 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
MT-Spike: A Multilayer Time-based Spiking Neuromorphic Architecture with Temporal Error Backpropagation
Mar 14, 2018
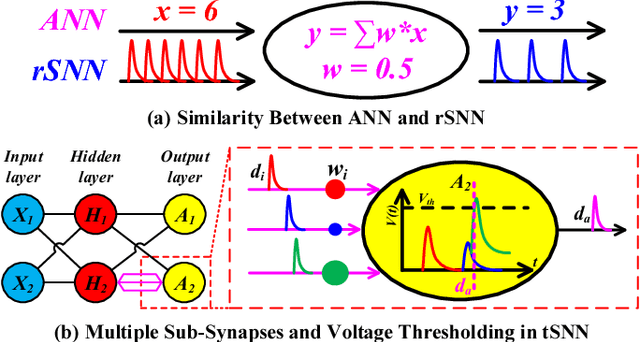


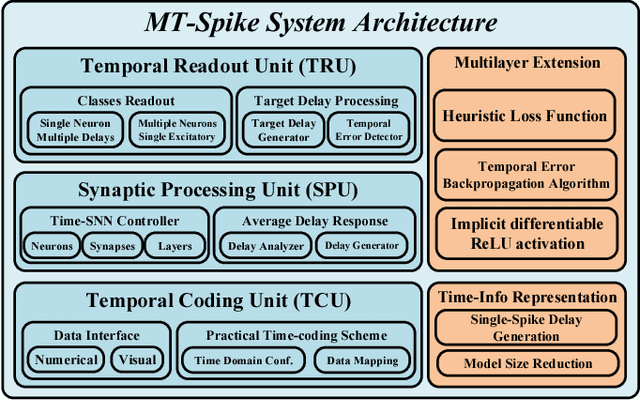
Modern deep learning enabled artificial neural networks, such as Deep Neural Network (DNN) and Convolutional Neural Network (CNN), have achieved a series of breaking records on a broad spectrum of recognition applications. However, the enormous computation and storage requirements associated with such deep and complex neural network models greatly challenge their implementations on resource-limited platforms. Time-based spiking neural network has recently emerged as a promising solution in Neuromorphic Computing System designs for achieving remarkable computing and power efficiency within a single chip. However, the relevant research activities have been narrowly concentrated on the biological plausibility and theoretical learning approaches, causing inefficient neural processing and impracticable multilayer extension thus significantly limitations on speed and accuracy when handling the realistic cognitive tasks. In this work, a practical multilayer time-based spiking neuromorphic architecture, namely "MT-Spike", is developed to fill this gap. With the proposed practical time-coding scheme, average delay response model, temporal error backpropagation algorithm, and heuristic loss function, "MT-Spike" achieves more efficient neural processing through flexible neural model size reduction while offering very competitive classification accuracy for realistic recognition tasks. Simulation results well validated that the algorithmic power of deep multi-layer learning can be seamlessly merged with the efficiency of time-based spiking neuromorphic architecture, demonstrating great potentials of "MT-Spike" in resource and power constrained embedded platforms.
