 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge"Time": models, code, and papers
An Online Multilingual Hate speech Recognition System
Dec 22, 2020
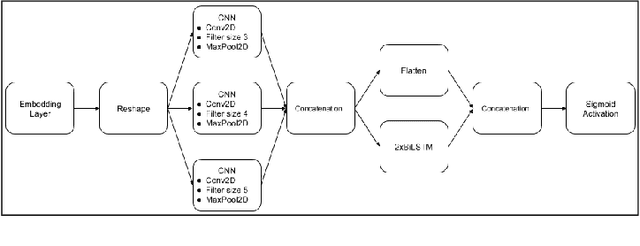
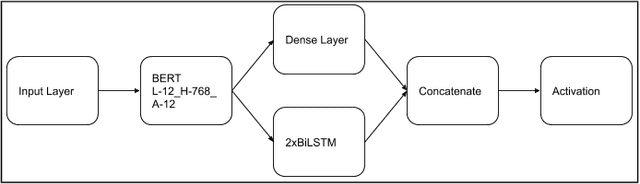

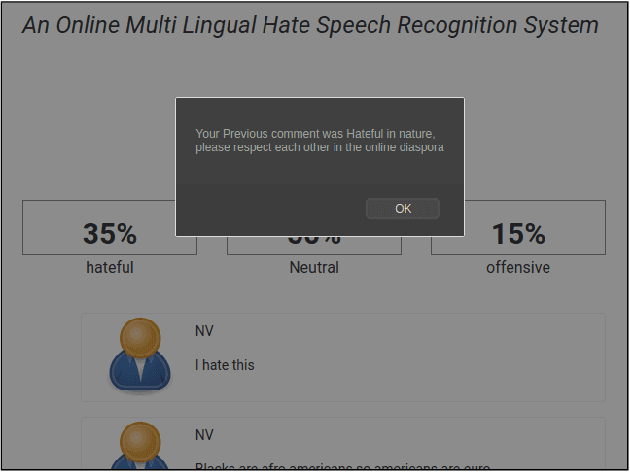
The exponential increase in the use of the Internet and social media over the last two decades has changed human interaction. This has led to many positive outcomes, but at the same time it has brought risks and harms. While the volume of harmful content online, such as hate speech, is not manageable by humans, interest in the academic community to investigate automated means for hate speech detection has increased. In this study, we analyse six publicly available datasets by combining them into a single homogeneous dataset and classify them into three classes, abusive, hateful or neither. We create a baseline model and we improve model performance scores using various optimisation techniques. After attaining a competitive performance score, we create a tool which identifies and scores a page with effective metric in near-real time and uses the same as feedback to re-train our model. We prove the competitive performance of our multilingual model on two langauges, English and Hindi, leading to comparable or superior performance to most monolingual models.
* 11 pages, 5 figures, appear in Special Issue "Natural Language Processing for Social Media" on MDPI Information 2021, 12(1), 5
Controllable Pareto Multi-Task Learning
Oct 13, 2020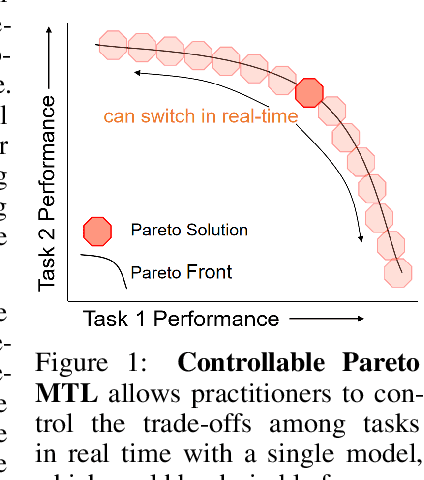
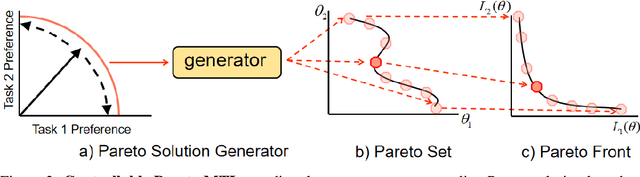
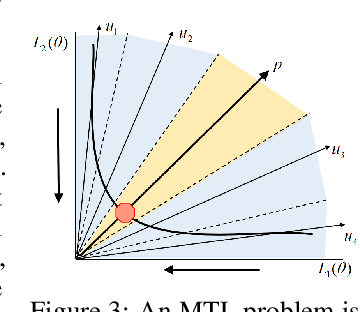

A multi-task learning (MTL) system aims at solving multiple related tasks at the same time. With a fixed model capacity, the tasks would be conflicted with each other, and the system usually has to make a trade-off among learning all of them together. Multiple models with different preferences over tasks have to be trained and stored for many real-world applications where the trade-off has to be made online. This work proposes a novel controllable Pareto multi-task learning framework, to enable the system to make real-time trade-off switch among different tasks with a single model. To be specific, we formulate the MTL as a preference-conditioned multiobjective optimization problem, for which there is a parametric mapping from the preferences to the optimal Pareto solutions. A single hypernetwork-based multi-task neural network is built to learn all tasks with different trade-off preferences among them, where the hypernetwork generates the model parameters conditioned on the preference. At the inference time, MTL practitioners can easily control the model performance based on different trade-off preferences in real-time. Experiments on different applications demonstrate that the proposed model is efficient for solving various multi-task learning problems.
FDMT: A Benchmark Dataset for Fine-grained Domain Adaptation in Machine Translation
Dec 31, 2020

