 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
A novel multimodal fusion network based on a joint coding model for lane line segmentation
Mar 20, 2021

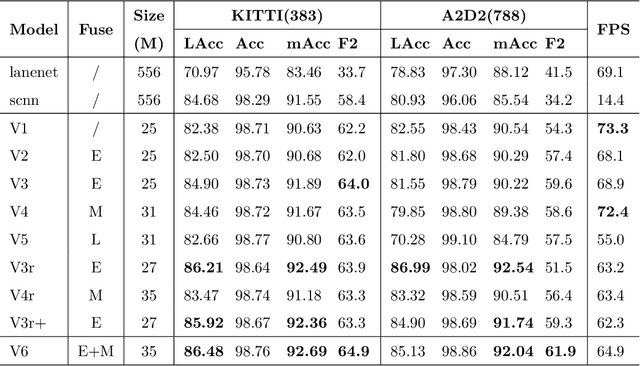
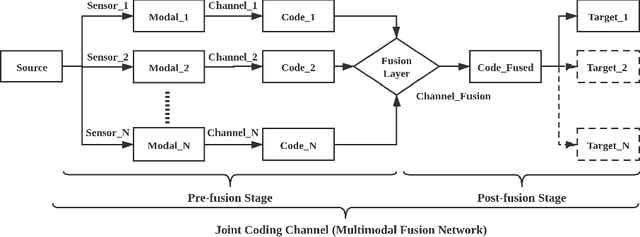
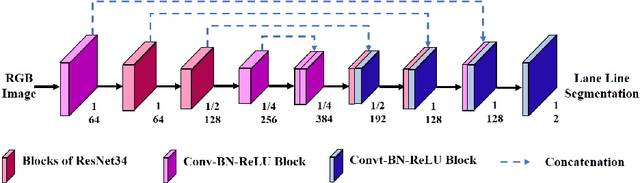
There has recently been growing interest in utilizing multimodal sensors to achieve robust lane line segmentation. In this paper, we introduce a novel multimodal fusion architecture from an information theory perspective, and demonstrate its practical utility using Light Detection and Ranging (LiDAR) camera fusion networks. In particular, we develop, for the first time, a multimodal fusion network as a joint coding model, where each single node, layer, and pipeline is represented as a channel. The forward propagation is thus equal to the information transmission in the channels. Then, we can qualitatively and quantitatively analyze the effect of different fusion approaches. We argue the optimal fusion architecture is related to the essential capacity and its allocation based on the source and channel. To test this multimodal fusion hypothesis, we progressively determine a series of multimodal models based on the proposed fusion methods and evaluate them on the KITTI and the A2D2 datasets. Our optimal fusion network achieves 85%+ lane line accuracy and 98.7%+ overall. The performance gap among the models will inform continuing future research into development of optimal fusion algorithms for the deep multimodal learning community.
Generative deep learning for decision making in gas networks
Feb 03, 2021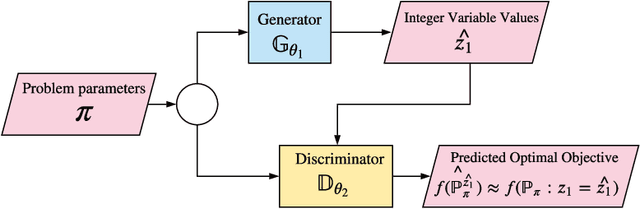
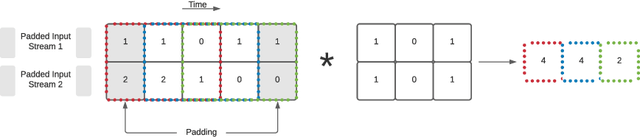
A decision support system relies on frequent re-solving of similar problem instances. While the general structure remains the same in corresponding applications, the input parameters are updated on a regular basis. We propose a generative neural network design for learning integer decision variables of mixed-integer linear programming (MILP) formulations of these problems. We utilise a deep neural network discriminator and a MILP solver as our oracle to train our generative neural network. In this article, we present the results of our design applied to the transient gas optimisation problem. With the trained network we produce a feasible solution in 2.5s, use it as a warm-start solution, and thereby decrease global optimal solution solve time by 60.5%.