Reservoir Transformer
Dec 30, 2020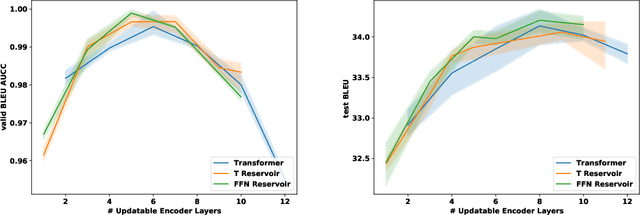
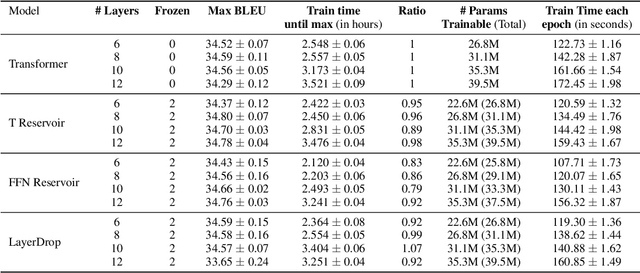
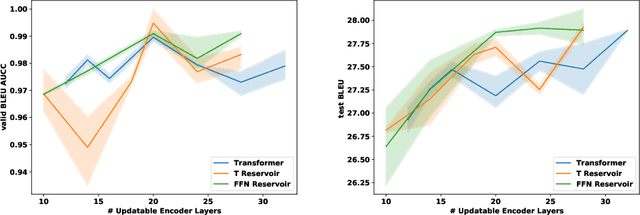
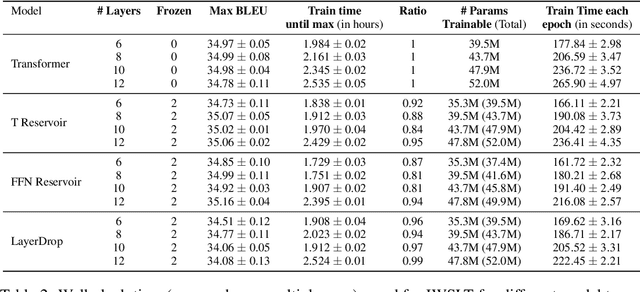
We demonstrate that transformers obtain impressive performance even when some of the layers are randomly initialized and never updated. Inspired by old and well-established ideas in machine learning, we explore a variety of non-linear "reservoir" layers interspersed with regular transformer layers, and show improvements in wall-clock compute time until convergence, as well as overall performance, on various machine translation and (masked) language modelling tasks.
Transient Information Adaptation of Artificial Intelligence: Towards Sustainable Data Processes in Complex Projects
Apr 18, 2021Large scale projects increasingly operate in complicated settings whilst drawing on an array of complex data-points, which require precise analysis for accurate control and interventions to mitigate possible project failure. Coupled with a growing tendency to rely on new information systems and processes in change projects, 90% of megaprojects globally fail to achieve their planned objectives. Renewed interest in the concept of Artificial Intelligence (AI) against a backdrop of disruptive technological innovations, seeks to enhance project managers cognitive capacity through the project lifecycle and enhance project excellence. However, despite growing interest there remains limited empirical insights on project managers ability to leverage AI for cognitive load enhancement in complex settings. As such this research adopts an exploratory sequential linear mixed methods approach to address unresolved empirical issues on transient adaptations of AI in complex projects, and the impact on cognitive load enhancement. Initial thematic findings from semi-structured interviews with domain experts, suggest that in order to leverage AI technologies and processes for sustainable cognitive load enhancement with complex data over time, project managers require improved knowledge and access to relevant technologies that mediate data processes in complex projects, but equally reflect application across different project phases. These initial findings support further hypothesis testing through a larger quantitative study incorporating structural equation modelling to examine the relationship between artificial intelligence and project managers cognitive load with project data in complex contexts.
Adversarial Semi-supervised Learning for Corporate Credit Ratings
Apr 12, 2021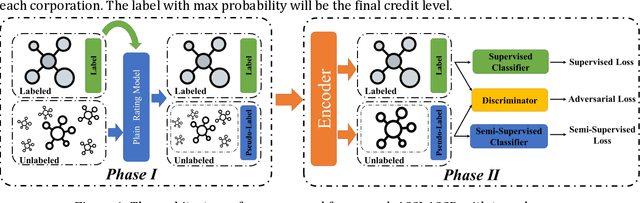
Corporate credit rating is an analysis of credit risks within a corporation, which plays a vital role during the management of financial risk. Traditionally, the rating assessment process based on the historical profile of corporation is usually expensive and complicated, which often takes months. Therefore, most of the corporations, which are lacking in money and time, can't get their own credit level. However, we believe that although these corporations haven't their credit rating levels (unlabeled data), this big data contains useful knowledge to improve credit system. In this work, its major challenge lies in how to effectively learn the knowledge from unlabeled data and help improve the performance of the credit rating system. Specifically, we consider the problem of adversarial semi-supervised learning (ASSL) for corporate credit rating which has been rarely researched before. A novel framework adversarial semi-supervised learning for corporate credit rating (ASSL4CCR) which includes two phases is proposed to address these problems. In the first phase, we train a normal rating system via a normal machine-learning algorithm to give unlabeled data pseudo rating level. Then in the second phase, adversarial semi-supervised learning is applied uniting labeled data and pseudo-labeled data. To demonstrate the effectiveness of the proposed ASSL4CCR, we conduct extensive experiments on the Chinese public-listed corporate rating dataset, which proves that ASSL4CCR outperforms the state-of-the-art methods consistently.
