 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Smartphone Impostor Detection with Behavioral Data Privacy and Minimalist Hardware Support
Mar 11, 2021
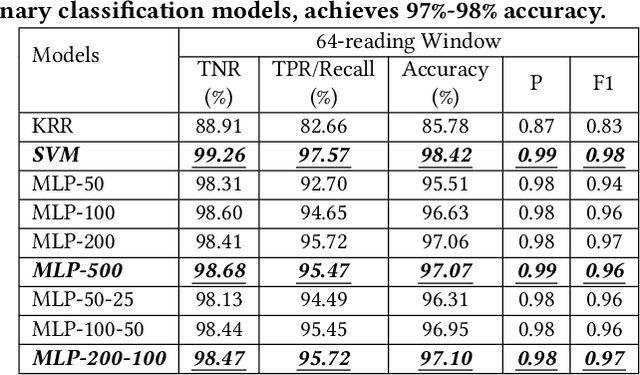
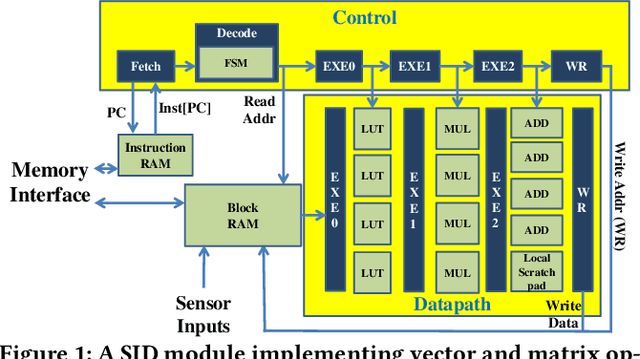
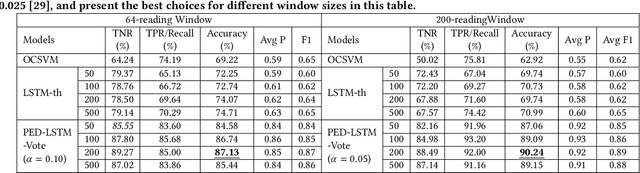
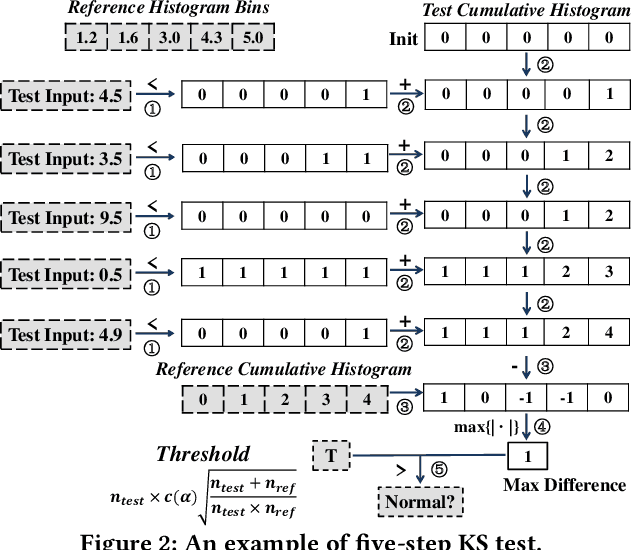
Impostors are attackers who take over a smartphone and gain access to the legitimate user's confidential and private information. This paper proposes a defense-in-depth mechanism to detect impostors quickly with simple Deep Learning algorithms, which can achieve better detection accuracy than the best prior work which used Machine Learning algorithms requiring computation of multiple features. Different from previous work, we then consider protecting the privacy of a user's behavioral (sensor) data by not exposing it outside the smartphone. For this scenario, we propose a Recurrent Neural Network (RNN) based Deep Learning algorithm that uses only the legitimate user's sensor data to learn his/her normal behavior. We propose to use Prediction Error Distribution (PED) to enhance the detection accuracy. We also show how a minimalist hardware module, dubbed SID for Smartphone Impostor Detector, can be designed and integrated into smartphones for self-contained impostor detection. Experimental results show that SID can support real-time impostor detection, at a very low hardware cost and energy consumption, compared to other RNN accelerators.
