 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Adversarial Machine Learning in Text Analysis and Generation
Jan 14, 2021
The research field of adversarial machine learning witnessed a significant interest in the last few years. A machine learner or model is secure if it can deliver main objectives with acceptable accuracy, efficiency, etc. while at the same time, it can resist different types and/or attempts of adversarial attacks. This paper focuses on studying aspects and research trends in adversarial machine learning specifically in text analysis and generation. The paper summarizes main research trends in the field such as GAN algorithms, models, types of attacks, and defense against those attacks.
Learning disentangled representations via product manifold projection
Mar 02, 2021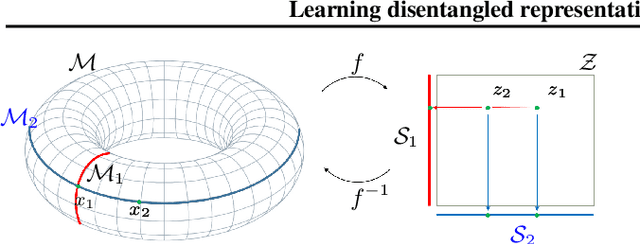
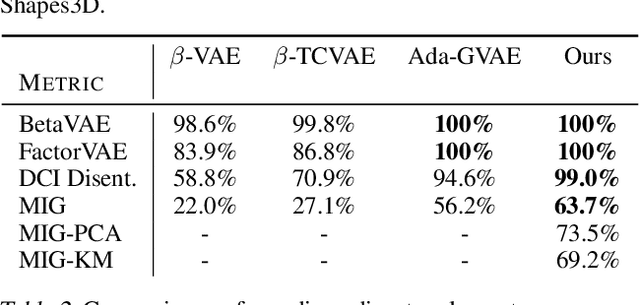
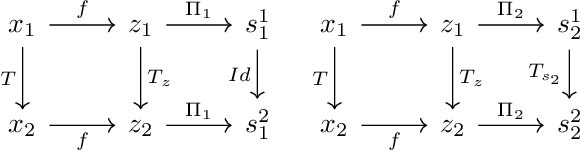
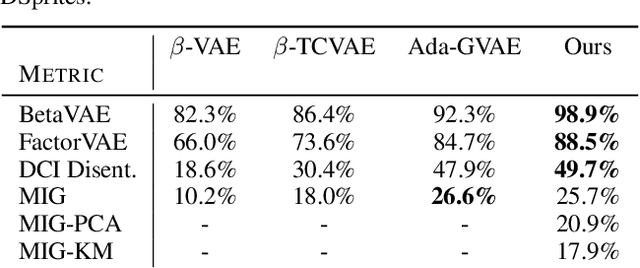
We propose a novel approach to disentangle the generative factors of variation underlying a given set of observations. Our method builds upon the idea that the (unknown) low-dimensional manifold underlying the data space can be explicitly modeled as a product of submanifolds. This gives rise to a new definition of disentanglement, and to a novel weakly-supervised algorithm for recovering the unknown explanatory factors behind the data. At training time, our algorithm only requires pairs of non i.i.d. data samples whose elements share at least one, possibly multidimensional, generative factor of variation. We require no knowledge on the nature of these transformations, and do not make any limiting assumption on the properties of each subspace. Our approach is easy to implement, and can be successfully applied to different kinds of data (from images to 3D surfaces) undergoing arbitrary transformations. In addition to standard synthetic benchmarks, we showcase our method in challenging real-world applications, where we compare favorably with the state of the art.