Generative Replay-based Continual Zero-Shot Learning
Jan 22, 2021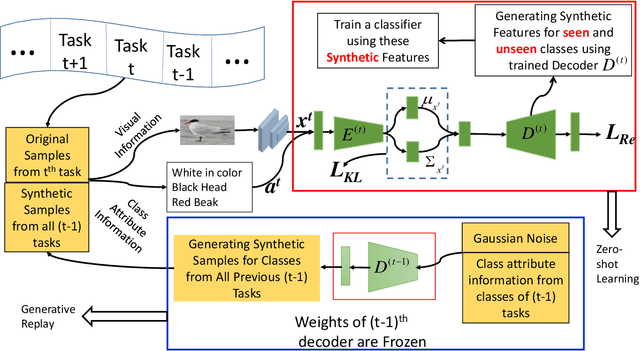


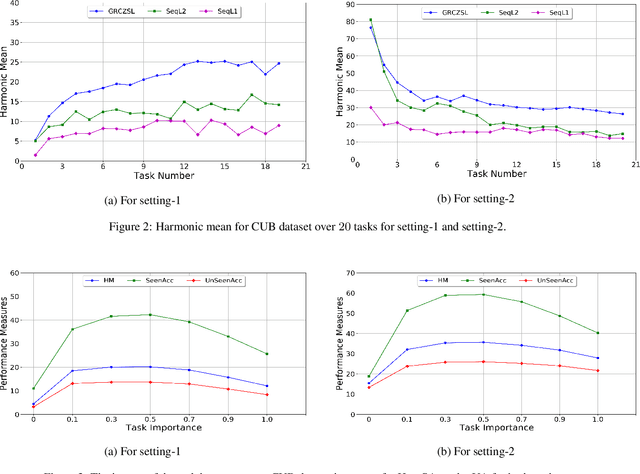
Zero-shot learning is a new paradigm to classify objects from classes that are not available at training time. Zero-shot learning (ZSL) methods have attracted considerable attention in recent years because of their ability to classify unseen/novel class examples. Most of the existing approaches on ZSL works when all the samples from seen classes are available to train the model, which does not suit real life. In this paper, we tackle this hindrance by developing a generative replay-based continual ZSL (GRCZSL). The proposed method endows traditional ZSL to learn from streaming data and acquire new knowledge without forgetting the previous tasks' gained experience. We handle catastrophic forgetting in GRCZSL by replaying the synthetic samples of seen classes, which have appeared in the earlier tasks. These synthetic samples are synthesized using the trained conditional variational autoencoder (VAE) over the immediate past task. Moreover, we only require the current and immediate previous VAE at any time for training and testing. The proposed GRZSL method is developed for a single-head setting of continual learning, simulating a real-world problem setting. In this setting, task identity is given during training but unavailable during testing. GRCZSL performance is evaluated on five benchmark datasets for the generalized setup of ZSL with fixed and incremental class settings of continual learning. Experimental results show that the proposed method significantly outperforms the baseline method and makes it more suitable for real-world applications.