Camera Calibration with Pose Guidance
Feb 19, 2021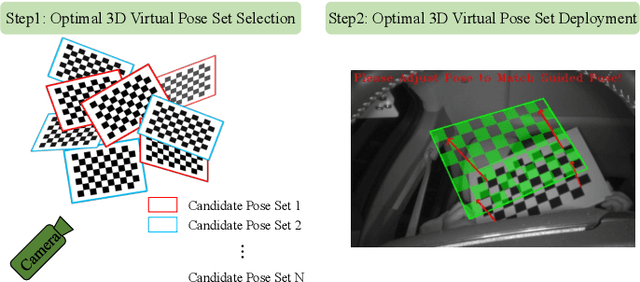
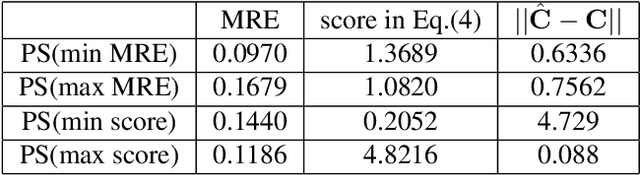
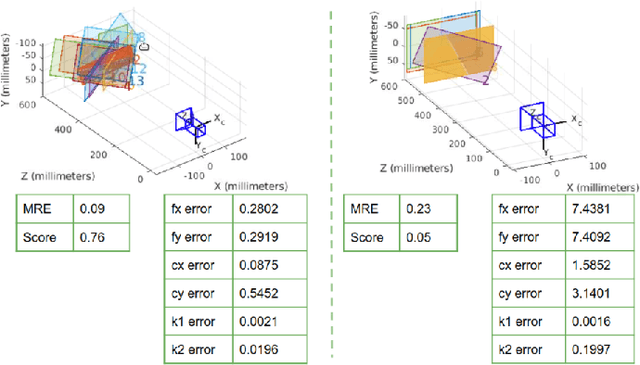
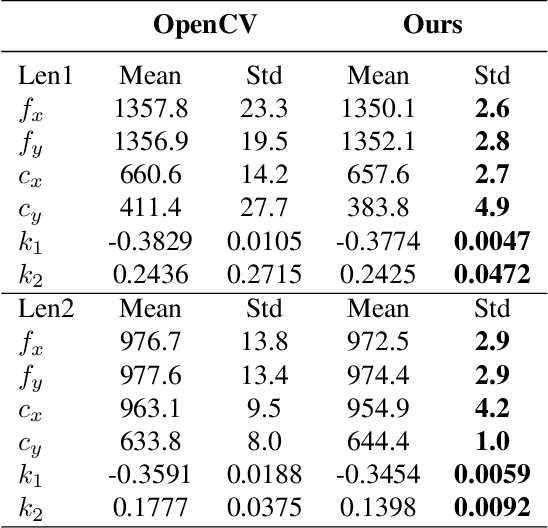
Camera calibration plays a critical role in various computer vision tasks such as autonomous driving or augmented reality. Widely used camera calibration tools utilize plane pattern based methodology, such as using a chessboard or AprilTag board, user's calibration expertise level significantly affects calibration accuracy and consistency when without clear instruction. Furthermore, calibration is a recurring task that has to be performed each time the camera is changed or moved. It's also a great burden to calibrate huge amounts of cameras such as Driver Monitoring System (DMS) cameras in a production line with millions of vehicles. To resolve above issues, we propose a calibration system called Calibration with Pose Guidance to improve calibration accuracy, reduce calibration variance among different users or different trials of the same person. Experiment result shows that our proposed method achieves more accurate and consistent calibration than traditional calibration tools.
FireFly Autonomous Drone Project
Apr 15, 2021
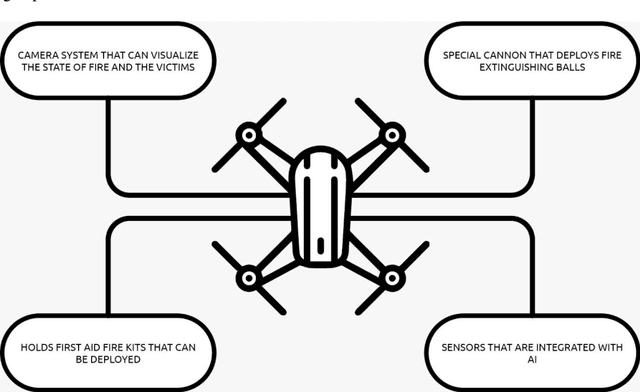
As a fire erupts, the first few minutes can be critical, and first respondents must race to the scene to analyze the situation and act fast before it gets out of hand. Factors such as road traffic condition and distance may not allow quick rescue operation using traditional means and methods, leading to unmanageable spreading of fire, injuries or even deaths that can be avoided. FireFly drone-based rescue consists of a squad of highly equipped drones that will be the first responders to the fire site. Their intervention will make the task of the fire rescue team much more effective and will contribute to reduce the overall damage. As soon as the fire is detected by in-building implanted sensors, the fire department would deploy a set of FireFly drones that would fly to the site, scan the building, and send live fire status information to the Fire fighter team. The drones would have the ability to identify trapped humans using AI based pattern recognition tools (using sensors and thermal cameras) and then drop them rescue kits as appropriate. The drones will also be equipped with fire detection and recognition capabilities and be able to drop fire extinguishing balls as first attempts to put off seeds of fires before they evolve. The integration of drones with firefighting will allow for ease of access and control of fire outbreaks. Drones will also result in increased response time, prevention of further damage, and allow relaying of vital information to out of reach places regarding the characteristics of the fire scene.
