 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Divide-and-conquer methods for big data analysis
Feb 22, 2021
In the context of big data analysis, the divide-and-conquer methodology refers to a multiple-step process: first splitting a data set into several smaller ones; then analyzing each set separately; finally combining results from each analysis together. This approach is effective in handling large data sets that are unsuitable to be analyzed entirely by a single computer due to limits either from memory storage or computational time. The combined results will provide a statistical inference which is similar to the one from analyzing the entire data set. This article reviews some recently developments of divide-and-conquer methods in a variety of settings, including combining based on parametric, semiparametric and nonparametric models, online sequential updating methods, among others. Theoretical development on the efficiency of the divide-and-conquer methods is also discussed.
PSpan:Mining Frequent Subnets of Petri Nets
Jan 28, 2021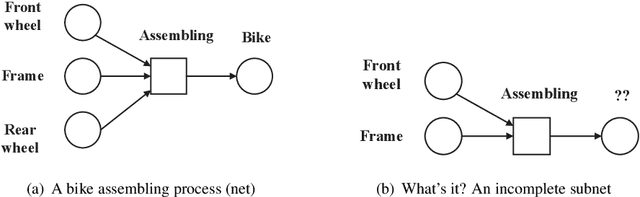

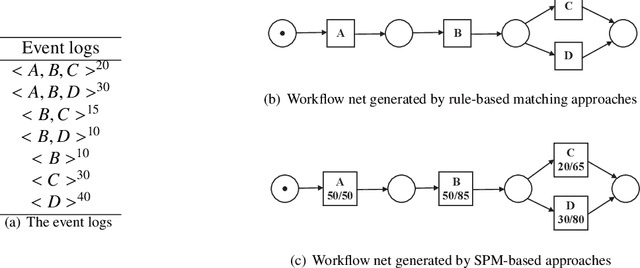
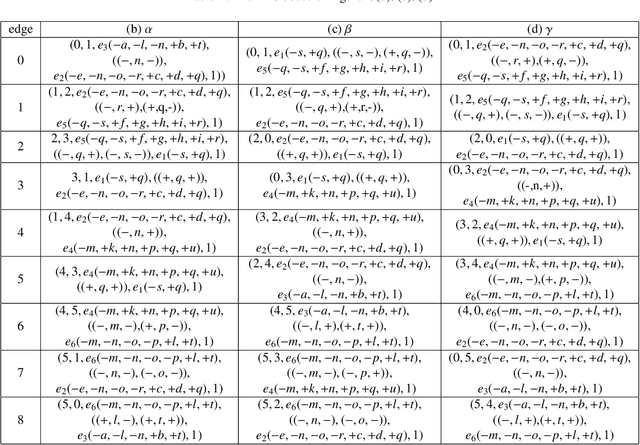
This paper proposes for the first time an algorithm PSpan for mining frequent complete subnets from a set of Petri nets. We introduced the concept of complete subnets and the net graph representation. PSpan transforms Petri nets in net graphs and performs sub-net graph mining on them, then transforms the results back to frequent subnets. PSpan follows the pattern growth approach and has similar complexity like gSpan in graph mining. Experiments have been done to confirm PSpan's reliability and complexity. Besides C/E nets, it applies also to a set of other Petri net subclasses.