Previous domain adaptation research usually neglect the diversity in translation within a same domain, which is a core problem for adapting a general neural machine translation (NMT) model into a specific domain in real-world scenarios. One representative of such challenging scenarios is to deploy a translation system for a conference with a specific topic, e.g. computer networks or natural language processing, where there is usually extremely less resources due to the limited time schedule. To motivate a wide investigation in such settings, we present a real-world fine-grained domain adaptation task in machine translation (FDMT). The FDMT dataset (Zh-En) consists of four sub-domains of information technology: autonomous vehicles, AI education, real-time networks and smart phone. To be closer to reality, FDMT does not employ any in-domain bilingual training data. Instead, each sub-domain is equipped with monolingual data, bilingual dictionary and knowledge base, to encourage in-depth exploration of these available resources. Corresponding development set and test set are provided for evaluation purpose. We make quantitative experiments and deep analyses in this new setting, which benchmarks the fine-grained domain adaptation task and reveals several challenging problems that need to be addressed.
Dopamine Transporter SPECT Image Classification for Neurodegenerative Parkinsonism via Diffusion Maps and Machine Learning Classifiers
May 07, 2021



Neurodegenerative parkinsonism can be assessed by dopamine transporter single photon emission computed tomography (DaT-SPECT). Although generating images is time consuming, these images can show interobserver variability and they have been visually interpreted by nuclear medicine physicians to date. Accordingly, this study aims to provide an automatic and robust method based on Diffusion Maps and machine learning classifiers to classify the SPECT images into two types, namely Normal and Abnormal DaT-SPECT image groups. In the proposed method, the 3D images of N patients are mapped to an N by N pairwise distance matrix and are visualized in Diffusion Maps coordinates. The images of the training set are embedded into a low-dimensional space by using diffusion maps. Moreover, we use Nystr\"om's out-of-sample extension, which embeds new sample points as the testing set in the reduced space. Testing samples in the embedded space are then classified into two types through the ensemble classifier with Linear Discriminant Analysis (LDA) and voting procedure through twenty-five-fold cross-validation results. The feasibility of the method is demonstrated via Parkinsonism Progression Markers Initiative (PPMI) dataset of 1097 subjects and a clinical cohort from Kaohsiung Chang Gung Memorial Hospital (KCGMH-TW) of 630 patients. We compare performances using Diffusion Maps with those of three alternative manifold methods for dimension reduction, namely Locally Linear Embedding (LLE), Isomorphic Mapping Algorithm (Isomap), and Kernel Principal Component Analysis (Kernel PCA). We also compare results using 2D and 3D CNN methods. The diffusion maps method has an average accuracy of 98% for the PPMI and 90% for the KCGMH-TW dataset with twenty-five fold cross-validation results. It outperforms the other three methods concerning the overall accuracy and the robustness in the training and testing samples.