Forecasting Black Sigatoka Infection Risks with Latent Neural ODEs
Dec 01, 2020

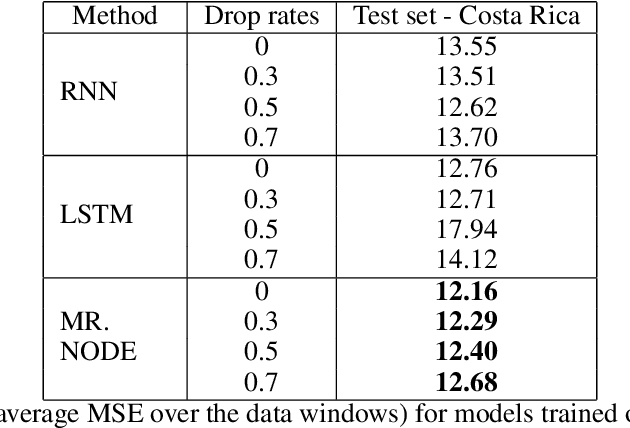
Black Sigatoka disease severely decreases global banana production, and climate change aggravates the problem by altering fungal species distributions. Due to the heavy financial burden of managing this infectious disease, farmers in developing countries face significant banana crop losses. Though scientists have produced mathematical models of infectious diseases, adapting these models to incorporate climate effects is difficult. We present MR. NODE (Multiple predictoR Neural ODE), a neural network that models the dynamics of black Sigatoka infection learnt directly from data via Neural Ordinary Differential Equations. Our method encodes external predictor factors into the latent space in addition to the variable that we infer, and it can also predict the infection risk at an arbitrary point in time. Empirically, we demonstrate on historical climate data that our method has superior generalization performance on time points up to one month in the future and unseen irregularities. We believe that our method can be a useful tool to control the spread of black Sigatoka.
Crowd Vetting: Rejecting Adversaries via Collaboration--with Application to Multi-Robot Flocking