Editable Free-viewpoint Video Using a Layered Neural Representation
Apr 30, 2021
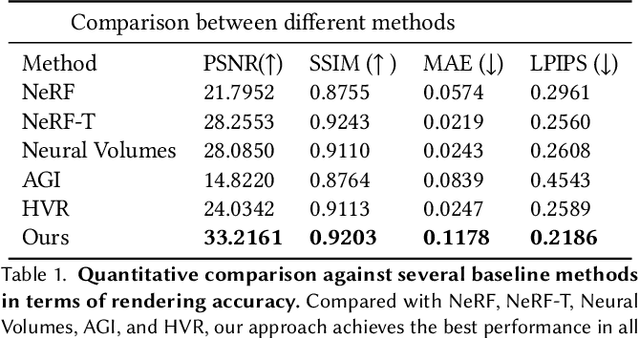
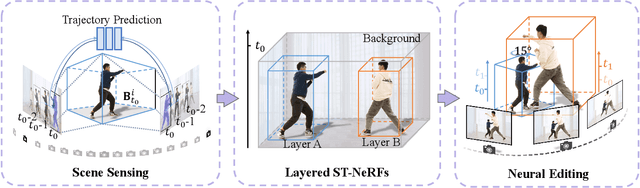
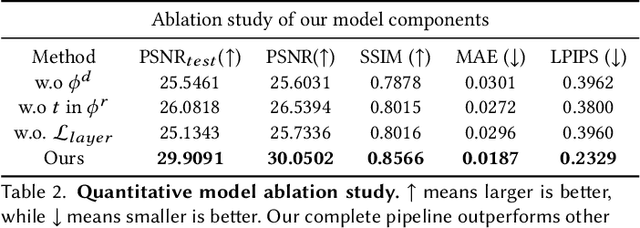
Generating free-viewpoint videos is critical for immersive VR/AR experience but recent neural advances still lack the editing ability to manipulate the visual perception for large dynamic scenes. To fill this gap, in this paper we propose the first approach for editable photo-realistic free-viewpoint video generation for large-scale dynamic scenes using only sparse 16 cameras. The core of our approach is a new layered neural representation, where each dynamic entity including the environment itself is formulated into a space-time coherent neural layered radiance representation called ST-NeRF. Such layered representation supports fully perception and realistic manipulation of the dynamic scene whilst still supporting a free viewing experience in a wide range. In our ST-NeRF, the dynamic entity/layer is represented as continuous functions, which achieves the disentanglement of location, deformation as well as the appearance of the dynamic entity in a continuous and self-supervised manner. We propose a scene parsing 4D label map tracking to disentangle the spatial information explicitly, and a continuous deform module to disentangle the temporal motion implicitly. An object-aware volume rendering scheme is further introduced for the re-assembling of all the neural layers. We adopt a novel layered loss and motion-aware ray sampling strategy to enable efficient training for a large dynamic scene with multiple performers, Our framework further enables a variety of editing functions, i.e., manipulating the scale and location, duplicating or retiming individual neural layers to create numerous visual effects while preserving high realism. Extensive experiments demonstrate the effectiveness of our approach to achieve high-quality, photo-realistic, and editable free-viewpoint video generation for dynamic scenes.