Machine Biometrics -- Towards Identifying Machines in a Smart City Environment
Feb 25, 2021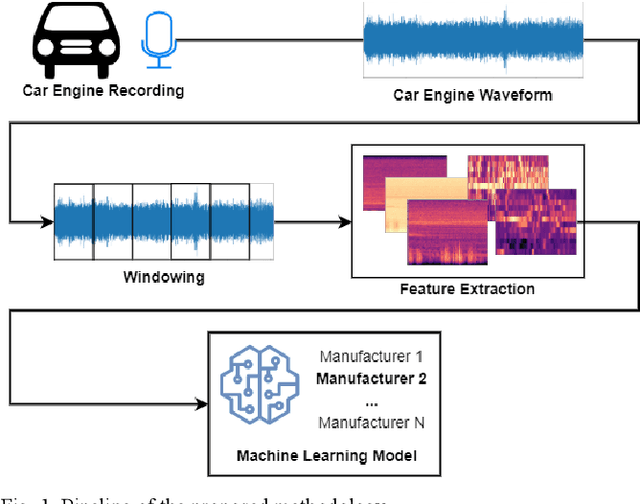
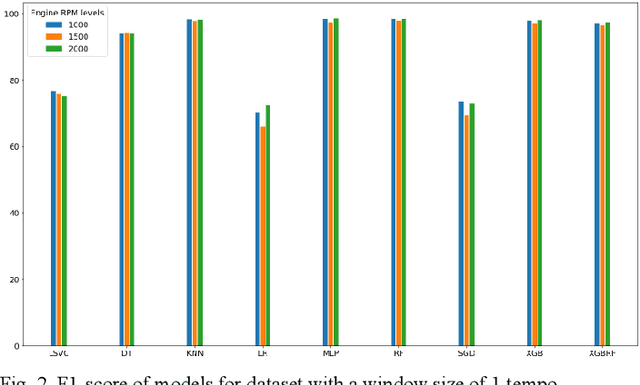
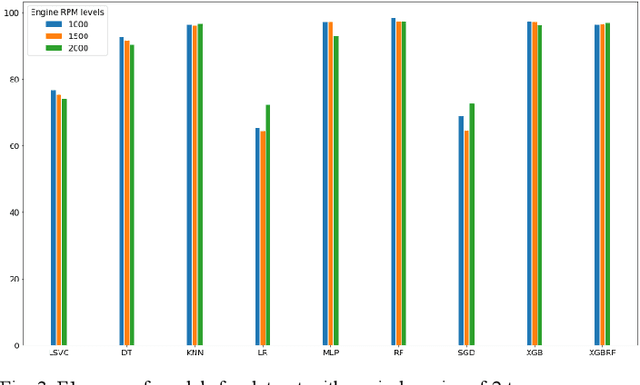
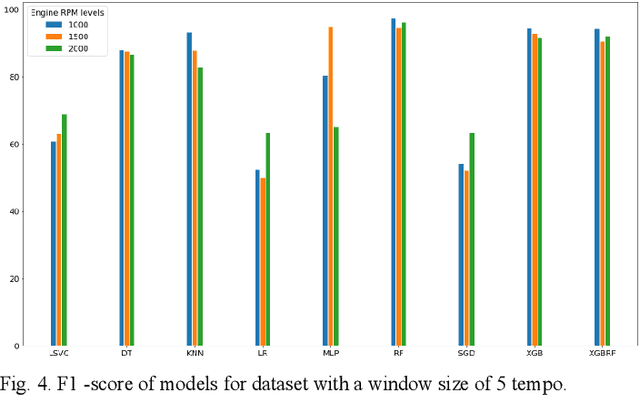
This paper deals with the identification of machines in a smart city environment. The concept of machine biometrics is proposed in this work for the first time, as a way to authenticate machine identities interacting with humans in everyday life. This definition is imposed in modern years where autonomous vehicles, social robots, etc. are considered active members of contemporary societies. In this context, the case of car identification from the engine behavioral biometrics is examined. For this purpose, 22 sound features were extracted and their discrimination capabilities were tested in combination with 9 different machine learning classifiers, towards identifying 5 car manufacturers. The experimental results revealed the ability of the proposed biometrics to identify cars with high accuracy up to 98% for the case of the Multilayer Perceptron (MLP) neural network model.