Variational approach for learning Markov processes from time series data
Dec 11, 2017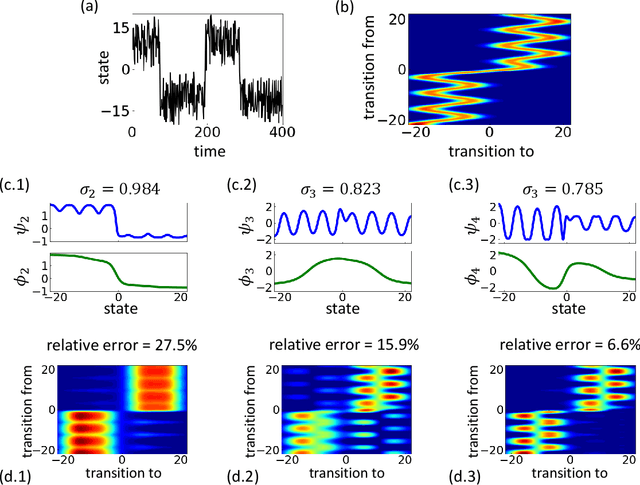
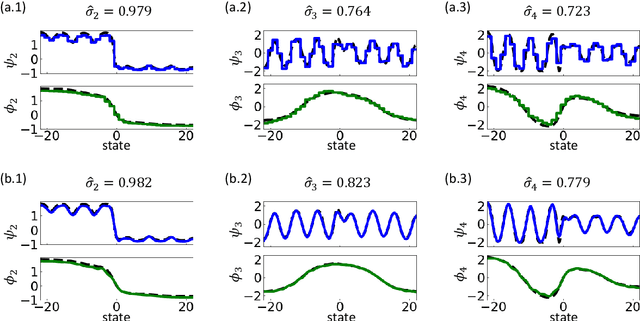
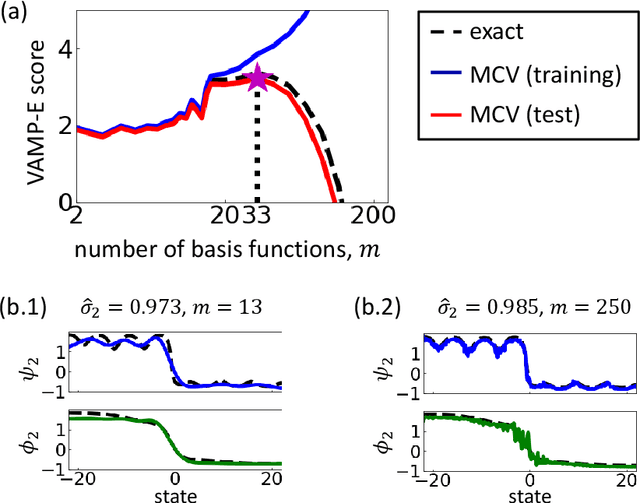
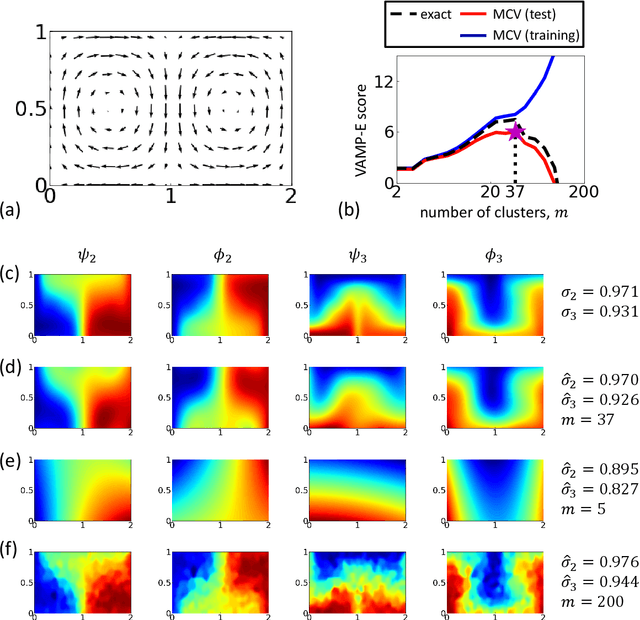
Inference, prediction and control of complex dynamical systems from time series is important in many areas, including financial markets, power grid management, climate and weather modeling, or molecular dynamics. The analysis of such highly nonlinear dynamical systems is facilitated by the fact that we can often find a (generally nonlinear) transformation of the system coordinates to features in which the dynamics can be excellently approximated by a linear Markovian model. Moreover, the large number of system variables often change collectively on large time- and length-scales, facilitating a low-dimensional analysis in feature space. In this paper, we introduce a variational approach for Markov processes (VAMP) that allows us to find optimal feature mappings and optimal Markovian models of the dynamics from given time series data. The key insight is that the best linear model can be obtained from the top singular components of the Koopman operator. This leads to the definition of a family of score functions called VAMP-r which can be calculated from data, and can be employed to optimize a Markovian model. In addition, based on the relationship between the variational scores and approximation errors of Koopman operators, we propose a new VAMP-E score, which can be applied to cross-validation for hyper-parameter optimization and model selection in VAMP. VAMP is valid for both reversible and nonreversible processes and for stationary and non-stationary processes or realizations.
