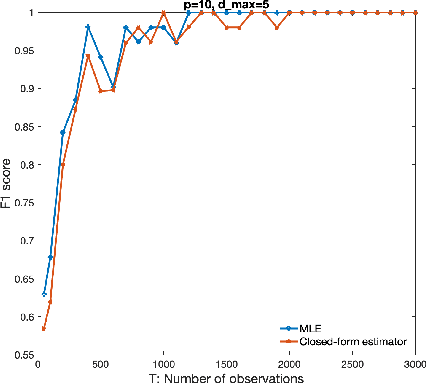
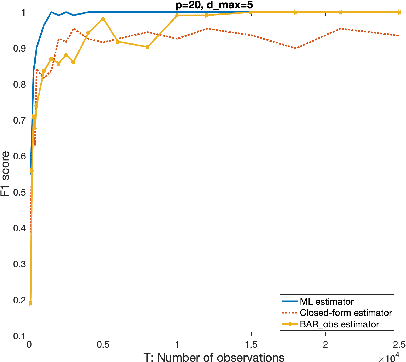
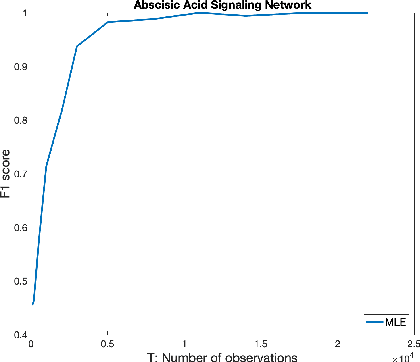
We consider the problem of identifying parameters of a particular class of Markov chains, called Bernoulli Autoregressive (BAR) processes. The structure of any BAR model is encoded by a directed graph. Incoming edges to a node in the graph indicate that the state of the node at a particular time instant is influenced by the states of the corresponding parental nodes in the previous time instant. The associated edge weights determine the corresponding level of influence from each parental node. In the simplest setup, the Bernoulli parameter of a particular node's state variable is a convex combination of the parental node states in the previous time instant and an additional Bernoulli noise random variable. This paper focuses on the problem of edge weight identification using Maximum Likelihood (ML) estimation and proves that the ML estimator is strongly consistent for two variants of the BAR model. We additionally derive closed-form estimators for the aforementioned two variants and prove their strong consistency.
A Spatio-Temporal Representation for the Orienteering Problem with Time-Varying Profits
Jul 02, 2017

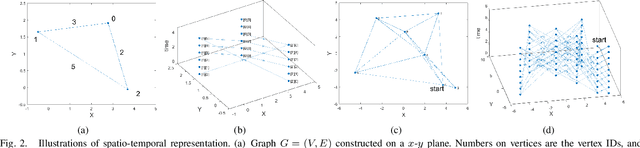
We consider an orienteering problem (OP) where an agent needs to visit a series (possibly a subset) of depots, from which the maximal accumulated profits are desired within given limited time budget. Different from most existing works where the profits are assumed to be static, in this work we investigate a variant that has arbitrary time-dependent profits. Specifically, the profits to be collected change over time and they follow different (e.g., independent) time-varying functions. The problem is of inherent nonlinearity and difficult to solve by existing methods. To tackle the challenge, we present a simple and effective framework that incorporates time-variations into the fundamental planning process. Specifically, we propose a deterministic spatio-temporal representation where both spatial description and temporal logic are unified into one routing topology. By employing existing basic sorting and searching algorithms, the routing solutions can be computed in an extremely efficient way. The proposed method is easy to implement and extensive numerical results show that our approach is time efficient and generates near-optimal solutions.