High-performance, Distributed Training of Large-scale Deep Learning Recommendation Models
Apr 12, 2021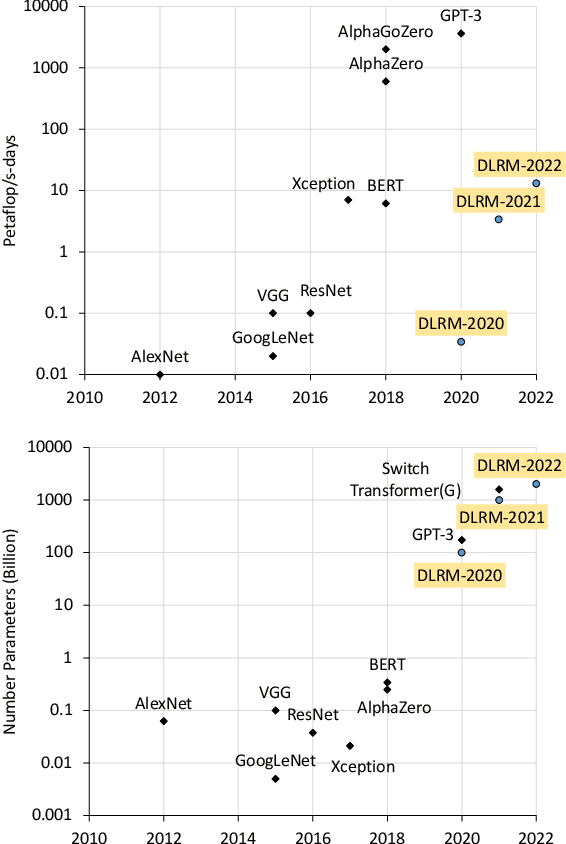

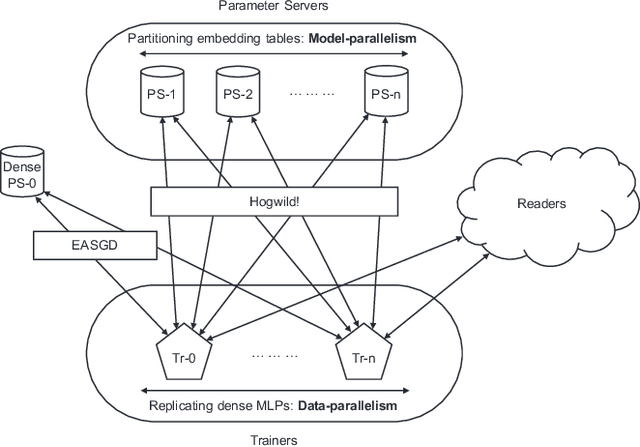
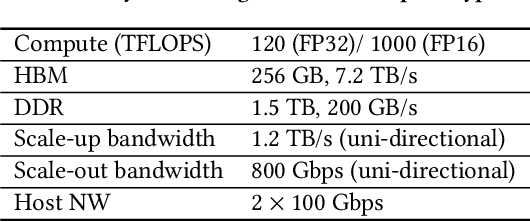
Deep learning recommendation models (DLRMs) are used across many business-critical services at Facebook and are the single largest AI application in terms of infrastructure demand in its data-centers. In this paper we discuss the SW/HW co-designed solution for high-performance distributed training of large-scale DLRMs. We introduce a high-performance scalable software stack based on PyTorch and pair it with the new evolution of \zion platform, namely \zionex. We demonstrate the capability to train very large DLRMs with up to \emph{12 Trillion parameters} and show that we can attain $40\times$ speedup in terms of time to solution over previous systems. We achieve this by (i) designing the \zionex platform with dedicated scale-out network, provisioned with high bandwidth, optimal topology and efficient transport (ii) implementing an optimized PyTorch-based training stack supporting both model and data parallelism (iii) developing sharding algorithms capable of hierarchical partitioning of the embedding tables along row, column dimensions and load balancing them across multiple workers; (iv) adding high-performance core operators while retaining flexibility to support optimizers with fully deterministic updates (v) leveraging reduced precision communications, multi-level memory hierarchy (HBM+DDR+SSD) and pipelining. Furthermore, we develop and briefly comment on distributed data ingestion and other supporting services that are required for the robust and efficient end-to-end training in production environments.