An Optimal Control Approach to Learning in SIDARTHE Epidemic model
Oct 28, 2020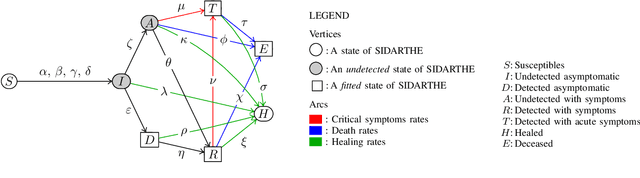
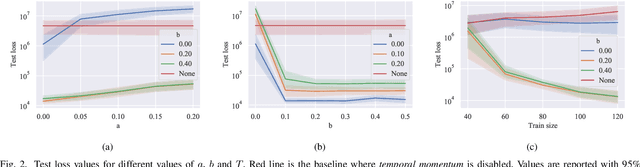
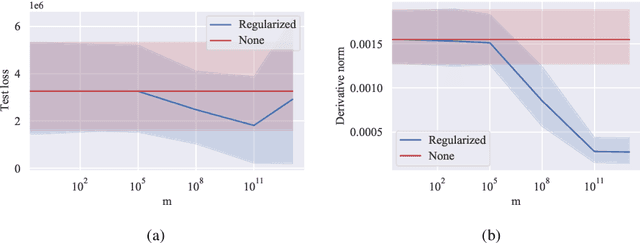
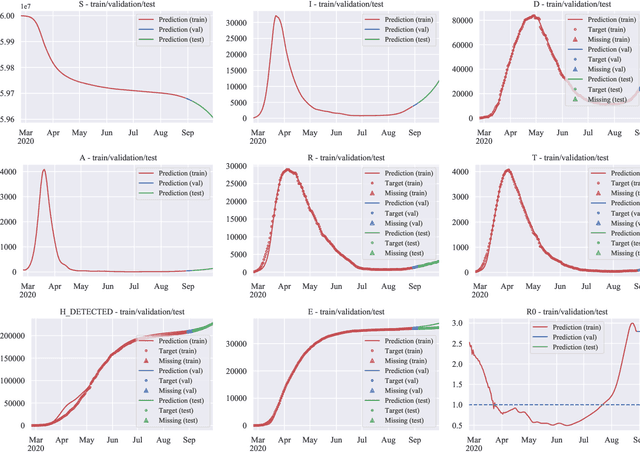
The COVID-19 outbreak has stimulated the interest in the proposal of novel epidemiological models to predict the course of the epidemic so as to help planning effective control strategies. In particular, in order to properly interpret the available data, it has become clear that one must go beyond most classic epidemiological models and consider models that, like the recently proposed SIDARTHE, offer a richer description of the stages of infection. The problem of learning the parameters of these models is of crucial importance especially when assuming that they are time-variant, which further enriches their effectiveness. In this paper we propose a general approach for learning time-variant parameters of dynamic compartmental models from epidemic data. We formulate the problem in terms of a functional risk that depends on the learning variables through the solutions of a dynamic system. The resulting variational problem is then solved by using a gradient flow on a suitable, regularized functional. We forecast the epidemic evolution in Italy and France. Results indicate that the model provides reliable and challenging predictions over all available data as well as the fundamental role of the chosen strategy on the time-variant parameters.
