 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
Skill Transfer via Partially Amortized Hierarchical Planning
Nov 27, 2020
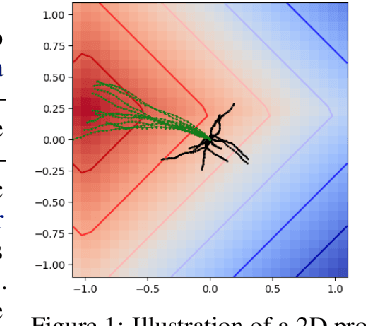
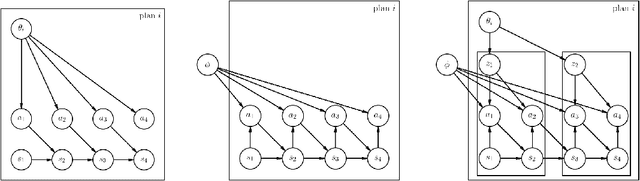
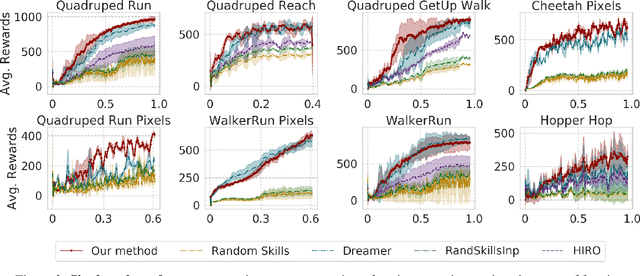
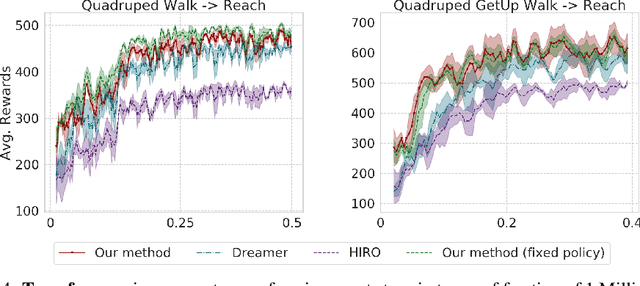
To quickly solve new tasks in complex environments, intelligent agents need to build up reusable knowledge. For example, a learned world model captures knowledge about the environment that applies to new tasks. Similarly, skills capture general behaviors that can apply to new tasks. In this paper, we investigate how these two approaches can be integrated into a single reinforcement learning agent. Specifically, we leverage the idea of partial amortization for fast adaptation at test time. For this, actions are produced by a policy that is learned over time while the skills it conditions on are chosen using online planning. We demonstrate the benefits of our design decisions across a suite of challenging locomotion tasks and demonstrate improved sample efficiency in single tasks as well as in transfer from one task to another, as compared to competitive baselines. Videos are available at: https://sites.google.com/view/partial-amortization-hierarchy/home
Real Negatives Matter: Continuous Training with Real Negatives for Delayed Feedback Modeling
Apr 29, 2021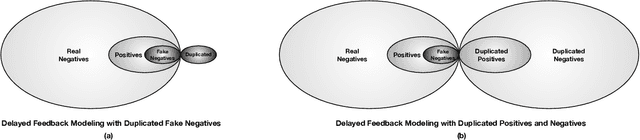

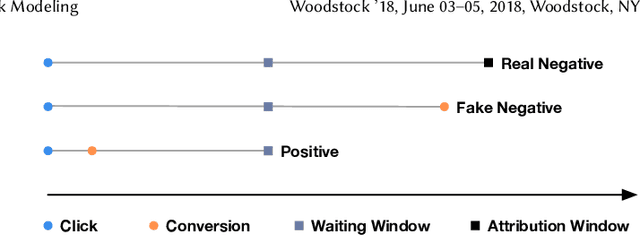
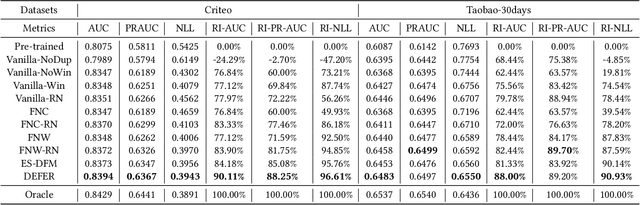
One of the difficulties of conversion rate (CVR) prediction is that the conversions can delay and take place long after the clicks. The delayed feedback poses a challenge: fresh data are beneficial to continuous training but may not have complete label information at the time they are ingested into the training pipeline. To balance model freshness and label certainty, previous methods set a short waiting window or even do not wait for the conversion signal. If conversion happens outside the waiting window, this sample will be duplicated and ingested into the training pipeline with a positive label. However, these methods have some issues. First, they assume the observed feature distribution remains the same as the actual distribution. But this assumption does not hold due to the ingestion of duplicated samples. Second, the certainty of the conversion action only