Recovering the Imperfect: Cell Segmentation in the Presence of Dynamically Localized Proteins
Nov 20, 2020
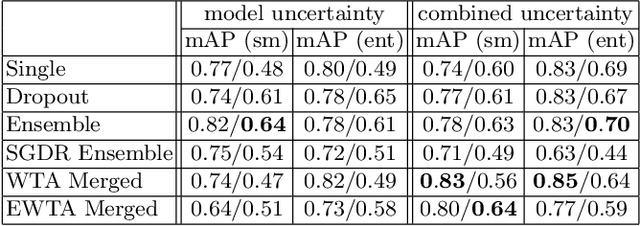
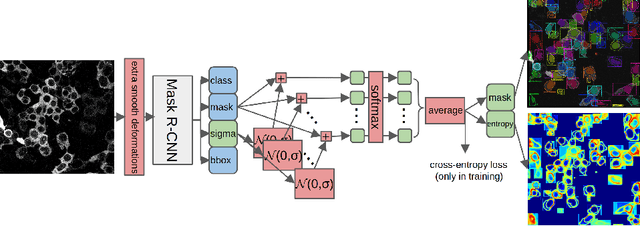
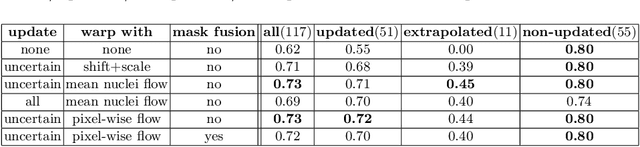
Deploying off-the-shelf segmentation networks on biomedical data has become common practice, yet if structures of interest in an image sequence are visible only temporarily, existing frame-by-frame methods fail. In this paper, we provide a solution to segmentation of imperfect data through time based on temporal propagation and uncertainty estimation. We integrate uncertainty estimation into Mask R-CNN network and propagate motion-corrected segmentation masks from frames with low uncertainty to those frames with high uncertainty to handle temporary loss of signal for segmentation. We demonstrate the value of this approach over frame-by-frame segmentation and regular temporal propagation on data from human embryonic kidney (HEK293T) cells transiently transfected with a fluorescent protein that moves in and out of the nucleus over time. The method presented here will empower microscopic experiments aimed at understanding molecular and cellular function.
Pole-like Objects Mapping and Long-Term Robot Localization in Dynamic Urban Scenarios
Mar 27, 2021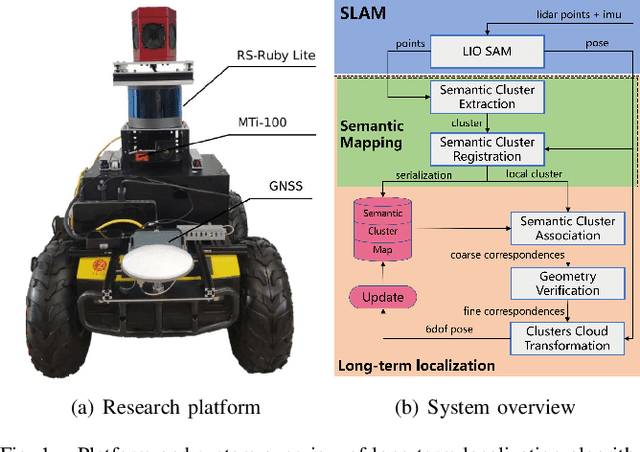
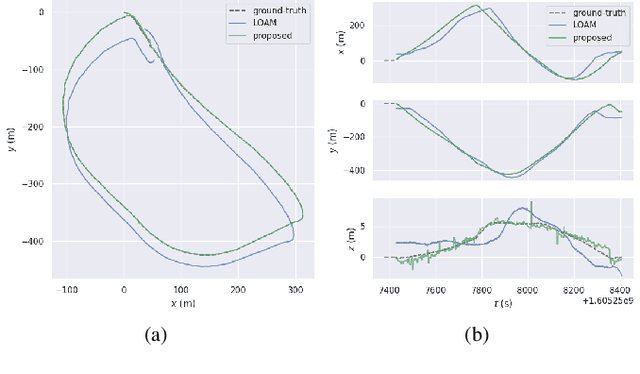
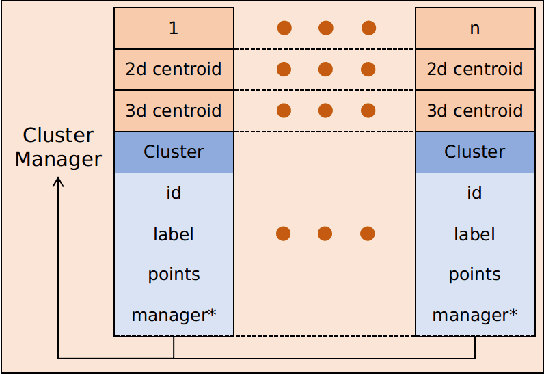
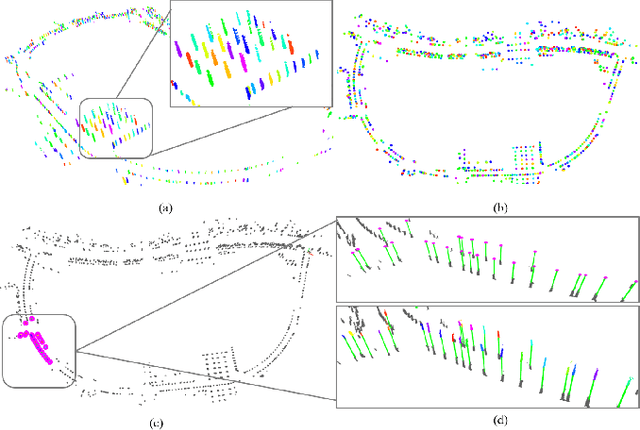
Localization on 3D data is a challenging task for unmanned vehicles, especially in long-term dynamic urban scenarios. Due to the generality and long-term stability, the pole-like objects are very suitable as landmarks for unmanned vehicle localization in time-varing scenarios. In this paper, a long-term LiDAR-only localization algorithm based on semantic cluster map is proposed. At first, the Convolutional Neural Network(CNN) is used to infer the semantics of LiDAR point clouds. Combined with the point cloud segmentation, the long-term