Temporal Action Segmentation from Timestamp Supervision
Mar 11, 2021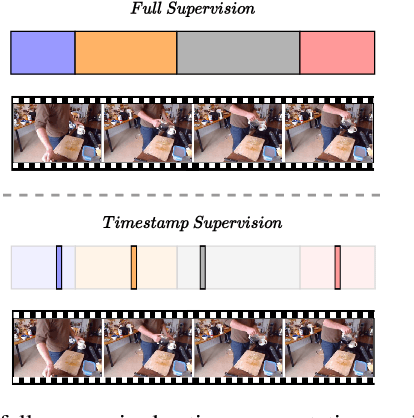
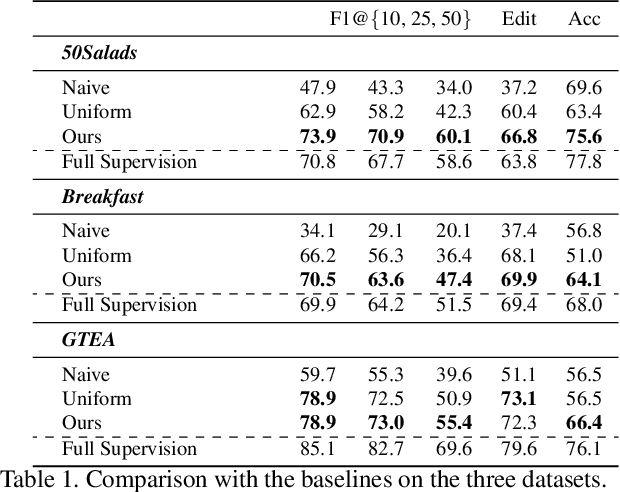
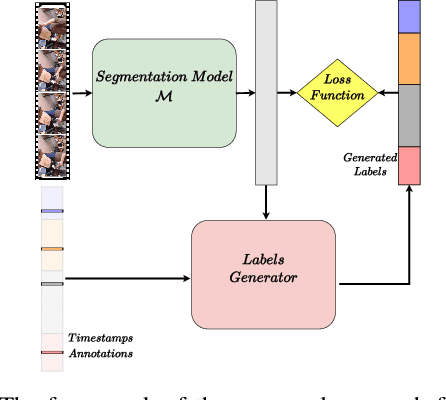
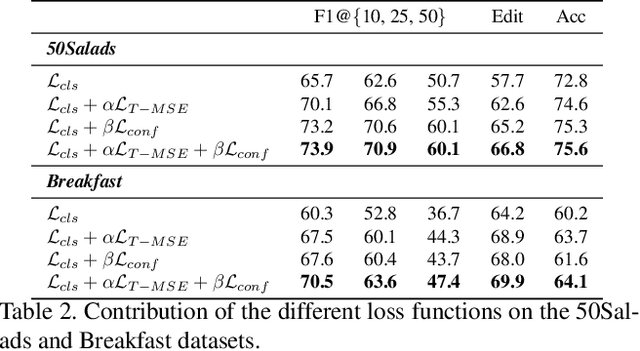
Temporal action segmentation approaches have been very successful recently. However, annotating videos with frame-wise labels to train such models is very expensive and time consuming. While weakly supervised methods trained using only ordered action lists require much less annotation effort, the performance is still much worse than fully supervised approaches. In this paper, we introduce timestamp supervision for the temporal action segmentation task. Timestamps require a comparable annotation effort to weakly supervised approaches, and yet provide a more supervisory signal. To demonstrate the effectiveness of timestamp supervision, we propose an approach to train a segmentation model using only timestamps annotations. Our approach uses the model output and the annotated timestamps to generate frame-wise labels by detecting the action changes. We further introduce a confidence loss that forces the predicted probabilities to monotonically decrease as the distance to the timestamps increases. This ensures that all and not only the most distinctive frames of an action are learned during training. The evaluation on four datasets shows that models trained with timestamps annotations achieve comparable performance to the fully supervised approaches.