comes from the positives. But the positives are scarce as conversions are sparse in commercial systems. These issues induce bias during the modeling of delayed feedback. In this paper, we propose DElayed FEedback modeling with Real negatives (DEFER) method to address these issues. The proposed method ingests real negative samples into the training pipeline. The ingestion of real negatives ensures the observed feature distribution is equivalent to the actual distribution, thus reducing the bias. The ingestion of real negatives also brings more certainty information of the conversion. To correct the distribution shift, DEFER employs importance sampling to weigh the loss function. Experimental results on industrial datasets validate the superiority of DEFER. DEFER have been deployed in the display advertising system of Alibaba, obtaining over 6.0% improvement on CVR in several scenarios. The code and data in this paper are now open-sourced {https://github.com/gusuperstar/defer.git}.
Robust Cell-Load Learning with a Small Sample Set
Mar 21, 2021
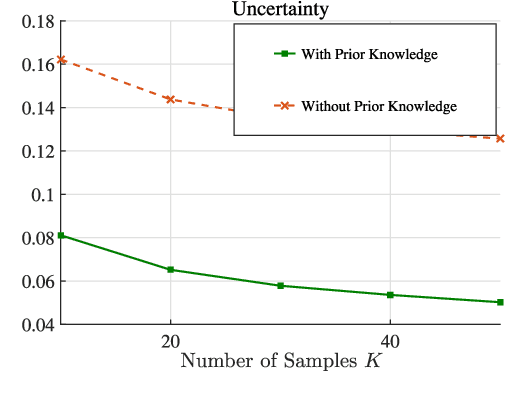
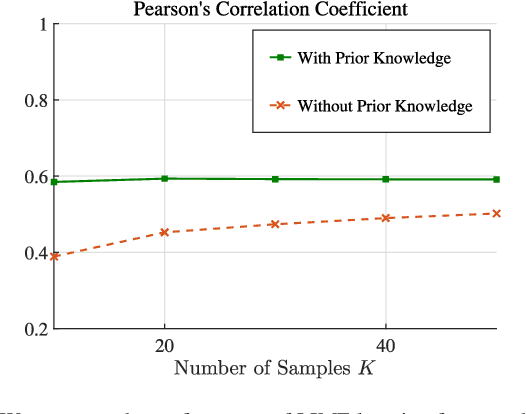
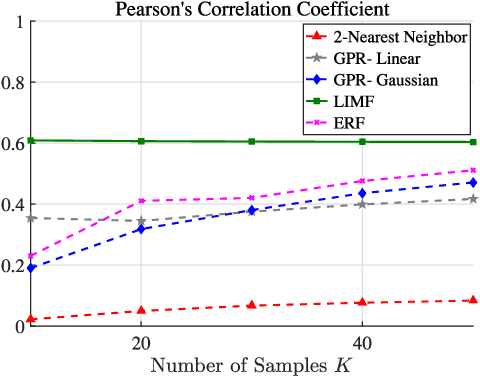
Learning of the cell-load in radio access networks (RANs) has to be performed within a short time period. Therefore, we propose a learning framework that is robust against uncertainties resulting from the need for learning based on a relatively small training sample set. To this end, we incorporate prior knowledge about the cell-load in the learning framework. For example, an inherent property of the cell-load is that it is monotonic in downlink (data) rates. To obtain additional prior knowledge we first study the feasible rate region, i.e., the set of all vectors of user rates that can be supported by the network. We prove that the feasible rate region is compact. Moreover, we show the existence of a Lipschitz function that maps feasible rate vectors to cell-load vectors. With these results in hand, we present a learning technique that guarantees a minimum approximation error in the worst-case scenario by using prior knowledge and a small training sample set. Simulations in the network simulator NS3 demonstrate that the proposed method exhibits better robustness and accuracy than standard multivariate learning techniques, especially for small training sample sets.