Dec 11, 2020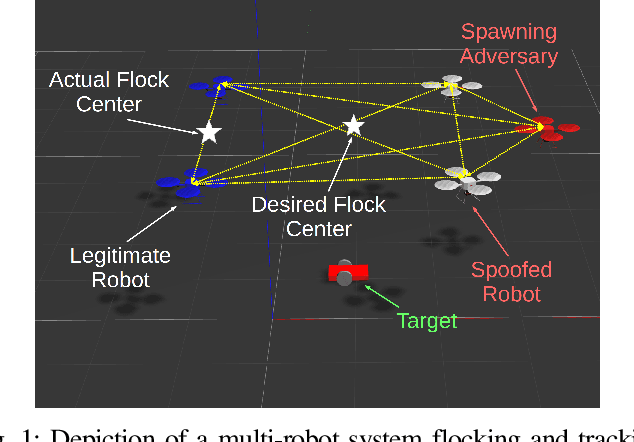
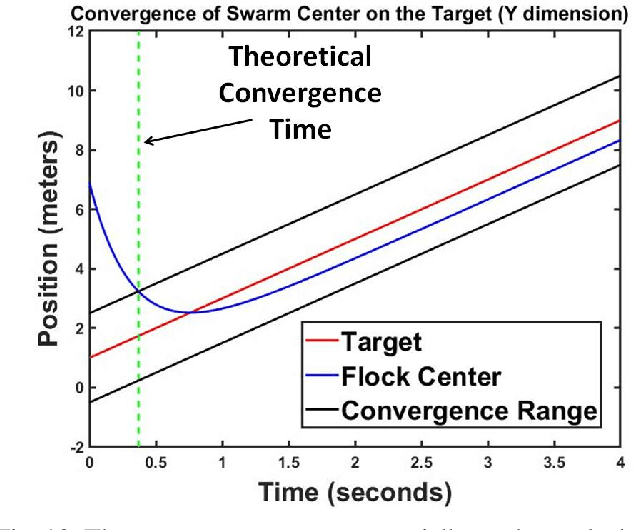
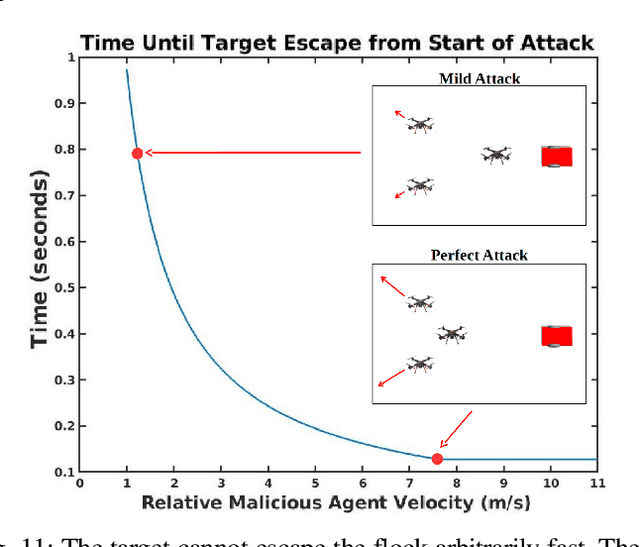
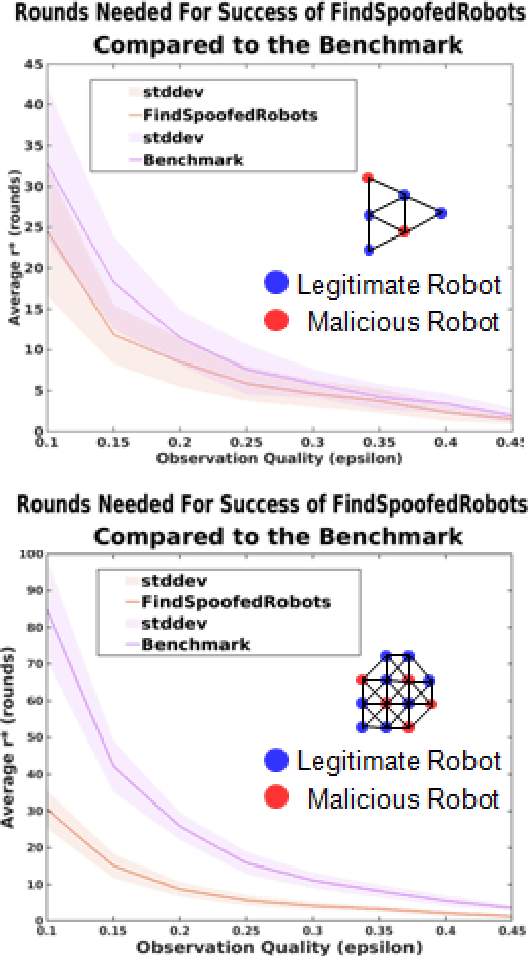
We characterize the advantage of using a robot's neighborhood to find and eliminate adversarial robots in the presence of a Sybil attack. We show that by leveraging the opinions of its neighbors on the trustworthiness of transmitted data, robots can detect adversaries with high probability. We characterize a number of communication rounds required to achieve this result to be a function of the communication quality and the proportion of legitimate to malicious robots. This result enables increased resiliency of many multi-robot algorithms. Because our results are finite time and not asymptotic, they are particularly well-suited for problems with a time critical nature. We develop two algorithms, \emph{FindSpoofedRobots} that determines trusted neighbors with high probability, and \emph{FindResilientAdjacencyMatrix} that enables distributed computation of graph properties in an adversarial setting. We apply our methods to a flocking problem where a team of robots must track a moving target in the presence of adversarial robots. We show that by using our algorithms, the team of robots are able to maintain tracking ability of the dynamic target.