Variational models for signal processing with Graph Neural Networks
Apr 03, 2021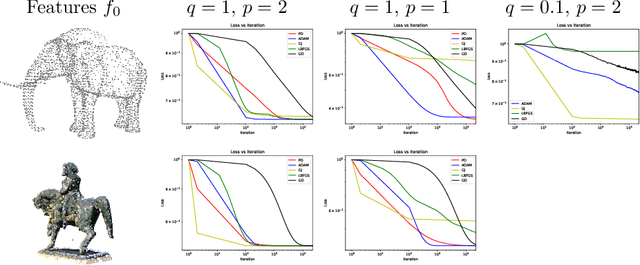
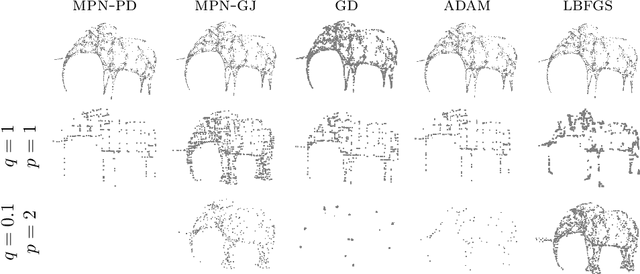

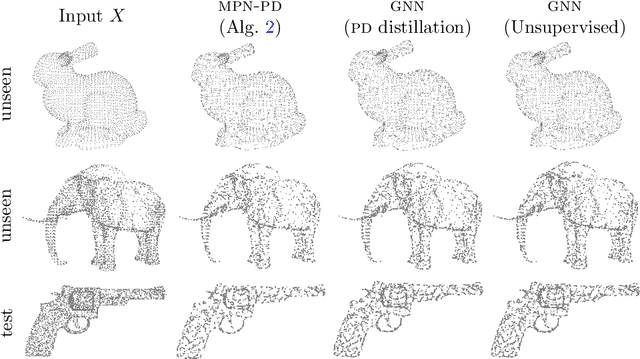
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning. Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning
Merchant Category Identification Using Credit Card Transactions
Nov 05, 2020
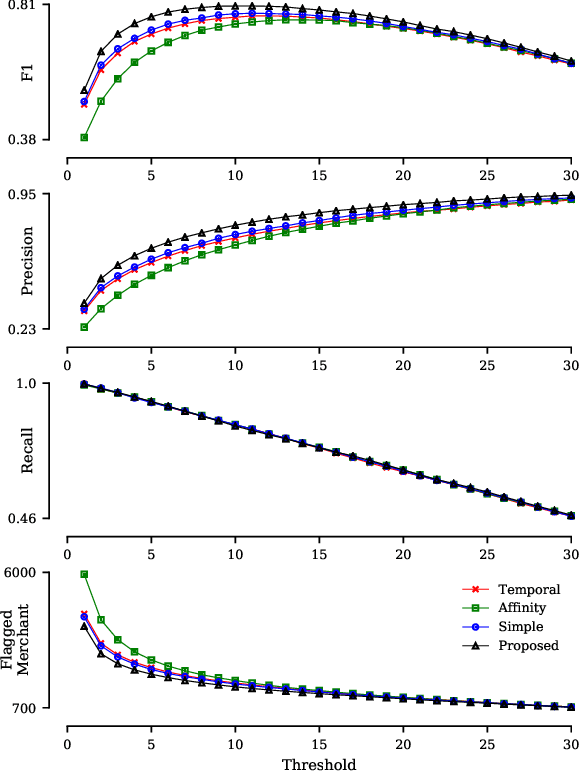
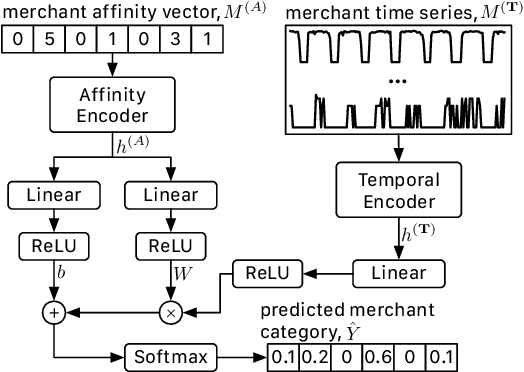
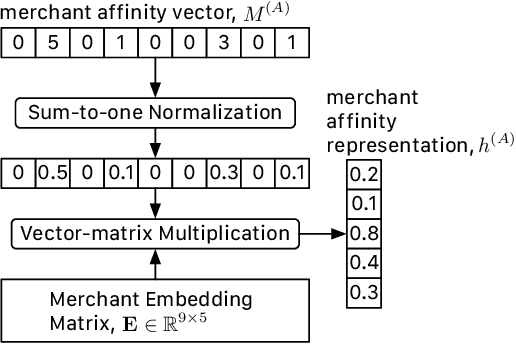
Digital payment volume has proliferated in recent years with the rapid growth of small businesses and online shops. When processing these digital transactions, recognizing each merchant's real identity (i.e., business type) is vital to ensure the integrity of payment processing systems. Conventionally, this problem is formulated as a time series classification problem solely using the merchant transaction history. However, with the large scale of the data, and changing behaviors of merchants and consumers over time, it is extremely challenging to achieve satisfying performance from off-the-shelf classification methods. In this work, we approach this problem from a multi-modal learning perspective, where we use not only the merchant time series data but also the information of merchant-merchant relationship (i.e., affinity) to verify the self-reported business type (i.e., merchant category) of a given merchant. Specifically, we design two individual encoders, where one is responsible for encoding temporal information and the other is responsible for affinity information, and a mechanism to fuse the outputs of the two encoders to accomplish the identification task. Our experiments on real-world credit card transaction data between 71,668 merchants and 433,772,755 customers have demonstrated the effectiveness and efficiency of the proposed model.