Stereo Camera Visual SLAM with Hierarchical Masking and Motion-state Classification at Outdoor Construction Sites Containing Large Dynamic Objects
Jan 17, 2021


At modern construction sites, utilizing GNSS (Global Navigation Satellite System) to measure the real-time location and orientation (i.e. pose) of construction machines and navigate them is very common. However, GNSS is not always available. Replacing GNSS with on-board cameras and visual simultaneous localization and mapping (visual SLAM) to navigate the machines is a cost-effective solution. Nevertheless, at construction sites, multiple construction machines will usually work together and side-by-side, causing large dynamic occlusions in the cameras' view. Standard visual SLAM cannot handle large dynamic occlusions well. In this work, we propose a motion segmentation method to efficiently extract static parts from crowded dynamic scenes to enable robust tracking of camera ego-motion. Our method utilizes semantic information combined with object-level geometric constraints to quickly detect the static parts of the scene. Then, we perform a two-step coarse-to-fine ego-motion tracking with reference to the static parts. This leads to a novel dynamic visual SLAM formation. We test our proposals through a real implementation based on ORB-SLAM2, and datasets we collected from real construction sites. The results show that when standard visual SLAM fails, our method can still retain accurate camera ego-motion tracking in real-time. Comparing to state-of-the-art dynamic visual SLAM methods, ours shows outstanding efficiency and competitive result trajectory accuracy.