Sequential Estimation of Nonparametric Correlation using Hermite Series Estimators
Dec 11, 2020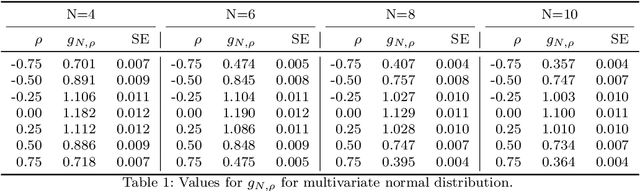
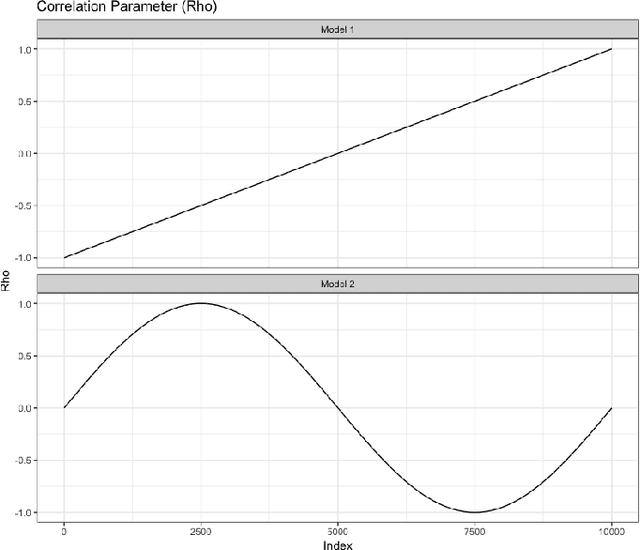
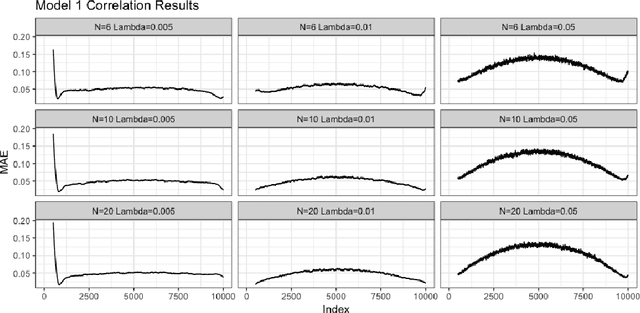
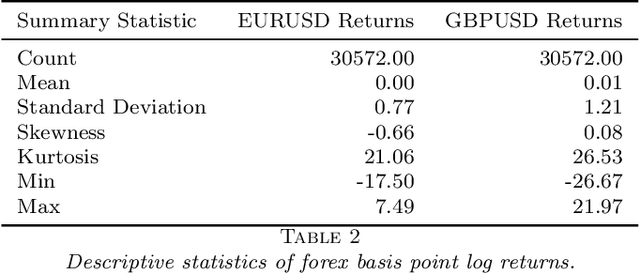
In this article we describe a new Hermite series based sequential estimator for the Spearman's rank correlation coefficient and provide algorithms applicable in both the stationary and non-stationary settings. To treat the non-stationary setting, we introduce a novel, exponentially weighted estimator for the Spearman's rank correlation, which allows the local nonparametric correlation of a bivariate data stream to be tracked. To the best of our knowledge this is the first algorithm to be proposed for estimating a time-varying Spearman's rank correlation that does not rely on a moving window approach. We explore the practical effectiveness of the Hermite series based estimators through real data and simulation studies demonstrating good practical performance. The simulation studies in particular reveal competitive performance compared to an existing algorithm. The potential applications of this work are manifold. The Hermite series based Spearman's rank correlation estimator can be applied to fast and robust online calculation of correlation which may vary over time. Possible machine learning applications include, amongst others, fast feature selection and hierarchical clustering on massive data sets.
Real-Time Fine-Grained Air Quality Sensing Networks in Smart City: Design, Implementation and Optimization
Oct 18, 2018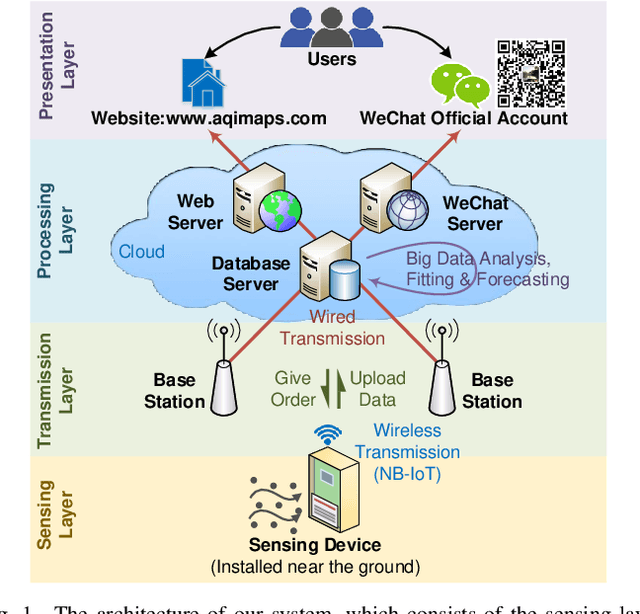
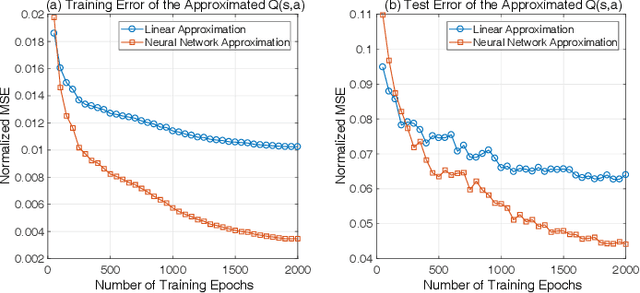
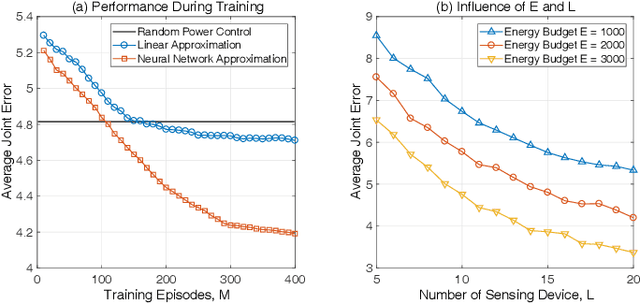
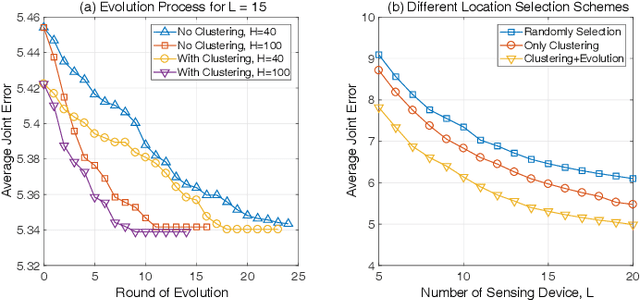