static objects pole/trunk in the scene are extracted and registered into a semantic cluster map. When the unmanned vehicle re-enters the environment again, the relocalization is completed by matching the clusters of the local map with the clusters of the global map. Furthermore, the continuous matching between the local and global maps stably outputs the global pose at 2Hz to correct the drift of the 3D LiDAR odometry. The proposed approach realizes localization in the long-term scenarios without maintaining the high-precision point cloud map. The experimental results on our campus dataset demonstrate that the proposed approach performs better in localization accuracy compared with the current state-of-the-art methods. The source of this paper is available at: http://www.github.com/HITSZ-NRSL/long-term-localization.
SCALE: Modeling Clothed Humans with a Surface Codec of Articulated Local Elements
Apr 15, 2021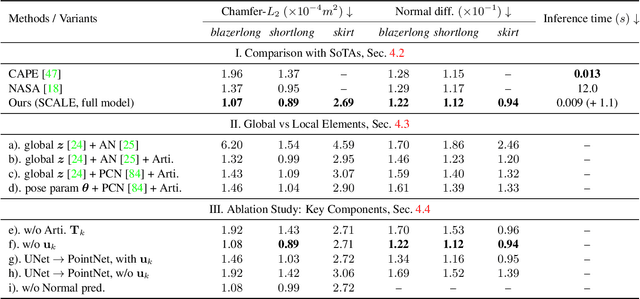
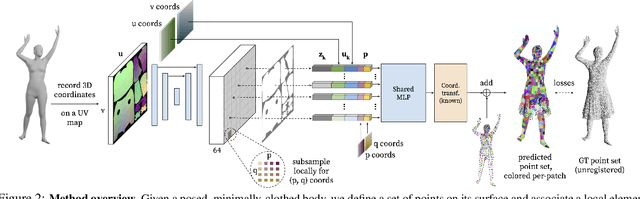
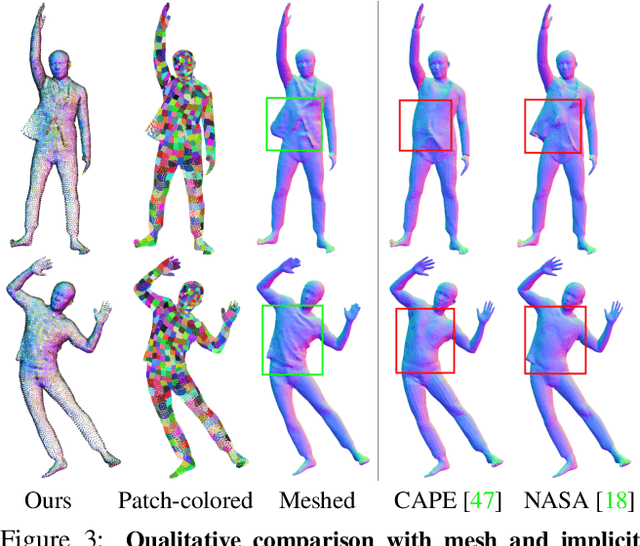

Learning to model and reconstruct humans in clothing is challenging due to articulation, non-rigid deformation, and varying clothing types and topologies. To enable learning, the choice of representation is the key. Recent work uses neural networks to parameterize local surface elements. This approach captures locally coherent geometry and non-planar details, can deal with varying topology, and does not require registered training data. However, naively using such methods to model 3D clothed humans fails to capture fine-grained local deformations and generalizes poorly. To address this, we present three key innovations: First, we deform surface elements based on a human body model such that large-scale deformations caused by articulation are explicitly separated from topological changes and local clothing deformations. Second, we address the limitations of existing neural surface elements by regressing local geometry from local