Gradient Descent Can Take Exponential Time to Escape Saddle Points
Nov 05, 2017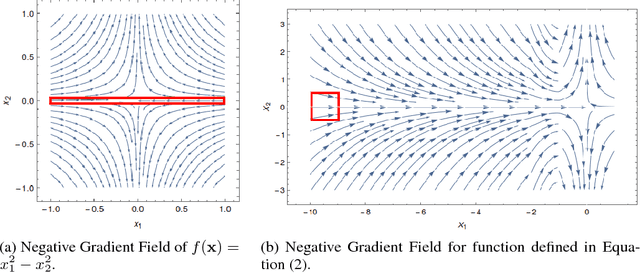
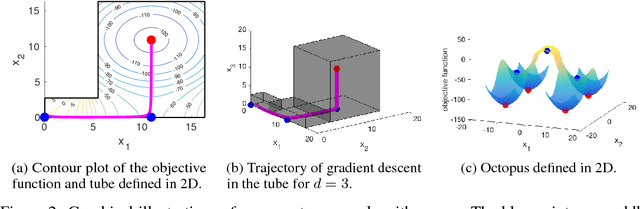
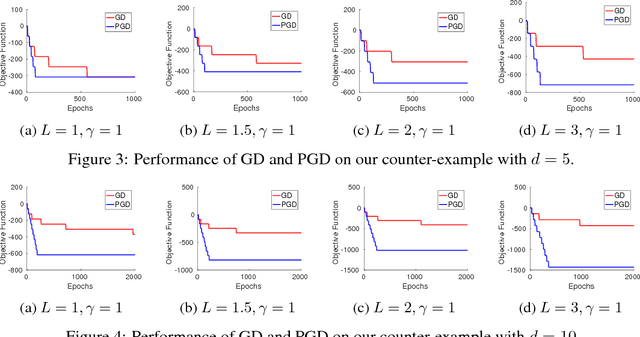
Although gradient descent (GD) almost always escapes saddle points asymptotically [Lee et al., 2016], this paper shows that even with fairly natural random initialization schemes and non-pathological functions, GD can be significantly slowed down by saddle points, taking exponential time to escape. On the other hand, gradient descent with perturbations [Ge et al., 2015, Jin et al., 2017] is not slowed down by saddle points - it can find an approximate local minimizer in polynomial time. This result implies that GD is inherently slower than perturbed GD, and justifies the importance of adding perturbations for efficient non-convex optimization. While our focus is theoretical, we also present experiments that illustrate our theoretical findings.