* This is an Accepted Manuscript of an article published by Taylor & Francis in Advanced Robotics on Jan. 11th, 2021, available online: https://www.tandfonline.com/doi/full/10.1080/01691864.2020.1869586 [Article DOI:10.1080/01691864.2020.1869586]
YOLO3D: End-to-end real-time 3D Oriented Object Bounding Box Detection from LiDAR Point Cloud
Aug 07, 2018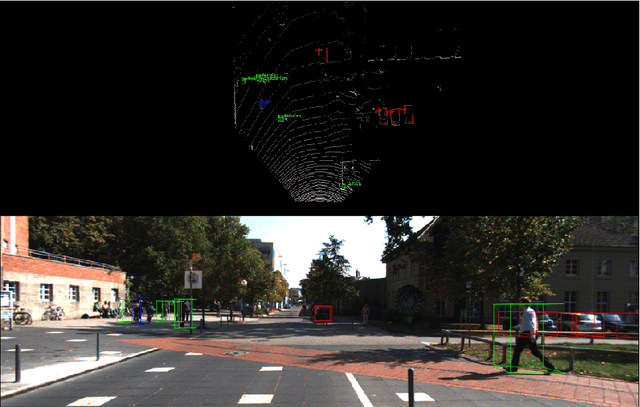
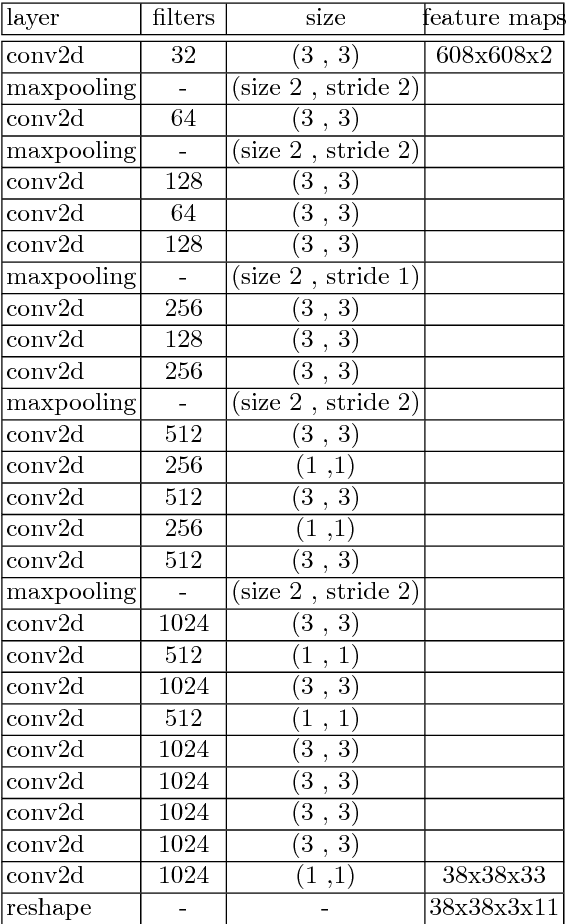

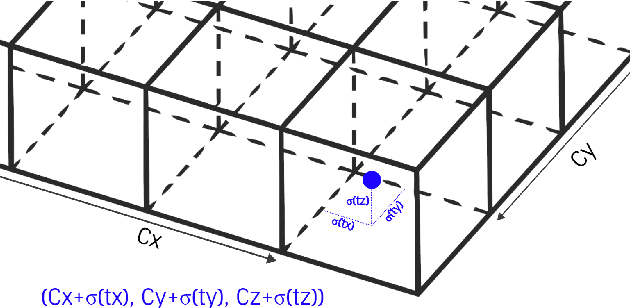
Object detection and classification in 3D is a key task in Automated Driving (AD). LiDAR sensors are employed to provide the 3D point cloud reconstruction of the surrounding environment, while the task of 3D object bounding box detection in real time remains a strong algorithmic challenge. In this paper, we build on the success of the one-shot regression meta-architecture in the 2D perspective image space and extend it to generate oriented 3D object bounding boxes from LiDAR point cloud. Our main contribution is in extending the loss function of YOLO v2 to include the yaw angle, the 3D box center in Cartesian coordinates and the height of the box as a direct regression problem. This formulation enables real-time performance, which is essential for automated driving. Our results are showing promising figures on KITTI benchmark, achieving real-time performance (40 fps) on Titan X GPU.
Towards Extremely Compact RNNs for Video Recognition with Fully Decomposed Hierarchical Tucker Structure
Apr 20, 2021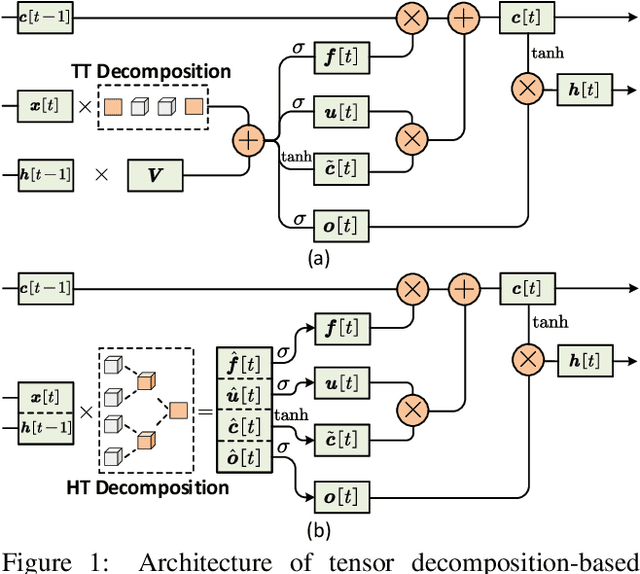
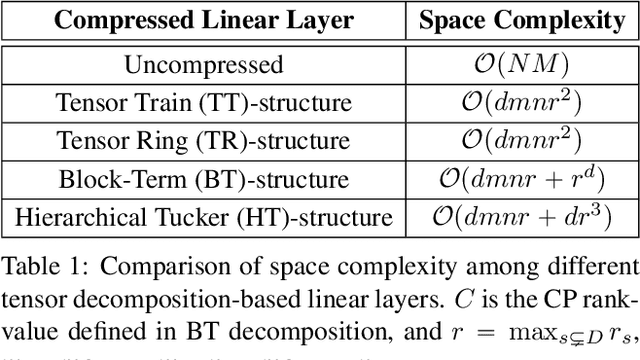
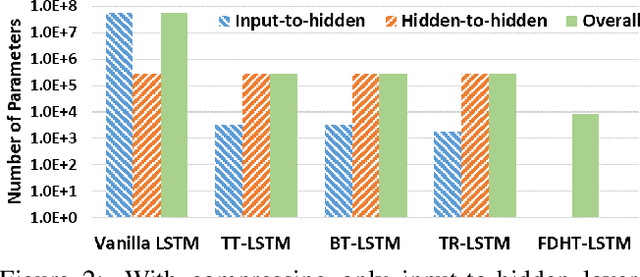
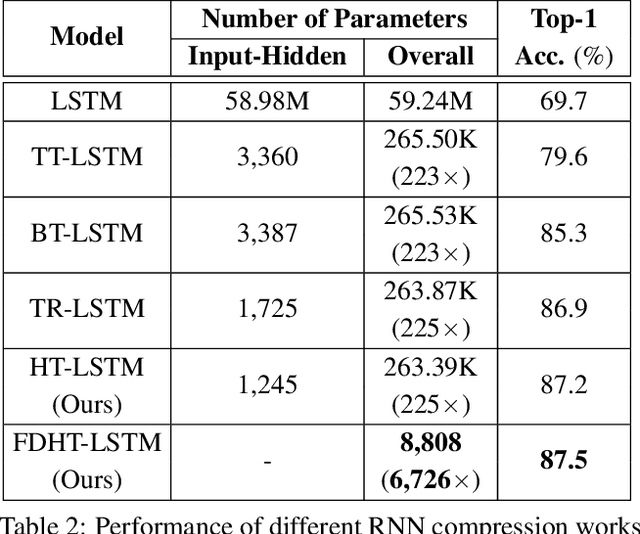