Deep Learning-Based Arrhythmia Detection Using RR-Interval Framed Electrocardiograms
Dec 01, 2020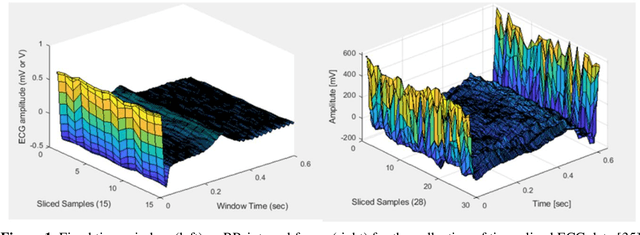
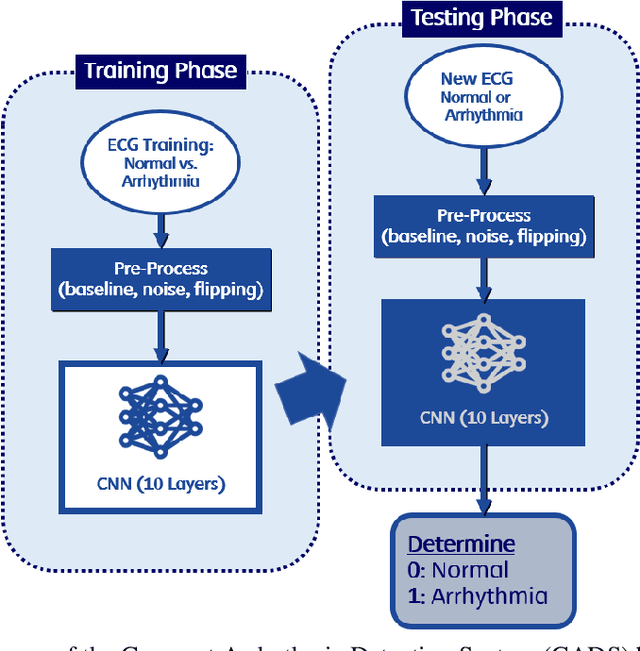
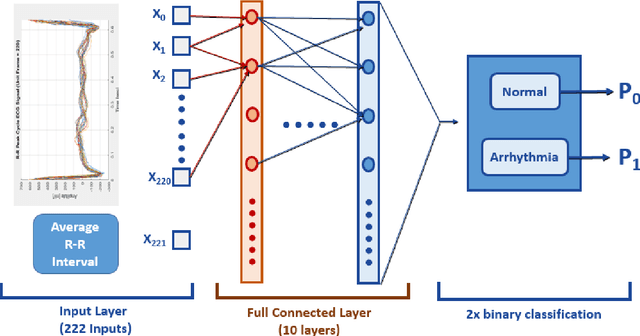
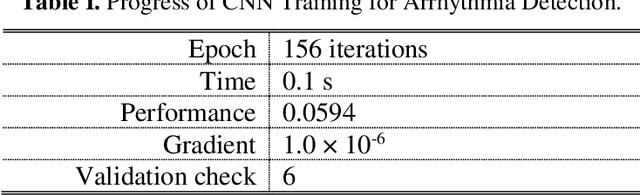
Deep learning applied to electrocardiogram (ECG) data can be used to achieve personal authentication in biometric security applications, but it has not been widely used to diagnose cardiovascular disorders. We developed a deep learning model for the detection of arrhythmia in which time-sliced ECG data representing the distance between successive R-peaks are used as the input for a convolutional neural network (CNN). The main objective is developing the compact deep learning based detect system which minimally uses the dataset but delivers the confident accuracy rate of the Arrhythmia detection. This compact system can be implemented in wearable devices or real-time monitoring equipment because the feature extraction step is not required for complex ECG waveforms, only the R-peak data is needed. The results of both tests indicated that the Compact Arrhythmia Detection System (CADS) matched the performance of conventional systems for the detection of arrhythmia in two consecutive test runs. All features of the CADS are fully implemented and publicly available in MATLAB.
