 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
GDPNet: Refining Latent Multi-View Graph for Relation Extraction
Dec 12, 2020

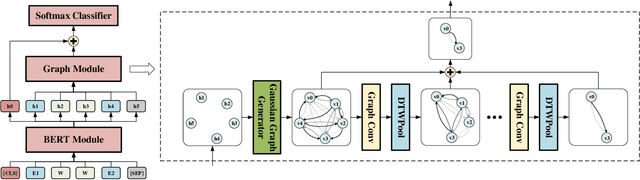
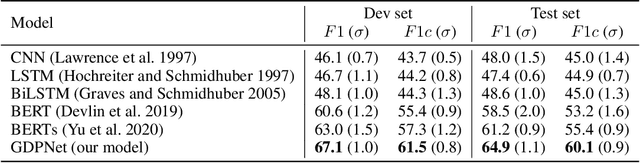
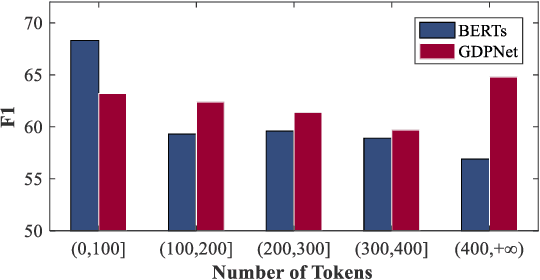
Relation Extraction (RE) is to predict the relation type of two entities that are mentioned in a piece of text, e.g., a sentence or a dialogue. When the given text is long, it is challenging to identify indicative words for the relation prediction. Recent advances on RE task are from BERT-based sequence modeling and graph-based modeling of relationships among the tokens in the sequence. In this paper, we propose to construct a latent multi-view graph to capture various possible relationships among tokens. We then refine this graph to select important words for relation prediction. Finally, the representation of the refined graph and the BERT-based sequence representation are concatenated for relation extraction. Specifically, in our proposed GDPNet (Gaussian Dynamic Time Warping Pooling Net), we utilize Gaussian Graph Generator (GGG) to generate edges of the multi-view graph. The graph is then refined by Dynamic Time Warping Pooling (DTWPool). On DialogRE and TACRED, we show that GDPNet achieves the best performance on dialogue-level RE, and comparable performance with the state-of-the-arts on sentence-level RE.
Algorithms and Hardness for Linear Algebra on Geometric Graphs
Nov 04, 2020

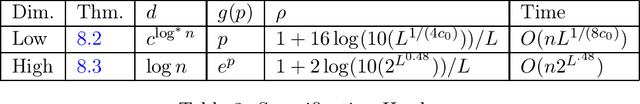

For a function $\mathsf{K} : \mathbb{R}^{d} \times \mathbb{R}^{d} \to \mathbb{R}_{\geq 0}$, and a set $P = \{ x_1, \ldots, x_n\} \subset \mathbb{R}^d$ of $n$ points, the $\mathsf{K}$ graph $G_P$ of $P$ is the complete graph on $n$ nodes where the weight between nodes $i$ and $j$ is given by $\mathsf{K}(x_i, x_j)$. In this paper, we initiate the study of when efficient spectral graph theory is possible on these graphs. We investigate whether or not it is possible to solve the following problems in $n^{1+o(1)}$ time for a $\mathsf{K}$-graph $G_P$ when $d < n^{o(1)}$: $\bullet$ Multiply a given vector by the adjacency matrix or Laplacian matrix of $G_P$ $\bullet$ Find a spectral sparsifier of $G_P$ $\bullet$ Solve a Laplacian system in $G_P$'s Laplacian matrix For each of these problems, we consider all functions of the form $\mathsf{K}(u,v) = f(\|u-v\|_2^2)$ for a function $f:\mathbb{R} \rightarrow \mathbb{R}$. We provide algorithms and comparable hardness results for many such $\mathsf{K}$, including the Gaussian kernel, Neural tangent kernels, and more. For example, in dimension $d = \Omega(\log n)$, we show that there is a parameter associated with the function $f$ for which low parameter values imply $n^{1+o(1)}$ time algorithms for all three of these problems and high parameter values imply the nonexistence of subquadratic time algorithms assuming Strong Exponential Time Hypothesis ($\mathsf{SETH}$), given natural assumptions on $f$. As part of our results, we also show that the exponential dependence on the dimension $d$ in the celebrated fast multipole method of Greengard and Rokhlin cannot be improved, assuming $\mathsf{SETH}$, for a broad class of functions $f$. To the best of our knowledge, this is the first formal limitation proven about fast multipole methods.