Continual Semantic Segmentation via Repulsion-Attraction of Sparse and Disentangled Latent Representations
Mar 10, 2021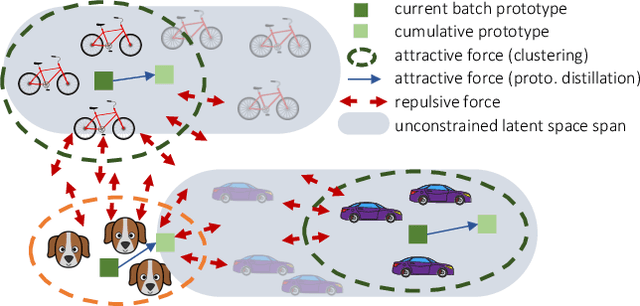
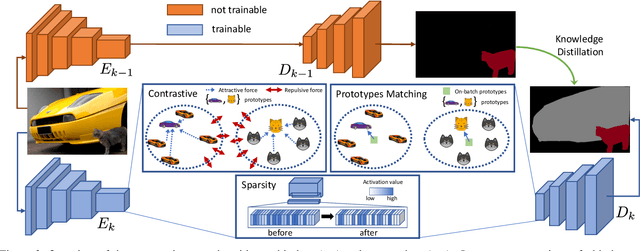
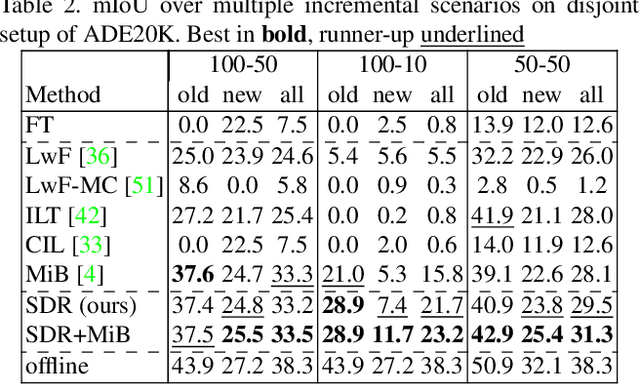

Deep neural networks suffer from the major limitation of catastrophic forgetting old tasks when learning new ones. In this paper we focus on class incremental continual learning in semantic segmentation, where new categories are made available over time while previous training data is not retained. The proposed continual learning scheme shapes the latent space to reduce forgetting whilst improving the recognition of novel classes. Our framework is driven by three novel components which we also combine on top of existing techniques effortlessly. First, prototypes matching enforces latent space consistency on old classes, constraining the encoder to produce similar latent representation for previously seen classes in the subsequent steps. Second, features sparsification allows to make room in the latent space to accommodate novel classes. Finally, contrastive learning is employed to cluster features according to their semantics while tearing apart those of different classes. Extensive evaluation on the Pascal VOC2012 and ADE20K datasets demonstrates the effectiveness of our approach, significantly outperforming state-of-the-art methods.
Variational Bayesian Sequence-to-Sequence Networks for Memory-Efficient Sign Language Translation
Feb 11, 2021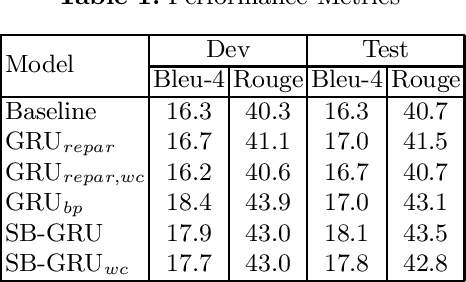
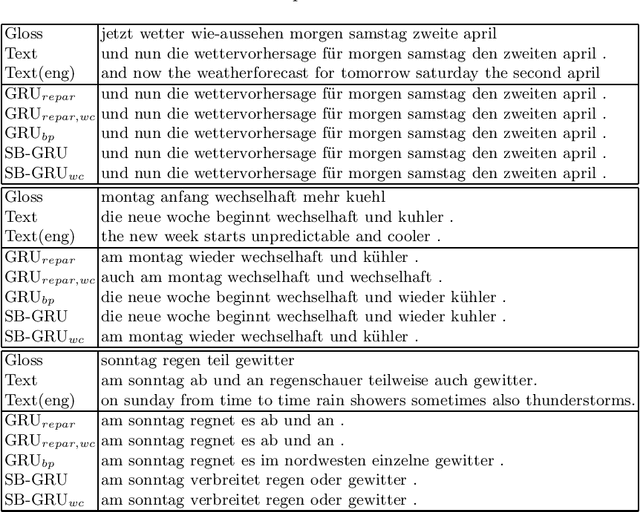
Memory-efficient continuous Sign Language Translation is a significant challenge for the development of assisted technologies with real-time applicability for the deaf. In this work, we introduce a paradigm of designing recurrent deep networks whereby the output of the recurrent layer is derived from appropriate arguments from nonparametric statistics. A novel variational Bayesian sequence-to-sequence network architecture is proposed that consists of a) a full Gaussian posterior distribution for data-driven memory compression and b) a nonparametric Indian Buffet Process prior for regularization applied on the Gated Recurrent Unit non-gate weights. We dub our approach Stick-Breaking Recurrent network and show that it can achieve a substantial weight compression without diminishing modeling performance.