Recurrent Neural Networks (RNNs) have been widely used in sequence analysis and modeling. However, when processing high-dimensional data, RNNs typically require very large model sizes, thereby bringing a series of deployment challenges. Although various prior works have been proposed to reduce the RNN model sizes, executing RNN models in resource-restricted environments is still a very challenging problem. In this paper, we propose to develop extremely compact RNN models with fully decomposed hierarchical Tucker (FDHT) structure. The HT decomposition does not only provide much higher storage cost reduction than the other tensor decomposition approaches but also brings better accuracy performance improvement for the compact RNN models. Meanwhile, unlike the existing tensor decomposition-based methods that can only decompose the input-to-hidden layer of RNNs, our proposed fully decomposition approach enables the comprehensive compression for the entire RNN models with maintaining very high accuracy. Our experimental results on several popular video recognition datasets show that our proposed fully decomposed hierarchical tucker-based LSTM (FDHT-LSTM) is extremely compact and highly efficient. To the best of our knowledge, FDHT-LSTM, for the first time, consistently achieves very high accuracy with only few thousand parameters (3,132 to 8,808) on different datasets. Compared with the state-of-the-art compressed RNN models, such as TT-LSTM, TR-LSTM and BT-LSTM, our FDHT-LSTM simultaneously enjoys both order-of-magnitude (3,985x to 10,711x) fewer parameters and significant accuracy improvement (0.6% to 12.7%).
