 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
SEP-28k: A Dataset for Stuttering Event Detection From Podcasts With People Who Stutter
Feb 24, 2021

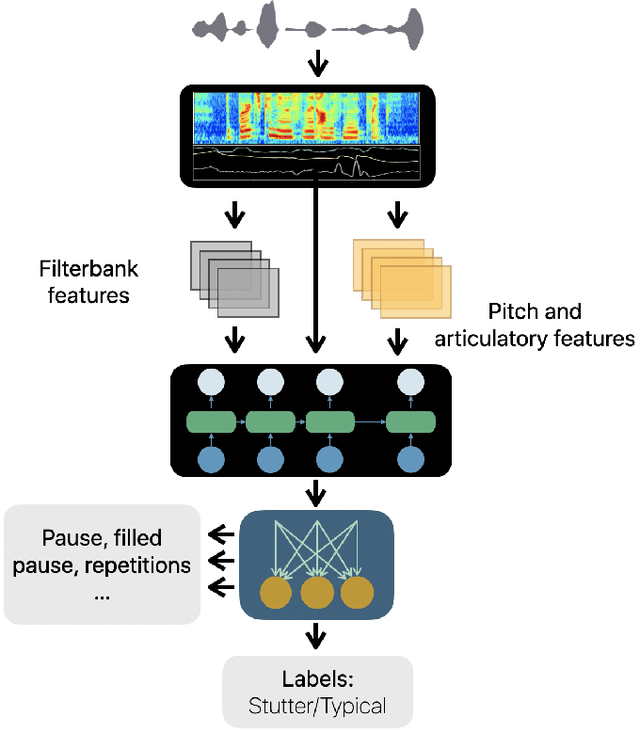
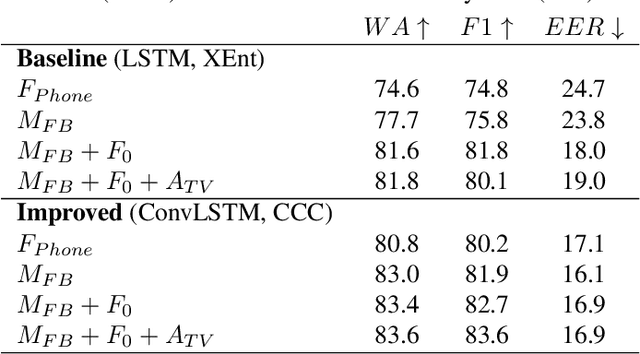
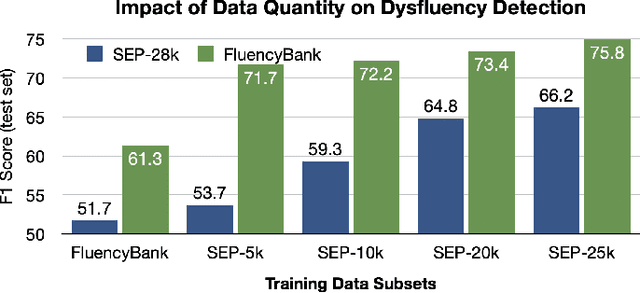
The ability to automatically detect stuttering events in speech could help speech pathologists track an individual's fluency over time or help improve speech recognition systems for people with atypical speech patterns. Despite increasing interest in this area, existing public datasets are too small to build generalizable dysfluency detection systems and lack sufficient annotations. In this work, we introduce Stuttering Events in Podcasts (SEP-28k), a dataset containing over 28k clips labeled with five event types including blocks, prolongations, sound repetitions, word repetitions, and interjections. Audio comes from public podcasts largely consisting of people who stutter interviewing other people who stutter. We benchmark a set of acoustic models on SEP-28k and the public FluencyBank dataset and highlight how simply increasing the amount of training data improves relative detection performance by 28\% and 24\% F1 on each. Annotations from over 32k clips across both datasets will be publicly released.