Understanding the Capabilities, Limitations, and Societal Impact of Large Language Models
Feb 04, 2021On October 14th, 2020, researchers from OpenAI, the Stanford Institute for Human-Centered Artificial Intelligence, and other universities convened to discuss open research questions surrounding GPT-3, the largest publicly-disclosed dense language model at the time. The meeting took place under Chatham House Rules. Discussants came from a variety of research backgrounds including computer science, linguistics, philosophy, political science, communications, cyber policy, and more. Broadly, the discussion centered around two main questions: 1) What are the technical capabilities and limitations of large language models? 2) What are the societal effects of widespread use of large language models? Here, we provide a detailed summary of the discussion organized by the two themes above.
Reinforcement Learning Control of a Forestry Crane Manipulator
Mar 03, 2021
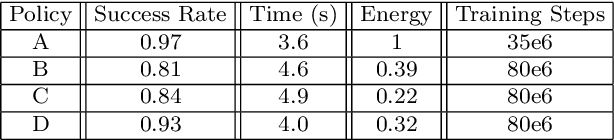
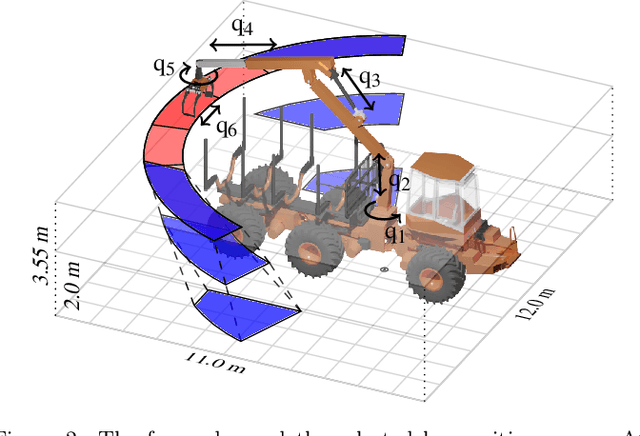
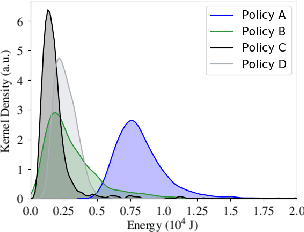
Forestry machines are heavy vehicles performing complex manipulation tasks in unstructured production forest environments. Together with the complex dynamics of the on-board hydraulically actuated cranes, the rough forest terrains have posed a particular challenge in forestry automation. In this study, the feasibility of applying reinforcement learning control to forestry crane manipulators is investigated in a simulated environment. Our results show that it is possible to learn successful actuator-space control policies for energy efficient log grasping by invoking a simple curriculum in a deep reinforcement learning setup. Given the pose of the selected logs, our best control policy reaches a grasping success rate of 97%. Including an energy-optimization goal in the reward function, the energy consumption is significantly reduced compared to control policies learned without incentive for energy optimization, while the increase in cycle time is marginal. The energy-optimization effects can be observed in the overall smoother motion and acceleration profiles during crane manipulation.