Learning Parallel Dense Correspondence from Spatio-Temporal Descriptors for Efficient and Robust 4D Reconstruction
Mar 30, 2021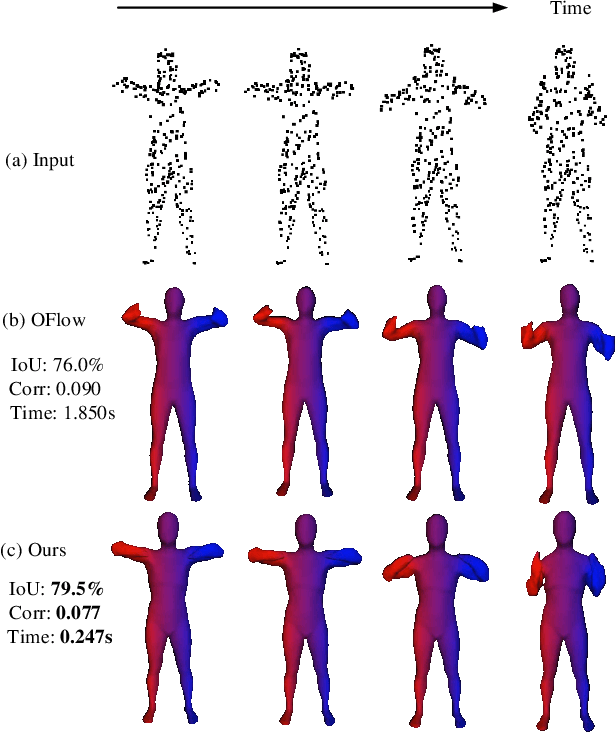
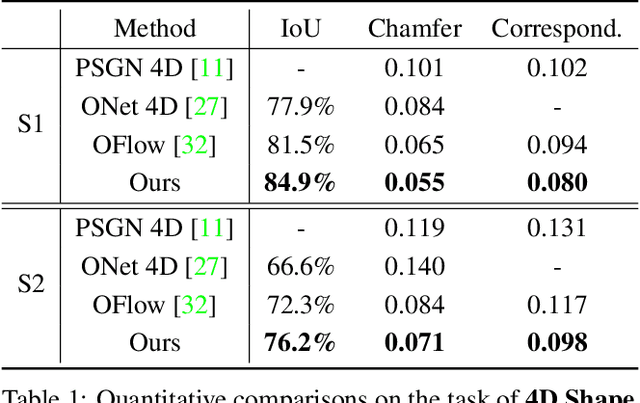
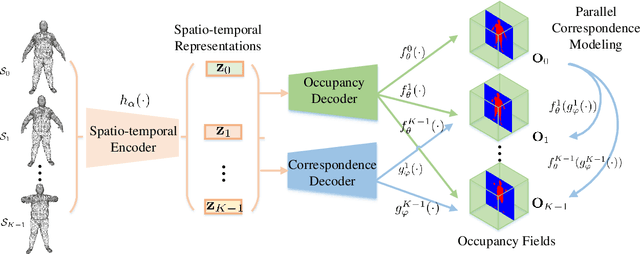
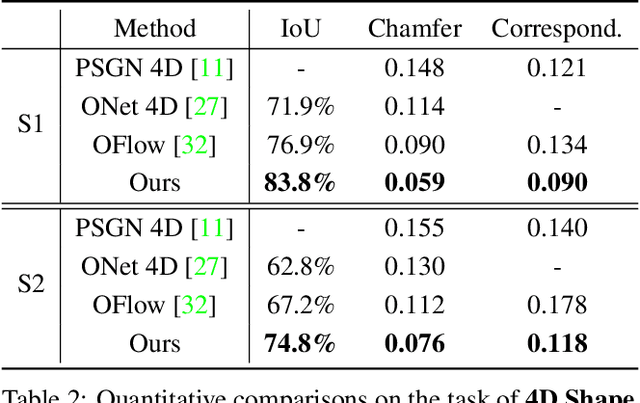
This paper focuses on the task of 4D shape reconstruction from a sequence of point clouds. Despite the recent success achieved by extending deep implicit representations into 4D space, it is still a great challenge in two respects, i.e. how to design a flexible framework for learning robust spatio-temporal shape representations from 4D point clouds, and develop an efficient mechanism for capturing shape dynamics. In this work, we present a novel pipeline to learn a temporal evolution of the 3D human shape through spatially continuous transformation functions among cross-frame occupancy fields. The key idea is to parallelly establish the dense correspondence between predicted occupancy fields at different time steps via explicitly learning continuous displacement vector fields from robust spatio-temporal shape representations. Extensive comparisons against previous state-of-the-arts show the superior accuracy of our approach for 4D human reconstruction in the problems of 4D shape auto-encoding and completion, and a much faster network inference with about 8 times speedup demonstrates the significant efficiency of our approach. The trained models and implementation code are available at https://github.com/tangjiapeng/LPDC-Net.