Transferring Domain Knowledge with an Adviser in Continuous Tasks
Feb 16, 2021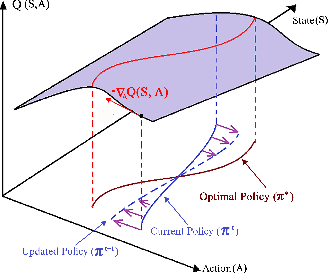
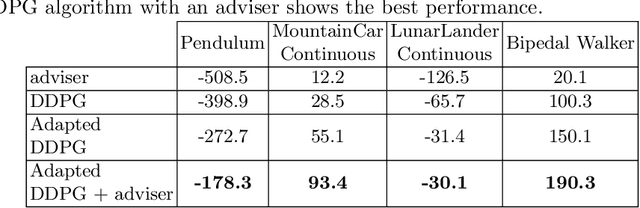
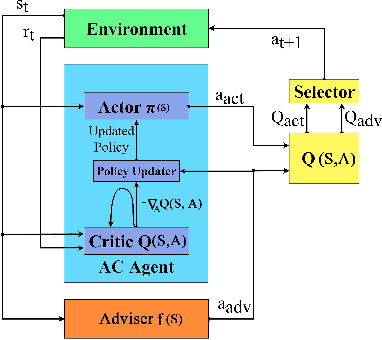
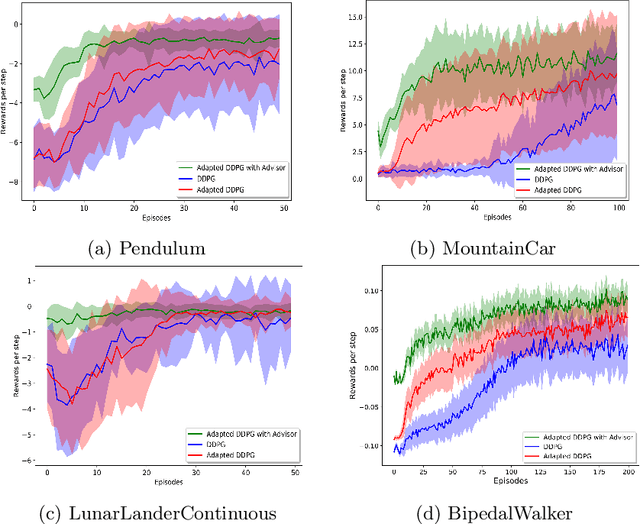
Recent advances in Reinforcement Learning (RL) have surpassed human-level performance in many simulated environments. However, existing reinforcement learning techniques are incapable of explicitly incorporating already known domain-specific knowledge into the learning process. Therefore, the agents have to explore and learn the domain knowledge independently through a trial and error approach, which consumes both time and resources to make valid responses. Hence, we adapt the Deep Deterministic Policy Gradient (DDPG) algorithm to incorporate an adviser, which allows integrating domain knowledge in the form of pre-learned policies or pre-defined relationships to enhance the agent's learning process. Our experiments on OpenAi Gym benchmark tasks show that integrating domain knowledge through advisers expedites the learning and improves the policy towards better optima.
Vessel-CAPTCHA: an efficient learning framework for vessel annotation and segmentation
Jan 27, 2021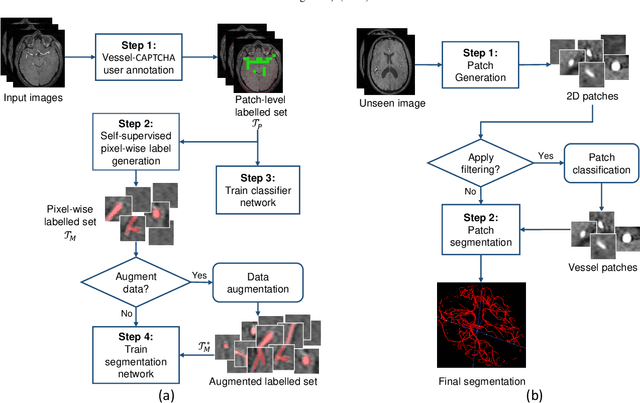
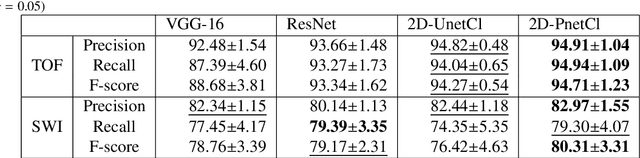
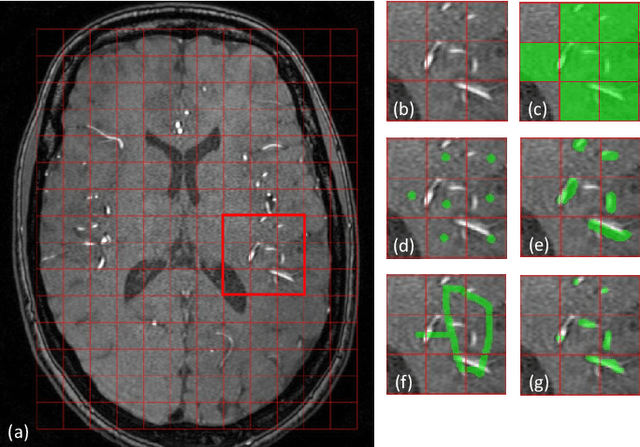

The use of deep learning techniques for 3D brain vessel image segmentation has not been as widespread as for the segmentation of other organs and tissues. This can be explained by two factors. First, deep learning techniques tend to show poor performances at the segmentation of relatively small objects compared to the size of the full image. Second, due to the complexity of vascular trees and the small size of vessels, it is challenging to obtain the amount of annotated training data typically needed by deep learning methods. To address these problems, we propose a novel annotation-efficient deep learning vessel segmentation framework. The framework avoids pixel-wise annotations, only requiring patch-level labels to discriminate between vessel and non-vessel 2D patches in the training