features, significantly improving the expressiveness. Third, we learn a pose embedding on a 2D parameterization space that encodes posed body geometry, improving generalization to unseen poses by reducing non-local spurious correlations. We demonstrate the efficacy of our surface representation by learning models of complex clothing from point clouds. The clothing can change topology and deviate from the topology of the body. Once learned, we can animate previously unseen motions, producing high-quality point clouds, from which we generate realistic images with neural rendering. We assess the importance of each technical contribution and show that our approach outperforms the state-of-the-art methods in terms of reconstruction accuracy and inference time. The code is available for research purposes at https://qianlim.github.io/SCALE .
Distributed Bootstrap for Simultaneous Inference Under High Dimensionality
Feb 19, 2021
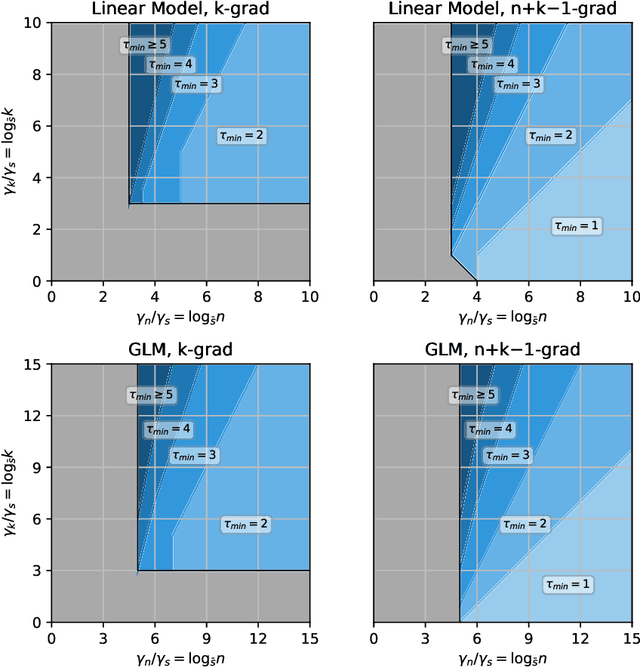
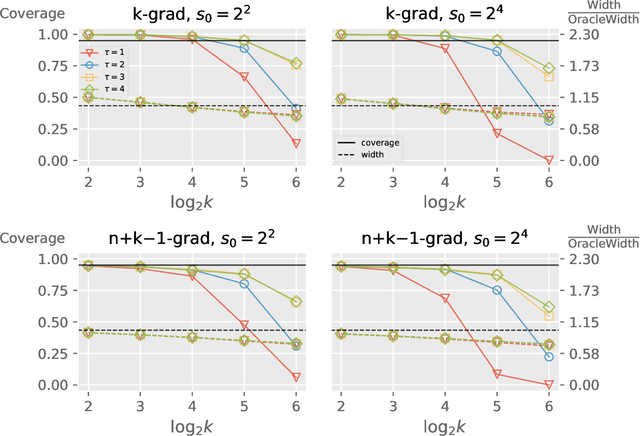
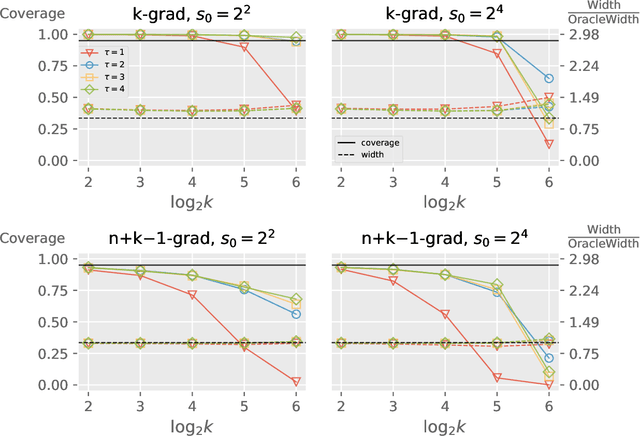
We propose a distributed bootstrap method for simultaneous inference on high-dimensional massive data that are stored and processed with many machines. The method produces a $\ell_\infty$-norm confidence region based on a communication-efficient de-biased lasso, and we propose an efficient cross-validation approach to tune the method at every iteration. We theoretically prove a lower bound on the number of communication rounds $\tau_{\min}$ that warrants the statistical accuracy and efficiency. Furthermore, $\tau_{\min}$ only increases logarithmically with the number of workers and intrinsic dimensionality, while nearly invariant to the nominal dimensionality. We test our theory by extensive simulation studies, and a variable screening task on a semi-synthetic dataset based on the US Airline On-time Performance dataset. The code to reproduce the numerical results is available at GitHub: https://github.com/skchao74/Distributed-bootstrap.