* Published in IEEE Transactions on Signal Processing ( Volume: 68)
Towards Real-time Eyeblink Detection in The Wild:Dataset,Theory and Practices
Feb 21, 2019
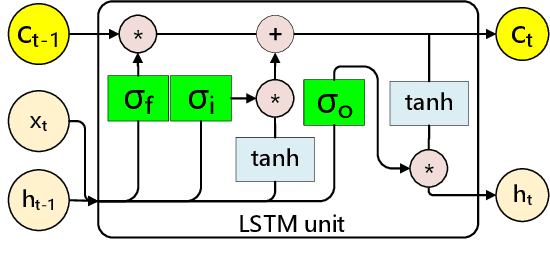
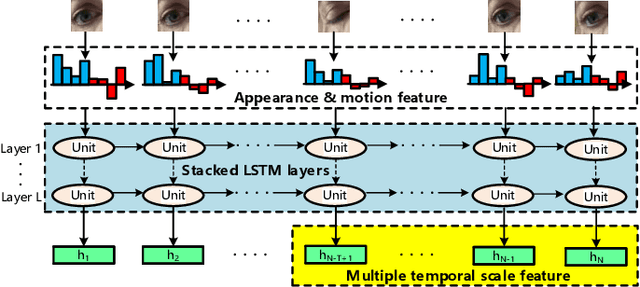
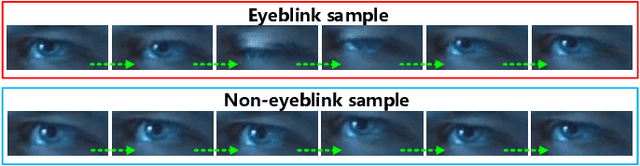
Effective and real-time eyeblink detection is of wide-range applications, such as deception detection, drive fatigue detection, face anti-spoofing, etc. Although numerous of efforts have already been paid, most of them focus on addressing the eyeblink detection problem under the constrained indoor conditions with the relative consistent subject and environment setup. Nevertheless, towards the practical applications eyeblink detection in the wild is more required, and of greater challenges. However, to our knowledge this has not been well studied before. In this paper, we shed the light to this research topic. A labelled eyeblink in the wild dataset (i.e., HUST-LEBW) of 673 eyeblink video samples (i.e., 381 positives, and 292 negatives) is first established by us. These samples are captured from the unconstrained movies, with the dramatic variation on human attribute, human pose, illumination condition, imaging configuration, etc. Then, we formulate eyeblink detection task as a spatial-temporal pattern recognition problem. After locating and tracking human eye using SeetaFace engine and KCF tracker respectively, a modified LSTM model able to capture the multi-scale temporal information is proposed to execute eyeblink verification. A feature extraction approach that reveals appearance and motion characteristics simultaneously is also proposed. The experiments on HUST-LEBW reveal the superiority and efficiency of our approach. It also verifies that, the existing eyeblink detection methods cannot achieve satisfactory performance in the wild.