Optimization of the Waiting Time for H-R Coordination
Sep 22, 2017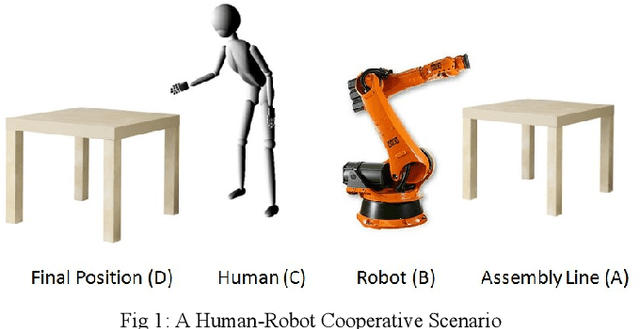
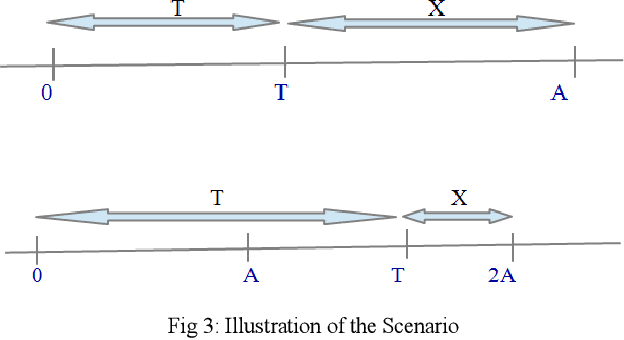
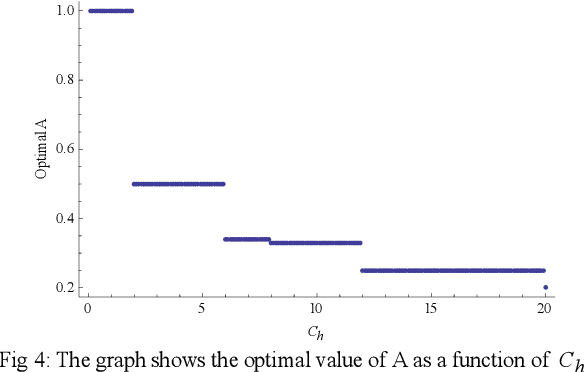
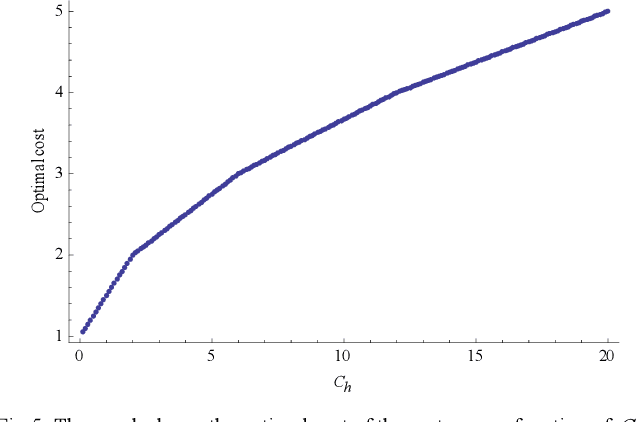
An analytical model of Human-Robot (H-R) coordination is presented for a Human-Robot system executing a collaborative task in which a high level of synchronization among the agents is desired. The influencing parameters and decision variables that affect the waiting time of the collaborating agents were analyzed. The performance of the model was evaluated based on the costs of the waiting times of each of the agents at the pre-defined spatial point of handover. The model was tested for two cases of dynamic H-R coordination scenarios. Results indicate that this analytical model can be used as a tool for designing an H-R system that optimizes the agent waiting time thereby increasing the joint-efficiency of the system and making coordination fluent and natural.