Driven by the increasingly serious air pollution problem, the monitoring of air quality has gained much attention in both theoretical studies and practical implementations. In this paper, we present the architecture, implementation and optimization of our own air quality sensing system, which provides real-time and fine-grained air quality map of the monitored area. As the major component, the optimization problem of our system is studied in detail. Our objective is to minimize the average joint error of the established real-time air quality map, which involves data inference for the unmeasured data values. A deep Q-learning solution has been proposed for the power control problem to reasonably plan the sensing tasks of the power-limited sensing devices online. A genetic algorithm has been designed for the location selection problem to efficiently find the suitable locations to deploy limited number of sensing devices. The performance of the proposed solutions are evaluated by simulations, showing a significant performance gain when adopting both strategies.
Image/Video Deep Anomaly Detection: A Survey
Mar 02, 2021
The considerable significance of Anomaly Detection (AD) problem has recently drawn the attention of many researchers. Consequently, the number of proposed methods in this research field has been increased steadily. AD strongly correlates with the important computer vision and image processing tasks such as image/video anomaly, irregularity and sudden event detection. More recently, Deep Neural Networks (DNNs) offer a high performance set of solutions, but at the expense of a heavy computational cost. However, there is a noticeable gap between the previously proposed methods and an applicable real-word approach. Regarding the raised concerns about AD as an ongoing challenging problem, notably in images and videos, the time has come to argue over the pitfalls and prospects of methods have attempted to deal with visual AD tasks. Hereupon, in this survey we intend to conduct an in-depth investigation into the images/videos deep learning based AD methods. We also discuss current challenges and future research directions thoroughly.
Are pre-trained text representations useful for multilingual and multi-dimensional language proficiency modeling?