Learning to Solve the AC-OPF using Sensitivity-Informed Deep Neural Networks
Mar 27, 2021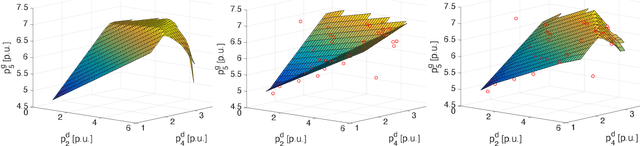
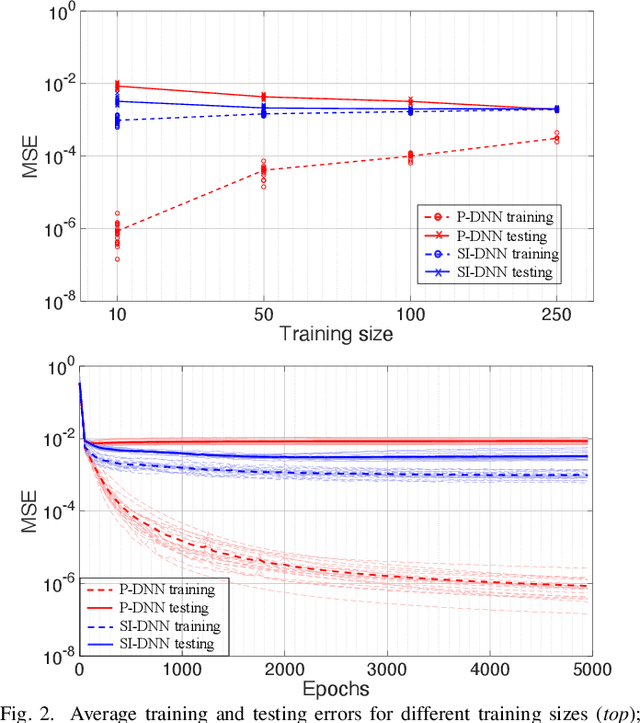
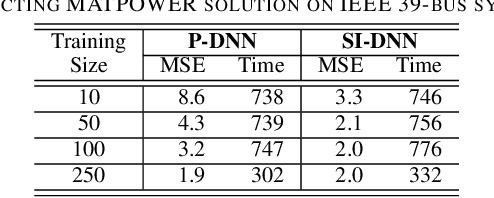
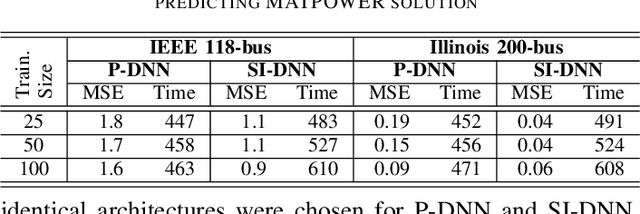
To shift the computational burden from real-time to offline in delay-critical power systems applications, recent works entertain the idea of using a deep neural network (DNN) to predict the solutions of the AC optimal power flow (AC-OPF) once presented load demands. As network topologies may change, training this DNN in a sample-efficient manner becomes a necessity. To improve data efficiency, this work utilizes the fact OPF data are not simple training labels, but constitute the solutions of a parametric optimization problem. We thus advocate training a sensitivity-informed DNN (SI-DNN) to match not only the OPF optimizers, but also their partial derivatives with respect to the OPF parameters (loads). It is shown that the required Jacobian matrices do exist under mild conditions, and can be readily computed from the related primal/dual solutions. The proposed SI-DNN is compatible with a broad range of OPF solvers, including a non-convex quadratically constrained quadratic program (QCQP), its semidefinite program (SDP) relaxation, and MATPOWER; while SI-DNN can be seamlessly integrated in other learning-to-OPF schemes. Numerical tests on three benchmark power systems corroborate the advanced generalization and constraint satisfaction capabilities for the OPF solutions predicted by an SI-DNN over a conventionally trained DNN, especially in low-data setups.