set, in a setup similar to the CAPTCHAs used to differentiate humans from bots in web applications. The user-provided annotations are used for two tasks: 1) to automatically generate pixel-wise labels for vessels and background in each patch, which are used to train a segmentation network, and 2) to train a classifier network. The classifier network allows to generate additional weak patch labels, further reducing the annotation burden, and it acts as a noise filter for poor quality images. We use this framework for the segmentation of the cerebrovascular tree in Time-of-Flight angiography (TOF) and Susceptibility-Weighted Images (SWI). The results show that the framework achieves state-of-the-art accuracy, while reducing the annotation time by up to 80% with respect to learning-based segmentation methods using pixel-wise labels for training
Understanding the Robustness of Skeleton-based Action Recognition under Adversarial Attack
Mar 09, 2021
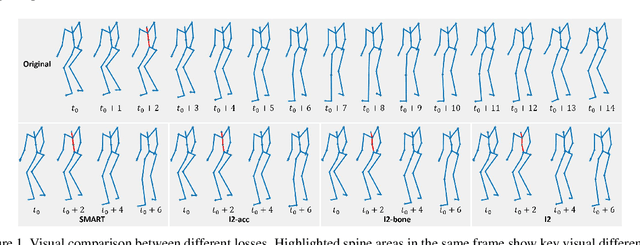
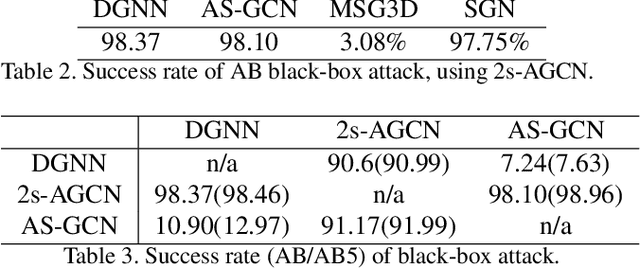

Action recognition has been heavily employed in many applications such as autonomous vehicles, surveillance, etc, where its robustness is a primary concern. In this paper, we examine the robustness of state-of-the-art action recognizers against adversarial attack, which has been rarely investigated so far. To this end, we propose a new method to attack action recognizers that rely on 3D skeletal motion. Our method involves an innovative perceptual loss that ensures the imperceptibility of the attack. Empirical studies demonstrate that our method is effective in both white-box and black-box scenarios. Its generalizability is evidenced on a variety of action recognizers and datasets. Its versatility is shown in different attacking strategies. Its deceitfulness is proven in extensive perceptual studies. Our method shows that adversarial attack on 3D skeletal motions, one type of time-series data, is significantly different from traditional adversarial attack problems. Its success raises serious concern on the robustness of action recognizers and provides insights on potential improvements.