Variational models for signal processing with Graph Neural Networks
Mar 30, 2021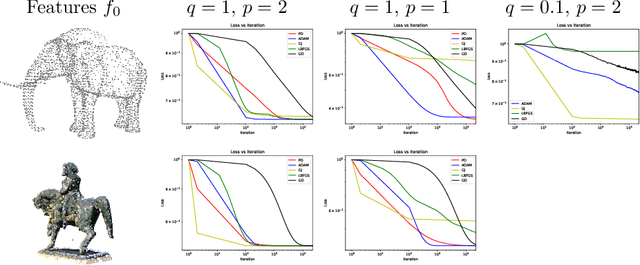
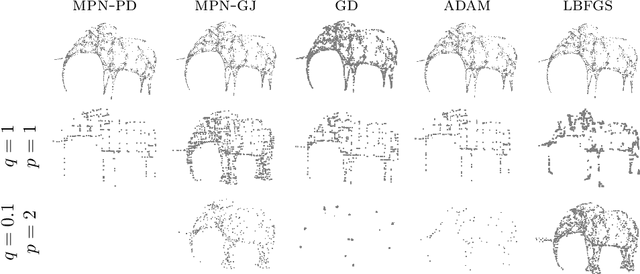

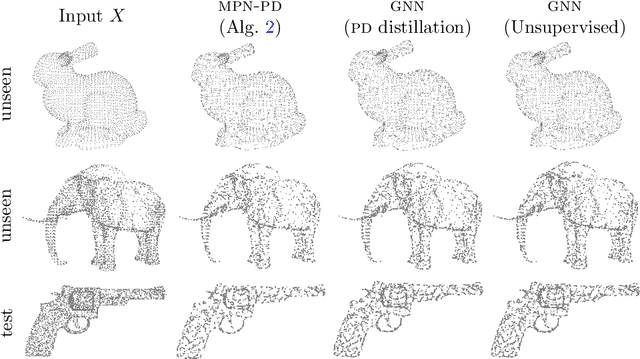
This paper is devoted to signal processing on point-clouds by means of neural networks. Nowadays, state-of-the-art in image processing and computer vision is mostly based on training deep convolutional neural networks on large datasets. While it is also the case for the processing of point-clouds with Graph Neural Networks (GNN), the focus has been largely given to high-level tasks such as classification and segmentation using supervised learning on labeled datasets such as ShapeNet. Yet, such datasets are scarce and time-consuming to build depending on the target application. In this work, we investigate the use of variational models for such GNN to process signals on graphs for unsupervised learning.Our contributions are two-fold. We first show that some existing variational-based algorithms for signals on graphs can be formulated as Message Passing Networks (MPN), a particular instance of GNN, making them computationally efficient in practice when compared to standard gradient-based machine learning algorithms. Secondly, we investigate the unsupervised learning of feed-forward GNN, either by direct optimization of an inverse problem or by model distillation from variational-based MPN. Keywords:Graph Processing. Neural Network. Total Variation. Variational Methods. Message Passing Network. Unsupervised learning