Neural networks behave as hash encoders: An empirical study
Jan 14, 2021

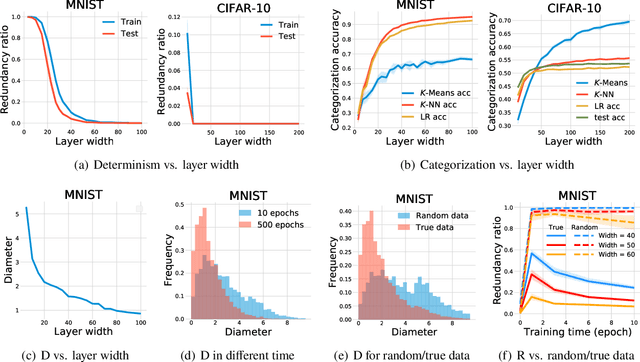
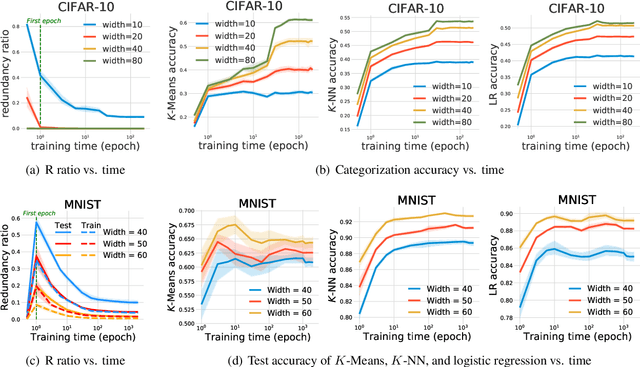
The input space of a neural network with ReLU-like activations is partitioned into multiple linear regions, each corresponding to a specific activation pattern of the included ReLU-like activations. We demonstrate that this partition exhibits the following encoding properties across a variety of deep learning models: (1) {\it determinism}: almost every linear region contains at most one training example. We can therefore represent almost every training example by a unique activation pattern, which is parameterized by a {\it neural code}; and (2) {\it categorization}: according to the neural code, simple algorithms, such as $K$-Means, $K$-NN, and logistic regression, can achieve fairly good performance on both training and test data. These encoding properties surprisingly suggest that {\it normal neural networks well-trained for classification behave as hash encoders without any extra efforts.} In addition, the encoding properties exhibit variability in different scenarios. {Further experiments demonstrate that {\it model size}, {\it training time}, {\it training sample size}, {\it regularization}, and {\it label noise} contribute in shaping the encoding properties, while the impacts of the first three are dominant.} We then define an {\it activation hash phase chart} to represent the space expanded by {model size}, training time, training sample size, and the encoding properties, which is divided into three canonical regions: {\it under-expressive regime}, {\it critically-expressive regime}, and {\it sufficiently-expressive regime}. The source code package is available at \url{https://github.com/LeavesLei/activation-code}.
STDP enhances learning by backpropagation in a spiking neural network
Feb 21, 2021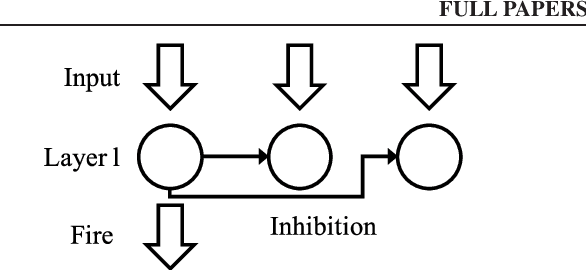
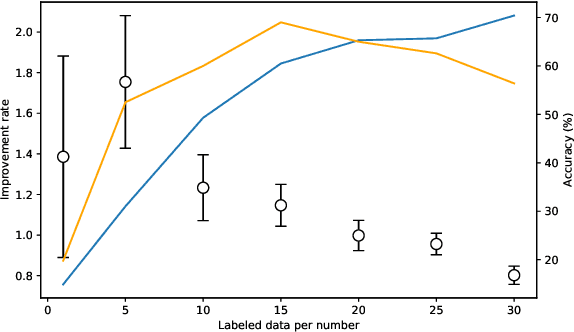
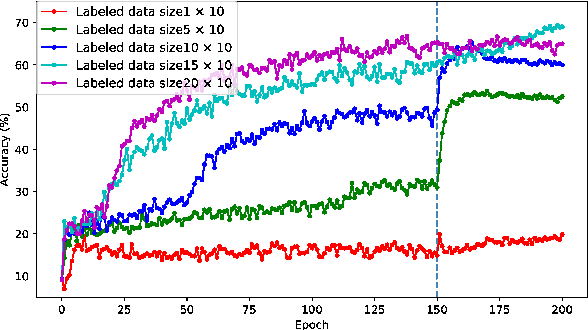
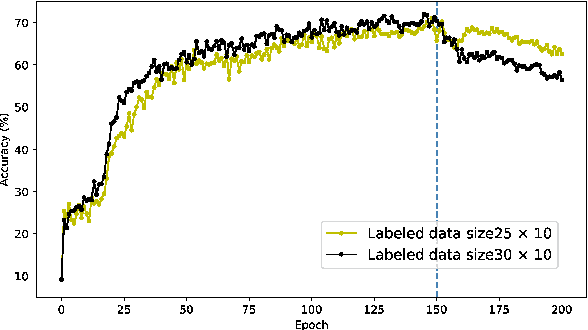
A semi-supervised learning method for spiking neural networks is proposed. The proposed method consists of supervised learning by backpropagation and subsequent unsupervised learning by spike-timing-dependent plasticity (STDP), which is a biologically plausible learning rule. Numerical experiments show that the proposed method improves the accuracy without additional labeling when a small amount of labeled data is used. This feature has not been achieved by existing semi-supervised learning methods of discriminative models. It is possible to implement the proposed learning method for event-driven systems. Hence, it would be highly efficient in real-time problems if it were implemented on neuromorphic hardware. The results suggest that STDP plays an important role other than self-organization when applied after supervised learning, which differs from the previous method of using STDP as pre-training interpreted as self-organization.