A Learnable Self-supervised Task for Unsupervised Domain Adaptation on Point Clouds
Apr 12, 2021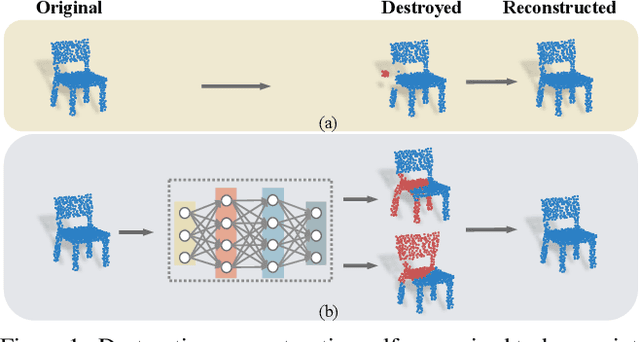
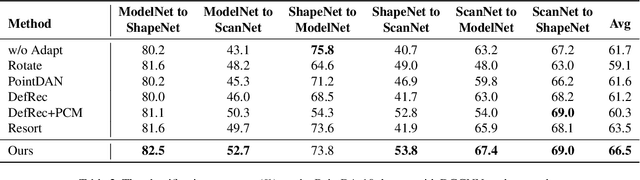
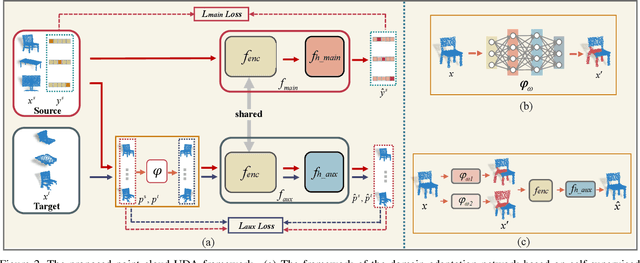
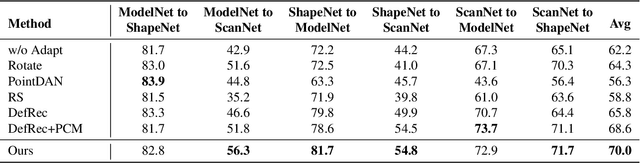
Deep neural networks have achieved promising performance in supervised point cloud applications, but manual annotation is extremely expensive and time-consuming in supervised learning schemes. Unsupervised domain adaptation (UDA) addresses this problem by training a model with only labeled data in the source domain but making the model generalize well in the target domain. Existing studies show that self-supervised learning using both source and target domain data can help improve the adaptability of trained models, but they all rely on hand-crafted designs of the self-supervised tasks. In this paper, we propose a learnable self-supervised task and integrate it into a self-supervision-based point cloud UDA architecture. Specifically, we propose a learnable nonlinear transformation that transforms a part of a point cloud to generate abundant and complicated point clouds while retaining the original semantic information, and the proposed self-supervised task is to reconstruct the original point cloud from the transformed ones. In the UDA architecture, an encoder is shared between the networks for the self-supervised task and the main task of point cloud classification or segmentation, so that the encoder can be trained to extract features suitable for both the source and the target domain data. Experiments on PointDA-10 and PointSegDA datasets show that the proposed method achieves new state-of-the-art performance on both classification and segmentation tasks of point cloud UDA. Code will be made publicly available.
GDPNet: Refining Latent Multi-View Graph for Relation Extraction
Dec 12, 2020
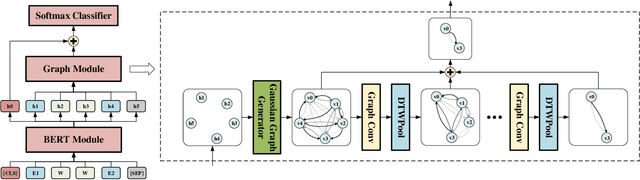
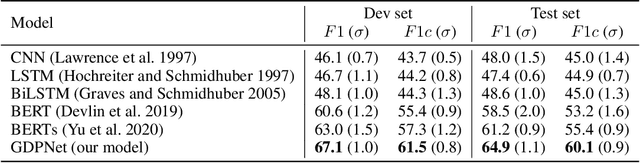
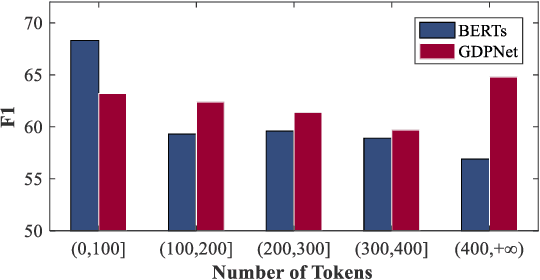
Relation Extraction (RE) is to predict the relation type of two entities that are mentioned in a piece of text, e.g., a sentence or a dialogue. When the given text is long, it is challenging to identify indicative words for the relation prediction. Recent advances on RE task are from BERT-based sequence modeling and graph-based modeling of relationships among the tokens in the sequence. In this paper, we propose to construct a latent multi-view graph to capture various possible relationships among tokens. We then refine this graph to select important words for relation prediction. Finally, the representation of the refined graph and the BERT-based sequence representation are concatenated for relation extraction. Specifically, in our proposed GDPNet (Gaussian Dynamic Time Warping Pooling Net), we utilize Gaussian Graph Generator (GGG) to generate edges of the multi-view graph. The graph is then refined by Dynamic Time Warping Pooling (DTWPool). On DialogRE and TACRED, we show that GDPNet achieves the best performance on dialogue-level RE, and comparable performance with the state-of-the-arts on sentence-level RE.