A Mask R-CNN approach to counting bacterial colony forming units in pharmaceutical development
Mar 09, 2021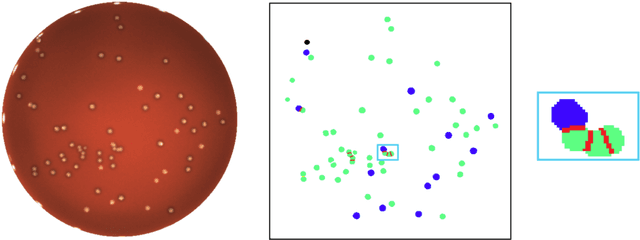
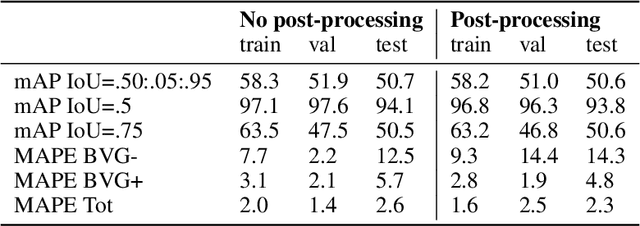
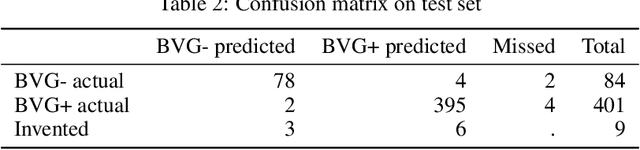
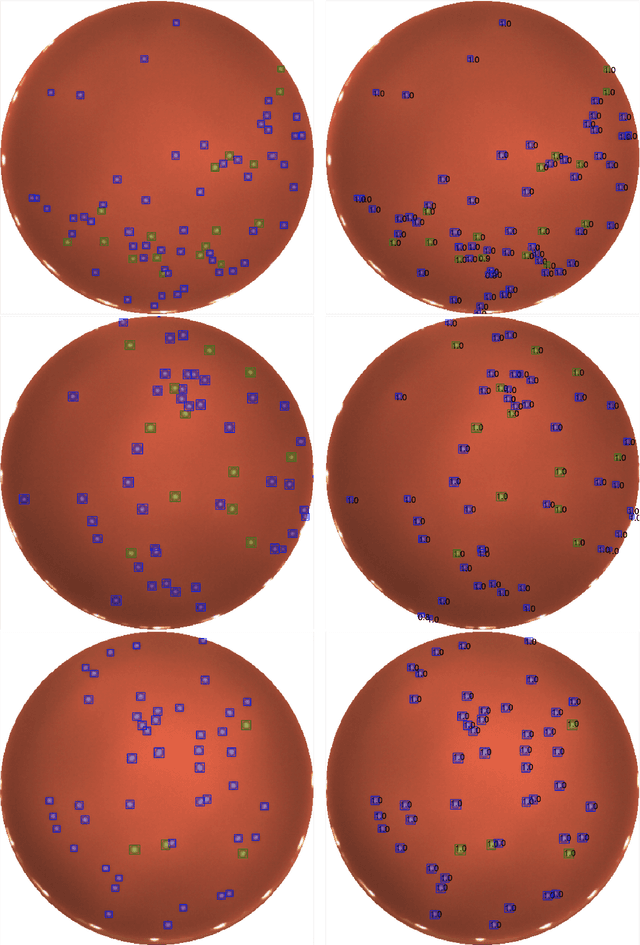
We present an application of the well-known Mask R-CNN approach to the counting of different types of bacterial colony forming units that were cultured in Petri dishes. Our model was made available to lab technicians in a modern SPA (Single-Page Application). Users can upload images of dishes, after which the Mask R-CNN model that was trained and tuned specifically for this task detects the number of BVG- and BVG+ colonies and displays these in an interactive interface for the user to verify. Users can then check the model's predictions, correct them if deemed necessary, and finally validate them. Our adapted Mask R-CNN model achieves a mean average precision (mAP) of 94\% at an intersection-over-union (IoU) threshold of 50\%. With these encouraging results, we see opportunities to bring the benefits of improved accuracy and time saved to related problems, such as generalising to other bacteria types and viral foci counting.