Multi-Frame to Single-Frame: Knowledge Distillation for 3D Object Detection
Sep 24, 2020
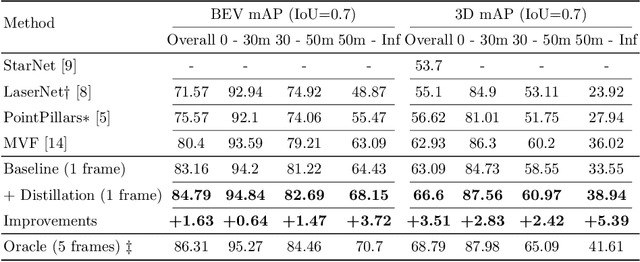

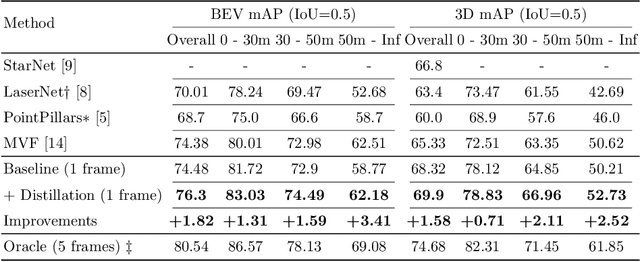
A common dilemma in 3D object detection for autonomous driving is that high-quality, dense point clouds are only available during training, but not testing. We use knowledge distillation to bridge the gap between a model trained on high-quality inputs at training time and another tested on low-quality inputs at inference time. In particular, we design a two-stage training pipeline for point cloud object detection. First, we train an object detection model on dense point clouds, which are generated from multiple frames using extra information only available at training time. Then, we train the model's identical counterpart on sparse single-frame point clouds with consistency regularization on features from both models. We show that this procedure improves performance on low-quality data during testing, without additional overhead.
Position-based Content Attention for Time Series Forecasting with Sequence-to-sequence RNNs
Aug 21, 2017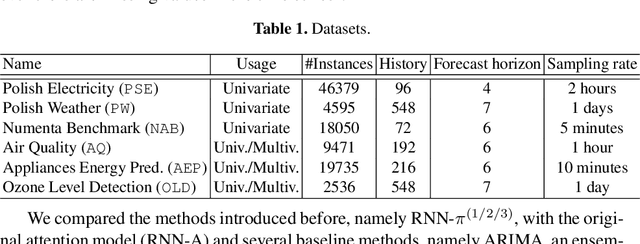
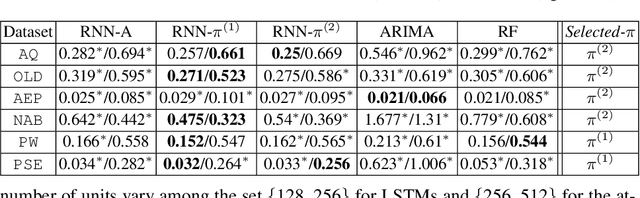
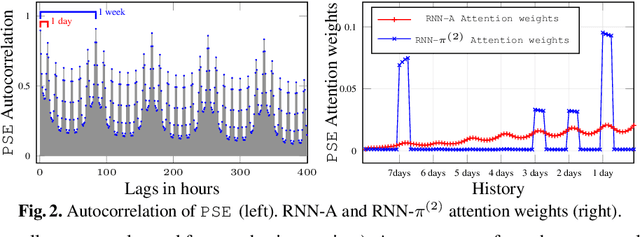
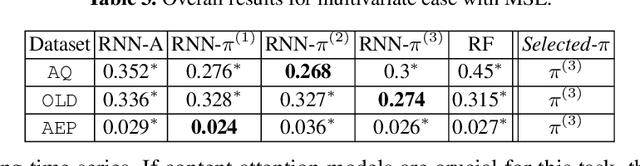
We propose here an extended attention model for sequence-to-sequence recurrent neural networks (RNNs) designed to capture (pseudo-)periods in time series. This extended attention model can be deployed on top of any RNN and is shown to yield state-of-the-art performance for time series forecasting on several univariate and multivariate time series.