Beyond Image to Depth: Improving Depth Prediction using Echoes
Apr 03, 2021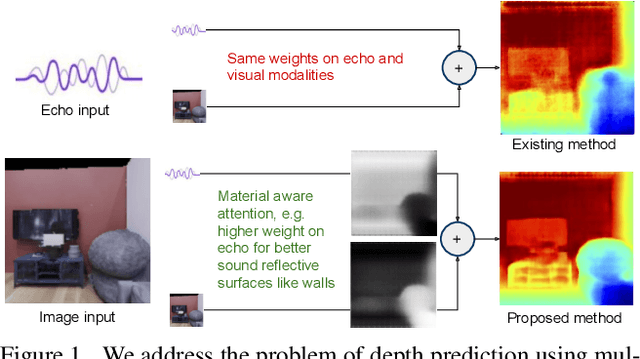
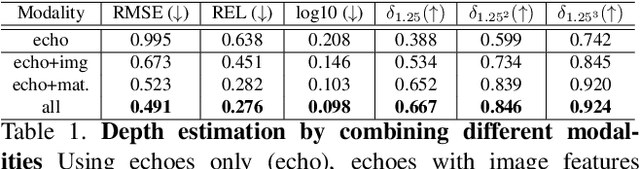
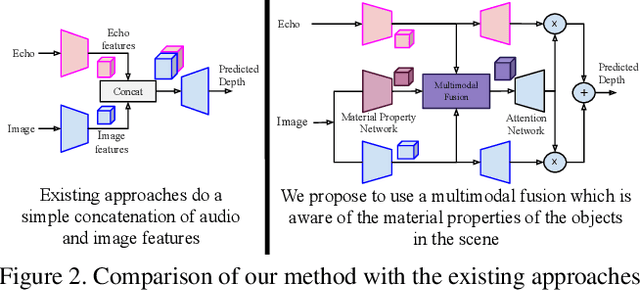
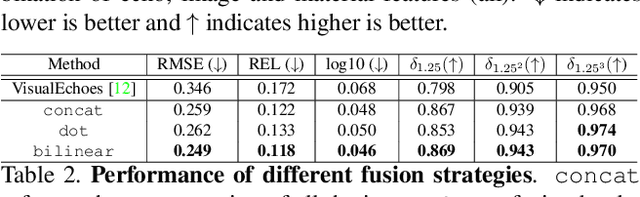
We address the problem of estimating depth with multi modal audio visual data. Inspired by the ability of animals, such as bats and dolphins, to infer distance of objects with echolocation, some recent methods have utilized echoes for depth estimation. We propose an end-to-end deep learning based pipeline utilizing RGB images, binaural echoes and estimated material properties of various objects within a scene. We argue that the relation between image, echoes and depth, for different scene elements, is greatly influenced by the properties of those elements, and a method designed to leverage this information can lead to significantly improved depth estimation from audio visual inputs. We propose a novel multi modal fusion technique, which incorporates the material properties explicitly while combining audio (echoes) and visual modalities to predict the scene depth. We show empirically, with experiments on Replica dataset, that the proposed method obtains 28% improvement in RMSE compared to the state-of-the-art audio-visual depth prediction method. To demonstrate the effectiveness of our method on larger dataset, we report competitive performance on Matterport3D, proposing to use it as a multimodal depth prediction benchmark with echoes for the first time. We also analyse the proposed method with exhaustive ablation experiments and qualitative results. The code and models are available at https://krantiparida.github.io/projects/bimgdepth.html
Unsupervised Domain Adaptation with Global and Local Graph Neural Networks in Limited Labeled Data Scenario: Application to Disaster Management
Apr 03, 2021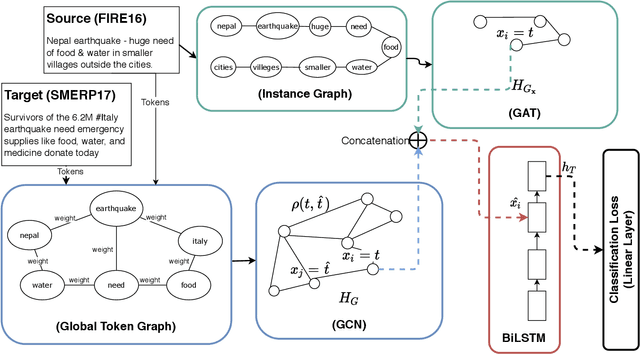
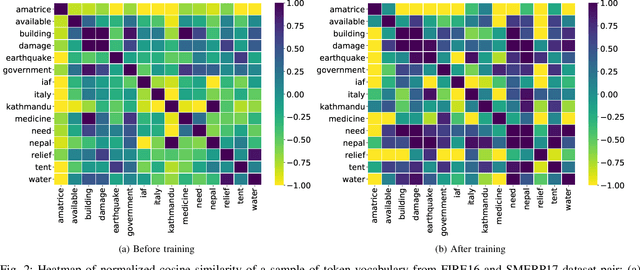
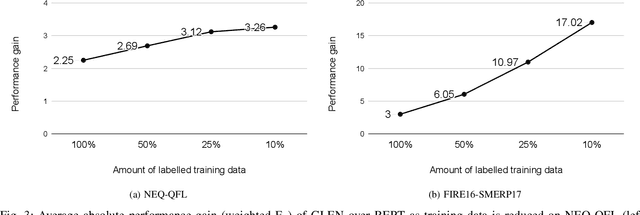

Identification and categorization of social media posts generated during disasters are crucial to reduce the sufferings of the affected people. However, lack of labeled data is a significant bottleneck in learning an effective categorization system for a disaster. This motivates us to study the problem as unsupervised domain adaptation (UDA) between a previous disaster with labeled data (source) and a current disaster (target). However, if the amount of labeled data available is limited, it restricts the learning capabilities of the model. To handle this challenge, we utilize limited labeled data along with