Feb 25, 2021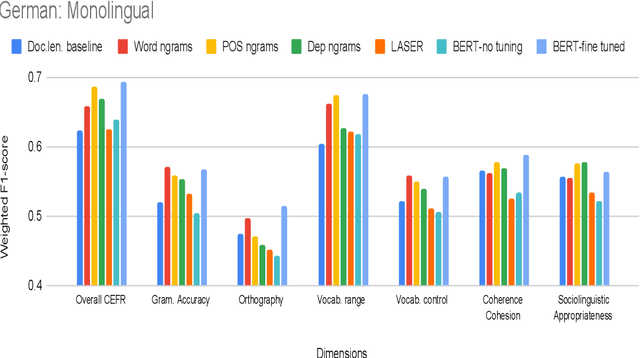
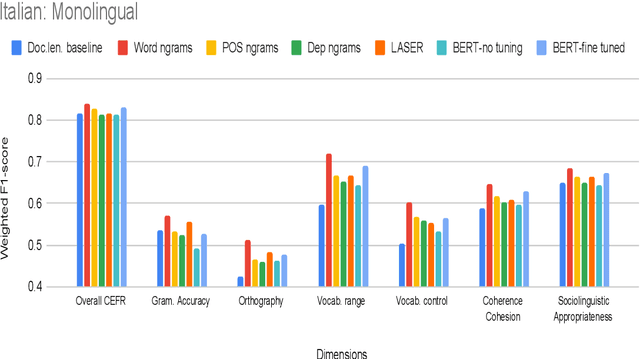
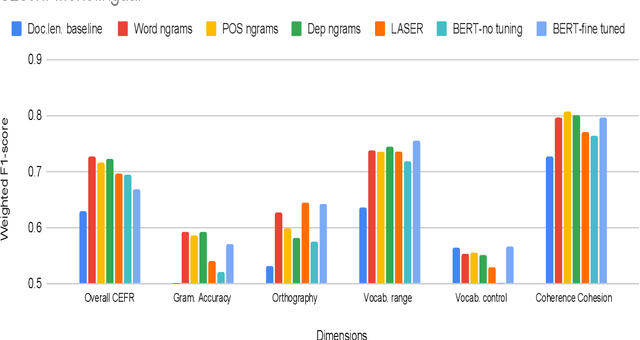
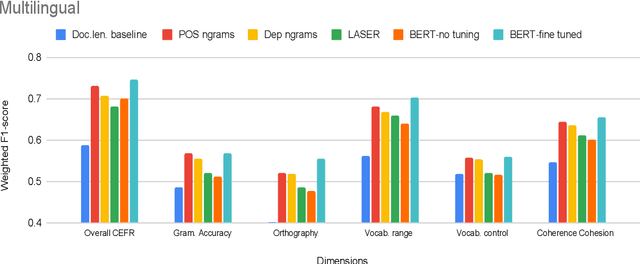
Development of language proficiency models for non-native learners has been an active area of interest in NLP research for the past few years. Although language proficiency is multidimensional in nature, existing research typically considers a single "overall proficiency" while building models. Further, existing approaches also considers only one language at a time. This paper describes our experiments and observations about the role of pre-trained and fine-tuned multilingual embeddings in performing multi-dimensional, multilingual language proficiency classification. We report experiments with three languages -- German, Italian, and Czech -- and model seven dimensions of proficiency ranging from vocabulary control to sociolinguistic appropriateness. Our results indicate that while fine-tuned embeddings are useful for multilingual proficiency modeling, none of the features achieve consistently best performance for all dimensions of language proficiency. All code, data and related supplementary material can be found at: https://github.com/nishkalavallabhi/MultidimCEFRScoring.
Query Understanding for Natural Language Enterprise Search
Dec 11, 2020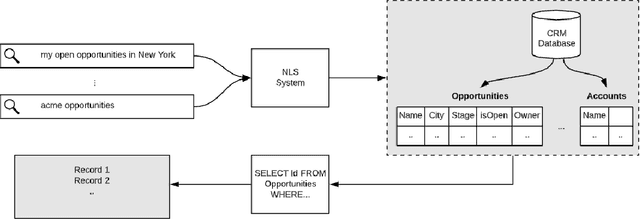
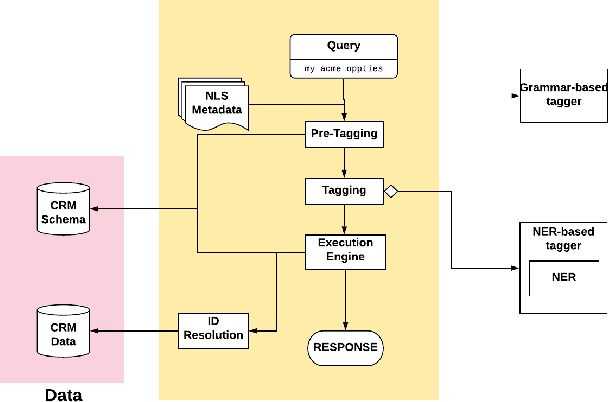

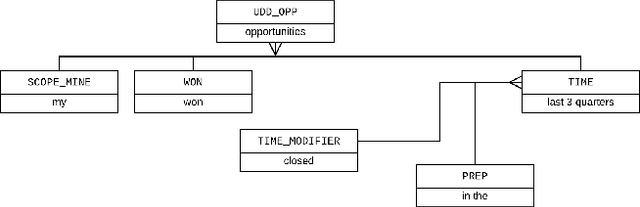
Natural Language Search (NLS) extends the capabilities of search engines that perform keyword search allowing users to issue queries in a more "natural" language. The engine tries to understand the meaning of the queries and to map the query words to the symbols it supports like Persons, Organizations, Time Expressions etc.. It, then, retrieves the information that satisfies the user's need in different forms like an answer, a record or a list of records. We present an NLS system we implemented as part of the Search service of a major CRM platform. The system is currently in production serving thousands of customers. Our user studies showed that creating dynamic reports with NLS saved more than 50% of our user's time compared to achieving the same result with navigational search. We describe the architecture of the system, the particularities of the CRM domain as well as how they have influenced our design decisions. Among several submodules of the system we detail the role of a Deep Learning Named Entity Recognizer. The paper concludes with discussion over the lessons learned while developing this product.