When Noise meets Chaos: Stochastic Resonance in Neurochaos Learning
Feb 02, 2021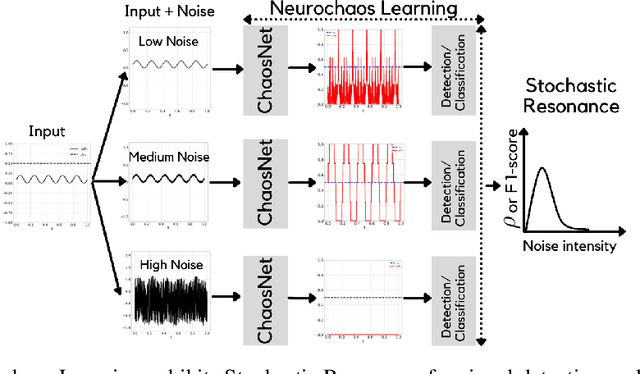
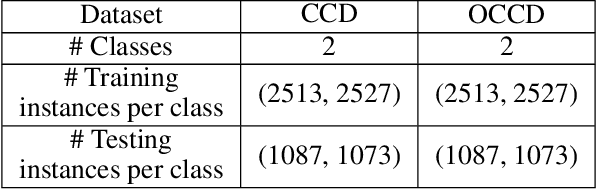
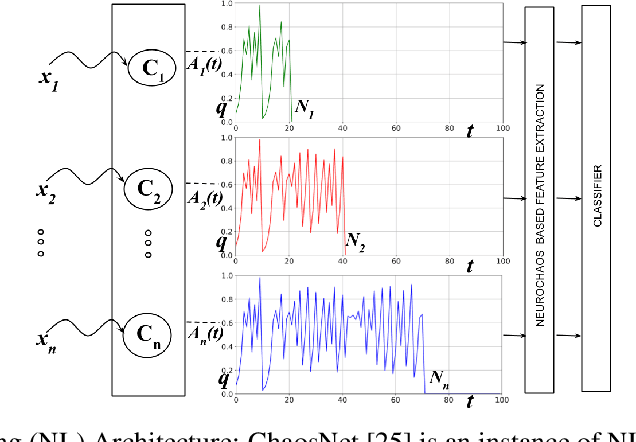
Chaos and Noise are ubiquitous in the Brain. Inspired by the chaotic firing of neurons and the constructive role of noise in neuronal models, we for the first time connect chaos, noise and learning. In this paper, we demonstrate Stochastic Resonance (SR) phenomenon in Neurochaos Learning (NL). SR manifests at the level of a single neuron of NL and enables efficient subthreshold signal detection. Furthermore, SR is shown to occur in single and multiple neuronal NL architecture for classification tasks - both on simulated and real-world spoken digit datasets. Intermediate levels of noise in neurochaos learning enables peak performance in classification tasks thus highlighting the role of SR in AI applications, especially in brain inspired learning architectures.