Restore from Restored: Single-image Inpainting
Feb 16, 2021
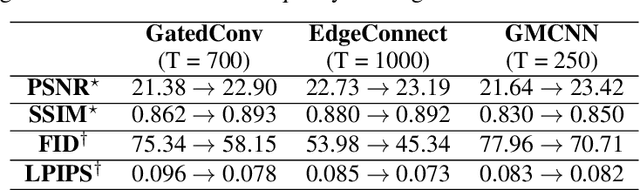
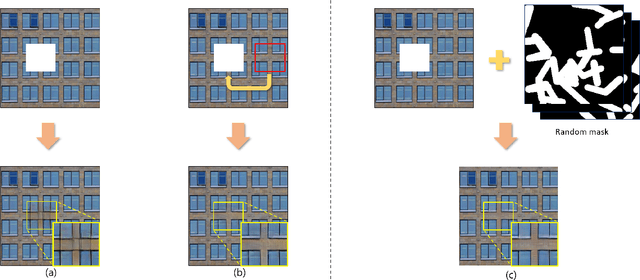
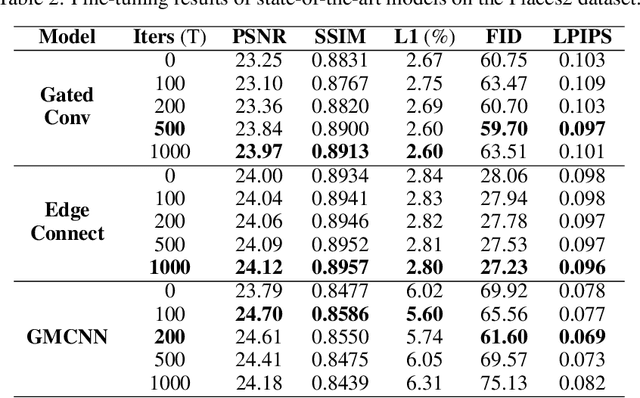
Recent image inpainting methods show promising results due to the power of deep learning, which can explore external information available from a large training dataset. However, many state-of-the-art inpainting networks are still limited in exploiting internal information available in the given input image at test time. To mitigate this problem, we present a novel and efficient self-supervised fine-tuning algorithm that can adapt the parameters of fully pretrained inpainting networks without using ground-truth clean image in this work. We upgrade the parameters of the pretrained networks by utilizing existing self-similar patches within the given input image without changing network architectures. Qualitative and quantitative experimental results demonstrate the superiority of the proposed algorithm and we achieve state-of-the-art inpainting results on publicly available numerous benchmark datasets.