How COVID-19 Is Changing Our Language : Detecting Semantic Shift in Twitter Word Embeddings
Feb 15, 2021
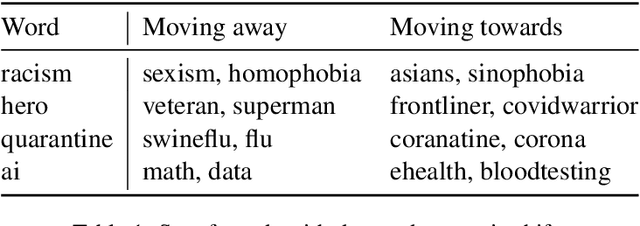
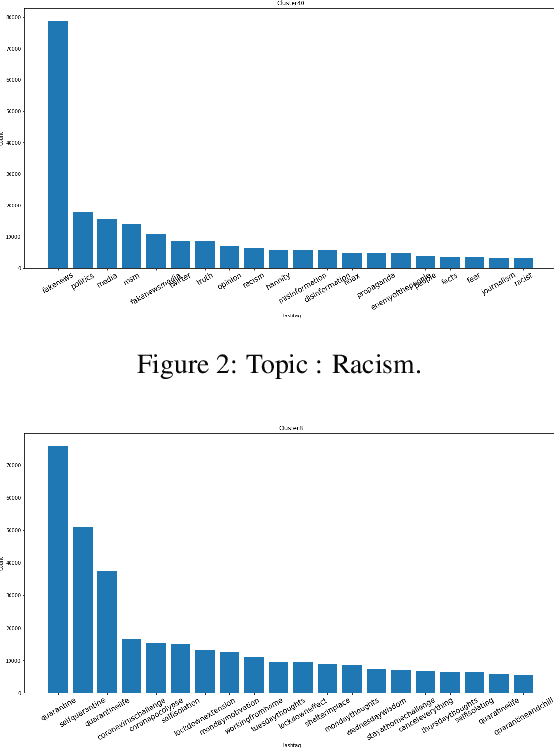
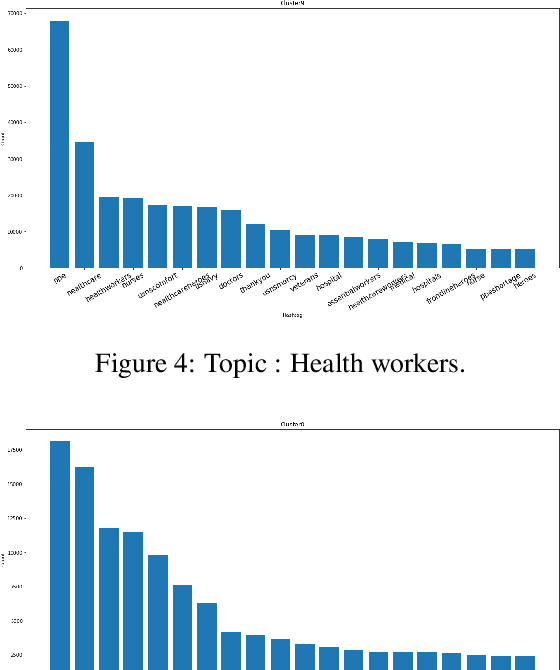
Words are malleable objects, influenced by events that are reflected in written texts. Situated in the global outbreak of COVID-19, our research aims at detecting semantic shifts in social media language triggered by the health crisis. With COVID-19 related big data extracted from Twitter, we train separate word embedding models for different time periods after the outbreak. We employ an alignment-based approach to compare these embeddings with a general-purpose Twitter embedding unrelated to COVID-19. We also compare our trained embeddings among them to observe diachronic evolution. Carrying out case studies on a set of words chosen by topic detection, we verify that our alignment approach is valid. Finally, we quantify the size of global semantic shift by a stability measure based on back-and-forth rotational alignment.