An End-To-End-Trainable Iterative Network Architecture for Accelerated Radial Multi-Coil 2D Cine MR Image Reconstruction
Feb 01, 2021
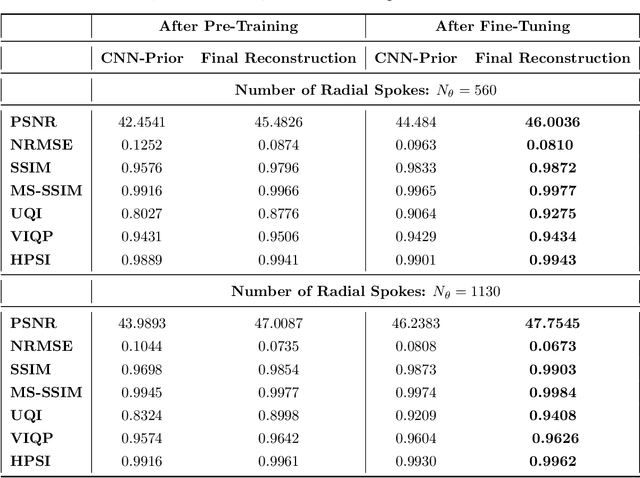
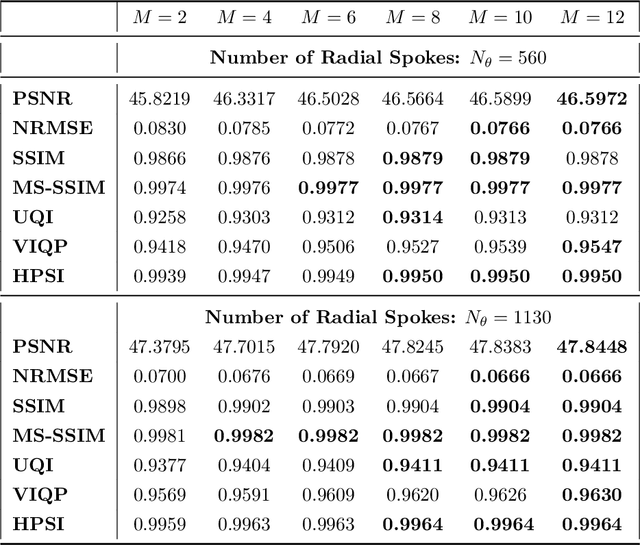
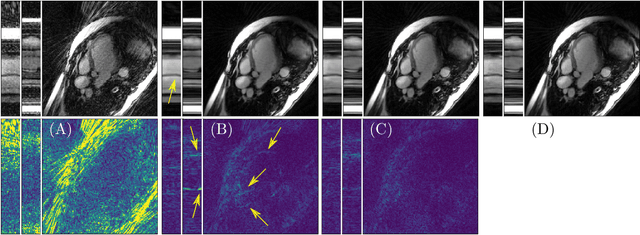
Purpose: Iterative Convolutional Neural Networks (CNNs) which resemble unrolled learned iterative schemes have shown to consistently deliver state-of-the-art results for image reconstruction problems across different imaging modalities. However, because these methodes include the forward model in the architecture, their applicability is often restricted to either relatively small reconstruction problems or to problems with operators which are computationally cheap to compute. As a consequence, they have so far not been applied to dynamic non-Cartesian multi-coil reconstruction problems. Methods: In this work, we propose a CNN-architecture for image reconstruction of accelerated 2D radial cine MRI with multiple receiver coils. The network is based on a computationally light CNN-component and a subsequent conjugate gradient (CG) method which can be jointly trained end-to-end using an efficient training strategy. We investigate the proposed training-strategy and compare our method to other well-known reconstruction techniques with learned and non-learned regularization methods. Results: Our proposed method outperforms all other methods based on non-learned regularization. Further, it performs similar or better than a CNN-based method employing a 3D U-Net and a method using adaptive dictionary learning. In addition, we empirically demonstrate that even by training the network with only iteration, it is possible to increase the length of the network at test time and further improve the results. Conclusions: End-to-end training allows to highly reduce the number of trainable parameters of and stabilize the reconstruction network. Further, because it is possible to change the length of the network at test time, the need to find a compromise between the complexity of the CNN-block and the number of iterations in each CG-block becomes irrelevant.