unzipFPGA: Enhancing FPGA-based CNN Engines with On-the-Fly Weights Generation
Apr 03, 2021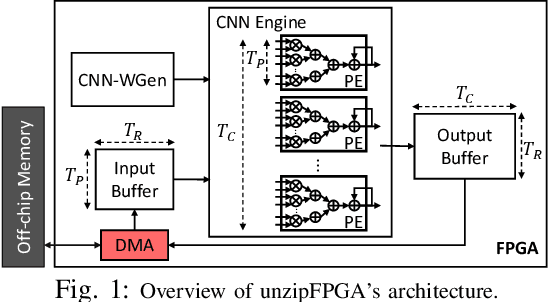
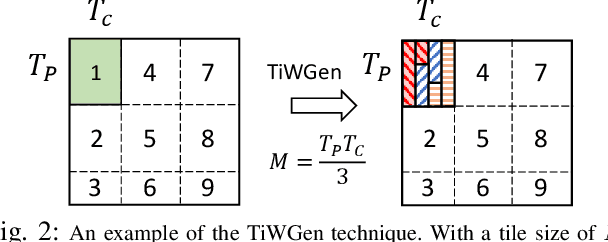
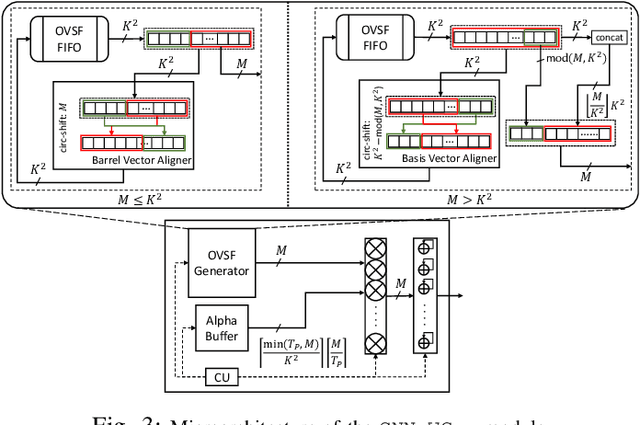
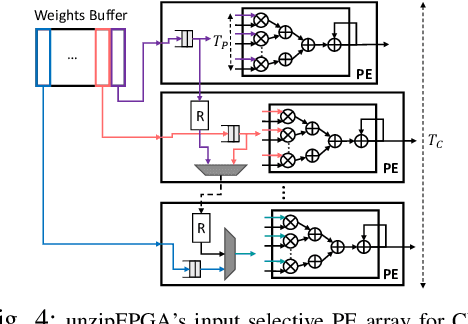
Single computation engines have become a popular design choice for FPGA-based convolutional neural networks (CNNs) enabling the deployment of diverse models without fabric reconfiguration. This flexibility, however, often comes with significantly reduced performance on memory-bound layers and resource underutilisation due to suboptimal mapping of certain layers on the engine's fixed configuration. In this work, we investigate the implications in terms of CNN engine design for a class of models that introduce a pre-convolution stage to decompress the weights at run time. We refer to these approaches as on-the-fly. To minimise the negative impact of limited bandwidth on memory-bound layers, we present a novel hardware component that enables the on-chip on-the-fly generation of weights. We further introduce an input selective processing element (PE) design that balances the load between PEs on suboptimally mapped layers. Finally, we present unzipFPGA, a framework to train on-the-fly models and traverse the design space to select the highest performing CNN engine configuration. Quantitative evaluation shows that unzipFPGA yields an average speedup of 2.14x and 71% over optimised status-quo and pruned CNN engines under constrained bandwidth and up to 3.69x higher performance density over the state-of-the-art FPGA-based CNN accelerators.