S3-Net: A Fast and Lightweight Video Scene Understanding Network by Single-shot Segmentation
Nov 04, 2020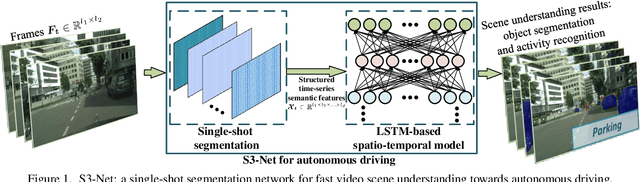
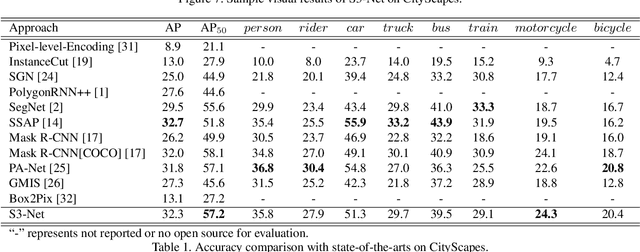
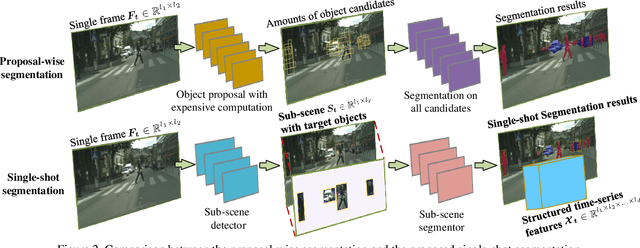
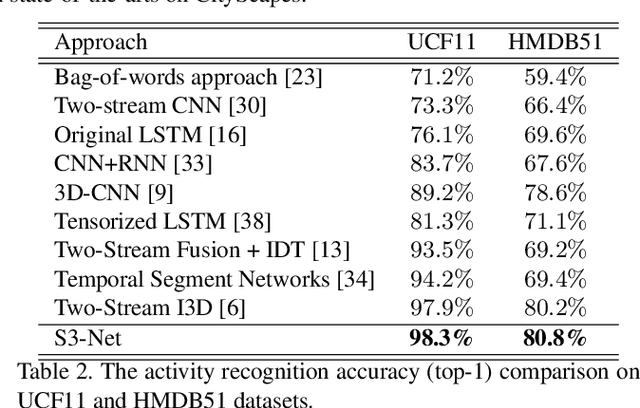
Real-time understanding in video is crucial in various AI applications such as autonomous driving. This work presents a fast single-shot segmentation strategy for video scene understanding. The proposed net, called S3-Net, quickly locates and segments target sub-scenes, meanwhile extracts structured time-series semantic features as inputs to an LSTM-based spatio-temporal model. Utilizing tensorization and quantization techniques, S3-Net is intended to be lightweight for edge computing. Experiments using CityScapes, UCF11, HMDB51 and MOMENTS datasets demonstrate that the proposed S3-Net achieves an accuracy improvement of 8.1% versus the 3D-CNN based approach on UCF11, a storage reduction of 6.9x and an inference speed of 22.8 FPS on CityScapes with a GTX1080Ti GPU.