TrackMPNN: A Message Passing Graph Neural Architecture for Multi-Object Tracking
Jan 26, 2021
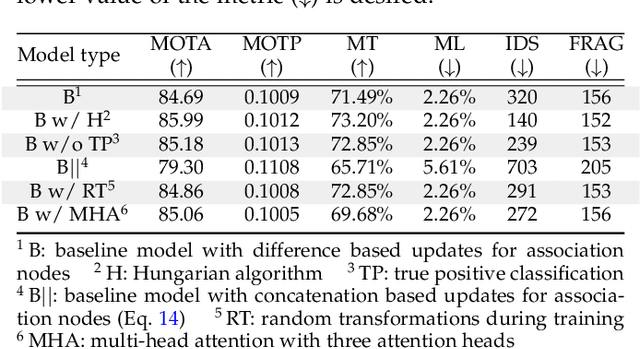
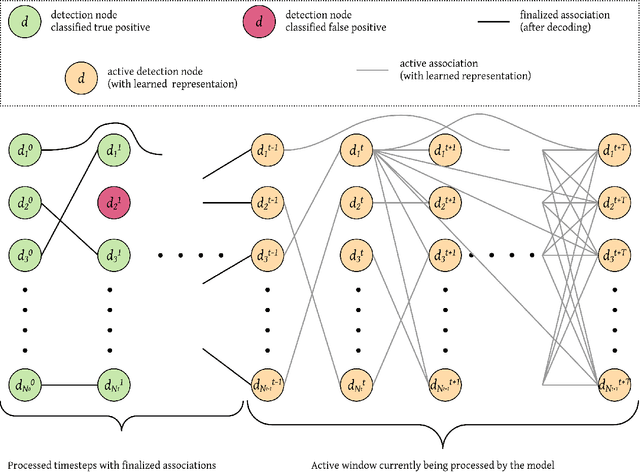
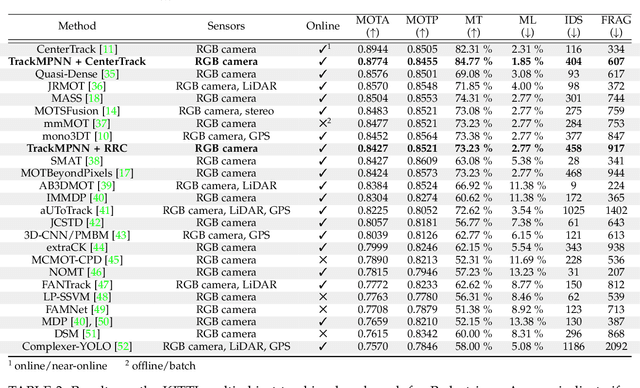
This study follows many previous approaches to multi-object tracking (MOT) that model the problem using graph-based data structures, and adapts this formulation to make it amenable to modern neural networks. Our main contributions in this work are the creation of a framework based on dynamic undirected graphs that represent the data association problem over multiple timesteps, and a message passing graph neural network (GNN) that operates on these graphs to produce the desired likelihood for every association therein. We further provide solutions and propositions for the computational problems that need to be addressed to create a memory-efficient, real-time, online algorithm that can reason over multiple timesteps, correct previous mistakes, update beliefs, possess long-term memory, and handle missed/false detections. In addition to this, our framework provides flexibility in the choice of temporal window sizes to operate on and the losses used for training. In essence, this study provides a framework for any kind of graph based neural network to be trained using conventional techniques from supervised learning, and then use these trained models to infer on new sequences in an online, real-time, computationally tractable manner. To demonstrate the efficacy and robustness of our approach, we only use the 2D box location and object category to construct the descriptor for each object instance. Despite this, our model performs on par with state-of-the-art approaches that make use of multiple hand-crafted and/or learned features. Experiments, qualitative examples and competitive results on popular MOT benchmarks for autonomous driving demonstrate the promise and uniqueness of the proposed approach.