Collocation Polynomial Neural Forms and Domain Fragmentation for Initial Value Problems
Mar 29, 2021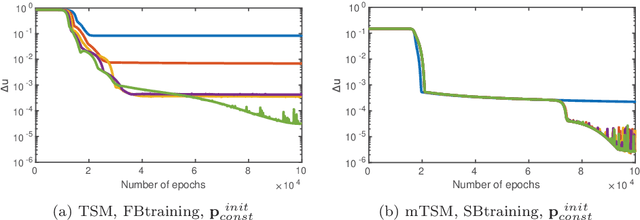
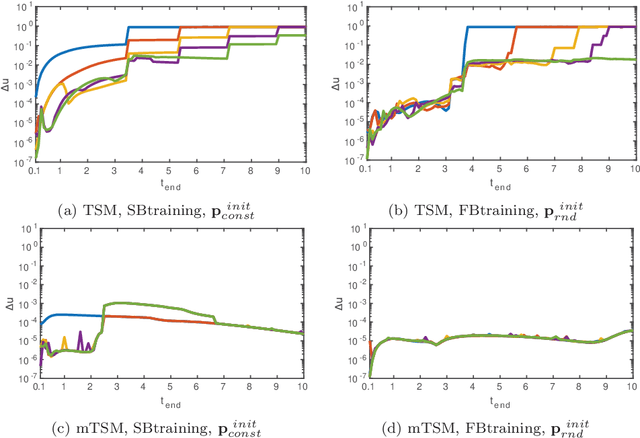
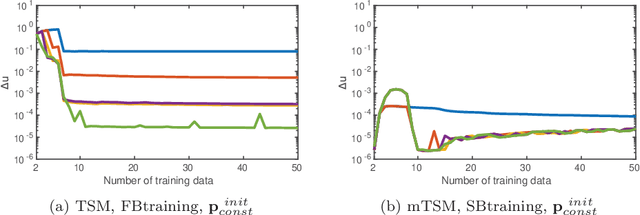
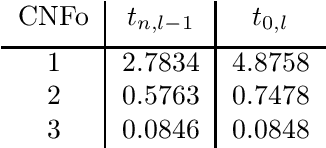
Several neural network approaches for solving differential equations employ trial solutions with a feedforward neural network. There are different means to incorporate the trial solution in the construction, for instance one may include them directly in the cost function. Used within the corresponding neural network, the trial solutions define the so-called neural form. Such neural forms represent general, flexible tools by which one may solve various differential equations. In this article we consider time-dependent initial value problems, which require to set up the neural form framework adequately. The neural forms presented up to now in the literature for such a setting can be considered as first order polynomials. In this work we propose to extend the polynomial order of the neural forms. The novel collocation-type construction includes several feedforward neural networks, one for each order. Additionally, we propose the fragmentation of the computational domain into subdomains. The neural forms are solved on each subdomain, whereas the interfacing grid points overlap in order to provide initial values over the whole fragmentation. We illustrate in experiments that the combination of collocation neural forms of higher order and the domain fragmentation allows to solve initial value problems over large domains with high accuracy and reliability.
External Dynamic InTerference Estimation and Removal (EDITER) for low field MRI
Apr 18, 2021
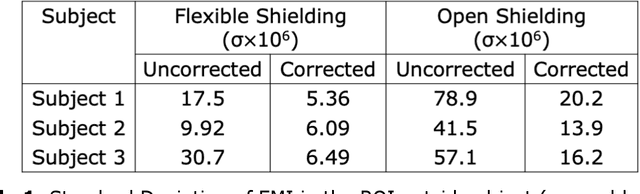
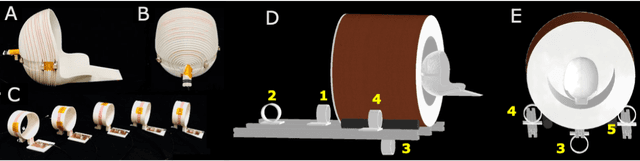
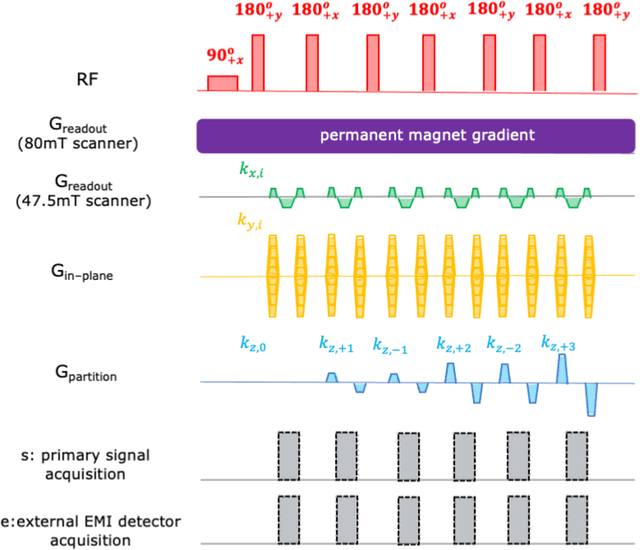
Purpose: Point-of-care MRI requires operation outside of a faraday shielded room normally used to block image-degrading electromagnetic Interference (EMI). To address this, we introduce the EDITER method, an external sensor based dynamic EMI estimation and removal method to retrospectively remove time-varying external interference sources. Theory and Methods: The method acquires data from multiple EMI detectors (tuned receive coils and electrodes placed on the body) simultaneous with the primary MR coil during image data acquisition. We dynamically calculate impulse response functions that map the data from the detectors to the artifacts in the kspace data, then remove the transformed detected EMI from the MR data. Performance of the EDITER algorithm was assessed in phantom and in vivo imaging experiments in an 80mT portable brain MRI