Few-Shot Learning of an Interleaved Text Summarization Model by Pretraining with Synthetic Data
Mar 08, 2021
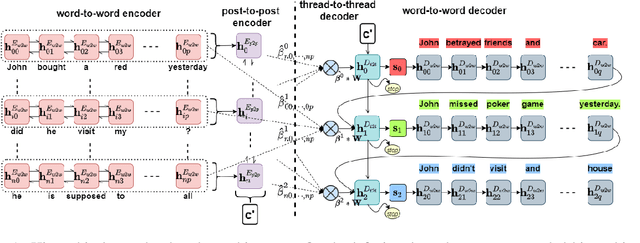

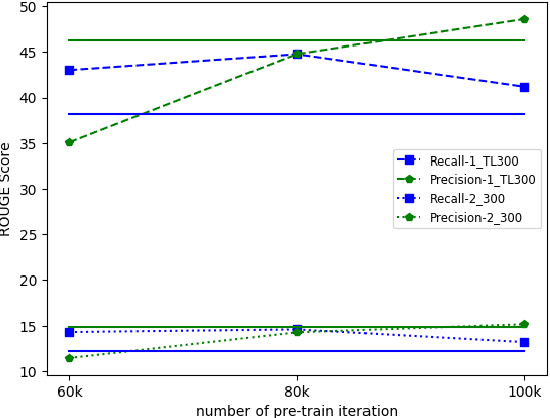
Interleaved texts, where posts belonging to different threads occur in a sequence, commonly occur in online chat posts, so that it can be time-consuming to quickly obtain an overview of the discussions. Existing systems first disentangle the posts by threads and then extract summaries from those threads. A major issue with such systems is error propagation from the disentanglement component. While end-to-end trainable summarization system could obviate explicit disentanglement, such systems require a large amount of labeled data. To address this, we propose to pretrain an end-to-end trainable hierarchical encoder-decoder system using synthetic interleaved texts. We show that by fine-tuning on a real-world meeting dataset (AMI), such a system out-performs a traditional two-step system by 22%. We also compare against transformer models and observed that pretraining with synthetic data both the encoder and decoder outperforms the BertSumExtAbs transformer model which pretrains only the encoder on a large dataset.
Detecting and Explaining Causes From Text For a Time Series Event
Jul 27, 2017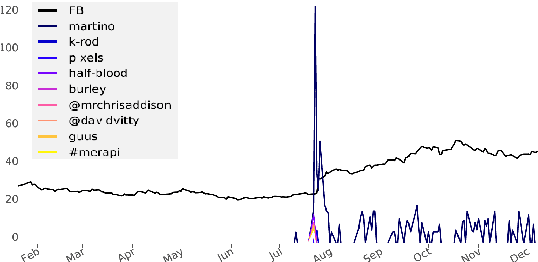
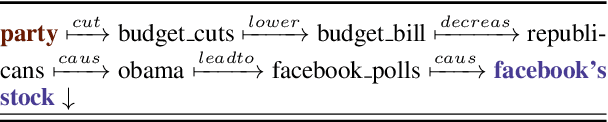
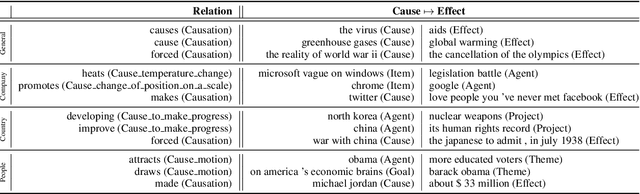
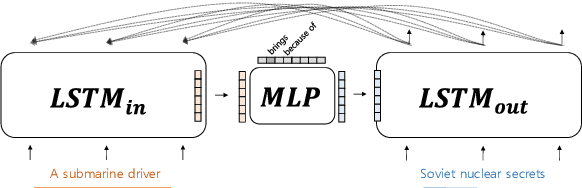
Explaining underlying causes or effects about events is a challenging but valuable task. We define a novel problem of generating explanations of a time series event by (1) searching cause and effect relationships of the time series with textual data and (2) constructing a connecting chain between them to generate an explanation. To detect causal features from text, we propose a novel method based on the Granger causality of time series between features extracted from text such as N-grams, topics, sentiments, and their composition. The generation of the sequence of causal entities requires a commonsense causative knowledge base with efficient reasoning. To ensure good interpretability and appropriate lexical usage we combine symbolic and neural representations, using a neural reasoning algorithm trained on commonsense causal tuples to predict the next cause step. Our quantitative and human analysis show empirical evidence that our method successfully extracts meaningful causality relationships between time series with textual features and generates appropriate explanation between them.