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements
Apr 15, 2021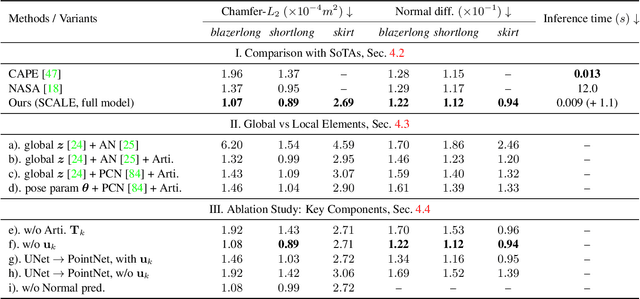
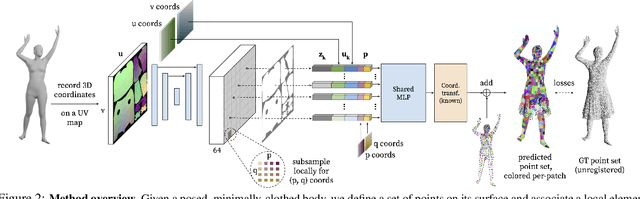
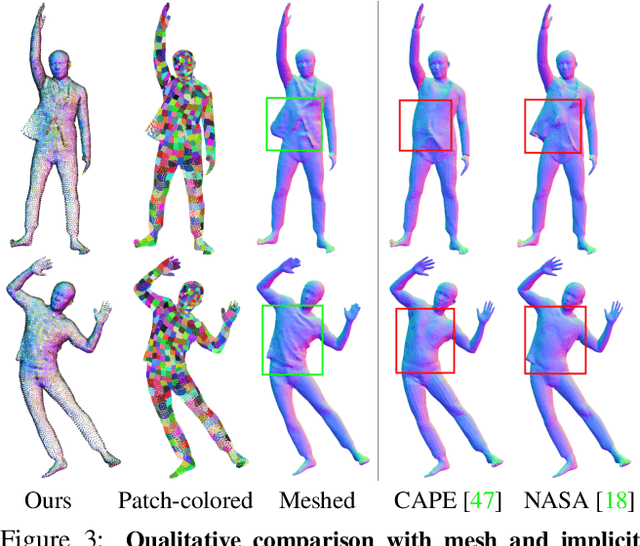

Learning to model and reconstruct humans in clothing is challenging due to articulation, non-rigid deformation, and varying clothing types and topologies. To enable learning, the choice of representation is the key. Recent work uses neural networks to parameterize local surface elements. This approach captures locally coherent geometry and non-planar details, can deal with varying topology, and does not require registered training data. However, naively using such methods to model 3D clothed humans fails to capture fine-grained local deformations and generalizes poorly. To address this, we present three key innovations: First, we deform surface elements based on a human body model such that large-scale deformations caused by articulation are explicitly separated from topological changes and local clothing deformations. Second, we address the limitations of existing neural surface elements by regressing local geometry from local features, significantly improving the expressiveness. Third, we learn a pose embedding on a 2D parameterization space that encodes posed body geometry, improving generalization to unseen poses by reducing non-local spurious correlations. We demonstrate the efficacy of our surface representation by learning models of complex clothing from point clouds. The clothing can change topology and deviate from the topology of the body. Once learned, we can animate previously unseen motions, producing high-quality point clouds, from which we generate realistic images with neural rendering. We assess the importance of each technical contribution and show that our approach outperforms the state-of-the-art methods in terms of reconstruction accuracy and inference time. The code is available for research purposes at https://qianlim.github.io/SCALE .
Lightweight Real-time Makeup Try-on in Mobile Browsers with Tiny CNN Models for Facial Tracking
Jun 11, 2019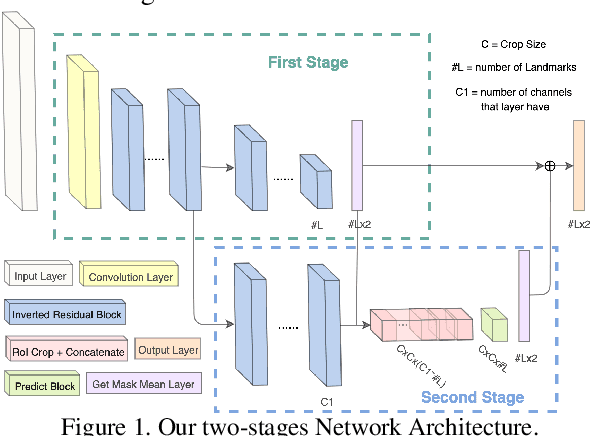

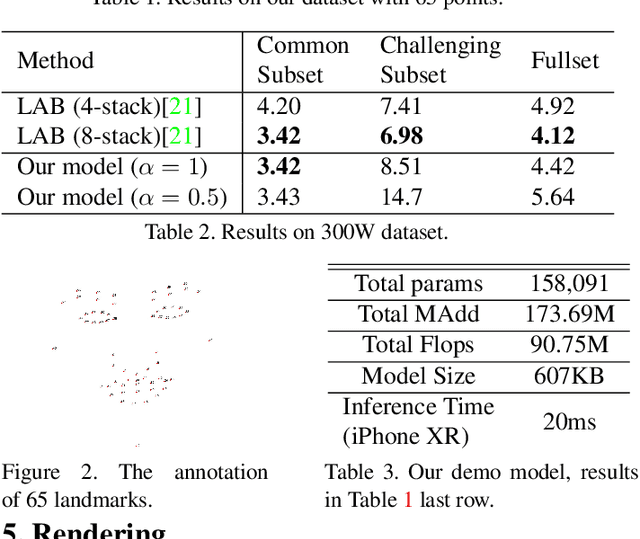
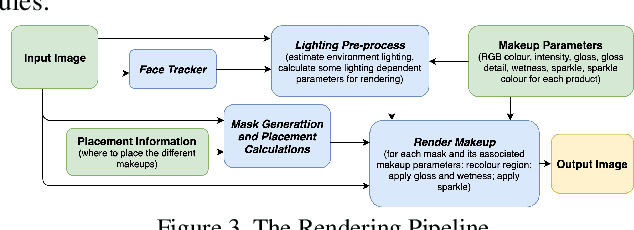