abundantly available unlabeled data, generated during a source disaster to propose a novel two-part graph neural network. The first-part extracts domain-agnostic global information by constructing a token level graph across domains and the second-part preserves local instance-level semantics. In our experiments, we show that the proposed method outperforms state-of-the-art techniques by $2.74\%$ weighted F$_1$ score on average on two standard public dataset in the area of disaster management. We also report experimental results for granular actionable multi-label classification datasets in disaster domain for the first time, on which we outperform BERT by $3.00\%$ on average w.r.t weighted F$_1$. Additionally, we show that our approach can retain performance when very limited labeled data is available.
SplitSR: An End-to-End Approach to Super-Resolution on Mobile Devices
Jan 20, 2021
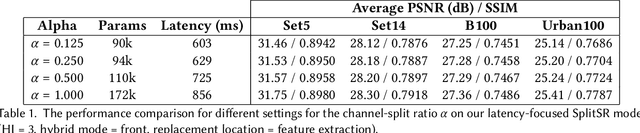
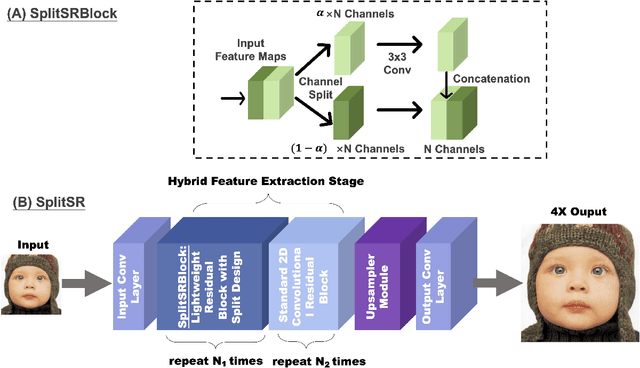

Super-resolution (SR) is a coveted image processing technique for mobile apps ranging from the basic camera apps to mobile health. Existing SR algorithms rely on deep learning models with significant memory requirements, so they have yet to be deployed on mobile devices and instead operate in the cloud to achieve feasible inference time. This shortcoming prevents existing SR methods from being used in applications that require near real-time latency. In this work, we demonstrate state-of-the-art latency and accuracy for on-device super-resolution using a novel hybrid architecture called SplitSR and a novel lightweight residual block called SplitSRBlock. The SplitSRBlock supports channel-splitting, allowing the residual blocks to retain spatial information while reducing the computation in the channel dimension. SplitSR has a hybrid design consisting of standard convolutional blocks and lightweight residual blocks, allowing people to tune SplitSR for their computational budget. We evaluate our system on a low-end ARM CPU, demonstrating both higher accuracy and up to 5 times faster inference than previous approaches. We then deploy our model onto a smartphone in an app called ZoomSR to demonstrate the first-ever instance of on-device, deep learning-based SR. We conducted a user study with 15 participants to have them assess the perceived quality of images that were post-processed by SplitSR. Relative to bilinear interpolation -- the existing standard for on-device SR -- participants showed a statistically significant preference when looking at both images (Z=-9.270, p<0.01) and text (Z=-6.486, p<0.01).