in a controlled EMI environment and with an open 47.5mT MRI scanner in an uncontrolled EMI setting. Results: In the controlled setting, the effectiveness of the EDITER technique was demonstrated for specific types of introduced EMI sources with up to a 97% reduction of structured EMI and up to 76% reduction of broadband EMI. In the uncontrolled EMI experiments, we demonstrate EMI reductions of 37% with a single pickup coil and 89% with a single electrode and up to 99% with both. Conclusion: The EDITER technique is a flexible and robust method to improve image quality in portable MRI systems with minimal passive shielding. This could reduce the reliance of MRI on shielded rooms and allow for truly portable MRI with specialized compact POC scanners
Neural Particle Image Velocimetry
Jan 28, 2021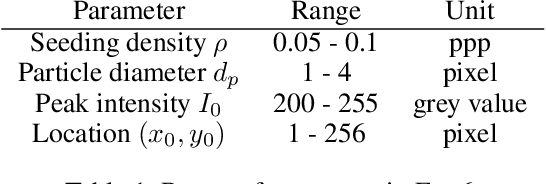
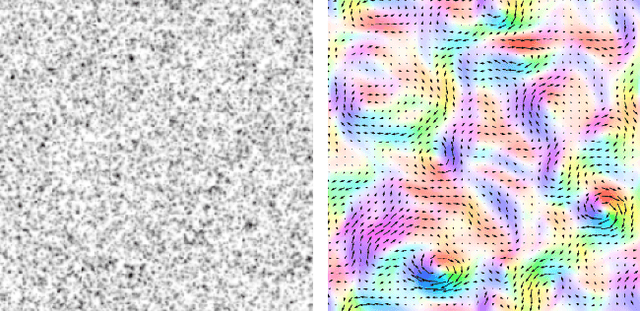

In the past decades, great progress has been made in the field of optical and particle-based measurement techniques for experimental analysis of fluid flows. Particle Image Velocimetry (PIV) technique is widely used to identify flow parameters from time-consecutive snapshots of particles injected into the fluid. The computation is performed as post-processing of the experimental data via proximity measure between particles in frames of reference. However, the post-processing step becomes problematic as the motility and density of the particles increases, since the data emerges in extreme rates and volumes. Moreover, existing algorithms for PIV either provide sparse estimations of the flow or require large computational time frame preventing from on-line use. The goal of this manuscript is therefore to develop an accurate on-line algorithm for estimation of the fine-grained velocity field from PIV data. As the data constitutes a pair of images, we employ computer vision methods to solve the problem. In this work, we introduce a convolutional neural network adapted to the problem, namely Volumetric Correspondence Network (VCN) which was recently proposed for the end-to-end optical flow estimation in computer vision. The network is thoroughly trained and tested on a dataset containing both synthetic and real flow data. Experimental results are analyzed and compared to that of conventional methods as well as other recently introduced methods based on neural networks. Our analysis indicates that the proposed approach provides improved efficiency also keeping accuracy on par with other state-of-the-art methods in the field. We also verify through a-posteriori tests that our newly constructed VCN schemes are reproducing well physically relevant statistics of velocity and velocity gradients.