Recent works on convolutional neural networks (CNNs) for facial alignment have demonstrated unprecedented accuracy on a variety of large, publicly available datasets. However, the developed models are often both cumbersome and computationally expensive, and are not adapted to applications on resource restricted devices. In this work, we look into developing and training compact facial alignment models that feature fast inference speed and small deployment size, making them suitable for applications on the aforementioned category of devices. Our main contribution lies in designing such small models while maintaining high accuracy of facial alignment. The models we propose make use of light CNN architectures adapted to the facial alignment problem for accurate two-stage prediction of facial landmark coordinates from low-resolution output heatmaps. We further combine the developed facial tracker with a rendering method, and build a real-time makeup try-on demo that runs client-side in smartphone Web browsers. More results and demo are in our project page: http://research.modiface.com/makeup-try-on-cvprw2019/
EventProp: Backpropagation for Exact Gradients in Spiking Neural Networks
Sep 21, 2020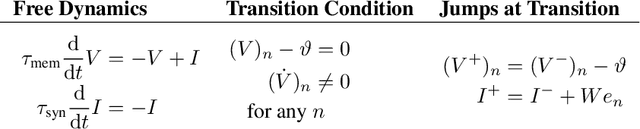
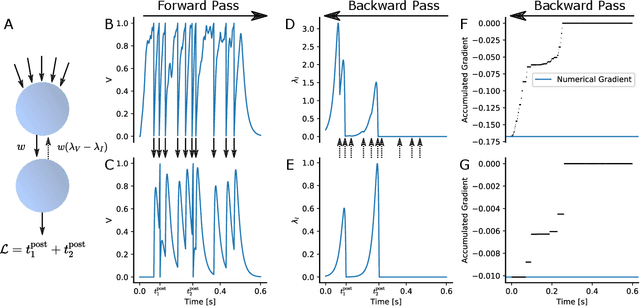
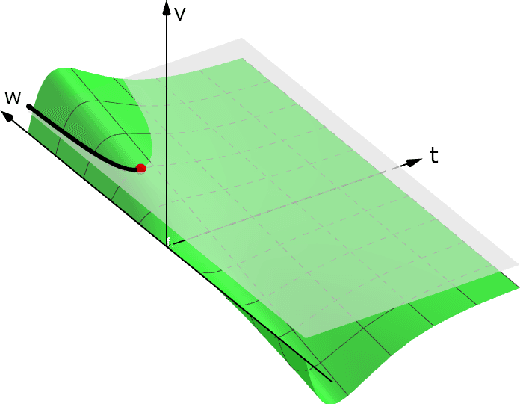
We derive the backpropagation algorithm for spiking neural networks composed of leaky integrate-and-fire neurons operating in continuous time. This algorithm, EventProp, computes the exact gradient of an arbitrary loss function of spike times and membrane potentials by backpropagating errors in time. For the first time, by leveraging methods from optimal control theory, we are able to backpropagate errors through spike discontinuities without approximations or smoothing operations. As errors are backpropagated in an event-based manner (at spike times), EventProp requires storing state variables only at these times, providing favorable memory requirements. EventProp can be applied to spiking networks with arbitrary connectivity, including recurrent, convolutional and deep feed-forward architectures. While we consider the leaky integrate-and-fire neuron model in this work, our methodology to derive the gradient can be applied to other spiking neuron models. We demonstrate learning using gradients computed via EventProp in a deep spiking network using an event-based simulator and a non-linearly separable dataset encoded using spike time latencies. Our work supports the rigorous study of gradient-based methods to train spiking neural networks while providing insights toward the development of learning algorithms in neuromorphic hardware.