Real-Time Fine-Grained Air Quality Sensing Networks in Smart City: Design, Implementation and Optimization
Oct 18, 2018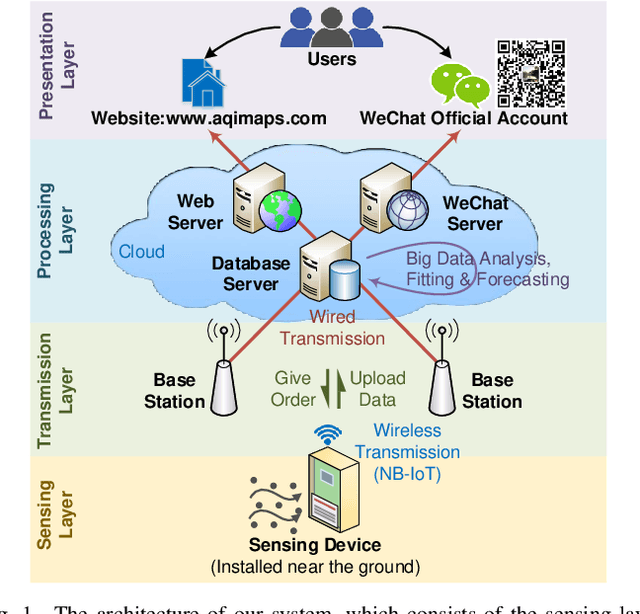
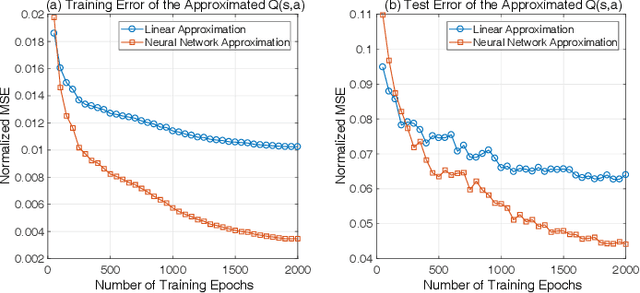
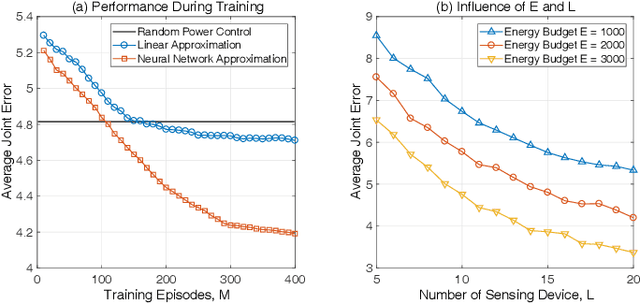
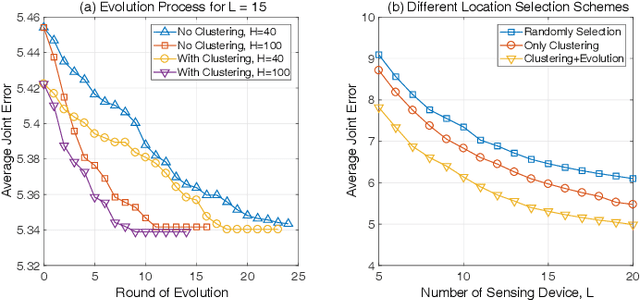
Driven by the increasingly serious air pollution problem, the monitoring of air quality has gained much attention in both theoretical studies and practical implementations. In this paper, we present the architecture, implementation and optimization of our own air quality sensing system, which provides real-time and fine-grained air quality map of the monitored area. As the major component, the optimization problem of our system is studied in detail. Our objective is to minimize the average joint error of the established real-time air quality map, which involves data inference for the unmeasured data values. A deep Q-learning solution has been proposed for the power control problem to reasonably plan the sensing tasks of the power-limited sensing devices online. A genetic algorithm has been designed for the location selection problem to efficiently find the suitable locations to deploy limited number of sensing devices. The performance of the proposed solutions are evaluated by simulations, showing a significant performance gain when adopting both strategies.