Comparing hundreds of machine learning classifiers and discrete choice models in predicting travel behavior: an empirical benchmark
Feb 01, 2021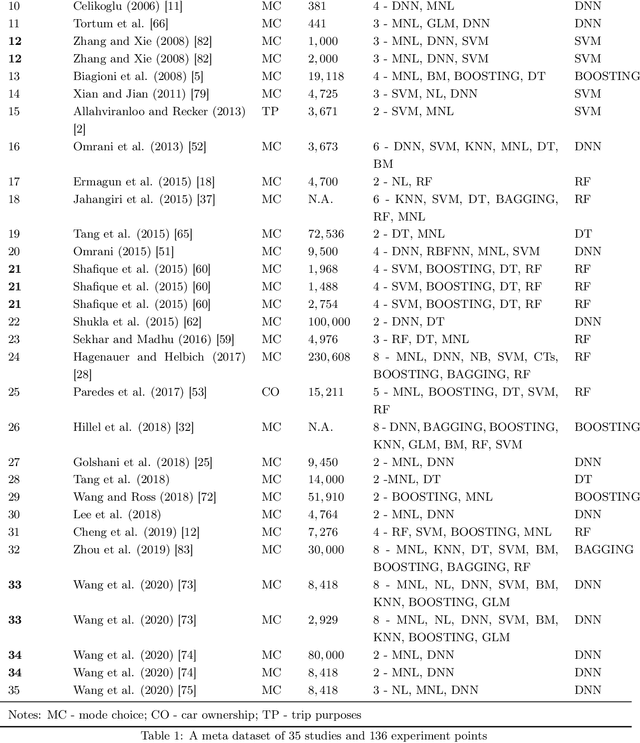
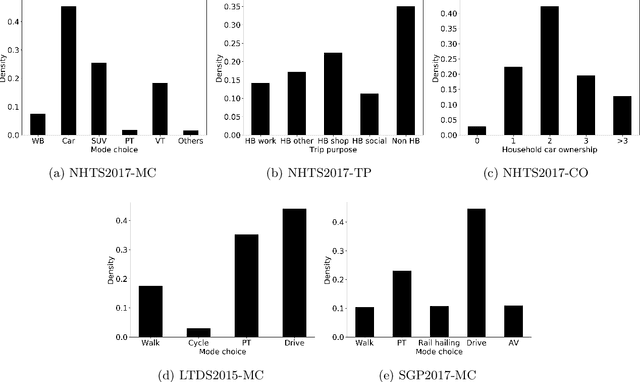

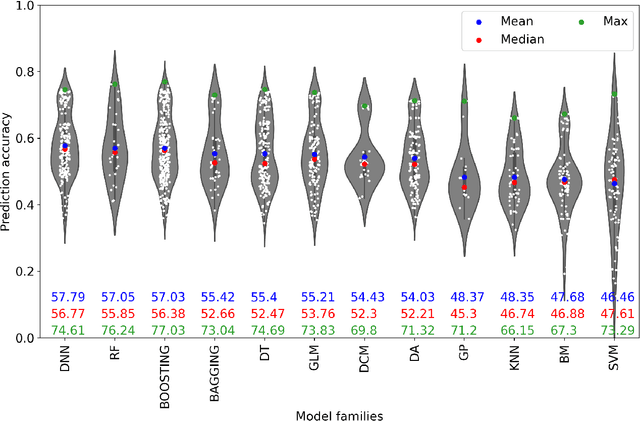
Researchers have compared machine learning (ML) classifiers and discrete choice models (DCMs) in predicting travel behavior, but the generalizability of the findings is limited by the specifics of data, contexts, and authors' expertise. This study seeks to provide a generalizable empirical benchmark by comparing hundreds of ML and DCM classifiers in a highly structured manner. The experiments evaluate both prediction accuracy and computational cost by spanning four hyper-dimensions, including 105 ML and DCM classifiers from 12 model families, 3 datasets, 3 sample sizes, and 3 outputs. This experimental design leads to an immense number of 6,970 experiments, which are corroborated with a meta dataset of 136 experiment points from 35 previous studies. This study is hitherto the most comprehensive and almost exhaustive comparison of the classifiers for travel behavioral prediction. We found that the ensemble methods and deep neural networks achieve the highest predictive performance, but at a relatively high computational cost. Random forests are the most computationally efficient, balancing between prediction and computation. While discrete choice models offer accuracy with only 3-4 percentage points lower than the top ML classifiers, they have much longer computational time and become computationally impossible with large sample size, high input dimensions, or simulation-based estimation. The relative ranking of the ML and DCM classifiers is highly stable, while the absolute values of the prediction accuracy and computational time have large variations. Overall, this paper suggests using deep neural networks, model ensembles, and random forests as baseline models for future travel behavior prediction. For choice modeling, the DCM community should switch more attention from fitting models to improving computational efficiency, so that the DCMs can be widely adopted in the big data context.