Phase-Modulated Radar Waveform Classification Using Deep Networks
Feb 15, 2021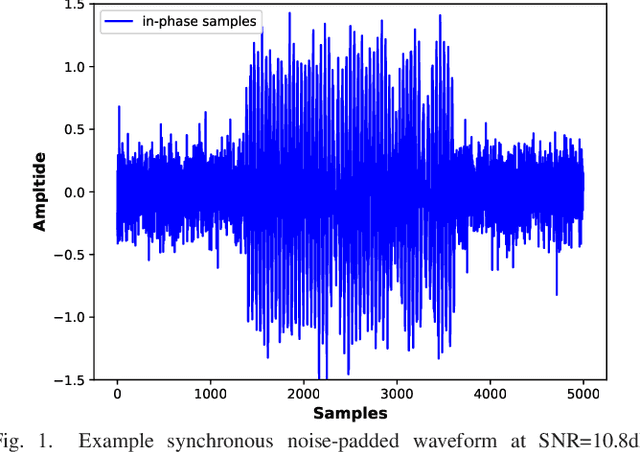
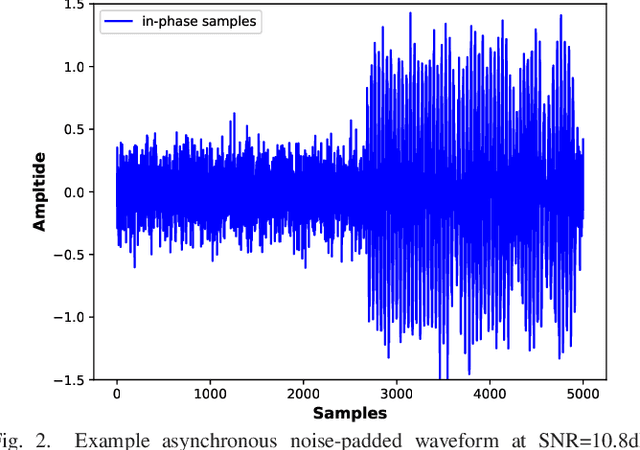
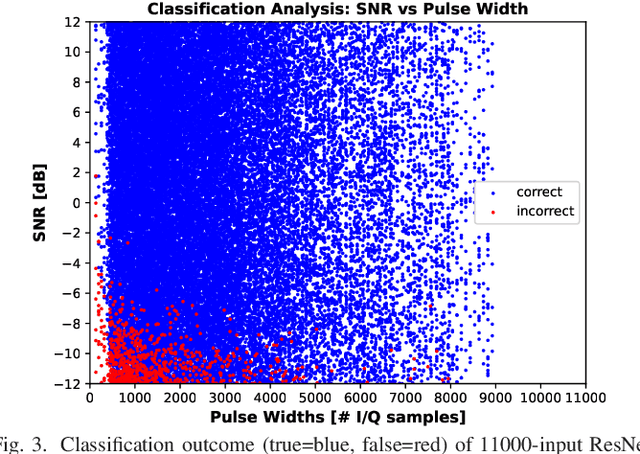
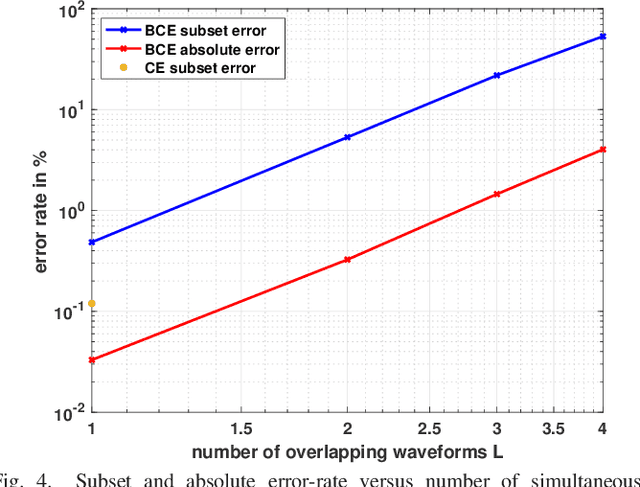
We consider the problem of classifying noisy, phase-modulated radar waveforms. While traditionally this has been accomplished by applying classical machine-learning algorithms on hand-crafted features, it has recently been shown that better performance can be attained by training deep neural networks (DNNs) to classify raw I/Q waveforms. However, existing DNNs assume time-synchronized waveforms and do not exploit complex-valued signal structure, and many aspects of the their DNN design and training are suboptimal. We demonstrate that, with an improved DNN architecture and training procedure, it is possible to reduce classification error from 18% to 0.14% on asynchronous waveforms from the SIDLE dataset. Unlike past work, we furthermore demonstrate that accurate classification of multiple overlapping waveforms is also possible, by achieving 4.0% error with 4 asynchronous SIDLE waveforms.