Demystifying Batch Normalization in ReLU Networks: Equivalent Convex Optimization Models and Implicit Regularization
Mar 02, 2021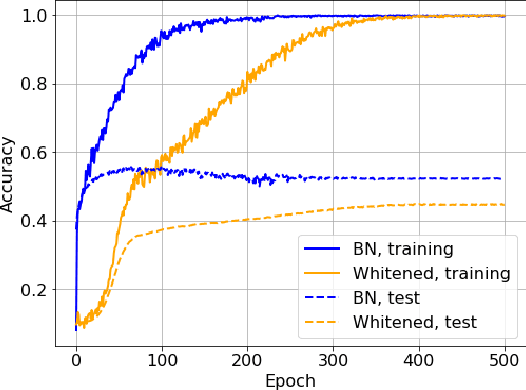
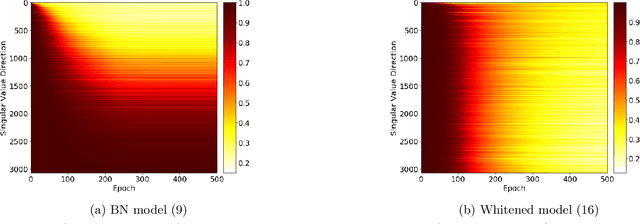
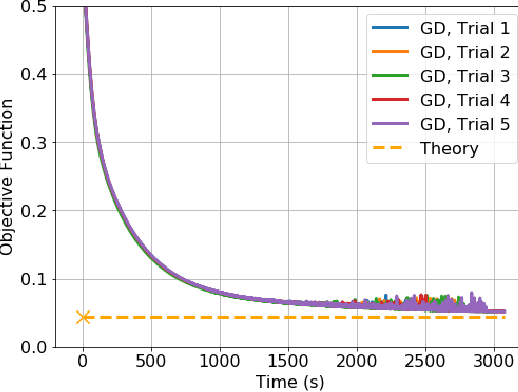
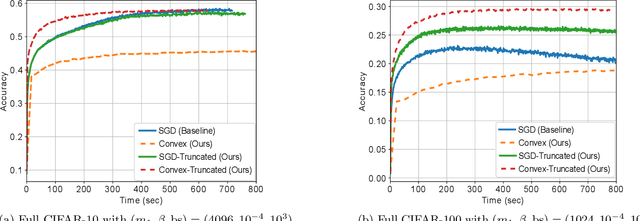
Batch Normalization (BN) is a commonly used technique to accelerate and stabilize training of deep neural networks. Despite its empirical success, a full theoretical understanding of BN is yet to be developed. In this work, we analyze BN through the lens of convex optimization. We introduce an analytic framework based on convex duality to obtain exact convex representations of weight-decay regularized ReLU networks with BN, which can be trained in polynomial-time. Our analyses also show that optimal layer weights can be obtained as simple closed-form formulas in the high-dimensional and/or overparameterized regimes. Furthermore, we find that Gradient Descent provides an algorithmic bias effect on the standard non-convex BN network, and we design an approach to explicitly encode this implicit regularization into the convex objective. Experiments with CIFAR image classification highlight the effectiveness of this explicit regularization for mimicking and substantially improving the performance of standard BN networks.