Spatial-Temporal Tensor Graph Convolutional Network for Traffic Prediction
Mar 10, 2021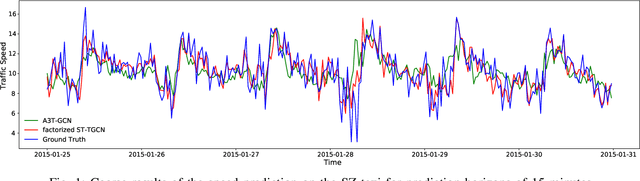
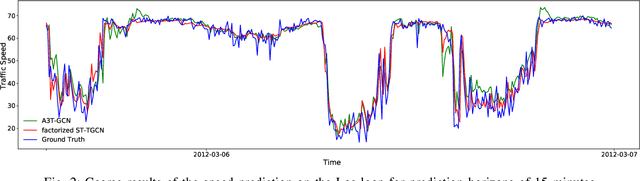
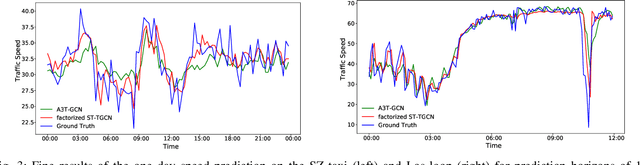
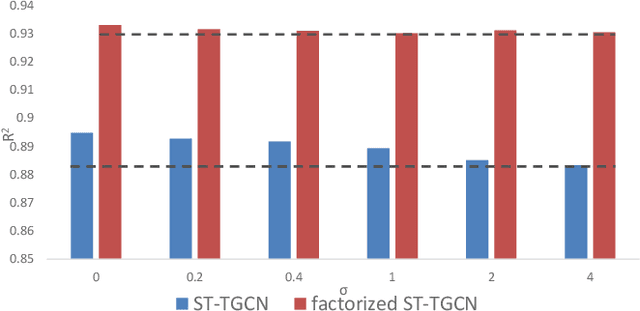
Accurate traffic prediction is crucial to the guidance and management of urban traffics. However, most of the existing traffic prediction models do not consider the computational burden and memory space when they capture spatial-temporal dependence among traffic data. In this work, we propose a factorized Spatial-Temporal Tensor Graph Convolutional Network to deal with traffic speed prediction. Traffic networks are modeled and unified into a graph that integrates spatial and temporal information simultaneously. We further extend graph convolution into tensor space and propose a tensor graph convolution network to extract more discriminating features from spatial-temporal graph data. To reduce the computational burden, we take Tucker tensor decomposition and derive factorized a tensor convolution, which performs separate filtering in small-scale space, time, and feature modes. Besides, we can benefit from noise suppression of traffic data when discarding those trivial components in the process of tensor decomposition. Extensive experiments on two real-world traffic speed datasets demonstrate our method is more effective than those traditional traffic prediction methods, and meantime achieves state-of-the-art performance.