A Koopman Approach to Understanding Sequence Neural Models
Feb 15, 2021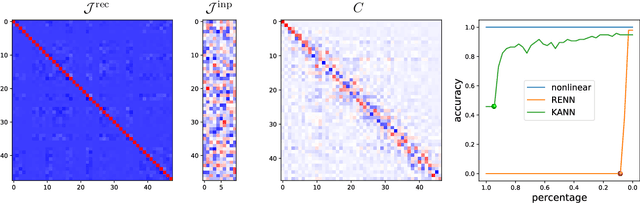

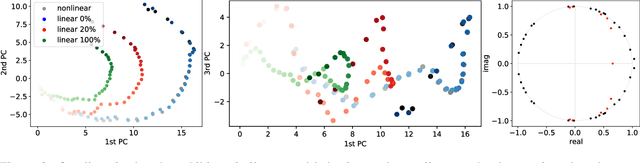

We introduce a new approach to understanding trained sequence neural models: the Koopman Analysis of Neural Networks (KANN) method. Motivated by the relation between time-series models and self-maps, we compute approximate Koopman operators that encode well the latent dynamics. Unlike other existing methods whose applicability is limited, our framework is global, and it has only weak constraints over the inputs. Moreover, the Koopman operator is linear, and it is related to a rich mathematical theory. Thus, we can use tools and insights from linear analysis and Koopman Theory in our study. For instance, we show that the operator eigendecomposition is instrumental in exploring the dominant features of the network. Our results extend across tasks and architectures as we demonstrate for the copy problem, and ECG classification and sentiment analysis tasks.
Bayesian hierarchical stacking
Jan 22, 2021
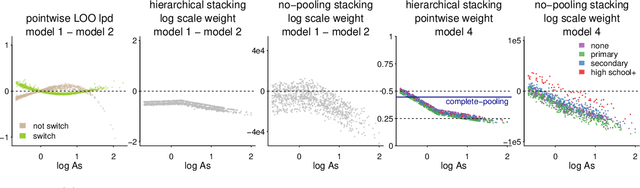
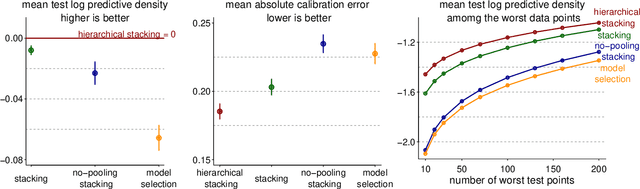
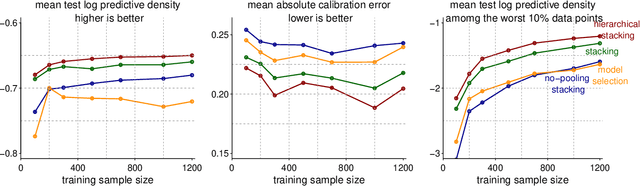
Stacking is a widely used model averaging technique that yields asymptotically optimal prediction among all linear averages. We show that stacking is most effective when the model predictive performance is heterogeneous in inputs, so that we can further improve the stacked mixture with a hierarchical model. With the input-varying yet partially-pooled model weights, hierarchical stacking improves average and conditional predictions. Our Bayesian formulation includes constant-weight (complete-pooling) stacking as a special case. We generalize to incorporate discrete and continuous inputs, other structured priors, and time-series and longitudinal data. We demonstrate on several applied problems.